基于胶囊模型的短文本细粒度情感分类
2023-03-30邵辉
邵 辉
(广东科学技术职业学院计算机工程技术学院,珠海 519090)
0 引言
情感分析(sentiment analysis)是指人们对各种服务、产品,包括其属性的情感、评价和观点等的分析研究,又被称为观点挖掘[1]。传统的文本情感分析[2‑4]重在对句子、文档级别进行分析,得出文本中主要观点所表达的情感倾向,通常分为积极、中立以及消极这三种。但互联网普及之前,情感分析的相关研究成果很少,一是因为收集情感文本语料存在困难,很难获取所需要的文本语料。二是文本处理、分析方法达不到应用要求。进入新世纪后,互联网迎来爆发式增长,基于此,各种海量的文本信息在互联网上不断出现,特别是社交领域和电商平台,促使情感分析研究快速发展。
在社交领域和电商平台等,篇幅短小的短文本是互联网用户经常使用的。短文本文字有限,但往往包含明确的观点,特别是在社交软件中,更是经常出现带有用户直接偏好的短文本,这些都非常有利于情感分析领域的研究。当前,情感分析研究已经发展到涉及社会的方方面面,互联网上每天都有无数的短文本产生,对短文本的情感分析工作可以让政府掌握舆情,及时掌握社会大众的诉求,以便于保证社会的稳定和谐;可以让企业和单位了解用户对服务和产品的意见,以便于做出更好的服务和产品。由此可见,短文本情感分析工作是十分有意义的。本文以短文本为研究对象,从目标级的情感分类角度提出了一种基于胶囊模型的方法。
1 相关研究
目标级的情感分类(aspect‑based sentiment classification,ABSC)与情感分析(SA)不同[5],其重在发现文本中实体方面有关的情感。例如对于评论文本,就不同于以往对整句做出情感分析,而是根据句中不同的实体分别做出不同的情感分析,如此一个短文本评论就可能有多个情感极性。比如,“今天一位朋友请我们吃饭,饭菜的味道还可以,但是人太多了,我们等了很久才吃上,而且价格也不便宜。”从这个例子可以看出来,此评价带有三个实体方面的情感倾向:一是餐厅的味道还可以,这是积极的情感倾向;二是等待的时间太久,这是负面的情感倾向;三是价格太贵,这也是消极的情感倾向。如果是情感分析(SA)任务,那就不会有这么多情感极性分析,可能就这个文档或整句给出一个情感极性,那就会忽略其它包含在文档或整句中的情感,只有目标级的情感分类才能做到更细粒度的要求。
目前ABSC 相关研究中,卷积神经网络[6]、循环神经网络[7]和循环自编码模型[8]等神经网络模型已经取得了很好的效果,但是目前存在数据集标注成本高昂、有时需要附加的语言知识辅助等问题。胶囊网络出现后,对解决上述问题起到了很好的作用。胶囊网络由一组神经元构成,是基于动态路由的结构[9]。胶囊利用动态路由算法完成参数互相传递,每个类别的语义由高层胶囊的输出向量来表示;每个实体的实例化参数由激活向量来表示;每个情感极性的预测概率则由向量长度来表示。文本分类中应用胶囊网络是Zhao 等[10]第一次实现,发现胶囊网络不仅能保持灵活的表达能力,同时提高了编码的有效性;Chen 等[11]提出了一种迁移胶囊网络模型,用于将文档级别的知识迁移到面向目标的情感分类。
