基于综合干旱数据库与随机森林算法的草地干旱监测模型构建*
2023-05-14袁雪琪李静朱欣然张召星柳钦火
袁雪琪,李静,朱欣然,张召星,柳钦火
(1 中国科学院空天信息创新研究院 遥感科学国家重点实验室, 北京 100094; 2 中国科学院大学电子电气与通信工程学院, 北京 100049)
气候变化被认为是二十一世纪地球的主要威胁之一。近些年来,随着全球地表温度上升[1],气候变暖加剧,极端事件频发。在各种极端事件中,干旱是对经济和环境的损害最严重的一种,也是发展最缓慢、持续时间最长、最不可预测的一种[2]。草地是中国陆地面积最大的生态系统,对保护生物多样性、发展畜牧业、维持水土和生态平衡具有重要的意义和价值[3]。然而,草原通常位于干旱和半干旱地区,非常容易受到干旱的影响。干旱监测和预测可以为相关部门提供决策支持,从而减少对社会和生态的影响[4]。因此,草地干旱监测具有重要应用研究意义。
草地干旱属于农业干旱,应用适宜的干旱指数是监测和分析农业干旱的重要方法。20世纪后半叶以来,科学家们从不同的科学视角和对干旱定义的理解出发建立了一系列的干旱指数。这些指数根据数据来源可分为3类:气象干旱指数、遥感干旱指数和综合干旱指数。气象指数发展较为成熟且准确,已经得到广泛的应用,但气象监测只考虑气象因子对于干旱的驱动效果,没有考虑植被的生长和需水状态,在农业干旱监测方面存在一定的局限性;遥感干旱指标具有监测范围广、数据获取及时等优点,但遥感监测指标多用来探测植被状况异常,很难将真正的干旱影响与其他环境因素造成的植被变化区分开来[5]。
农业干旱是涉及植被、土壤、降水等多种环境因子的自然灾害,单一的干旱指标无法全面地刻画复杂的干旱过程。为了更好地监测干旱,研究人员试图融合不同类型的干旱因子构建综合干旱监测模型。然而农业干旱的成因十分复杂,当前对多种致旱因子如何耦合并导致灾害的过程并不清楚,因此近些年来通过模糊聚类分析确定多种因子与干旱状况之间关系的机器学习方法成为综合干旱监测研究的热点。Brown等[5]利用分类回归树构建了植被干旱响应指数(the vegetation drought response index, VegDRI),并在美国中北部7个州验证了其干旱监测的能力;Wu等[6]利用相同方法融合站点气象数据、卫星植被参数及其他生态信息,建立了适用于中国东部地区的综合干旱监测模型;Feng等[7]采用3种机器学习方法融合中分辨率成像光谱仪(moderate-resolution imaging spectroradiometer, MODIS)和热带降水测量任务(tropical rainfall measuring mission, TRMM)构建的30个干旱因子来监测澳大利亚东南部的农业干旱。