语义通信性能评估体系及指标
2023-05-13郑远ZHENGYuan王凤玉WANGFengyu许文俊XUWenjun
郑远/ZHENG Yuan,王凤玉/WANG Fengyu,许文俊/XU Wenjun
( 北京邮电大学,中国 北京100876)
从20世纪80年代后期1G的诞生到如今5G商业化进程的稳步展开,移动通信经历了近半个世纪的高速发展。得益于高峰值速率、低传输时延与高连接密度,5G 系统支持包含虚拟/增强现实、智能驾驶、智慧城市等在内的多样化垂直应用[1]。随着全球新一轮科技与产业革命的加速发展,信息通信技术将进一步重构人与人、人与物、物与物之间的复杂联系,为工业、医疗、交通、教育、金融、娱乐、零售等千行百业带来革新。当前通信系统主要基于香农信息论研究设计。从1G 到5G,通信系统虽然在业务形式、服务对象、网络架构和承载资源等方面进行了技术变革,但都依赖于增加信息传输的物理维度、通过技术堆叠处理来逼近香农信息论极限。
随着通信系统与各垂直行业领域的紧密结合,面向个人、行业等用户的智能需求将被进一步挖掘,这对通信系统准确传递信息含义提出更高要求。而以香农信息论为基础的传统通信系统并不关注信息中承载的含义,只关注每个传输比特的正确接收。这导致不必要的通信资源耗费,难以满足未来通信持续发展的需求。语义通信通过交叉融合人工智能与通信技术,深度挖掘信息本身的语义维度,引入语义层次的信息,关注传输信息内容而非编码符号,更加满足未来通信需求。通过充分利用语义层面信息的高度抽象、智能简约等特性,语义通信将变革经典香农信息论框架,有望突破经典通信系统的传输瓶颈,形成智能化的新型通信体系[2]。
当前,语义通信尚处于研究初期,构建统一的、具有泛化价值的性能评估体系对语义通信的发展至关重要。本文围绕评估体系在语义通信系统设计实现中的作用展开探讨,并在分析现有通信系统评估指标的基础上提出具有泛化性的语义通信评估体系,为语义通信的发展奠定基础。
1 语义通信性能评估体系需求
当前,语义通信尚处于研究初期,语义通信理论在代表性的人-机、机-机等智能交互场景中快速发展,关键性成果不断涌现,系统性能增益更加显著。然而,由于缺乏统一且具有泛化价值的性能评估体系,语义通信研究成果的可理解性有所欠缺,成果间的横向对比难以实现。
一般而言,准确性与时效性是评价通信系统性能的两个重要指标。现有语义通信相关研究所采用的评估体系主要由传统通信系统评估体系演化而来,或由下游语义任务评估体系迁移而来。对于由传统通信系统评估体系演化而来的情况,相应的准确性评估指标常采用误比特率,时效性评估指标常采用比特传输速率。这类评估指标的问题在于无法有效反映通信收发端语义信息传递的能力。对于由下游语义任务评估体系迁移而来的情况,由于系统模型多采用通信模块与下游语义任务模块组合确定结构、端到端训练固定参数的方式,这类评估指标具有与通信任务场景、信息模态高度关联的特征。如面向语义重建的语义通信系统普遍采用原始信息与重建信息的误差函数作为准确性度量,采用压缩比的函数作为时效性度量;而面向文本翻译、图像分割等语义任务的语义通信系统则普遍将模型输出与监督标签的差异作为准确性度量。
上述各评估指标的定义不同,取值范围存在显著差异,导致诸多研究的系统模型之间无法横向贯通。即使针对相同评估指标,由于信道、干扰、信源语义特征等差异性存在,不同场景下的语义传输方案也无法进行有效对比。统一且具泛化价值的语义通信评估体系,从整体视角对通信系统性能进行直观的评估,不仅能验证系统的合理性,还可以为系统的优化改进提供参考,进而为系统演进提供方向。语义通信评估体系相关研究亟待开展,以便为语义通信的稳步发展夯实基础。
