数据传输过程中数据结构的映射实现
2023-05-17张大禹
张大禹
(中国人民解放军91550 部队 辽宁省大连市 116000)
在数据传输的过程中,数据本身的结构变化对于用户来说是透明的,但是数据的接收端和发送端,在数据结构和存储策略方面不可能永远一致,因此就出现了称之为“字节一致”的原则,用于实现数据接收端对于所接收到数据处理,尤其是当涉及传输位域结构相关问题的时候,这一原则的价值尤其突出,能够帮助将将传输过程中的数据碎片重新组合在一起。
1 数据的书写规则
数据无论是在日常生活中还是在计算机传输和存储领域中,都有一定的规则可以遵循,这些规则的存在让读者或者信息的接收端能够合理对内容进行理解。
数据存储涉及到字节序(byte-order)与比特序(bit-order)两个概念,多种情况下字节会被作为数据存储的基本单元对待,但是字节序并不是存储顺序,这二者之间还存在比特的编址问题。对于不同的存储系统来说,其存储顺序也有所不同,这样的系统之间想要实现有效的数据交换,如果涉及到按位定义的位域结构(bit-field)时,就必须将比特序纳入考虑的范围。这里需要进一步明确比特序的常规形态,即如果将数的高位存储置于高地址之上,则 称之为小端(little-endian),反之则称之为大端(big-endian)[1]。
在实际对于数进行书写的时候,从左到右位次从高到低,无论系统是小端还是大端,这个规则都不应当有所改变,这是将二进制数的每一位与物理存储的比特位进行对应的时候必须坚持的原则。但是需要依据大小端的定义对每个字节和比特的地址偏移状况进行标记。除此以外,图形表示法也是常见的方法。此种表达方式对每个数据成员进行记录的时候,遵循在水平方向从左到右表示地址从低到高,垂直方向的高度则表示从最高位到对低位的变化。此种表达方式可以对交换数据过程中的数据成员分布以及高低位变化一目了然,这对于弄清楚数据传输过程中的各种细节十分重要,也有助于我们正确复原数据[2]。这种用来表示字符串的图多呈现出锯齿形状,以字符串“SUN”为例,其锯齿图参见图1。
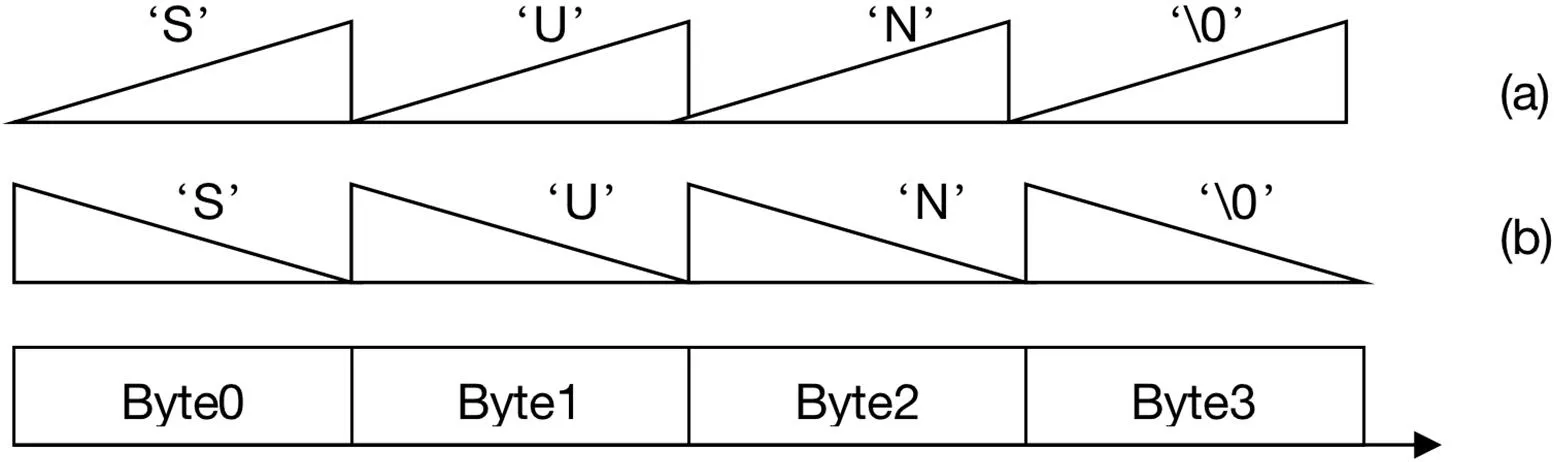
图1: 从小端传输到大端的字符串锯齿图
2 数据传输中的字节一致原则
首先来对字节一致原则进行阐述。
