基于MpBERT-BiGRU的中文知识图谱补全
2023-03-27张骁雄刘文杰刘姗姗
田 昊,张骁雄,刘文杰,刘 浏,3,刘姗姗,丁 鲲
(1.国防科技大学 第六十三研究所,江苏 南京 210007;2.南京信息工程大学 计算机与软件学院,江苏 南京 210044;3.宿迁学院,江苏 宿迁 223800)
0 引 言
知识图谱通常是表示实体和关系的语义关系图,存储形式为三元组,三元组由头实体h,尾实体t,以及它们之间的关系r组成,通常用这些三元组来描述事实。相较于传统数据库,知识图谱更加直观,搜索能力更加优秀[1]。因此,知识图谱被广泛应用于金融、军事、医疗等领域[2]。
随着知识图谱的规模越来越大,其存储的数据量增多,知识图谱出现了图谱稀疏和不完整问题,导致知识缺失现象发生,降低了图谱质量。如图1所示,由三元组<约瑟夫·拜登,妻子,娜丽亚·亨特>、<娜丽亚·亨特,母子,博·拜登>以及<博·拜登,兄弟,亨特·拜登>,易得实体“约瑟夫·拜登”与实体“亨特·拜登”之间的关系为“父子”,但对于同样的结构,知识图谱可能就缺失了“威廉王子”和“路易斯王子”之间的关系。
知识补全是一项解决知识缺失问题的技术,目的是使知识图谱更加完整。知识补全的质量一定程度影响知识图谱的存储质量,从而影响下游应用的质量,如问答、搜索等[3]。知识补全技术首先需要对知识图谱进行表示和建模,然后预测各个三元组中缺失的部分,并判断预测后的三元组是否有效合理[4]。在知识图谱构建过程中,知识补全技术是知识加工的重要组成部分,在学术界和工业界都具有一定的现实意义[5]。
近年来,预训练语言模型在自然语言处理(Natural Language Processing,NLP)任务取得了良好的效果。例如,ELMo[6]借助双向LSTM解决多义词的表示问题,GPT[7]以Transformer的Decoder架构完成分类、相似度等任务;而BERT模型[8]综合考虑ELMo双向编码和GPT使用Transformer编码器的思路,采用Transformer双向编码器作为特征提取器,利用大量未标记数据对模型进行预训练以获取通用的语言表示,再利用少量的标记数据进行微调以应对具体任务,解决了缺少大量高质量标记数据的问题,并有效地捕获了上下文信息。考虑到BERT模型在多个NLP任务的优异表现,该文将BERT引入到知识补全任务中。
不过BERT在进行知识补全任务时,存在以下问题。首先,传统BERT一般采用[CLS]输出值对序列进行表征,但当序列信息过多积压在[CLS]输出值上时,会造成不同知识数据特征近似,影响模型表征能力,降低下游任务效果。有相关研究工作证实此观点,例如Reimers等人[9]在sentence-bert模型中认为,BERT传统表征序列的方法效果不佳,在语义文本相似性任务上的效果甚至不如GloVe,原因就在于[CLS]输出值难以有效表征序列信息,特征信息易形成重叠堆积[10];其次,BERT并行化处理文本,仅依靠位置嵌入向量表示文本之间的位置关系[8],无法像串行的神经网络模型一样按照时间戳建模位置信息,从而弱化了字词位置信息。
同时,就知识图谱构建过程而言,中文知识图谱与英文知识图谱在语法结构、构词方法、句式逻辑结构等方面存在差异[11],而中文语法结构和语言逻辑更加灵活多变,同义词、多义词较多,中文文本的特征更加复杂,更易产生上述的特征重叠堆积问题[12],同时中文语序多变,语境相关性更强,相比英文更加依赖字词间位置关系来表征文本语义,所以BERT在处理中文文本时问题更加突出。
