基于机器学习算法的企业财务舞弊预测及可解释性分析
2023-05-10童洁蒋红艳
童洁 蒋红艳


摘 要: 财务舞弊不仅损害了投资者信心,也对资本市场产生极大影响。为预测企业的财务舞弊行为,文章选取2016-2020未发生舞弊行为与首次发生舞弊行为的企业作为研究对象,依据Python机器学习算法建立决策树、支持向量机、神经网络及逻辑回归模型,基于舞弊三因素理论选取44个指标预测企业财务舞弊行为,并通过SHAP可解释性工具重点关注单个指标变化对财务舞弊预测的重要性程度,同时分析财务指标以及非财务指标对预测财务舞弊的相互作用、预测错误的样本查看的影响。研究结果表明支持向量机对于预测舞弊效果最优,逻辑回归在模型的精确度表现最佳。
关键词: 财务舞弊; 机器学习; 预测; 可解释性分析
中图分类号:F275;F406.7 文献标识码:A 文章编号:1005-6432(2023)11-0000-04
[DOI]10.13939/j.cnki.zgsc.2023.11.000
1 引言
近些年来,部分上市公司出于维持股价、避免退市等动机,存在虚构资产、虚构利润等财务舞弊行为,给投资者们造成了巨大的损失,也对资本市场的稳定产生影响[1]。由于审计机构的独立性有限[2],仅依靠审计意见无法有效预测企业的财务舞弊行为,故而如何有效识别出企业财务舞弊行为,是一直存在的亟待解决的难题。
随着大数据和人工智能的兴起,机器学习在模拟对象具体特征、處理复杂及大量的数据时具有优越性,通过对大数据进行多维度统计分析,剔除干扰信息,可得到预测准确率较高的结果。所以,利用机器学习方法对财务舞弊因素进行研究具有一定的优势。
本文的创新之处:一是本文根据舞弊理论,选取预测指标共44个,涵盖财务指标和非财务指标,相比以往研究更全面;二是在决策树模型中,除使用网格搜索外,还编制程序自行改变树深参数进行训练;三是可解释性分析全面严谨,使用多个可解释性工具进行分析,其结论均可互相验证和补充。
2 模型与算法
2.1支持向量机
支持向量机是一种广义线性分类器[3],应用于解决复杂的回归和分类问题,以间隔最大化为原则,将线性不可分数据扩展到多维空间中,并运用超平面进行划分,寻找全局最优解,增强模型的泛化能力,从而解决对小样本、非线性的统计预测。
若利用支持向量机进行财务舞弊识别,首先要找到舞弊和非舞弊的样本点中离这个超平面最近的点,并使这个点到超平面的距离最大化,从而区分出舞弊样本和非舞弊样本,确定的这个超平面也就可以作为判断样本是否舞弊了的分类器[4]。
其中,Q为最优化目标值;W为权重系数。
最后通过Lagrangian函数,转化为对偶形式,以求取最优超平面,设![]() ,
,![]() 为拉格朗日因子;
为拉格朗日因子;![]() 为核函数,包括以线性核函数、多项式核函数、RBF核函数等[5],得到回归函数如下:
为核函数,包括以线性核函数、多项式核函数、RBF核函数等[5],得到回归函数如下:
2.2逻辑回归
逻辑回归作为比较常用的机器学习方法,属于广义回归模型。逻辑回归模型的因变量为二分类变量[6],利用已有训练集样本数据进行模型拟合,利用所得模型对测试集进行预测,公式如下:
2.3决策树
决策树由结点和有向边构成,是一种以树状结构进行表达的预测模型[7]。决策树从根节点开始在不同属性空间进行最优属性选择,以此分裂不同的分支并继续在属性空间中进行最优属性选择,直至属性分纯。其中,C5.0以信息熵的下降速度作为确定最佳分支变量和分割阀值的依据。
2.4神经网络
神经网络是经典的机器学习算法,根据给定的训练样本,不断将误差项作为反馈信号进行多层次的算法训练,调整神经网络参数。神经网络主要包含输入层、隐含层和输出层三层,不同层之间的神经元可以利用通道进行信息传输[8]。本文将个财务指标的样本数据作为输入层,将是否舞弊作为输出层。
