基于分簇与改进Q 学习的车联网V2V 复合路由算法
2023-03-16张本宏
毕 翔,黄 晃,张本宏,卫 星,3
(1.合肥工业大学 计算机与信息学院,合肥 230009;2.合肥工业大学 安全关键工业测控技术教育部工程研究中心,合肥 230009;3.合肥工业大学 智能制造技术研究院,合肥 230009)
0 概述
在城市场景中,基于车-车(V2V)通信方式的车辆自组织网络(VANETs)能够快速地传输数据[1],有效提高人们的出行安全和驾乘体验,在智能交通系统中起着支撑性作用[2]。然而,车辆节点的运动随机性和分布不均匀性给建立稳定的通信路由带来了极大的挑战[3]。
专用短程通信(Dedicated Short Range Communication,DSRC)技术的MAC 层协议[4]作为V2V 通信中常用的一种技术,主要由IEEE 1609.4 和IEEE 802.11P 协议构成。车辆节点采用竞争机制获得信道的使用权。在城市车辆高密度场景下,信道访问的冲突问题频繁发生,从而严重影响了VANETs 的整体性能。
鉴于分簇机制能够有效地缓解大规模无线网络的访问冲突问题[5],研究人员提出基于分簇结构的VANETs 路由建立方法[6-8],用于解决移动自组织网络地理协议中的网络规模问题[9]。文献[10]提出一种基于目标感知的路由协议,以提高簇与簇之间数据的传输效率。与现有基于位置选择下一跳簇头的方式相比,该方式考虑簇头和数据传输的方向,有效降低了数据反向传输对链路稳定性和通信延迟的影响。文献[11]提出一种基于车辆属性信息的两级路由算法,在簇头选择阶段,考虑车辆类型、总距离、车辆速度变化、邻居数目等因素对簇结构稳定性的影响。但大多基于分簇的VANETs 路由算法需要路由请求和路由确认数据包建立从源节点到目的节点的多跳路由。车辆的高机动性和行驶轨迹的随机性使得所建立的路由会因链路的断开而变得不可用,需要不断地对路由进行维护甚至重新建立从源车辆到目的车辆的路由,不仅影响了网络的通信性能,也极大增加了通信开销。
上述路由建立方法属于非实时的方法,适用于拓扑结构较稳定的网络,无法满足VANETs 拓扑结构快速变化的网络进行实时数据传输的要求。现有VANETs 中基于Q 学习的算法[12-14]通过车辆与环境不断交互获取新Q值的方式,达到适应周围复杂多变VANETs 环境的目的。但这种Q值更新并不涉及Q 表结构的维护,也不能实时体现环境参数的变化。此外,在数据传输阶段,仅依据最大Q值寻找下一跳的方式,因为车辆的机动性和链路状态不确定性,所以容易造成“盲路”问题[15]。
本文提出基于分簇和改进Q 学习的多跳通信复合路由算法RCRIQ,通过定义一种网关效用性函数,将边缘车辆中通信性能较优且速度相对稳定的节点作为网关节点,以提升通信路由的稳定性。通过动态方法确定学习率和折扣率,实现了对现有Q 学习算法的改进。
1 系统模型
