基于深度学习的COVID-19智能诊断系统
2023-04-26郭静霞白金牛
贾 楠,李 燕,郭静霞,徐 立,白金牛
(1.内蒙古科技大学 包头医学院计算机科学与技术学院,内蒙古 包头 014040;2.包头市中心医院,内蒙古 包头 014040)
0 引言
自2019年12月以来,新冠肺炎仍在全球蔓延。所以快速、准确地识别出新冠肺炎对于患者的及时医治以及控制疫情的传播具有非常重要的意义。目前新冠肺炎检测的金标准是逆转录聚合酶链反应(RT-PCR)[1],但在实践中常常会由于采样质量或者病毒的载量出现假阴性或弱阳性结果,从而导致较高的复检率,容易延误治疗,增加其他人员感染的风险。利用胸部X光片(CXR)也可以很好地进行新冠肺炎的辅助诊断。CXR是最常见的诊断放射学检查之一,CXR成像比CT成像更容易获得。因为CT扫描仪价格高昂且维护成本较高,而CXR系统相对较为便宜,且在乡镇一级的医院也普遍存在。但想通过CXR影像来识别患者是否感染新型冠状病毒,非常依赖放射科医生的经验。即便是训练有素的放射科医生也很容易犯错误,因为其它类型的肺炎和新冠肺炎往往具有相似的视觉特征。因此,用深度学习的方法构建一个模型支持放射科医生的决策过程,加速新冠筛查,帮助减少诊断错误具有非常重要的意义。
深度学习通过使用卷积神经网络可实现对医学影像特征的自动提取,具有强大的表征能力[2]。因此将深度学习应用于针对胸片的新冠肺炎检测也是当下研究的热点。Narin等[3]运用ResNet50、ResNet101、ResNet152、InceptionV3和Inception-ResNetV2五个模型,通过五折交叉验证对胸片进行训练,实现了COVID-19、正常(健康)、病毒性肺炎和细菌性肺炎四分类任务。实验结果显示ResNet50模型获得了最高的分类准确率。Wang等[4]基于DenseNet-121构造了一个深度学习管道,除了可区分由COVID-19引起的病毒性肺炎和其它类型的肺炎外,可以对新冠肺炎的严重程度进行评估。Wang等[5]利用神经网络搜索技术构建了COVID-Net模型,实现了正常(Normal)、其它肺炎(Non-COVID)、新冠肺炎(COVID-19)的三分类检测任务,并取得了不错的结果。Siddhartha等[6],提出了一种名为COVIDLite的方法,该方法在图像预处理阶段运用白平衡与限制对比度自适应直方图均衡化相结合,在神经网络构建中又采用了深度可分离卷积,最终实现了Normal、Non-COVID、COVID-19的三分类准确率为97.12%。Oh等[7]提出了一种基于patch的深度神经网络架构,可以在小数据集上稳定地训练,从而解决了新冠肺炎数据集较少的问题。
