空气污染时序数据特征提取方法研究
2023-04-29于璐姜珊王新秀
于璐 姜珊 王新秀


关键词:空气污染时序数据;后缀索引;清晰模型;特征提取
中图分类号:X831 文献标志码:B
前言
为监测和预测大气环境,政府在全国范围内建立了大量的空气质量监测站点,收集了大量的空气污染时序数据。空气污染时序数据可以提供有关空气质量变化的实时信息,通过对数据的监测和分析,可以及时发现空气质量下降趋势和异常,预警公众和决策者并采取相应措施,以保护公众健康。然而,如何从这些数据中提取出有用的特征,以便更好地监测和预测空气质量,是气象监测领域面临的一个重要挑战。
随着对时序数据特征提取问题的研究越来越多。文献[3]中使用HYSPLIT模型研究了临汾市空气污染物的时间变化特征、轨迹输送特征和可能来源,该方法能够较好地监测空气污染物的时间变化情况并简要归纳特征。文献[4]中提出了基于Prophet模型的空气污染物浓度预测方法,运用Prophet模型,确定环境监测数据的突变点等特征,分析了各项污染物浓度的时空变化规律。但将以上方法应用于空气污染时序数据时,存在准确性不高的问题。
为解决这一问题,设计一种针对空气污染时序数据的特征提取方法,提高特征提取的精确度。
1空气污染时序数据特征提取方法设计
1.1空气污染时序数据挖掘
通过改进的PrefixSpan算法实施空气污染时序数据挖掘。基于后缀索引对PrefixSpan算法实施改进,将原本的投影数据库替换,缩小算法运行时的实际占用空间。
通过下式表示后缀索引:
G=
式(1)中,id为序列的ID或序列的位置下标;itemSetPosition为序列的项集;itemPosition表示项集的项;G为将序列中某项到序列末尾间的项集作为当前前缀的后缀。其中,itemSetPosition与itemPosition的编号从0开始。
将前缀树作为改进算法的数据结构,前缀树的结点能够记录子结点、后缀索引、前缀的类型以及新生成的前缀,分别用childTreeNode、suffixIndex、itemFlag、prefix来表示。
改进的PrefixSpan算法的具体运行流程如下:
(1)在标准站数据库中实施挖掘操作;
(2)R为前缀树的根结点,B为原始序列集,Smin为最小支持度。
(3)对前缀树的根结点R实施初始化处理,将R的itemFlag设置为0,childTreeNode、prefix设置为null。
(4)将suffixIndex的itemSetPosition与itemPosition设置为0。
(5)将id设置为序列集内序列的ID。
(6)从根结点开始对前缀树实施递归创建。具体步骤如下:
①以当前结点的后缀索引为依据对序列集内对应的后缀实施遍历,对后缀内各项的支持度进行计算,计算公式如式(2):
当未产生新前缀时,递归返回;当产生新前缀时,执行以下步骤:
③以当前结点的后缀索引为依据对产生的新前缀所对应的后缀索引进行计算,并分别对新的前缀树结点实施创建;
④将前缀树结点的prefix直接设置为新产生的前缀;
⑤将childTreeNode设置为null,
⑥将suffixIndex设置为新产生的前缀所对应的后缀索引;
⑦根据当前遍历的结点的prefix与新产生前缀的关系将itemFlag设置为1或者0;
⑧将全部新创建的前缀树结点当做目前遍历结点的子结点,并在前缀树中加入这些结点;