分布式网络模型结构如图1 所示(彩色效果见《计算机工程》官网HTML 版)。

图1 分布式网络模型结构Fig.1 Structure of distributed network model
每一个椭圆形区域是一个完整的簇结构,簇内黄色车辆表示簇头车辆,如图中编号为1、7、12、16、19 的车辆。绿色车辆表示网关车辆,如图中编号为2、5、8、14、17、22 的车辆。蓝色车辆表示簇成员车辆,如簇A 中编号为9、10、11 的车辆。红色车辆表示未定义车辆,如图中编号为23 车辆。在簇内的簇成员之间通信需借助簇头的转发,跨越不同簇之间进行通信,由簇头将数据包传输给本簇的网关车辆,再由网关节点选择邻居簇的簇头车辆或网关节点完成转发。其中,簇头采用独立的信道分别对簇内和簇间数据包进行转发。
2 网关选择
在传统基于分簇的路由算法中,当大多数路由协议在通信范围内没有合适的中继车辆时,数据包采用“存储转发”的方式,造成延迟偏高。如果选择边缘车辆中合适的车辆作为网关车辆,可以进一步拓展单个簇的覆盖范围,降低通信延迟。
根据式(1)计算簇成员与簇头之间欧氏距离的平方,簇头选择边缘车辆中合适的车辆构建候选列表ζ。如果簇成员与簇头之间的距离满足条件D(Vch,Vcm)≥Dth·Dth,则将这个车辆节点加入到ζ中,其中Dth为距离阈值常数。
其中:xch、ych、xcm和ycm分别表示簇头车辆和簇成员车辆的x轴和y轴坐标值。
本文通过网关效用性函数fG构建网关效用性函数列表LGW。网关效用性函数形式化如式(2)所示:
其中:D(Vi,Vj)为车辆距离;R为车辆通信半径;ncm为簇中车辆数目;为车辆Vi的簇成员列表;和分别为车辆Vj的总带宽和已用带宽;LCG为簇头的候选网关列表。
3 基于车辆运动学特征改进的Q 学习算法
标准的Q 学习是一种基于智能体的启发式算法,智能体的学习过程可以用一个三元组[16]表示{S,A,R}。其中,S表示状态空间,A表示动作空间,智能体在相邻状态之间转移的行为被当作一个动作,R表示对于执行一次动作对应的即时奖励。本文提出改进Q 学习的相关定义及其学习过程。
定义1(基本组件)整个VANETs 环境作为智能体的学习环境。状态空间S与传统车联网中运用Q 学习的研究不同,本文没有将环境中的每一辆车当作一个状态,一辆簇头或网关车辆和它的邻居簇头车辆和网关车辆分别作为独立的一个状态,由多个这样的状态构成的集合为状态空间。智能体从一跳邻居中选择下一跳并发生状态转移的过程,可以看作是一个动作,智能体可执行的动作为当前节点的单跳邻居列表,多个这样动作的集合构成动作空间A。在智能体中每一个数据包是一个智能体,它的职责是在每个离散状态下通过执行不同的动作以获得不同的奖励,以寻求到达目的节点的最优策略。
定义2(奖励值)根据定义1,智能体每执行一次动作所获得的奖励被称为即时奖励,用R表示,取值范围为[0,1]。
