面向新冠疫情应对的文本挖掘框架研究
2023-04-14谭明亮
谭明亮
摘要:非结构化文本是最基础和最主要的数据类型之一,蕴含着巨大的价值与潜能,对其进行分析挖掘和有效利用对于新冠疫情的应对处置有着重要的意义。文章从中国知网数据库中检索2020年和2021年两年间发表于重要学术期刊上,与新冠疫情文本挖掘相关的研究文献共计127篇,然后对研究文献进行逐篇阅读和内容分析,以实现研究文献的系统化梳理和深层次分析。文章构建了面向新冠疫情应对的文本挖掘框架,从应用场景、文本数据、分析方法、算法模型和软件工具五个方面展开分析论述,为开展面向新冠疫情应对的文本挖掘提供了整体系统的架构设计和切实可行的解决路径。
关键词:新冠疫情应对;文本挖掘;突发公共卫生事件;大数据分析
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2023)06-0051-03
开放科学(资源服务)标识码(OSID)
1 引言
2020年爆发的新冠疫情是新中国成立以来传播速度最快、感染范围最广、防控难度最大的重大突发公共卫生事件,同时也是百年来全球发生的最严重的大流行传染病。目前,新冠疫情已蔓延至上百个国家和地区,截至2022年2月,全球新冠感染确诊病例超过4亿,死亡病例超过580万例。如何有效地应对新冠疫情是党和国家的重大现实需求,同时也是各学科领域的研究者们所共同面临的重要学术问题。
作为一种新兴的基础性战略资源,大数据中蕴含着巨大的价值与潜能,对于重塑国家竞争优势、提升国家治理能力、推动经济发展、引领科技创新有着十分重要的作用。在数据驱动的管理决策和科学研究的第四范式的背景下,以数据为中心,分析、挖掘、组织和利用数据资源能够有效地推动科学知识发现、提升科学决策水平、强化综合治理能力和创造社会经济价值。非结构化文本数据是数据资源中最基本和最主要的构成之一,对其进行分析挖掘对于新冠疫情的应对处置有着重要的意义。
2 文献数据收集
本文通过收集新冠疫情文本挖掘相关的研究文献,对文献进行逐篇阅读和内容分析;然后以此为基础,结合数据挖掘和情报分析领域的相关理论方法,构建面向新冠疫情应对的文本挖掘模型。考虑到研究文献的权威性和代表性,本文将学术期刊的来源类别确定为北大核心、CSSCI和CSCD;将出版年度设定为2021年和2022年。
为了全面充分地从CNKI数据库中检索出相关的研究文献,本文将检索条件设定为(主题=“新冠感染”OR“新型冠状病毒感染”OR“COVID-19”OR“新冠疫情”OR“新冠感染疫情”OR“新型冠状病毒感染疫情”)AND(主题OR摘要=“文本挖掘”OR“文本分析”OR“情感分析”OR“文本聚类”OR“文本分类”OR“信息抽取”OR“关联分析”OR“文本”OR“词频”OR“频数”OR“主题挖掘”OR“主题聚类”OR“LDA”)。
完成文献检索后,接下来需要对获得的检索结果进行筛选。在信息管理和计算机科学的语境下,文本挖掘主要是利用计算机从非结构化文本数据中提取和发现有价值的模式和知识。因此,本文去除了检索结果中通过人工的方式来对文本数据进行分析的研究文献,最终得到研究文献共计127篇。
3 面向新冠疫情应对的文本挖掘框架构建
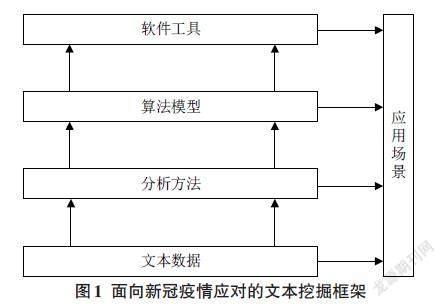
本文对以127篇研究文献的内容分析为基础,结合数据挖掘的基本思路和流程,以及中信所提出的“事实型数据+专用方法工具+专家智慧”方法论,构建了面向新冠疫情应对的文本挖掘框架,如图1所示。该框架主要由应用场景、文本数据、分析方法、算法模型、软件工具五部分所构成,通过采集非结构化文本数据,运用相关的分析方法、算法模型和软件工具对文本数据进行分析、处理和挖掘,从而为管理决策提供支持和依据。