⑨将当前结点的suffixIndex直接设置为null;
⑩依次对当前结点的子结点实施遍历,执行步骤1~2。
(7)获取挖掘的多组空气污染时间序列。
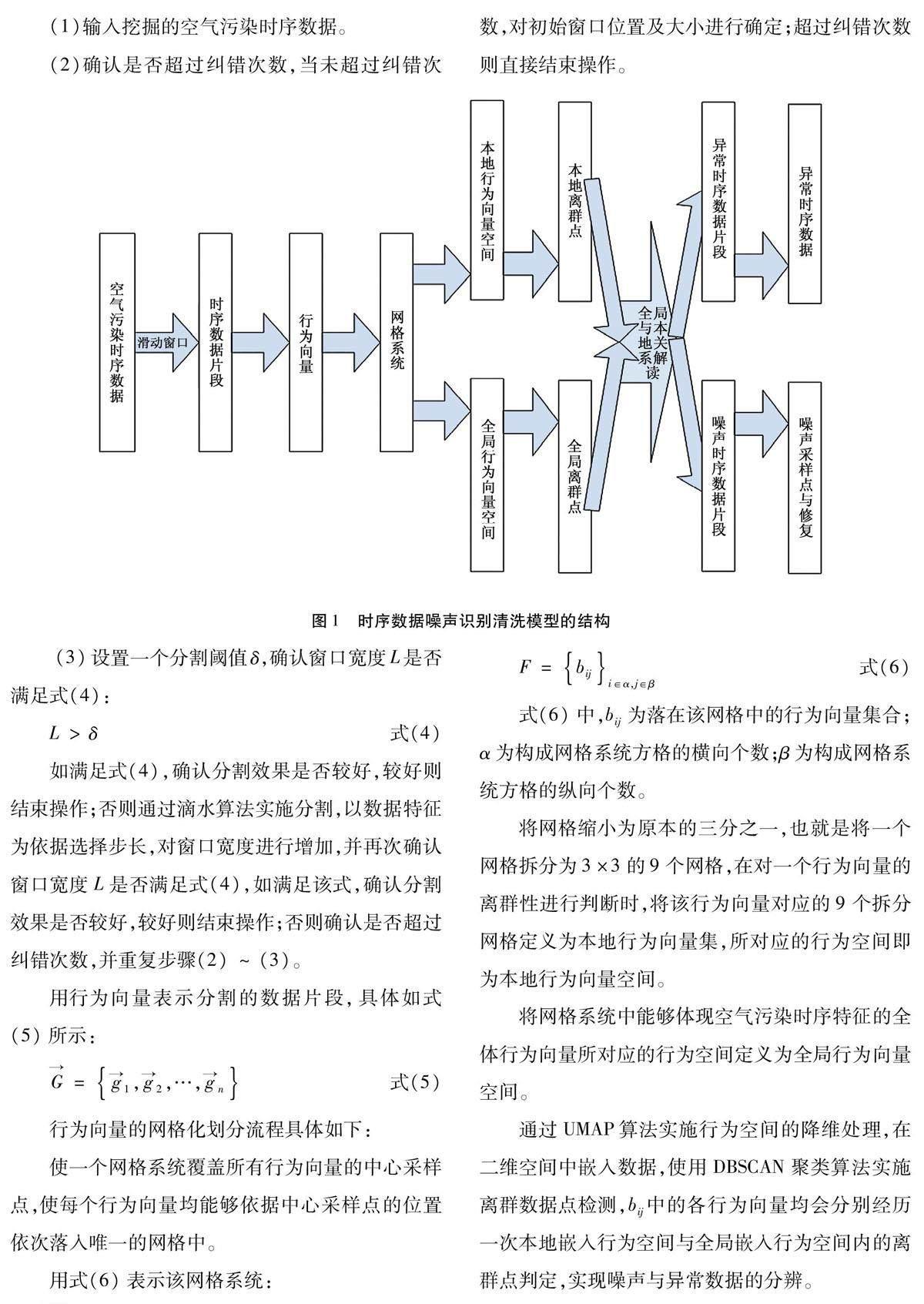
1.2挖掘时序数据的噪声识别与清洗
设计考虑异常保留的时序数据噪声识别清洗模型,实现挖掘的空气污染时序数据中噪声数据的处理。该模型通过降维与聚类方法实现离群点的判定,通过网格系统拆分行为空间,从而实现噪声与异常的分辨。
该时序数据噪声识别清洗模型的结构见图1。
通过自适应滑动窗口将空气污染时序数据分割为数据片段,具体操作步骤如下:
2案例测试
2.1实验数据集
该市共有15个标准站,其中大型标准站共有八个,均分布在郊区,小型标准站共有七个,均分布在市内。利用改进的PrefixSpan算法挖掘以上15个标准站最近六个月的空气污染时序数据作为实验数据集,测试设计方法的特征提取性能。
2.2实验过程
挖掘的空气污染时序数据共56852条,找到其中的28 563条被认为含有噪声的数据段,最终定位了6852个噪声点实施了差值修复,提高了空气污染时序数据的质量。
通过基于多维评价与模态重构设计特征提取方法实现实验数据集的特征提取。在该过程中,将压缩率P分别设置为75%、80%、85 010、90%、95%,通过遗传寻优算法获取加权参数与去噪阈值,不同压缩率下的参数寻优结果如下:
压缩率P为75%:加权参数与去噪阈值的寻优结果分别为0.71、0.24;
压缩率P为80%:二者寻优结果分别为0.83、0.22:
压缩率P为85%:二者寻优结果分别为0.94、0.17:
压缩率P为90%:二者寻优结果分别为0.47、0.17:
压缩率P为95%:二者寻优结果分别为0.41、0.16。
在不同参数寻优结果下,获取PLR序列内全部分段点的连接曲线,实现特征的提取,其中压缩率为75%时的连接曲线见图2。
测试设计方法特征提取中的平均拟合误差与拟合损失,将基于转折点和趋势段的时间序列趋势特征提取方法与时间序列数据并行化排列熵特征提取方法作为对比测试方法,共同进行测试,并分别用方法1、方法2来表示。
2.3测试结果
2.3.1平均拟合误差测试结果
首先测试不同压缩率下设计方法与方法1、方法2特征提取中的平均拟合误差,测试结果见表1。
根据表1的测试结果,设计方法在压缩率P为85%时平均拟合误差最低;方法1在压缩率P为90%时平均拟合误差最低;方法2在压缩率P为80%时平均拟合误差最低。设计方法的平均拟合误差整体低于两种对比方法,说明其特征提取更加准确,特征提取性能更好。
2.3.2测试结果
接着测试三种方法的拟合损失,测试结果见图3。
根据图3测试结果,随着时间的增长,三种方法的拟合损失都越来越低,其中设计方法的拟合损失一直低于方法1、方法2这两种对比方法,并在最终达到了0.1以下的拟合损失。
3结束语
通过文章的研究,可以得到以下结论:空气污染时序数据特征提取方法是一种有效的手段,可以从空气污染时序数据中提取出有用的特征,以便更好地监测和预测空气质量。在特征提取过程中,需要结合不同的算法和模型,以适应不同的数据类型和监测需求。此外,特征提取的结果可以为空气质量监测和预测提供重要的参考依据,帮助政府和相关机构及时采取措施,减轻空气污染对人类健康和环境的影响。因此,空气污染时序数据特征提取方法具有广泛的应用前景和研究价值。
