大数据环境下开放教育学习者画像的构建
2023-04-06王旭红张彤申志华
王旭红 张彤 申志华
关键词:开放教育;数据挖掘;协同过滤;用户画像
0 引言
随着大数据时代的到来,数据挖掘与信息推荐在行政、教育、经济、医疗等各个领域都已经有了一定作用与价值。在线的不断发展使得在线教育行业迎来了更为广阔的发展方向[1]。目前越来越多的人员选择在线课程进行学习,极大地提升人民群众日常接受教育的便利性。
在线教育网站之中存在着大量的注册用户,同时每天都会产生大量的用户注册信息,其中包括用户个人信息、用户学习课程、学习时间等。面对这些大量的信息,日常却无法进行统计和决策工作[2]。平台在给予学习者较高自由度的同时也降低了对学习者的学习引导,从而导致学习者没有合理的学习路径指导,对学习资源进行盲目地学习与浏览,课程体系缺乏逻辑性,学习失败风险升高。学习者在课程进行中逐渐凸显出来的盲目性学习、学习质量下降、参与积极性降低等问题引起了广大师生和研究者的反思。因此,需要将基于学习者的基本信息和在线学习数据进行耦合,刻画学习者学习画像,以此更好地提高学习效率,为学习者提供良好的服务[3]。
1 相关理论
1.1 用户画像
用户画像的定义与发展用户画像是根据用户社会属性、生活习惯和消费行为等信息而抽象出的一个标签化的用户模型[4],其核心是用户标签。在大数据技术支持下通过分析用户信息提炼特征标识丰富用户标签,让用户画像变得立体真实。
用户画像随着大数据等技术的成熟迅速发展,使原本大量沉睡的数据开始发挥商用价值。通过收集用户生活习惯、社会信息、心理特征等信息,建立数学模型,将用户信息标签化,抽象出一个带有标签的虚拟用户。
1.2 大数据
在整个信息化系统逐步发展过程之中,需要处理的数据信息规模越来越大,整个数据所在的应用场景也越来越复杂,需要采用新的技术与分析工具对这些业务进行处理,此时逐步产生了与大数据分析处理相关的专业名词[5]。
在数据挖掘的处理之中,主要的操作内容是对大量的业务数据信息进行分析,这些业务数据信息可能存在数据信息不完全、不规律、数据模糊、瑕疵或者损坏等特点,经过数据挖掘处理之后,能够从这些信息发现有价值、可能有效的数据信息。在整个数据挖掘的处理之中,并不只采用单一的技术进行分析与处理,还将目前的诸多方式进行整合,包括目前应用广泛的人工智能处理领域、应用数学分析处理、机器学习与模式识别领域等技术[6]。
2 研究现状
数据挖掘的相关技术最早于20世纪80年代产生,而知识发现的这个概念来源于数据挖掘领域。20世纪90年代前后,在人工智能国际会议之上,数据挖掘的专门概念第一次被提出,至此数据挖掘的相关技术进入了快速发展的时期。同时由于信息化与互联网的快速发展,数据信息存储与应用的范围越来越广,行业业务快速发展,存储的数据类型种类越來越多,包括音频数据、文字数据、图像数据、网络页面数据等类型,而这些数据信息存储的量也越来越大,由此需要数据库对这些庞大的数据信息进行存储。在完成这些数据信息存储的同时,后续需要对这些庞大数据信息进行管理与分析,而分析正是其中的难点,需要从庞大的业务数据信息之中寻找可能有价值的数据,其难度显而易见,主要原因在于这些大数据量之中,许多数据信息是冗余,与真正的处理需求无关,此时需要对信息之间的距离进行定义,学者也提出了DIT、DIST等相关理念,主要用于对信息状态的转移距离进行衡量,而针对这些数据库之中存在的大数据,数据挖掘正是其中重要的工作方式,分类、聚类等处理理念被陆续提出[7]。