仅当下一跳车辆是目的车辆的簇头车辆或网关车辆时,获得的奖励值等于1,其余情况的即时奖励均为0。奖励值形式化表示如式(3)所示:
其中:Vj表示当前簇头车辆Vi的邻居簇头或网关车辆;表示目的车辆Vk所在簇的簇头或网关车辆的邻居列表。
定义3(Q 表)Q 表的第一行包含所有可到达目的车辆ID,用di表示,第一列表示单跳邻居的ID,用ni表示。Qi(j,k)表示节点i选择节点j作为到达目的节点k的下一跳节点对应的Q值,Q值范围为0~1。Q 表是一个二维表,其大小由邻居节点数和目的节点数决定,Q值通过节点之间周期性发送的HELLO包来更新。
Q 学习过程主要是更新节点维护的Q 表结构,同时更新Q 表中的状态行为值,Q 学习的形式化如式(4)所示:
3.1 基于链路持续时间的学习率
传统运用在车联网中的Q 学习算法由学习率和折扣率确定。文献[17]在仿真实验中选取多组学习率和折扣率进行实验,但是其作为一个常量,一旦设定就不能更改,不能体现算法的自适应性,难以适应多种VANETs 场景。学习率越高,最新的学习值在更新的Q值中所占的比例越大,学习速度就越快。由于学习率设置得太大也会误导数据包转发,因此智能体在某些情况下可能获得不正确的即时奖励0。为了进一步提高RCRIQ 算法的自适应性,本文将当前节点和下一跳节点之间的链路持续时间与当前节点和邻居节点列表持续时间总和的比值作为学习率,如式(5)所示:
车辆之间的初始距离服从对数正态分布,记作X∈loga N(ui,δi),i=0,1,…,n,且满足0 ≤X<R。假定道路的最大限速为vmax,对于t≥0 的任意时刻,车辆i的瞬时加速度记作ai(t),瞬时速度为vi(t),在T时间段内行驶的距离为Si(T)。对t≥0 的任意时刻,加速度的取值情况可以分为2 种情况:
1)如果ai(0)=0,对于任意t≥0 满足ai(t)=0,表示车辆i在t≥0 时始终做匀速直线运动。
2)如果ai(0)≠0,表示车辆做匀加速运动或匀减速直线运动,如式(6)所示:
根据情况2,只要车辆没有达到最大限速或者停止,则车辆i的加速度仍然是ai(0)。当车辆达到最大限速vmax或者速度减为0 时,加速度会变为0,即车辆达到最大限速vmax后做匀速直线运动,或者车辆速度减为0 之后车辆处于静止状态。
假定车辆i的初始速度为vi(0),车辆i在任意t≥0时刻的速度vi(t)表示如式(7)所示:
其中:u∈[0,t];ai(u)为车辆i的瞬时加速度。
根据式(6)和式(7)得到速度vi(t)的进一步表示有两种情况,一种是如果ai(0)=0,可得vi(t)=vi(0),对于t≥0 任意时刻,车辆做匀速直线运动,另一种是当车辆做匀加速或匀减速直线运动,则:
车辆i在t时间段内行驶的距离如式(9)所示:
假设车辆Vi和Vj之间通信的初始距离为X,车辆Vj在车辆Vi之前。链路断开情景示意图如图2 所示,两辆车都自西往东行驶。
