极限学习机及其在质子交换膜燃料电池参数辨识中的应用
2023-05-08曾春源陈义军束洪春曹璞璘
杨 博, 曾春源, 陈义军, 束洪春, 曹璞璘
(昆明理工大学 电力工程学院, 昆明 650500)
日益增长的能源需求、传统燃料资源的枯竭和环境污染给社会的可持续发展带来巨大的挑战[1].为缓解上述问题,优化能源结构,发展绿色能源技术势在必行[2].其中,燃料电池(Fuel Cell, FC)系统以其高效、低污染、可持续发展等优点得到广泛的应用.燃料电池一般可分为4种类型,即质子交换膜燃料电池(Proton Exchange Membrane Fuel Cell, PEMFC)[3-4]、磷酸燃料电池、固体氧化燃料电池(Solid Oxide Fuel Cell, SOFC)和熔融碳酸盐燃料电池.
PEMFC具有响应速度快、启动速度快、工作温度低、无污染等优点,已广泛应用于航空、电动汽车和分布式发电等领域.此外,为获得准确可靠的电压-电流(V-I)特性,研究人员开发了多种PEMFC模型,如三维稳态模型[5]、物理电解槽模型[6]、电化学稳态模型[7]等.尤其是由半经验方程推导出的电化学稳态模型能够很好地预测PEMFC的稳态和瞬时状态,该模型中包含的一些未知参数对PEMFC的准确性和可靠性有很大影响.
然而,PEMFC的高度非线性、强耦合和多峰值特性严重阻碍人们利用传统方法获得满意的参数辨识结果.近年来,启发式算法(Meta-Heuristic Algorithms, MhAs)[4]以其极大的灵活性被广泛应用于PEMFC模型的参数辨识.例如,文献[8]采用粒子群优化算法对Nexa 1.2 kW PEMFC进行离线参数辨识.文献[9]模拟遗传学和自然选择的自然进化行为,利用改进遗传算法(Genetic Algorithm, GA)辨识PEMFC参数.同时,其他先进的MhAs也用于PEMFC参数辨识,例如,灰狼优化(Grey Wolf Optimizer, GWO)算法[10]、鲸鱼优化算法(Whale Optimization Algorithm, WOA)[11]、飞蛾扑火算法[12]、差分进化算法[13]、蚁狮优化(Antlion Optimization, ALO)算法[14]、蜻蜓算法(Dragonfly Algorithm, DA)[14]、平衡优化器(Equilibrium Optimizer, EO)[15]等.到目前为止,MhAs在提高搜索能力和效率方面已取得显著进展.但是,上述文献忽略了数据噪声对PEMFC参数辨识的干扰,而由于测量误差或环境影响,这种情况在实际应用中不可避免且普遍存在.噪声的存在会导致MhAs的收敛速度减慢,PEMFC的参数辨识误差增大,使得后续的建模准确性降低.因此,需要采用一种切实有效的手段对数据噪声进行处理.
在数据降噪处理领域中,传统的方法有回归分析、聚类分析和分箱方法等.这些方法只能通过处理临近数据来确定最终解,没有自主学习能力,具有一定的缺陷.而人工神经网络(Artificial Neural Network, ANN)有强大的学习和适应能力,能够模拟人脑神经元的协同以实现信息的传递和处理,在数据降噪方面得到广泛研究.
因此,提出一种基于极限学习机(Extreme Learning Machine, ELM)的MhAs——ELM-MhAs来提高PEMFC的参数辨识性能.同时,对比ELM和另一种ANN策略——贝叶斯正则神经网络(Bayesian Regularization Neural Network, BRNN)[16]的噪声性能.主要贡献和创新点可以总结如下:
(1) 考虑数据噪声对PEMFC参数辨识的影响,利用ELM策略减少或滤除数据噪声,以获得PEMFC更准确的V-I数据.
(2) 结合ELM降噪策略和多种先进MhAs,在低温、低相对湿度和高温、高相对湿度两个算例下全面比较6种主流MhAs性能,全面评价与分析ELM-MhAs的性能.
(3) 综合对比ELM-MhAs策略和BRNN-MhAs策略的降噪性能,仿真结果表明ELM-MhAs能够更有效地辨识PEMFC参数,且辨识精度高、速度快、稳定性好.
(4) 基于ELM和BRNN两种降噪策略,全面对比神经网络训练端到端参数辨识模型,即列文伯格-马夸尔特反向传播法(Levenberg-Marquardt Backpropagation, LMBP)[17]与6种MhAs算法的PEMFC参数辨识结果,验证ELM降噪策略具有较强的泛化能力,能够与其他参数辨识算法结合.
1 质子交换膜燃料电池建模
1.1 电化学反应
在实际运用中,PEMFC的电势会逐渐降低,这是因为电池内部存在不可逆的损失,这些不可逆的损失又被称为过电压或极化电势.PEMFC的极化曲线主要受3部分影响,即活化极化、欧姆极化、浓差极化,如图1所示.
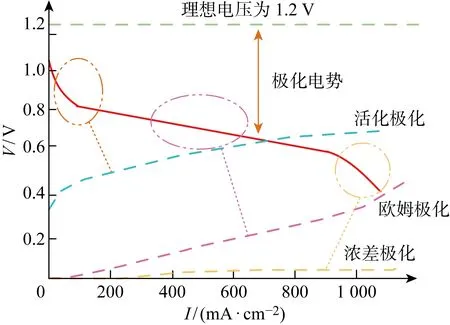
图1 PEMFC极化曲线
PEMFC内部的电化学反应[18]可表示为
阳极:
H2→2H++2e-
(1)
阴极:
(2)
总反应:
2H2+O2→2H2O
(3)
该反应放能.
1.2 数学建模
在考虑电化学反应的极化情况下,单个PEMFC输出电压[17]为
Vc=Enerns-Vact-Vohmic-Vcon
(4)
式中:Enerns为能斯特电动势;Vact为活化过电压;Vohmic为欧姆过电压;Vcon为浓差过电压.