3.1 应用场景
新冠疫情文本挖掘所面向的应用场景和实际需求主要包括网络舆情分析与管理、虚假信息和网络谣言识别与治理、新冠感染用药规律与诊疗方案分析、政府政策分析与评价、公众信息需求和诉求分析等。CNNIC发布的第48次《中国互联网络发展状况统计报告》显示,目前我国的网民规模达到了10亿以上,并呈现出逐年上升的趋势;在此背景下,对网民在微博、贴吧、BBS论坛和微信等社交媒体上发表的文本内容进行分析挖掘,从而有效地监测、管理和引导网络舆情具有重要的意义。因此,网络舆情分析对于文本挖掘技术的需求和应用尤为突出。
新冠感染用药规律与诊疗方案分析主要通过挖掘新冠感染的防治处方、研究论文、国家及各省市自治区卫健委推荐的COVID-19诊疗方案和指南建议等来探究新冠感染的用药规律、组方特征,从而为新冠感染的防治和用药提供参考与依据。新冠疫情爆发后,国家和各级政府管理部门针对疫情防控、复工复产、产业扶持等发布了大量的政策文件;政府政策分析与评价主要研究政策主题演化、政策扩散特征、政策量化、政策差异和协同等。公众信息需求和诉求分析主要通过挖掘用户在网络平台发表的文本信息来掌握新冠感染期间人们的信息需求和诉求。
3.2 文本数据
面向新冠疫情应对的文本挖掘需要根据应用场景和实际问题采集和获取相应的非结构化文本数据,典型的文本数据例如社交媒体文本、政策文本、诊疗方案文本、医药处方文本、学术论文文本、新闻报道文本、领导留言板文本、病例轨迹描述性文本等。文本数据的来源主要包括政府部门官方网站、网络平台、文献数据库、社交媒体平台、新闻门户网站等。文本数据采集的方式主要有爬虫爬取、数据库导出、手工下载和API接口获取等。在数据采集方式的选择上,需要综合考虑数据源的特點、数据量的大小等诸多方面的因素,例如,针对文献数据库中的数据适合通过批量导出的方式获取,新浪微博平台上的数据则适合通过爬虫和API接口的方式获取。
网络舆情分析与管理、虚假信息和网络谣言识别与治理场景所需要采集的文本数据主要包括新浪微博文本、百度贴吧帖子、知乎帖子、抖音评论文本、QQ空间文本、微信公众号文本等。新冠感染用药规律与诊疗方案分析所需要采集的文本数据主要包括CNKI、万方、Pubmed、Elsevier、SpringerLink等数据库中的学术论文文本,国家及各省自治区直辖市发布和推荐的诊疗方案、指南建议,HIS系统中的处方文本和全国名医公开的新冠感染防治处方文本等。政府政策分析与评价所需要采集的文本数据主要是各级政府管理部门发布的疫情防控、企业复工复产等相关的政策文本。公众信息需求和诉求分析所需要采集的文本数据则主要是公众在知乎、新浪微博等网络平台和领导留言板上发表的热门话题和咨询提问文本等。
3.3 分析方法
运用数据采集方法获取了实际应用场景所需的非结构化文本数据之后,为了获取对于应对新冠感染疫情潜在有价值的知识和模式,需要运用一定的文本分析方法对采集的文本数据进行处理和挖掘。针对新冠疫情文本数据所采用的分析方法主要包括词频分析、情感分析、文本分类、文本聚类、主题分析、关联规则挖掘、社会网络分析、文本相似度分析、信息抽取和可视化分析等。
词频分析主要通过统计新冠疫情文本数据中各个词语出现的次数,从而揭示文本数据所表达的核心内容。词频分析法具有实现简单、便于理解、易于操作等特点,是新冠疫情文本挖掘研究文献中使用最为广泛的分析方法之一。例如,陈雅薇等利用词频分析法来研究长三角地区各政府产业政策的相似性与差异化[1];彭宗超等基于词频分析法来对网络大数据进行挖掘,以分析新冠疫情各个阶段中社会舆论的核心关注点[2]。
