无监督数据集子类划分的人脸口罩佩戴识别算法
2023-05-05向富贵冯绍玮吕明鸿姜小明
向富贵,冯绍玮,王 添,吕明鸿,姜小明
(重庆邮电大学 生物信息学院,重庆 400065)
0 引 言
2019年以来受新型冠状病毒疫情的影响,为实现联防联控,降低疫情传播和复发的风险,专家建议人们疫情期间出行佩戴口罩,戴口罩对疫情的防控作用也越来越被人们重视。规范佩戴口罩可以有效地防范有害的气体、气味、飞沫及病毒等通过空气扩散而侵入人体。规范佩戴口罩在保护其他人的同时,也可以保护佩戴者,减少佩戴者所接触的病毒的接种量,使得病毒感染风险更低。当前针对佩戴口罩的监测主要还是通过人工检测,高精度实时的口罩佩戴检测系统较少,且缺乏对是否规范佩戴口罩的检测。
现有针对口罩佩戴情况的检测主要是基于深度学习的目标检测,目标检测主要分为两阶段检测网络和单阶段检测网络。两阶段检测网络主要有Faster RCNN[1],R-FCN[2]和FPN[3]等,该类方法需要在特征提取之后,对候选区域进行进一步的处理,然后通过分类和回归进行目标的识别和定位,检测速度相对较慢;单阶段检测网络主要有YOLOv3[4],YOLOv4[5],RetinaNet[6],EfficientDet[7]等,此类方法通过对目标进行规则的密集采样提取特征,在生成区域建议的同时进行分类和回归,结构变得更加简洁,检测速度相对较快。针对口罩佩戴检测的精度和速度提升,学者们做了大量的工作。现有的口罩佩戴检测的算法主要检测是否佩戴口罩。百度基于PyramidBox[8]实现的口罩佩戴检测应用,在某些情况下识别准确率可达到80%~90%。文献[9]提出了一种面部-眉毛多粒子面罩人脸识别模型,对数据集的识别精度达到95%,在达到高检测精度的同时,检测速度较慢。其他学者改进RetinaFace[10],YOLOv4[11]等网络,提升了口罩佩戴检测的精度和速度。现有的口罩遮挡人脸视频检测方法主要关注于检测是否佩戴口罩,这导致很多不规范佩戴口罩的情况也会被识别为佩戴口罩,并不能很好地起到辅助监督的作用。文献[12]通过YCrCb的椭圆肤色模型对人脸佩戴口罩区域进行肤色检测,根据口和鼻周围皮肤的暴露情况判断目标是否规范地佩戴口罩,该方法由于引入了较大的检测网络结构影响了网络的检测速度,且因为皮肤的暴露情况很难度量,使得网络的检测精度较低。百度基于PyramidBox实现的口罩检测将不规范佩戴口罩识别为不佩戴口罩,且许多不规范佩戴口罩的情况无法被识别。针对不规范佩戴口罩的检测方法需要进一步地完善,更好地为疫情防控服务。
实际应用场景存在对实时口罩佩戴情况的细粒度检测需求,考虑数据集的类内差异较大,如不规范佩戴口罩数据包含露鼻子、露嘴、正脸和侧脸等情况,为了减少数据集的类内差异,使得网络训练时更加收敛,采用聚类的思想对数据集进行子类划分[13]。人工划分数据集子类需要很大的人力成本和预算开销,不能保证人为划分的子类之间的差异符合网络提取特征的需求。基于此,提出对现有的人脸数据集进行无监督分类。