基于马尔可夫链的车辆规划行驶工况构建方法研究*
2023-04-27王伟曲辅凡杨钫李文博
王伟 曲辅凡 杨钫 李文博
(1.中汽研汽车检验中心(天津)有限公司,天津 300300;2.中国第一汽车股份有限公司研发总院,长春 130013)
主题词:工况构建 聚类分析 马尔可夫链 在线地图
1 前言
车辆行驶工况是车辆性能提升的共性基础,对于车辆能耗优化、控制策略标定及新技术的开发具有重要意义。当前,应用最广泛的车辆行驶工况是标准循环工况,但受地域差异、道路差异影响,标准循环工况与车辆实际工况差异较大[1]。因此有必要研究一种能够规划、预测车辆实际行驶状态的工况构建方法。
国内外学者在车辆工况构建方法方面进行了大量的研究,工况构建包含行驶数据压缩重构和工况合成2个部分[2]。数据压缩重构过程将运行数据视为离散片段,提取速度、加速度、行驶距离等典型参数,通过主成分分析(Principal Component Analysis,PCA)法对数据进行降维,保留原始数据的核心信息[3],如尹安东等以合肥市纯电动汽车的行驶工况为对象,采用主成分分析法构建行驶工况,对不同类型工况的汽车能量消耗量进行估算,但是该方法忽略了车辆实际行驶过程中的不确定性,能耗预测结果有待验证。工况合成方法包含聚类分析法、马尔可夫链法、V-A 矩阵法等算法[4-5]。秦大同等采用K 均值(K-Means)聚类分析法构造车辆能耗与行驶特征的关联关系,合成某山地城市的典型行驶工况,但是忽略了实时交通状态的影响,难以代表实际行驶特征[6-7]。Hereijgers 等提出一种同时考虑汽车行驶速度和道路坡度的多维马尔可夫链的工况合成方法,构建的工况更符合真实路况数据,但是该方法以车速作为依据进行整体分析,划分为加速、减速、匀速、怠速(或停车)4 种状态[8-9],导致该方法合成的工况受初始随机车速的影响较大,难以反映车辆实际行驶状态。
综上,当前工况构建方法均为针对历史数据的工况构建方法,没有融合道路交通实时运行状态,无法反映车辆未来行驶工况。本文提出一种基于马尔可夫链的车辆规划行驶工况构建方法,采集车辆行驶数据,采用马尔可夫链构建工况片段库,将在线地图规划路径与工况片段融合,最终生成规划行驶工况。
2 基于马尔可夫链的在线地图规划工况构建
工况片段库基于实际行驶数据构建,用于在线地图行驶工况规划。本文提出的工况构建流程如图1所示。

图1 在线地图规划行驶工况构建流程
2.1 车辆行驶工况片段库构建
2.1.1 行驶数据清洗