本文将构建一个轻量化的神经网络模型,该模型在满足检测精度的前提下,参数量要尽可能的小。同时为了使所训练的模型不是仅仅停留在实验室,而是能够真正地运用到临床辅助诊断中,本文还将搭建一套方便医院影像工作人员使用的web系统。
1 智能诊断系统结构及原理
本系统原理如图1所示。包括如下5个模块,1)数据集的整理和划分;2)分割模型;3)图像预处理;4)分类模型;5)模型部署。

图1 智能诊断系统原理图
具体说明如下:1)数据集整理和划分是将收集到影像数据按照类别进行整理,一个类别对应一个文件夹,文件夹中存入相应类别的影像。然后将整理后的影像按照一定比例划分为训练集、验证集和测试集;2)用训练集训练一个肺部分割模型,实现胸部X光片的肺部区域的分割;3)对分割后的肺部影像进行图像预处理,扩充训练样本的数量,提高模型的泛化能力;4)基于处理后的影像数据训练一个新冠肺炎检测三分类模型;5)将分割模型和分类模型进行组合部署,满足实际应用需求。
2 COIVD-19深度学习检测技术与方法
2.1 数据集介绍
本研究训练模型使用的是类别为COVID-19、Non-COVID、Normal的三分类数据集。一方面此类公开数据集较多;另一方面这种分类方法,有助于临床医生对COVID-19进行初筛分诊,如果检测为COVID-19可通过RT-PCR进一步进行确诊。同时COVID-19和其它肺炎采取的治疗方案不同,如此分类还有助于医生快速采取相应的治疗策略。数据集详细说明如下:
COVID-QU-Ex Dataset[8-12],是本文训练模型的数据集。该数据集来源于kaggle网站,包含33 920 张胸部x光片,其中COVID-19为11 956张,Non-COVID为11 263张,Normal为10 701张,并且所有影像均包含肺部边缘轮廓分割掩膜。本研究将该数据集进行训练集、验证集和测试集的划分。影像示例如图2所示,数据集详细统计见表1。

(a)~(c)分别为新冠肺炎患者、其它肺炎患者和正常人胸部x光片;(d)~(f)分别为新冠肺炎患者、其它肺炎患者和正常人肺部边界区域。图2 COVID-QU-Ex Dataset影像示例
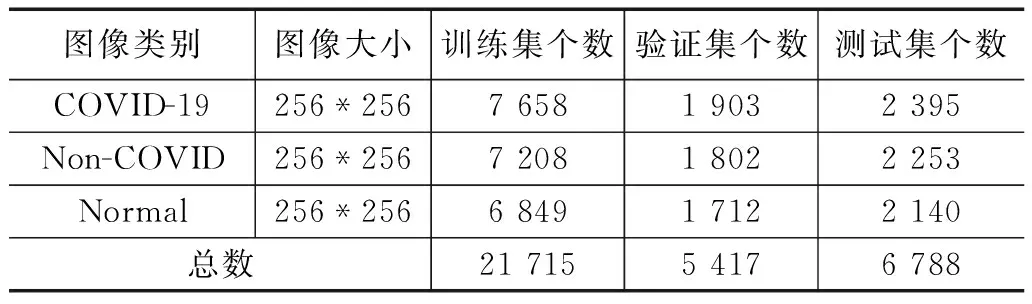
表1 COVID-QU-Ex Dataset详细统计
此外为了验证模型的泛化能力和稳定性,本论文还用COVID CXR Image Dataset[13-15]对模型进行了测试。该数据集也来源于kaggle网站,数据集包括Normal、Non-COVID和CVOID-19患者的胸部X光片的后前方(PA)视图。共有1823张CXR影像,包含536张COVID-19影像,619张Non-COVID影像和668张Normal影像。数据集中COVID-19病例的年龄范围为18~75岁。
