多层次过采样集成的不平衡数据缺陷预测模型
2023-04-19饶珍丹李英梅
饶珍丹,李英梅,董 昊,张 彤
(哈尔滨师范大学 计算机科学与信息工程学院,哈尔滨 150025) E-mail:yingmei_li2013@163.com
1 引 言
随着日常生活变得越来越智能化,人们对软件系统的依赖逐渐加深,软件质量的保障也越来越重要.而软件中缺陷量的多少直接关系到了软件质量的优劣,产品中不满足软件要求或者损害用户体验感的缺陷,倘若未在早期被定位出来,应用后缺陷查复和修复成本则会大大增加.所以为了减少软件中的缺陷数量,测试人员通常会对产品进行彻底的筛查.然而逐一对软件模块进行检测的方法随着软件产品的复杂化、差异化而变得越来越费时费力.在上个世纪90年代初,研究人员就发现:缺陷的出现不是杂乱无章的,而是具有相对分布规律的,规律服从着“2-8 原则”即80%的缺陷分布在20%的程序模块中.软件缺陷预测的作用就是在开发过程中更早的预测到含缺陷更多的模块,帮助开发人员优先分配有限的测试资源,加快生产率,从而降低软件修复代价.软件缺陷预测技术的出现对软件工程的发展具有非常关键的作用.
机器学习是软件缺陷预测中常用的分类方法,它能利用标记数据来训练分类器,在训练过程中运用相关分类规则对测试数据进行分类预测.但是传统的机器学习在缺陷类和非缺陷类数目比大致相等时,才能拥有良好分类性能.然而现实中,在诸如医疗检测[1]、破产预测[2]、欺诈检测[3]、入侵检测[4]、工业故障检测[5]等许多实际工作领域中,异常事件数据的存在通常只有百分之一,分类器就是将所有事件都识别为正常事件,都能得到99%的准确率.显然只关注准确率的高低对缺陷预测来说是不合理的,对存在故障的少数类数据进行准确预测才更符合以降低成本为目的的实际情况.
进行软件缺陷预测的数据集里,缺陷类占比往往比非缺陷类更小,这种现象被称为类不平衡现象.该现象的存在是导致分类器性能低下和有偏向的主要原因.将这样的数据强行放入机器学习中进行训练,算法将由于没有足够的缺陷类样本信息而无法对该类进行准确的分类学习,最终导致假性正常分类率增加,造成更大的损失.因此,提高机器学习分类的有效方法之一就是通过加强不平衡数据中少数类的数量占比或权重占比缓解类不平衡问题,以提高少数类的分类性能.
针对软件缺陷预测中不平衡数据的分类问题,许多研究者在重采样[6-8]、集成学习[9-11]和代价敏感方向[12-14]都进行了大量的研究.然而最直观还是独立于分类器通过物理方法对数据分布进行处理,将失衡现象变得平衡的重采样方法.本文基于现实生活中类失衡现象的分布特性,在数据处理层面经过多种采样方法的文献阅读与实验分析,提出了一种基于过采样和集成学习的不平衡数据软件缺陷预测模型XG-AJCC.
XG-AJCC的构建分为两个阶段:
1)过采样预处理阶段:该阶段提出了AJCC-Ram方法,该方法基于改进的ADASYN自适应过采样和CURE-SMOTE过采样分别在类边缘和类中心多层次生成新样本形成平衡数据集,通过CLNI进行平衡数据集的噪声过滤清理.
2)模型构建阶段:与集成算法XGBoost结合形成最终的不平衡数据缺陷预测模型.
本文在AEEEM数据集和NASA数据集中对AJCC-Ram方法及XG-AJCC模型进行了实验验证,结果表明:提出的方法较于经典的采样方法和采样集成相结合的不平衡数据缺陷预测模型,在F1指标上均能够取得有效的预测结果.
2 相关研究
与代价敏感和集成学习两种技术相比,数据层面的采样方法能够真实反映研究对象的性质,可以作为一种预处理方法嵌入到集成学习算法中,具有简易性和通用性.而集成学习是融合多个基分类器或采样方法通过投票或求平均值来组成总预测模型的方法,能够有效的提高整体预测性能,提高泛化性.
2.1 采样方法研究
根据对多数类进行删减、对少数类复制、增添或两者都进行改变等方式不同.重采样技术又分为欠采样、过采样和混合采样.在所有的重采样方法中,随机过采样和随机欠采样是平衡数据集最简单的采样方法,但其缺点也是显而易见的(容易过拟合或易删除重要信息[15]),采样后的数据容易缺乏代表性.近10年来,许多研究者致力于通过研究更好的重采样方法来降低数据不平衡比率,从而提高分类器的性能.
