基于K-means SMOTE 和随机森林算法的陷落柱识别模型
2023-03-27王怀秀刘最亮
郝 帅,王怀秀,刘最亮
(1.北京建筑大学 电气与信息工程学院,北京 102616;2.华阳新材料科技集团有限公司,山西 阳泉 045000)
近年来,随着现代化大型矿井建设的发展以及煤炭开采的不断深入,陷落柱的存在严重威胁着煤矿的生产安全,同时影响煤矿安全高效发展。为此需要寻找一种方法能够比较准确地识别矿区地下陷落柱,为煤矿高产高效提供有力的技术支持[1]。
目前,高精度三维地震勘探技术已在地质异常体识别领域得到广泛应用。高精度三维地震资料具有数据量大,信息丰富,空间分辨率高的特征,可以较为精细地反映地震振幅、相位的变化,可以用于精细的断层、陷落柱及地质异常体的解释。多维环境中的各种信息,包括几何学、运动学、动力学和统计特征都包含在这些多维地震数据之中。它们通常用地震属性来描述[2]。目前,针对各种不同地质任务提出的地震属性达到上百种之多,这些地震属性能用来凸显地质异常体的地质特征,并在一定程度上辅助地震解释工作。白瑜等[3]应用相干体属性分析技术在研究区域成功地识别多处小规模的陷落柱,在实现对地质构造的解释的同时也弥补了常规三维地震解释不能很好地识别小规模陷落柱的不足;李强等[4]通过分析陷落柱的属性特征及实例对比,证实相干、曲率、倾角、纹理等地震属性分析技术均可以有效提高陷落柱识别的准确度和可靠性。上述方法虽然取得了一定的成果,但是存在单一属性信息量少,往往不能全面反应地质体特征;存在多解性可能导致片面结果,并且需要主观判断和解释经验的问题。因此,需要一种联合多种地震属性的解释方法[5]。
随着计算机水平的高速发展,机器学习的出现为地震解释提供了更多的工具。它能综合利用多种地震属性来对陷落柱进行识别。LI Dong 等[6]讨论了多种传统机器学习算法在陷落柱识别工作中的可行性,证明了将机器学习算法应用于地质构造预测,可以有效地提高地震解释的效率。但是基于机器学习的地震构造解释方法对原始地震数据质量和属性值有较高的要求。因此,改进机器学习算法和提高算法容错性成为未来研究的方向[7]。
目前主要使用机器学习算法中的监督分类算法来实现对地质异常体进行识别的目的,即使用既有特征数据又有标签的数据进行训练,让模型学习到特征和标签之间的关联,使得模型在面对只有特征而没有标签的数据时,可以判断出其标签值。但是这类方法存在1 个缺陷,即当训练样本数据集存在数据不平衡情况时,就会导致模型的分类效果下降[8]。对于地震多属性数据集来说,当非陷落柱数据数量明显多于陷落柱数据数量时,分类结果将向非异常体方向偏移,导致目标的预测准确率降低。为了解决数据不平衡带来的分类结果偏移问题,国内外学者研究并提出了大量解决方法。其中比较经典的是CHAWLA 等[9]在2002 年提出的1 种改进的随机过采样SMOTE 算法,该算法不是简单的随机抽样,重复原始样本,而是由公式生成的新的人工样本。但是SMOTE 算法也会在一定程度上增加样本正负类之间的不平衡性。
