基于深度学习的股票趋势预测算法
2023-03-21周润佳
周润佳
(华南师范大学计算机学院,广东 广州 510631)
0 引 言
随着经济的发展,全球金融体系的完善,全球股市的总市值已经越来越大。股市是最大的金融市场之一,对股票未来趋势的预测一直是学者们研究的热点,通过对股票趋势的准确预测可以获取更高的投资收益,具有实际意义[1]。然而股票的运动趋势存在着随机性,使其成为一个极具挑战性的问题。
对股票运动趋势的研究可分为2 类:个股预测和关联预测。个股预测仅依靠该股票本身的信息进行预测,而关联预测不止是使用股票本身的信息,还结合了该股票之外的多个股票信息进行预测,以提高预测的准确度。
在以往的研究中,很多关于股票走势预测的方法都集中在个股预测,期望从独立的历史信息中捕捉到股票的运动模式,进而对未来趋势进行准确的预测。长短期记忆网络(LSTM)是一种经典的时间序列预测算法,文献[2]表明LSTM 的预测效果优于传统的机器学习算法;文献[3]在LSTM 中引入注意力机制将不同时间步关联起来,以解决LSTM 在长时间序列预测方面的局限性;文献[4]通过引入对抗训练,增加数据的扰动,提高算法的鲁棒性,可以得到更好的预测效果。卷积神经网络(CNN)多用于图像识别领域,文献[5]提出一个基于CNN 的算法框架用于预测股票趋势;文献[6]提出一种基于Transformer 的HMG-TF模型,对股票短期趋势进行预测;文献[7]使用强化学习对投资组合进行有效的管理;文献[8]利用历史价格中的极端情况作为预测的依据。此外还有研究是结合一些外部数据,以提高预测的准确度,如文献[9]尝试结合该股票的历史数据和推特文本数据对股票走势进行预测。这些研究都是基于独立的股票信息进行预测,并不依赖股票与股票之间的联系。
股票之间的涨跌是会相互影响的,如当股票同属于同一行业时,往往会呈现出类似的涨跌趋势;除此之外,同属于行业上下游的企业,企业间的经营状况也会相互影响,间接影响股票走势。许多学者通过图卷积的方式对股票间的联系进行研究[10-15],建图时大多以股票为节点,股票之间的关系为边,而图的建立往往依赖于股票之间预定义的相关性[16-17]。文献[18]尝试用企业的行业关系进行建图,通过图卷积神经网络利用其他公司的股票信息,以获得更准确的预测结果。文献[19]提出了HATR 模型,通过扩张因果卷积和注意力机制对股票特征进行提取,并结合行业信息和主题信息进行建图,对股票趋势进行预测。文献[19]中还提出了自适应图,即建图时不依赖预定义信息,图结构是通过模型学习而得到的。文献[20]则不通过建图而是通过多头注意力机制捕捉股票之间的关联信息。
本文的主要工作如下:
1)提出利用CNN 和LSTM 进行特征提取,并结合注意力机制和对抗训练的AACL算法。
2)在2 个公开数据集和一个自己收集的数据集上与基线模型进行实验对比,验证算法的有效性。同时进行消融实验,通过实验对比证明算法各个模块的有效性。
1 模型结构
1.1 总体结构
本文提出的算法(AACL)通过结合CNN[21]和LSTM[22]对股票特征进行提取,并通过多头注意力机制捕捉股票与股票之间潜在的联系。为了提高算法的鲁棒性,获得更好的预测效果,算法引入了对抗训练,对数据进行扰动。
1.2 CNN-LSTM
文献[5]提出了一个基于CNN 的框架进行股票预测,本文算法CNN-LSTM 中的卷积部分使用与其相同的结构,如图1 底部所示,该部分拥有5 层网络。对于一个给定的股票数据x∈RT×d,T为股票数据天数,d为特征维度,第一层的卷积核大小为1×d,输出通道为8;随后叠加2 个卷积层,卷积核大小均为3×1,输出通道为8;在这2 层卷积层后面都接入一个最大池化层,池化核大小为2×1;在每次卷积之后都通过ReLU激活函数进行激活。
LSTM 相比RNN 通过引入额外的门控单元在一定程度上解决了梯度消失的问题,但在长时间序列的预测上依旧是困难的,因此本文的LSTM 模块给出了一个截断机制,只截取最新k天股票信息,捕捉股票最近k天的短期波动信息,k是一个可以调节的超参数。本文提出的CNN-LSTM 结构如图1所示,分别通过CNN 和LSTM 对股票数据进行特征提取,随后将提取结果进行拼接。CNN 模块输入的数据包括T天的数据,经过卷积之后可以得到一个整体的趋势信息,而LSTM 的输入只包含最近k天数据,捕捉的是股票的短期波动信息。