针对上述BERT的模型问题以及中文文本的语言特点,该文改进了BERT模型,提出了一种名为MpBERT-BiGRU的知识补全模型,采用平均池化(mean-pooling)策略,在[CLS]输出值的基础上,计算字词级别隐层特征的均值,使用更合适的均值特征取代[CLS]输出值,缓解传统方法特征信息重叠堆积的问题,增强BERT对句子的表征能力;同时,MpBERT-BiGRU模型通过双向门控循环单元网络(Bidirectional Gated Recurrent Unit,BiGRU)增强均值特征,BiGRU可以串行化处理输入序列,并采用两层GRU学习上下文的字词依赖关系,并且GRU简化了长短期记忆网络(Long Short-Term Memory,LSTM)的门控结构,减少参数量的同时降低了过拟合风险,提高了模型效率[13],这在时间消耗较大的知识补全任务中显得尤为关键。
为了研究MpBERT-BiGRU模型在中文数据集上的知识补全效果,以及以往的知识补全模型是否适用于中文语境,而目前大多数的知识补全研究都以英文数据集为主,如FB15K-237[14]、UMLS[15]和WN18RR[15]等,缺乏高质量中文标记数据,该文结合UMLS数据集和ownthink数据集(http://www.ownthink.com/),并通过数据预处理,构造了UMLS+ownthink中文数据集。
主要贡献如下:(1)构建了中文数据集UMLS+ownthink,验证知识补全模型在中文语料库上的有效性;(2)提出了MpBERT-BiGRU模型,采用平均池化策略处理BERT模型输出的特征向量,改进BERT模型表征三元组能力,并利用BiGRU学习序列位置关系,进一步增强特征向量表示能力;(3)验证了MpBERT-BiGRU模型在中英文数据集上都有所提升,其中在UMLS+ownthink数据集上相较于以往方法,平均排名(Mean Rank,MR)指标上提高10.39,前10命中率(Hit@10)指标上提高4.63%。
1 相关工作
现有的知识补全技术主要包括三种方法,分别是知识嵌入模型、基于深度学习的补全模型和基于预训练语言模型的知识补全模型。
1.1 知识嵌入模型
知识嵌入模型思路类似于Word2Vector模型[16],使用向量来表示实体及其关系。Bordes等人[14]提出的TransE算法是经典的知识嵌入算法,算法将实体间关系映射为两个实体向量之间的变换关系,并调整向量表示以满足h+r=t。随后提出的TransH[17]、TransR[18]、TransD[19]等算法对TransE模型难以处理复杂关系的缺陷进行了改进,取得了较好的效果。Socher等人[20]提出了神经张量网络模型(Neural Tensor Network,NTN),利用实体名称的平均词向量表示每个实体,共享相似实体名称中的文本信息,达到良好的链接预测效果。然而该模型的训练过程耗时较长[20],难以满足特定的速度要求,无法简单有效地处理大型知识图谱。Yang等人[21]在NTN模型的基础上,提出DistMult模型,使用对角矩阵简化NTN模型的得分函数,但是DistMult模型无法有效应对非对称关系。为此,Trouillon等人[22]提出的ComplEx模型在DistMult模型基础上引入复数概念,将实体和关系映射到复数空间中,由于复数空间的共轭向量乘积不具有交换性,且保留了点积的优势,有效应对非对称关系。
