基于随机森林和优化GRU算法的柴油机NOx预测
2023-05-09郭智刚闫立冰冯健洧
郭智刚,申 宗,江 楠,闫立冰,冯健洧
(潍柴动力股份有限公司,山东 潍坊 261021)
近年来,中国环境污染越来越严重,涉及水污染、空气污染等各种污染,其中最引人关注的当属空气污染[1]。机动车排放是大气污染物的主要贡献者,且柴油车排放的NOx 超过机动车氮氧化物的80%[2]。传感器测量排放污染物由于受到成本、精度误差等因素制约[3],通常采用模型预测柴油机的NOx 排放[4]。基于MAP 映射是一种常用的方法,根据发动机的转速与喷油量查找对应工况下MAP 图的NOx 排放,而对MAP 图的标定是依赖于发动机台架标定实验。随着对性能的追求以及排放要求的提升,各种新技术会应用到发动机上,这也就使得发动机系统变得更加复杂,进而使得标定实验变得更加复杂困难,再加之标定工作的效果很大程度上依赖于标定人员的操作,这使得整个试验成本较高并且耗费的时间较长。设计结构简单又能表达非线性系统特征的模型成为研究人员关注的问题[5]。随着机器学习与神经网络的发展,借助于神经网络模型预测排放物浓度成为研究的热点问题[6-8]。文献[6]提出使用深度极限学习机,基于发动机不同运行状态下的数据对尾气排放进行预测。周斌[5]建立不依赖于研究对象数学模型的三层Back Propagation(BP)神经网络预测发动机的排放。胡杰等[8]选用最小二乘法提取特征并利用神经网络进行拟合,建立柴油机NOx排放预测模型。
上述研究并没有考虑到样本之间的时间序列联系,网络表达能力有限。本文考虑到影响NOx产生的因素过多,导致整个模型的训练与预测时间过长,采用随机森林选取重要特征,同时注意到内燃机的NOx 排放与各参数的变化时序有关,即上个状态的各个工况参数与当前NOx 的排放有一定关系,使用基于优化的门控循环单元(Gate Recurrent Unit, GRU)网络对最终结果的预测更加有效。综上提出使用随机森林与GRU 结合的方法建立NOx 预测模型。
1 基于随机森林的特征选择算法
NOx 的产生影响因素较多,本文初步选择了18 个相关参数作为影响NOx 的特征:增压压力、轨压、进气温度、进气压力、废气再循环(Exhaust Gas Recirculation, EGR)冷却温度、燃油流量、进气流量、EGR 流量、EGR 开度、EGR 设定、节流阀位置、节流阀设定、发动机转速、发动机扭矩、主喷提前角、主喷油量、预喷油量、后喷油量。
神经网络训练过程中,并不是特征越多性能就会越好,输入特征数过多造成的最直接影响就是计算量剧增,除了给计算量带来不利的影响外,有些特征对于最后结果的表达贡献并不大,这就需要通过特征提取去压缩数据特征维数,在满足最终预测精度的前提下,尽量减少处理数据的冗余度。因此,有保留地选择出对最终结果影响最大的特征参数成了重要的过程,也是必不可少的一步[9-11]。文献[9]利用主成分分析法(Principal Component Analysis, PCA)对内燃机的噪声特征进行提取并取得了较好结果。文献[10]在轴承状态监测的故障分类中使用PCA 进行最优特征选取。文献[11]选用通过特征降维后提高了柴油机部件的故障识别率。