图1 CNN-LSTM结构图
1.3 多头注意力机制
AACL 算法通过注意力机制[23]将股票联系起来,捕捉股票之间潜在的联系,结构图如图2 所示。AACL 算法通过CNN-LSTM 模块可以提取到每个企业股票的特征向量h,堆叠起来构建股票信息上下文矩阵H∈ℝs×u,其中s为同一时刻一同预测的企业数量,u为每个企业股票经过CNN-LSTM 模块提取后的特征长度,然后生成Query(Q)、Key(K)、Value(V)矩阵,如式(1)~式(3)所示。

图2 Attentive CNN-LSTM 结构图
通过Query 和Key 可以计算出每个向量得分,并将向量进行聚合,如式(4)所示,是向量维度的平方根,d=u/m,起调节内积不要过大的作用。多头注意力机制通过式(4)计算m次,每个head 之间参数都不共享,随后将m个head 的计算结果进行拼接,再通过Watt进行线性变换即可得到多头注意力机制的结果,如式(5)所示。
计算得到多头注意力机制的结果后,更新股票的上下文矩阵信息,并通过tanh 激活函数进行激活,如式(6)所示。
在注意力机制之后,加入一个全连接层,并通过sigmoid 激活函数σ(·)计算每个股票的分类置信度,如式(7)所示。
1.4 对抗训练
股票数据具有很大的随机性,训练起来有可能导致模型过拟合,缺乏泛化能力。训练时可以尝试对股票数据添加一些微小的扰动来模拟股票的随机性,以增强算法的鲁棒性和泛化性。对抗训练可以实现此项功能。对抗训练[24]一开始是应用于图片分类领域的,并在该领域获得了成功。
与大多数分类问题的解决方式一样,算法训练的目标是最小化一个损失函数。作为一个分类问题,本文采用的是交叉熵损失函数,数学表达如式(8)所示。
为了防止过拟合,在损失函数中加入了||Θ||2F正则化项,α为超参,此时需要最小化的函数为式(9)所示,n为总样本数。
为了提高算法的鲁棒性,进而得到一个更好的预测效果,AACL 算法加入了对抗训练,加入对抗训练的算法结构如图3 所示,这里一同给出对抗训练的损失函数,如式(10)所示。
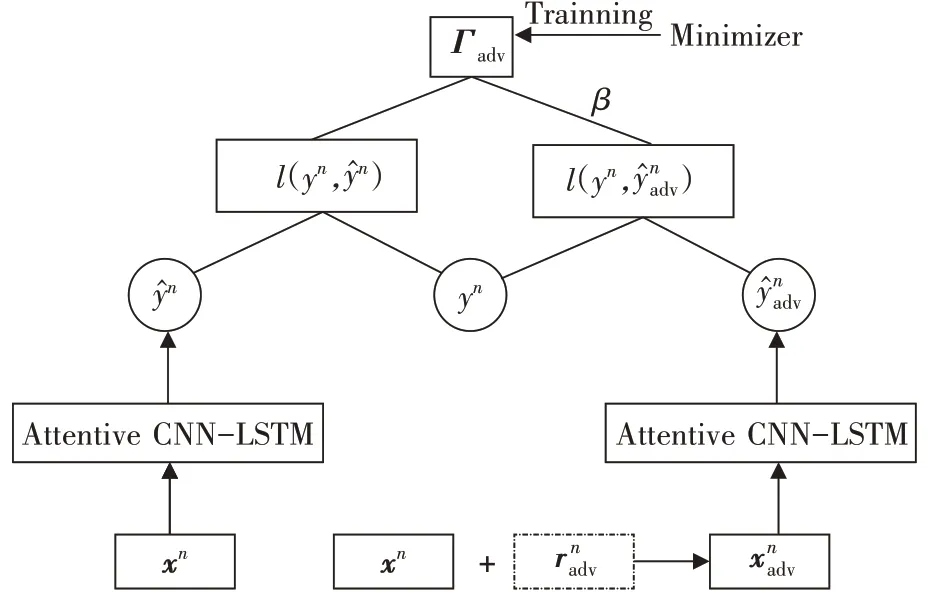
图3 Adversarial Attentive CNN-LSTM 结构图
式(10)中的第二项为对抗损失函数,y^adv为对抗后股票数据的分类置信度,β作为超参数,用以平衡损失函数中原始样本和对抗样本的权重。通过最小化函数Γadv,鼓励模型尽可能地将原始样本和对抗样本正确地分类,使得模型算法尽可能地适应股票数据中的随机性。
在每一次迭代中,对抗样本都由式(11)生成,其中xn为股票的原始数据,rnadv为增加的对抗扰动。
randv 的计算如式(12)、式(13)所示。ran dv 计算的是在L2 范数约束下的损失函数梯度,通过梯度上升的方法对原始数据xn进行扰动。往损失函数最大化的方向进行扰动,尽可能地使模型的预测值发生最大的变化。其中ε 作为一个超参数,用以控制对抗训练的扰动尺度。
2 实验与结果分析
本文是将股票的运动趋势预测作为一个二分类问题进行研究,通过过去30 天的股票数据预测一周之后的股票运动趋势,即t+5 日的收盘价大于t日的收盘价时,为上涨趋势,否则为下跌趋势。对于每个样本的标签通过式(14)进行确定。
2.1 实验环境
本文的实验环境为Linux 系统,内存为16 GB,GPU 为NVIDIA GeForce 1080Ti,CPU 为E5-2680,深度学习框架为Pytorch 1.6,编程语言为Python3.6。
2.2 数据集
实验共使用3 个数据集KDD17、ACL18 和China50。其中KDD17[25]和ACL18[9]为公开数据集。China50 是自己收集的数据集,包括5 个类别:汽车、医药生物、计算机、电气设备和综合,分别取每个类别中市值最大的10个企业,共计50家企业的股票信息。3个数据集中每个数据集都包含以下信息:open(开盘价)、close(收盘价)、high(最高价)、low(最低价)、volume(成交量)。
2.3 数据处理
为了避免数据泄露,将数据集严格按照时间顺序划分为训练集、验证集和测试集,具体的划分情况如表1所示。数据在进行训练和预测前需要进行标准化处理,使用的是z-score 标准化,公式如式(15)所示。由于股票数据时间跨度较长,静态的数据标准化在这种情况下并不合适,使用参考文献[26-27]里面所使用的动态标准化方法,对每个样本进行标准化的时候参考该样本之前10天的均值和标准差进行标准化。