知识嵌入模型从结构层面进行研究,可以有效应对结构性较强、语义较简单的知识图谱,达到良好效果。不过在许多知识图谱中,由于实体与关系语义信息复杂且丰富,知识嵌入模型忽略了文本描述等外部信息,同时在应对知识补全任务时NTN等模型训练时间长,成本消耗大,效率较低。
1.2 基于深度学习的补全模型
为了更好地应用文本中的语义信息,许多研究都将深度学习模型应用在知识图谱补全中。Dettmers等人[15]提出名为ConvE的多层卷积网络模型,该模型利用2D卷积进行链接预测,在公共数据集上取得了良好的性能。Nguyen等人[23]提出了一种基于卷积神经网络的嵌入模型ConvKB,该模型将每个三元组表示为一个三列矩阵,将三列矩阵输入卷积神经网络,生成不同的特征图,该模型在链接预测任务中也取得了良好的性能。
不过,ConvE模型在同一维度上的全局特征可能会丢失,影响模型补全性能,而ConvKB模型仍然将实体和关系视为独立的元素,忽略其紧密联系,导致关系隔离和特征丢失[24]。并且,基于深度学习的模型为了增强其泛化能力,需要在大规模标记数据集上进行训练,但以现有的方法,获取大规模的标记数据十分费时费力,因此基于深度学习的模型局限性较大。
1.3 预训练语言模型
随着预训练语言模型在NLP领域的应用越来越广泛,近年来已有研究使用预训练语言模型进行知识补全,取得了一定效果。
Zha等人[25]利用一种称为BERTRL的一体化解决方案推理实体间关系,借助预训练语言模型,通过将关系实例及其可能的推理路径作为训练样本对模型进行微调,达到了良好的效果。Liu等人[26]提出了一种基于XLNet的补全模型,将知识补全任务转化为分类和评分任务,根据不同任务构建三种基于XLNet的知识图谱补全模型。Yao等人[27]提出了名为KG-BERT的框架,该框架将知识补全任务转化为句子分类问题,通过三元组序列进行微调模型,在链接预测、三元组分类和关系预测任务中实现了先进的性能。
不过基于预训练语言模型的知识补全模型存在一定问题,例如KG-BERT模型没有证明在中文语境下的有效性,也没有改进BERT输出值以缓解[CLS]标签表征能力不足的问题,在处理字词位置信息时,只采用了原始的位置编码,无法完全有效地学习字词位置信息。
1.4 中文知识图谱补全模型
以往大多研究都以英文数据集为主,不过近年来,有关中文知识图谱的知识补全工作逐渐增多。
Zhang等人[28]提出BERT-KGC模型,该模型在KG-BERT模型[27]基础上,融入实体类型信息,并根据专家制定的规则从公开数据源抽取中文文物实体,构建中文文物知识图谱数据集CCR20,验证了模型在CCR20数据集上的有效性。Xie等人[29]以生成式Transformer模型为基础,提出GenKGC模型,将知识补全任务转化为序列生成任务,在中文知识图谱AliopenKG500上取得了良好效果。不过,这些中文知识图谱数据集大多没有公开,并且上述方法并没有根据中文特点,针对性地增强模型的特征表征能力和学习语序位置关系的能力。
2 MpBERT-BiGRU模型
针对现有BERT模型在知识补全任务上表征能力不足、字词位置信息弱化的问题,以及中文文本易特征重叠堆积、依赖字词间位置关系的特点,该文提出采用MpBERT-BiGRU模型完成知识补全任务,其中BERT采用bert-base-chinese模型,以应对中文知识图谱语境,模型结构如图2所示。