随机森林是一种有效的机器学习方法,在诸多领域均有应用,如疲劳驾驶检测[12]、癌症诊断[13]、信用评估[14]等。随机森林的突出优点是计算复杂度低,随机选择样本和特征,泛化能力较强、特征重要性评估准确性高[15]。随机森林基本组成单元为决策树,通过随机的选择样本建立不同的决策树,从而组成性能更加强大的随机森林。本文中的随机森林算法具体过程如下:
1)从共计含有18 880 个样本的数据集中有放回的随机抽取70%的样本作为一个训练集;
2)利用步骤1)中的样本集生成一颗决策树,决策树每个节点的生成规则,如重复的选择随机,不重复地选择16 个特征;
3)在所选样本集中寻找16 个特征的最优划分点,特征划分的基本原则为使得划分后的熵增益最大;
4)重复步骤1)、步骤2)建立150 棵决策树,即建立成随机森林;
5)用随机森林对测试样本进行预测,并利用票选法决定预测结果。
随机森林算法流程如图1 所示。
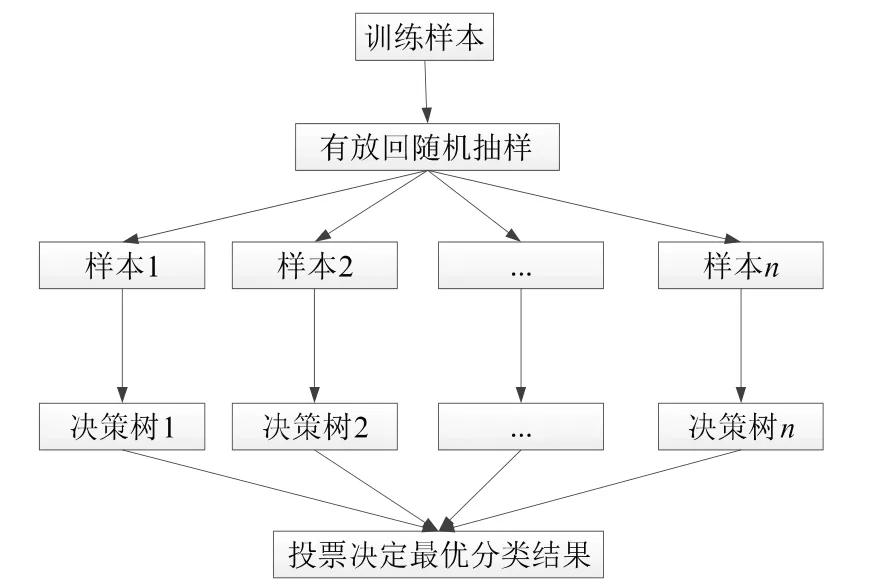
图1 随机森林算法流程
由图1 可见,随机森林的强大之处体现在随机性上,不仅在样本的选择上随机选取,建立决策树时也会随机选择特征。随机森林的一个重要的用途便是评估重要特征,本文采用袋外数据分类的准确性来测试特征的重要性,流程如下:
1)计算每一棵决策树的袋外数据误差,记为err1;
2)对袋外数据所有样本的特征随机添加噪声,再次计算袋外误差,记为err2;
3)计算特征的重要性I。
其中,袋外数据是指在进行随机有放回选择样本的时候,没有用于建立决策树的数据,而这部分数据会被用作评估决策树,这样避免造成使用训练数据进行评估而造成的数值误差。模型在袋外数据下的预测错误率,被称为袋外错误率,重要性I计算公式为
式中,N为随机森林中的N棵树。越重要的特征在被改变后,对最后的结果产生的影响越大,因此,在对特征添加随机噪声后,使得袋外误差增加越大,说明对最终预测结果的重要性越大。
依据以上步骤进行特征重要性的绘制如图2所示,根据特征重要图的特征重要性排序选取EGR 冷却温度、进气温度、增压压力、转速、扭矩、进气流量的六个特征作为网络特征输入。
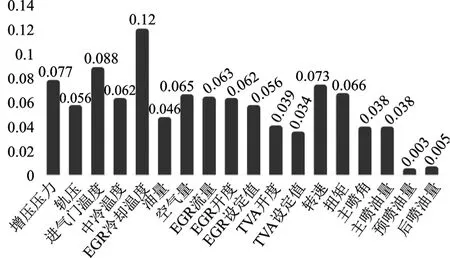
图2 特征重要性
2 基于门控单元的排放模型与优化