2.2 检测方法
该研究利用深度学习对CXR影像进行分类的工作流程如图3所示。首先利用COVID-QU-Ex Dataset数据集中的肺部胸片以及肺部分割掩膜,训练一个UNet分割模型,UNet模型在医学图像分割领域表现优异,该模型能够很好地实现CXR影像肺部区域(ROI区域)的自动分割。其次将自动提取后的ROI区域送入图像分类模型,最终实现Normal 、Non-COVID、 COVID-19的三分类。
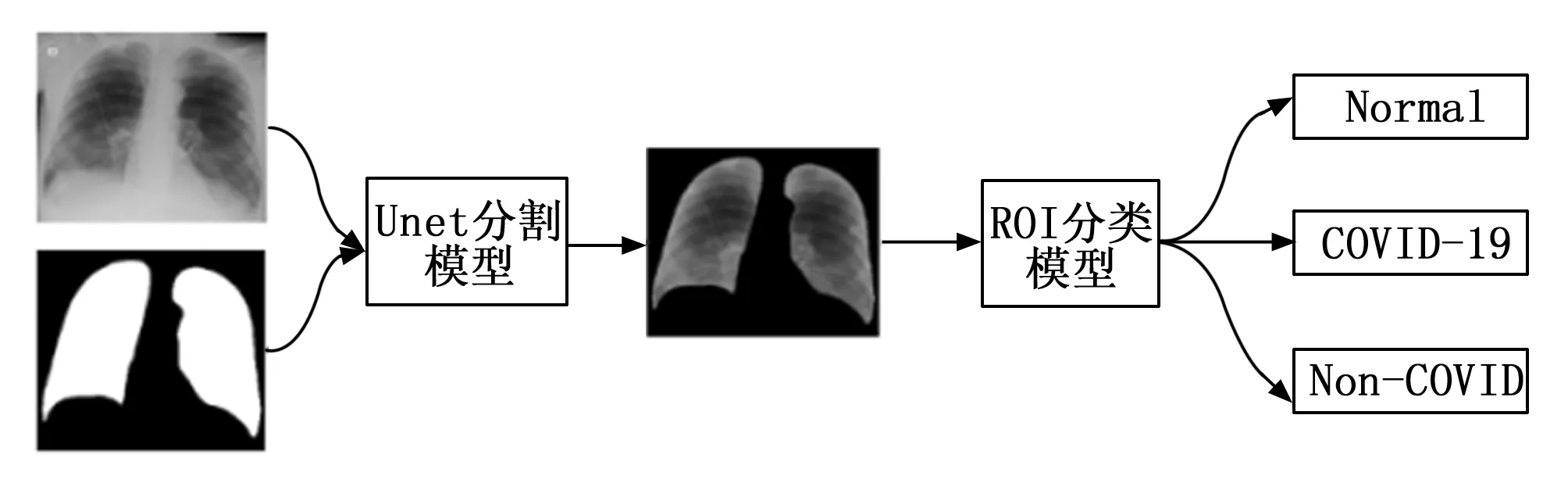
图3 工作流程图
本研究比较了当下流行的10种主流深度学习分类模型。详细的实验数据见文中第3部分。在以上10种模型的对比实验中,发现针对COVID-QU-Ex Dataset数据集,同系列的模型并不是模型深度越深,模型精度越高。而是随着模型深度增加到一定程度,精度不增反而略微下降。以RestNet系列为例,模型在验证集上的准确率如下:RestNet18为0.947、RestNet34为0.948、RestNet50为0.946、RestNet101为0.946。图4、图5分别为RestNet系列在训练集和验证集上直观展示。
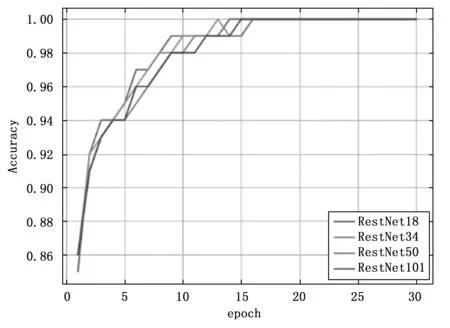
图4 训练集准确率

图5 验证集准确率
受此启发,针对该分类任务,构建模型时可以不用设计过深的网络,同样也能达到较好的分类效果,这样就可以控制模型的大小,方便模型在终端部署。为此本文以MobileNetV2[16]为基础,增加了CA(coordinate attention)[17]注意力机制,构建了一个新的模型用于CXR影像新冠肺炎检测任务,并将其命名为MBCA-COVIDNET。
2.3 MBCA-COVIDNET模型结构
该模型的整体结构如图6所示。
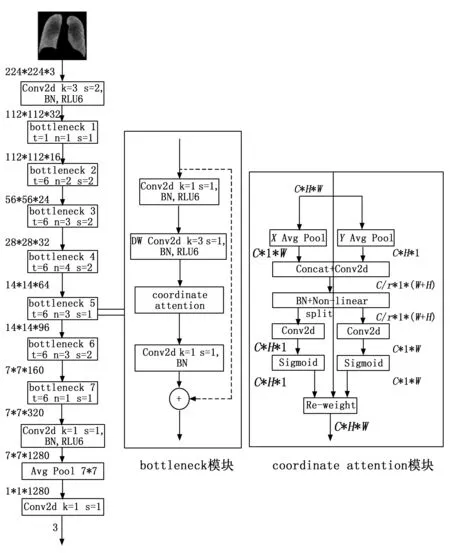
图6 MBCA-COVIDNET网络结构示意图
图6中,k代表卷积核大小;卷积中的s代表卷积步距;BN代表批归一化;RLU6、Non-Linear、Sigmoid代表非线性激活函数;t代表隐藏层的扩展因子;n代表bottleneck的重复次数;图中左侧MBCA-COVIDNET中包含7个bottleneck层,需要注意的是每个bottleneck层中标识出的s是对应的第一个bottleneck模块中的卷积步距,其它bottleneck模块s均为1;Avg Pool代表全局平均池化;DW Conv2d代表深度可分离卷积;C代表通道数;H代表特征图的高度;W代表特征图的宽度;r为代表特征图的缩放因子。
2.3.1 CA模块
