车载智能语音助手综合评估模型建立及应用
2023-04-11道发发丁敏袁粲璨陈晓军黎小平赵嵩
道发发 丁敏 袁粲璨 陈晓军 黎小平 赵嵩
(一汽-大众汽车有限公司,长春 130011)
缩略语
NLP Nature Language Processing
BLEU Bilingual Evaluation Understudy
ROUGE Recall-Oriented Understudy for Gisting Evaluation
TTS Text To Speech
VPA Virtual Personal Assistant
AI Artificial Intelligence
0 引言
随着物联网、车联网、自动驾驶技术的发展,汽车行业的竞争力正在从传统的以性能为核心转变为以数字化和智能化为核心,包括众多的智能座舱服务和辅助驾驶服务。车载语音助手是汽车数字化的一部分[1],也是人机交互的一级入口,常见的车载语音助手包含任务型对话功能和闲聊功能,其中任务型对话应用于车内支持的功能操作,如车控、导航、天气等,闲聊则是通用的聊天型对话,不完成具体的任务。
车载语音助手的出现解放了驾驶员的双手和双眼,用户无需注视屏幕或操作按钮即可完成对应的需求。但同时,为了“可见即可说”,车载语音助手需要支持数百个常用的指令及无穷的说法变换,其性能的优劣直接影响用户的体验[2]。故针对车载语音助手的综合性评价非常重要。
语音助手的实现逻辑是基于人工智能的自然语言处理(Nature Language Processing,NLP)模型。常用的模型评估方法通常是针对单个模型的点对点评估,如对于实体识别[3]、序列标注[4]的模型,采用精确率、召回率、精确率和召回率的加权平均(F1 Score)数值等评估指标;对于文本生成[5]任务使用双语评估研究(Bi⁃lingual Evaluation Understudy,BLEU)、自动摘要评价(Recall-Oriented Understudy for Gisting Evaluation,ROUGE)方法进行评估。车载语音助手通常由至少十几个不同的模型组成,每个模型在开发过程中的训练数据不一定相同,评估指标也不相同,故不能用各部分的单独技术性指标来描述整个系统的性能。在开发过程中,开发人员完成所有组件的开发并整合成语音助手之后,测试人员会根据其设计所支持的功能进行通过性测试。这种测试方式会忽略实际应用场景的复杂性、用户表达的多样性,无法深度探查语音助手的能力及其背后算法的有效性[6]。
综上所述,本文提出了一套综合性的语音助手评估模型,旨在以贴近用户的方式量化描述语音助手的综合表现,并可以反推出各个子系统的性能,用于问题定位和优化。
1 评估模型建立
本模型包含评价数据库、指标生成模型、可视化组件、自动化组件4个主要部分。其中评价数据库包含10 026 条由人工构造的高阶用例,以矩阵形式组织,横向按语义点区分,如意图联想、语义容错、多意图识别共31 个评价项,纵向按车载常用功能分为64个功能,主要涉及车控、导航、天气、多媒体、电话主要车载技能以及维保、蓝牙、计算器、油价等长尾技能[7]。指标生成模型包含完成率、意图识别率生成模型以及意图联想、语义容错、多意图识别子项指标生成模型。可视化组件包含数据载入、低代码分析、柱状图、条形图、饼图、时间序列分析功能。自动化组件主要包括自动化分析、多轮对话模拟、报告生成辅助性组件。
标准的指标生成模型可生成主要的技术性描述指标,大量的评估用例保证评估结果无偏差,本模型可应用于需求调研阶段的竞品分析,也可应用于生产阶段的需求对接,保证产品交付质量。
1.1 评估用例
本模型的核心设计目标是一款普适的车载语音助手评估模型,可应用于市场上常见的搭载智能语音助手的综合评估。一般的评估过程需要遵循可量化、层次性、普遍性、客观性原则。针对以上原则和实际需求,构建了一批用于评估的用例库,所有用例均由经验丰富的测试人员和产品人员编写,并通过一个审核小组逐条审核,最终形成了一个万余条的评估用例库。
评估用例库中,用例的组织方式遵从分层原则,分别从智能等级、功能点、困难程度、语义维度4个方面进行分级。为了能够得到精确的量化指标,在构造用例时确保每条用例只对应于一种语义指标。
表1 示意每个维度上的详细层次结构,其中技能共有27个一级项和64个二级项,语义维度分3个一级项和31个二级项。表1中只列出一级项,省略了二级项。