深度学习中对于传统的序列问题通常使用循环神经网络(Recurrent Neural Network, RNN),t时刻接收到输入Xt之后,隐藏层的值为St,输出为Ot,此时关键点在于St的计算参考St-1,即上个时刻的状态,这时的网络初步具备了“记忆”功能,也就是说对于一个序列,后一个输入与前一个输入并不是没有关系,通过将本时刻的输入与上一时刻的状态建立联系,从而提高网络的表达能力。随着时间序列的推移,后面的时间节点对之前节点的感知能力会逐渐下降,并且 RNN 无法控制写入记忆模块的内容[4]。GRU 可以很好地解决这种问题,且能够更好地捕捉序列中较长的依赖关系[16]。
GRU 的基本结构如图3 所示,其使用门控机制控制输入信息和记忆信息,并在当前时间状态下给出预测信息。GRU 通过两个门控制神经网络的输出,能长时间保存时间序列信息,不会随时间推移和预测结果不同而被丢弃[17]。
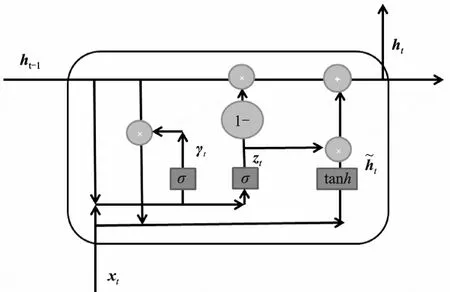
图3 GRU 基本结构
图3 中的zt与γt分别为GRU 的update gate(更新门)与reset gate(重置门)。更新门反映的是前一状态信息对当前状态信息的影响权重,该值越大表明,当前信息应该增大包含前一状态信息的权重。重置门反映的是抛弃前一信息的权重,该值越大应该更多忽略上一状态信息。GRU 通过使用一种“门”的结构,极大地避免了梯度消失的问题,可以更有效地分析长期依赖关系,同时GRU化简了单元复杂度[18],实际运行过程中效率更高,其中σ为Sigmoid 激活函数;tanh为激活函数。GRU 前向传播公式为
式中,[]为向量相连;*为矩阵乘积,即损失函数是神经网络中衡量预测值与真实值之间差距的指标,损失函数的设计优劣对网络的最终训练结果有重要的影响,损失函数选用Smooth L1 Loss 函数,公式为
Smooth L1 Loss 的优势在于真实值与预测值差别较小时,神经网络的梯度更新较小,使得神经网络的效果更精准,如图4 所示。而真实值与预测值差别较大时,梯度值并不会太大以至于产生梯度爆炸的情况。
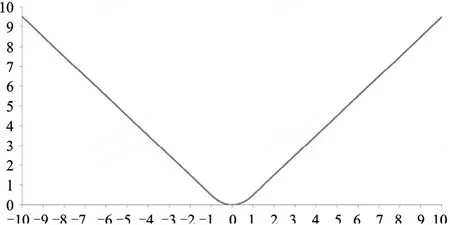
图4 Smooth L1 Loss 函数图像
神经网络的优化通过梯度下降的方法实现,针对梯度下降的优化算法[19-21]有很多。本文选用Adam(适应性动量估计)的优化算法,Adam 参数更新为
Adam 综合了文献[19]与文献[20]的方法,全面估计了梯度的一阶矩和二阶矩,其中β1通常取0.9,β2通常取0.999,相比于其他优化算法,Adam算法计算高效,同时能自适应调整学习率,在神经网络的优化过程中表现更优。
GRU 网络参数设置如表1 所示。

表1 GRU 网络参数设置
受制于影响NOx 排放的因素过多,且各个工况下内燃机的运行复杂性,部分样本的预测结果不理想。提高网络的预测结果,最直接的方法就是对样本的处理,困难样本加强的核心思想是使用网络模型对样本进行处理,把其中难以达到预期的样本统一放置一个集合中,之后使用该集合继续训练分类器。也就是说,训练结束后使用训练的模型对样本进行测试,测试结束后挑选困难样本,将困难样本形成一个集合后,对原有的模型使用困难样本集合继续训练,当阈值过大时认定为是困难样本需要重新训练,反之不进行重新训练。对困难样本的挖掘重新训练,可以增强网络的泛化能力,提高模型的鲁棒性。