CA是将位置信息嵌入到通道注意力中。与通道注意力机制不同,传统的通道注意力机制是通过二维全局平均池化将每个通道上对应的空间信息(H×W)压缩为1个具体的数值,最终维度变为1×1×C的向量,这种操作会损失物体的空间信息。而CA将通道注意力分解为两个一维特征编码的过程,分别沿着两个空间方向聚合特征。这种方法可以在一个空间方向上捕获长距离依赖,同时在另一个空间方向上保留精确的位置信息,它们可以互补地应用到输入特征图来增强感兴趣的目标表示。具体实现过程如图6所示,首先将输入特征图分别在宽度和高度两个方向进行全局平均池化,分别获得在宽度和高度两个方向的特征图zw和zh,公式如下所示:
(1)

(2)

然后将特征图zw的最后两个维度调换,再将其与特征图zh拼接在一起并送入卷积模块,卷积核为 1×1,输出维度降低为原来的C/r,r为通道的缩放比率,并将经过批量归一化处理的特征图F1经过非线性激活函数得到形如 1×(W+H)×C/r的特征图f,f∈RC/r×(H+W),公式如下所示:
f=δ(F1([zh,zw]))
(3)
式中,zh为高度方向上的特征图,zw为宽度方向上的特征图,[. ,.]为在空间维度上的拼接操作,F1为对输入特征进行1×1卷积并进行批归一化操作,δ为非线性激活函数。
接着,沿着空间维度将f切分为两个单独的张量fh∈RC/r×H和fw∈RC/r×W再利用两个1×1卷积将特征图fh和fw变换到和输入x同样的通道数。
gh=σ(Fh(fh))
(4)
gw=σ(Fw(fw))
(5)
式中,fh为沿高度方向将f切分的特征,fw为沿宽度方向将f切分的特征,Fh、Fw表示分别对fh和fw进行1×1卷积,并将特征通道数从C/r变回为C,σ为sigmoid函数。
最后对gh和gw进行拓展,作为注意力权重与输入相乘,CA模块的最终输出可以表述如下式:
(6)
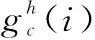
2.3.2 改进MobileNetV2结构
为了进一步提高MobileNetV2模型分类的准确率,在原模型的每个bottleneck模块中加入了CA模块,加入位置如图6所示。CA模块中BN层后的非线性激活函数采用RELU6激活函数。
2.4 数据预处理和数据增强
图像预处理,本实验将所有的影像缩放到224*224,数据集中的绝大部分图像都比该尺寸要大,也有个别图像的尺寸小于224*224,为将图像扩大至224*224,实现输入模型的图像尺寸统一,采用了最近邻插值。
为了更好地训练模型,提高模型的精度,在实验中也尝试了医学影像中常用的数据增强方法,如直方图均衡化、Gamma变换、TrivialAugment[18]等。
1)直方图均衡化:直方图表示的是图片灰度值的分布,直方图均衡化是将原图经过某种变换,得到一幅灰度直方图为均匀分布的新图像的方法。其基本思想是对在图像中像素个数多的灰度级进行展宽,而对像素个数少的灰度级进行缩减,从而达到清晰图像的目的。