无监督分类方法采用近邻语义聚类[14](semantic clustering by adopting nearest neighbors,SCAN)。该方法改进了基于深度学习和传统聚类融合的方法,将传统聚类方法替换为能够聚类高级语义特征的聚类方法。针对SCAN聚类后的子类可能含有一些划分错误的噪声数据的情况,引入Co-teaching网络[15]进行标签校正,减少数据集中的噪声数据,提高标签分配的准确性。
针对口罩佩戴检测网络对检测速度和检测精度的需求,由于单阶段检测网络YOLOv3检测速度快,在目标检测任务中应用广泛,而后续的改进版本和其他网络引入了较多的网络结构,在提升网络多尺度检测性能的同时,降低了检测速度,所以选择YOLOv3来完成实际口罩佩戴情况检测任务。考虑到实际口罩佩戴检测时,主要应用到入口、通道等小场景,检测的目标集中在大中尺度,而YOLOv3专注于对小目标检测性能的提升,对大中尺度的检测性能下降。因此,调整了YOLOv3网络结构,使网络专注于检测大中尺度的目标。网络缺少对细粒度特征的提取,会导致通用网络无法被充分利用[16]。为了提升网络对不规范佩戴口罩和规范佩戴口罩这种类间差异较小的数据类别的分类能力,引入注意力机制。利用注意机制处理图像分类任务,可以有效增强网络对图像细粒度特征的提取,进而提高网络的分类能力[17]。注意力机制中通道注意力机制有SENet[18],SKNet[19],ECANet[20]等;空间注意力有STN[21],DCN[22]等;空间和通道注意力机制有CBAM[23]等。由于ECANet可以直接插入主干网,无须引入大量的网络分支,只需消耗少量的计算资源,最终选取ECANet来提升网络性能。
改进的网络称为YOLOv3_Sim(Simple YOLOv3),自动子类划分后的数据集通过改进的网络进行训练后得到的模型,能有效地提升口罩佩戴情况的检测速度和精度。本文的贡献如下。
1)为解决数据集类内差异较大,不易收敛的问题,提出了一种无监督数据集子类自动划分方法;
2)针对口罩实际应用时主要检测大中尺度的目标的情况,去除了YOLOV3小尺度检测的网络层;
3)为提升网络细粒度分类能力,在改进的YOLOV3网络的主干网中嵌入ECANet结构。
1 数据集的创建
通过网上搜集、实验室内部志愿者帮助、素材征集等方式采集数据10 000余张,其中规范戴口罩数据4 000余张,不规范戴口罩数据2 000余张,不戴口罩数据4 000余张。根据口罩的实际佩戴情况,将数据集分为3类,即不戴口罩(non-wearing mask)、不规范戴口罩(wrong way wearing mask)和规范佩戴口罩(standard wearing mask)。标签分别为Nomask,Wrmask和Swmask。
首先对收集到的图片数据进行统一尺寸的处理。这样处理是为了避免训练时图像较大增加额外的计算量,便于训练。然后,按照VOC数据集[24]的格式,标记3种类型的数据集面部区域并添加标签,所有的数据都是真实的人脸口罩佩戴情况的图像,如图1所示。