以上综合干旱监测模型的构建多是将标准化降水蒸散指数(the standardized precipitation evapotranspiration index, SPEI)和帕默尔干旱指数(palmer drought severity index, PDSI)等传统气象指标视为目标变量,SPEI和PDSI均需考虑蒸散发等地表参量,计算较为复杂,且对农业干旱的表征能力具有一定的局限性。因此应当考虑应用更可靠稳定的数据源作为目标变量构建综合干旱监测模型。
因而,本研究利用随机森林机器学习方法,以稳定可靠的USDM干旱监测产品为因变量,构建气象遥感数据驱动的综合干旱监测模型,同时考虑气候和地理条件适用性在内蒙古地区进行普适性验证,以期获得更好的草地干旱时空监测效果[8]。
1 研究区与研究数据
1.1 研究区
选择内蒙古草地区作为实验区对模型进行普适性验证。内蒙古拥有8 700万hm2天然草地,占中国天然草原面积的21.7%,是世界上最大的连续生态群落——欧亚大草原的重要组成部分,也是中国重要的农牧业基地之一,但除相对湿润的大兴安岭地区外,其余地区多为干旱、半干旱气候,干旱发生频率高、持续时间长、影响范围广、地域差异明显,因此非常适合草地干旱监测模型的评价研究。
1.2 研究数据
1.2.1 USDM干旱数据
USDM是综合了气候指数、数值模式,以及各地方专家知识等大量丰富信息开发成的综合干旱监测产品[9],其灵活使用了6个关键指标和多个辅助参考指标监测国家或州尺度的旱情空间分布,并利用来自美国不同地区的450位气候和水文专家的干旱相关研究成果(实测数据和田间报告等)对旱情监测结果进行校正。6个关键指标包括帕默尔干旱指数、CPC土壤湿度模式、美国地质测量局日流量指标、标准降水百分位数、标准降水指数和卫星遥感植被健康指数,辅助性参考指标包括溪流流量、积雪、雪水当量、水库和地下水等信息。多种干旱指标和专家的最佳判断的结合使USDM成为一种独特可靠的干旱产品,在本研究中,USDM干旱类别被认为是实际的干旱状况,作为模型的因变量,从官方网站(http:∥droughtmonitor.unl.edu/)获得。
我们将草地站点限制在美国大平原的北部和中部,该地区的主要土地覆盖类型为农田和草原,基于地表覆盖分类数据NLCD 2016在该区域选取60个草地点,如图1(a)所示,并提取了相应站点2005—2019年的USDM干旱信息。
1.2.2 遥感数据
本文的主要遥感数据为2005—2019年的MODIS陆地数据产品MOD09GA和MOD11A1。MOD09GA为7波段的每日地表反射率产品,空间分辨率为500 m,可构建植被参数提供草地生长状况信息;MOD11A1为采用分裂窗算法获得每日地表温度产品,空间分辨率为1 km,可提供昼、夜地表温度信息。将两种产品投影转换并通过双线性内插重采样至1 km空间分辨率,然后分别计算植被状态指数(vegetation condition index,VCI)和温度状态指数(temperature condition index,TCI),指数的具体构建方法如下所示
