基于XGBoost 的非侵入式污染企业环保工况识别
2023-03-29李霄铭陈汉城
黄 锐 李霄铭 余 翔 熊 军 陈汉城
(国网福建省电力有限公司信息通信分公司,福建福州 350013)
0 引言
环保作为实现碳达峰、碳中和的重要路径,在“双碳”政策背景下备受关注。目前,传统的环保监测工作主要是通过在每条线末端设置各种传感器进行化学检测,来判断企业是否违规排污[1]。然而,治污设备所处位置的周围环境比较脏乱差,传感器工作容易受外界环境干扰,产生偏差甚至失效。
而电力数据具有覆盖度广、价值密度高、实时准确性强等特点[2],利用电力数据进行环保监测工作实时性强,能从产污源头进行环保监测。目前,大多数基于电力数据的环保监测工作,主要是对治污设备进行电力信息的采集与分析[3-4],当需要监测的治污设备数量众多时,监测设备数量也随之增加,环保监测成本会随之升高,企业较难接受。
基于上述分析,本文研究提出了一种基于XGBoost的非侵入式污染企业环保工况识别方法,即记录企业的生产工况,将企业生产工况与环保设备工况相结合得到企业环保工况,再将企业环保工况与用电数据输入XGBoost中进行训练,得到最终的模型。
1 企业环保工况提取
需要对企业生产工况与环保设备工况一定的先验数据进行训练。对于环保工况的判断方法如图1所示,对于某一个时刻的环保工况,若企业生产正常,且环保设备为开启状态,那么环保工况即为正常,当环保设备关闭,则视为异常,其中,生产设备关闭时视为环保工况正常。这样就得到了环保工况标签。

图1 环保工况判定流程
2 基于XGBoost的环保工况识别
2.1 XGBoost的基本原理
XGBoost(Xtreme Gradient Boosting)是一种高效的基于决策树(CART)的分布式梯度提升算法,它可被应用到分类、回归、排序等任务中。
预测值计算公式如下:
目标函数计算公式如下:
最小化目标函数,经过正则化项对算法学习权重的平滑,最终得到目标函数的最优解如下:
2.2 环保工况异常识别流程
本文提出的环保工况异常识别方法主要流程如图2所示,其主要步骤如下:

图2 环保工况异常识别流程
(1)在监测点获取电能质量监测数据,在选择数据时包括电能质量监测数据与基本电气数据;
(2)记录企业生产工况与环保工况;
(3)将环保工况与电能质量的监测数据输入到XGBoost模型中进行训练;
(4)将企业后续电能质量监测数据输入到XGBoost中进行测试,得到企业的环保工况,识别其中的异常环保工况。
3 仿真算例分析
3.1 污染企业用电工况仿真模型基本情况说明
为了验证本文方案的实用性,搭建了模拟污染企业用电工况的仿真模型。考虑实际企业中各种设备的用电情况,如图3所示,仿真将以一条10 kV的母线进行模拟,其中包含两台生产设备与两台环保设备,同时为了更好地模拟各种用电场景,加入了线性负荷、整流器及单相线性负荷。可以发现,在企业中生产设备多为线性负荷与变频电机,例如变频电机包括钢厂用于轧钢的大型电动机、水泵、压缩机等,而环保设备如静电除尘、增压风机、袋式除尘器等运用了调频、调速、升压等相关电力电子技术,所以在这里用两个变频器进行模拟。

图3 仿真电气接线图
参考非侵入式负荷监测,在10 kV进线处安装一个模拟的电能质量监测装置[5]。如表1所示,在实际监测中,一天24 h,每隔3 min进行一次数据采集,会得到480个点的监测数据,其中包括基本电气量数据与电能质量监测数据。采用等比例缩放的方法,将一天24 h等比例缩放,仿真时间设置为960 s,每隔2 s进行一次数据采集。

表1 仿真数据说明
在算例中,为了更好地监测本方案的实用性,负荷1~5将采用生成随机数的方法来控制负荷启停,即随机生成1~24内的两个随机数,随机数中,前者为开启时间,后者为关闭时间。不同于实际生产中设备的启停具有一定的周期性与规律性,仿真模型中设备的不定时启停,能更好地验证变点检测与聚类算法的实用性与准确性。对于负荷6~9,则一直处于运行状态,来模拟企业工厂中不间断运行的设备。
对于生产工况的分类,模型中共有两个生产设备,针对不同的企业生产场景可能采用不同的生产设备,在这里设置两个不同的生产用电场景。
场景1:负荷1运行时,视为企业正在正常生产,反之为停止生产。
场景2:负荷2运行时,视为企业正在正常生产,反之为停止生产。
划分好生产工况,就可以结合环保设备的工况得到企业的环保工况是否异常。根据实际环保部门的监管规则,设置判定企业环保工况的规则,当企业正常生产时,仅当两台环保设备同时开启时视为环保工况正常,反之则为异常。
3.2 环保工况类别先验数据获取
对模型进行24天数据仿真,共11 520个样本点,用前70%数据进行模型训练,后30%数据进行测试。如表2所示,分别对两个场景下前70%数据的环保工况进行统计。