能斯特电动势为热力学电动势,指理想情况下的输出电压,表示为
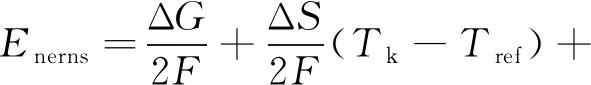
(5)
式中:ΔG为吉布斯自由能的变化;F为法拉第常数,取96.487 C/mol;ΔS为熵变;R为气体常数,取8.314 J/(K·mol);Tk和Tref分别为实际工作温度和参考温度;pH2和pO2分别为氢分压和氧分压,可描述为
(6)
(7)
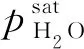
Tc=Tk-273.15
(8)
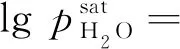
(9)
活化过电压[19]可表示为
Vact=ε1+ε2Tk+ε3TklncO2+ε3Tklnicell
(10)
式中:εi′(i′=1, 2, 3, 4)为半经验系数;cO2为氧催化界面氧气浓度,可描述为
(11)
欧姆过电压计算如下:
Vohmic=icell(Rm+Rc)
(12)
式中:Rc为电子传导的等效接触电阻;Rm为质子传导的等效膜电阻,表示为
(13)
式中:l为膜厚度;ρm为膜电阻率,描述为
ρm=
(14)
式中:λ为经验系数,表示膜的含水量.
浓差过电压受氢、氧浓度的影响[20],可表示为
(15)
式中:b为经验系数;J和Jmax分别为实际电流密度和最大电流密度.
从式(4)~(15)可以看出PEMFC模型需要确定7个未知参数,即ε1,ε2,ε3,ε4,b,λ和Rc.
1.3 目标函数
为准确辨识PEMFC的7个参数,需设计合理的目标函数,使实际值与估计值之间的误差最小.选用均方根误差(RMSE)作为目标函数,如下:
(16)
式中:x′为待优化变量,即x′=(ε1,ε2,ε3,ε4,b,λ,Rc);N为实际数据量;In为实际数据集中第n个电流值;Vav,n和Vest,n为实际数据集中第n个输出电压值以及In对应的估计电压值.
同时,为高效实现参数辨识,对待辨识的PEMFC参数上下边界进行约束,有
(17)
2 PEMFC参数辨识的 ELM-MhAs设计
2.1 ELM基本原理
与其他常规的前馈神经网络相比,ELM[21]能显著提高鲁棒性、泛化能力、学习速度和训练精度.ELM的拓扑结构如图2所示.
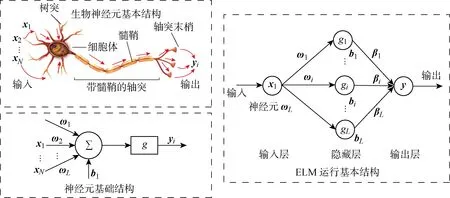
图2 ELM的拓扑结构图
训练开始时,ELM能随机初始化输入权重和偏置,且在后续训练中无需进行调整,仅需设定隐藏层的神经元个数,即可在输出层获得全局最优解.
详细论证ELM主要数学机理[22-23]:假设ELM的输入层有N个神经元,对应N个输入变量;隐藏层有L个神经元;输出层有M个神经元,对应M个输出变量.当有N个训练数据(xi,ti),xi=(xi1,xi2, …,xin)T∈Rn,ti=(ti1,ti2, …,tim)T∈Rm时,对应于该ELM的输出计算如下:
(18)
式中:xi为ELM的第i个输入;ωj=(ωj1,ωj2, …,ωjn)T为输入层神经元和第j个隐藏层神经元之间的权重;bj为第j个隐藏层神经元的偏置;g(·)为激活函数;βj=(βj1,βj2, …,βjm)T为第j个隐藏层神经元与输出层神经元之间的权重.
(19)
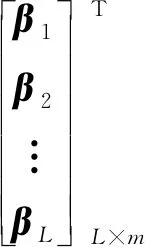
将式(18)和式(19)以矩阵的方式表达为
Hβ=T
(20)
(21)
(22)
式中:H为隐藏层的输出矩阵;T为期望输出向量;β表示隐藏层神经元与输出层神经元之间的权向量[25-26],可表示为
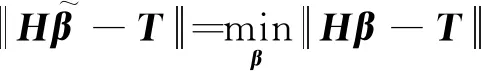
(23)
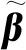
(24)
式中:H†为隐藏层输出矩阵H的Moore-Penrose广义逆矩阵.
在各种实际运行条件下,V-I测量数据中不可避免地存在噪声,这通常会导致MhAs参数辨识不理想甚至出现严重错误.因此,需要通过改变输入层和隐藏层神经元之间的权重,即对随机初始化的权重进行一定范围的限制以强化泛化能力并降低过拟合的情况.随后,对比多种范围限制的结果,选择对原始数据拟合效果最好的一组,进而实现ELM减少或滤除噪声.
2.2 PEMFC参数辨识
基于ELM-MhAs的PEMFC参数辨识过程主要包括数据采集、数据预处理和参数辨识3个部分,如图3所示.首先,收集PEMFC的V-I测量数据,并传输到ELM.然后,利用ELM训练测量V-I数据,进行数据预处理.最后,运用MhAs进行一系列的全局搜索和局部探索,根据处理后的数据精确辨识出PEMFC模型参数.ELM-MhAs详细执行步骤如下.其中:Np为初始种群大小.