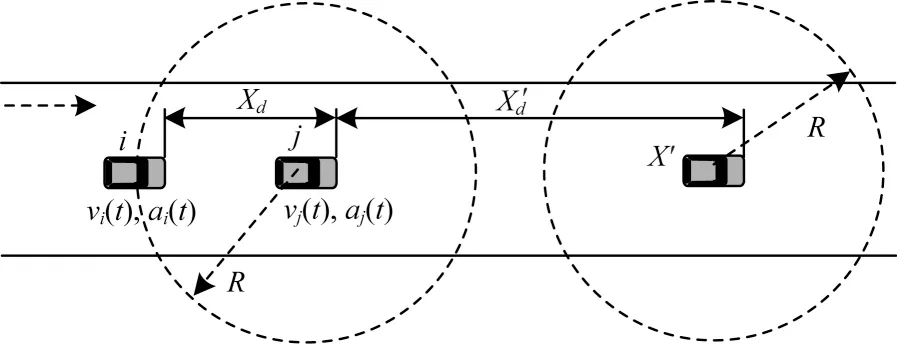
图2 链路断开情景示意图Fig.2 Schematic diagram of link disconnection scenario
两辆车在T时间段内的距离差如式(10)和式(11)所示:
当车辆Vj在车辆Vi之前,两者距离差为R,当车辆Vi在车辆Vj之前,两者距离差为-R。
以上分析的是两辆车同向行驶的情况,当两辆车反向行驶时,车辆Vi和车辆Vj之间的距离差表示如式(12)所示:
两辆车之间的最大链路时间可以分为2 种情况:
3.2 折扣率
车辆在选择下一跳节点时,应避开选择距离当前车辆节点较远的车辆节点,将选择距离较远的邻居车辆作为下一跳中继车辆,增加了链路的不稳定性。因此,车辆i与邻居车辆的距离因子如式(15)所示:
根据式(15)可知,选择距离当前车辆节点i最近的下一跳车辆节点j,的值也会相应增大。本文将的值作为折扣率。根据式(4)可知,折扣率越大表明下一跳节点j的邻居节点j'到目的节点对应的Q值所占的比重越大,进而影响到当前节点i选择节点j作为到达目的节点k的中继节点所获得Q值的比重。
3.3 改进的Q 学习算法
改进的Q 学习算法如式(16)所示:
传统的Q 学习算法选取邻居列表中Q值最大的邻居节点作为下一跳节点。因车辆行驶轨迹的随机性,会造成链路拓扑结构的改变。由于链路通信状况具有不确定性,因此按照最大Q值选择下一跳的方式并不一定是最优的。当前车辆Vi在选择下一跳邻居簇头或网关时,本文引入节点性能评估函数,有效缓解只按照最大Q值的方式选择下一跳节点造成“盲路”问题。实时计算的性能评估函数值还可以起到对选择的下一跳节点进行修正的作用,确保选择的下一跳节点能够及时适应网络环境的改变。本文对式(16)进一步修改,改进后的Q 学习算法如式(17)所示:
其中:Wj(m,k)表示当前车辆Vj选择车辆m作为到达目的车辆Vk对应的下一跳时获得的Q值;m表示车辆Vj的邻居车辆列表中某车辆。Wj(m,k)表示如式(18)所示:
其中:argmaxQj(j′,k)表示按照传统Q 学习算法中最大Q值的方式选出Q 表中到达目的节点对应的邻居节点j';argmaxFj(j″,k)表示从性能评估函数的角度选出邻居车辆j''。,根据式(18)得到的车辆j'和车辆j''完成对Wj(m,k)最终的赋值,如式(19)所示:
其中:j'和j''分别表示按照两种策略选择下一跳节点时对应的节点。如果采用两种方式选出的车辆对应同一辆车,则表明按照最大Q值方式选出的下一跳节点在具有最优可达性的同时,通信性能和运动学方面的参数也是最优的。当采用两种方式选出的节点不是同一车辆时,车辆的移动性以及车辆驾驶操作的不确定性,会造成数据包反向传输以及下一跳车辆与当前车辆之间的链路不稳定。此外,通信中每辆车的通信状况不确定,如果不考虑下一跳待选车辆的通信状况,可能会加剧现有网络的拥塞,导致通信延迟增加。按照最大Q值选中的车辆节点可能因为车辆机动性在下一刻超出当前车辆i的通信范围,存在“盲路”问题。本文将式(18)和式(19)得到的Q值代入到式(17)中,完成本轮Q 学习过程。虽然选中的Q值不是最优的,但是从链路通信质量、数据包转发的方向性,以及两跳车辆之间链路稳定性的角度来确保当前选中的下一跳车辆是最优的。