在欠采样中,Liu[16]等人运用集成思想提出了EasyEnsemble和BalanceCascade算法,有效的缓解了关键样本信息易丢失的问题.Tsai[17]等人提出了基于聚类的欠采样实例选择算法CBIS.该算法聚类将多数类的数据分为多个子类,并从每个分组中通过实例选择过滤掉不具代表性的数据样本,以此提升分类性能.ClusterCentroids方法通过KMeans对各类样本进行聚类,将聚类中心作为新样本点,以此达到欠采样效果.Tomek Link和Edited Nearest Neighbours方法分别通过对类别不同的最近邻噪声对中的多数类数据和K近邻数类别差异大的多数类数据进行了数据清洗,达到了欠采样的目的.
然而以数据清洗来进行欠采样的缺点是无法控制删除数量的多少,只能稍微缓解类不平衡问题,不能有效的将数据平衡.其他的欠采样的改进算法中即使能避免部分重要信息的丢失,但是却不能加强缺陷类样本的分类准确性,故而在大量的软件缺陷预测实验中,过采样是较优于欠采样的.令预测样本中缺陷数占比增加是缓解不平衡数据、提升缺陷类样本分类性能的有效方法之一.
在过采样中,Chawla等人[6]提出了合成少数过采样SMOTE算法:其假设是距离越近的实例比距离更远的实例更相似,故使用KNN算法通过随机线性公式计算邻域和小类样本并从中进行插值生成.过采样在采样区域方面又可以分为边界区采样和中心区采样.
边界区采样:当选取的少数类样本周围K近邻也都是少数类时,对该样本进行SMOTE插值合成新样本可能不会对分类产生很大的价值作用,就像SVM中远离边界的样本点对决策的影响不大.因此,加强缺陷边界的分类成了许多研究人员在过采样领域的研究方向之一.Han等人[18]为强调边界的重要性提出了Borderline-SMOTE采样,该采样强调在位于边界处的缺陷和其最近邻之间合成少数类样本,使类别边界界线变得更清晰,从而提高了预测模型的性能.He等人[7]为加强少数类的边界清晰度提出了ADASYN自适应算法,算法根据小类样本点周围大类样本数量占比,通过自适应地分配取样权重将新合成的少数实例集中于边界区域.Gong L等人[19]为了改善SMOTE算法样本合成实例分布在小范围内缺乏多样性的问题,提出了KMFOS方法,该方法应用Kmeans聚类将缺陷样本分为K个簇,在簇与簇间根据两簇缺陷占比插值生成新的实例,将生成的缺陷实例分散在缺陷空间中.
中心区采样:是指将使新样本限制在一定区域内,由区域内的点之间随机生成新样本点.中心区采样可以缓解样本分散程度,使得其分布更加集中,以减少噪声样本或离群样本的生成.赵清华等人[20]根据随机森林和SMOTE组合算法在不平衡数据集上存在数据集边缘化分布以及计算复杂度大等问题,提出TSMOTE和MDSMOTE算法,目的是将新少数类限制在一定区域类,具有中心化特性,从而降低算法复杂度.Bejjanki K K等人[21]计算少数类样本所有的属性,提出了一种质心与质心之间插值合成新样本的技术CIR,而样本质心是由缺陷与其两个近邻缺陷构建的三角形成的.Douzas G等人[8]通过将样本进行KMeans聚类,过滤少数类密度较高的簇,将剩下的少数类含量稀疏的簇进行SMOTE采样,提出了KMeansSMOTE聚类采样算法.该方法首先通过仅在安全区域进行过采样来避免产生噪声缓解了类间不平衡问题,又通过增加少数类稀疏的簇内样本的缓解了类内不平衡问题.Ma L等[22]人通过分层聚类算法CURE,提出了CURE-SMOTE采样.该方法通过分层聚类清除离群点的数据,生成了各个簇的中心点和代表点,通过以上两点之间插值生成新样本,减少了噪声生成.CURE-SMOTE能够有效防止过拟合,保证样本数据的原始分布属性.
本文结合Border-line SMOTE的思想,按少数类采样点的K近邻中缺陷类和非缺陷类的占比将该点分为两类,即边缘类和中心类(边缘类指该少数类样本点K近邻中有一半以上为非缺陷类.中心类指该少数类样本点K近邻中有一半以上为缺陷类).在边缘采样时采用对ADASYN的改进算法,在中心采样时将采用CURE-SMOTE算法,分层次进行样本生成.采样点类别划分如图1所示.

图1 采样点类别划分图Fig.1 Classification diagram of sampling points
2.2 噪声研究
在数据挖掘过程中,训练集里存在的噪声也会影响到机器学习的分类性能.(噪声指存在于数据集中,对分类器性能的提高产生抑制作用的劣质数据.)在类不平衡采样中,边界处样本生成的增多可能会导致类边界重叠,具有边界模糊、分类复杂度加重等危害,这与采样加强边界清晰度的初衷有所冲突.所以对数据集进行噪声识别及清理是提高采样后分类性能的有效方法之一.
