一种基于k-Means算法的船舶主机工况二次划分方法
2023-03-31陆思宇文逸彦
陆思宇,季 盛,文逸彦
(上海船舶运输科学研究所有限公司 航运技术与安全国家重点实验室, 上海 200135)
0 引 言
近年来,随着国际油价不断升高、船舶营运环境日益复杂和全球排放法规越来越严格,航运业和造船业对智能船舶的需求不断提升。智能船舶是当前国家正在大力发展的领域,是船舶未来的一个重要发展方向,关系到航运业和造船业的转型升级[1]。柴油机作为智能船舶的动力核心,需在运行、维护和管理等方面实现智能化,从而使其整体性能进入一个新的层级。
为分析船舶及其主机的性能变化,通常会对二者进行建模和优化,但在不同工况下主机的性能标准不尽相同,因此对主机工况进行划分具有重要意义。谭笑等[2]提出基于聚类算法,根据相对风速和吃水对船舶航行工况进行划分;张惠玲等[3]提出一种基于k均值聚类和马尔科夫链的汽车工况划分方法;林建新等[4]提出一种基于混合约束自编码器的运用主成分分析方法和k-Means聚类算法的机动车工况智能划分方法;孔庆好等[5]提出一种基于卷积神经网络的农机工况识别方法;葛凌峰等[6]提出一种基于高斯混合聚类方法的电厂脱硫节能系统工况划分方法。
当前的工况划分方法多是基于单层次单阶段进行工况划分,这在实际应用中,特别是在海量实船运营数据分析中存在局限性。本文结合能反映船舶主机性能的直接因素和间接因素,提出一种基于k-Means算法的船舶主机工况二次划分方法,为船舶及其主机的性能分析提供参考。
1 主机工况划分方案
船舶智能化是指将信息通信、物联网、数据分析和人工智能等技术应用到船舶上,是智能船舶的关键切入点,是无人船的初级阶段。近年来,中国远洋海运集团有限公司积累了大量基于船端物联网的船舶运营数据,例如船舶状态数据、主机运行数据和气象数据等。通过这些数据,可对船舶的航行情况、能效等进行分析和预测,保证船舶安全高效运营。该方法以船舶大数据为基础进行数据挖掘和分析,整体方案如下。
1) 对数据进行清洗。从数据库中获取船舶航行时采集并储存的数据。该方法需获取船舶主机运行数据,包括第一阶段工况划分和第二阶段工况划分中的相关参数,因此需进行2次数据获取。由于在船舶航行过程中,随着对传感器故障、设备启停和船舶操控等方面的要求越来越严格,可能会出现数据缺失、产生奇异数据的情况,因此需对获取的数据进行缺失和异常方面的处理。
2) 基于聚类算法划分主机工况。根据第一阶段工况划分所需的经过处理的数据,采用聚类算法对其进行分析,若单阶段的聚类结果出现数据过于集中的现象,则引入第二阶段工况划分,通过特征识别,选择与第一阶段不同的参数,采用相同的方法得到第二阶段工况划分的结果。
3) 计算参数的特征值。选取平均值和标准差作为参数的特征值,其中:平均值能反映某个参数在不同取值范围内的一般情况,可用于比较某个参数在不同取值范围内的变化;标准差能度量一组数据的离散程度,标准差越小,意味着数据越接近平均值。[7]将平均值和标准差作为工况划分中的评价指标。
整个主机工况划分方案的简要原理和步骤见图1。