4 RCRIQ 路由算法
分簇机制能够有效解决大规模网络中数据传输效率较低的问题。Q 学习作为一种自学习算法,通过与周围环境的不断交互来达到适应复杂多变外部环境目的。因此,将Q 学习算法运用到复杂多变的VANETs 环境是合适的。但是,Q 学习采用最大值查找最优路径的方式,容易产生“盲路”问题。在数据包路由阶段,本文给出节点性能评估函数对下一跳车辆的综合性能进行评估,路由过程按照Q学习算法和节点性能评估函数两种策略选择下一跳车辆。
4.1 节点性能评估函数
当车辆Vi选择到达目的车辆Vk的下一跳中继节点Vj时,Vi需要对下一跳车辆Vj的选择方法进行量化评估。从链路通信质量因子、方向因子和移动因子3 个角度衡量车辆Vi和Vj之间链路的综合性能。
4.1.1 链路通信质量因子
链路通信质量因子从链路通信质量的角度量化下一跳车辆对网络性能的影响。车辆定期发送HELLO 消息的时间间隔为τ,邻居车辆通过计算在一段时间内接收到的HELLO 数据包数目和发送的数据包数目之间的比值,衡量相邻两跳车辆之间的链路质量。将5τ内每辆车HELLO 数据包接收率的平均值作为链路通信质量因子,并根据发送数据包数目分别进行讨论,如式(20)所示:
当收到邻居车辆发送的HELLO 报文时,车辆从中提取邻居车辆的qlink值。qlink值越大,表明链路通信质量越好,选择qlink值较大的邻居车辆,可以提高链路的稳定性,提高传输效率。
4.1.2 方向因子
方向因子可量化评估数据包朝向性对链路通信效率的影响。在实际数据包转发的过程中,数据包可能向后转发,造成数据包离目的车辆越来越远,背离了数据包朝向目的车辆所在方向转发的初衷。本文通过定义当前车辆Vi、下一跳车辆Vj和目的车辆Vk三者之间角度的关系来确保每一次数据包转发的过程都朝向目的方向,确保数据包离目的节点越来越近,使得数据包能尽快地转发给目的车辆,形式化表示如式(21)所示:

图3 方向因子计算过程示意图Fig.3 Schematic diagram of direction factor calculation process
4.1.3 移动因子
移动因子可以量化下一跳车辆移动性对路由链路稳定性的影响。车辆的移动性会对相邻两辆车之间的链路产生影响,选择稳定性更好的链路,更有利于数据包的传输。本文以当前车辆Vi和Vj为例,移动因子形式化表示如式(22)~式(27)所示:
其中:为预先给定的移动性阈值,当车辆Vi和车辆Vj之间的移动性小于该阈值时,给移动因子赋值为1,表示从移动性角度选择对应的下一跳邻居车辆作为中继车辆,否则赋值为-1。