2 现有语义通信性能评估指标
语义通信性能评估指标与具体通信任务场景、信息模态高度关联。其中,信息重建任务广泛出现在以人类作为最终接收用户的应用场景中,如音视频通话、多媒体文件云备份等,该类任务要求在收端将信息恢复至发端信息模态,并尽量保证信息的准确,性能评估指标基于发送信息与重建信息的差异进行定义;非信息重建任务多出现于人-机、机-机交互场景中,如智能驾驶、工业物联网等,该类任务要求所发信息的关键内容能够被理解和应用,性能评估指标基于所输出信息与相应监督标签之间的差异定义。对于信息模态而言,人类针对文本、图像/视频、语音等模态信息采用不同的重点捕捉方式,各模态信息的失真无法简单通过欧氏距离等方式统一度量。各模态信息所衍生的后续任务存在很大差异,文本情感分析、智能问答、图像分割、语音识别等任务均需要定义各自的性能评估指标。
基于重建任务与其他代表性人工智能任务(例如文本分类、图像目标检测、语音识别)的划分,本节对文本、图像/视频、语音3种常见模态信息传输模型的性能评估指标进行分析总结,为后续构建统一、具有泛化性的语义通信性能评估体系奠定基础。
2.1 面向重建任务的评估指标
2.1.1 文本信息重建
文本信息重建的现有常用衡量指标主要为双语替换评测分数[3](BLEU),该指标最初被用于文本翻译的质量评估。BLEU基于加权n元模型(n −gram)精确度进行定义,其具体形式为:
其 中 , pn表 示 n −gram 精 确 度 , Countclip(n −gram)、 Count(n −gram')分别表示n 长词组在原始文本X 与重建文本X̂中的出现次数。BLEU 的物理意义是衡量重建文本的所有n长词组中同时出现在原始文本中的数量占比。尽管作为最为常用的文本信息重建衡量指标,BLEU仍无法实现对于词汇语义的理解[4],存在未考虑到词汇语料的召回率[5]等不足。
2.1.2 图像/视频信息重建
现有图像/视频信息重建的常用衡量指标包括峰值信噪比(PSNR)与多尺度结构相似性[6](MS −SSIM)。PSNR 定义为均方误差(MSE)的对数函数。对于动态范围N 的图像/视频帧,PSNR计算如下:
MS −SSIM将人眼生理特性纳入考虑:人眼在衡量两幅图的相似性时,对于两幅图的局部结构差异更为敏感。故一方面,MS −SSIM 的运算基于一定尺寸的图像块;另一方面,MS −SSIM 通过分别定义亮度、对比度、结构对比函数,将3 类信息拆分,赋予它们不同的权重并独立进行对比。相较于PSNR,MS −SSIM的评估结果更符合人眼感知。MS −SSIM的计算方式为:
其中,降采样次数M、亮度权重αM、对比度权重βJ、结构对比权重γJ为超参数,其常用取值为:M = 5, β1= γ1=0.044 8, β2= γ2= 0.285 6, β3= γ3= 0.300 1, β4= γ4=0.236 3, α5=β5= γ5= 0.133 3。XM、分别为原图及重构图像/视频帧的M级降采样结果。
C1=(k1N)2、C2=(k2N)2、C3= C2/2 为固定参数,用于防止除法运算问题的产生。N为图像/视频帧的动态范围,k1= 0.01、k2= 0.03为经验取值。
近年的相关工作[8-9]多采用PSNR与MS −SSIM指标并行的方式。此外,文献[8]还采用了对数形式的MS −SSIM 指标,以应对MS −SSIM取值范围过小的问题。
2.1.3 语音信息重建
语音信息重建的现有衡量指标包括语音质量感知评估[10](PESQ)与短时客观可懂度[11](STOI)等。早期语音质量衡量主要通过主观打分方式获得平均意见值(MOS)。PESQ是用于模拟MOS打分的音频质量评价算法,其定义为:
其中,dSYM与dASYM分别为算法求得的语音信息对称与非对称干扰,反映重建模型的预测精度和概括能力。PESQ是对重建语音信号可理解程度的衡量,侧重人的主观感受,在早期的无线通信系统中广泛使用。
同样被广泛使用的指标还包括STOI。STOI 是对重建语音信息失真程度的客观度量,其取值与基于人工智能的语音识别等下游任务性能相关。具体而言,首先定义̂(k,m)为第m 帧语音信号的第k 个离散傅里叶变换(DFT)波瓣,计算第m帧语音信号的第j个1/3倍频程范数Xj(m)。
其中,k1(j)、k2(j)为定义的取值边界。同理,可定义重建语音信号的相应范数Yj(m),计算Yj(m) 的归一化形式
2.2 面向其他人工智能任务的评估指标
2.2.1 文本分类
文本分类是自然语言处理领域的典型任务,其目的在于通过人工智能为文本信息按照一定的标准进行标记,可细分为情感分析、主题分类、问答任务、意图识别等多种应用场景。以单标签二分类的情感分析任务为例,现有评价指标主要为分类准确率与F 分数[13](F −score),具体计算逻辑如下:
按照各样本的分类结果与真实标签,可将各样本的分类结果分为真阳性(TP)、真阴性(TN)、假阳性(FP)、假阴性(FN),如表1 混淆矩阵所示。在此基础上,准确率定义为经模型正确分类的样本占总样本的比例,是对任务性能最简单直观的度量。在实际应用场景中,FN与FP的代价可能是不同的,准确率指标无法对其进行细化评估,而F分数弥补了这方面的不足。
2.2.2 图像目标检测
图像目标检测的目的在于通过人工智能判断出图像中物体的类别与相应位置。图像目标检测任务的现有评价指标主要为平均精确度均值(mAP),其定义为各类目标查准率(P)-查全率(R)曲线下方面积的均值。

▼表1 二分类任务混淆矩阵
具体而言,首先,根据目标检测结果Bp的置信度,以及Bp与真实结果Bgt的重合程度(可用两者的交并比IoU 度量,,可将检测结果分为如表2 混淆矩阵所示的TP、TN、FP、FN;其次,由检测顺序中TP、FP数量的累加情况计算查准率与查全率的累加值:
然后,对于各类目标样本,以查全率为横坐标,以查准率为纵坐标,绘制P-R曲线并计算精确度均值(AP);最后,由AP 加权平均可得mAP,即分别为目标类别数量与该类别样本数量。
目前,基于上述定义的mAP 指标在现有工作[16]中已被广泛使用。值得注意的是,在如图像检索等实例级图像任务中,存在另一种基于整图匹配结果定义的mAP 指标(已应用在文献[17]的端到端车辆重识别系统中)。两者的运算逻辑一致,仅在混淆矩阵定义上存在差异。
2.2.3 语音识别
语音识别的目的在于通过人工智能实现语音信息到文本信息的模态转换过程。语音识别任务的现有评价指标主要为准确率ACCURACY。准确率可基于字错误率(WER)定义,即:

▼表2 目标检测任务混淆矩阵
整体而言,语义通信评价指标存在以下问题:
1)现有评价指标普遍从具体的重建任务/人工智能任务直接迁移而来,侧重于反映任务完成的准确性维度,忽视了时效性维度。语义通信系统追求的是在有限带宽资源消耗与时延下的任务完成准确性,而非不计成本地逼近准确性上限。
2)不同任务场景/模态信息下的评估指标不互通,性能评估结果不易理解。在语义通信过程中,受通信意图变化的影响,系统的评估指标会不断发生变化,造成通信质量评估混乱。
3)各评价指标的取值范围、量纲不一致,给性能的横向对比带来困难。如上文中所提到的PESQ、PSNR指标与文本分类和语音识别准确率指标存在明显差异。这种差异主要表现在取值范围与物理意义方面。