图1 主机工况划分方案的简要原理和步骤
2 k-Means算法原理
k-Means算法是最常用的聚类算法,属于无监督的机器学习算法,其根据未知标签样本的数据集内部数据的特征将数据集划分为多个不同的类,适用于主机工况划分[8]这种相关参数数量和总体数据量庞大、敏感度分析不易的情况,具体算法描述如下:
1) 选择合适的k值,输入样本集为D={x1,x2,…,xm},输出簇为C={C1,C2,…,Ck}。
2) 在D中随机选择k个样本作为初始的k个质心向量μ1,μ2,…,μk。
3) 计算样本xi与各质心向量μj(j=1,2,…,k)之间的距离,有
(1)
4) 重新计算Cj中的所有样本点的质心,有
(2)
5) 若k个质心向量都没有发生变化,则输出簇C={C1,C2,…,Ck};若k个质心向量有变化,则重复上述步骤,直到收敛。
船舶航行过程中的主机工况本来没有明确的分类,但受海况、船舶载况和机桨匹配等多种因素的影响,情况变得较为复杂。k-Means算法是典型的基于距离的聚类算法,其采用距离作为相似性评价指标,认为簇是由距离相互靠近的对象组成的,因此将得到紧凑且独立的簇作为最终目标[9]。对于该方法中的主机工况划分模型来说,首先要将每个阶段选取的2个参数转化为二维向量,而质心μj为这一类样本的中心点。接着,对于一组二维向量,通过欧式距离公式计算其与样本中心点的距离,将距离μj最近的点作为工况划分输出的Cj。以此类推,对各二维向量进行计算,重复迭代,直至质心μj不再发生变化。
k-Means算法的优点[10]如下:
1) 原理简单,容易实现,收敛速度快;
2) 在同类算法中,聚类效果相对较好;
3) 可解释性较强;
4) 对时间的复杂度要求较低;
5) 在处理大数据集方面具有较高的效率,时间复杂度的变化接近线性,适合挖掘大规模数据集。
因此,采用k-Means算法对船舶主机运行数据进行挖掘,实现工况划分,分析不同工况下主机的各项运行指标,判断船舶及其主机性能的变化情况,进而根据船舶总体和主机内部各运行参数的变化对船舶及其主机性能做出定量化分析。
3 基于k-Means算法的主机工况二次划分
根据上述主机工况划分方案和算法原理,以某大型干散货船为研究对象,基于该船2021年的营运数据进行主机工况划分。
3.1 第一阶段工况划分
根据先验知识,选择与船舶航行时的主机工况最直接关联的主机转速和功率作为第一阶段工况划分参数。影响船舶及其主机性能的因素除了船舶吃水、船舶污底和气象条件等外部因素之外,大部分都是主机状态方面的因素[11]。为分析主机的性能,通常会对影响主机性能的指标进行分析,其中主机的转速和功率能清晰地体现主机的性能和运转情况[12],基于这2个参数进行第一阶段的主机工况划分,划分的结果能合理地体现主机在不同工况下的性能变化。该阶段选取的2个参数能直接体现主机的性能。
获取该船2021年的主机转速和功率数据(每小时测量的数据),并绘制主机转速与功率散点图,见图2。由图2可知,数据散点并没有呈现均匀分布的状态,而是呈现出总体分散、大多数点集中在转速为50~65 r/min范围内的状态。因此,将转速为50~65 r/min范围内的数据作为聚类分析的对象,经过数据筛选和清洗的该范围内的主机转速与功率散点图见图3。

图2 原始的主机转速与功率散点图

图3 经过数据筛选和清洗的主机转速与功率散点图
由图3可知,散点主要分布在图中4个区域,主机常在这些区域运转。为得到主机常用工况,区分这4个区域内的数据,确定聚类数k=4,将其代入k-Means算法中进行计算,结果见图4。
图5为第一阶段工况划分中各工况的数据量柱状图。由图5可知,工况2的数据量最大,分布范围较广,实际应用中效果不佳,因此第二阶段的主机工况划分将集中于工况2。