表1 用例维度分级表
根据评估模型的特点,设计了一套用例构建标准,从语义维度对用例的构建原则、评估目标以及其智能程度进行分级,表2描述了用例构建过程中语义维度各指标的定义以及对应的评价项,由于篇幅所限,本文仅列出部分内容,全量的评价项共有31项,基本覆盖所有语义类型。本文中的所有用例都根据此表进行构建。其中,L1、L2、L3、L4 分别代表4 个不同的智能程度。
1.2 主要指标评估模型
评估模型分为主要指标和次要指标,其中主要指标为任务完成率、意图识别率,用于评估语音助手在任务型对话上的端到端能力;次要指标是语音维度的31 个细分维度,用于对车载语音智能程度、语义理解能力、语义理解模型效果的分析。
评估过程中,为了降低评估人员主观的误差,使3名评估人员同时进行打分,当所有评估人员都认为该用例通过时,则该用例通过。
对于任务完成率和意图识别率,指标的量化计算公式如式(1)。
式中,pa为评估用例结果的得分;αi为第i条用例的得分;X为用例集合。当所有评估人员的打分都为1时,ai=1,否则ai=0。
此外,为了能够捕捉评估一致的随机性,除了上述pa指标外,引入指标pc,对于多个评估人员ej,用例集合X的评估分数是集合S,那么pc的计算公式为:
式中,p(s|ei)是每个评估人员给出分数s的频率估计;s是用例;最后能够得到和评估一致性相关的结果σ:
式中,当σ越靠近1,则表示多名评价者评价的一致性越强,评估结果越可靠。在本模型中,当σ>0.8 时,认为当轮评价有效,采用该轮评价结果。
同时,对于完成率和意图识别率,将整个语音助手视为一个统一的机器学习模型,采用查准率、查全率和F1值描述语音助手的整体表现:
式中,Pr为查准率;TP为语音助手成功完成的任务数;FP为语音助手未识别的拒识用例数;Recall为查全率;FN为语音助手成功识别到的拒识用例数;F1代表语音助手的实际表现,其数值越靠近1,表示语音助手的性能越佳。
综上,在评价任务完成和意图识别2 个主要维度时,使用了2套指标,第1套综合指标使用一致性评估方式保证评估人员的一致性,第2套指标将语音助手看做一个整体的AI模型,使用查准率、查全率和F1值来评估其整体表现。
在实际研发过程中,研发人员或项目管理人员不仅关注语音助手的整体指标,更需要注意各部分子功能的具体指标,以此保证子模块算法的性能。
1.3 语义指标评估模型
在本评估模型中,语义方面共分3 个一级语义和31个二级语义,从算法角度进行分类,可以归结为文本分类任务、匹配任务、序列标注任务和文本生成任务。
对于文本分类任务和序列标注任务,由于评估样本有限,且样本分布不完全均衡,为避免忽略小样本数据,故使用MicroAveraged方法评估:
其中,Pmicro为微平均查准率,Rmicro为微平均查全率,TPi为第i类任务里识别正确的数量,FPi为第i类任务里识别错误的数量,FNi为第i类里把错误类别识别成正确类别的数量,----TP,----FP,分别为TPi和FPi的算数平均值。
对于文本匹配任务,使用Top@N覆盖率来描述其性能,计算方式为前N项候选指标中包含正确结果的准确率。
对于文本生成任务,使用BLEU作为其评估指标:
式中,BP为最佳匹配长度;wn为赋予Pn权重;Pn为多元精度得分;lc为结果的长度;lr为标准答案句子的长度。
综上,描述了本模型中2 个主要指标(任务完成和意图识别)以及31个二级语义指标的评估方法,主要指标将语音助手视为一个单独对象,使用查准率、查全率、F1值来描述其性能,并采用σ约束来规避评估人员主观上导致的评分不一致问题[8]。二级语义指标将语音助手视为多个子模型的集合,针对每个二级语义项,都给出单独的评价指标,开发人员可以借助这些指标进行深度的问题定位,需求分析人员可以借助这些指标完成对目标产品的多维度分析。
在实际的开发过程中,由于项目采用敏捷的工作方式,项目版本迭代次数最高可以达到每天一次,导致开发人员对于问题定位的需求频率非常高。使用人工分析来定位问题会带来大量的人力需求,为了降低对于人工的消耗,使用一个简单的算法模型来进行快速的自动化问题定位。
2 分析方法
2.1 问题描述
评估模型的输出结果是2 个主要指标和31 个语义指标的评分,这些指标的集合代表了语音助手各部分及整体的表现。为了适应语音助手复杂的任务型对话逻辑,如前文所述,评估模型也遵从分层的构建逻辑,并从功能点和语义的维度进行了两级划分。整体的指标体系可以分为4层,上一层级的评估指标值为下一层级指标的算数平均值(图1)。
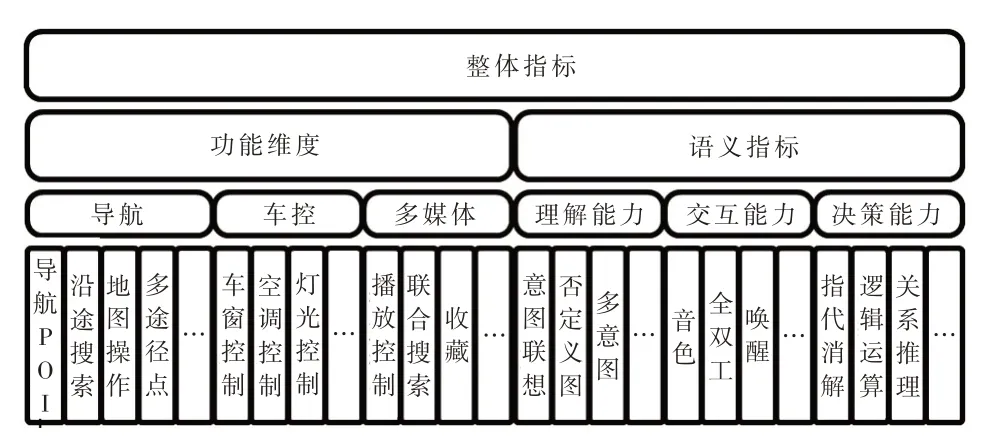
图1 评估指标层级划分
表3为使用评估模型对上述组织方式的用例集合进行打分后的结果,其中3项打分S1、S2、S3分别为语义识别、意图识别、任务完成情况。由于篇幅限制,此处省略了一些其它辅助字段的信息。