(1)
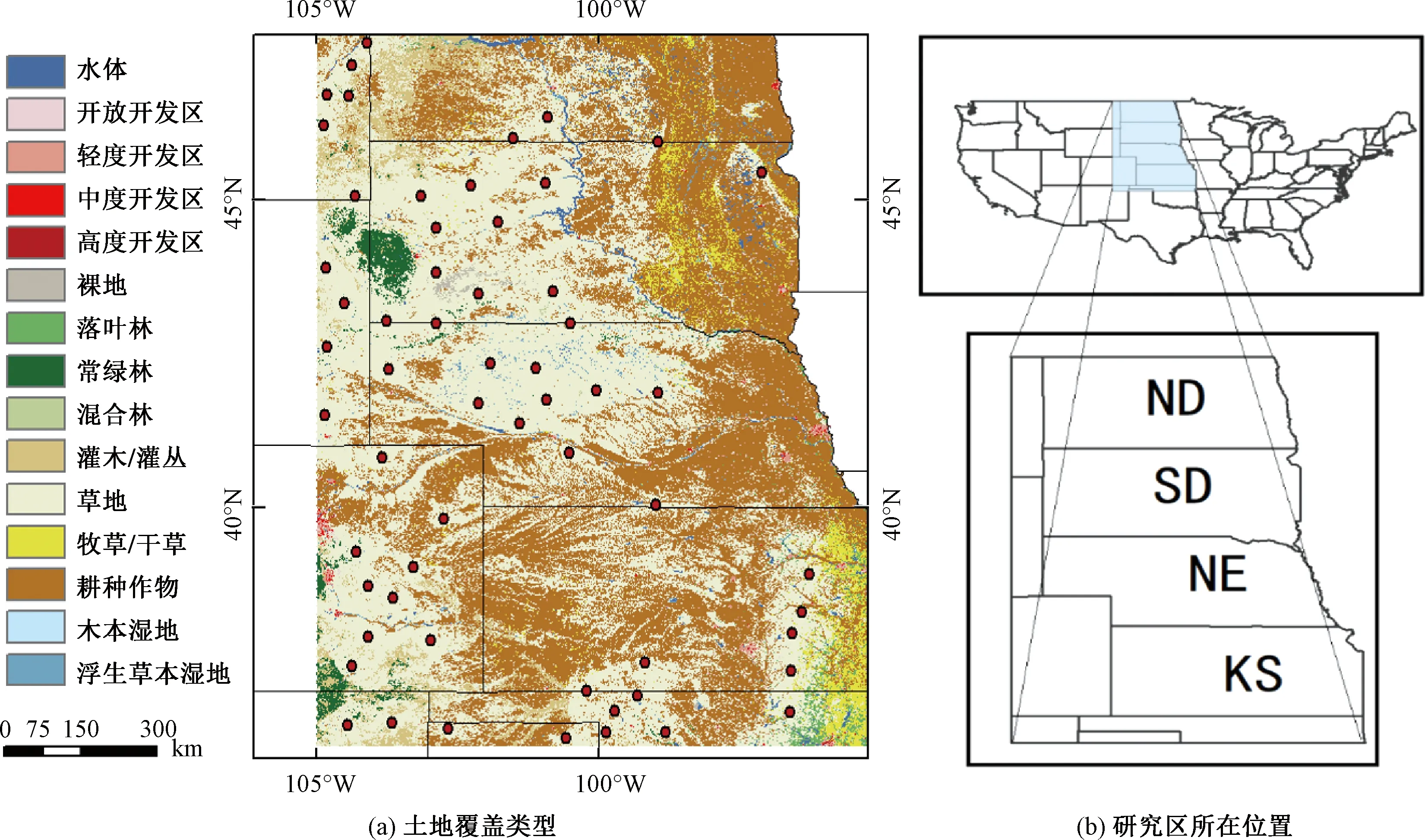
红色圆点为选择的草地站点的位置图1 美国大平原中北部土地覆盖类型图Fig.1 Land cover type map of the north-central Great Plains of United States
(2)
(3)
其中:ρNIR为MODIS近红外波段反射率,ρRED为MODIS红波段反射率;NDVImax和NDVImin分别为整个时间序列上各像元的同期最大值和最小值;LSTi为平滑后采用7天平均值合成的地表温度,LSTmax和LSTmin分别为整个时间序列上各像元地表温度的同期最大值和最小值;VCI和TCI分别表征植被的生长状况和植被冠层所受到的温度胁迫[10-11]。
此外,使用的数字高程数据为国际热带农业中心(International Center for Tropical Agriculture, CIAT)利用新的插值算法得到的SRTM DEM V4.1版本,空间分辨率为90 m。生态分区数据来源于美国地质调查局和Esri公司合作发布的250 m分辨率的全球生态陆地单元。
1.2.3 降水及土壤湿度数据
降水数据来源于欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts, ECMWF)发布的第5代全球再分析气候数据集,时间分辨率为1 h,空间分辨率为 0.25°。
土壤湿度数据来源于全球陆面数据同化系统(The goal of the Global Land Data Assimilation System, GLDAS),GLDAS 利用地基观测与卫星遥感观测数据产品,驱动陆面过程模型生成全球的地表状态和通量数据[12],并提供不同深度的土壤湿度数据。
本研究选取1985—2015年共30 a的每日降水数据和根区土壤湿度数据作为算法的数据参数,重投影、重采样至与MODIS遥感数据一致。处理后的降水和根区土壤湿度数据均通过标准化计算公式被尺度化为[0,1]的干旱参数范围,从而构建了降水异常指数P-Z和标准化土壤湿度指数(standardized soil moisture index,SSMI)。具体构建方法如下
(4)

1.2.4 农业气象站点数据