2)Gamma变换:Gamma变换是对输入图像灰度值进行非线性操作,使输出图像灰度值与输入图像灰度值呈指数关系。Gamma变换就是用来图像增强,其提升了暗部细节,通过非线性变换,让图像从曝光强度的线性响应变得更接近人眼感受的响应,对过曝或过暗的图像进行矫正。
3)TrivialAugment:TrivialAugment是一种自动增强策略。它不像AutoAugment和RandAugment需要搜索空间,其不需要任何搜索,整个方法非常简单,每次随机选择一个图像增强操作,然后随机确定它的增强幅度,并对图像进行增强。TrivialAugment的图像增强集合和RandAugment基本一样,只不过其定义了一套更宽的增强幅度,目前torchvision中已经实现了TrivialAugmentWide。
2.5 模型评估指标
针对胸片的三分类任务,采用如下7个评估指标对模型进行评估:正确率(Accuracy)、精度(Precision)、灵敏度(Sensitivity)、F1Score、特异度(Specificity)、参数量(Parameters)、计算量(MACs)。
(7)
Accuracy为所有被分类正确的影像数量与所有影像数量的比值。
(8)
Precision为被分类为正例的影像中,实际为正例的比例。
(9)
Sensitivity为影像中所有正例被分类正确的比例,用来衡量模型对正例的识别能力。
(10)
F1Score兼顾了分类模型的精确率和召回率,可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
(11)
Specificity为影像中所有的负例被分类正确的比例,衡量模型对负例的识别能力。
公式(7)~(11)中TP表示实际上是正例,预测结果也是正例的数量;TN表示实际上是负例,预测结果也是负例的数量;FP表示实际上是负例,预测结果为正例的数量;FN表示实际上是正例,预测结果为负例的数量。
Parameters为模型内部总的参数数量,用来衡量模型的大小;MACs为乘加累积次数,1MACs等于1个乘法和1个加法。
3 实验结果与分析
3.1 实验步骤
本研究所有实验均基于Python3.9.5和pytorch1.11.0的深度学习框架实现,具体硬件设备配置:显卡为NVIDIAGeForceRTX 3080 LaptopGPU,显存16 G,电脑内存32 G,CPU为AMDRyzen 9 5900HX。