情感分析被用于分析人们在新冠疫情文本中所表达的观点、情感、评价、情绪和态度等,情感分析的具体方法主要包括:基于词典的方法,将文本内容与情感词典中的情感词进行匹配以实现文本情感倾向判断;基于机器学习的方法,利用经标注的数据集来训练机器学习模型,然后基于训练的模型来实现文本情感分类。例如,冯志仙等运用情感分析法来研究新冠疫情防控期间医院重要通知群和护士交流群中信息的情感倾向[3]。
文本分类主要根据文本数据的语义特征将文本自动归入到预先定义相应的类别中。例如,石锴文等运用文本分类来将新冠感染微博谣言自动检测出来[4]。不同于文本分类的监督学习,文本聚类自动地将新冠疫情文本数据集合划分为若干个类簇,使得同一类簇中文本之间的相似性高,而不同类簇中文本之间的相异性高。例如,禹卫华等将文本聚类应用于探究新冠疫情下政务新媒体的议题[5]。
主题分析通过挖掘新冠疫情文本中的潜在主题来实现对文本数据语义内容的理解、整理和判断。当前研究者们主要利用关联规则挖掘方法来分析新冠感染相关的研究论文、防治处方、诊疗方案和指南建议等文本中药物之间的关联关系,从而为新冠感染的用药和防治等提供决策支持。
社会网络分析主要用于分析发布新冠疫情政策的主体的联合发文关系,以及社交媒体用户之间因转发、评论、关注而形成的社会网络关系。文本相似度分析通过判定给定文本在内容上之间的差异,从而确定相似程度,通常用0至1之间的数值进行衡量。
信息抽取主要用于抽取新冠肺炎流行病学调查形成的病例轨迹描述性文本中抽取时间、地点、病例关系等信息,以实现疫情传播路径的精准定位。可视化分析将新冠疫情文本内容以直观易理解的图形、图像进行呈现,从而形象地表示文本数据的内在含义。
3.4 算法模型
选择一种或多种文本分析方法在对新冠疫情文本数据进行挖掘的过程中表现为使用具体的算法模型,算法模型是分析方法的具体实现和体现。例如,利用主题分析法来对新冠疫情文本的语义内容进行挖掘时,专家学者们往往使用的是Blei等提出的LDA模型;应用关联规则挖掘来对防治处方文本中的药物关系进行分析时则使用的主要是Apriori算法。对于中文文本数据的挖掘,首先需要对非结构化文本进行中文分词、词性标注、去停用词、文本表示、特征权重计算等文本预处理操作,然后在此基础上进行主题分析、关联规则挖掘、文本相似度分析、情感分析、文本分类和文本聚类等。
中文分词和词性标注所用的算法模型主要包括HMM模型、CRF模型和最大熵模型等。文本表示所用的算法模型主要包括词袋模型、布尔模型、N-Gram模型、向量空间模型(VSM)、Word2vec词嵌入模型、BERT词向量模型等。特征权重计算所用的算法模型主要包括特征频率、布尔函数、信息增益、倒排档文本频率、TF-IDF算法、互信息等。文本主题分析所用的算法模型主要包括LDA主题模型、ETM主题模型模型、STM主题模型模型等。关联规则挖掘所用的算法模型主要是Apriori算法。文本相似度分析所用的算法模型主要包括余弦相似度算法、欧氏距离、皮尔逊系数等。
情感分析和文本分类所用的算法模型主要包括朴素貝叶斯算法、随机森林算法、SVM算法、LSTM算法、CNN算法、RNN算法、Bi-LSTM算法、XGBoost算法、BiGRU模型、Transformer模型等。文本聚类所用的算法模型主要包括K-Means算法、DBSCAN算法、Fast Unfolding算法、Single-Pass算法等。基于采集的127篇研究文献可以直观地发现,随着深度学习和人工智能技术的快速发展,大量的深度神经网络算法模型已经被研究者们广泛地应用于新冠疫情文本挖掘中。专家学者们还将多种模型进行融合和集成,以更好地实现文本的语义理解和语义挖掘;例如,融合LDA模型与BERT模型;集成CNN算法、BiLSTM算法与attention模型。