本文利用农业气象站点实测的草地旱灾数据和土壤墒情数据对草地综合干旱监测模型进行验证。草地旱灾记录数据来源于“中国农业气象灾情旬值数据集”,数据集记载了1991年9月至2011年12月中国农气站观测的农业灾情旬报告,包括区站号、站名、经度、纬度、灾害名称、受害程度等信息。数据集将干旱划分为轻、中、重3个等级,已被广泛应用于修正帕默尔干旱指数,ISDI等干旱指标的验证和构建[6,13-14]。土壤相对湿度数据来自于“中国农作物生长发育和农田土壤湿度旬值数据集”,该数据集包含了1991年9月至2012年12月中国农气站观测的农作物生长发育状况和不同深度的土壤相对湿度数据。本研究考虑数据的完整性和空间分布的均匀性共选取了12个农业气象站点,如图2所示,然后利用中国气象数据共享服务系统获取了站点2005—2011年的旱灾观测记录和20 cm深度的土壤墒情数据,用于随机森林草地干旱监测模型的验证。
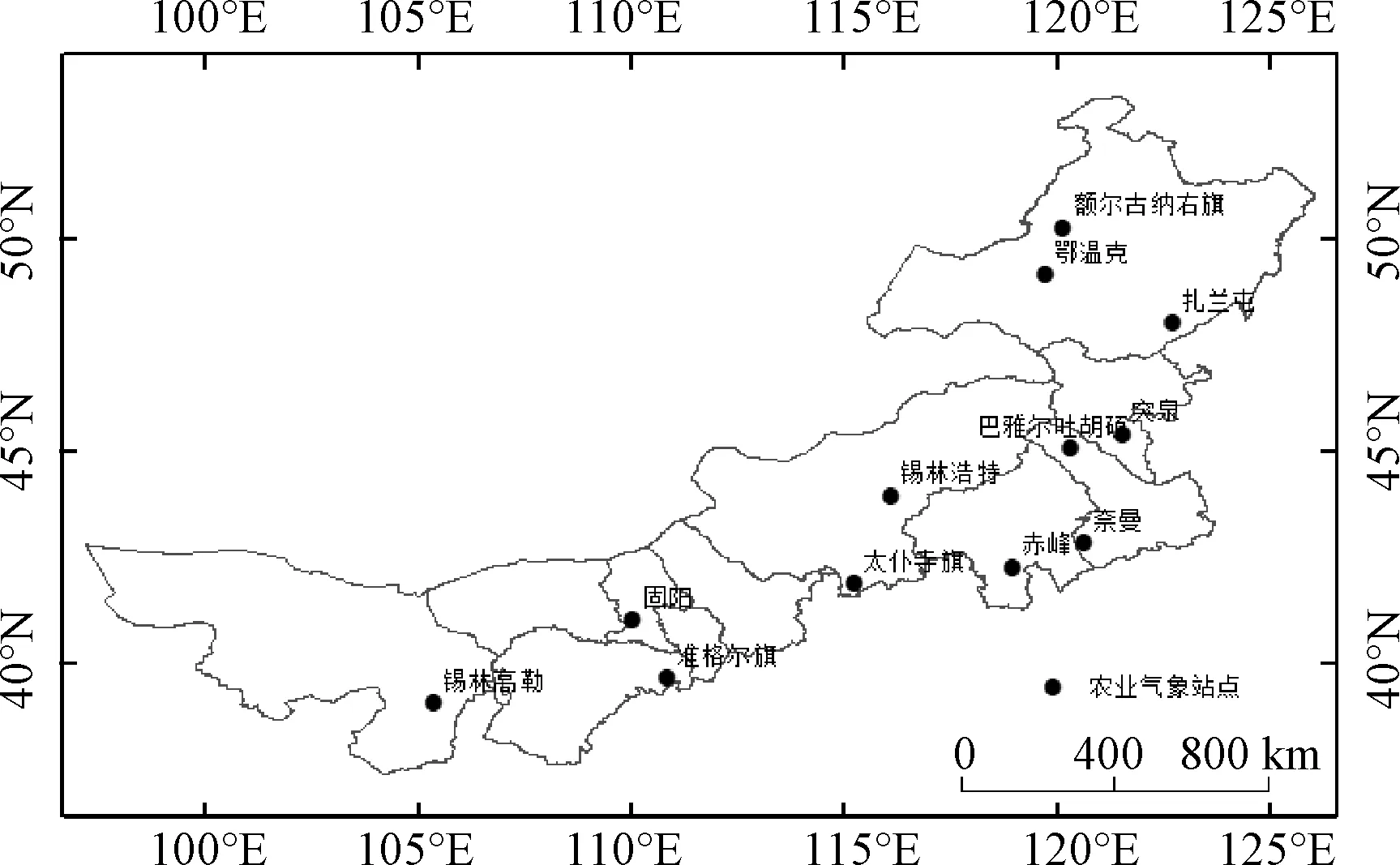
基于自然资源部标准地图服务网站GS(2021)5448号标准地图制作,底图无修改,下同图2 内蒙古农业站点分布图Fig.2 Distribution of agro-meteorological stations in Inner Mongolia
2 综合干旱监测模型构建
2.1 模型构建原理
构建综合干旱监测模型的理论基础是农业干旱过程是由多个致灾因子决定的,不仅涉及到降水、土壤和植被生长状态等,还与地貌类型等因素有关[15]。植被状态指数VCI平滑了NDVI数据中的非均匀性,有助于将NDVI数据中的短期天气信号与长期生态信号分离[16],已被证明是探测干旱发生、评价干旱强度、持续时间和影响的有效手段[17-19]。然而在雨季,基于光学波段的植被指数VCI受到云和雨水的影响,其值往往会降低,从而造成对干旱事件的误判。基于地表温度LST构建的温度状况指数TCI不受天气的影响,可以表征植被冠层所受到的温度胁迫。降水异常指数P-Z能够较好地反映区域降水异常,标准化土壤湿度指数SSMI呈现土壤水分亏缺的状态,生态区划数据反映了区域的环境特征,高程DEM(digital elevation model)解释了基本气候条件和太阳能收支的差异。以上单个干旱指标均从不同层面反应干旱发生时的环境异常,耦合多种参数的综合干旱监测模型可以更全面地表征区域干旱状态。
随机森林(random forests)是由美国科学家Breiman,L结合Bagging集成学习理论随机子空间方法提出的一种机器学习算法[20],该算法继承和发展了决策树的优点,预测精度高,运算速度快,同时极大地降低了决策树的过拟合问题,在多个研究领域已取得较好的应用[21-24],在干旱监测方面也表现出较好的性能[7,25]。
因此本研究以USDM干旱类别为目标变量,基于模糊聚类分析的思想,通过随机森林数据挖掘技术分析历史干旱指数和生物物理变量(见表1)构建的干旱综合数据库建立干旱分类模型,并考虑模型的适用性进行验证,以期在草地区获得更好的监测效果。

表1 模型输入参数Table 1 Input parameters of the model
