基于深度学习的荧光图像成分分类
2023-04-19何小海滕奇志
王 爽, 何小海, 滕奇志, 龚 剑
(1 四川大学 电子信息学院, 成都 610065; 2 成都西图科技有限公司, 成都 610065)
0 引 言
在荧光显微技术中,将赋存于烃源岩及储集岩中的石油统称为发光沥青,发光沥青可分为油质沥青、胶质沥青及沥青质沥青。 其中,油质沥青发出黄、绿、蓝色的荧光,胶质沥青的荧光以橙色为主,沥青质沥青以褐色为主[1]。 沥青组分的荧光色彩特性对于分析研究不同沥青组分的类别、含量以及发光颜色等数据至关重要。 在实际的工作环境中,荧光产生的机理是通过紫外光或蓝光等激发光源的照射,岩石中石油的烃类会发出波长较长的可见光。故而对于不同的激发光源,得到的荧光图像不同,如图1 所示。 同时由于不同地区地质结构的多样性,不同地区、不同层位的油发出的荧光颜色也会有所差异。 为了得到沥青的种类和含量,目前的做法是用阈值分割方法先把荧光部分提取出来,再根据ISODATA 聚类算法[2]利用每个像素点的颜色信息进行成分分类,再将分类结果保存为划分文件,此过程速度较慢,并且不同荧光的色彩差异性会导致分析结果的不准确。 图2 是用ISODATA 聚类算法生成的同一划分文件对不同光源激发的荧光图像进行分类的结果。 由图2 可以看到由于激发光源不同,同一荧光图像的分类结果是不同的,这显然是不对的。 为了得到正确的结果,需要对不同色彩表现的荧光图片分别聚类,生成不同的划分文件,随后在实际分析过程中,选择对应的划分文件进行分析,但此过程较为繁琐。
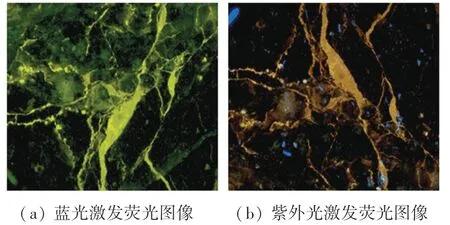
图1 不同激发光源下的荧光图像Fig. 1 Fluorescence image under different excitation light sources

图2 同一划分标准对不同激发光源的荧光图像(图1)下的分割结果Fig. 2 Segmentation results of fluorescence images (Fig. 1) of different excitation light sources with the same division standard
此前,用于解决色彩差异问题的方法是对荧光图像进行色彩迁移。 Reinhard 等学者[3]提出了一种适用于大部分彩色图像的色彩迁移算法,该方法的缺点是迁移结果中损失了较多的颗粒以及孔隙细节。 庞战[4]提出的基于FCM 的局部迁移算法,相比于全局彩色迁移算法,虽然细节更为丰富,但存在匹配关系不够准确的问题,偶尔会产生错误的色彩迁移结果。 王杰[5]提出的改进的松弛化最优传输荧光图像色彩迁移方法虽然在整体色彩准确性和稳定性等方面比前述的两者都好,但是也会出现局部色彩误迁移的问题。