图1 三类数据集的标签样例Fig.1 Annotation examples of three classes of data sets
2 数据集子类划分方法
通过引入无监督的图像分类方法,实现数据集的子类划分,流程图如图2所示。在数据集处理速度上与人工子类划分方法相比具有明显的优势。人工方法直接按照特定的标准进行划分,无监督数据集子类划分通过SCAN方法划分出网络特征更加相似的子类,通过Co-teaching方法减少噪声标签,实现了数据集的自动子类划分。

图2 数据集子类划分方法流程图Fig.2 Flowchart of data set subclass division method
2.1 人工子类划分方法
人工子类划分方法以数据中肉眼可辨别的特征为依据,人为将单个类别划分为2个子类,如图3所示。不规范佩戴口罩这一类数据集,可以根据鼻子和嘴的遮挡情况,将其标签手动重新标记为露鼻子或者嘴和鼻子和嘴均露出这2个子类,即Wrmask0和Wrmask1,在实际训练时,将三类数据均按照正脸和其他情况划分为两类。

图3 不规范佩戴口罩子类划分的标签样例Fig.3 Example of a label subclass of non-standard mask wearing data
实际检测中面临的情况十分复杂,人工划分不一定能够准确地提取出对适合神经网络做出一致性判别的特征,如网络可能会检测到侧脸和正脸的差异,也可能会检测到仅露鼻子与鼻子和最均露出的差异。同时,人工划分数据集需要耗费大量的时间。
2.2 自动子类划分方法
自动子类划分方法首先通过无监督分类将数据集中的单个类别划分为多个子类。这个任务可以通过聚类分析实现,即通过寻找数据之间的相似性,对数据进行分组。类似K-means聚类方法,SCAN方法通过神经网络训练提取数据中的特征,利用特征间的相似性来聚类数据。
SCAN方法的算法流程分为3个部分,第1部分是通过一个替代有监督学习中分类先验的任务来学习数据的特征表示。该任务基于特征相似性来挖掘每幅图像的最近邻居,即
minδ(Iδ(x),Iδ(Ax))
(1)
(1)式中:δ表示网络参数;Iδ表示带参数的神经网络;x表示图像数据;Ax表示图像数据的增强数据或相似数据。通过学习一个神经网络,提取图像的高级语义特征,聚类具有相似特征的增强数据和其他图像数据作为邻居先验。因为替代任务的输出以图像为条件,会迫使Iα从其输入中提取特定信息;同时,由于Iα的容量有限,它必须从输入的信息中剔除对任务没有太大关系的语义信息,所以具有相似高级特征的图像会被更紧密地映射在一起。

(2)
第3部分通过self-labeling[25]方法,首先从第2部分训练后的网络获取的高置信度预测(pmax≈1)的样本中,通过定义一个阈值,筛选出置信度大于阈值的样本,获得伪标签,然后计算交叉熵损失来更新参数。为了避免过拟合,不断地添加超过阈值的样本作为输入,迭代有限次后结束,分类结果得到多个类别的伪标签。
由于SCAN方法在对数据集进行聚类时,不可避免地会出现一些错误聚类的数据。在神经网络训练中,若数据集中包含有噪声标签,将会影响最终结果的判别,使得最终训练出来的网络泛化性能差,这种现象并不会随着训练优化或网络架构的选择而改变[26-27]。故通过Co-teaching方法清洗数据集中的噪声标签。Co-teaching方法的算法示意图如图4所示,交替训练2个对等带参神经网络Wf和Wg,f和g表示权重参数。每次迭代时打乱训练数据集;然后分批次导入训练数据及标签,对于每一个批次,2个网络同时计算每个数据的二元交叉熵损失并由大到小排序,设定一个百分比阈值,通过阈值剔除损失较大的部分数据,剩下的数据交叉输入到对等网络进行训练,由于深度网络的权重具有记忆性[27],当噪声数据流到对等网络时,通过设计特定阈值可以判断标签是否为噪声。

图4 Co-teaching算法示意图Fig.4 Co-teaching algorithm schematic diagram
3 检测网络
针对口罩佩戴检测中对检测速度的需求,提出了YOLOv3_Sim检测网络。目标网络改善了YOLOv3网络结构,使得网络集中检测大中尺度的目标,通过在主干网引入注意力机制模块ECANet,提升了网络的细粒度分类能力,网络更加简洁高效。
原始的YOLOv3的网络结构如图5所示,主干网采用Darknet-53,首先将训练样本集中的图像输入到主干网络进行多尺度变换,提取多尺度分类和定位特征,通过主干部分提取三层不同尺度的特征进行特征融合;后一特征层通过反卷积和上采样调整到与前一特征层一样大小;然后与前一特征层进行拼接,这样3个不同尺寸的特征层之间信息可以更好地联系起来,通过从早期特征图获得小尺度的信息进行卷积处理可以获得相同特征不同尺度的张量;最后,网络通过提取的位置和类别特征对目标进行分类和回归。每个特征层分配3个尺寸的检测框,得到9个尺寸的检测框,大小分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。