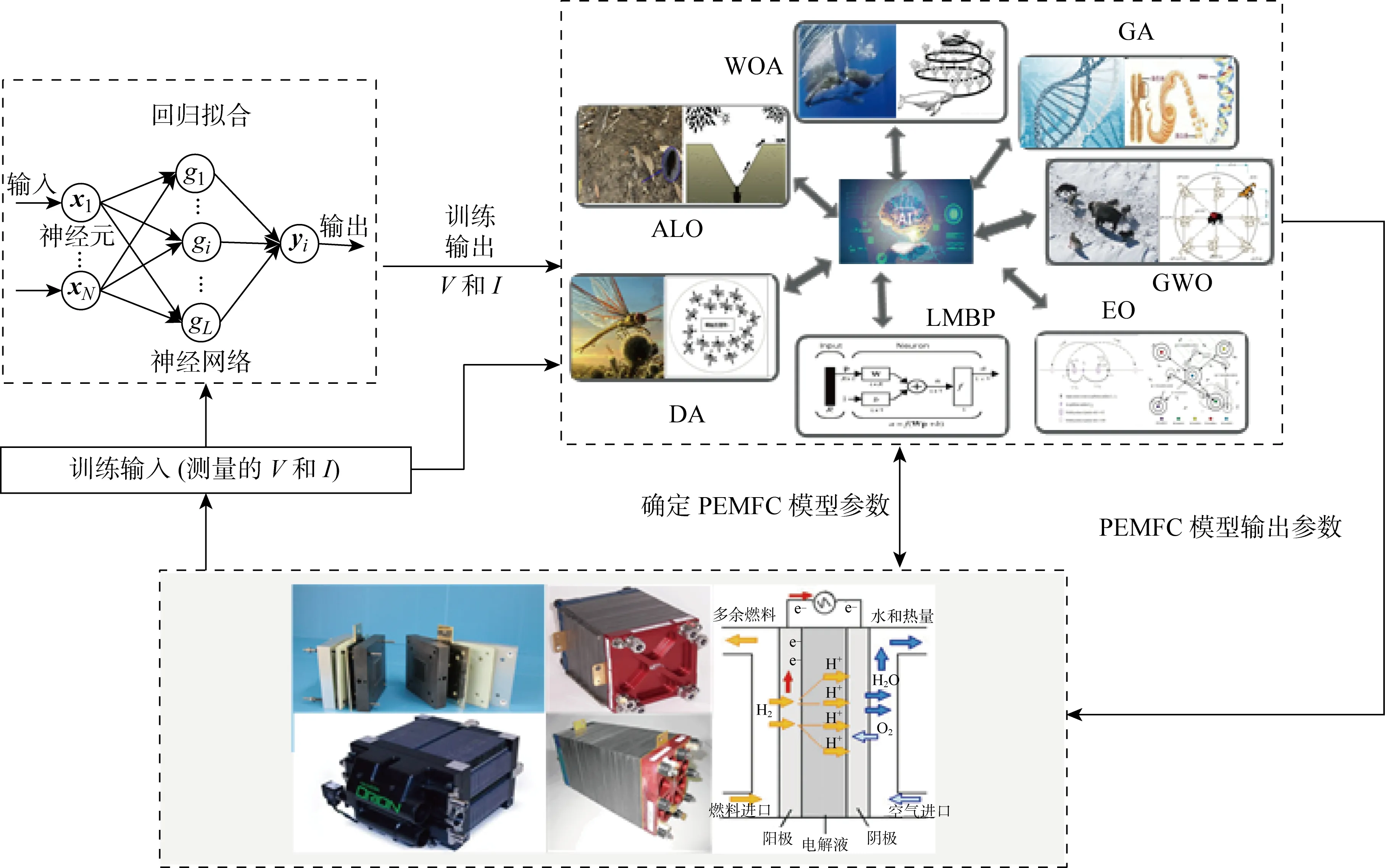
图3 PEMFC基于ELM算法的参数辨识总体框架

算法1:ELM-MhAs的实现步骤
步骤1: 构建PEMFC模型;
步骤2: 采集PEMFC的V-I数据;
步骤3: 使用ELM对V-I数据进行训练;
步骤4: 初始化MhAs参数;
步骤5: 设置t=0;
步骤6: WHILEt≤tmax
步骤7: FOR1p=1
步骤8: 通过式(16)计算第p个个体的适应度值;
步骤9: END FOR1
步骤10: 根据每个个体的适应度值来调整其角色;
步骤11: FOR2p=1:Np
步骤12: 基于第p个个体搜索规则更新解;
步骤13: END FOR2
步骤14: 设置t=t+1;
步骤15: END WHILE
步骤16: 输出PEMFC全局最优参数.
需要说明的是,目前燃料电池参数辨识研究忽视了客观存在的数据噪声带来的干扰,绝大部分PEMFC参数辨识的研究没有运用相应策略进行滤波降噪处理,且仅采用单一启发式算法进行参数辨识[4].ELM作为一种成熟的人工神经网络策略,能够很好地减少或滤除数据噪声,具有较强的泛化能力,因此其应用不局限于对燃料电池数据的处理.
3 算例分析
温度、阴极和阳极气体相对湿度对PEMFC的V-I曲线和参数都有影响.因此,在低温Tk=333.15 K、低相对湿度Hr,a=50%和Hr,c=50%以及高温Tk=353.15 K、高相对湿度Hr,a=100%和Hr,c=100%条件下,运用6种MhAs(ALO[14]、DA[14]、EO[15]、GA[9]、GWO[10]、WOA[11])和LMBP[17,28]进行PEMFC的7个参数(ε1、ε2、ε3、ε4、b、λ和Rc)辨识.同时,为提高效率和准确性,对参数边界条件进行限制[10],如表1所示.值得注意的是,目前绝大部分燃料电池数据采集主要依赖于测量精度为mV的数据采集系统[29].由于电池内部环境复杂,采集的信号不可避免地会受到一些噪声等高频信号的干扰,故用信号调理电路对这些信号进行处理[30],但技术的限制使得当前精度的信号调理电路无法完全滤除这些干扰信号[31].为增强研究的实用性和准确性,目前多用白噪声数据模拟这些噪声信号.从Ballard-Mark-V PEMFC中取25组V-I数据[32]作为无噪声的原始数据,并设置随机独立分布3 mV级别的白噪声以获取噪声数据,电池膜厚 178 μm,有效面积为50.6 cm2.

表1 PEMFC参数辨识的范围[10]
特别地,BRNN和ELM都属于ANN技术,BRNN具有良好的学习能力和降噪效果,其性能已在文献[16]中充分验证.在后续PEMFC研究中发现ELM降噪处理精度更高,能够处理更小的噪声数据,故采用BRNN和ELM进行滤波降噪效果的对比研究.此外,亦在SOFC研究中运用神经网络训练端到端参数辨识模型LMBP[28],并充分验证其稳定性、准确性和效率.因此,为区别于MhAs对PEMFC的参数辨识,采用LMBP与MhAs进行对比研究.