2.2 模型构建过程
构建以每个草地站点位置为中心的9×9像元窗口,提取窗口内VCI、TCI、P-Z、SSMI、DEM和生态区编号作为自变量,以每周的USDM干旱等级值作为因变量,利用随机森林方法,构建如下所示的干旱监测模型
USDM=f(VCI,TCI,P-Z,SSMI,DEM,生态区).
(5)
由于USDM干旱等级的划分是基于历史干旱的发生频率,轻旱的发生频率是20%~30%,而异常干旱的发生频率不到2%,因此训练数据样本分布十分不平衡。本研究采用过采样和欠采样算法对数据进行平衡采样,以减少类不平衡对分类器性能的影响,同时考虑到VCI和TCI适用于植被生长期的旱情监测,主要监测5月至10月草地生长季的干旱情况,从而构建起2005—2019年的原始训练据集(X,Y)。模型的构建过程如图3所示。
1)利用Bootstrapping 抽样从训练集(X,Y)中有放回地抽取k个与训练集容量大小一样的训练样本,未被抽到的样本组成k个袋外数据。
2)每个训练样本集构造一个对应的决策树,其中决策树为二叉树,在二叉树中,根节点包含全部训练数据,按照节点纯度最小原则,分裂为左节点和右节点,它们分别包含训练数据的一个子集,按照同样的规则节点继续分裂,直到满足分支停止规则而停止生长,每个非叶节点代表对一个属性特征的判断,叶子节点代表最终的类别划分。若节点n上的分类数据全部来自于同一类别,则此节点的纯度I(n)=0,纯度度量方法是基尼准则,基尼指数越小表示样本被分错的概率越小,也就是说集合的纯度越高。基尼指数的具体计算方式如下
(6)
式中:pk表示选中的样本属于k类别的概率。
3)将以步骤2)方式训练得到K个决策树,组成随机森林。当输入训练样本时,随机森林输出的干旱结果由K个决策树投票决定,即取k种分类结果的众数,预测精度以每棵回归树的平均OOB误差来确定,基于OOB误差最小的原则对决策树的个数K和决策树深度N进行调优,随机森林干旱监测模型得以确定。将模型应用于地理空间栅格数据集,即可生产单周时间尺度,空间分辨率为1 km的干旱监测图。
3 模型评价与验证
3.1 模型与USDM产品的一致性
将训练集和测试集的数据分别输入模型中,得到模型模拟值,计算其与USDM干旱等级的平均绝对误差(MAE)、均方根误差(RMSE)和相关系数(R),以评价模型与USDM数据的一致性,结果见表2。训练集的模拟值与USDM之间的相关系数为0.981,测试集的相关系数为0.782,且MAE和RMSE都较小,表明模拟值与USDM相关性高,模型泛化能力强,模型具有较高的预测精度。
图4展示了模型的监测结果和同期的USDM干旱监测产品。模型监测结果和USDM所描绘的干旱总体空间格局和强度是相似的,并且该模型的空间分辨率为1 km,相比较空间尺度近似于气候分区的USDM产品具有更高的空间分辨率,在区域尺度上具有更优的监测能力。