为了克服上述问题并更好地识别陷落柱,构建了1 种基于K-means SMOTE 结合随机森林的机器学习分类模型,首先利用K-means 方法找出原始负类的中心点,再根据SMOTE 过采样方法得出“新增负类”,将原始数据集中的负类全部替换为“新增负类”,再次利用SMOTE 算法得出“新数据集”,有效地克服了类间和类内的不平衡和经典SMOTE 算法的缺点[10];再结合随机森林分类算法,将地震多属性数据集作为学习样本来对陷落柱进行识别。
1 地震属性评估与选择
1.1 地震属性评估
地震属性是通过三维地震勘探技术得到的能够反映陷落柱构造特征的数据,尽管这些地震属性都在一定程度上可以对陷落柱进行解释,但是过多的属性还是会难免造成信息的冗余[11]。为了进一步提高陷落柱识别的精度,需要对属性进行评估。首先,通过计算属性之间的相关系数得到各个属性之间的相关性关系;再通过分析属性之间相关系数的绝对值大小来判断属性之间的相关性强弱,相关系数的绝对值大小和相关性成正比关系。
在分析完各个地震属性之间相关性关系后,再进行R 型聚类分析。该分析的目的是评估各属性之间的相关性,将相关性较强的地震属性聚为一簇,以便得到更直观的属性之间相关性关系[12]。最终通过结合随机森林重要性分析,对属性值和标签值相关性进行分析,使得最终选择的属性与其他属性和目标值之间都存在较好的相关性。
1.2 地震属性选择
在对地震属性进行评估之后,将多余的地震属性从属性数据集种筛选出去完成对属性的选择,为了使优选的属性能够满足陷落柱识别的任务,所优选的地震属性需要具备2 个标准:①不能盲目选择地震属性,并且不是属性数量越多越好,而是需要选择有限个属性使模型的识别准确率达到最高;②应该独立统计每1 个地震属性,相关性较强的属性不应放在同1 个数据集中用来进行分类,相关性较强的属性应该放在一起进行讨论,组成1 个属性簇,再根据属性重要性分析,从每个簇中只选取1 个属性作为最具代表性的属性组成数据样本。
2 方法原理
2.1 K-means SMOTE 过采样算法原理
K-means SMOTE 采用常用的K-means 聚类算法和SMOTE 过采样方法相结合,以用来对数据集进行平衡处理。该方法的思想是设法在安全区域进行过采样来避免噪声的产生并同时解决类别间的不平衡和类别内的不平衡问题[13]。K-means SMOTE 算法原理图如图1。

图1 K-means SMOTE 算法原理图Fig.1 K-means SMOTE algorithm schematic
1)使用K-means 对整个空间进行聚类。在所有样本中,随机选择个数据点并将其作为样本聚类中心:C1、C2、C3、…、CK。
2)计算每个样本到聚类中心的距离d:
式中:xi∈D;D 为样本合集;CK∈C。
3)将样本分配到最近的集群中。xi∈Cnearest,Cnearest为最近的样本集群。
4)重新计算集群中心:
式中:μi为新的集群中心;Ci为样本聚类中心。5)重复上述步骤2)~步骤4),直到聚类中心不再改变。
6)过滤少数类较少的聚类,选择少数类较多的聚类,合成新的少数类样本。
7)在每1 个经过过滤的簇中执行SMOTE 过采样算法:
式中:rand(0,1)为0~1 之间的随机数;Xnew为1个新的合成少数类样本;xc为从过滤的簇中的最近邻集群中随机选择的少数类样本;~x 为表示过滤后的聚类中的少数类样本。
2.2 改进的随机森林陷落柱识别模型构建
随机森林是Breiman 于2001 年基于随机决策树的概念提出1 种高级集成学习算法。它首先利用Bagging 算法的思想结合几个传统的决策树分类模型来改善泛化误差,并结合随机特征选择技术来参与每个基决策树的节点划分过程。这种集成方法集成了多个模型并相互补充,与单个决策树分类器相比,随机森林具有更高的预测精度和不易发生过拟合的优点且能较好地处理高维度数据,并且能够分析各个样本特征对分类结果的重要性[14]。具体的随机森林实现步骤如下:
1)假设训练集有N 个样本,利用Bootstrap 法有放回的抽取样本(每次随机选取1 个,然后返回继续选择),最终选择好了N 个样本用来组成训练决策树的训练集。
2)假设样本中包含H 个属性,随机从这H 个属性中选取h 个属性(h≤H)用于每1 颗决策树的每个节点的分裂。然后从其中选择1 个最具有分类能力的属性作为该节点的分裂属性。
3)用步骤2)的方式来形成决策树的每1 个节点。直到不能分裂为止。
4)按照步骤1)~步骤3)建立大量决策树,构成随机森林。分类结果按照树分类器的投票量而定。
构建随机森林需要通过经验选择合适的超参数n_estimators(森林中树的个数)和max_tepth(树的最大深度)使得模型的分类效果达到预期。人工选择参数需要不断地对2 个参数进行组合并比较模型准确率,既增加了工作量又耗费时间。所以提出利用网格搜索与交叉验证的方式来寻找使模型得分最高的参数组合,实现自动超参数寻优。
网格搜索法是1 种穷举搜索的超参数寻优算法,该算法具有较强的通用性,并且简单高效适合对较少的参数进行寻优。其本质就是将参数空间划分成若干个网格,通过遍历网格交叉点处所有参数组合来对需要训练的模型进行优化,同时计算其对应模型的准确率。只有遍历网格平面的所有节点,才能得到使准确率最高的参数组合。随机森林通过网格搜索得到最优参数值,最优参数得到的模型可以使用网格搜索参数best_score,即模型的平均交叉验证得分来评估分类效果的好坏,得分越高表明该分类模型的分类效果越好。
同时随机森林在分析不同的样本特征时会展现出不同的分类效果并且在对不平衡数据集进行训练时,模型的预测精度会向多数类样本进行偏移。因此在此基础上提出了1 种对随机森林模型进行优化的方法,分为3 个步骤:①利用前期的地震属性优选工作,挑选出使模型分类准确率最高的特征组合作为样本特征,评价指标为模型的准确率Precision;②利用K-means SMOTE 算法对样本数据集进行处理获得平衡的地震多属性数据集,用该数据集作为训练样本训练随机森林分类模型;③利用网格搜索和交叉验证的方法对随机森林的超参数n_estimators和max tepth 进行寻优,以期获得最高得分的随机森林分类模型。基于改进的随机森林模型识别陷落柱的过程,可看作1 个监督学习过程,同时也是1 个二分类问题,即将地震多属性数据分成“陷落柱”和“非陷落柱”2 类;每个样本的特征为优选后地震属性组成。改进的分类模型构建过程如图2。