基于BRNN和ELM两种降噪策略实现数据噪声的处理,并结合上述7种算法进行已降噪和未降噪数据的参数辨识;最后,综合比较基于BRNN和ELM降噪下各算法参数辨识的结果和最小RMSE,以充分验证ELM-MhAs辨识参数的良好性能.
为确保所有算法在相同条件下运行,设置最大迭代次数kmax=120、初始种群Np=40,均独立运行15次.仿真在2.9 GHz IntelRCoreTMi7 CPU和16 GB RAM配置的个人计算机上运行,模型利用MATLAB/Simulink2019a搭建.
3.1 低温、低相对湿度
表2为无降噪处理、BRNN以及ELM降噪处理下7种算法的最优参数辨识结果和最小RMSE,其中符号‘N’表示无降噪处理,‘B’表示由BRNN降噪处理,‘E’表示由ELM降噪处理(最优值加粗表示,后同).从表中可以看出,降噪处理后各算法得到的RMSE要明显小于无降噪处理的RMSE;相比于BRNN降噪,ELM降噪后参数辨识精度更高,性能更优良.例如,相较于无降噪和BRNN降噪处理后算法的准确性,ELM降噪处理后ALO准确性分别提高22.03%和2.72%,GWO准确性分别提高24.80%和21.68%,EO准确性分别提高52.63%和58.80%,DA准确性分别提高0.82%和6.63%,LMBP准确性分别提高4.81%和14.07%.
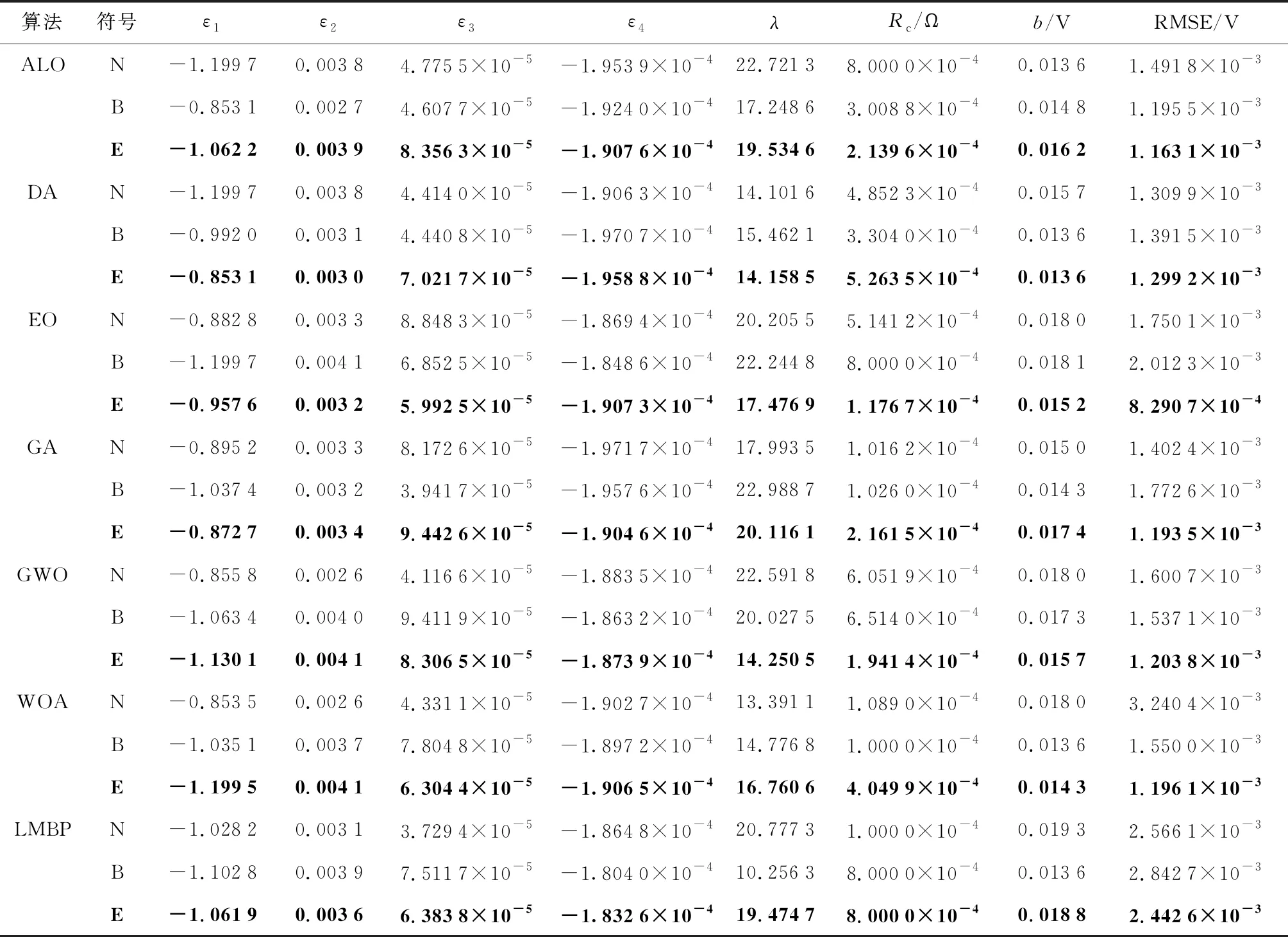
表2 低温低相对湿度下的参数辨识结果
图4给出不同数据在低温、低相对湿度下的极化拟合曲线.由图可知,数据噪声对原始数据干扰性较强,导致偏差较大,数据重合点较少;而ELM和BRNN降噪数据与原始数据重合点多,表明降噪技术能实现更好的数据拟合.其中,ELM降噪数据的拟合情况优于BRNN降噪数据,证明ELM能够更有效减少或滤除噪声,使数据更准确可靠.