近些年随着深度学习的迅速发展,图像语义分割结合了图像分类、目标检测和图像分割技术,通过一定的方法逐像素点进行分类,再进行区域划分,最终得到一幅具有像素级的分割图像。 2012 年,卷积神经网络(Convolutional neural network,CNN)、尤其是Kkrizhevsky 等学者[6]提出的AlexNet 模型,在计算机视觉领域取得了重大突破,成为图像分类、对象检测、目标跟踪和图像分割等计算机视觉领域任务中性能优异、且获广泛应用的深度神经网络学习模型[7]。 卷积神经网络主要由4 个部分组成,分别是:卷积层、池化层、全连接层以及softmax分类器[8],通过对卷积层和池化层进行一系列的叠加, 能够获得更深层次的网络结构,如VGGNet[9]、ResNet[10]等网络。 这些深度学习方法能够自动学习图像中的有效特征从而进行分类,免除了传统荧光图像分析方法中人工交互以及需要对不同激发光源分开聚类产生划分标准的繁杂过程。 因此,本文提出了基于深度学习的荧光图像分类技术。
1 本文方法
VGG 模型是由Simonyan 等学者[9]于2014 年提出的一种通过增加卷积神经网络的深度来提高识别性能的网络,其中最佳网络包含16 个权值层。 VGG模型由于其基于微小滤波器尺寸的设计,已广泛用于分类和定位任务,基于VGG 架构的网络则已在检测和分割[11-12]等方面进行探索与研究。 一般来说,网络越深,特征提取能力越强。 然而,下采样可能会导致低层特征丢失。 UNet 使用跳跃连接将低层特征与高层特征进行融合,能够保留高分辨细节信息。因此本文采用结合VGG16 与UNet 的方法来构建网络,在VGG16 模型的基础上,将最后的3 个全连接层替换为UNet 解码器部分的结构。 用VGG16 网络作为编码器部分进行主干特征提取,产生低分辨率的图像;UNet 作为解码部分进行加强特征提取,将低分辨率图像映射到像素级别的预测上去;同时增加注意力机制来防止像素级信息的缺失,提高特征提取的准确性。
1.1 编码器模块
VGG 的核心思想是利用多个小卷积核代替大卷积核,既可以保证感受视野,又能够在减少卷积层参数的同时提升网络的表达能力。 近年来,VGG 网络衍生出了A ~E 七种不同的层次结构,本文使用的是其中的D结构,也就是VGG16,主要包含了13个卷积层、5 个池化层和3 个全连接层。 一般来说,池化层、也即下采样层,分为最大池化和平均池化两种,主要位于连续的卷积层之间,用来压缩图像的特征尺寸。 而在VGG16 网络中使用的是最大池化方法,在几个卷积层之后续接一个最大池化形成了一个block。 卷积层、池化层用来将原始图像数据映射至特征空间中,最后的3 个全连接层以及softmax分类器则用来将映射后的特征进行分类。 VGG16 网络结构如图3 所示,由图3 可知,该结构共包括5 个block,每个block 的通道数一致,最大池化层用来减少特征图的尺寸[13]。
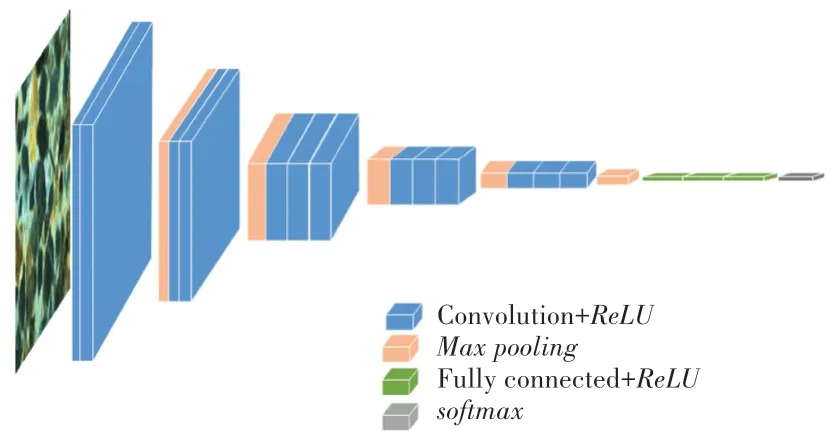