针对COVID-QU-Ex Dataset数据集的影像分类任务,对比了如下几个模型,RestNet系列(RestNett18、RestNet34、RestNet50、RestNet101)、EfficientNet系列(EfficientNetB0、EfficientNetB3)、MoblieNetV2、MobileNetV3、SwinTransformer、ConvNext_small以及新设计的MBCA-COVIDNET模型。所有这些模型训练的参数设置如下:训练迭代次数(epoch)30,因为30次模型已经收敛,再继续进行训练,模型精度没有继续提升;batchsize为64,因为受于实验硬件设备所限,该大小可使得所有基线模型在当前GPU(16 G)下训练;初始学习率为5×10-4,由于所有基线模型都采用迁移学习,都用到在ImageNet1K上的预训权重,所以初始学习率不易过大;优化器选用效果较好的AdamW,weight_decay设置为5×10-2,AdamW是在Adam的基础上引入了L2正则化,可有效地减小过拟合,针对该训练数据集,实验证明AdamW要优于SGD;学习率下降策略采用warmup+Cosine的下降策略,热身训练为1个epoch。实验证明该下降策略相比等间隔调整学习率(StepLR)能够带来精度的提升。同时所有模型训练时均不采用任何图像增强技术,只是将数据集中的图像大小缩放为224*224作为模型输入。
3.2 实验结果
基于上述统一设置的训练参数,训练得到的10个神经网络模型在COVID-QU-Ex Dataset测试集上的性能表现如表2所示,各模型的混淆矩阵如图7所示。从表2中可以看出MBCA-COVIDNET的模型的正确率为97.02%,是所有模型最高的,ConvNext_small模型的正确率为96.99%,仅从正确率这个指标看前者只比后者仅提升了0.03%。但是对比模型的参数量可以发现MBCA-COVIDNET模型的参数量仅为2.67 M,而ConvNext_small模型的参数量为49.46 M,前者的参数量远小于后者。对比MACs指标,前者为0.33 G,后者为8.7 G,前者的计算量也远小于后者。
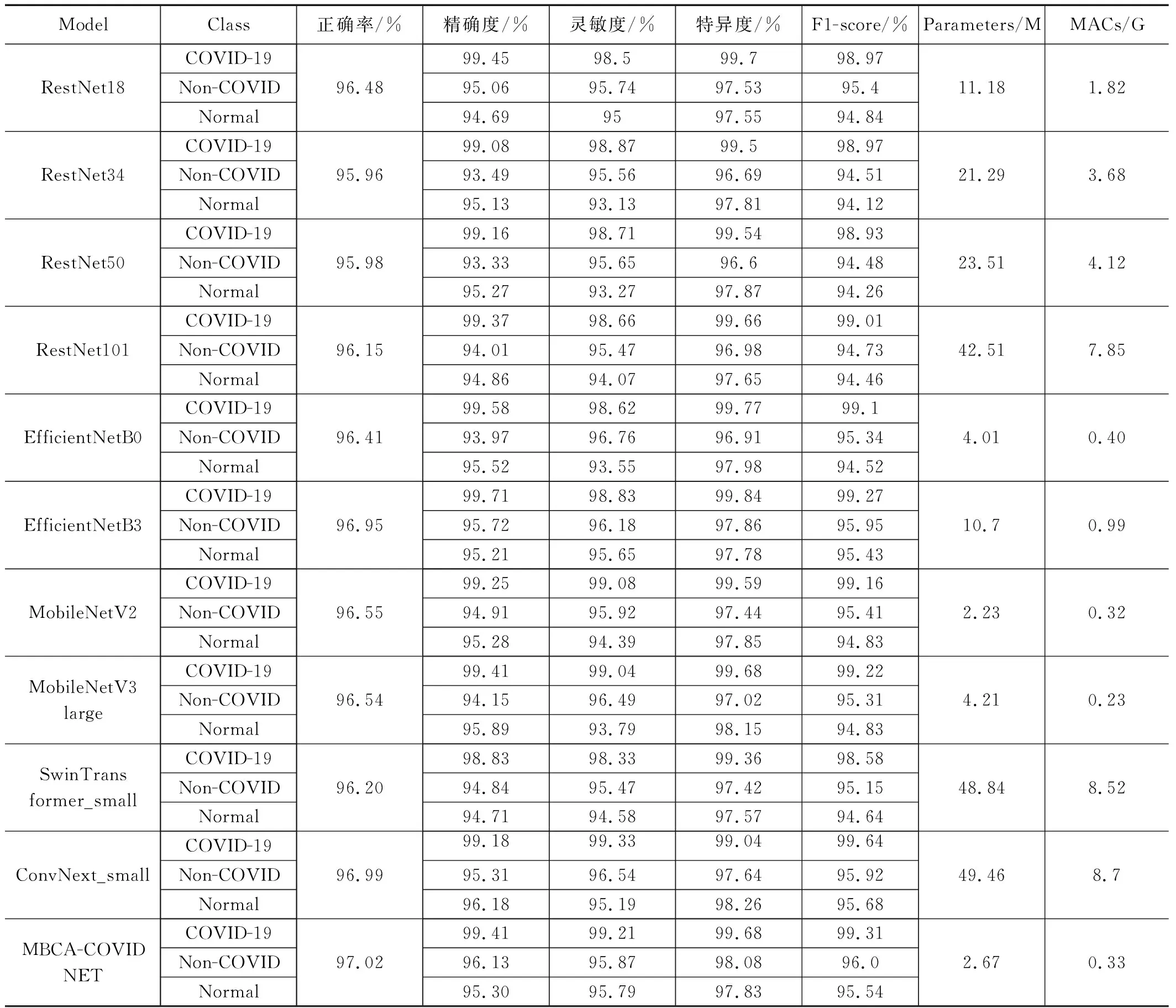
表2 各深度学习模型在COVID-QU-Ex数据集上的性能对比
图7 各深度学习模型在COVID-QU-Ex数据集上的混淆矩阵
对比MBCA-COVIDNET模型和MoblieNetV2模型,可以发现正确率前者比后者提升了0.47%,参数量前者仅比后者多0.44 M,计算量前者比后者多0.01。同时也证明了MoblieNetV2加入CA注意力机制的有效性。