根据链路通信质量因子、方向因子、移动因子定义节点性能评估函数,用于评估下一跳车辆Vj的综合性能。节点性能评估函数如式(28)所示:
其中:Fi(j,k)表示当前车辆节点i选择邻居节点j作为到达目的车辆节点k的下一跳节点时,对应的节点性能评估函数值。当取值都为1 时,的取值为1,对最终的函数值形成正反馈,否则方向因子或移动因子中只要一个取值为-1,最终Fi(j,k)值为0,将最终求得F值最大的节点作为候选中继节点。
4.2 路由建立过程
当源节点发送数据包时,由所在簇的簇头代为转发。簇头车辆首先检查Q 表以查看是否有到目的节点的下一跳车辆,若存在,则启动数据传输过程。路由转发策略流程如图4 所示。
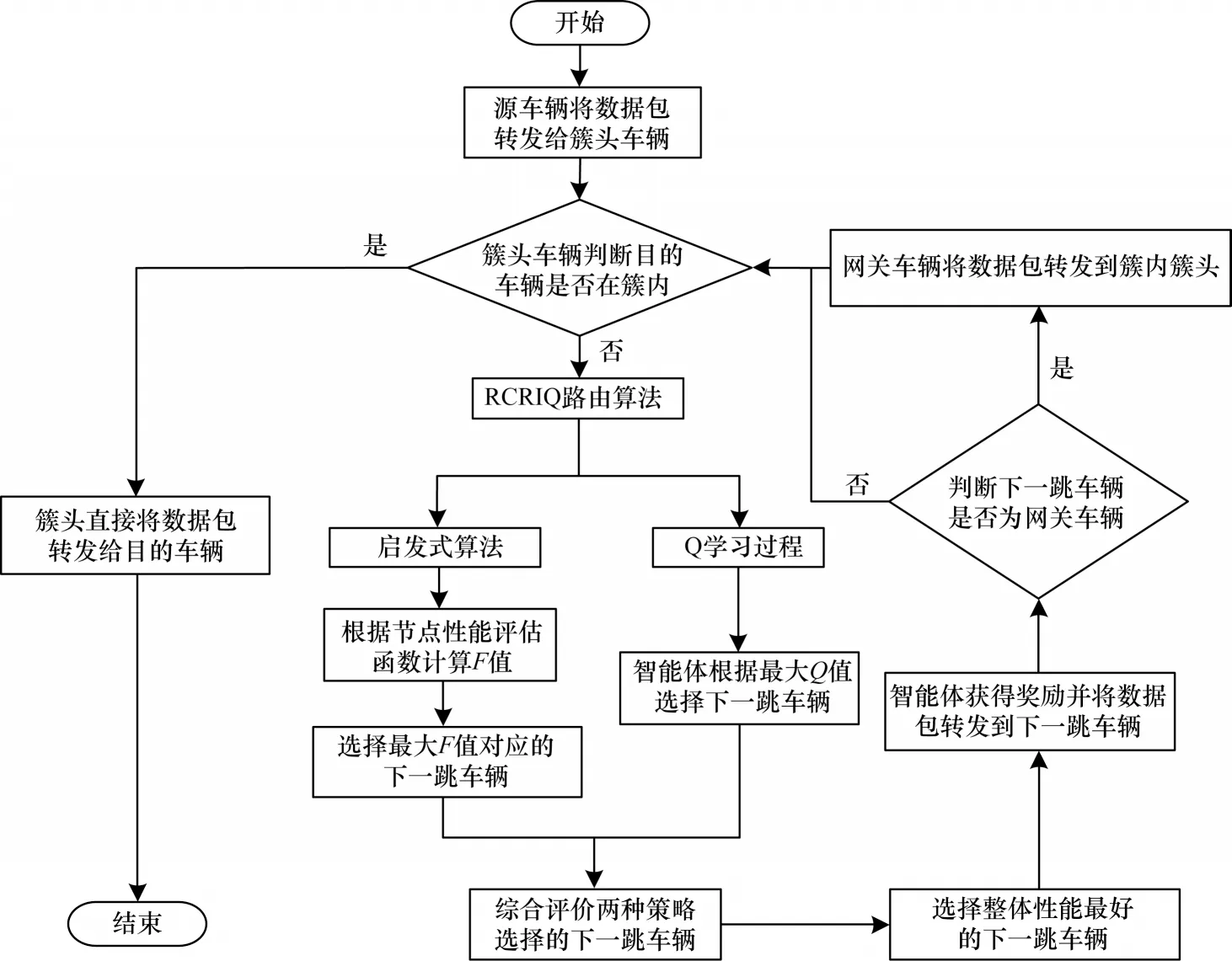
图4 路由转发策略流程Fig.4 Procedure of routing forwarding strategy
在启动路由发现过程中,簇头车辆通过组播的形式向所有邻居车辆发送RREQ 数据包并启动路径请求定时器,其中RREQ 数据包记录了它在路由过程中经过的所有节点ID。与大多数研究采取只有当RREQ 数据包到达目的节点时才返回RREP 消息的策略不同,本文采取的策略是当中间某个节点的Q 表中有到达目的车辆对应的Q值存在时,由该节点根据RREQ 数据包中的路径生成一个RREP 数据包,并以单播的形式返回给上一跳节点,其中RREP 数据包包含到达目的节点对应的Q值,以达到提前返回的目的,从而缩短路由整体的延迟。当上一跳节点收到返回的RREP 后,从中提取对应的Q值,并根据Q值计算公式更新Q 表结构和计算新的Q值,重复上述过程,直至数据包到达源簇头车辆,源簇头收到返回的RREP 消息后取消请求定时器。此外,本文将RREQ 数据包最大请求次数设为3 次,若在3 次定时周期内源簇头都没有收到返回的RREP 数据包,则通知源节点目的节点不可达。
路由转发策略的伪代码如下:
车辆V4选择邻居车辆V7作为到达目的车辆Vd的中继车辆对应的Q值为0.6,选择邻居车辆V6作为到达目的车辆Vd的中继车辆对应的Q值为0.52,其中学习率取值为0.8,折扣率取值为0.7。数据包传输路径示意图如图5 所示。

图5 数据包传输路径示意图Fig.5 Schematic diagram of data packet transmission paths
如果按照最大Q值的方式选择下一跳车辆,则最终的数据包传输路径为Vs→V2→V4→V6→V9→V11→Vd或Vs→V1→V4→V6→V9→V11→Vd。因为节点性能评估函数综合考虑了下一跳车辆的通信性能,所以在选择下一跳车辆时会根据实际链路质量、数据包传输方向和两辆车之间的移动性进行综合分析。例如,当车辆V1选择下一跳车辆时,按照最大Q值的方式应选择网关车辆节点V4。然而,因为V4车辆作为另一个簇的网关车辆,与当前簇的相对速度和簇内的网关车辆V3相比,V3车辆更稳定,即按照节点性能评估函数值最大的方式选出的下一跳车辆是V3,综合考虑选择V3作为下一跳车辆。两种策略综合评估的机制在确保Q值最大和最优可达性的同时,使得其他运动特征和通信方面的参数也是最优的,实现数据高效传输的目的。