图3 VGG16 网络结构Fig. 3 VGG16 network structure
1.2 解码器模块
UNet[14]是2015 年首次提出用于生物医学图像分割的功能强大的卷积神经网络架构之一。 这是一个“U”型对称网络结构,由编码器和解码器两个通用部分组成。 编码器能够捕捉上下文信息,完成图片的下采样。 编码部分遵循交替卷积和池化操作的卷积网络的典型架构,并逐步向下采样进行特征映射,同时增加每层特征映射的数量。 每层通过对2个3×3 的卷积核、ReLU函数,包括一个2×2 的最大池化核进行操作,一共经过4 次相应的下采样操作后,特征图的宽度得以减小,通道数翻倍,从而能更好地完成对像素点的特征提取。 解码器部分能够实现精确定位,主要用于特征图的上采样。 通过对特征图的上采样以及卷积操作处理后,又融合了编码部分对应的特征图,进一步增加了输出的分辨率,从而逐步恢复特征图像的像素信息及图像精度。 UNet将特征图从编码器的每一层传递到解码器的类似层,就使得分类器可以依据不同规模和复杂性的特征来做出决策。 这种架构已被证明对于数据量有限的分割问题非常有用,网络结构如图4 所示。

图4 UNet 网络结构Fig. 4 UNet network structure
1.3 注意力机制
随着深度学习的迅速发展,注意机制在图像分类以及语义分割中也得到了大范围的应用。 卷积运算的原理是将空间层次特性图的局部特性与通道层次特性图的局部特性加以相互融合,进而得到多维多尺寸的空间结构信息。 但是,各个通道所含信息内容的重要性也因图像分类任务的差异而有所不同,如果不加以区别地整合每个通道的信息内容,那么在某种程度上会丢失许多重要的信息。 因此,Woo 等学者[15]于2018 年提出了一种轻量的注意力模 块 ( Convolutional Block Attention Module,CBAM),可以在通道和空间维度上增加注意力,并且在ResNet 和MobileNet 等经典结构上添加了CBAM 模块并进行对比分析,同时也进行了可视化,发现CBAM 更关注目标物体识别,这也使得CBAM具有更好的解释性。
CBAM 由通道注意力模块和空间注意力模块组成[16]。 其中,通道注意力模块是一种考虑特征图通道之间关系的注意力机制,突出输入图像提供的代表性信息。 空间注意力模型能够帮助神经网络系统,使其更注重图片中那些对图像分类起着决定性意义的关键像素区域而忽略那些无关紧要的区域。实验证明,输入特征先指向通道注意力模块、再指向空间注意力模块效果会更好。
给定一个中间特征映射F∈RC×H×W作为输入,CBAM 按顺序推断出一个1D 的通道注意映射Mc∈RC×1×1和一个2D 的空间注意映射Ms∈R1×H×W, 总的作用公式[17]可描述为:
其中,“ ⊗”表示元素级乘法;F表示输入特征图;F1表示经过通道注意力加权得到的特征图;F2表示经过空间注意力加权得到的特征图;Mc(F) 表示通道注意力输出权值;Ms(F1) 为空间注意力输出权值。 整体结构如图5 所示。