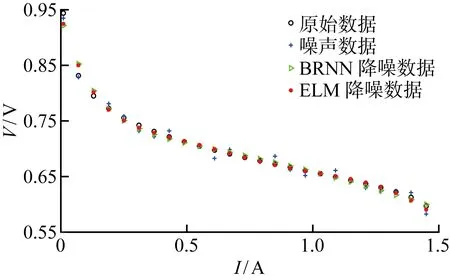
图4 低温、低相对湿度下的数据拟合
图5为各算法分别基于无降噪、BRNN降噪和ELM降噪进行15次独立参数辨识后的RMSE.大部分基于BRNN降噪的RMSE均大于基于ELM的RMSE,表明ELM-MhAs能找到更好的全局最优解,从而更准确、稳定地实现PEMFC的参数辨识.由图可知,ELM降噪处理后,DA的RMSE约为无降噪处理的40%,BRNN降噪处理的35%,算法的准确性和稳定性显著提高.
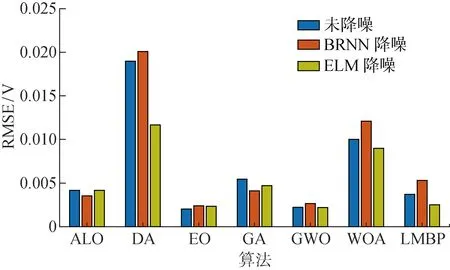
图5 低温、低相对湿度下7种算法的RMSE
图6为7种算法的箱形图.由图可见,经过BRNN和ELM降噪处理后,大部分算法的误差及分布范围明显减小.特别地,ELM降噪后所有算法的RMSE波动范围更小,异常值也更少,进一步验证ELM降噪处理能够增强算法在参数辨识中的全局搜索能力和寻优稳定性.例如,ELM-DA较DA和BRNN-DA误差分布范围显著减小,ELM-LMBP较LMBP和BRNN-LMBP整体误差减小且剔除异常值.
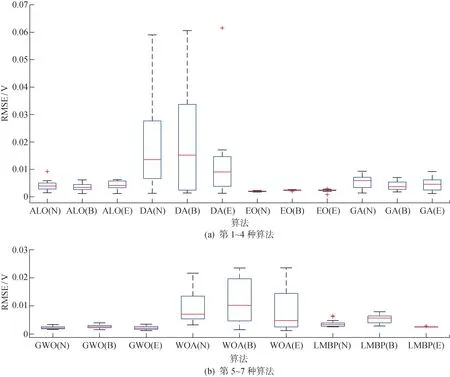
图6 低温、低相对湿度下7种算法的箱形图
图7给出所有算法在无降噪处理和两种降噪策略处理后的收敛曲线.图中:k为迭代次数.由图可知,经过BRNN或ELM降噪处理后,算法在迭代后期能较为稳定地进行参数寻优,而未降噪处理的算法受数据噪声干扰大,误差波动大,难以趋于平稳.对比BRNN和ELM降噪处理后的收敛曲线,ELM降噪策略保证更多算法只需更少的迭代次数就能辨识到高准确性的参数,进一步验证ELM-MhAs辨识参数的稳定性、精确性和快速性.
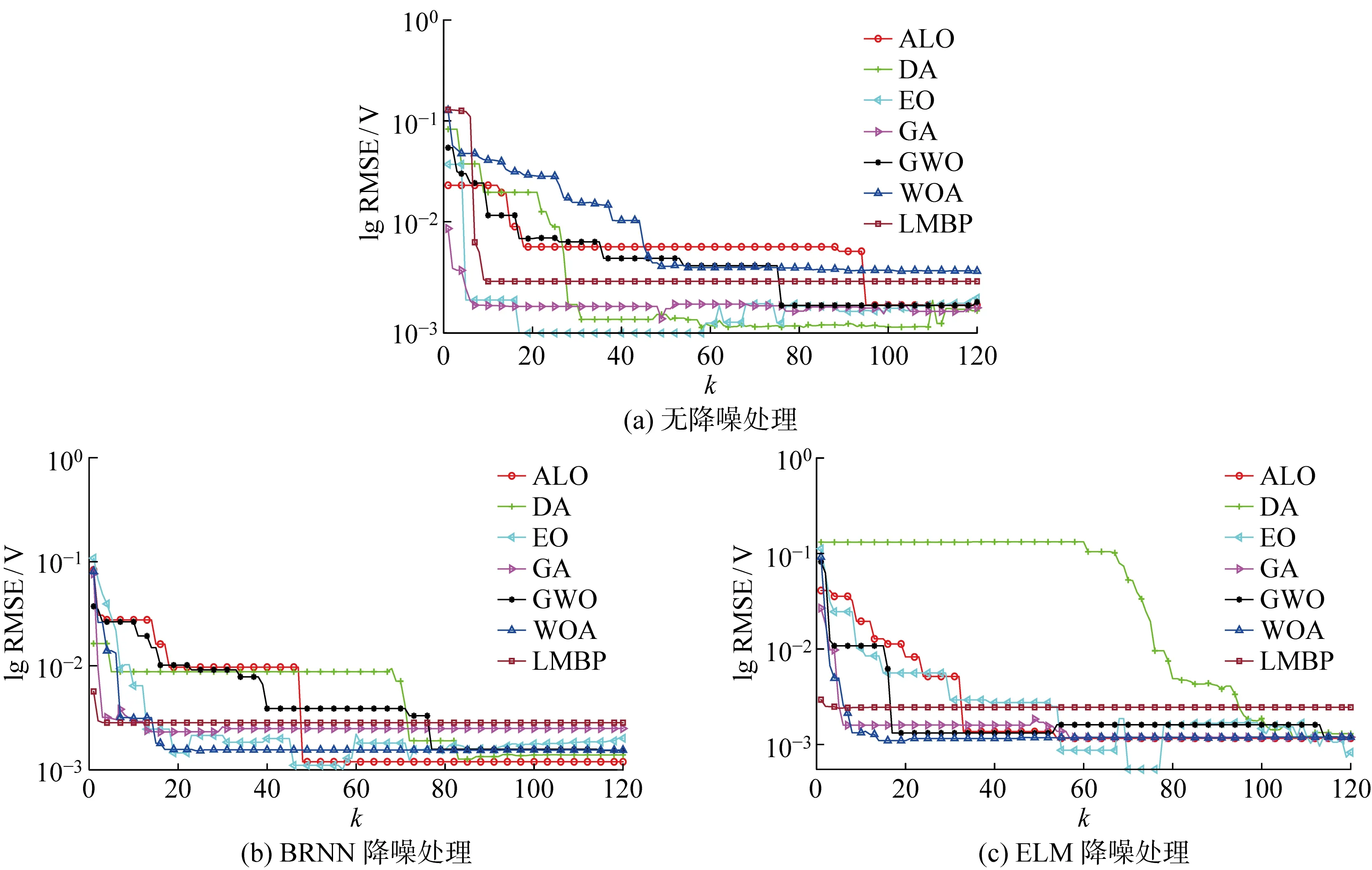
图7 低温低相对湿度下7种算法收敛曲线
3.2 高温、高相对湿度
6种MhAs和LMBP最优参数辨识结果和最小RMSE如表3所示.从表中可以看出,相较于基于BRNN和ELM降噪策略的算法,无降噪处理算法的最优参数辨识误差更大,精确性不足.对比两种降噪策略,ELM降噪后ALO、EO、GA、GWO、WOA和LMBP共6种算法得到的RMSE比BRNN降噪的RMSE更小,表明ELM能够显著提高数据噪声干扰下各算法的全局搜索能力并降低陷入局部最优解的概率,从而实现更高精度的参数辨识.例如,ELM-GA的准确性较GA和BRNN-GA分别显著提高43.84%和42.74%;ELM-ALO的准确性较ALO和BRNN-ALO分别显著提高22.75%和15.50%;ELM-LMBP的准确性较LMBP和BRNN-LMBP分别显著提高44.95%和2.27%.