在数据传输过程中,数据的发送端和接收端,具体来说就是两侧的内存,在这两侧内存中间,还有诸多的通信环节,诸如通信链路和各类接口等等。但是不管经过多少环节,都必须遵循“字节一致”的原则,这个原则让大端和小端不同系统之间,在经历了数据的传输之后,保持着字节的顺序不变,而只是对每个字节内的比特序进行反转,字节的值不会有所改变。具体来说,就是在数据传输的过程中,不同存储顺序的系统之间交换数据时,坚持字节顺序不变,以及字节的值不变,但是对应的,字节内的比特序会发生反转改变[3]。
在此基础之上进一步对数据传输过程进行审视。在TCP/IP 协议框架之下,普遍选用大端序展开工作,这种统一的标准使得所有在TCP/IP 协议框架之下传输数据的存储端都可以实现对于协议以及传输结果的正确解读。因为大端序广泛应用在TCP/IP 协议基础的网络环境中,因此也会被人称为网络序,但是这里存在一个误解,即TCP/IP 协议采用的网络序只会作用于协议头部中参数的存储顺序,而不会作用于整个传输的数据包。例如在struct sockaddr_in 结构之中,头部的IP 地址和端口号都会采用大端序进行编辑,但是对于除去头部以外的部分,也就是用户需要传输的数据部分而言,TCP/IP协议并不会干涉用户定义的数据结构,也不会过问遵从了大端还是小端规则,只会依据字节一致的原则将数据作为字节流进行传输,保证每个字节的顺序和内容保持一定。对于负责数据传输的函数进行考察可以更好地对此种情况进行了解。在函数sendto()以及recvfrom()中,其收发缓冲区的类型被定义为const char*或char*,也就是说,数据的接收端会对字节流进接收以及解读,依据发送端的数据结构来将传输接收到的数据结构进行映射,从而实现对于数据成员的还原。
在传输的过程中,如果数据的收发双方采用了同种存储顺序逻辑,则数据接收端可以直接对数据结构进行定义和还原,但是对于存储策略也有所不同的收发双方而言,数据接收端就必须利用字节一致的原则对所接收到的数据进行考察,将这些数据重新映射到新的数据结构之中。
在这个数据传输的过程之中,还有一个重要的问题需要予以关注,就是字节对齐。对于数据传输参与的收发两端而言,不同的字节对齐方式必然会造成传输数据群体中的每一个元素,其排列方式和结构长度的变化。即便是数据收发两侧采用了同样的存储序策略,如果无法落实字节对齐问题,同样也会造成数据接收端数据内容接收的失败。