图2 改进的分类模型构建过程Fig.2 Improved classification model building process
3 陷落柱识别实例
3.1 研究区概况
以山西新元煤矿首采区东翼南部矿区煤层为研究区。研究区行政区划属晋中地区寿阳县,勘探范围由以下坐标点连线圈定,东西宽2 km,南北长1.5 km,勘探面积3.0 km2。
研究区含煤地层主要为二叠系下统山西组。其中3#煤层属主要可采煤层,煤层厚度2.41~3.60 m,平均厚3.18 m,顶板为砂质泥岩、泥岩,底板为砂质泥岩,属稳定煤层。从以前研究本区进行的二维地震资料来看,区内陷落柱较为发育,构造复杂程度应属中等。研究区域陷落柱构造图如图3。

图3 研究区域陷落柱构造图Fig.3 Structural diagram of collapsed column in the study area
选取首采区东翼南部矿区作为研究区域,研究中利用三维地震勘探成果,按照5×5 网格提取出研究区域3#煤层所对应x、y 坐标及相关属性信息,结合专家经验最终提取了12 种地震属性(方差体、均方根振幅、平均能量、倾角、瞬时频率、瞬时相位、最大振幅、最大能量、最小振幅、总振幅、中值振幅、主频),对该区域内的属性数据进行分类标记,共得到5 360 个数据点。其中代表无地质异常构造的数据点有4 496 个,用标签值“0”来表示;代表陷落柱的数据点只有864 个,用标签值“1”来表示。由此可见,数据集中2 个不同类别的样本数量之间存在较大的差异,即存在数据不平衡现象。
3.2 采区属性评估与选择
1)对12 种地震属性进行相关性分析,计算得到的属性之间相关系数见表1。
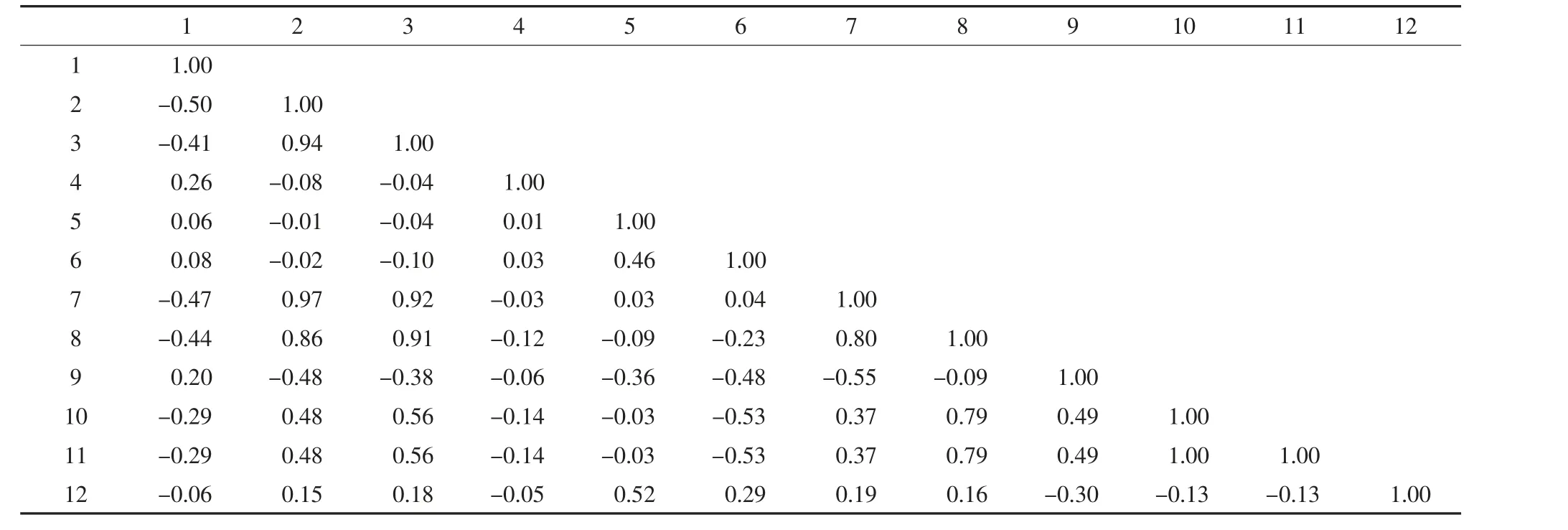
表1 地震属性之间相关性分析Table 1 Correlation analysis between seismic attributes
2)利用R 型聚类分析将相关性较高的地震属性聚为一簇。R 型聚类结果图如图4。

图4 R 型聚类结果图Fig.4 R-type clustering result graph
3)根据随机森林重要性分析,从每个簇中选出与目标相关性最高的地震属性作为最终的样本特征。随机森林重要性分析如图5。聚类模型效果图如图6。
由图6 可知:优选6 个属性时,随机森林分类模型的准确率达到最高。这时瞬时相位、总振幅、中值振幅的相关性较高聚为1 簇;均方根振幅、平均能量、最大振幅、最大能量的相关性较高聚为1 簇;瞬时频率和主频的相关性较高聚为1 簇;其余属性相对独立。由此优选出中值振幅、主频、最小振幅、最大振幅、倾角、方差作为最终的样本特征。

图6 聚类模型效果图Fig.6 Clustering model rendering
3.3 构建模型及参数优化
