一种信道自适应的辐射源无监督训练与识别方法
2023-05-04张财生
王 聪,但 波,张财生
(海军航空大学, 山东 烟台 264001)
0 引言
特定辐射源识别技术是指通过接收信号的外部特征来区分辐射源个体的技术[1]。该特征是由于发射机组成器件的多种非理想特性混合在一起,导致同一型号的不同个体之间发射的信号存在细微的差异,具有一定的稳定性和唯一性,又被称为射频指纹。在军事领域,由于大量同型号的辐射源广泛部署,通过特定辐射源识别技术来区分同样型号、参数一致的军用辐射源设备,具有重要的战略和战术意义[2-3]。传统基于特征变换的辐射源个体识别技术[4-6]需要借助丰富的专家知识并且经过复杂的处理步骤才能保证特征的有效性。随着深度学习技术的飞速发展,凭借其强大的特征提取和分类能力,给特定辐射源识别技术提供了一个更高效且通用的处理框架和流程[7-9]。文献[10]将采集到的IQ数据作为输入,验证了有监督条件下,卷积神经网络可以实现对5个软件无线电设备的精确识别。
在电子侦察过程中,时常面临的是复杂多变的信号环境,即辐射源目标经过各种外部因素影响导致到达接收机的信号不是恒定不变的,其中信道的影响最大[11-12]。具体而言,包括多径、多普勒频移、带内噪声等,不同的信道会对辐射源信号造成“染色”。
为了克服信道带来的不利影响,文献[13]通过实验说明了在低信噪比条件下通过增加网络规模进行有监督训练可以提高识别精度。但是网络规模的增加必然带来较大的计算量并且需要重新训练模型。并且在实际应用中,实时采集到的大量无标签的数据难以被利用进行有监督的训练。文献[14]提出了合作通信基础上的信道校正的方法来补偿信道带来的影响,但是在实际电子侦察过程中主要面临的是非合作通信场景。
本文中基于深度学习的辐射源识别方法在信道变化时识别性能下降的问题,提出了信道自适应的特定辐射源无监督训练和识别方法,提高了识别系统的鲁棒性和可靠性,以适应实际应用中不可预测的战场情况。
1 问题描述
1.1 信号建模
根据已有的研究,通常认为辐射源的指纹特性源于发射机各器件的“非理想”特性,这会给信号带来各种“无意调制”,而这些“无意调制”是客观存在且相对稳定的,并具有一定程度的唯一性和可分辨性,因此也被认为是辐射源指纹。理想通信信号的模型可表示为:
s(t)=(ao(t)+au(t))cos[2π(fo(t)+
fu(t))t+(φo(t)+φu(t))]
(1)
式中:ao(t)、fo(t)、φo(t)分别表示理想信号的幅度、频率、相位;au(t)、fu(t)、φu(t)分别表示幅度的无意调制、频率的无意调制、相位的无意调制。
1.2 不同信道下的信号建模
在实际环境中,经过对不同信道条件下的实测信号进行分析,由于多径、多普勒频移、带内噪声的因素,会给接收到的信号附加一些非指纹的信道特征。对于同一个辐射源发出的信号,在2个不同场景下接收到的相同信号分别可以表示为:
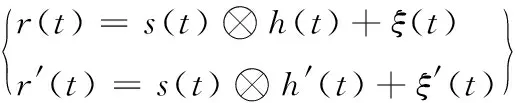
(2)
式中:h(t)为信道的冲击响应;⊗为卷积操作;ξ(t)为信道噪声。我们的目的就是在接收到的信号中突出个体指纹特征,而且尽量少的受到信道等因素的影响。
2 信道自适应的辐射源识别模型
通常在有限数据集上训练的深度学习模型泛化性比较差,这是因为基于深度学习的分类方法通常假设所有的数据都服从相同的分布。但在实际中,这种假设过于严格,用于训练的数据和测试数据由于环境的影响会存在一定的差异。这种差异会使得基于深度学习的识别方法在实际应用无法适应新数据。

