面向用户兴趣模型的数字图书馆个性化推荐技术应用研究
2023-03-20唐静
唐 静
(湖南图书馆,湖南 长沙 410011)
0 引言
随着信息资源日益开放,推荐系统已经成为信息管理需求中的一个热门研究领域。目前,推荐系统广泛适用于电子商务领域,大多数相关研究也都致力于商业服务的应用。一般情况下,推荐系统通过改进算法和揭示用户隐含信息来提高信息推荐的力度。很多大型的电子商务网站都在使用电子商务推荐系统,比如互联网上最大的在线书店Amazon.com,是在EB领域应用推荐系统最典型的案例。
推荐系统也称为个性化推荐系统,它是根据用户的兴趣爱好推荐符合用户兴趣的对象。传统意义上的推荐系统是单向传递信息的,用户只能被动地得到推荐的产品或者服务,而现代意义的推荐系统具有双向选择的功能[1]。并不是所有的在线消费者都对该种商品或服务感兴趣。一般信息过滤系统是为了减少用户搜寻信息资源时所产生的附加成本而产生的。Resnick[2]认为,一般的信息过滤系统,也即推荐系统,可以根据使用者的兴趣、需求和偏好,对其推荐其所需要的信息,让其了解相关产品和服务。此外,相关推荐系统还可以被与电子商务营运架构整合在一起,企业从中能挖掘更多潜在利益。目前,各行各业都可以看到推荐系统被应用,推荐对象也非常广泛,包括了各个方面。
1 用户兴趣模型的建立
1.1 图书借阅行为分析
所谓图书借阅行为分析,是指对数字图书馆中历史图书的借阅数据预先进行处理,从而让得到的图书借阅信息能够符合一定数据格式。在此基础上,相关主体可以对数据采用数据挖掘方法继续分析和挖掘。表1和表2分别表示的是读者对图书借阅信息的历史记录原始数据格式,从中可知相关读者基本信息以及其所借阅书籍的详细信息。表1~2数据还记录了相关书籍被借阅和归还的日期,从中可以查看读者所借书籍是否还在有效借阅期。通过分析读者对不同类型图书的借阅行为,可以统计研究其对哪些书籍更加喜好,哪些图书比较冷漠、很少去关注。另外一个思路,可以通过读者对图书的借阅效率来反映读者对图书的偏好程度。

表1 借书历史记录原始数据格式

表2 还书历史记录原始数据格式
1.2 用户浏览行为分析

图1 基于内容分析与行为分析的用户兴趣模型的构建
用户浏览行为分析是指通过分析读者在网上查阅数据库或者实体在图书馆浏览轨迹,得到一种用户兴趣矩阵,然后应用挖掘算法来实现用户行为的分析与挖掘[3]。研究内容表明,读者在图书馆的很多查阅行为能比较准确地显示用户的喜好,比如读者在查阅某本书时的停留时间、翻看书籍的次数以及向同学做出的推荐,还有借阅频繁度等,而且读者在上网搜寻图书馆馆藏图书时的浏览行为也能反映他们的借阅偏好,比如点击鼠标、标记书籍内容、拖动鼠标以及前进、后退等。不论是实际去图书馆查阅行为还是去校园网上对图书馆网页浏览信息都能够很好地揭示读者的借阅兴趣。