表2 模型精度分析Table 2 Accuracy analysis of model
3.2 模型适用性验证
形成农业干旱的原因虽然相对复杂,但基本可以归纳为气象、地形、农作物类型和人类活动4个方面[26]。该模型基于美国中北部大平原的天然草地构建,与农作物不同,天然草地较少受到灌溉、施肥等人类活动的干扰,模型在相似气候、地理、土壤条件及相同植被类型下也应适用。本研究选择内蒙古的天然草地分析验证了模型在相似气候和地理条件下的适用性。内蒙古与美国中北部大平原处在同一纬度带上,同属温带大陆性气候,夏季炎热少雨,易受干旱胁迫,同属高原型地貌且具有相似的土壤质地(主要构成均为疏松沉积物、硅质碎屑沉积岩和混合沉积岩)。模型的构建过程中,融入了全球的生态区划和高程数据,降水、土壤和植被因子也均依据长时间序列的数据归一化为VCI等状态指数,区域上具有时间和空间的可比性。同时,模型在内蒙古进行验证分析时,综合考虑了草地区对降水和地表温度的响应关系变化,考虑草地生育期的变化,对降水等数据进行了调整。

图4 模型监测结果与同期USDM产品对比图Fig.4 Comparison of model monitoring results with corresponding USDM products
3.2.1 模型监测结果与土壤墒情的相关性分析
土壤墒情是表征农业旱情的一个重要指标,是评价遥感干旱指数滞后性的一个重要参数[27-28]。为了验证模型响应干旱的精度,本研究在内蒙古草地区随机选取12个空间分布均匀的农气站点,提取各站点的模型监测值、植被状态指数VCI和温度状态指数TCI与同期 20 cm土壤相对湿度进行相关性分析,结果见表3所示。模型监测结果与20 cm土壤墒情的相关系数均通过了0.05水平双侧显著性检验,且由于随机森林模型融合了大气异常、植被状态、土壤水分等多个方面的信息,相较于单个干旱指标与土壤墒情具有更高的相关性,能够非常好地反映草地农业干旱。
3.2.2 模型监测值与农气站点实测值对比分析
为了验证干旱监测模型能否准确表征草地受干旱胁迫的程度,对比分析2005—2011年农业气象站点的模型监测结果与相应站点的同期旱涝观测记录。经过统计,如表4所示,26.59%的模型监测结果与观测等级保持一致,75.14%的干旱等级差在1以内。因为本模型可监测到5个级别的干旱状况,而农业气象站点的野外观测只有3个干旱类别,等级误差多在1级以内表明模型能准确描述草地的受害程度。
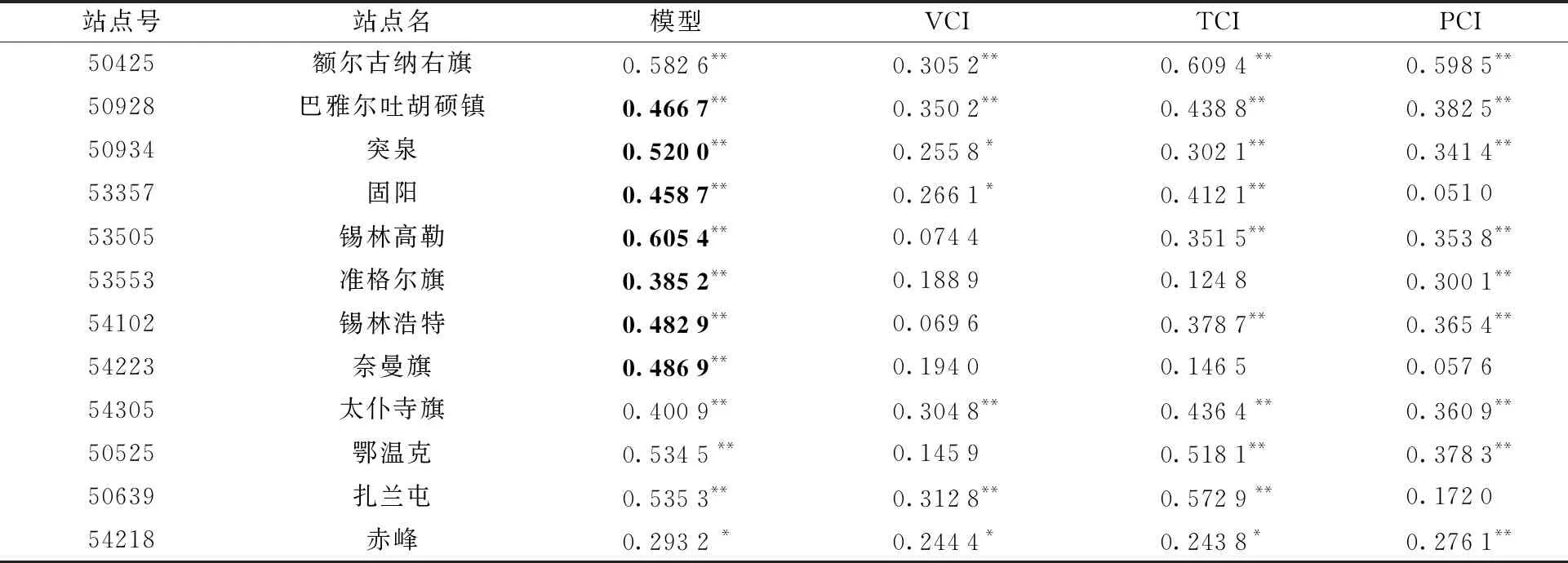
表3 不同干旱指数与20 cm土壤墒情的相关关系Table 3 Correlation between different drought indices and 20 cm-depth soil moisture