4.3 路由维护阶段
当数据包在路由链路中丢失时,传统路由协议会从源车辆重新将数据包发送到目标车辆[18-19],或者切换到第2 条备用路由[20],继续发送数据包,这2 种方式具有较高的路由开销。本文采用的策略如下:若车辆与下一跳车辆之间的链路断连,则会通过Q 表结构的维护,删除Q 表中失效车辆的记录,即删除邻居车辆对应的行。如果Q 表中到达目的节点的Q值在指定的时间内没有更新,则视为目的节点已失效,将删除Q 表中该目的车辆对应的列数据。因为Q 表的结构和Q值,体现了网络的状况。因此,通过Q值的不断迭代更新和Q 表结构的不断维护,使得RCRIQ 能够实时适应网络环境的改变。
5 仿真结果
本文采用GAPC[21]中的分簇算法构建簇结构,在此基础上,RCRIQ 分别与GPSR、RSAR、TCRA 算法从路由跳数、链路持续时间、吞吐量、丢包率、通信延迟等角度进行仿真实验。为了确保仿真的真实性和有效性,本文采用德国科隆[22]和国内某市[23]移动数据集作为车辆移动数据集,根据节点数的不同,分别进行40、60、80、100、120、140、160、180、200 个车辆节点的仿真实验。本文实验的仿真参数设置如表1 所示。

表1 本文实验的仿真参数设置Table 1 Simulation parameters settings of experiment in this paper
5.1 路由跳数对比
路由跳数表示当数据包成功到达目的车辆时经过的中继节点数目,用于评估路由的稳定性。图6所示为在不同数据集上4 种路由算法的平均路由跳数与车辆数之间的关系。随着节点数的增多,2 个数据集中4 种路由算法的平均路由跳数均呈现下降的趋势。在德国科隆数据集中,当节点数从120 增加到140 时,RCRIQ 算法路由跳数的下降速度比RSAR快。RCRIQ 基于分簇机制,有利于隔离广播冲突,以提高传输效率并减少传输路由跳数。尽管RCRIQ和RSAR 均基于Q 学习的原理,但是在路由构建阶段,RCRIQ 由簇头车辆选取边缘车辆列表中通信性能和稳定性均较优的车辆作为网关车辆,极大拓展簇结构的通信范围且减少路由整体通信跳数。在数据传输阶段,RCRIQ 采用复合路由,综合评估下一跳车辆的综合性能,相比RSAR 只按照最大Q值选择下一跳车辆的方式,更能适应复杂多变的VANETs环境。GPSR 路由跳数较少的原因在于其采用贪婪转发的策略,当数据包成功转发到目的节点时,能保证路由跳数最少。TCRA 主要基于分簇的路由算法,通过多个簇头构建主干路由,可以极大提高通信效率,但在路由阶段,没有对邻居簇头进行量化评估,造成选择的簇头虽然距离最近,但通信性能并没有达到最优节点的通信性能。