对于此种问题,C/C++编译器提供了预处理指令#pragma pack(n),这一命令可以让数据的接收端与数据的发送端保持同样的字节对齐方式。然而虽然有这样的指令用于支持,但如果数据传输双方的存储顺序存在差异,也仍然需要面对复杂的处理过程。如果有数据元素超越了字节边界,则需要在数据的接收端对数据结构进行重新定义,这个时候字节对齐问题的意义就会显得尤为突出。编译器为了保持字节对齐,还有可能需要对结构体进行填充。这个时候预处理指令#pragma pack(1)可以用于实现结构成员之间没有填充或者基于字节定义位域结构等情况的填充,实现方法即面对结构进行字节的逐一填充[4]。
3 不同存储策略的数据传输收发两端的结构映射
上一节中已经提到,如果在数据传输过程之中,数据收发的两端采用了不同的存储顺序,则二者之间的数据结构映射就会面对更为复杂的情况,处理方案也会更加复杂。在这一部分中对此类情况展开更为深入的阐述。
首先,对于以字节作为基本单位的数据来说,都可以依据字节一致的规则进行传输,字节的顺序以及具体的值都不会发生改变,数据的接收端只需要按照发送端的数据结构定义来对数据进行处理即可。这样的情况下,虽然字节的高低位会发生反转,但是对接收端来说并没有什么影响,也不需要额外进行控制。此类状态之下的传输可以参见图1。
其次,对于多字节数据而言,当数据的收发两端采用了不同额字节序的时候,同样,在字节一致原则的控制之下,接收端获取到的字节顺序和值并不会因为传输过程而有所变化,但字节权重值会出现反转。小端系统中的低地址字节在大端系统中就会成为高位地址字节,这种转变需要在数据传输中给予关注。此种情况可以参见图2。
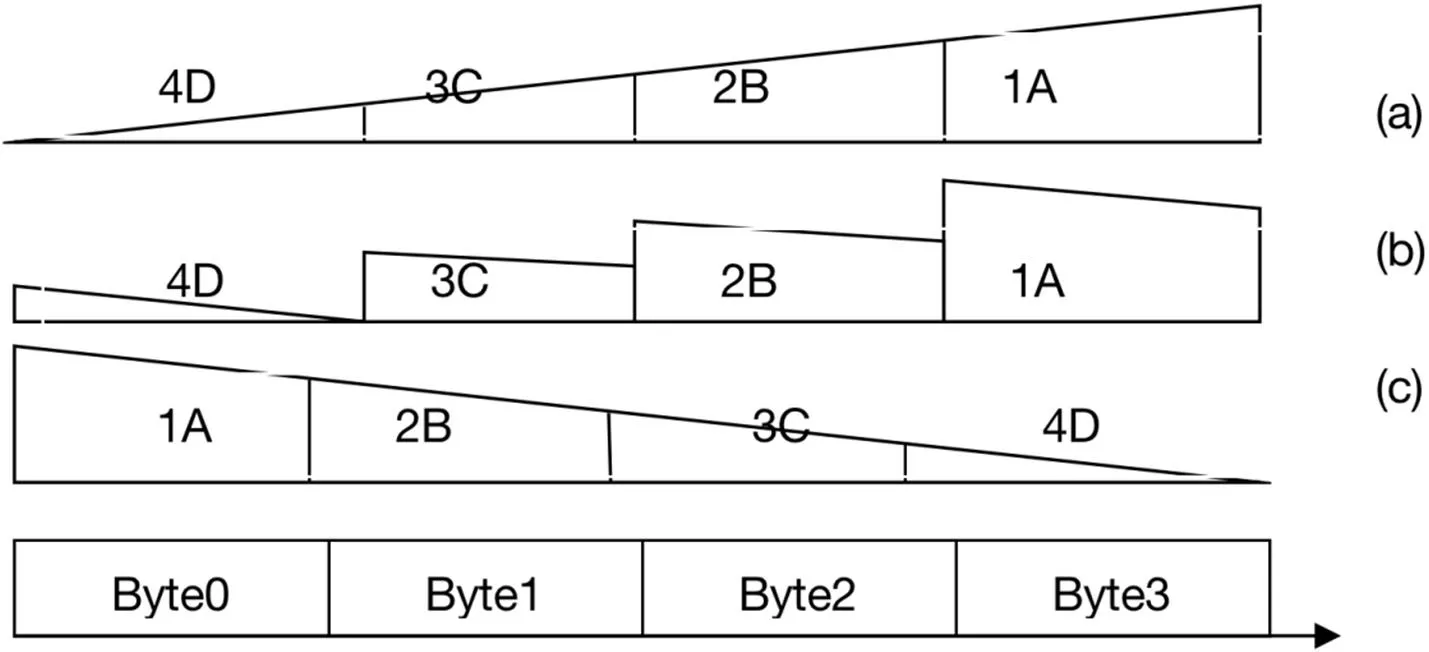
图2: 多字节数据传输锯齿图
图2(a)为信息发送端,假设为小端系统,传输的数据如图,为一个四个字节的整数,在进行传输之后,在信息接收端形成如图2(b)的形态,其中数据接收端为大端系统。因此就涉及到需要在数据接收端对接收到的数据结果进行调整,具体来说,就是要将图2(b)调整成为图2(c)状态。具体而言调整规则比较简单,即将多字节数据的最高地址上的字节内容与最低地址上的字节内容进行交换,次高地址上的字节内容与次低地址上的字节内容进行交换,以此类推,完成整个数据的翻转。