图2 MpBERT-BiGRU模型架构
利用MpBERT-BiGRU模型进行知识补全的思路与先前的知识嵌入模型和深度学习模型的思路有所区别,主要是利用预训练语言模型进行初始编码,然后经过池化策略和神经网络增强特征信息,采用线性层输出得分,将知识补全任务看做序列分类任务。该模型进行知识补全的主要流程为:
(1)输入层:将头尾实体和关系表示为三段文本,并将三段文本输入模型,其中头尾实体文本为对应的描述文本;
(2)Bert编码层:将输入序列经过BERT编码和多头自注意力机制等计算,得到包含上下文语义信息的初步特征向量;
(3)平均池化层:利用平均池化策略,获取Bert编码层编码后的特征向量均值,缓解[CLS]标签信息堆积、特征重叠的问题;
(4)特征增强层:经过BiGRU网络,利用串行化神经网络处理池化后的特征,充分学习中文文本字词间位置关系,进一步增强特征信息;
(5)输出层:通过线性分类层和激活函数处理BiGRU的强化特征,得到一个二分类得分结果,即将知识补全任务转化为分类任务,合理有效的三元组的得分较高。
2.1 输入层


(1)

图3 增加实体描述的输入序列
2.2 Bert编码层
Bert编码层主要以BertModel为基础,BertModel由BertEmbeddings和BertEncoder组成,BertEmbedd-ings负责对三元组输入进行初始编码,得到的向量由BertEncoder进一步进行语义信息融入。
定义L为输入序列Seq(h,r,t)的长度,H为模型的隐藏层大小。BertEmbeddings负责处理序列化输入,将输入序列Seq(h,r,t)转化为三种嵌入矩阵,分别是词嵌入矩阵Ew、位置嵌入矩阵Ep和类型嵌入矩阵Et,其中Ew是每个字的嵌入值,Ep代表每个字的位置信息,Et用来区分三元组不同部分。再将3种嵌入矩阵求和,合并成输出的嵌入矩阵X,如式(2)所示。
X=Ew+Ep+Et=(x1,x2,…,xL)T
(2)
其中,xi(i=1,2,…,L)是每个字的向量表示,xi维度为H×1,X维度为L×H。
BertEncoder是BertModel的编码层,BertEncoder主要由N层BertLayer组成,每层BertLayer由BertAttention、BertIntermediate和BertOutput组成,BertLayer结构如图4所示。
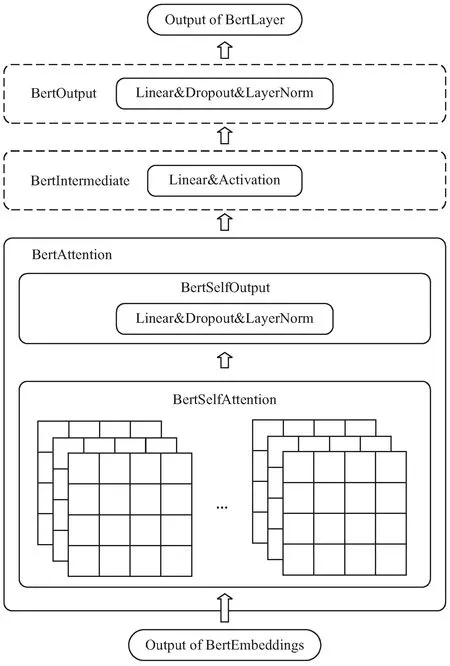
图4 BertLayer架构

(3)
(4)
(5)

再将Q和K矩阵相乘,进行缩放点积操作,通过softmax函数并与V矩阵相乘,得到第i头的注意力权重分量Yi,如式(6)所示,连接n头注意力权重分量,得到多头注意力权重Y,如式(7)所示。
(6)
Y=(Y1,Y2,…,Yn)
(7)
其中,Yi维度为H×d,Y维度为L×H。
BertSelfOutput层将BertSelfAttention层输出的Y经线性层、Dropout层和LayerNorm层归一化,得到整个BertAttention层的输出A,如式(8)和式(9)所示。
(8)

(9)
其中,参数矩阵Wdrp维度为H×H,偏置向量bdrp维度为1×H,αdrp∈[0,1)为Dropout率,A维度为L×H。
BertIntermediate层包含线性层和激活函数,将A的维度从L×H扩大到L×S,如式(10)所示。
U=gelu(AWInt+bInt)
(10)
其中,参数矩阵WInt维度为H×S,偏置向量bInt维度为1×S,U维度为L×S。
BertOutput层和BertSelfOutput层类似,由线性层、Dropout层和LayerNorm层组成,线性层将矩阵U由维度L×S缩小到维度L×H,然后归一化得到BertLayer的输出,再将这个输出作为输入到下一层的BertLayer中,经过N层的BertLayer叠加,得到充分融合上下文语义信息的特征矩阵Z,如式(11)和式(12)所示。
(11)

(12)
其中,参数矩阵Wdrp′维度为S×H,偏置向量bdrp′维度为1×H,αdrp′∈[0,1)为dropout率,Z维度为L×H。
2.3 平均池化层

(1)传统BERT以[CLS]标签表征序列的思路为:
设特征矩阵Z在每个维度i(i=1,2,…,H)的第一个位置的隐层值h(i,0)为[CLS]标签值,并以各个维度的[CLS]标签值拼接为序列表征向量E'=(h(1,0),h(2,0),…,h(H,0))。
(2)采用的平均池化策略的主要思路为:

(13)
(14)
2.4 特征增强层
特征增强层由两个GRU子网络组成,分别进行前向传播和后向传播。GRU利用更新门控制当前时刻t对前一时刻t-1的信息接收程度,并通过重置门控制对前一时刻t-1的信息忽略程度,单向GRU网络结构如图5所示。

图5 GRU网络结构
rt=σ(ht-1Wr+etWr+br)
(15)
(16)
zt=σ(ht-1Wz+etWz+bz)
(17)
(18)
E=(h1,h2,…,ht,…,hH)
(19)