进入图书馆以后,用户多半会前往自己专业或自己研究方向的借阅区,去选择符合自己需要的书籍。读者的借阅图书类型范围可以大致被划定。通过了解读者在哪些书籍停留了多长时间以及对哪些书籍进行过翻阅,可以进一步确定读者对某本书籍的兴趣程度。不仅仅是已经被借阅过的书籍,那些经过读者行为处理的书籍,在下次也可能成为被借阅的对象,即所谓的潜在图书。在向读者推荐一些已借阅书籍的同时,也可以深入分析挖掘这部分潜在图书,从而对潜在图书的借阅概率更为清晰深入了解,为后续借阅提供更多参考依据。
1.3 基于内容分析与行为分析相结合的用户兴趣模型
目前,关于用户兴趣模型的研究不是很深入,比如很多情况下研究人员只局限于对单纯的图书借阅信息进行分析产生用户兴趣模型,或者只是从读者的浏览行为角度来考虑读者兴趣矩阵的挖掘,这些情况下均不能全面、准确地反映用户的借阅兴趣取向[4]。
针对这种问题,本文提出了基于图书借阅信息与读者浏览行为来发现用户兴趣度,建立用户兴趣模型,从而挖掘出用户最为感兴趣的图书信息。基于对图书借阅信息的分析和对读者浏览行为的研究,本文提出了二者结合的用户兴趣模型,如图1所示。
该用户兴趣模型主要是从两个方面入手:一方面是从图书借阅信息考虑,对各种类型读者借阅的图书信息进行处理,这些数据主要通过图书类型、借阅时间、读者类型、借阅状态以及借阅效率等维度来归纳,应用上述聚类方法对其历史借阅内容进行分析,以文本形式表示的数据转变为矩阵的形式;另一方面是对读者在图书馆中浏览图书的行为进行行为分析,读者的浏览行为中主要是从读者在图书馆浏览书籍频数、停留时间、翻阅书籍的时间以及在网站上浏览图书馆数据库的次数、各种操作(如单击、双击、评论)等角度来考虑,将聚类的方法应用于用户对浏览的图书进行行为分析,形成一种用户行为兴趣度[5]。
将两种不同角度考虑下的数据进行整合,形成能够包括两个层次的用户兴趣矩阵。在具体实现上,图书借阅行为数据预处理形成改进前的用户兴趣矩阵可以用一个m×n阶矩阵R(m,n)表示,m行代表m个读者,n列代表n本图书,第i行第j列的元素Rij代表读者i对图书j的借阅效率大小,用户的浏览行为通过用户对书籍浏览的兴趣度I与对书籍的浏览时间T和翻页/拉动滚动条次数J之间寻找相互依存关系,用户浏览行为和图书页面兴趣度之间的回归方程可建立为:I(p)=a×T+b×J+c,其中,a,b,c是与T(P)和J(P)无关的未知参数,它们的估计可采用最小二乘法。这样通过该方程就可以计算用户对图书馆图书浏览的行为兴趣度BI(Behavior Interesting)[6]。
改进后的用户兴趣矩阵是在原有的只是局限于图书借阅行为而衍生出来的数据矩阵基础上,通过引入由用户浏览行为经过行为分析(线性回归分析方法)计算得到的用户浏览行为兴趣度而生成的。改进后的用户兴趣矩阵C可表示为:
聚类就是将数据对象分组成为多个类或簇,在同一簇中的对象之间具有较高的相似度,不同类中的对象差别较大。通过应用K-means聚类算法将用户矩阵中各组数据进行聚类,就得到由用户兴趣分类树表示的用户兴趣模型[7]。
2 用户兴趣模型的应用实例