图5 CBAM 模块结构Fig. 5 Structure of CBAM module
1.4 整体VGG16-UNet 网络模型
本文所用的整体网络的结构框架如图6 所示。图6 中,左半部分是编码器部分,有5 个子模块。 设计上整合了原始VGG16 的13 个卷积层以及4 个池化层,实现下采样。 网络的右半部分是解码器部分,也有5 个块。 每个块后面是一次上采样操作,用于恢复图像的尺寸。 此外,每层之间有一组跳跃连接用于恢复图像的尺寸,这些跳跃连接是使用连接操作去组合相应的特征映射来实现的。 由于这是用于语义分割的全卷积神经网络FCN 的变体,需要保留图像的空间维度信息,因此需要使用跳跃连接。 最后一个卷积层只有一个滤波器,这与大多数其他神经网络的最后一个密集层相似,并给出二进制掩码预测。 对于网络的瓶颈中心部分,本文去掉了VGG16 最后的3 个全连接层,取而代之的是通过上采样直接把特征图放大成一个与编码器同层部分具有相同尺寸的图像。 此外,本文还在编码器部分提取出来的所有有效特征层上增加了注意力机制。

图6 VGG16-UNet 整体网络结构Fig. 6 VGG16-UNet overall network structure
2 实验
2.1 数据集
本文使用的数据集均是通过高清相机在显微镜下对不同石油地质部门的荧光薄片进行拍摄而得的,随后对采集到的图像进行裁剪,裁剪后数据集中的原始图像大小均为512×512。 本文实验所用数据集共有1 199张,包括蓝光激发的荧光图像和紫外光激发的荧光图像,如图7 所示。 训练集和测试集按照9∶1的比例,即用作训练数据1 079 张,测试数据120 张。

图7 数据集图示Fig. 7 Dataset images
实际研究中,考虑到在显微镜下采集到的荧光图像的尺寸通常是远大于512×512 的,所以在预测时会对原图进行预处理,首先将原图裁剪为512×512 的图片,然后用训练后的模型分别对每一个裁剪后的图进行预测,接着将预测后的图加以拼接,最后可以得到一整张荧光图像分类结果图。
2.2 实验设置
在本次实验中,硬件环境为Ubuntu 20.04 LTS操作系统,CPU 的型号为i7-9700,GPU 型号为GeForce RTX 2080 Ti 以及32 GB 内存。 开发环境采用的是Pytorch 深度学习框架。 在训练过程中,初始学习 率 为1 × 10-4,BatchSize为4, 共 训 练100epoches,每个epoch总共训练1 199 张图。 同时,使用Adam 优化器,因为Adam 算法能够自适应调节学习效率。
卷积层使用ReLU激活函数,该函数是从底部开始半修正的一种函数,数学公式具体如下:
其中,x表示输入。
对岩石荧光薄片图像的石油成分进行提取,是一个多分类问题。 对于分类问题,最常用的损失函数是交叉熵损失函数(Cross Entropy Loss)。