表1 数据集信息
2.4 基线模型
MR:利用均线进行预测的一种方法,股票趋势的预测方向为30日价格均线向最新价格移动的方向。
LSTM[22]:是时间序列预测问题中一种经典的算法。
CNNpred[5]:一种基于CNN的股票趋势预测框架。
Adv_ALSTM[4]:在带有注意力机制的LSTM 算法中引入对抗训练,通过添加扰动来模拟股票的随机性,在股票趋势预测中获得更好的效果。
DTML-MC[20]:利用带注意力机制的LSTM提取股票特征,并通过多头注意力机制捕捉同一市场中不同股票之间潜在的联系,以获取更好的趋势预测效果。
2.5 评价指标
在二分类问题中可以使用ACC(准确率)、F1-score(F1分数)和MCC(马修相关性系数)对模型的预测效果进行评估,如式(16)~式(20)所示,其中混淆矩阵如表2所示。
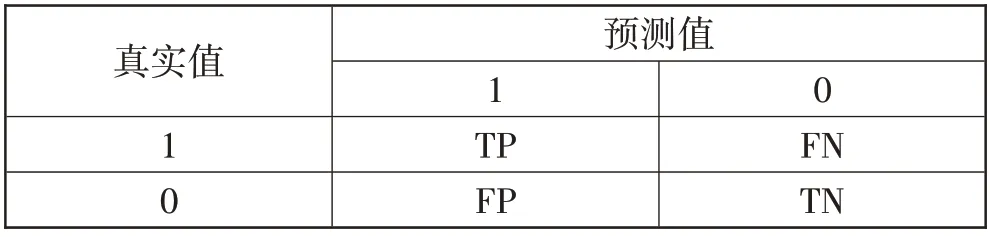
表2 混淆矩阵
2.6 结果及分析
2.6.1 基线模型实验对比
将AACL 算法和基线模型算法分别在KDD17、ACL18 和China50 这3 个数据集上进行实验,实验结果如表3所示。图4~图6为AACL算法与基线模型在指标ACC、F1-score、MCC 上的对比图,由图4~图6 可知AACL算法在3个指标上均取得最优预测效果。在3 个数据集中,AACL 算法相比次优模型在ACC 指标上最少提高了5.24%,最多提高了7.83%;相比次优模型在F1-score 指标上最少提高了4.85%,最多提高了8.95%;相比次优模型在MCC 指标上最少提高了87.99%,最多提高了136.61%。