2.5 输出层


(20)
其中,W为模型2×H的参数矩阵,Sco是一个二维向量,由两部分Sco1,Sco2∈[0,1]组成,且Sco1+Sco2=1。
微调阶段,由于数据集中的三元组都是事实,这些事实组成真样本集D+,因此需要采用替换法构造负样本D-,具体做法如下:(1)对于真样本三元组T=
D-={(h',r,t)|h'∈E∧h'≠
h∧(h',r,t)∉D+}
∪{(h,r,t')|t'∈E∧t'≠
t∧(h,r,t')∉D+}
(21)
因此,给定正负样本集D+和D-,计算二进制交叉熵损失函数L,如式(22)所示。
(22)
其中,yT∈{0,1}为三元组T的标签(负样本或真样本),Sco1,Sco2∈[0,1]分别是三元组T属于两种标签的概率得分。
3 实验分析
3.1 数据集
目前大多研究都使用FB15K-237[14]或WN18RR[15]等英文数据集,缺少合适的中文知识补全数据集。为验证模型在中文数据集上的效果,该文构建了数据集UMLS+ownthink,该数据集主要由中文UMLS数据集[15]和ownthink中文数据集的子数据集组成,并通过数据预处理、实体对齐等操作,解决了重复实体等问题。
其中UMLS是一个主要以医药领域为基础的知识图谱,以<实体,关系,实体>的三元组形式存储数据,包含了135个医药领域实体和46个实体间关系,以及6 000多条三元组数据,整个图谱结构性完整,紧密性良好,原数据集为英文数据集,该文对英文数据集进行了裁剪和中文加工,构建了中文的UMLS数据集。
ownthink数据集是一个拥有亿级三元组的通用领域知识图谱,但由于ownthink的存储形式为<实体,属性,值>,并不完全符合<实体,关系,实体>的三元组形式,加之原数据集稀疏性较大,数据构成不规范、值缺失等,因此根据“所属国家”“界”“软件语言”等属性,从庞大的ownthink数据集中抽取了部分高质量数据形成ownthink数据集的子集,再按照子集的实体名称,将实体的描述文本从ownthink数据集中抽出,将子数据集和描述文本加入中文UMLS数据集,融合组成UMLS+ownthink。
表1展示了ownthink数据集、ownthink子集、中文UMLS数据集以及所用的UMLS+ownthink数据集统计信息。

表1 中文数据集统计
3.2 基线模型
为验证和测试MpBERT-BiGRU模型的有效性,将如下模型作为基线模型:TransE模型[14],由Bordes等人于2013年提出,将实体间关系表示为实体间的平移向量;TransH模型[17],于2014年由Wang等人提出,改进了TransE模型,将三元组映射到基于关系的超平面;TransD模型[19],由Ji等人于2015年提出,模型提供两种动态投影矩阵来投影实体;DistMult模型[21],由Yang等人于2015年提出,采用对角矩阵替代关系矩阵,简化了模型复杂度;ComplEx模型[22],于2016年由Trouillon等人提出,引入复数概念,较好地处理了非对称关系嵌入;KG-BERT模型[27]由Yao等人在2019年提出,将预训练语言模型应用于英文知识补全任务。
3.3 实验设置
实验部分采用Pytorch框架实现,实验环境为24G显存的GeForce RTX 3090 GPU,模型的BertModel部分选择bert-base-chinese模型,参数总数量为110 M,隐层大小为768,BertLayer层数为12,多头注意力机制头的数目为12。
经过实验调整,模型的超参数设置:最大输入序列长度为30,训练批次为5,批处理大小为256,激活函数为gelu,Adam优化器的学习率为5×10-5,dropout率为0.1。
3.4 实验任务及评估指标
链接预测是知识补全领域的典型任务之一,用于评估知识补全效果,给定三元组
(23)
(24)
链接预测的主要评估指标为平均排名(Mean Rank,MR)和前k命中率(Hit@k)。MR指目标三元组的平均排名,此指标越小代表模型性能越好;Hit@k指目标三元组排名在前k名的比率,此指标越大代表模型性能越好。实验排除了替换后的其余正确三元组对目标三元组排名的影响,使用Filtered Mean Rank和Filtered Hits@k指标,分别表示删去了其他正确三元组后目标三元组的平均排名和删去了其他正确三元组后目标三元组在前k个三元组中出现的概率。
3.5 链接预测实验
在中文数据集UMLS+ownthink上的链接预测实验结果如表2所示。该文使用开源知识图谱嵌入工具包OpenKE[30]对TransE模型[14]、TransH模型[17]、TransD模型[19]、DistMult模型[21]、ComplEx模型[22]进行链接预测实验,KG-BERT模型[27]在原模型基础上,将英文BERT模型bert-base-cased更改为bert-base-chinese模型进行链接预测实验。