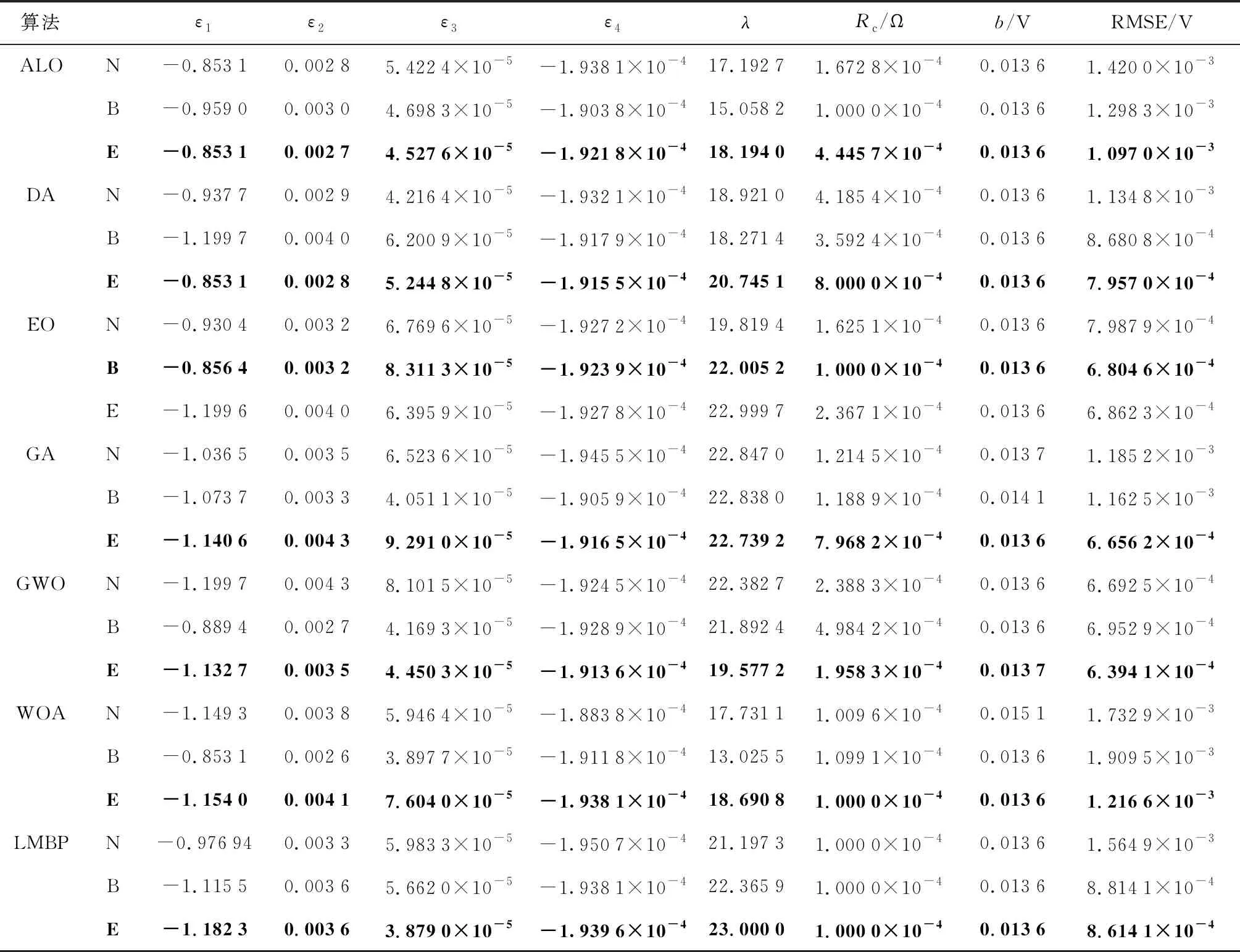
表3 高温、高相对湿度下的参数辨识结果
高温、高相对湿度下,4种数据的拟合对比如图8所示.由图可以明显看出,相较于无降噪处理和BRNN降噪处理的数据,ELM降噪处理的数据与原始数据重合点多,数据偏差小,拟合效果优良.进一步验证ELM降噪策略能显著减少数据中的噪声,使拟合数据更为理想.