2.5SHAP模型
除去模型自身特征重要度衡量指标,SHAP模型也可反映某个特征对整体模型和结果的贡献程度。计算某个特征(指标)的归因值(shap value),将模型的预测值解释为每个输入特征的归因值之和,使其输出结果具有可加一致性[9]。
对于每一个预测样本,模型输出预测值,shap value为该样本中每个特征(指标)分配到的数值[10]。
其中表示样本的shap value,使用这种方法既可以确保贡献值加和为最终预测结果,也能消除模型间结构性差异带来的可解释性差异。如果某指标在大多数样本上表现出了一致的趋势,那么说明模型认定这一指标具有重要的正向或者负向作用。
3 数据及变量选择
3.1样本数据选取
本文预选取从2016-2020年发生财务舞弊的样本进行研究,依据国泰安CSMAR数据库,根据违规类型筛选出“虚构利润、虚假记载、虚列资产、重大遗漏、披露不实”五大类型舞弊公司样本共288个。由于需要获取样本对应的数据资料,我们选取首次舞弊年份作为样本的研究年份;且为了统一样本股票类型,筛后保留A股主板样本共205个。
本文根据《中国上市公司质量评价报告》选取非舞弊公司样本,将报告中公司进行违规处理筛选,选取在2016-2020年间非舞弊样本共205个。
根据选取的样本进行样本清洗并收集数据,因退市或未核算等原因,不同指标均含有缺失值,由于同一指标的缺失值数量较少且是面板数据,本文利用删除指标缺失值对应样本的方式进行样本删除。经整理,选取262个样本,包括舞弊样本124个,非舞弊样本138个。
由于选择的指标存在正向指标和逆向指标,故而对数据进行标准化处理,具体方法如下:
3.2变量选择
根据舞弊三因素理论,企业财务舞弊的发生需要满足三个前提,分别是舞弊机会、舞弊压力以及舞弊借口[11]。舞弊机会主要是指企业的内部制度存在漏洞或其他原因允许企业进行财务舞弊。舞弊压力是指当企业面对较大的破产风险或其他财务风险承受的压力。舞弊借口是指企业认为财务舞弊行为不易被发现且在下一年的财务报表可以调整今年财务舞弊带来的影响。根据三因素主要选择以下财务指标以及非财务指标。
进行财务指标数据与非财务指标数据收集时,利用wind金融终端和国泰安CSMAR数据库获取各样本指标数值,并利用Python软件对数据进行整理和指标计算。
选取财务指标:流动比率、资产负债率、利息保障倍数、年化总资产净利率、营业成本率、净利率、管理费用增长率、总资产增长率、可持续增长率、营业收入增长率、存货周转率、应收账款周转率、总资产周转率、经营杠杆、财务杠杆、综合杠杆、全部现金回收率、营业收入现金含量、托宾Q值、账面市值、破产风险(Z值)、避免退市或者ST和资产减值准备增长率/
选取非财务指标:董事长与总经理兼任情况、董事人数、独立董事比例、监事人数、高管前3名薪酬总额、第一大股东控制度、股权集中度、总资产净利润率行业比值、销售费用率行业比值、营业外收入占比行业比值、资产负债率行业比值、营业收入增长率行业比值、审计意见类型、审计师规模、会计事务所变更次数、交易方关联程度、总资产周转率前年比值、总资产净利润率前年比值、销售费用率前年比值、营业收入现金含量前年比。
数据预处理:由于本文选择的指标数量较多,为提升模型拟合效果,在建立模型前对变量进行低方差过滤,过滤掉差异小的变量。同时为了避免不同变量的量纲差异对模型预测产生影响,进行了特征标准化处理。上述处理完成后进行了降维处理,减少指标数量。
4 实证分析
4.1模型识别及效果分析
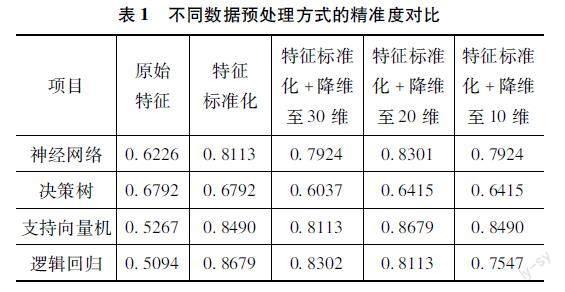