综上,基于优化GRU 的NOx 预测排放框架如图5 所示。

图5 优化GRU 架构
3 实验过程和结果
为了验证模型的效果,进行全球统一瞬态试验循环(World Harmonized Transient Cycle, WHTC)试验,以稳态数据作为实验数据,其中实验数据70%作为训练集,30%作为测试集,其中模型在瞬态工况下预测效果如图6 所示。
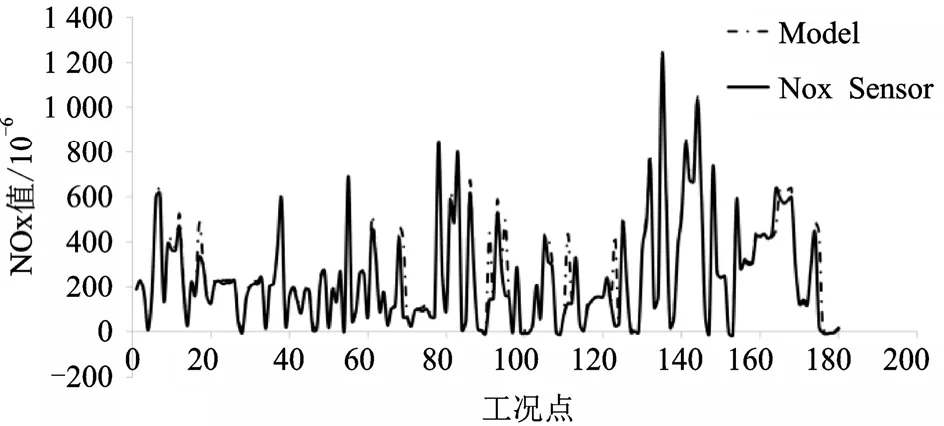
图6 瞬态工况下GRU 与传感器结果对比
模型在稳态工况下预测效果如图7 所示。

图7 稳态工况下GRU 与传感器结果对比
使用随机森林选择的六个特征(EGR 冷却温度、进气温度、增压压力、转速、扭矩、进气流量)进行试验,预测值基本符合实际值的变化,表明该模型具有较高的精准度,但部分工况点存在偏差,推测原因如下:
1)网络表达能力的限制,网络的表达能力与网络的设置结构有重要关系,但复杂的结构不仅会造成训练时间过长,甚至可能造成过拟合情况出现,导致模型在训练集中表现良好但测试集中表现较差,实际使用中需要在模型精度与训练时间做一个有效权衡;
2)实际采集数据中可能存在的异常点导致部分工况无法准确学习。
设置对照试验,使用相同数据设置BP 模型与多项式模型的NOx 预测对照试验。使用均方根误差(Root Mean Square Error, RMSE)与R2 两个参数来量化训练效果,RMSE 与R2 是回归分析中常用的两个评价指标,其中RMSE 的计算公式为
R2 决定系数用以衡量预测值与真实值之间的偏差,其计算公式为
式中,为当前样本的预测值;为样本的平均值。
为说明算法的有效性,将本文算法与BP 神经网络以及多项式模型进行对比,其中BP 神经网络的相关参数设置同与本文算法GRU 参数设置相同。而多项式模型中使用最小均方误差进行拟合,各个模型分别对相同的稳态和瞬态数据进行试验,相关对比结果如表2、表3 所示。由实验结果可知,在瞬态工况与稳态工况下,相比于BP 模型与多项式拟合模型,随机森林结合GRU 具有更高的精准度。

表2 瞬态工况下预测结果图

表3 稳态工况下预测结果图
4 结论
本文以柴油机NOx 的排放预测为研究对象,提出使用随机森林与GRU 神经网络结合的方法进行预测,随机森林选取对预测结果影响较大的特征,构建基于门结构的循环神经网络,并针对实际训练提出一些优化训练的方法。针对上述算法,以WHTC 工况数据以及万有数据为输入,进行了对比实验,根据实验结果显示,本文使用的方法在稳态工况与瞬态工况均有良好表现,瞬态工况下较传统的BP 模型精度提高了54.3%,稳态工况下较传统的BP 模型精度提高了49.81%,从而证明本算法预测NOx 排放的高精准度以及良好的泛化性。