Tang等人[23]认为离群样本点更可能是噪声点,故提出一种定义方法检测离群点噪声因子,并将噪声因子大的点进行移除.实验表明,噪声点的减少能够提高准确率.Gupta等人[24]根据他们所提出的度量方法对327个二分类数据集计算了复杂度和重叠度,实验结果表明:噪声去除的训练数据可以更好的提高分类器的预测性能.Laurikkala等人[25]认为,分类结果的质量并不一定取决于类的大小,还应该考虑噪声等特性,从而提出了NCL邻域清洁方法,提高了少数类中困难类的识别.Kim等人[26]通过在数据集中人工添加假阳性或假阴性噪声,研究了数据质量对分类的影响.研究发现,当数据集同时具有以上噪声时,缺陷预测的性能会显著下降.因此,他们提出了一种噪声检测方法——最近列表噪声识别CLNI,CLNI噪声处理的思想是:基于每个实例的K近邻不同,认为所有类别的实例中都可能存在噪声,方法按照与该实例类别不同的前N个近邻的百分比进行记录,并将记录大于设定阈值的实例视为噪声删除,合理准确地识别错误样本.
不平衡数据采样和噪声清理都是对数据进行预处理的有效方法之一,部分学者通过将两者结合更好的提升了数据预测的可靠性.L Chen等人[27]为改善类重叠和类不平衡问题,将被邻域清洗NCL算法去除重叠后的非缺陷样本和其他原数据中的缺陷样本一起进行多次随机欠采样生成平衡子集,然后利用AdaBoost集成算法建立预测模型ERUS.
本文进行改进的ADASYN算法和原算法一样存在着部分不足:强调边界自适应样本的生成时,容易产生更多的噪声实例影响预测算法的性能.所以本文将在完成采样后将采用CLNI方法进行噪声过滤,可以更好的将随机生成的不合理样本与噪声的样本进行清除.
2.3 集成学习研究
集成学习的思想经常被用于分类器中,通常指通过融合多个基分类器组成总分类器,来有效的提高整体预测性能的方法.常用的集成学习的思想有:Bagging、Boosting、Stacking.Freund Y等人[9]通过对训练样本训练多个弱分类器,对每次分类误差大的运用投票法进行权值加重并迭代训练,提出了AdaBoost方法.该方法的优点是在学习中重点关注被错误分类的实例,从而提高分类正确率.
同样的,在不平衡数据集中,由于采样方法具有随机性,分类器分类可能产生偏差,故研究人员也会将具有能够有效提升预测并能持续稳定性能的集成学习思想运用于采样中,以获得更高效的解决类不平衡问题的软件缺陷预测模型.Chen等人[10]结合过采样和集成学习提出了RAMOBoost采样,RAMOBoost借助ADASYN思想根据少数类样本的分布比自适应地调整抽样权值,对少数类生成新样本进行排序.再通过AdaBoost集成,迭代提高了边界难学实例的权重.Huda等人[28]提出了一种结合多种过采样的集成采样预测模型,模型通过ROS、MWMOTE和FIDos采样分别与随机森林结合成基学习器,再进行分类器间的投票构建而成.戴翔和毛宇光[29]借助K-NN过滤法、SMOTE过采样和K-means聚类降采样运用集成投票的方式构成训练模型,解决了跨项目缺陷预测问题和类不平衡问题.张菲菲等人[30]通过将两类数据集划分成不同的子簇,再根据子簇概率分布改进了过采样方法,并将改进的过采样结合基分类器决策树运用AdaBoost集成构建了最终的分类模型.Jiang Y等人[31]同时考虑了类不平衡和标记样本少的问题,提出了Rocus半监督学习方法.该方法运用Bagging思想加入随机构造训练了各具多样性的基分类器.通过集成投票,在小规模不平衡数据欠采样处理中,提高了对少数类的灵敏度.进一步将其应用于半监督学习中,提升了半监督的分类性能.
本文也将数据预处理方法与集成学习XGBoost相结合,形成最终的软件缺陷预测模型XG-AJCC以提升分类性能.后续也将更进一步的把本研究的方法应用于半监督领域,缓解样本标记少的问题.
3 XG-AJCC过采样集成缺陷预测模型
3.1 研究动机
软件缺陷预测可以通过对历史仓库的挖掘,描写与之相关的度量信息形成数据集,通过机器学习等方法对数据集进行学习,以此构建有效的预测模型.然而现实中有缺陷的数据样本较少,会导致机器学习的分类偏向于对多数类,在软件缺陷预测中深深的影响模型的分类性能.因此采用一定的方法缓解类不平衡问题是很有必要的.本文就类不平衡问题基于ADASYN算法和CURE-SMOTE算法提出了一种自适应判断聚类随机采样AJCC-Ram(Adaptive Judgment CureClustering Random Sampling),并与集成学习XGBoost相结合形成软件缺陷预测模型XG-AJCC.
3.2 算法框架
本文的算法框架包括以下3部分,其中第1部分为整体框架图.