道路和环境等因素的干扰会造成采集数据的异常,甚至缺失,故需对采集的数据进行清洗。异常数据主要体现在停车时间或怠速时间、加速度和车速等方面。数据清洗后需采用递推平滑滤波算法对原始数据进行滤波处理,降低异常因素对车速数据的影响。
由于车速数据连续采集的时间较长,行驶特征难以准确表达,因此将数据分段处理。城市道路行驶车辆因受到交通条件的限制,存在停车、加速、减速、匀速状态间的频繁切换,因此将从一次停车或者怠速的起始时刻至下一次停车或者怠速的起始时刻定义为一个交通片段[10-11]。通常,每个交通片段至少包含1个加速状态和1个减速状态,时长不少于10 s,加速度一般处于-4~4 m/s2范围内。将采集的数据分为数量为N的交通片段,选择如表1 所示的特征参数描述每个片段的加速、减速、匀速、停车(或怠速)等行驶特征,其中平均行驶速度为行驶过程中的平均车速。

表1 片段特征参数
2.1.2 数据降维
经过上述处理后得到的交通片段数据量大、维度高,且交通片段各特征参数间具有一定的相关性,直接聚类存在计算量大、聚类效果差等问题,因此需要将特征参数降维[12-13]。本文采用主成分分析法对车辆行驶数据进行降维处理,将原始变量线性组合成相互独立的新变量。
将所有片段的特征参数记为特征矩阵X:
式中,n为交通片段的数量;p为每个片段特征参数的数量。
对X进行标准化处理,得到标准化矩阵S,其元素Sij为:
处理后的矩阵S并不改变各参量的相关性。根据矩阵S计算出相关系数矩阵及其特征值和特征参数,基于特征值计算出累计贡献率。选择特征值大于1,且累积贡献率在80%以上的主成分,用于行驶工况构建。
2.1.3 K-Means聚类
采用K-Means聚类算法对主成分进行聚类,具体步骤为[14-15]:
a.根据实际问题确定分类数量k,并在每一类中确定初始聚类中心;
b.计算各样本到聚类中心的距离,距离较近的归入一类,欧式距离的计算公式为:
式中,xik为第i个样本的第k个主成分;xjk为聚类中心j的第k个主成分;q为主成分的数量。
c.计算每一类的中心位置,并将该位置确定为新的聚类中心;
d.按照新的聚类中心重新进行分类,重复步骤b、步骤c 的操作,随着重复次数的增多,聚类中心不再发生大的偏移,聚类结果趋于稳定。
按上述步骤,获得了类别数量为n的片段样本、每类样本包含的片段数量及特征参数的均值,用于马尔可夫链工况构建。
2.1.4 基于马尔可夫链的片段库构建