通过观察MBCA-COVIDNE模型在测试集上的混淆矩阵,可以发现,2 395例COVID-19测试影像中正确预测2 376例,4例预测为Non-COVID类别,15例预测为Normal类别。预测正确率为99.41%,灵敏度为99.21%,特异度为99.68%,F1Score为99.31%;2 253例Non-COVID测试影像中正确预测2 160例,7例预测为COVID-19类别,86例预测为Normal类别。预测正确率为96.13%,灵敏度为95.87%,特异度为98.08%,F1Score为96.0%;2 140例Normal测试影像中正确预测2 050例,7例预测为COVID-19类别,83例预测为Non-COVID类别。预测正确率为95.30%,灵敏度为95.79%,特异度为97.83%,F1Score为95.54%。实验证明该模型对COVID-19影像分类正确率要高于其它2个类别。而其它2个类别的影像分类正确率低的原因,主要是模型将部分Non-COVID类别影像预测为Normal类别,将部分Normal类别影像预测为Non-COVID类别造成的。
3.3 消融实验
为了更好地训练一个轻量化的模型,本研究做了如下3个消融实验。
1)针对CA模块中的非线性激活函数,对比了RELU、RELU6、SiLU、LeakyReLU、Mish 5个激活函数,结果表明RELU6激活函数效果更好一些,具体情况详见表3。

表3 CA模块中不同激活函数的性能对比
2)为了验证在COVID-QU-Ex数据集上CA注意力模块优于其它注意力模块,以MobileNetV2为基础,对比了加入SE模块、CBAM模块以及CA模块后的效果,结果表明MobileNetV2+CA的正确率要优于MobileNetV2+CBAM和MobileNetV2+SE,而且针对该数据集MobileNetV2+CBAM和MobileNetV2的正确率差别不大,具体情况如表4所示。
表4 MobileNetV2中加入不同注意力模块的性能对比
3)本文也尝试了两种不同的数据增强策略,第一种用到了Albumentations[19]库中RandomGamma、RandomBrightnessContrast、CLAHE、Blur、MotionBlur、MedianBlur、HorizontalFlip、ShiftScaleRotate数据增强方法的组合;第二种用的是TrivialAugment。同时训练模型的迭代次数也从之前的30次增加到了50次,使得模型更好的收敛。实验结果表TrivialAugment数据增强的效果更优,详见表5。

表5 不同数据增强策略的性能对比
3.4 类激活图可视化
由于神经网络模型需要大量的数据来训练,是以数据驱动的方式创建的,因此通常认为神经网络是一个“黑盒”,其做出的分类缺乏可解释性。为了对MBCA-COVIDNET模型的分类决策进行解释,本研究利用Grad-CAM[20]技术,在胸片上进行了类激活图可视化,如图8所示。从图中可以看出该模型关注的影像区域较为合理,覆盖了肺部感染区域,能够辅助医生发现病灶,有助于医生对患者的诊断和治疗。