表4 模型监测与农气站点实测等级差异分布Table 4 The difference distribution between the monitoring results and agro-meteorological site observations
为进一步评价模型能否监测整个草地生长期的旱情等级变化,在准格尔旗、突泉和锡林浩特3个农业气象站点比较了整个生长期内模型监测结果与实地观测结果的变化趋势,如图5所示。可以看出,模型监测结果总体变化趋势与观测结果的变化趋势基本一致,模型能够准确监测干旱程度的发展变化情况,具有较好的监测能力。监测结果与观测数据存在部分等级划分差异,主要由本模型5个干旱等级与农业气象站点野外观测的3个干旱等级的干旱划分差异所致。也可看出由于本模型结合了温水气象条件及地面土壤、植被等遥感参数产品,监测结果除能够显示大的干旱事件外,也可显示出小的干旱波动变化。

图5 草地生长期模型监测结果与实地观测结果对比Fig.5 Comparison between model monitoring results and field observation results during grassland growth period
3.2.3 模型对典型干旱事件的区域监测能力
为验证模型是否可以准确反映干旱发生、发展的空间演变情况,对比分析典型干旱事件发生时,模型监测图反映出的干旱变化信息与官方报道的干旱动态,从而评价模型监测干旱变化的空间有效性。
图6为2017年7月26日气象局发布的气象综合监测与模型监测结果的对比图,两者描述的干旱结果相似,西部、中南部的草地旱情相对较轻,北部、东北部的旱情较重,兴安盟的南部地区可达到特旱及以上的旱情。两监测结果在部分区域存在些许差异,这是由于综合干旱监测模型除了考虑降水等气象因子外,还考虑了草地的生长状况,所以在部分区域虽然当前的气象条件较好,但草地还未从前期的干旱影响中恢复过来,生长状况较差,导致模型的干旱判定结果相比气象监测结果偏重。

图6 气候中心发布的气象干旱综合监测图与模型监测结果Fig.6 Comprehensive meteorological drought monitoring map and model monitoring result
根据新华网等媒体的报道,2017年春季以来,内蒙古自治区降水较常年偏少、气温偏高,高温少雨天气导致牧区土壤失墒严重,牧草生长受限,牲畜草料严重短缺。进入7月中下旬,内蒙古东北部旱情持续发展,东部存在中到重度气象干旱,局部达特旱,其中锡林郭勒盟和呼伦贝尔市草原牧草大面积减产,西部旱情相对较轻。8月2日内蒙全区近60%气象站出现降水,雨水使多地旱情得到缓解,干旱面积减少3.1万km2。此后,内蒙古出现多场连续降水,截至8月16日,全区重特级气象干旱几乎消失,土壤墒情较好。图7显示了旱情发展6个时段的模型监测结果,对比分析可看出模型监测结果与实际旱情基本一致,模型能够监测出内蒙古草地本次旱情的发生发展及空间演变情况。