3.2.1 缺陷预测模型XG-AJCC的整体框架图
如图2所示,实验将初始数据分为1∶9,取90%为训练数据集,并进行AJCC-Ram采样预处理,预处理后的平衡数据放入调试好参数的XGBoost集成学习中,形成了最终的XG-AJCC不平衡数据软件预测模型.剩下10%的初始数据放入该模型可以进行分类预测的测试.

图2 缺陷预测模型XG-AJCC整体框架图Fig.2 Overall frame diagram of defect prediction model XG-AJCC
3.2.2 AJCC-Ram算法的框架图
图3是AJCC-Ram采样预处理算法的详细框架图,算法根据少数类样本的K近邻的类别数将其分为两个分支,即两个层次:
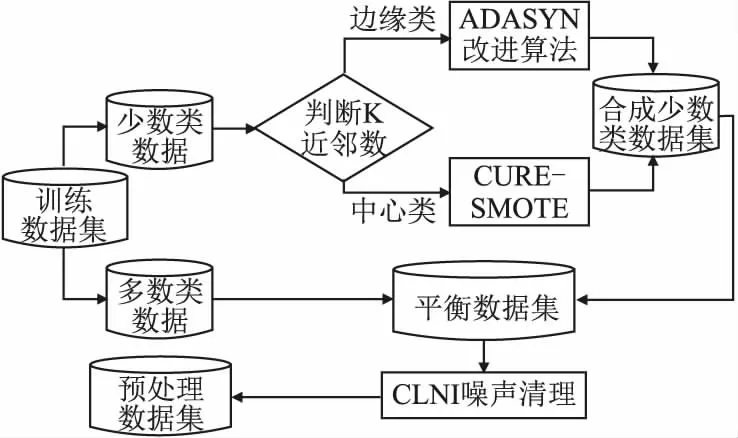
图3 AJCC-Ram采样算法框架图Fig.3 Frame diagram of AJCC-Ram sampling algorithm
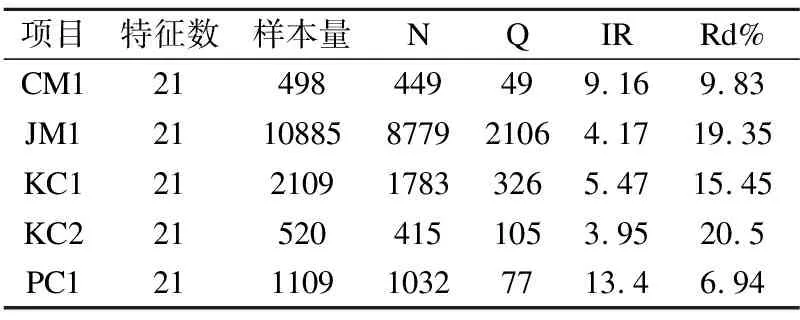
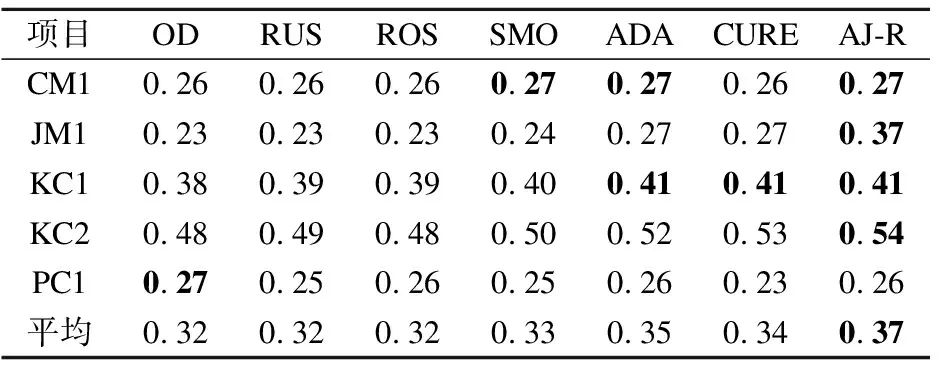
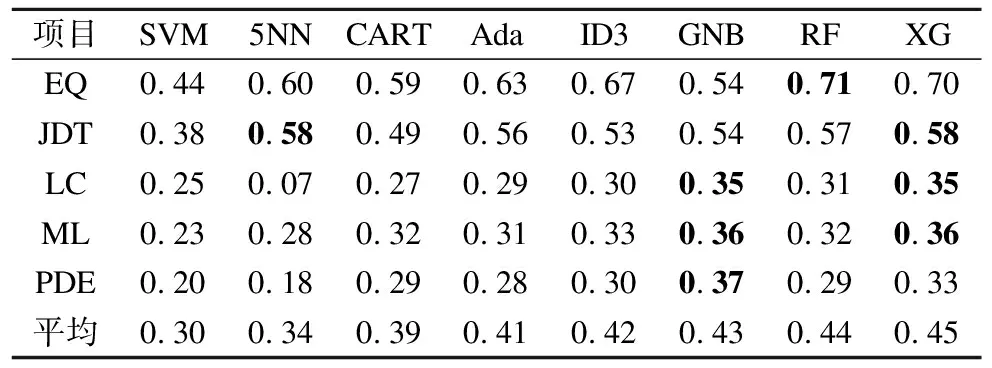
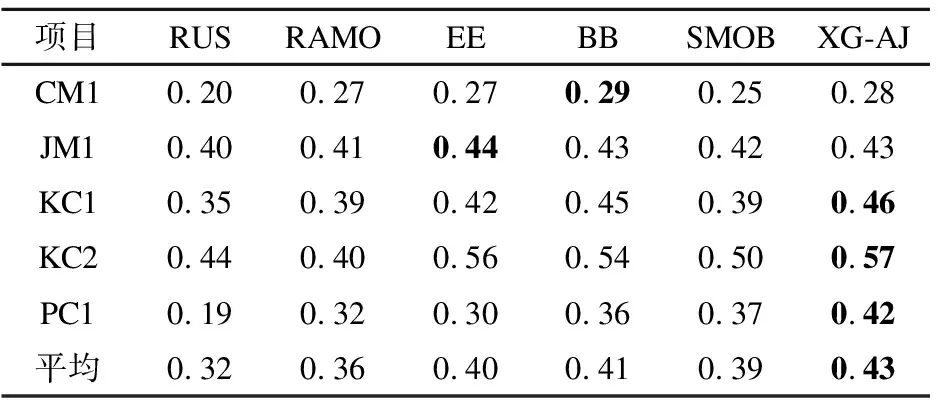
对非缺陷近邻≥K/2即边缘类,进行改进的ADASYN算法采样,能自适应的加强对边界处的样本采样,增加类边界线的清晰度.对非缺陷近邻 3.2.3 改进的ADASYN算法框架图 图4详细的描写了AJCC-Ram采样中ADASYN改进算法的内容.为了加强边界处样本多样性,将针对样本点与近邻中少数类之间才具有的采样行为进行改进:将随机选取进行插值生成的近邻由原来SMOTE中缺陷近邻扩充到任意近邻.通过判断随机选取的近邻类别改变随机插值数生成新缺陷样本. 图4 改进的ADASYN算法框架图Fig.4 Frame diagram of improved ADASYN algorithm 不平衡数据处理的解决办法中,重采样是一个直观的方法,它独立于分类器可以更好的在采样预处理后任意地和集成方法或者分类器相结合.本文在采样侧重中,从不同层面考虑了所有少数样本对新样本生成的影响,在边界区和中心区分别进行了采样. 在边界区,由于该处的少数类可能更难以学习,因此需要让边界处的样本生成更多新样本,以迫使最终的分类学习更集中于困难区域,从而采用了ADASYN算法.针对边界处ADASYN采样的单一性改进了ADASYN算法:在权重计算后,由原来只对K近邻中的少数类随机插值采样,改进到对K近邻中任意样本随机插值采样,根据随机选取近邻样本的类别不同,采取不同范围的插值随机数进行样本生成,增加了样本生成的多样化.在安全区,将进行CURE-SMOTE采样以达到有效的防止过拟合,保证样本数据的原始分布属性的目的. 针对改进算法采样后噪声和边界模糊问题,在采样平衡后,将平衡数据进行CLNI噪声清理.与ADASYN相比,AJCC-Ram可以有效地抑制噪声的负面影响,与CURE-SMOTE采样相比,AJCC-Ram可以有效的提高难分类缺陷样本的分类准确性. 算法1.采样算法 输入:输入训练数据集S、少数类数据近邻数目K 输出:过采样后合成的数据集N 1.Calculate the number of samples in the majority class and the minority class in the training setS:N1、N2; 2.Calculate the total number of samples to be generated:G=N1-N2; 3.forZn∈N2do: 4. Calculate the Euclidean distance to obtainKnearest neighbors of each instanceZn,add the neighbor instance tolistn; 5. Calculate the number of majority classes inKnearest neighbors:ΔKn; 6.end for; 7.ifΔKn≥K/2: 8.Xi=Zn;Listi=listn;Δi=ΔKn;i=i+1; 