在前面工作的基础上,本文设计的胶囊模型第一利用BERT预训练模型充分挖掘文本蕴含的情感语义信息,使模型具有更加丰富的情感语义表达;第二利用多头注意力机制让各类特征进行交互,抽象更深层次的上下文内部语义关联;第三采用胶囊网络生成最终的文本表征,从而实现了更好的短文本细粒度情感分类。
2 胶囊网络模型
给定上下文嵌入[12],其由n个词构成上下文序列s={w1,w2,…,wn}。再给定目标嵌入,其由k个目标构成目标序列,t={a1,a2,…,an},很显然,a是s的一个子序列。由此本文的目标可以表示为pol=fpol(s,ai),其中fpol是非线性变换函数。本文设计的胶囊模型如图1所示,分为词嵌入层、特征提取层、注意力编码层和胶囊层,共四层。

图1 胶囊模型各层
在词嵌入层使用BERT预训练模型,将包含n个词的上下文序列转换成s={v1,v2,…,vn},其中vi表示上下文序列第i个词的d维向量,句子的输入词向量矩阵则是S;同理,目标实例则转换为T={vα,vα+1,…,vα+m-1},其包含m个词,形成目标词嵌入序列。其中vi表示目标实例第i个词的d维向量。
在特征提取层,对于上下文序列形成的词向量矩阵,其中的每个词的依赖关系利用LSTM 进行建模,充分在BERT 预训练模型的基础上对隐含语义进行挖掘,得到隐藏状态序列Lh={l1,l2,…,lk},形成上下文序列的高阶特征;对于目标词序列,其中属性实例的各词依赖关系也利用LSTM 进行建模,同理充分对隐含语义进行挖掘,得到隐藏状态序列Th={t1,t2,…,tm},最后也形成目标词序列的高阶特征。
在注意力编码层,上下文序列、目标词序列均采用多头注意力完成注意力编码。多头注意力机制可以简单有效地对上下文依赖关系进行抽象,并捕获句法和语义特征。本层继续对上层输入表示做进一步挖掘,并生成两类输出特征。
最后在胶囊层,对两个多头注意力的输出Ok和Om进行封装加工,最后转换为矢量胶囊集合。胶囊网络确定彼此关系是依据动态路由协议,利用反复迭代的方式直到收敛成功。在注意力编码层,因其输出只能表达局部特性,无法对句子级别进行全局语义表示,因此本层在水平方向对注意力编码层的输入采用全局最大池化进行压缩,使得输出特征在各子空间内聚合。同时利用squash 函数将胶囊向量的模长压缩到1以内,用来表示该特征存在的概率。最后最终情感分类输出层由多类胶囊构成,完成每个情感极性分类。
3 实验
本文评测标准数据集采用semeval2014 的餐厅评论数据集,对于不同的目标实体,分成三类情感极性:积极,中性和消极。此数据集中有极少量数据标记为冲突,将其予以删除。数据集的情况如表1所示。

表1 餐厅评论数据集 单位:个
本模型采用预训练BERT,其维度设置为768。为保证性能,学习率设为2e-5,动态路由迭代次数设置为7,多头注意力头数设置为8。模型最后利用分类精度和F1值来评价模型性能,并同两个基线模型RAM、TransCap 进行比较,结果如表2 所示。从表2 可知,胶囊模型的分类精度和F1值均高于RAM和TransCap。
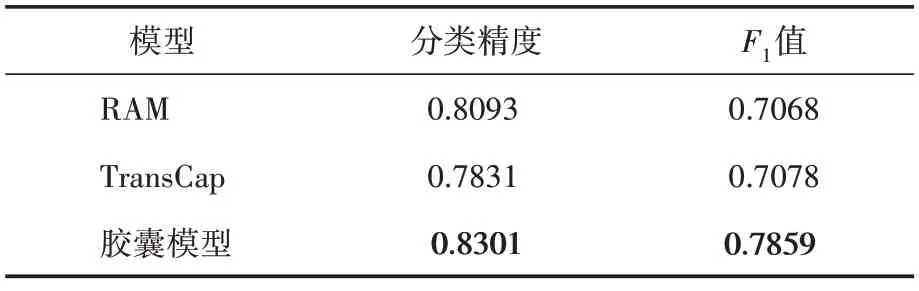
表2 对比结果
4 结语
从实验结果看,本文采用的胶囊模型,其网络深度的有效增加提升了模型性能;采用预训练模型BERT也提高了分类精度,并且对参数微调能可继续提高模型性能;采用胶囊模型则不仅有效提高了分类精度,而且F1值也得到了不小的提升,这说明本文模型对短文本的细粒度情感分类是有效的。