图4 第一阶段工况划分聚类结果
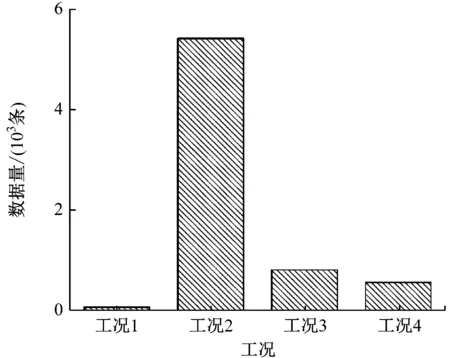
图5 第一阶段工况划分中各工况的数据量柱状图
3.2 第二阶段工况划分
由于第一阶段工况划分是基于主机的转速和功率实现的,若第二阶段仍采用这2个参数划分工况,则所得结果缺乏横向对比,且难以应对主机运行的复杂性。在船舶航行期间,影响主机运转效率的2个环节是做功和冷却。对于大型二冲程低速机而言,扫气箱具有扫排气作用,其温度发生变化意味着主机的运行状况发生变化[13]。船舶设备一般采用海水冷却[14],船舶在航行期间所处海域是不断发生变化的,故海水温度也是不断发生变化的,当用温度发生变化的海水作为冷却介质对设备进行冷却时,会对其运行状况造成一定的影响。因此,该阶段选取海水温度和扫气箱温度作为工况划分的参数,这2个参数能间接体现主机的性能。
由于第二阶段工况划分主要是针对工况2进行的,因此在获取数据时应选择第一阶段参数取值范围内的海水温度和扫气箱温度,经过数据筛选和清洗之后,得出海水温度与扫气箱温度散点图,见图6。

图6 第二阶段工况划分中的海水温度与扫气箱温度散点图
关于第二阶段聚类数k的设定:若取k=2,则在第二阶段仅能得出2个工况,且这2个工况的参数取值范围相差较大,效果并不理想;若取k=4,则得到的4个工况的参数取值范围平均值波动较大,不符合需求。最终确定聚类数k=3,将其代入k-Means算法中进行计算,结果见图7。
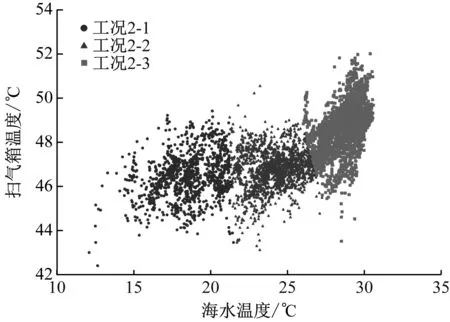
图7 第二阶段工况划分聚类结果
第二阶段工况划分中各工况的数据量柱状图见图8。由图8可知,3个工况的平均值之差相对稳定,符合需求。根据以上工作得出的工况1、工况2、工况3、工况4、工况2-1、工况2-2和工况2-3,整合出最终的工况划分结果。

图8 第二阶段工况划分中各工况的数据量柱状图
4 工况划分结果与参数特征值
根据以上聚类分析结果得出每阶段工况划分的各参数取值范围和不同工况下各参数的平均值和标准差,结果如下。
4.1 第一阶段工况划分结果
第一阶段工况划分中不同工况下各参数的取值范围和特征值见表1。
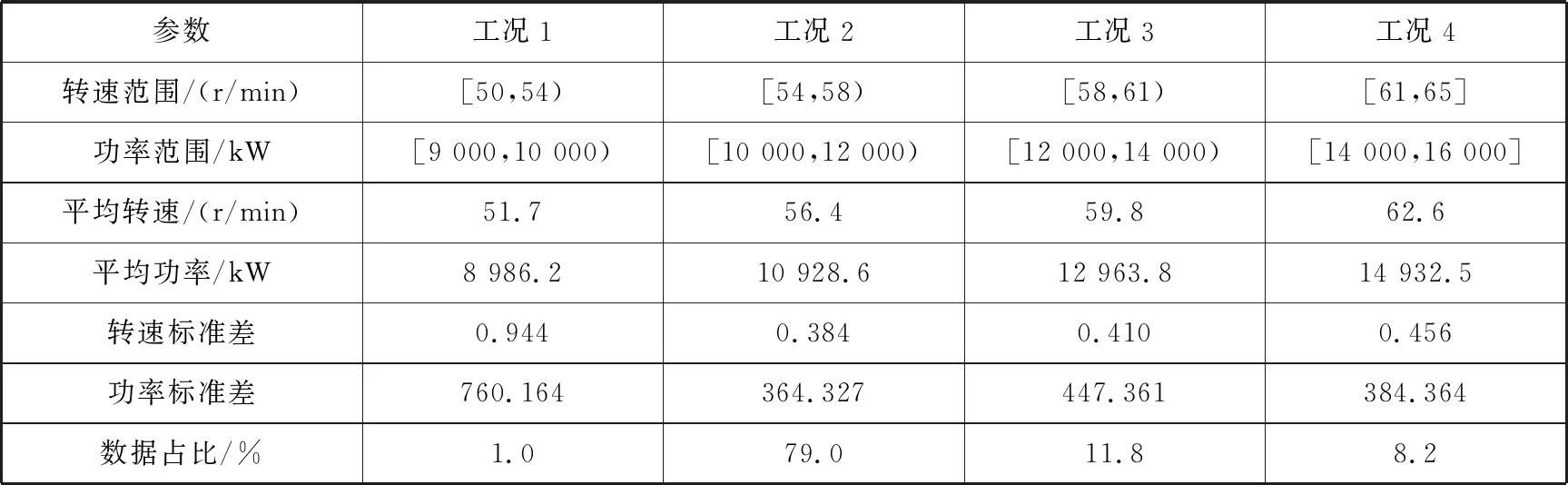
表1 第一阶段工况划分中不同工况下各参数的取值范围和特征值
4.2 第二阶段工况划分结果
第二阶段工况划分中不同工况下各参数的取值范围和特征值见表2,其中“数据占比”为所占工况2的比例。