表2 环保相关工况类别情况
3.3 基于XGBoost模型的环保工况识别结果
这里引入混淆矩阵与机器学习模型评价指标[6]。如图4所示,混淆矩阵是机器学习中总结分类模型预测结果的情形分析表。在本方案中,混淆矩阵表示的是模型判断的环保工况正常与异常两种情况与其真实值的对比情况,其中TP表示模型正确识别出环保工况异常情景下的数量,TN表示模型正确识别出环保工况正常情景下的数量,FN表示模型错误识别出环保工况异常情景下的数量,FP表示模型错误识别出环保工况正常情景下的数量。在预测性分类模型中,肯定希望模型能准确预测环保工况。那么对应到混淆矩阵中,TP与TN的数量越多,FP与FN数量越少,则该模型的拟合程度越高。
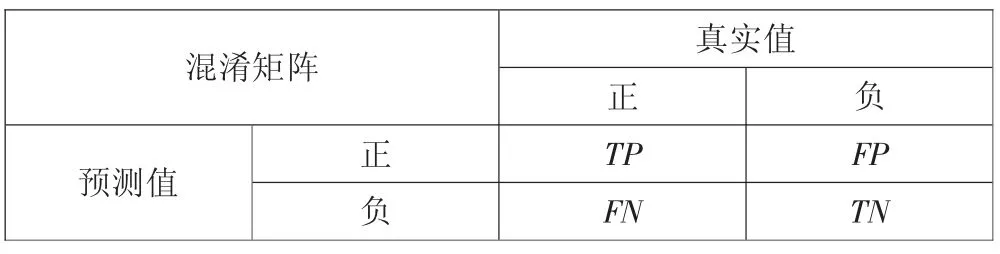
图4 混淆矩阵示意图
在混淆矩阵中统计的为真实值与预测值的数量,当测试的数据集很大的时候,采用百分比能更好地判断模型的好坏。因此,在混淆矩阵统计结果的基础上,又引入了如下3个指标,分别为准确率SACC、精确率SPRE、召回率SREC,下面给出这三个指标的定义。
准确率是预测环保工况正确的结果占总样本的百分比,其表达式见式(4)。
精确率的含义为在被所有预测为环保工况异常的样本中实际为环保工况异常样本的概率,表达式见式(5)。
召回率的含义为在实际为环保工况异常的样本中被预测为环保工况异常样本的概率,其表达式见式(6)。
通过以上3个二级指标,就将混淆矩阵中的数量转为0%~100%之间的百分数,其结果更加直观。在有些场景中,需要同时考虑精确率和召回率,于是便产生了一个新的指标,它的计算公式见式(7)。
对两个生产用电场景,根据环保规则得到环保工况类别。对24天共11 520个数据点,以时间为标准,取前70%数据作为训练数据,后30%数据作为测试数据,其各项指标如表3所示。利用XGBoost模型对环保工况进行测试,在两个生产场景下,SACC与SF1均能达到99%以上,具有较高的识别准确率。
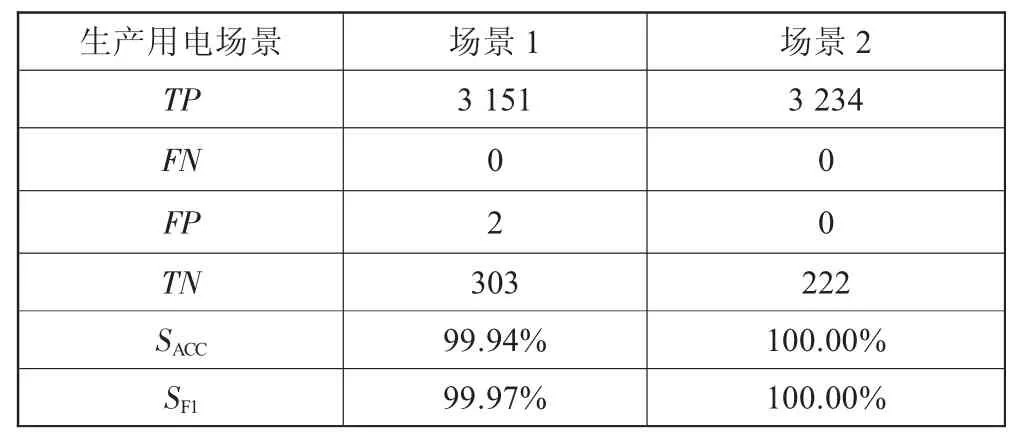
表3 不同场景的分类结果与各项指标
4 结论
针对企业环保监测问题,本文利用电能质量监测数据,根据环保规则,获取环保工况先验数据;然后将电能质量数据与环保工况输入XGBoost中进行学习与训练,实现异常环保工况识别。利用仿真算例对本文方案进行测试与分析,得到以下结论:
(1)利用XGBoost进行学习与训练,对于仿真模型中的数据,在两个生产场景下,SACC与SF1均能达到99%以上。
(2)相比于传统的化学含量检测与对设备一一进行监测,本文方案具有更好的实用性与便利性,减少了监测成本,不影响企业实际生产活动。同时,电力数据还可以在更多领域进行推广应用。