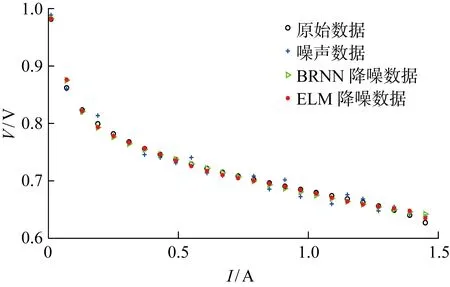
图8 高温高相对湿度下的数据拟合
图9给出7种算法在无降噪以及两种降噪策略处理下独立运行15次的RMSE对比.由图可见,经过BRNN或ELM降噪后,所有算法的RMSE都较未降噪处理算法的RMSE更小.其中,基于ELM策略得到的参数辨识误差较BRNN更小,ELM-MhAs能获得更好的全局最优解.ELM降噪算法较BRNN降噪算法性能优化程度最好的为WOA,其次为DA、GA、GWO、LMBP、ALO以及EO.
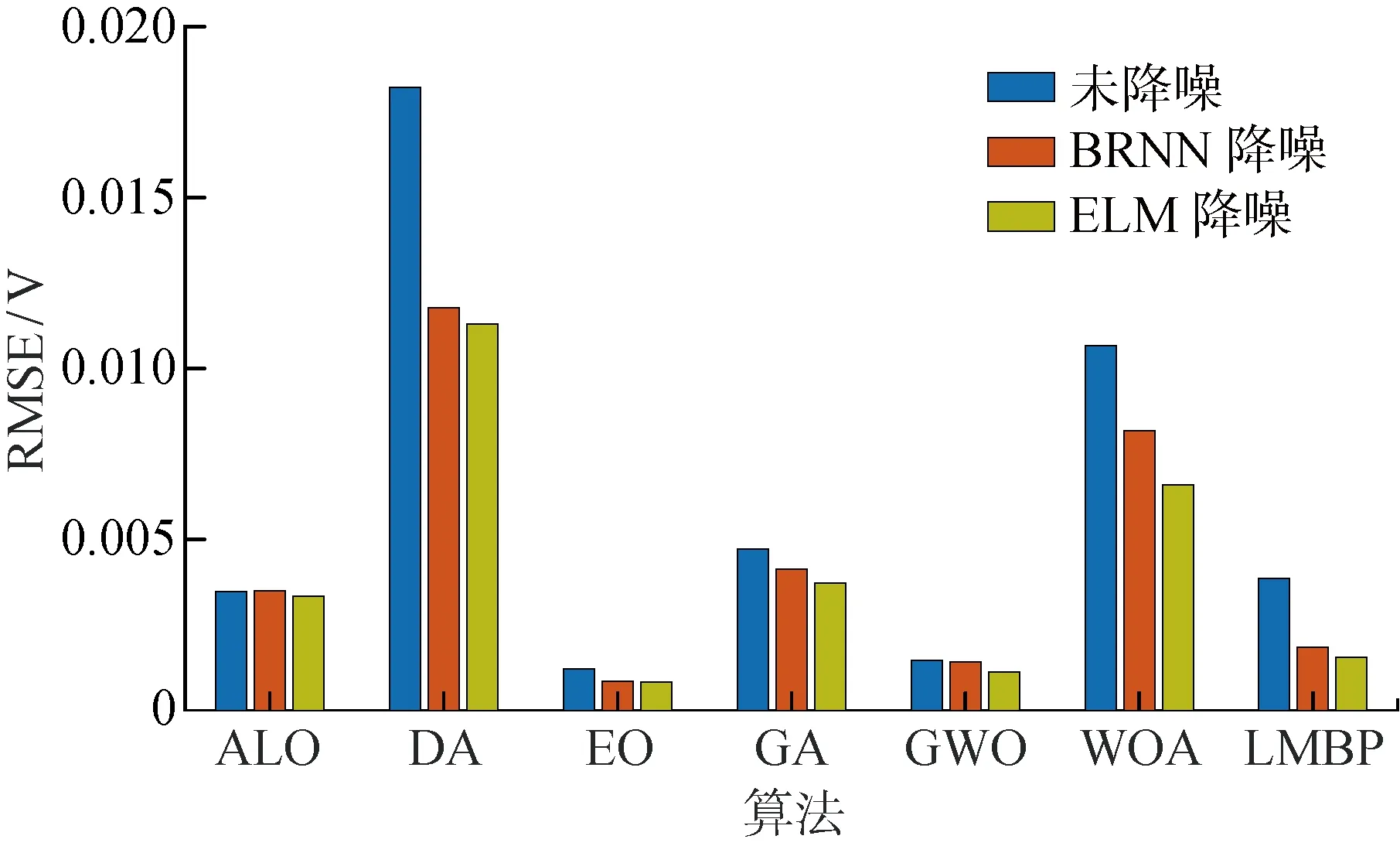
图9 高温、高相对湿度下7种算法的RMSE
7种优化算法独立运行15次的误差箱形图如图10所示.可以看出,利用噪声数据进行辨识的误差和误差波动范围皆大于降噪数据的误差和误差波动范围,说明引入降噪技术能够切实减小数据噪声的干扰,从而提高辨识参数的精度.此外,基于ELM降噪处理的各算法误差区间远小于基于BRNN降噪处理的误差区间,且异常值亦更少.例如,ELM-LMBP的误差上下限小于BRNN-LMBP的误差上下限,并且ELM-LMBP辨识PEMFC参数的稳定性和精确性也进一步提升.