(a)~(c)为数据集中新冠肺炎患者原始胸部X光片样例;(d)~(f)为新冠肺炎患者肺部边界区域;(g)~(i)为新冠肺炎患者类激活图。图8 MBCA-COVIDNET新冠影像类激活图
4 结束语
本文利用MobileNet网络结构并与CA注意力模块相结合,构建了一个针对胸片的COVID-19检测模型MBCA-COVIDNET。该模型在COVID-QU-Ex Dataset数据集上的三分类任务中,采用了TrivialAugment图像预处理、迁移学习以及一系列训练技巧,最终在测试集上取得了97.98%的准确率,该模型比之前较先进的COVIDLite模型提升了0.8个百分点,同时该模型的参数量和计算量也均处于较低水平,易于在各种硬件上进行部署。
为了更好地演示该模型,利用Hugging Face[21]开源软件开发了一个COVID-19智能辅助诊断演示系统。该开源软件可以非常容易的将训练好的模型托管到Hugging Face Spaces中,只需编写一个app.py文件,就可以很方便地随时随地进行系统的演示,软件界面如图9所示。
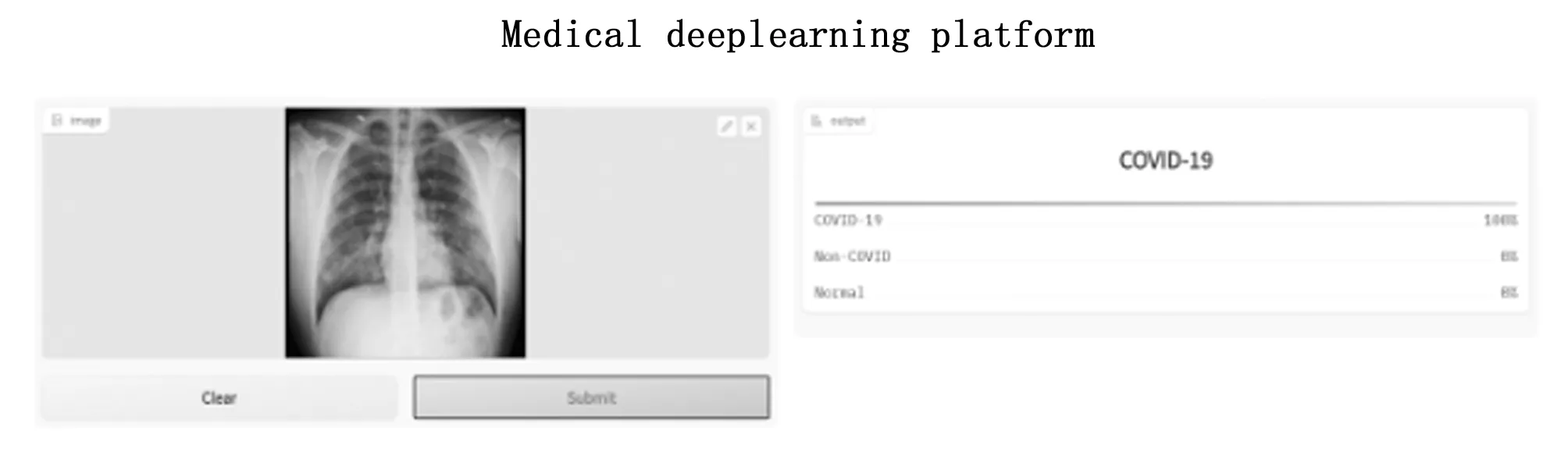
图9 Hugging Face系统界面
同时,为了使训练好的模型能够真正地应用于临床实践,而不是停留在实验室阶段,利用Flask开发了一个COVID-19的web应用程序,Flask是一个使用 Python 编写的轻量级 Web 应用框架。该系统能够辅助医院工作人员,快速的判断CXR影像的类别。具体操作步骤如下:1)点击选择文件按钮,加载一张待检测的影像;2)点击预测按钮,系统会使用训练好的模型,对该影像进行预测,并且给出预测为各个类别的概率。经过实际测试该系统在普通的笔记本电脑上就可以部署并且能够流畅运行,具有极佳的用户体验。系统界面如图10所示。
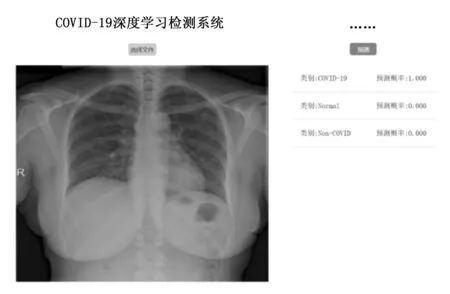
图10 COVID-19深度学习检测系统界面
本研究的局限性:1)训练好的模型未能在更多的数据集上做测试,特别是当前新冠病毒进行了多次变异,针对感染变异后新冠病毒患者的胸部X光片,该模型的泛化能力有待进一步验证;2)训练模型的数据集来源单一,没能做到多中心;3)训练模型完全依赖于胸部X光片未能结合患者的临床相关数据;4)该模型最终功能只实现对胸部X光片进行新冠肺炎、其它肺炎、正常三分类任务,未能指出新冠肺炎感染的严重程度。
下一步研究工作可在现有研究的基础上,收集、标注新冠肺炎感染区域并训练一个感染区域分割模型,从而实现利用胸部X光片对新冠肺炎感染严重程度进行量化分析。