表2 中文数据集链接预测实验结果
实验结果表明,提出的MpBERT-BiGRU模型在UMLS+ownthink中文数据集取得了最优的指标效果。具体分析如下:
(1)在MR指标上,MpBERT-BiGRU模型相较于第二名KG-BERT模型提高了10.39(提升了21.07%),相较于第三名TransH模型更是提高了808.55(提升了95.41%),而KG-BERT模型相较于第三名TransH模型也提升了798.16(提升了94.18%),说明在模型的平均性能上,预训练语言模型提升十分明显,这得益于预训练语言模型独特的训练机制和融入的实体知识信息;在Hit@10、Hit@3和Hit@1指标上,MpBERT-BiGRU模型相较于第二名KG-BERT模型,分别提高了4.63百分点(提升了8.13%)、4.77百分点(提升了10.48%)、4.2百分点(提升了11.37%),这说明在预测目标三元组时,MpBERT-BiGRU模型都有更大几率预测正确;这说明了该模型利用BERT模型结合平均池化策略和BiGRU的方法相比较原始BERT补全模型,取得了一定进步;
(2)DistMult模型和ComplEx模型采用双线性乘法运算,比较依赖实体相似性特征,因此在应对UMLS+ownthink这种多实体少关系的稀疏图谱时,难以发挥其优势,在MR和Hit@10上表现并不突出,不过在Hit@1上表现良好;
(3)Trans系列模型相较于DistMult模型和ComplEx模型,采用了向量平移方法,针对稀疏图谱时可以捕捉实体信息,有效地进行实体和关系建模,因此在中文数据集上的Hit@10的指标比DistMult模型和ComplEx模型都好,尤其是TransH模型根据不同的关系构建对应的超平面,将三元组映射到不同超平面上,在关系较少时,可以有效建模三元组。不过,Trans系列模型在Hit@1指标上表现不佳,说明了Trans系列模型在面对较多候选实体时,难以做出准确预测,模型有一定局限性。
3.6 消融实验
3.6.1 池化策略对比