本文选择的是使用Clementine挖掘工具来具体实现用户兴趣度模型的构建。在Clementine中应用聚类K-means节点和关联规则Apriori节点进行图书信息以及用户行为预测的过程如下:(1)选择数据源,在导入文件中选择要用的数据源library。(2)在选项板中选择字段的选项值,选择其中的数据类型和输入输出方式,进行编辑,读取所有值后将读者类型以及借阅时间、借阅效率设置为输出,如图2所示。单击图2最下方Modeling图标,将其拖动到处理区域中,下一过程和聚类实现操作一样,也可以双击图标就得到了如图2所显示的关联规则挖掘模型。
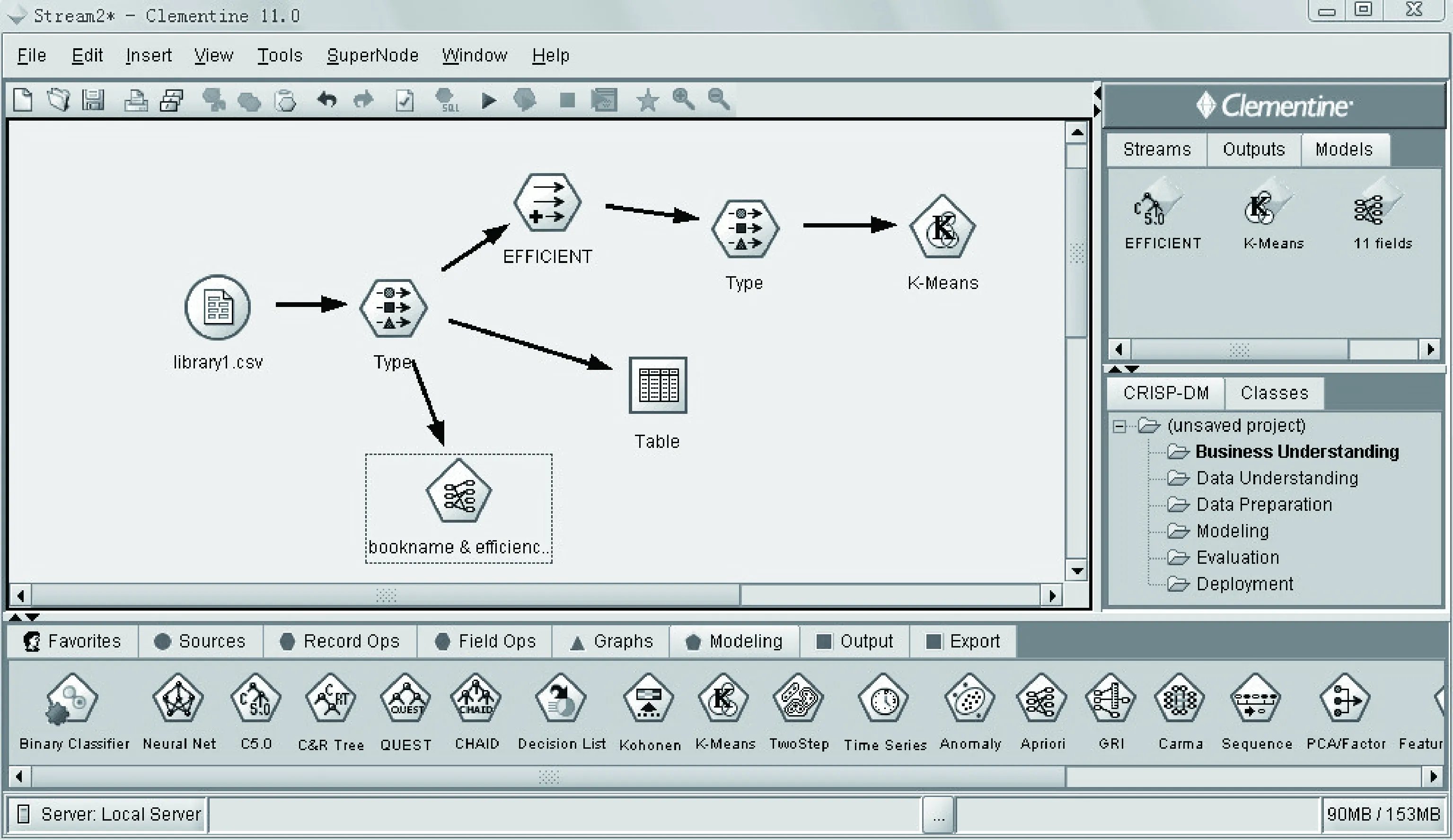
图2 Clementine 11.0 挖掘聚类及关联规则模型过程
数据挖掘模块根据数据处理所得到的数据集,通过应用挖掘算法,进一步挖掘分析相关信息,然后存储挖掘结果。设计过程中,可以实现如下两方面的挖掘。
2.1 图书聚类(K-means算法实现)
根据读者对图书的借阅频率,对图书做聚类分析。图书的借阅频率的确定,参考图书借阅次数以及每次读者借阅该书的时间长短两个因素。在图书借阅数据库,可以对相关图书的借阅次数进行查询,图书被借阅的时间长度,为还书时间减去借出时间(借阅时间都统一以天数为基本单位)。如此,可得图书借阅频率:图书的借阅频率=图书的总借阅时间/图书的总借阅次数。对图书借阅频率进行聚类分析,相关结果既有利于图书馆管理人员更为高效地放置图书,也有利于读者更高效选择自己需要的书籍。
图书聚类的实现过程:设置聚类数目以及对图书的借阅频率进行聚类分析。由于对于借阅次数很少的图书进行聚类实际意义不大,因此聚类的记录个数一般是选择图书借阅次数较多的图书类别。根据K-means算法,对整理后的数据集进行聚类,获得聚类结果。
2.2 图书关联规则发现(Apriori算法实现)
对图书进行关联性挖掘,目的是找出读者借阅图书的潜在规律。实际借阅中,研究者通过关联规则,能更好地发现那些轻易被忽略的潜在规律。图书之间的关联性让图书馆管理人员更好地了解读者的借阅兴趣,将其运用于读者个性化服务中。
图书关联规则发现的实现过程:首先,生成事务集。将包含所有借阅图书信息的读者借阅记录进行逐一扫描,从而得到图书关联规则过程所需要的数据源。由于在实际情况中有可能存在某个读者在一定时间段内重复借阅了同一本书,这样就会造成数据库中事务集的冗余;其次,有些馆藏图书很少有人去借,像这类图书就需要在事务集中剔除,从而提高图书挖掘的效率。具体可以应用图书借阅效率的计算结果,根据关联规则中的最小支持度和最低置信度来划分。最小支持度和最低置信度需要根据实际问题进行设置,总的原则是设置值不宜过大也不宜过小,太大挖掘不到结果,太小得到的数据不准确,误差不能控制在有效范围内。可以通过Apriori算法来进行关联规则的发现,得出的关联规则结果是项集的形式。
3 结语
综上所述,随着数字化阅读的推进,个性化推荐系统的应用越发广泛,其已经涉足于图书馆的个性化服务。本文提出的用户兴趣度模型构建的个性化阅读推进系统能为数字图书馆的建设和服务更新提供助力。在这一系统下,借阅图书或文献的读者都可以互相共享信息,而且每个读者都作为过滤代理人的一分子,帮助目标用户获取馆藏书籍信息,为未来读者提供图书推荐服务。