9. Calculate the proportion ofKnearest neighbors of Δi:ri=Δi/K 11.end if 12.for each instanceXido: 14. Count the number of samples generated around it: g=G×Wi; 15. forj=1 togdo; 16. Random neighbor instancesXijin Listi; 17. ifXij∈N2; 18. Generate new samples: 24.end for 26.end for 27.forU∈Cdo: 28. forV∈Cdo: 29.d(U,V)=mind(p,q)(p∈Ur,p∈Vr) //Calculate the distance between clusters 30. end for 31.end for 32.The cluster with the smallest distance between clusters is merged and namedc. 33.for each clustercdo: 34. Update the center and representative points: Among them,the |U|as the number of clusters,αis the contraction factor (Generally take 0.5). 35.end for 36.Calculate the number of generated samples:g=N1-N2; 37.forj=1 togdo: 40.end for 41.Synthesized balanced data set:N=N1+N2; 42.returnN. 算法2.噪声清理算法 输入:输入合成的平衡数据集N、近邻数K、阀值δ 输出:清理后的数据集N 1.forXi∈Ndo: 2. Calculate the Euclidean distance to obtainKnearest neighbors of each instanceXi,and add the neighbor instance toListi 3. Calculate the number of categories inListithat differ fromXi:Δi 4. Calculate the proportion ofΔiin theKnearest neighbor ofXi:ri=Δi/K 5.end for 6.ifri>δ: 7. DeleteXiinstances inN; 8.else 9. continue; 10.end if 11.returnN. XGBoost全名为eXtreme Gradient Boosting,是14年由陈天奇[32]提出的基于决策树的梯度提升boosting集成算法.该算法可自定义损失函数并在目标函数中加入了正则项,能有效的控制复杂度、防止过拟合,是一种高效的机器学习算法. 其基本原理如下: 首先,定义一个目标函数=损失函数+正则化项+常数: (1) C为常数,Ω(ft)正则项如公式(2)所示: (2) 其中,γ表示 L1正则的惩罚项,λ表示 L2正则的惩罚项,T表示叶子节点个数,wj表示第j个叶子节点的权重. 用泰勒近似展开目标函数: (3) (4) 其中,令Gj=∑i∈Ijgi,Hj=∑i∈Ijhi,求导令其等于0,可得: (5) 将wj带入目标函数得: (6) 式(6)可以作为评分函数来衡量一个树型结构t的质量.通过自定义损失函数,计算其一阶、二阶导.简化后再根据其所选特征计算增益,从而选取合适的节点划分,构造最优结构树.使用贪心算法选取节点的最大化期望式如式(7)所示: gain(φ)=gain(before)-gain(after) (7) XGBoost在近些年竞赛中被积极运用,且取得了很优秀的成绩[33].本文使用该集成算法和采样相搭配使用的软件缺陷预测模型XG-AJCC可以很好的处理采样的过拟合问题. 