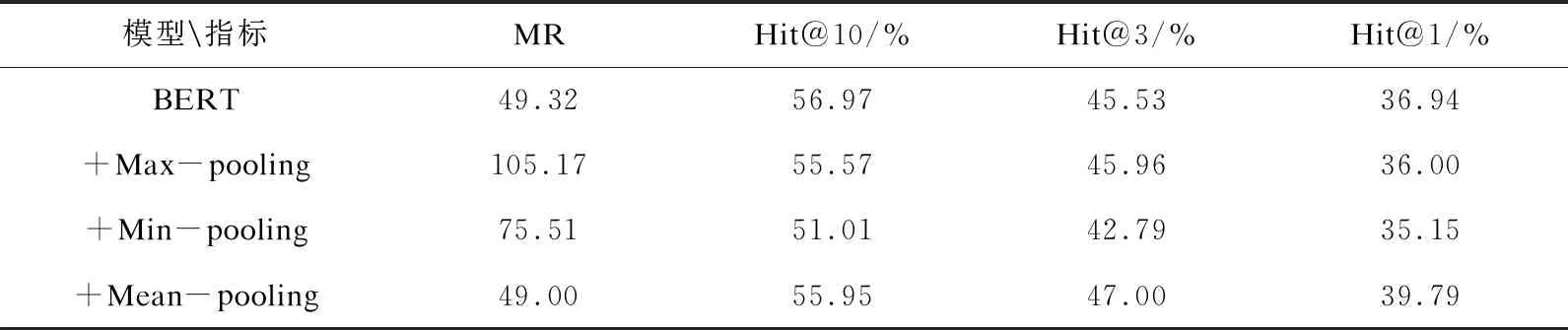
表3 BERT池化策略对比实验结果

表4 BERT-BiGRU池化策略对比实验结果
(25)
(26)
实验结果表明,无论是否有BiGRU模块,平均池化策略在MR、Hit@3、Hit@1指标上都有所提高,具体分析如下:
(1)不叠加BiGRU的BERT模型在采用平均池化策略后(即MpBERT模型),在MR指标上相比第二名提高了0.32,基本持平,不过在Hit@3和Hit@1指标上相比第二名分别提高1.04百分点和2.85百分点,说明平均池化策略有助于BERT模型预测出正确三元组;
(2)叠加了BiGRU的BERT模型在采用平均池化策略后(即MpBERT-BiGRU模型),在MR、Hit@3和Hit@1指标上相比第二名分别提高了1.0、1.65百分点和0.28百分点,说明平均池化策略的有效性,总体上改善了模型对三元组序列的表征能力,提升了链接预测的实验效果。
3.6.2 特征增强策略对比
为了验证BiGRU网络增强特征的有效性,对BERT叠加不同的神经网络模型(BERT-RNN、BERT-BiLSTM、BERT-BiGRU)进行链接预测对比实验,并舍弃平均池化策略以排除其影响,链接预测实验结果如表5所示。同时,为了验证GRU运行效率比LSTM更高,设置不同训练批次,对比了BERT-BiGRU模型与BERT-BiLSTM模型实验时长,如图6所示。

表5 不同神经网络模块实验结果

图6 不同神经网络模块实验时长
实验表明,BiGRU网络在实验效果和运行时间方面都取得了良好的效果,具体分析如下:
(1)BERT-BiGRU模型相较于无BiGRU网络的BERT模型,MR提高7.71,Hit@10提高3.87百分点,Hit@3提高1.9百分点,Hit@1提高0.82百分点,说明了叠加了BiGRU网络的BERT模型在总体性能上有所提高,BiGRU网络有助于BERT预测正确实体,提高了知识补全效率;
(2)BERT-BiGRU模型除了在Hit@1指标略低于BERT-BiLSTM模型外,MR、Hit@10和Hit@3指标相比于BERT-BiLSTM模型分别提高了12.75、3.75百分点和1.06百分点,而BERT-RNN模型在各项指标上都不如BERT-BiGRU模型,在Hit@10、Hit@3和Hit@1指标上甚至不如原BERT模型,说明了在链接预测任务中,BiGRU网络相较于RNN或BiLSTM网络更加有效;
(3)不同神经网络模块的实验时长显示,BERT-BiGRU模型相较于BERT-BiLSTM模型,在各个训练批次数下都具有更快的运行速度,训练用时较少,证明了BiGRU模块较BiLSTM模块效率更高;
(4)对比表3和表4可知,采用不同池化策略的模型在叠加了BiGRU模块之后,在各个指标上都有一定提升,其中MpBERT-BiGRU模型相比MpBERT模型在4种指标上分别提升了10.07、5.65百分点、3.3百分点和1.35百分点,说明BiGRU网络是有效的,有助于模型预测正确的实体,改善模型的补全效果。
4 结束语
针对传统BERT知识补全模型表征能力不足、字词位置信息学习能力不足的问题,以及中文文本易特征重叠堆积、依赖字词间位置关系的特点,提出名为MpBERT-BiGRU的中文知识图谱补全模型,采用平均池化策略,缓解了传统BERT模型将[CLS]标签输出值作为表征向量,序列表征能力不足的问题,以及中文文本特征相似重合的问题,并且叠加BiGRU网络,充分学习中文文本字词间位置关系,缓解BERT模型并行运算带来的弱化位置信息的负面影响;同时模型将三元组转化为文本序列,注入实体描述信息作为模型输入,赋予实体具体的背景语义信息,叠加线性分类层,将知识补全任务看作句子分类任务,利用预训练语言模型优势,克服传统方法忽视语义特征的缺点,并使用少量标记数据进行微调模型,减少数据收集处理成本和模型训练成本。
为了验证方法在中文语料库的性能,构建了UMLS+ownthink中文数据集,并在此语料库上完成链接预测实验和对应消融实验。结果表明,MpBERT-BiGRU模型性能相较于以往方法有一定提升,平均池化策略和BiGRU网络具有一定合理性,验证了MpBERT-BiGRU模型在中文语料库上的知识补全是有效的。
未来研究方向应包含如下几点:采用更适合的预训练语言模型替代BERT模型;针对Hit系列指标不突出问题,采用更适合的池化策略,或考虑如何更好地融入实体间关系特征;该文研究的是静态知识图谱补全,下一步应研究如何运用到动态知识图谱补全领域。