我们借鉴了文献[17]中的所提出的域对抗网络的方法设计了一个适用于辐射源个体识别的训练和识别模型。通过在训练中对得到的特征加以约束,提升模型在目标域数据集上的适应能力。如图1所示,本模型主要包括特征提取模块、分类模块和信道判别模块。下面逐一进行详细介绍。
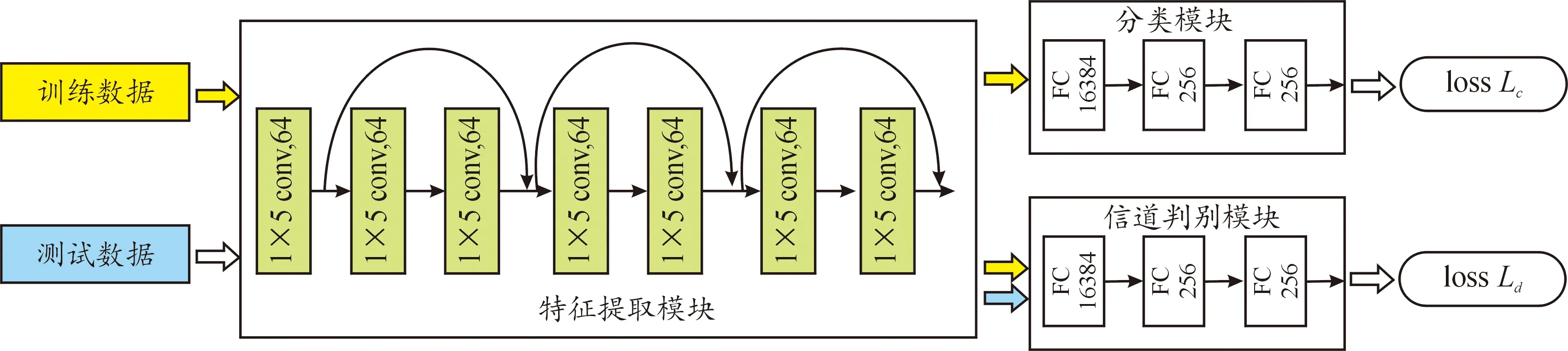
图1 网络结构示意Fig.1 The network architecture
2.1 特征提取模块
特征提取模块主要功能是对输入数据进行特征提取。改进于经典ResNet18结构[18]的残差网络部分,共由4个部分组成。模块的第一部分由卷积层、批归一化层和Leaky Relu激活层组成。后续第二至第四部分是3个相同的残差块。每个残差块包括2个计算单元,每个计算单元都是由卷积层、批归一化层、Leaky Relu激活层组成。第1个计算单元的输入和第2个计算单元的输出之和经过Leaky Relu激活之后作为这一部分的总输出。
本模块中的改进主要体现在3个部分:一是将二维卷积滤波器改为适应通信信号的一维卷积滤波器;二是设置合适的滤波器个数和卷积核大小,提高训练和识别的运算速度;三是采用Leaky Relu激活函数,相比于原Relu激活函数可以使网络学习到值为负数的信号部分。
2.2 分类模块
分类模块主要功能是对特征提取模块得到的高维特征向量进行分类判别,由两层全连接层和Leaky Relu激活函数组成。
训练中优化器选择为随机梯度下降法,损失函数为负对数似然损失,学习率函数为指数衰减函数。训练的损失函数可以写为:
(3)
式中:Xs和Ys表示原始信号数据集的数据和标签;F代表特征提取模块;C代表分类模块。
2.3 信道判别模块
信道判别模块由一层梯度反转层,两层全连接层、激活函数组成。若要在目标数据集实现较好的分类结果,必须让特征提取器和判别器不能正确区分目标信号数据集和原始信号数据集。因此,信道判别模块的主要任务是在训练过程中不断优化特征提取器,实现信道判别误差的最大化,从而使得输出的高维特征向量不能被信道判别模块正确判别。
此模块的输入为原始信号数据xi和目标信号数据zj经过特征提取模块后的特征向量,分别表示为Xi和Zj:
Xi=F(xi),xi∈Xs
(4)
Zj=F(zj),zj∈Xt
(5)
损失函数可以写为:
(6)
在特征提取器F进行优化更新过程中,由于lossdis和lossclass的梯度方向是相反的,为了避免分阶段训练,在此模块中加入了梯度反转层,使得前向传播的过程中实现恒等变换,反向传播的过程中梯度方向自动取反。如下式:
(7)
其中,Rλ为梯度反转层;Xi为输入的特征向量;λ为动态参数,随着迭代次数而变化。
2.4 算法流程
本文中算法按照以下步骤进行:
1) 特征提取模块和分类模块随机初始化后在原始信号数据集上进行训练,收敛后保存模型参数。
2) 加载有监督训练保存的特征提取模块和分类模块的网络参数,从原始信号数据集中随机选出一批数据送入特征提取模块,得到特征向量Xi,接着送入分类模块,同已知的分类标签得到分类损失lossclass。
3) 从目标信号数据集中随机选出一批数据送入特征提取模块得到特征向量Zj,将Xi和Zj送入信道判别模块,得到判别损失lossdis。
4) 统计2)和3)模块中总的损失,通过梯度反向传播,实现各网络模块的参数更新。多次重复第2)至第4)步至收敛后,保存各模块网络参数。
5) 最后是模型推理,加载无监督训练后保存的特征提取模块和分类模块的网络参数。将测试集数据送入特征提取模块和分类模块,选取置信度最高的类别作为每一个数据的推理结果。
3 实验设置
3.1 数据集生成
为了验证本文中所提方法的有效性,使得实验更符合实际的应用场景,同时保证实验的可扩展性。本文中实验采用5个软件无线电设备,型号为USRP B210。每个设备包含2个发射通道,所以一共可以构造10个带有辐射源指纹特征的数据集。这样做的优势是模拟实战场景构建参数可控的标准数据集,以便更灵活和全面的评估本方案的性能。出于研究的目的,采用仿真信道的方式也是为了更容易控制变量,同样也包含了辐射源的指纹信息。
首先用一个采集设备通过同一个同轴电缆采集了10类辐射源发出的连续数据,实验场景如图2所示。因为通过同轴电缆连接辐射源和采集设备,可以认为采集到的数据不受自由空间传输过程中信道影响。每一类共采集3×108个样点作为原始信号数据集,信号参数和采集参数如表1所示。