图7 基于草地干旱模型监测的内蒙古2017年7—8月的干旱情况Fig.7 Drought monitoring in Inner Mongolia in July-August 2017 based on grassland drought model
4 结论
耦合多种致旱因子的干旱监测模型综合考虑土壤水分胁迫、植被生长状态和气象降水盈亏等因素,是现今干旱监测研究的热点。美国干旱监测USDM将客观数据集与专家的最佳判断相结合,是综合干旱监测模型中的里程碑。本文基于多源遥感和气象数据构建的干旱综合数据库,通过随机森林模型学习USDM判断干旱的方式,并考虑到模型的有限适用性,在内蒙古地区进行了应用验证。结果表明:
1)模型监测值与USDM的相关系数为0.782,模型监测结果和USDM所描绘的干旱总体空间格局和强度相似,模型能够实现USDM对干旱判断的能力,且其空间分辨率为1 km,具有更高的空间分辨率,在区域尺度上具有更优的监测能力。
2)考虑模型的有限适用性,评价了模型在内蒙古草地的干旱监测能力。基于农气站点实测土壤相对湿度的验证表明,模型监测结果与土壤墒情显著相关,且由于随机森林模型融合了大气异常、植被状态、土壤水分等多个方面的信息,相较于单个干旱指标(VCI,TCI,PCI)的监测结果与土壤墒情具有较高的相关性,能够非常好地反映草地农业干旱。
3)利用2005—2011年的农业气象站点观测数据集,评价了模型判断草地受害程度的能力。模型监测等级与实测结果保持一致,75.14%的干旱等级差在1以内,且模型监测结果的总体变化趋势与观测结果的变化趋势基本一致,表明模型能准确描述干旱的具体类别且能够监测旱情随时间的发展变化情况。
4)以本文构建的模型对2017年7—8月的内蒙古典型干旱事件进行监测,监测结果与实际旱情相符,并能够实时反映干旱空间发展演变情况。该模型的时间分辨率为周,相比较以月或16 d为时间尺度的SDI、ISDI综合干旱指数,更能反映干旱变化的细节信息,可以以近实时的方式实现对草地干旱时空变化的监测。
综上所述,草地综合干旱监测模型融合了大气异常、植被状态、土壤水分等多个方面的干旱数据,并基于稳定可靠的USDM数据构建,相较于单个干旱指标与土壤墒情具有较好的相关性。模型能够实现USDM对干旱判断的能力,在相似的气候和地理条件下具有很好的适用性,相对于其他的综合干旱监测指数,对草地干旱具有较好的时空变化监测能力。综合干旱监测模型基于草地类型而构建,在未来的研究中,将探究利用该方法对其他农作物类型的监测效果并进一步完善模型的应用验证和干旱机理研究。