综上所述,对于语义通信系统的评价指标,一方面,应在选取应用任务导向的准确性指标的同时,引入时效性指标以进行制约;另一方面,应筛选物理意义相似的指标以组成指标集合,并设计指标的标准化逻辑统一取值范围,使在不同任务场景下构建的语义通信系统之间能够进行横向性能对比。对于包含不同通信意图的语义通信系统,它们的具体实现需要与场景、应用紧密结合。从整体视角进行直接的性能评估,有助于系统之间横向贯通,促进系统的迭代演进。
3 语义通信性能评估新角度
为解决现有语义通信性能评估指标存在的问题,我们提出语义通信效率指标Esc与语义通信效用指标Usc,并以语义图像重建与语音重建任务为例,搭建端到端语义通信仿真系统,基于所提指标对仿真系统性能进行评估。
3.1 新评估指标定义
其中,γ表示给定的通信资源条件,包含信噪比(SNR)与带 宽 等 参 数 ; ACC ∈{g(BLEU,MS −SSIM,TOP −n ACCURACY,mAP,…)}、TIM ∈{ f(计算时延,传输时延,端到端时延,…) }分别为语义任务相关的准确性与时效性评价指标,g(∙)与f(∙)分别为相应的变换函数;ACCmin与ACCth分别为特定语义任务的准确性下界与优化边界,TIMth为特定语义任务时效性优化边界。这里,超越边界的准确性或时效性指标的取值不存在或不具备进一步优化的需求。
标准化操作旨在规范不同评估指标的取值尺度,剔除语义任务难易度差异对语义通信系统性能评估产生的影响。进一步地,基于上述标准化指标,我们定义语义通信效率指标Esc:
语义通信效率指标Esc∈[0, 1]旨在衡量通信系统在给定通信资源下、在单位时间开销内的任务完成准确性。当通信系统的准确性指标增大或时效性指标减小时,Esc会增大,即Esc越接近1,系统的语义通信效率越高。
语义通信效用指标Usc为:
其中,λ表示加权因子,用于权衡准确性需求和时效性需求的比重。语义通信效用指标Usc∈[0, 1]旨在衡量通信系统在给定通信资源下,对于任务性能上限的接近程度。当系统侧重于任务完成准确性或时效性时,Usc的前项或后项会增大,但另一项会相应减小。Usc越接近1,系统在准确性与时效性两方面的综合效用表现越高。
3.2 新性能指标分析与评估
本文首先以图像重建任务为例,选取车联网领域的传感器扩展应用作为具体验证场景,基于上述评估指标进行仿真分析。传感器扩展应用要求车辆、行人、交通设施等通信节点之间能够实现传感器所采集的图像/视频信息的实时交互,对数据传输的准确性、时效性均有较高要求。
针对上述应用场景,准确性指标ACC 转换为对数形式MS −SSIM,时效性指标TIM 为传输时延,变换函数g(∙)与f(∙)均选取恒等函数,即:
根据第3代合作伙伴计划(3GPP)制定的《5G NR Rel-16 V2X车联网标准》,准确性边界、时效性边界与通信参数如表3所示。

▼表3 通信模型仿真参数
进一步地,我们搭建包含图像压缩重建、信道编码与调制模块在内的端到端通信仿真模型,基于选定指标进行验证。图像压缩重建模块基于文献[19]的网络结构实现,并分别采用ImageNet数据集、Cityscapes数据集进行训练和验证。图像压缩重建模块在训练过程中采用了4组不同的率失真参数α ={256, 512, 1 024, 2 048}。采用更高的α 参数训练的模型会更倾向于降低图像压缩比以换取更高的重建质量。模型采用低密度奇偶校验码(LDPC)进行信道编码,并根据信噪比条件将LDPC 码率控制在1/5~8/9 之间。调制方式采用二进制相移键控(BPSK)。