算法3.XGboost算法 输入:训练数据集N′={(x1,y1),(x2,y2),…(xn,yn)},最大迭代次数T,损失函数L,正则化系数λ、γ,特征数M 输出:集成的强学习器ft(x) 1.fort=1->Tdo: 2. fori∈Ndo: 4. end for 5.Gj=0;Hj=0;score=0; 6. forj=1 tondo: 7.Gj=Gj+gi;Hj=Hj+hi; 8. form=1 toMdo: 9.GL=0;HL=0; 10. fori∈Ndo: 11.GL=GL+gi,GR=G-GL HL=HL+hi,HR=H-HL //Calculate the sum of the first and second derivatives of the left and right subtrees after the instance is put into the left subtree 12. Try to update the maximum score: 14. end for 15.end for 16.if Max score!=0: 17. continue->2; 18.else 19. Get the weak learnerht(x); 20. Update the learnerft(x); 21.end if 22.end for 23.returnft(x) 算法4.XG-AJCC模型算法 输入:输入训练数据集S、测试数据集S′、XGBoost集成分类器ft(x) 输出:测试数据集的预测结果Y(s)′ 1.Pretreatment stage: Sampling algorithm(S,5)→N; Noise cleaning algorithm(S,5,0.6)→N; 2.The integration phase: (N,S′,ft(x))′→Y(s)′ 3.returnY(s)′ XG-AJCC过采样集成缺陷预测模型是一种将AJCC-Ram多层次采样和XGBoost集成学习相结合的高效的软件缺陷预测模型.为了验证AJCC-Ram采样和XG-AJCC缺陷预测模型的有效性,本文提出了3个研究问题,并就问题设计了3组对比实验: 1)与经典的类不平衡重采样软件缺陷预测方法相比,AJCC-Ram采样能否进一步提高分类性能? 为了验证AJCC-Ram采样的有效性,实验将与原始数据、随机过采样、随机欠采样、SMOTE采样、ADASYN采样、CURE-SMOTE采样在基础分类器朴素贝叶斯下进行对比实验. 2)与经典的分类器和集成器相比,XGBoost集成学习能否进一步提高分类性能? 为了验证XGBoost集成算法的有效性,将分别与经典的分类器SVM、5-NN、CART决策树、AdaBoost、ID3决策树、朴素贝叶斯、随机森林采用原始数据集进行对比实验. 3)与经典的采样和集成相结合的方法相比,XG-AJCC方法能否进一步提高分类性能? 为了验证AJCC-Ram采样和XGBoost集成学习结合的软件缺陷预测模型的有效性,将进一步把XG-AJCC与不平衡数据处理的采样集成方法:RUSBoost、RAMOBoost、EasyEnsemble、BalanceBagging、SMOTEBoost进行对比实验. 以上实验将在AEEEM数据集和NASA数据集上,通过控制变量法用F1作为评价指标进行10次十折交叉法即100次实验,取平均值做实验结果.以上的算法均通过python中的XGBoost工具包、sklearn工具包、github的somte-variants[34]和imbalanced-algorithms工具包进行代码调用.使用somte-variants工具包调用CURE-SMOTE算法、利用XGBoost工具包调用XGBoost集成分类器,并对XGBoost进行参数设定(设定值为:AEEEM数据集中使用学习率为0.001,树数为1000,树深为6.NASA数据集使用学习率为0.1,树数为10000,树深为10).使用imbalanced-algorithms调用实验3的SMOTEBoost和RAMOBoost方法,采用sklearn工具包调用各种分类器、评估方法F1和实验3的RUSBoost、EasyEnsemble、BalanceBagging方法.实验具有实际操作意义. 