3.5 软件工具
当前国内外的相关研究机构和专家学者们针对文本挖掘、机器学习、自然语言处理、数据分析和人工智能等技术领域开发了大量的软件、程序库和工具,对算法模型进行了实现和封装。这使得研究人员,特别是社会学、经济学、管理科学、法学等非计算机科学领域的科研工作者能够将注意力集中在新冠疫情文本挖掘所面向的应用场景和实际问题上,而不是将大量的精力和时间投入到文本挖掘相关的算法模型的编程实现上。例如,要基于LDA主题模型来对新冠疫情文本数据进行分析,不必从零开始编写一行行的代码来编程实现LDA模型,可以通过导入开源的Gensim工具包直接使用LDA模型。
数据采集所用的软件工具主要包括八爪鱼爬虫软件、谷歌爬虫插件Web Scraper、火车头采集器、后羿采集器、Scrapy爬虫框架等。文本大数据的存储和处理所用的基础设施主要包括HDFS、MapReduce、Hadoop、MongoDB、Spark等。中文分词、词性标注所用的软件工具主要包括jieba库、ICTCLAS、哈工大LTP、北大pkuseg、HanLP中文处理包、清华THULAC等,所使用的停用词表主要有哈工大停用词表、四川大学机器智能实验室停用词、百度停用词表等。
文本表示、文本分类、文本聚类、主题分析、情感分析、关联规则挖掘和信息抽取主要使用自然语言处理、数据分析、机器学习和深度神经网络相关的软件工具,主要包括SPSS Modeler软件、SPSS Statistics软件、scikit-learn库、Gensim包、bert-as-service库、keras库、Tensorflow库、pytorch库、百度智能云API等。社会网络分析所用的软件工具主要包括Gephi软件、NetDraw软件、Ucinet软件等。可视化分析所用的软件工具主要包括Vosviewer软件、LDAvis包、WordCloud库、Matplotlib库等。
4 结语
本文以过去两年内发表于核心期刊上关于新冠疫情文本挖掘的127篇研究文献为基础,构建了面向新冠疫情应对的文本挖掘框架,并框架所涉及的核心内容展开了分析论述,以期为面向新冠疫情应对的文本挖掘学术研究和应用实践提供借鉴参考。文本数据具有着不同的粒度,按照信息粒度的大小可以分为篇章、段落、句子、词语等层次。今后的重要研究方向之一是基于深度神经网络、知识库半自动构建、文本图表示学习和文本语义分析等技术实现各层次文本单元的语义理解和知识关联。
参考文献:
[1] 陈雅薇,朱华晟,姚飞.长三角地区新冠肺炎疫情应急与产业政策响应——基于政策文本的词频分析[J].现代城市研究,2021,36(1):45-51.
[2] 彭宗超,黄昊,吴洪涛,等.新冠肺炎疫情前期应急防控的“五情”大数据分析[J].治理研究,2020,36(2):6-20.
[3] 冯志仙,沈鸣雁,陈翔,等.新型冠状病毒肺炎疫情防控期间护理管理工作中信息传递质量改善研究[J].中国护理管理,2020,20(5):686-690.
[4] 石锴文,刘勘.突发公共卫生事件中微博谣言的识别[J].图书情报工作,2021,65(13):87-95.
[5] 禹卫华,黄阳坤.重大突发公共卫生事件的政务传播:响应、议题与定位[J].新闻与传播评论,2020,73(5):22-33.
【通联编辑:王力】