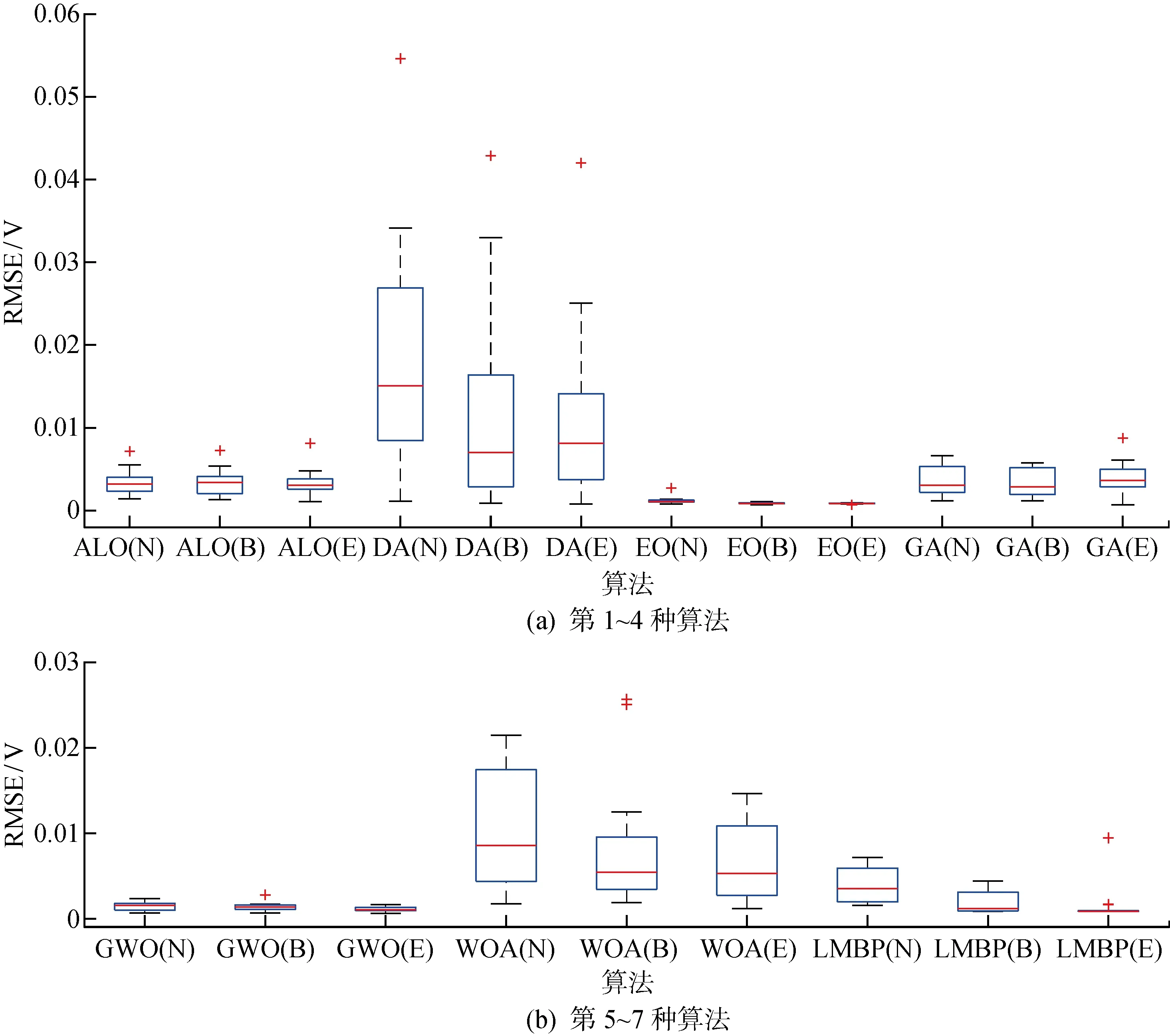
图10 高温、高相对湿度下7种算法的箱形图
图11(a)、11(b)和11(c)分别为基于无降噪、BRNN和ELM降噪处理下7种算法迭代120次的收敛曲线.对比3组迭代收敛曲线,可以看出基于噪声数据算法比基于降噪数据算法的迭代收敛RMSE更大,寻优收敛速度更慢.从图11(b)和11(c)可知,ELM降噪处理后,各算法的收敛速度更快,收敛误差更小,能够更好地平衡局部探索和全局搜索,不容易陷入局部最优解.其中,WOA算法的性能得到显著优化,BRNN-WOA约迭代55次收敛,ELM-WOA只需迭代7次即可收敛且其RMSE小于BRNN-WOA的RMSE.
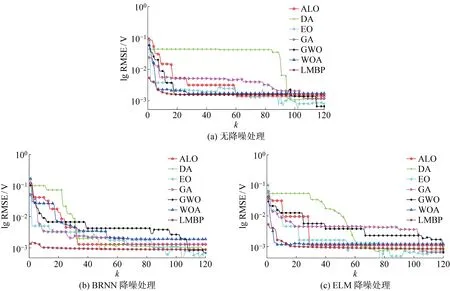
图11 高温高相对湿度下7种算法收敛曲线
4 结论
针对PEMFC提出一种基于ELM降噪处理的MhAs参数辨识策略,其贡献可概括为以下4个方面:
(1) 充分考虑数据噪声对PEMFC参数辨识精度的影响,引入降噪技术以获得更准确的V-I数据,从而提高电化学稳态建模的精确性.
(2) 相较于单一MhAs策略,ELM-MhAs策略能够显著减少数据噪声对辨识参数的干扰,保证更有效、可靠的全局搜索和局部探索,具有高准确性、快速性和鲁棒性.
(3) 全面综合地比较基于ELM-MhAs策略和BRNN-MhAs策略的参数辨识结果.算例研究表明,ELM降噪后获得的辨识精度、收敛稳定性和快速性皆优于BRNN降噪.例如,低温、低相对湿度情况下,ELM-EO参数精确性最多提高58.80%;高温、高相对湿度情况下,ELM-GA准确性最多提高42.74%.
(4) 对比神经网络训练端到端参数辨识模型LMBP与6种MhAs算法的PEMFC参数辨识结果.算例研究表明,在低温、低相对湿度情况下,ELM-LMBP参数精确性较LMBP和BRNN-LMBP精确性分别提高4.81%和14.07%,优化精度高于ELM-DA增加的0.82%和6.63%;在高温、高相对湿度情况下,ELM-LMBP参数精确性较LMBP和BRNN-LMBP精确性分别提高44.95%和2.27%,优化精度高于ELM-ALO增加的22.75%和15.50%.
ELM-MhAs具有普遍适用性,不受模型限制.未来可将其应用于光伏电池、固体氧化燃料电池等其他参数辨识问题.