表1 信号参数Table 1 The parameter of the signal

图2 数据采集场景示意图Fig.2 Setup of the data collection
将原始信号数据集和对应标签划分成训练集、验证集和测试集,分别为总数据量的70%、20%、10%。训练集用于网络模块调优,验证集用于评估网络模块训练过程的进展,测试集用于客观的测试网络模块的识别性能。
目标信号数据集是通过原始信号数据集仿真叠加仿真信道影响后得到,仿真的瑞丽信道环境同时包括了多径效应、多普勒效应、频率抖动以及高斯噪声的影响。每一类辐射源数据分别通过此信道后保存为目标信号数据集。信道响应通过Matlab软件的comm.RayleighChannel函数来随机产生,然后叠加到每一个数据上。
3.2 数据预处理
通信信号采集到的通常为一维连续数据。如图3所示,每类辐射源收集到的连续信号采样点为L=3×108。在后续训练过程中,每一次优化都在所有辐射源类别中随机选择固定长度为k=4 096,m=128个数据组成维度为128×4 096的数据集,同时得到维度为128×1的对应标签。这种随机起始点的方式可以避免数据中所含信息的影响,使得训练的模型更加稳健。
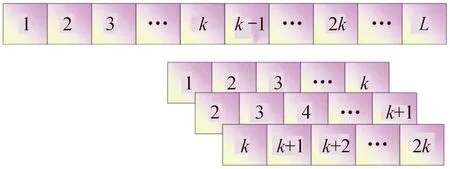
图3 随机选取数据示意图Fig.3 The random sampling process
然后对数据集中每个数据x按照下式分别进行标准化:
(8)