图5 YOLOv3网络结构Fig.5 YOLOV3 network architecture

图6 ECANet结构Fig.6 ECANet structure
ECANet模块结构如图6所示,在不降维的情况下使用全局平均池化聚合卷积特征后,首先自适应确定核大小k,并进行一维卷积,然后通过sigmoid函数学习通道注意力。
实际检测任务中,检测目标集中在大中尺度。YOLOv3_Sim在YOLOv3基础上删减了对较小尺度的检测层,通过利用在主干部分获得的最后2个有效特征层,进行特征融合,结合2个不同尺度的特征信息,网络专注于预测大中尺度的目标,结构更加简洁。图7给出了改进的YOLOV3_Sim的最终网络结构。在骨干网中引入了ECANet模块,提升网络的细粒度分类能力。

图7 改进的YOLOv3_Sim网络结构Fig.7 Improved YOLOv3_Sim network architecture
4 实验结果与分析
实验分别随机选取不规范佩戴口罩、规范佩戴口罩和不佩戴口罩数据各600张进行训练。本实验使用Pytorch深度学习框架,通过Python语言实现。网络模型的训练在服务器进行,系统为Ubuntu 18.04,通过GPU来加速网络的训练,硬件环境为Intel(R) Xeon(R) Gold 6148 CPU @2.40GHz、Tesla V100-PCIE、显存32 GByte。训练后的模型统一在Windows系统的笔记本电脑上进行测试,电脑硬件环境为Intel(R) Core(TM) i7-8750H CPU @2.20 GHz、GeForce GTX 1060 Ti、显存6GB。
4.1 YOLOv3_Sim网络检测结果
实验一采用未子类划分的数据集,通过YOLOv3_Sim进行训练。实验中训练集与测试集比例为5:1,图像在输入时均被等比例调整为416×416大小,如图8所示,通过K-means方法为数据集重新分配了9个不同尺寸的边界框,在较小尺度的目标较少,取较大的6个边界框来预测不同尺度的人脸图像,检测框分别为(70×60),(72×138), (104×92),(112×222),(148×136),(227×270)。
训练前导入骨干网络在图像数据集ImageNet[27]上运行得到的预训练权重,训练时首先冻结主干网参数,然后解冻更新整个网络参数,选取损失函数值较小且检测精度最高的权重进行测试。对比了原始的YOLOv3网络和引入注意力机制后的网络,检测结果如表1所示,FPS指每秒识别的画面数。可以看出,两阶段检测器Faster RCNN、单阶段检测器SSD、RetinaNet和YOLOv4的检测精度较高,但检测速度较慢。大中尺度的检测任务中,引入ECANet的YOLOv3_Sim网络比原始的YOLOv3和YOLOv4检测精度更高,检测速度更快。

表1 网络训练结果对比
4.2 子类划分方法的有效性验证
实验二检测网络采用结合ECANet的YOLOv3_Sim网络,首先人工将每一类数据划分为2个子类,划分标准为正脸和侧脸,然后与不进行数据集子类划分之前的数据集训练的检测结果进行对比,测试时,将检测的同一子类的标签归类为主类标签。
人工子类划分前后的数据集通过YOLOv3_Sim网络训练,测试集检测结果分别如图9和图10所示,人工子类划分后3个类别的误检率明显降低,表2列出了子类划分前后网络对各个类别的检测精度,可以看出,进行子类划分后,3个类别的检测精度均有提升。

图9 人工子类划分前测试数据正负样本统计Fig.9 Positive and negative sample statistics of test data before artificial subclass division