本文使用AEEEM数据集[35]和NASA数据集进行模型性能衡量.AEEEM数据集是由D′Ambros等人分析了5个开源项目(包括61个特征值)收集形成的.NASA数据集则是由美国国家航空航天局发布的,其数据下载位于PROMISE库(1)http://promise.site.uottawa.ca/SERepository中,具有真实可信性. 根据缺陷的预测目标不同,机器学习也分为回归学习和分类学习.本文研究的是缺陷倾向性预测,在机器学习研究中属于二分类问题.所以在数据集处理中,为使多标签或英文标签的数据集形成二分类标签y={0,1}(0为多数类,1为少数类),实验将进行以下操作: 设data={(x1,y1),(x2,y2),…(xi,yi)}为初始数据集,其中xi训练样本向量{a1,a2,…aj}, 当AEEEM数据集j=61时,令: (8) 当NASA数据集j=21,令: (9) AEEEM数据集和NASA数据集的基本信息如表1、表2所示. 表1 AEEEM数据集信息Table 1 Imformation of AEEEM datasets 表2 NASA数据集信息Table 2 Imformation of NASA datasets 其中,设非缺陷数为N,缺陷数为Q,相关定义如定义1、定义2所示. 定义1.缺陷率(rateofdefect,Rd):为缺陷模块数与总模块数的比值. (10) 定义2.不平衡率(Imbalance Ratio,IR):无缺陷模块数与有缺陷模块数的比值. (11) 二分类问题的预测结果会出现4种表示结果,由表3能够清晰地表示. 表3 混淆矩阵Table 3 Confusion matrix 通过4种表示结果的结合可以形成多种性能评价指标,包括:查准率、召回率、F-measure、AUC度量、MCC等.在不平衡数据分类的机器学习中,用准确率进行模型评估显然是不合理的.查准率和召回率是评估方法之一,但其生成的值几乎是互相矛盾的.AUC、MCC相对稳定,但不适合当检测解决类不平衡问题的评价标准.所以对预测模型选择合适的评价指标尤为必要.本文将采用F1评价指标对实验对比进行评估,有利于综合的考察查准率和查全率两个指标值,合理的给出预测性能的对比结果. 相关计算公式如下: 1)准确率:表示被正确分类的模块数在总模块数中的占比. (12) 2)查准率:表示所有被分类的缺陷类中被正确分类的占比. (13) 3)召回率:表示所有缺陷类中被正确分类的占比. (14) 4)F-measure:β=2时又叫F1度量:是一个关于查准率和召回率的调和平均定义. (15) 问题1.与经典的类不平衡重采样软件缺陷预测方法相比,AJCC-Ram采样能否进一步提高分类性能? 针对问题1进行的对比实验,结果如表4、表5所示.其中OD、RUS、ROS、SMO、ADA、CURE、AJ-R分别为原始数据、随机欠采样、随机过采样、SMOTE采样、ADASYN采样、CURE-SMOTE采样、AJCC-Ram采样的简称. 实验结果表明:相比较基准方法,随机欠采样的F1值性有时会略差,这是因为在小规模数据集中,随机欠采样可能会删除某些重要数据的而导致性能下降.而其他方法(包括随机过采样)除了在较稀疏的数据PC1中,大都能在一定程度上提升F1值,这说明过采样方法确实可以提升不平衡数据集的预测效果.进一步而言,本文提出的AJCC-Ram过采样方法与原数据集AEEEM和NASA的基准方法相比平均都提升了3%,与其他经典的过采样方法在两类不平衡数据集中又取得了9次最优预测效果.上述结果证明了AJCC-Ram采样方法在不平衡数据缺陷预测的有效性. 表4 多种采样方法在AEEEM数据集中的F1值Table 4 F1 value of multiple sampling methods in AEEEM dataset 表5 多种采样方法在NASA数据集中的F1值Table 5 F1 value of multiple sampling methods in NASA dataset 问题2.与经典的分类器和集成器相比,XGBoost集成学习能否进一步提高分类性能? 针对问题2进行的对比实验,结果如表6、表7所示.其中5NN、CART、Ada、ID3、GNB、RF、XG分别为5-NN、CART决策树、AdaBoost、ID3决策树、朴素贝叶斯、随机森林和XGBoost的简称. 