在二分类的情况下,网络预测的结果最终只有2 类,假设对于每个类别预测的概率分别为p和1 -p,那么此时交叉熵损失函数的计算公式为:
其中,y是样本标签,正样本标签为1,负样本标签为0;p表示预测为正样品的概率。
本文是一个多分类问题,多分类的交叉熵损失可表示为:
其中,K是种类数量;yi是一个One-hot 向量,除了目标类为1 之外其他类别上的输出都为0;pi是神经网络的输出,也就是类别i的概率。
2.3 评价指标
为了评估系统的有效性,本实验采用了语义分割中最常用的评价指标, 分别是精确率(Precision)、 像 素 准 确 率 平 均 值(mean Pixel Accuracy,mPA) 和平均交并比(Mean intersection over union,mIoU)。 这些指标可以衡量每个像素值的分类对整个分类任务的性能。 对于多分类问题,假设总共有k +1 个类别(包括背景),Pij是类i被推断为属于类j的像素数量。 也就是说,Pii表示分类正确的真正数(真正例TP +真负例TN),而Pij和Pji通常分别被解释为假正例FP和假负例FN。 对于本次实验中采用的评价指标,可做阐释分述如下。
(1)精确率:在全部预测为正的结果中,被预测正确的正样本所占的比例。 推得的数学定义公式为:
(2)mPA:对每个类计算正确分类的像素数量与所有像素数量的比值,再对类总数取平均。 推得的数学定义公式为:
(3)mIoU:这是用于图像分割问题的标准评价指标。 具体就是2 个集合(原始图和预测图)的交集和并集之间的比例。 在本实验中,则表示真实分割图和系统预测的分割图之间的交并比。 该比例可以看作交集(真正数)与总数(包括真正数、假正例、假负例)的比值。 最后也是按类别取平均。 由此推得的数学定义公式为:
2.4 组件消融实验
为证明本文提出的用UNet 作为编码部分以及注意力机制模块对网络的有效性,分别进行了实验比较上述模块对结果的影响。 实验结果见表1。 从3 组实验可以看出,VGG16+UNet 模型相较于原始VGG16 网络,各个分类评价指标都有了大幅度的提升;同时添加了注意力机制的模型能取得最佳效果,也说明了注意力机制对整个模型框架的有效性。
2.5 结果分析
图8 展示了训练过程中的一组训练参数曲线图。 图8(a)是损失函数曲线图,图8(b)是mIoU曲线图。 横坐标表示训练的次数,纵坐标分别表示训练损失值以及平均交并比。 由图8 可以看出,损失值随着训练次数的增长而逐步收敛到一个下界,而平均交并比则随着训练次数的增长而逐步增大。 损失函数中间凸起的原因是训练过程分为2 个阶段,分别是冻结阶段和解冻阶段。 设置冻结阶段是为了满足机器性能不足时的训练需求,此过程需要的显存空间较小,可以根据显卡情况动态设置参数,解冻阶段占用的显存空间较大,网络的参数也会随之发生改变。