在特征标准化及降维至20维的数据处理方法下,神经网络及支持向量机模型准确率均分别达到最大值83.02%及86.79%;决策树以及逻辑回归模型在特征标准化的处理方法下,准确率分别达到最大值67.92%及86.79%。在特征标准化处理下,除决策树模型外,剩余三种模型的准确率均得到大幅提升。且数据进行标准化处理后,降维至20维的数据在所有模型中准确率最高。
由图1不同模型的分类结果对比图得,除决策树模型外,其余模型的准确率均达到87%以上。逻辑回归的精确率最高,支持向量机的召回率与F1分数最高。
由图2不同深度的决策树效果对比得,深度为9层的决策树模型识别效果最好,准确率、精确率、F1分数均达到最大值。深度为5层的决策树模型的召回率最大。随着决策树层数的增多,四项模型性能参数均出现先减小后增至最高点,再减小的趋势。
4.2决策树结果讨论
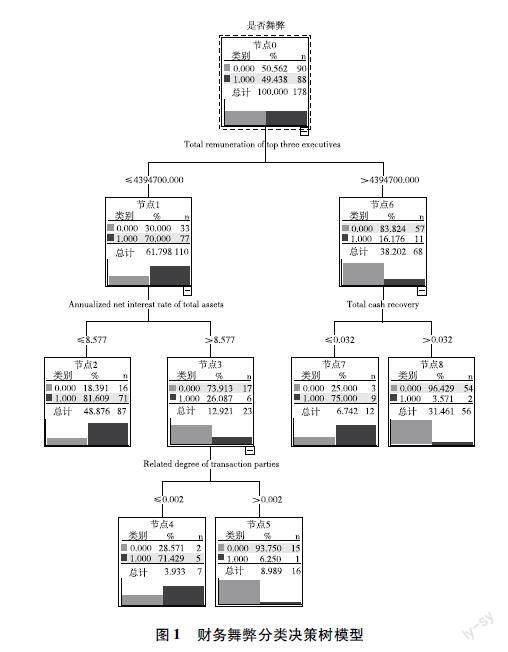
根据最佳树深和降维选择,生成决策树部分规则如下:
第一,高管前3名薪酬总额小于等于4394700元且总资产净利率小于等于8.577的上市公司更容易发生舞弊行为。
第二,高管前3名薪酬总额小于等于4394700元、总资产净利率大于8.577且交易方关联度小于等于0.002的上市公司更容易发生舞弊行为。
第三,高管前3名薪酬总额大于4394700元且全部现金回收率小于等于0.032的上市公司更容易发生舞弊行为。
以上规则是C5.0决策树经过迭代结果后,最终选择出来的规则。通过以上规则发现影响变量的重要性因素分别有“总资产周转率”、“高管前3名薪酬总额”、“全部现金回收率”等。
4.3可解释性分析
由图3特征排列重要性图得,企业的年化总资产净利率、高管前3名薪酬总额对企业是否舞弊最为重要,营业收入增长率、经营杠杆以及资产负债率行业比值的影响次之,账面市值比、总资产净利润率行业比值等因素对企业舞弊行为的发生存在一定影响,但影响较小。财务杠杆以及总资产周转率等因素对预测企业是否舞弊贡献度低。
如图4所有样本按照相似性排列的summary plot所示,从相似性角度分析,相似的非舞弊公司共同具体的特征为高管前3名薪酬总额较低、全部现金回收率较低;相似的舞弊公司共同具体的特征为年化总资产净利率较大、营业收入现金含量前年比较高。
由图5发生财务舞弊样本的force plot图得,样本企業发生舞弊概率低于基准线,发生舞弊的概率为低风险。样本企业的年化总资产净利率、高管前3名薪酬总额以及账面市值比对发生舞弊行为均具有负向贡献,三者的负向影响程度依次递减。
5 结论
本研究得出以下结论:支持向量机与神经网络、决策树以及逻辑回归相比,财务舞弊的预测效果最好。采用逻辑回归模型预测时,模型的精确度最高;采用支持向量机预测时,模型的召回率以及F1分数最高。随着决策树深度的增加,模型的预测效果先升后降;且在不同深度的决策树模型中,财务舞弊的预测效果在深度为9的模型中最佳。
其次,总资产净利率、股权集中度以及高管前三名薪酬总额等指标对预测财务舞弊十分重要,应当重点关注。其中,高管前三名薪酬总额、交易方关联度与企业发生财务舞弊的可能性存在负相关关系。总资产净利率与企业发生财务舞弊的可能性主要存在正相关关系。
根据以上结论得出以下建议:完善企业内部控制制度,保证董事以及监事数量,落实其监督责任。采用股权激励等多种薪酬激励方式,提升管理层积极性。建立风险预警制度,及时识别经营风险;同时企业内外部的监管者应当加强对企业的监督以及处罚措施,对于发生了财务舞弊的公司要监督其进行整改。审计人员应当建立完备的审计程序,针对容易发生舞弊的项目应当要重点审查。
参考文献
- 李辉.基于Logistic模型的深度贫困地区贫困人口致贫因素分析[J].西北民族研究,2018(4):51-58.
[作者简介]童洁,女,安徽安庆人,研究方向: 统计分析、机器学习;蒋红艳,女,湖南衡阳人,研究方向:财务会计。