表6 多种分类器在不平衡数据集AEEEM中的F1值Table 6 F1 values of multiple classifiers in unbalanced data set AEEEM 实验结果可以看出:XGBoost集成学习以F1为指标在不平衡数据集AEEEM和NASA的10个数据中,取得了7次最优的预测结果.朴素贝叶斯在小规模数据集AEEEM上具有优势,可以在一些数据中较大幅度提升分类性能,但优势存在的稳定性和性能的平均提高程度不如XGBoost.上述结果证明了在不平衡数据集上对比的其他分类器,XGBoost集成学习可以取得更好的预测效果. 表7 多种分类器在不平衡数据集NASA中的F1值Table 7 F1 values of multiple classifiers in unbalanced data set NASA 问题3.与经典的采样和集成相结合的方法相比,XG-AJCC方法能否进一步提高分类性能? 针对问题3进行的对比实验,结果如表8、表9所示.其中RUS、RAMO、EE、BB、SMOB、XG-AJ分别为RUSBoost、RAMOBoost、EasyEnsemble、BalanceBagging、SMOTEBoost、XG-AJCC的简称. 表8 多种采样集成方法在AEEEM数据集中的F1值Table 8 F1 values in AEEEM data set by multiple sampling integration methods 表9 多种采样集成方法在NANS数据集中的F1值Table 9 F1 values in NANS data set by multiple sampling integration methods 为了更直观的分析实验结果,本文由表8、表9得到如图5、图6所示的柱状图.从图5、图6、表8、表9可以看出:XG-AJCC预测模型以F1为指标在不平衡数据集AEEEM和NASA的10个数据中取得了7次最优预测结果,特别是两个数据集的平均值显著高于其他的对比实验:在AEEEM数据集均值分别提升了14%、7%、6%、4%和3%,在NASA数据集均值分别提升了11%、7%、3%、1%和4%.相比之下在性能略差时一些数据中,与其他最优的采样集成相结合的不平衡数据处理方法相比差距也不大.从整体来看,XG-AJCC方法的性能提升率和分类稳定性显著优于其他对照实验.由上述结果可以得知,XG-AJCC预测模型是一个有效的不平衡数据软件缺陷预测模型. 图5 各不平衡数据处理方法在AEEEM数据集中的F1值Fig.5 F1 value of each unbalanced data processing method in the AEEEM data set 图6 各不平衡数据处理方法在NASA数据集中的F1值Fig.6 F1 value of each unbalanced data processing method in the NASA data set 针对软件缺陷预测中类不平衡问题,本文在采样部分从不同层面上,考虑了所有少数类缺陷样本对新样本生成的影响,基于ADASYN算法和CURE-SMOTE算法提出了自适应判断合成随机采样AJCC-Ram,并通过CLNI噪声过滤进行数据清理.将该过采样预处理方法与集成学习XGBoost相结合形成最终的软件缺陷预测模型XG-AJCC.实验结果表明,XG-AJCC不平衡数据缺陷预测模型在数据集AEEEM和NASA中均能取得优良的预测效果. 下一步将通过研究不同的特征选择方法,在预处理阶段降低实验的时间复杂度,进一步将降低了时间复杂度的AJCC-Ram采样应用于半监督方面,补足标记数不足的原始数据,并继续结合集成学习XGBoost进行缺陷预测.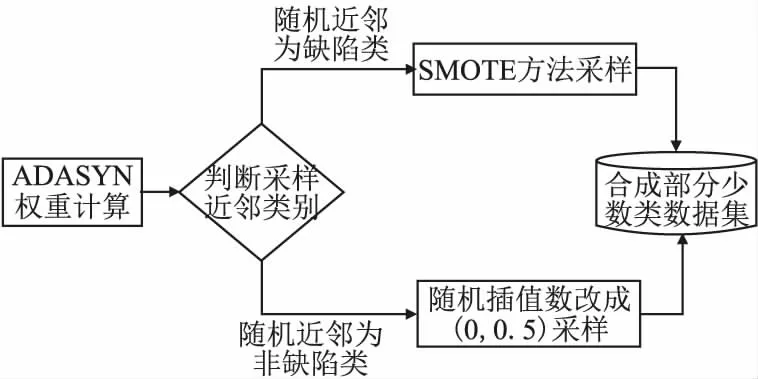
3.3 过采样预处理阶段
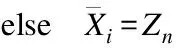

3.4 XGBoost集成学习阶段
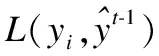
4 实 验
4.1 实验设计
4.2 实验数据集设计

4.3 实验评价指标

4.4 过采样预处理阶段结果及分析

4.5 集成处理阶段结果及分析

4.6 XG-AJCC类不平衡软件缺陷预测模型结果及分析



5 结束语