在目前对推荐算法的研究之中,使用的推荐算法主要类型包括基于内容的推荐、基于协同过滤方式的推荐处理等算法,在基于内容的推荐算法之中,其需要对用户与课程的信息进行确认,以此来完成新课程的推荐,但是它需求的信息是巨大的,而且很难获取所有用户和课程的属性以及其他信息。相比之下,协同过滤算法是当今使用最广泛最成功的推荐算法,更注重个性化。然而,该算法至今仍然存在诸多问题和挑战,例如评分矩阵的稀疏性问题,算法的可扩展性问题。针对这些问题,国内外学者进行了不同的研究,提出了不同类型的解决方法,对于数据维度的降低,主要通过主成分分析方法、奇异值分解的方法来进行分析与处理;对于协同过滤算法的稀疏性方面的问题,主要通过BP神经网络的方法进行处理。在这些不同方法的处理之中,都需要舍弃部分的数据信息,因此总体上影响了算法推荐的准确度[8]。
3 用户画像构建过程
3.1 用户数据预处理模块
在整个用户画像的挖掘与处理过程之中,其需要经过对用户信息的收集、整合、规约、清理、变换等多个阶段,每一个阶段主要围绕处理的目标不同,其中前几个阶段是数据信息的初始化处理阶段,以此来使得整个系统的数据信息符合处理的要求,具体每一个阶段的工作内容如下面所示:
1) 数据的收集过程:这个阶段主要的工作内容是确定整个数据信息的来源与处理,寻找合适的数据来完成相应业务的管理。在部分业务的处理过程之中,此部分有公开的数据集信息来进行下载,方便对整个业务进行实现。
2) 数据的整理过程:根据业务处理的需要,对整个用户数据信息进行初步整理,此部分主要的内容是分析与整理整个数据信息的分类与内容,若整理的数据信息不同,方便对这些数据进行整合。
3) 数据的规约处理过程:用户数据收集与整理过程过后需要完成整个数据信息的约定处理,目标是进一步对这些数据信息进行初步预处理,但同时需要对整个数据信息保持真实性。
4) 数据清理完善阶段:在这个阶段,需要对整个规约处理的数据信息进行查看,会发现这些数据信息可能有些存在噪声、有些属性值存在问题、有些数据的一致性存在问题等,这些都需要进行清理完善,以使得这些数据信息符合算法处理的要求,也根据算法的要求来对这些数据信息进行初步的结构化处理,方便数据处理符合要求。
5) 数据变换处理过程:相比清理完善阶段,此过程采用的处理技术更为专业,包括对这些数据信息进行规范化处理,可以采用概化与平滑聚集等方面的技术来对这些数据进行处理,在特定的业务场景之中也可以采用概念分层、数据离散分析等处理方式来完成整个数据挖掘处理的需要。
6) 算法挖掘处理阶段:对上述数据信息进行初步处理之中,将其输入填充到挖掘算法之中,按照整个算法的不同步骤进行处理,以此获取相应的处理结果,并对整个处理结果进行模式评估,判断在数据分析挖掘算法的处理下,得到的结果的正确性有多少,以此来调整对应的算法处理过程,评估整个算法处理的性能。针对整个算法处理的结果进行知识评估与分析,将整个算法处理的结果通过用户能够理解的语言进行可视化的处理,方便用户获取此结果信息。
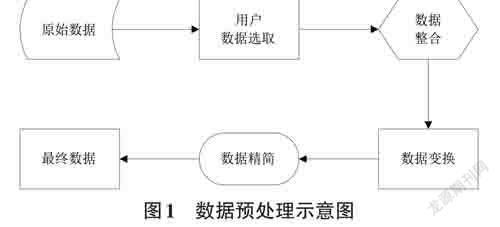
在整个用户画像构建过程中,第一步需要完成整个数据信息的预处理操作,以此获得满足算法处理需要的内容,具体这些数据信息的预处理操作示意图如图1所示。
本文实验将对采用的数据集中的用户画像数据、课程数据以及用户行为数据进行数据预处理,对内容进行提取,过滤冗余的数据,另外,对缺失值和关键词信息进行处理,提高数据质量。将处理后的结果放在字典里面,key为foodid,value为用户信息。