(9)
标准化操作可以提升模型训练过程中的速度,使模型尽快收敛。
3.3 实验环境和训练参数设置
1) 本文中实验使用的深度学习环境版本分别为Python 3.8,Pytorch 1.6.0,cuda10.2.89,显卡型号为 NVIDIA Tesla V100。
2) 在网络训练过程中,式(7)中的λ取值如下所示:
(10)
式中: epoch为网络优化过程中的迭代次数;batchsize设置为128;最大epoch设置为200;分类模块和信道判别模块的优化器均为Adam优化器;初始学习率为10-4;更新函数为每10个epoch变为上一个值的0.8倍。
4 实验及结果分析
本文中基于原始信号数据集和目标信号数据集设计3个实验。第1个实验是有监督训练实验,将特征提取模块和分类模块在原始信号数据集上进行训练,并评估模型的识别性能;第2个实验是将目标信号数据集送入已训练好的特征提取模块和分类模块,验证网络在模型失配下的识别性能;第3个实验是测试通过本文中所提方法进行训练后,模型对于目标信号数据集数性能的提升情况。
在本文中,衡量模型的性能主要有以下2个指标:一个是混淆矩阵,混淆矩阵是一个误差矩阵,常用来可视化地评估监督学习算法的性能;二是为了更直观的展示特征分布,我们采用了t-SNE(t-distributed stochastic neighbor embedding,t-SNE)[19]降维算法来可视化所有类别在二维空间的特征分布情况。T-SNE是一种非线性降维算法,通过仿射变换将数据点映射到概率分布上,可以将深度学习所提取的高维特征降维到二维或者三维。在实验中,通过将数据输入训练好的特征提取模块和分类模块,然后提取出分类识别模块最后一层全连接的输出向量进行t-SNE降维。
4.1 原始信号数据集的分类性能
按照2.4节的算法流程,首先在原始信号数据集上展开训练。模型收敛后将测试数据输入训练好的特征提取模块和分类模块,统计后得到的混淆矩阵的结果如图4所示。识别率接近100%。然后提取出分类识别模块最后一层全连接的输出向量进行t-SNE降维,结果如图5所示。可以看出10类目标的聚集性较好,类别之间的差异可以通过神经网络进行区分。