基于测试数据构建的片段库为在线地图规划行驶工况构建提供基础,因此需要选用合理的方法构建片段库。马尔可夫链能够基于历史交通数据较好地预测未来行驶工况,且车辆行驶特征符合马尔可夫性,因此采用马尔可夫链构建片段库。采用临近法将车辆行驶状态离散为有限的状态[16]:
在当前时刻行驶状态v(k)为vi时,下一时刻行驶状态v(k+1)为vj的概率为[17]:
式中,Pi,j为状态转移概率矩阵P的第i行第j列元素;概率转移矩阵P为:
状态转移矩阵的元素采用极大似然法求得:
式中,Fij为车辆从状态vi转移到vj的次数;Fk为当前状态的总统计量。
基于马尔可夫链构建工况的过程为:设定当前状态为v1,生成随机数λ∈(0,1),通过λ与状态转移矩阵P的相应元素大小进行对比,确定下一状态v2,如此重复计算,直至累计距离达到目标车速。
构建的片段库用于在线地图工况构建,而在线地图片段长度、平均车速等具有不确定性,因此构建的片段库应当尽可能覆盖全部行驶车速和距离。
2.2 在线地图规划工况融合
构建在线地图规划行驶工况需要基于地图应用程序编程接口(Application Programming Interface,API)数据生成基础规划工况,然后将构建的片段库与基础规划工况融合,形成能预测实际行驶特征的工况。
2.2.1 在线地图基础规划工况
在地图中规划路径,地图API可获取行驶距离和预计行驶时间,并可获取在规划路径片段的距离和通过时间、交通灯的位置,通过以下计算得出路径片段的目标车速。
首先根据交通灯位置以及车辆通过该片段的预估时间,确定在交通灯处是否停车以及停车时间。之后利用片段长度与通过时间计算片段平均车速,并根据交通片段长度与拥堵系数进行修正。最后识别连续交通片段中车速相等的匀速段,观察匀速段内是否包含停车点。如果未包含,则目标车速为该匀速段的车速。如果包含,则统计该片段内从0加速的次数n1、减速到0的次数n2和停车时间,计算目标车速Vt:
式中,a为平均加速度;d为平均减速度;T为通过时间;Ns为停车次数;ti为每次停车时间;D为匀速段的距离。
计算目标车速内的速度突变点需识别车速突变点的初始速度和终止速度,计算速度突变点的加速、减速过程需求车速及距离:
式中,V为目标车速;X为行驶距离;X0为初始距离;V0为初始位置的初始车速;t为加速、减速过程的时间。
通过上述计算得出基于地图API的基础规划工况,仅包含匀速和停车稳态工况,在细分的片段中不能进一步规划出车辆实际行驶工况。
2.2.2 马尔可夫链片段融合
基于在线地图需求信息,采用贪心算法对每个交通小片段选取最优的工况片段:
式中,Δl为地图交通小片段长度与k1个工况片段总长度的差值;k1为工况片段数量;d(i)为第i个工况片段的距离;L为地图交通小片段的长度。
以交通小片段的通过时间与工况片段的差值最小为寻优目标,且差值Δt应不小于0:
式中,t(i)为第i个工况片段的时间;T1为交通小片段的通过时间。
由于地图交通小片段的长度和时间存在不确定性,工况片段寻优可能出现3种情况:
a.Δl≥0 且Δt>0,则在Δt时间内补充车速为Δl/Δt的匀速段;
b.Δl>0 且Δt=0,则在时间T1内,将工况片段速度增大L/(L-Δl)倍;
c.Δl=0且Δt=0,则无需处理。
通过上述实际采集的数据所构造的工况片段,以规划路径片段的距离和平均车速作为约束条件,从片段库中选取、组合片段,最终实现了生成的工况与规划路径的距离和时间相等。
3 验证分析
在试验车内安装车速传感器、加速度传感器及数据采集设备(未采集交叉口、交通灯及车道特征等信号),采集同一驾驶员在某城市驾驶车辆连续3 个月的车辆行驶数据,行驶道路涉及城市工况、郊区工况、快速路工况等。降噪后的数据如图2所示,可以看出滤波后的数据平滑度更高。将滤波后的数据划分为11 587个片段,计算出各片段的特征参数如表2 所示。再按照本文提出的方法构建在线地图基础规划工况、在线地图规划行驶工况,采集车辆实际行驶工况。以某款电动车为研究对象,将3种工况导入新能源汽车数字化虚拟仿真平台(VPAT2021),进行验证分析。

表2 片段特征参数
各片段的特征参数在主成分分析后得到的相应特征值、贡献率及累计贡献率如表3所示,前3个主成分的特征值均大于1,累计贡献率为84.27%。因此选取主成分M1、M2、M3 来表征15 个特征参数所包含的行驶信息。
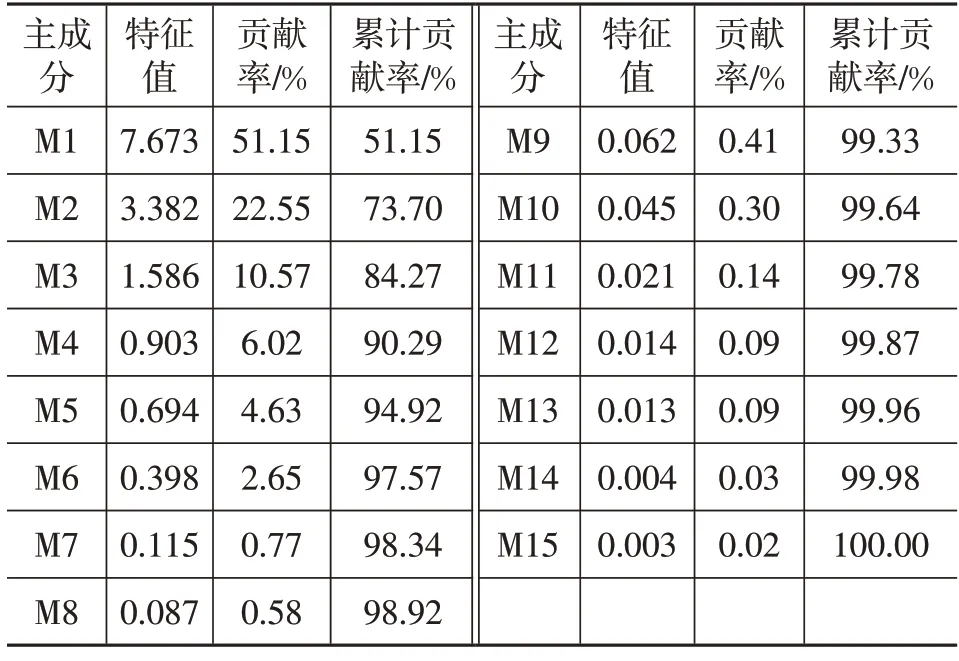
表3 主成分分析结果
对3 项主成分进行K-Means 聚类分析,得出4 类片段样本集,各类样本的部分特征参数如表4所示,由表4中速度和加速度可知,类别1~类别4 分别代表城郊工况、高速工况、城市工况、严重拥堵工况。
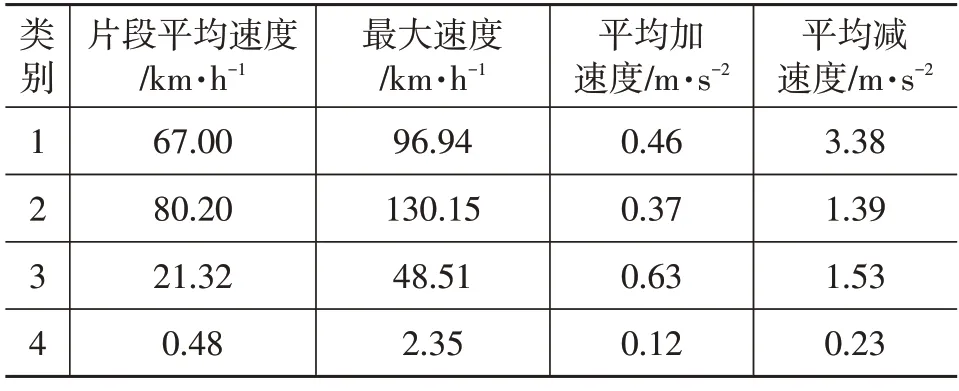
表4 聚类特征参数(部分)
基于聚类结果和行驶数据,采用式(6)计算车辆在不同类之间切换的概率矩阵P1,如表5所示。
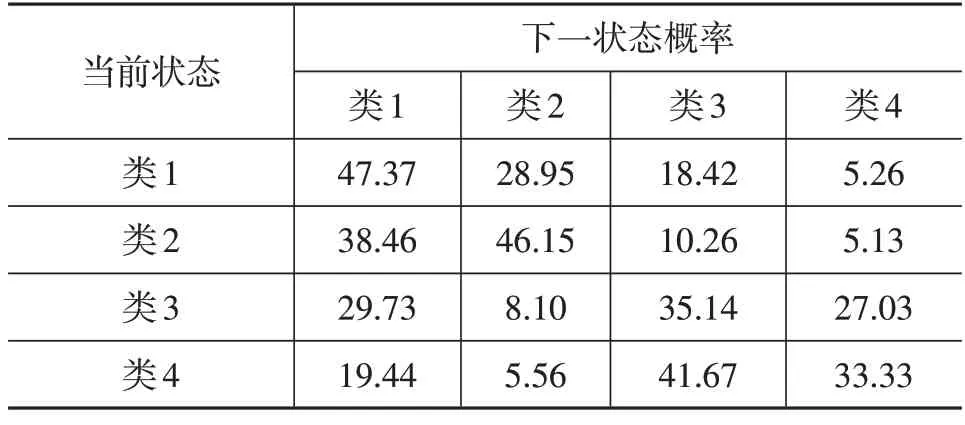
表5 类状态转移概率P1 %