表3 模型评估结果
通常,一次评估后会得到30 000条以上的评估结果数据。在研发生产过程中,伴随着敏捷迭代,需要进行高频的模型评估和问题定位分析,使用人工的方式进行分析会带来极大的人力需求。为了提高问题分析和定位的能力,设计了一套自动化的分析算法,用于研发过程中快速分析。
2.2 分析算法
模型的评估结果是一个多维分层指标体系,先构建数据模型,如图2所示。S为整体评估分数,由其下层指标合并而成(如整体的任务完成率由功能维度和语义维度得分合并而成)。因此,对于一个二级指标体系来说,分析算法的任务是从S得分的波动中找出造成这种波动的下级节点,且结果必须具有原子特性,即节点组合的最简约形式,如(A1B1、A1C1)的最简约形式为(A1B1C1)[9]。

图2 数据模型
在问题定位过程中,需要结果能够准确反应波动出现的原因,即异常点[10]。异常点的查找需要满足3个主要条件,也是算法设计过程中的难点[11]。
(1)对于每一个维度,结果需要尽可能解释主要指标波动原因;
(2)对于每一个维度,结果需要符合最简原则,即不可再分;
(3)在所有维度中,需要找出和预期结果相差最大的元素。
针对以上问题,参考Adtributor 方法[12],设计分析算法。S值为当前指标的惊喜度,代表该指标偏离预期的距离,距离越远,惊喜度越高[13],算法如下。
问题定位算法(根因分析)
2.3 试验结果
根据上述分析算法,使用真实的打分数据进行了相关试验,以验证该算法在数据集上的有效性。试验之前,使用前述用例集合对一款自研语音助手进行了全量的打分,生成原始打分数据并计算各个维度的打分以及整体的任务完成指标打分。此外,对原始数据集随机添加不同数量的异常点,通过统计该算法的识别效果验证上述算法的有效性。
结果如表4 所示,可以发现在精确度方面和人工分析的差距约为10%,且当异常和数据量增加时,算法性能有所下降。这样的性能在生产过程中是可接受的,同时,结合一些规则工具,实际的问题定位精确度可以进一步提升。本文只介绍纯算法的性能。

表4 Adtributor算法试验结果 %
表4 中,C1-3 代表在1 000 条数据中注入3 条异常,C10-5代表在10 000条数据中注入5条异常,以此类推。其中,P-Top为使用本模型进行评估的得分,人工-Top为使用人工评估后的得分。
3 相关工作
本模型已应用于正常的研发过程,使用本模型对市场上的车型进行了多次全量竞品分析,下面列出部分分析数据。表5 所示为整体评估指标,表6 所列为语义部分评估指标。可以看出,本模型可以对语音助手整体做出量化的评估,也可以按语义功能进行评估,维度更多更深,能够充分分析市场上车载语音产品的表现。

表5 整体指标评估结果 %

表6 部分语义指标评估结果 %
4 结束语
本文介绍了一个车载语音助手评估模型,该模型的设计背景来源于实际的生产项目。解决了车载语音助手研发过程中,设计开发人员在产品分析和问题定位过程中的问题。在构建大量模拟真实交互环境的数据集合的基础上,设计了分层指标评估模型和问题定位算法,并应用于实际研发过程,有效提高了产品质量以及研发效率。此外,本文仅阐述评估模型的核心思路及算法,实际生产过程中会用到一些自动化的辅助工具以提升系统工作效率和规范化输出。
随着需求的不断变化,本模型也在不断迭代更新,如计划在功能维度和语义维度之外新增环境维度,通过还原车辆和用户所处的环境,如设计高速行驶、城区道路行驶、车窗状态、车内噪声环境等,使评估过程更贴切拟合实际场景。
基于单独Adtributor 算法的模型问题定位能力比人工定位能力弱,计划额外引入HotSpot方法,通过投票决策的方式进行问题定位,以提升成功率。