图10 人工子类划分后测试集正负样本统计Fig.10 Positive and negative sample statistics of test data after artificial subclass division
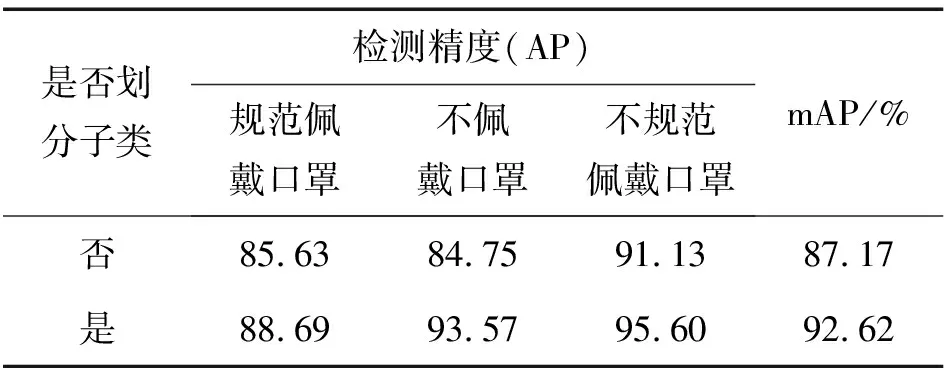
表2 子类划分对目标检测的影响
4.3 自动子类划分
实验三在无监督自分类方法SCAN中引入Co-teaching方法,在数据子类划分后进行噪声标签调整,得到自动子类划分后的子类数据集进行训练。实验中,输入图像调整为100×100大小,为了使得对等网络的参数不同,对网络的参数进行随机初始化。数据集每一类均划分为2个子类,根据噪声标签调整后的结果得到各类数据的子类数据集标签,然后进行目标检测训练,对比YOLO系列网络的检测结果。
YOLO系列网络检测结果如表3所示。通过自动子类划分后的数据集训练的各个模型,检测精度均有提高,引入ECANet的YOLOv3和YOLO_Sim的细粒度分类能力得以体现,检测精度分别提升了10.07%和5.95%。YOLOv3_Sim模型的平均检测精度达到93.12%,检测速度优于YOLOv3。FPS和mAP检测结果可视化对比图如图11所示,可以直观地看出,在引入ECANet后,YOLOv3_Sim损失了一定的检测速度,细粒度分类能力提高,检测精度提升,检测结果优于通过人工子类划分方法得到的数据集进行训练的模型的检测结果。

表3 自动子类划分的YOLO系列网络检测结果

图11 自动子类划分前后各网络模型FPS和 mAP结果对比图Fig.11 Comparison of FPS and mAP results of each network model before and after automatic subclass division
4.4 实际检测结果
图12给出了结合数据集自动子类划分后的YOLOv3_Sim(ECA)与原始YOLOv3的实际检测结果对比图,可以看出,改进前,YOLOv3对口罩佩戴情况的识别出现了误检和漏检现象,原本设计良好的网络的性能没有被充分利用,改进后的YOLOv3_Sim(ECA)网络结合自动子类划分方法能够更好地完成口罩佩戴检测任务,漏检和误检较少,对规范佩戴口罩、不规范佩戴口罩和不佩戴口罩检测精度较高。
5 结 论
为了提高口罩佩戴检测的速度和精度,提出了一种基于数据集子类划分和YOLOv3_Sim的检测方法。通过改进无监督分类算法,提出了数据集自动子类划分方法,生成更精确的子类标签。将ECANet结构嵌入到YOLOV3网络中,增强了网络相邻通道之间的联系,提高特征提取能力和对不容易识别的目标的评分,以获得更高的精度和召回率。为了使算法更加适用于检测大中尺度的目标,预测层的宽度改变,尺度数量减少,网络检测速度提升。通过主干网提取的后2个尺度的特征层进行预测,网络对大中尺度的目标的检测精度显著提高。引入数据集自动子类划分方法训练的YOLOv3_Sim网络,口罩佩戴检测的速度和精度均得到了提升。

图12 改进前后的口罩佩戴情况检测结果Fig.12 Detection results of mask wearing before and after improvement
通过实验发现,网络结合ECANet后,在牺牲较少的计算资源的同时,提升了检测精度,效果较好。在单阶段检测器中,YOLOv4的检测精度比YOLOv3更高,但检测速度较慢,后续YOLO系列还更新了更高的版本,同时也出现了很多其他新的模型。由于实际任务对实时和精度的需求,更为复杂的模型在精简时更加困难,未来研究工作可以结合注意力机制或其他提升网络细粒度特征提取能力的改进方法,改进YOLOv4或其他网络得到效果更好的模型。