在聚类样本内部,车辆存在怠速(或停车)、加速、匀速、减速4种行驶状态,不同类所代表的车速、加减速度等行驶状态不同,行驶状态转移概率也不同。以类别1为例,采用式(6)计算出各行驶状态转移概率矩阵P2如表6所示。

表6 类别1行驶状态转移概率P2 %
基于概率转移矩阵,利用马尔可夫链合成片段的步骤为:
a.选择类别3 为初始类状态,选择怠速或停车状态为初始行驶状态;
b.根据类状态转移矩阵P1和随机数λ选择接下来的类状态;
c.根据该类的行驶状态转移矩阵P2和随机数λ选择行驶状态;
d.重复步骤b、步骤c,组合构建的片段,直到满足片段距离要求。
计算平均车速是否达到目标平均车速,将达到要求的片段列入候选工况库,然后对比候选工况库的平均误差,选择平均误差最小的为典型片段。基于马尔可夫链构建的片段示例如图3所示。
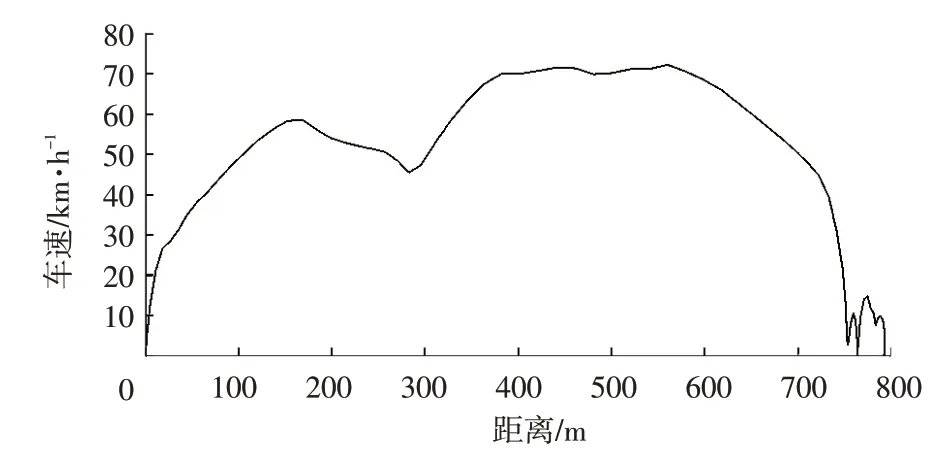
图3 基于马尔可夫链的车速片段
在地图上规划车辆实际行驶的出发点和终点,生成在线地图工况,从工况片段库选取片段,融合在线地图工况,形成规划行驶工况,如图4所示,与车辆实际行驶状态相比,构造的工况特征值如表7所示。
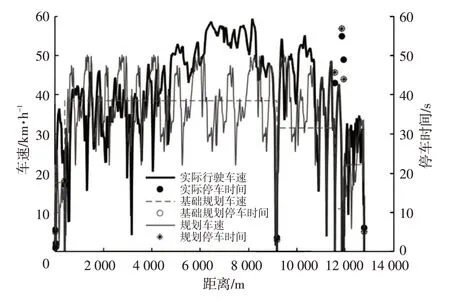
图4 规划行驶工况
由表7可见,基于马尔可夫链片段库构建的工况与实际行驶工况的平均误差仅为4.29%,最大相对误差为9.09%。在线地图基础规划工况以匀速为主,因此最终与实际行驶工况的平均误差达到316.40%,明显高于前者。故基于马尔可夫链片段库的车辆规划工况构建方法能够较好地反映车辆实际行驶状态。
在VPAT2021中搭建某款电动车的模型,车辆基本参数如表8所示。

表8 车辆基本参数
进行工况能耗仿真对比分析,仿真过程如图5 所示,仿真结果如表9 所示,基于马尔可夫链片段库规划的车辆工况与实际行驶工况的误差更小,百公里电耗为12.73 kW·h,误差仅为4.09%。
图5 VPAT2021能耗仿真过程

表9 能耗仿真对比
4 结束语
本文基于采集的实际交通数据,经过数据清洗、划分,计算出多个交通片段的特征参数,通过PCA法和KMeans聚类法对数据进行分析,利用马尔可夫链构建了片段库,与在线地图基础规划工况融合,构建了在线地图规划行驶工况。
将在线地图规划行驶工况与车辆实际行驶工况进行对比,采用特征参数和仿真能耗2 个维度评价,发现采用马尔可夫链片段库与在线地图融合的方式能更准确地反映车辆实际行驶特征,工况特征参数平均误差为4.29%,能耗仿真误差为4.09%。