最后,在数据传输领域之中,有一个特殊的领域叫做“位域”。从概念上看,位域本质上也是一种数据结构,其可以将数据以“位”的形式进行紧凑存储,并且允许工作人员对这一类结构中的位进行操作。总体来说,位域的核心优势在于对存储空间的节约,这种节约尤其是在程序需要大容量的数据单元的时候,能够突出其优势。
对于位域的传输而言,需要进一步分为两种情况进行考察。
(1)即单字节内的位域结构。在对此种位域进行传输的时候需要注意,无论何种系统,在进行结构定义的时候,编译器都会按照结构成员来进行次序的确定,从内存的低地址开始进行存储资源的分配。假设在大端系统中来对某位域结构进行定义如下:

改数据传输到小端系统之后,高低位出现了翻转,因此对应的结构会转变成如下:

对于上述的这种情况,用锯齿图进行表示,可以参见图3。
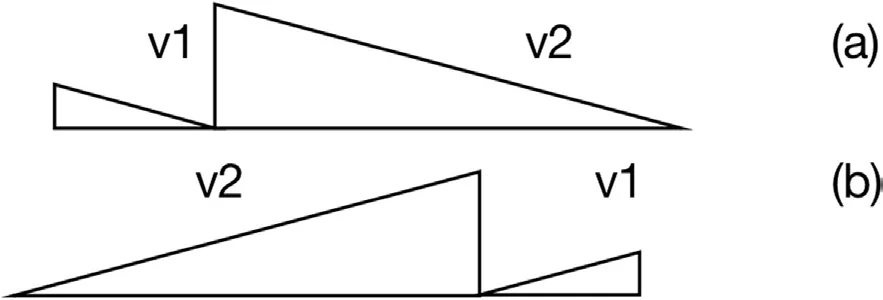
图3: 数据传输发送端以及接收端分别问大端系统和小端系统情况下的镜像关系
从图3 中可以看到,当传输内容到达接收端之后,原来的高低位发生了变化,低位换到了高位,原来的高位换到了低位,但是其数据值并未发生改变。
(2)则是跨字节的位域结构。此种情况发生在位域结构超出了字节边界,对应的情况也会随之变得复杂。这主要是考虑到高位和低位反转之后,跨字节的位域会出现地址不连续的问题,即整个存储内容会出现在两个或者更多地址空间中。这种情况通常称之为空间断裂。例如,一个数据发送端如果采用大端系统规则工作,其上的位域结构为:

在存储的时候,上面的结构在内存中的映像参见图4(a),其中灰色部分是跨字节边界的部分。这样的数据传输到小端系统之后,对应的在内存中的映射见图4(b)。

图4: 跨字节位域数据从大端系统传输到小端系统中的对比
无论是大端还是小端系统,都是从存储环境的低位开始展开存储资源的分配,因此想要实现对于发送端结构的正确描述,就需要数据的接收端重新展开对于结构成员的顺序定义。对于上述大端系统发送的数据,小端系统应当将数据定义成如下结构:

在此种情况中,变量s3.v2 跨越了字节边界,对应在到达信息接收端的时候,存储空间断为两个部分。对于这种情况,可以考虑用移位拼接的算法进行处理:

4 结论
数据传输过程看似透明,但是其中的细节关系十分微妙,尤其是高低位的翻转以及位域的地址断裂问题。在面对此类情况的时候,需要牢牢把握字节一致原则,结合内存映射和 锯齿图进行理解,实现数据的有效还原。