3.2 行为提取和分析模块
在整个用户画像构建之中,行為提取与分析模块主要的作用是确定用户的行为偏好,用户行为特征树状模型之中,主要叙述具体用户行为偏好的建模过程,采用的模型为树状网络模型,每一次对模型的构建都可能影响最后的推荐结果。用户分为多个行为偏好类型,在每一个行为偏好类型之中,其可能包括多个课程类型,每一个课程对应着相应的权重信息。在这个用户行为特征树状模型之中,首层地位主要是用户为主体,在确定用户这个主体之中,第二层主要对行为偏好进行分析,最后完成用户画像的构建。
3.3 用户画像构建
行为提取与分析之后,完成用户偏好信息的获取,之后进行整个用户数据整理,将这些数据信息推荐完成,确定整个用户的历史数据信息。
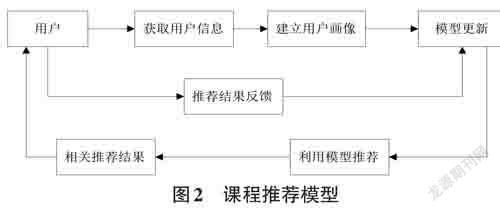
在整个用户画像模型的设计之中,第一步的任务工作重点是获取用户的偏好,这个偏好能够完成用户画像模型的建模,之后采用推荐算法将整个用户的模型与课程信息结合处理,以此进行课程推荐算法的处理。如图2所示。
从图2 课程推荐模型之中能够看出,对于用户而言进行建模首先需要获取这些用户自身的信息,以此方便来完成用户模型的创建,后期对推荐处理之中对模型进行更新,同时记录每一次推荐的结果内容,将这些推荐结果展示在页面之中,方便用户进行查看。
3.4 课程推荐算法
协同过滤推荐算法首先对于用户目录中的用户C1,得到该用户评价高的课程I1,然后找到同样喜欢I1的用户C2,记录用户C2,并计算用户C1和C2的相似度,接着按照相似度从大到小进行排序,选择最相似的N个邻居用户,最后根据邻居用户喜欢的课程,选择用户C1没有评价过的课程进行推荐。
在整个课程推荐算法进行处理的时候,第一步需要获取用户画像,记录这些用户在进行搜索时候的关键字,对这些数据信息进行封装,获取用户相关的数据信息。为了提升算法使用的便利性,对于用户使用频率高的数据信息,需要将这些数据信息添加到词汇库之中,后期用户在检索的时候能够快速显示处理结果信息。根据整个数据信息处理的变化,通过算法来完成使用者兴趣模型的更新处理,为用户提供更为便利的推荐处理服务。对于推荐算法而言,其需要良好的数据信息处理能力,获取用户关键信息,在用户进行检索时候快速反馈处理结果,有效保障数据信息处理的效率与安全性。在整个推荐算法待处理之中,具体包括以下内容:
1) 推荐算法的预处理模块:此功能主要作用是对算法的数据信息进行预处理,使得处理的数据信息符合算法处理的需要,同时去除不合适的数据信息。
2) 算法模型建模:在数据信息预处理之后,后续需要对整个算法的模型进行建模,此模型主要的作用是完成用户兴趣建模。对不同时刻或者不同用户的兴趣进行分析与记录,在整个用户对应兴趣模型出现变化时候,对应进行整个模型的处理。
3) 完成算法模型建模之后,后续主要对输入的预处理数据信息进行分析与处理,将不同的用户分类进行聚类,以此提升算法处理的准确度。同时为了提升算法的准确性,需要将不同用户之间的距离尽可能变大,同时减小相似用户之间的距离,以此降低整个处理的相似空间。
4) 推荐处理结果展示:在整个算法模型处理完成之后,输出处理结果,这些结果信息通过TopN的方式来进行排名,用户能够查询到这些推荐结果的可视化平明,后续需要对这些结果进行过滤评估,以此确定更合适的推荐目标。