首先利用K-means SMOTE 算法对数据集进行平衡处理,最终陷落柱和非陷落柱的数据点数量均为4 496 个,从中选取70%的数据作为训练样本,其余的作为测试样本。利用网格搜索与交叉验证的方法对随机森林的超参数(n_estimators 和max_depth)进行寻优,把随机森林模型的得分作为评价指标。最终确定n_estimators=61,max depth=18 时模型的分类效果最好,准确率达到92%。
但在2 698 个测试样本中有259 个实测陷落柱样本,剩下的都是通过K-means SMOTE 算法合成的。因此,为了验证随机森林模型的有效性,仅计算实际259 个测试样本的混淆矩阵准确率达到87%。
3.4 评价模型结果及对比分析
为了对建立的随机森林模型效果进行评价以判定其是否具有有效性和优越性,作为对比;同时使用另外3 种机器学习算法与之比较,3 种机器学习分类算法分别是决策树算法、KNN 算法、BP 神经网络算法。对于二分类问题,为了对分类器的评估更全面,利用召回率(recall)、准确率(Precision)和f1 score 等评估指标来评估模型的分类效果。可以将样本划分为:真正例(True Positive,TP);假正例(False Positive,FP);假负例(False Negative,FN);真负例(True Negative,TN)。然后就可以构建混淆矩阵计算相应的指标,分类结果混淆矩阵见表2。

表2 分类结果混淆矩阵Table 2 Classification results confusion matrix
查准率P,又称准确率(Preciscin):
召回率R,又称查全率(Recall):
准确率和召回率整合在一起的判定标准F1为:
算法对比分析见表3。
由表3 可知:经过K-means SMOTE 处理后的数据集作为输入,随机森林模型预测准确率、召回率、F1-score 相较于其他算法模型均得到了相应的提高。
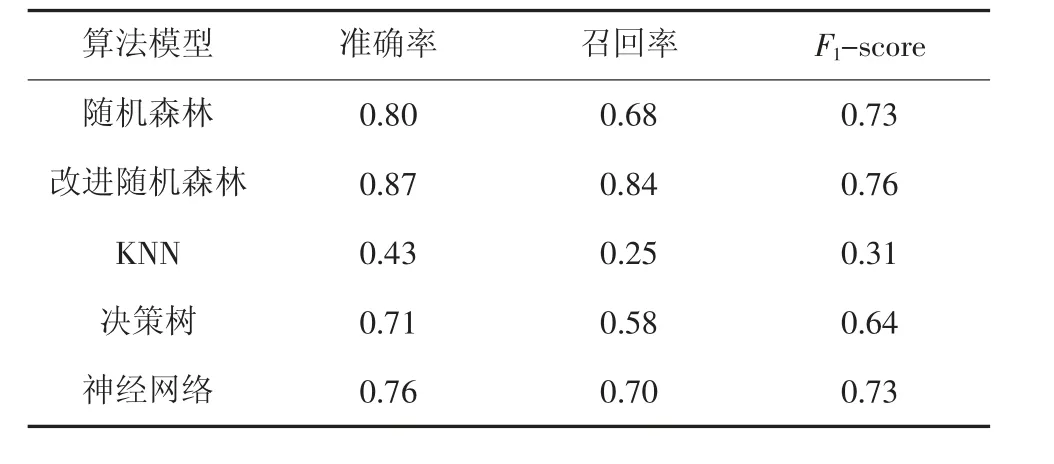
表3 算法对比分析Table 3 Algorithm comparative analysis
将预测为陷落柱的数据点导入软件,并结合陷落柱实际揭露的构造进行对比,模型预测效果图如图7。

图7 模型预测效果图Fig.7 Model prediction rendering
由图7 可知:陷落柱数据点预测较为吻合,进一步证明了模型具有良好的精度,数据点预测较为精确;其中测试集中1 349 个非异常体数据点有1 114个被预测正确;259 个实测陷落柱数据点有225 个被预测正确。
4 结 语
1)综合分析属性与属性之间的相关性和属性与目标值之间的相关性并且优选出相对独立且与目标值相关性高的属性作为训练数据,可以有效降低数据集的维度并提高模型预测精度,提高预测工作的效率。
2)基于随机森林算法的陷落柱识别模型融合了各个不同地震属性识别陷落柱的优势,从多个角度来分析识别陷落柱,相较于单一属性更为精确并且基本与人工解释和实际揭露相吻合,所以模型具有良好的适用性。
3)陷落柱数据点和非地质异常体数据点的数量将直接影响模型识别的准确率。因此通过改善数据集的不平衡程度,可以提高模型识别的准确率。