表3 AACL与基线模型的预测结果

图4 AACL与基线模型的ACC实验对比图

图5 AACL与基线模型的F1-score实验对比图
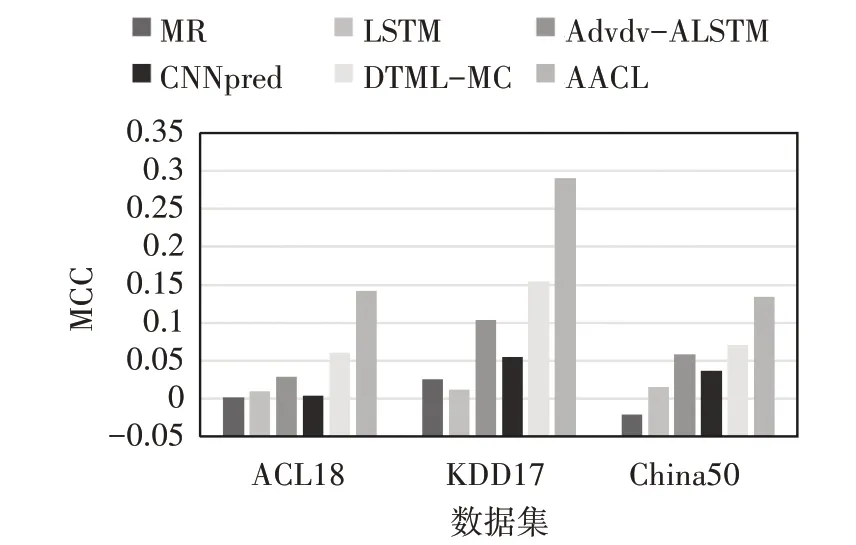
图6 AACL与基线模型的MCC实验对比图
2.6.2 消融实验
AACL 算法利用CNN-LSTM 对特征进行提取,通过多头注意力机制捕捉股票间的联系,并通过对抗训练增加算法的鲁棒性。为了验证这些模块的有效性,在3 个数据集上进行消融实验。其中CL 为CNNLSTM模块,即不包括多头注意力机制和对抗训练,并在最后叠加一层全连接层计算分类置信度;ACL(Attentive CNN-LSTM)为CNN-LSTM 加上多头注意力机制,不包括对抗训练。
实验结果如表4所示,图7~图9为CL、ACL与AACL在指标ACC、F1-score、MCC上的对比图。由图7~图9可知,ACL相比CL可以取得更好的预测效果,在ACC指标上最少提高了4.93%,最多提高了9.39%;在F1指标上最少提高了5.62%,最多提高了16.8%;在MCC指标上最少提高了118.04%,最多提高了390.64%,可知加入注意力机制之后模型算法可以捕捉到股票之间的潜在联系。AACL相比ACL可以取得更好的预测效果,在ACC指标上最少提高了3.05%,最多提高了4.82%;在F1-score指标上最少提高了1.42%,最多提高了3.77%;在MCC指标上最少提高了8.55%,最多提高了31.71%,可知引入对抗训练之后可以提高预测的准确度。

表4 消融实验预测结果
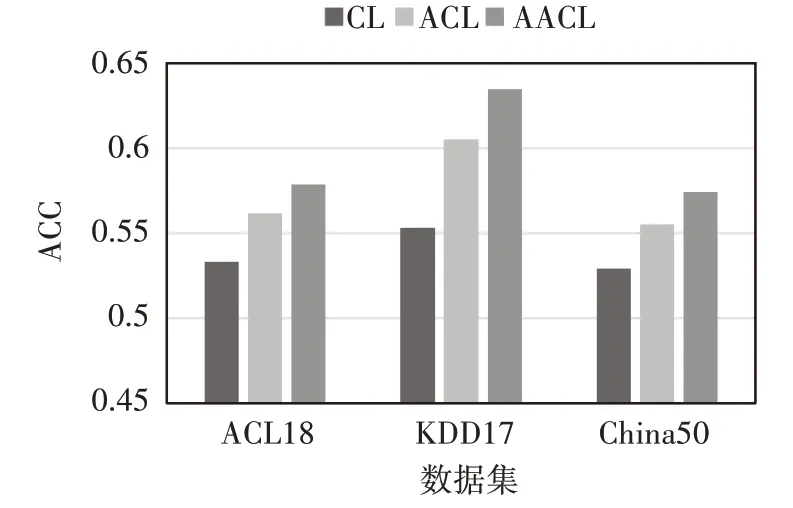
图7 消融实验的ACC实验对比图

图8 消融实验的F1-score实验对比图

图9 消融实验的MCC实验对比图
3 结束语
本文提出了一种用于股票趋势预测的AACL 算法。该算法相比现有的其他预测算法取得了最优的预测效果。本文算法提高了预测的准确度,有助于在投资中获取更高的收益。本文只是利用了股票过往的价格信息对未来趋势进行预测,在后续的研究中可以引入更多的外部市场信息和行业特征,以提高预测的准确度。