表2 第二阶段工况划分中不同工况下各参数的取值范围和特征值
4.3 工况分析与最终划分结果
1) 由第一阶段工况划分结果可知,从工况1到工况4,平均转速和平均功率是不断增大的。标准差反映了一组数据的离散程度,工况2的数据占比最大,工况1的数据占比最小,在这2组工况的参数取值范围上下限之差相同的情况下,由于工况2的数据占比远高于工况1,即工况2的数据集中度高于工况1,导致其转速和功率的标准差都小于工况1。工况3的数据占比略高于工况4,在数据占比和参数取值范围差别不大的情况下,工况3的转速标准差小于工况4,功率标准差大于工况4。但是,工况3和工况4的转速和功率标准差都大于工况2,小于工况1。
2) 由第二阶段工况划分结果可知,从工况2-1到工况2-3,平均海水温度不断上升,平均扫气箱温度变化不大,但总体呈上升趋势。从工况2-1到工况2-3,海水温度的标准差随着数据占比的提高而不断减小,扫气箱温度的标准差并未出现这样的一致性,说明工况2-3中数据量的增加并不能掩盖其数据的分散性。
根据上述两阶段工况划分结果,通过整合得出该船最终的主机工况划分结果和各工况下的参数取值范围,主要是以下6个工况:
1) 工况A,即符合工况1的各参数取值范围;
2) 工况B,即符合工况2的各参数取值范围和工况2-1的各参数取值范围;
3) 工况C,即符合工况2的各参数范围和工况2-2的各参数取值范围;
4) 工况D,即符合工况2的各参数取值范围和子工况2-3的各参数取值范围;
5) 工况E,即符合工况3的各参数取值范围;
6) 工况F,即符合工况4的各参数取值范围。
本文采用的是基于k-Means算法的工况划分方法,由于该算法的时间复杂度和空间复杂度较低,因此其在大型数据集中应用较为简单高效。在未来的研究中,将考虑加入风浪对主机性能的影响,并通过自适应调整聚类数k实现工况自动划分。
5 结 语
本文提出了一种基于k-Means算法的主机工况划分方法,采用两阶段多参数的工况划分方法,通过对实船航行过程中主机的各参数进行分析处理,提高主机工况划分的精准度,最终得出实船基于转速、功率、海水温度和扫气箱温度的工况划分结果及各工况下各参数的特征值。该方法没有考虑风浪对船舶阻力的影响,同时因算法本身存在缺陷,聚类结果往往不是全局最优解,而是收敛于局部最优解[15]。在后续研究中,将考虑基于特征识别进行多阶的工况划分迭代。
总体而言,该算法的原理简单,能真实有效地反馈主机运行时所处的工况,为分析和优化船舶及其主机的性能提供参考。后续可对工况作更详细的分析,比如在相同工况下,通过分析主机温度和功率的变化趋势评估主机的性能。此外,还可检查主机在不同工作环境下可承受的温度极限,对温度过高或过低的情况进行预警,并开发辅助指导程序为操作人员提供指导,尽可能地防止故障发生。