图1 给出了语义通信效率Esc与通信系统信噪比的关系曲线。随着信噪比的上升,包含不同参数的语义任务模型均表现出更高的语义通信效率。此外,采用高α参数训练的模型对信噪比的变化更为敏感,在低信噪比条件下表现出明显的性能劣化,同时在高信噪比条件下具有更高的性能上限。这是由于此类模型在低信噪比条件下产生了过多的编码开销以保护信息不被噪声破坏,从而无法满足任务的时效性需求;在高信噪比条件下,通信所需的编码冗余显著减少。此类模型能够在时效性不超出阈值的前提下,实现更高的任务准确性。
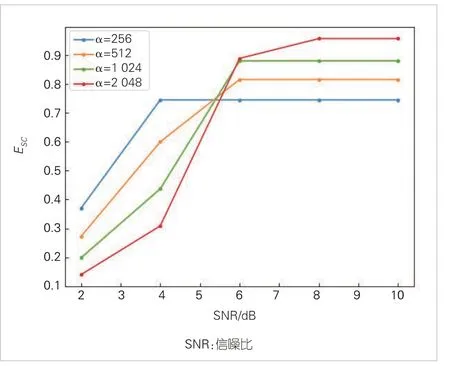
▲图1 图像重建任务语义通信效率Esc与信噪比的关系曲线
图2给出了λ = 5条件下语义通信效用Usc与通信系统信噪比的关系曲线。考虑到实际语义任务场景中存在对准确性或时效性更为侧重的情况,参数λ使效用指标更为真实地反映语义任务需求。本部分以准确性需求导向的任务为例。随着信噪比的上升,4组模型的语义通信效用均表现出与直觉吻合的上升趋势。即使在低信噪比条件下,高α参数模型表现出较高的准确性与较低的时效性,其语义通信效率劣于低α参数模型。但由于任务对于准确性需求的侧重,高α参数模型具有更高的语义通信效用。图3与表4分别展示了典型图像经语义图像重构模型仿真传输后的可视化结果与具体性能参数。高α参数模型表现为更出色的图像重建质量(红绿灯的色彩更准确,建筑物、地砖的细节更清晰)与更高的图像传输时延开销,在较好的信道条件下,其传输时延未超出阈值,故高α参数模型具有更高的语义通信效率与语义通信效用。

▲图2 图像重建任务语义通信效用Usc与信噪比的关系曲线(λ = 5)

▲图3 通信模型可视化结果

▼表4 通信模型性能参数
接着我们以语音信息重建任务为例,构建应用自适应多速率宽带(AMR −WB)语音编码的高清语音通信模型,并基于上述评估指标进行仿真分析。准确性指标ACC转换为宽带语音质量感知评估(WB −PESQ),时效性指标TIM 为传输时延,变换函数g(∙)与f(∙)均选取恒等函数,即:
同时,准确性边界、时效性边界与通信参数如表3所示。
本文采用日本电报电话公司(NTT)宽带语音数据集[20]的美式英语子集进行验证,同时为AMR −WB编码设定4组不同的速率参数α ={12.65,15.85,19.85,23.85 (kbit/s)}。采用更高码率的模型会更倾向于降低压缩比以获得更高的重建质量。模型同样采用LDPC 信道编码与BPSK 调制方式,并根据信噪比条件将LDPC的码率控制在1/5~8/9之间。
图4给出了λ = 1/5条件下语义通信效率Esc与效用Usc随通信系统信噪比的变化趋势曲线。与面向图像重建任务的语义通信系统相似,随着信噪比的上升,效率与效用指标均表现出上升趋势。同时,在语义效用Usc方面,低速率编码方案具有更显著的优势,能够反映出系统对时效性需求的侧重。在上述面向图像与语音重建任务的通信模型仿真中,除带宽之外的通信参数都是一致的。语义通信效率指标与效用指标的评估结果表现出统一性,为两者的横向性能对比提供指导。带宽参数的设定与信息模态相关,它所产生的影响可通过对变换函数进一步设计来消除。

▲图4 语音重建任务语义通信效率Esc与效用Usc随信噪比的关系曲线(λ = 1/5)
4 结束语
通过融合人工智能与通信技术,充分利用语义层面信息的高度抽象、智能简约等特性,语义通信有望形成突破经典通信系统传输瓶颈的智能新型通信体系。由于语义通信尚处于研究初期,统一且具泛化价值的性能评估体系的缺失,阻碍了关键性成果间的横向贯通与对比。本文通过分析语义通信评估痛点,提出语义通信效率指标Esc与语义通信效用指标Usc。该指标具有更好的泛用性,且为不同任务场景、模态信息下的语义通信模型的横向性能对比提供指导,进而促进语义通信的快速发展。