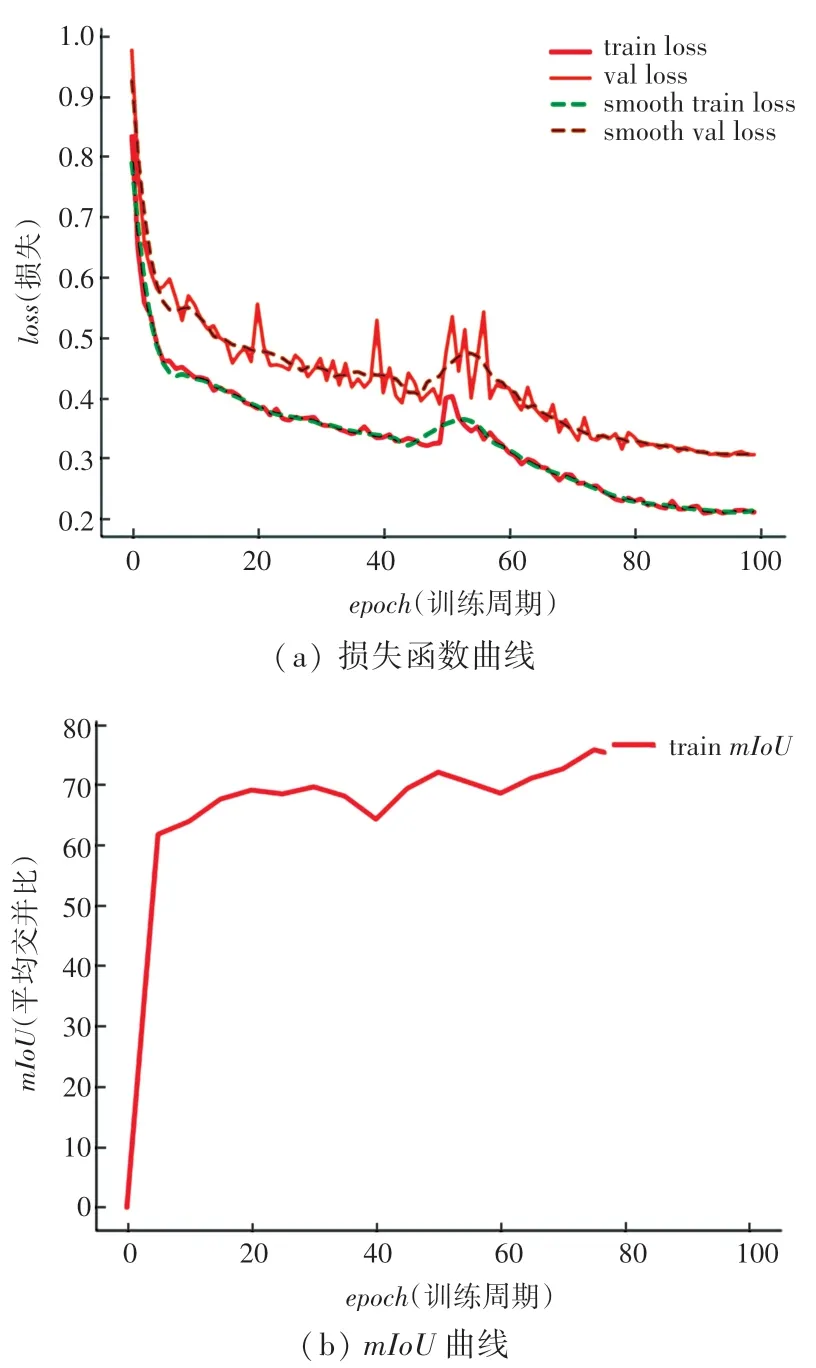
图8 训练参数曲线Fig. 8 Training parameters curve
为了客观验证本文所用网络的分类性能,使用了相同的数据集分别在ResNet、PspNet 等主流分割网络上进行了对比实验,表2 为不同网络模型在3个评价指标上的结果。 由表2 可以看到,本文所使用的方法在各个指标上都有一定的优势。
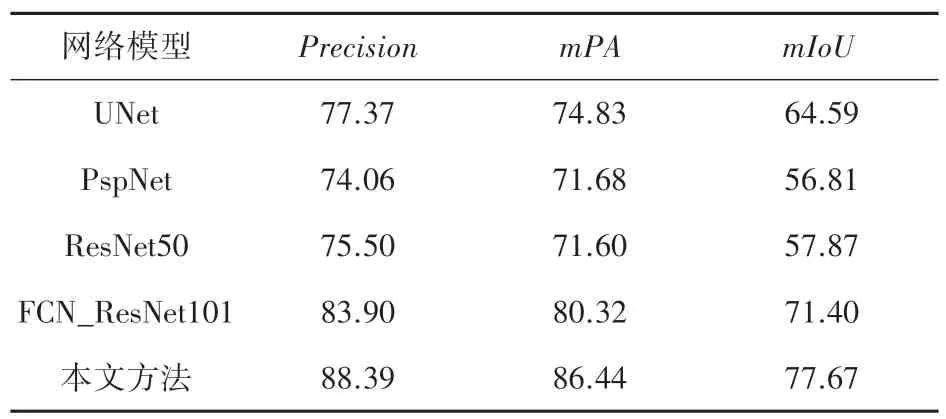
表2 不同网络模型下荧光成分分类结果评价指标Tab. 2 Evaluation indicators for classification results of fluorescent components under different network models
同时,本文还选取了不同尺寸大小的荧光图片,在分类时间上与传统ISODATA 聚类方法做了对比,结果见表3。 由表3 可以看到,在不同尺寸的图像下,本文的运行时间都优于传统算法,尤其是在大图下,其时间性能上的优势则体现得更加明显。

表3 荧光成分分类运行时间对比Tab. 3 Comparison of fluorescent component classification operation time ms
最后,为了直观地感受本文的分类效果,图9 给出了表3 中的4 张荧光图像的分类结果,包括了不同激发光源下的岩石薄片荧光图像。 图9(a)是原始荧光图像,图9(b)是用本文的深度学习方法分类的结果图,图9(c)是用ISODATA 聚类算法分类的结果。 从结果可以看到,本文分类的结果在整体上没有出现误分类的情况,并且相较于ISODATA 聚类算法不会出现太多孤立的噪点,见图9(c)中第一列标出来的区域。 在对整张荧光图像进行分类时,ISODATA 聚类算法有时会把不发光的部分划分为沥青质,而本文算法的分类结果则不会出现此问题,见图9 中第三列图标记的部分。
3 结束语
本文针对岩石荧光薄片图像在荧光成分提取上需要大量人工交互,并且对于不同色彩差异的荧光图像需要分开聚类并产生不同的划分文件的问题,提出了一种基于深度学习的荧光图像成分分类技术。 该方法在VGG16-UNet 的网络技术基础上融入了注意力机制,UNet 框架实现了端到端的自动分割;VGG16 用较小的卷积核既有利于提高感受视野,又有利于在减小卷积层参数的同时提高网络的表现力;同时融入注意力机制模块,增加特征信息内容的学习权重,抑制无关背景信息内容的影响。 通过一系列实验数据比对分析,分类结果不论是在主观效果上、还是在客观指标上都有一定的优势。 对多个不同油田采集的荧光薄片图像进行实验,均取得了较好的分类结果,实验结果也说明,该模型具有良好的性能,并且减少了传统荧光成分分析过程中的人工交互过程。 后期将考虑在保证有效性的前提下,优化网络模型,进一步减少参数量,将算法应用于实际工程中。