图4 原始信号数据集的混淆矩阵Fig.4 The confusion matrix of original data

图5 原始信号数据集的特征分布图Fig.5 The feature map of original data
4.2 模型失配下的分类性能
本实验是测试目标信号数据集在未进行所提方法的训练之前的识别率。首先加载训练好的特征提取模块和分类模块的网络参数,然后将目标信号数据集中的数据分批次送入模块,经过统计得到混淆矩阵如图6所示。整体准确率为52.5%。训练出的网络模型比原始目标数据集上的识别率下降了47.5%。通过提取出分类识别模块最后一层全连接的输出向量进行t-SNE降维,结果如图7所示,可以看出特征混淆比较严重。说明在目标信号数据集中,变化的信道极大的影响了网络模块的特征提取和分类的准确性。
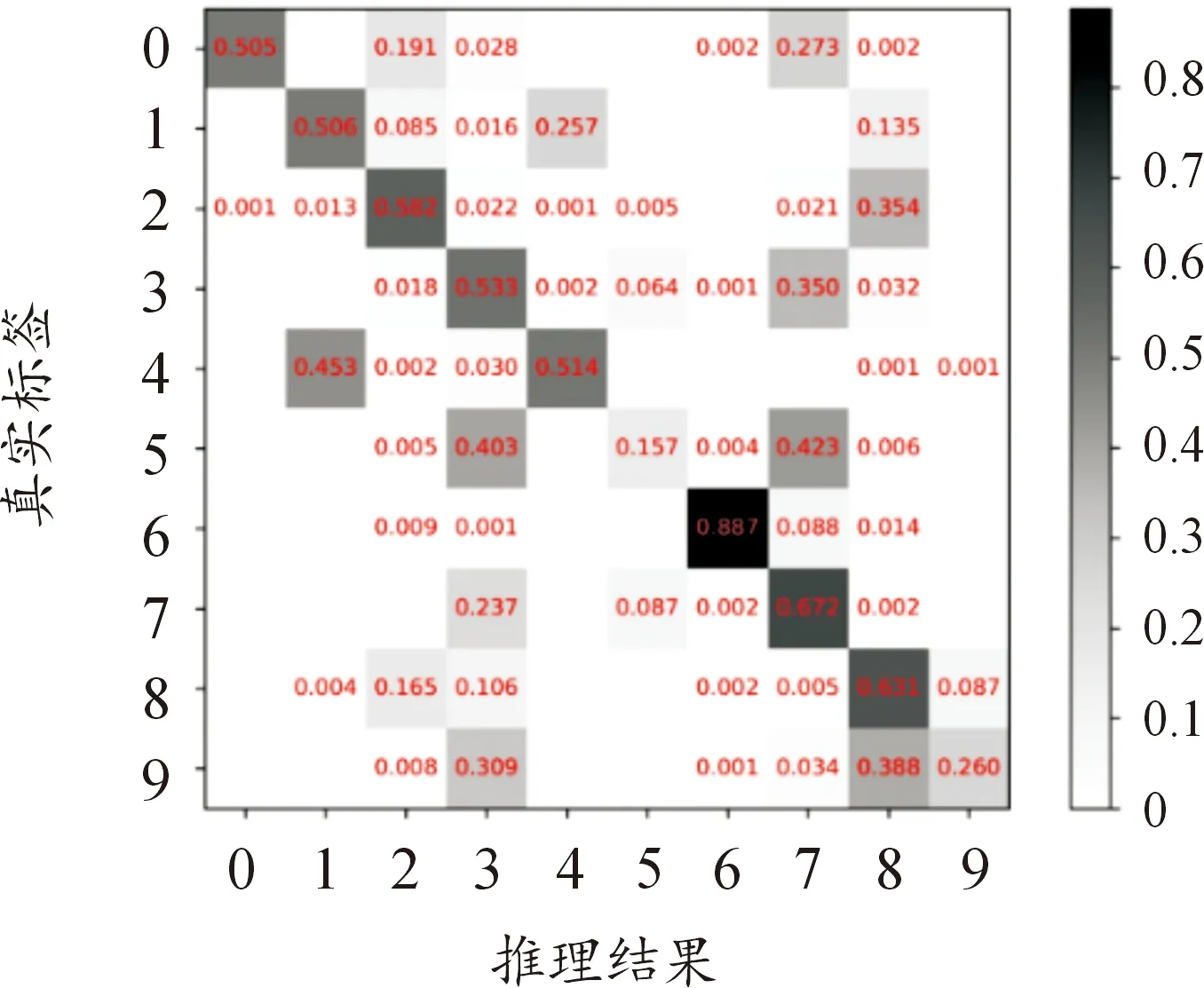
图6 目标信号数据集的混淆矩阵Fig.6 The confusion matrix of target data

图7 目标信号数据集的特征分布图Fig.7 The feature map of target data
4.3 本文中方法在目标信号数据集的分类性能
执行2.4节的算法第2~5步,利用无标签的目标数据集和已经训练好的模型参数进行无监督训练。结果的混淆矩阵如图8所示,准确率提升到77.6%。相比于未训练之前的识别率提升了47.8%。t-SNE降维结果如图9所示,10类目标又具有了相对较好区分性,验证了所提方法的有效性和可行性。可以看出经过无监督训练,特征提取模块和分类模块已经可以适应信道的变化提取到较稳定的特征,得到较高的识别率。

图8 无监督训练后目标信号数据集的混淆矩阵Fig.8 The confusion matrix of target data after training

图9 无监督训练后目标信号数据集的特征分布图Fig.9 The feature map of target data after training
5 结论
在利用深度学习算法实现辐射源个体识别时,针对用于训练网络的数据集与待测无标签数据集分布不一致,从而导致识别率严重降低的问题,本文中提出了一种基于信道自适应的无监督训练与识别方法。该方法通过在模型训练中对特征层进行约束,使得模型可以鲁棒性的提取个体特征,降低信道等环境参数对模型性能的影响。通过实采数据集和仿真实验,在识别率严重降低的情况下,本文中所提的方法带来了47.8%的性能提升。对于推动基于深度学习的辐射源识别算法在实际中的应用具有较高的参考价值。
虽然本文中所提的方法可以带来较大的性能提升,但是相比于有监督训练的识别率还有较大的差距。未来需要进一步研究提升无监督训练识别率的方法。同时未来需要针对不同类型的信号样式、更复杂的信道环境、变化的接受设备等开展研究,真正解决深度学习方法在射频指纹识别领域的应用问题。