图6 不同路由算法的路由跳数对比Fig.6 Routing hops comparison among different routing algorithms
5.2 路由生存时间对比
路由生存时间表示从源节点到目的节点之间通信链路的存活时间。本文根据路由生存时间的变化情况来衡量通信链路的稳定性。在不同车辆节点下,各路由算法的路由生存时间对比如图7 所示。随着车辆节点数目的增多,在2 个数据集上4 种算法的路由生存时间均增加,这是因为随着节点数的增加,邻居列表中选择通信状况且稳定性较优的下一跳节点的可能性增加,以确保4 种路由算法的生存时间均增加。在2 个不同的移动数据集下,RCRIQ算法的路由生存时间分别比RSAR、GPSR 和TCRA平均提高13.49%、23.41%和16.33%。路由生存时间的提升是因为RCRIQ 的节点性能评估函数充分考虑了链路通信质量、数据包传输方向、车辆之间移动性对通信链路的影响,而RSAR 仅考虑了速度变化对通信链路稳定性的影响。GPSR 的路由生存时间最低是因为它采用贪婪机制,没有考虑链路稳定性和网络负载情况对路由生存时间的影响。TCRA 路由生存时间较短的原因是基于AODV 协议,需要不断对路由进行维护,不能很好适应VANETs 环境。
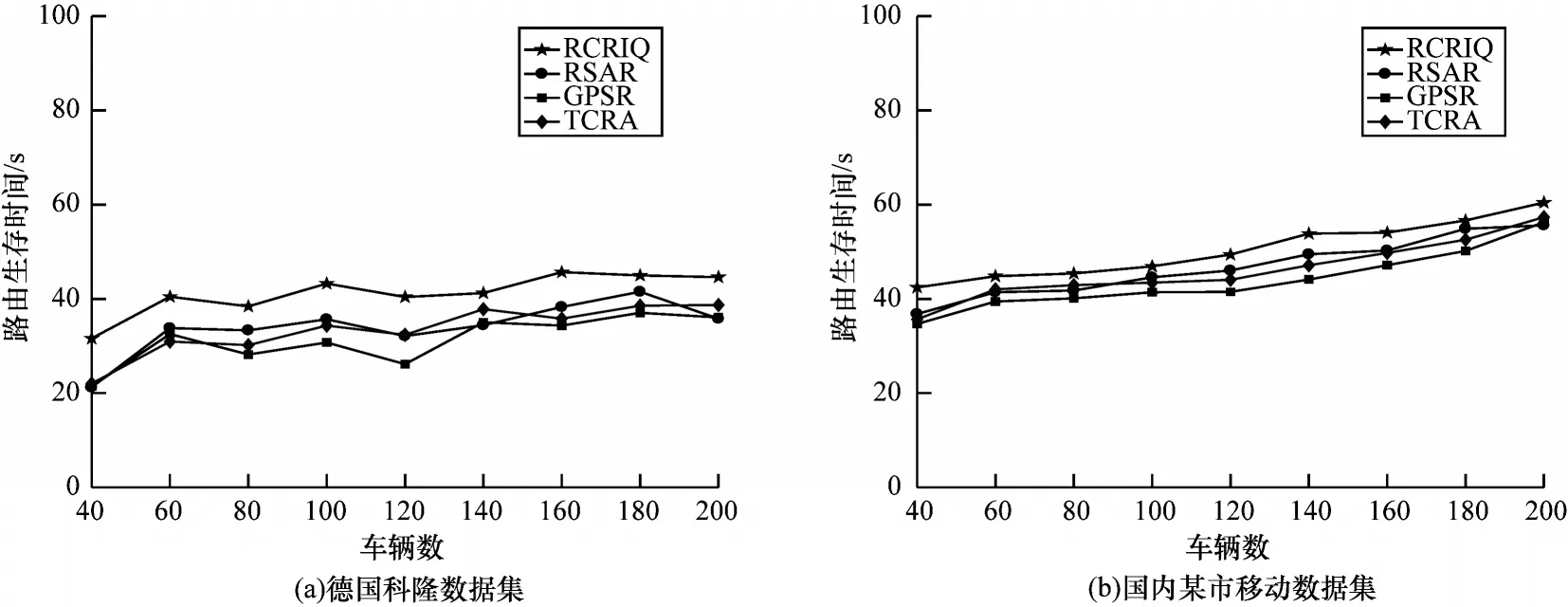
图7 不同路由算法的路由生存时间对比Fig.7 Routing lifetime comparison among different routing algorithms
5.3 吞吐量对比
吞吐量表示目的车辆在一定时间内接收有效数据包的总字节数与时间间隔的比值[24]。在不同车辆节点下,不同路由算法的吞吐量对比如图8 所示。随着车辆节点规模的不断增大,在2 个数据集中4 种路由算法的吞吐量均增大。RCRIQ 的平均吞吐量分别比RSAR、GPSR 和TCRA 提高28.76%、52.97%、15.96%。RCRIQ充分考虑影响链路稳定性的因素,同时还将相邻车辆的链路持续时间和距离定量化表示成Q 学习中的学习率和折扣率。链路持续时间长和距离近的邻居节点能够获得更大的Q值,便于后续数据传输阶段按照最大Q值策略查找下一跳车辆。相反,在RSAR 数据传输阶段,只按照最大Q值查找下一跳节点,因车辆具有移动性,容易产生“盲路”问题,最终影响数据包的传输。GPSR 的吞吐量最低是因为其没有重传机制,当采用贪婪机制未能成功选出下一跳节点时,会直接丢弃该数据包,造成有效传输到目的节点的数据包偏少。TCRA 吞吐量较高是因为分簇可以对网络频谱进行高效管理,减少网络拥塞的出现,极大提高单位时间内的数据传输率。
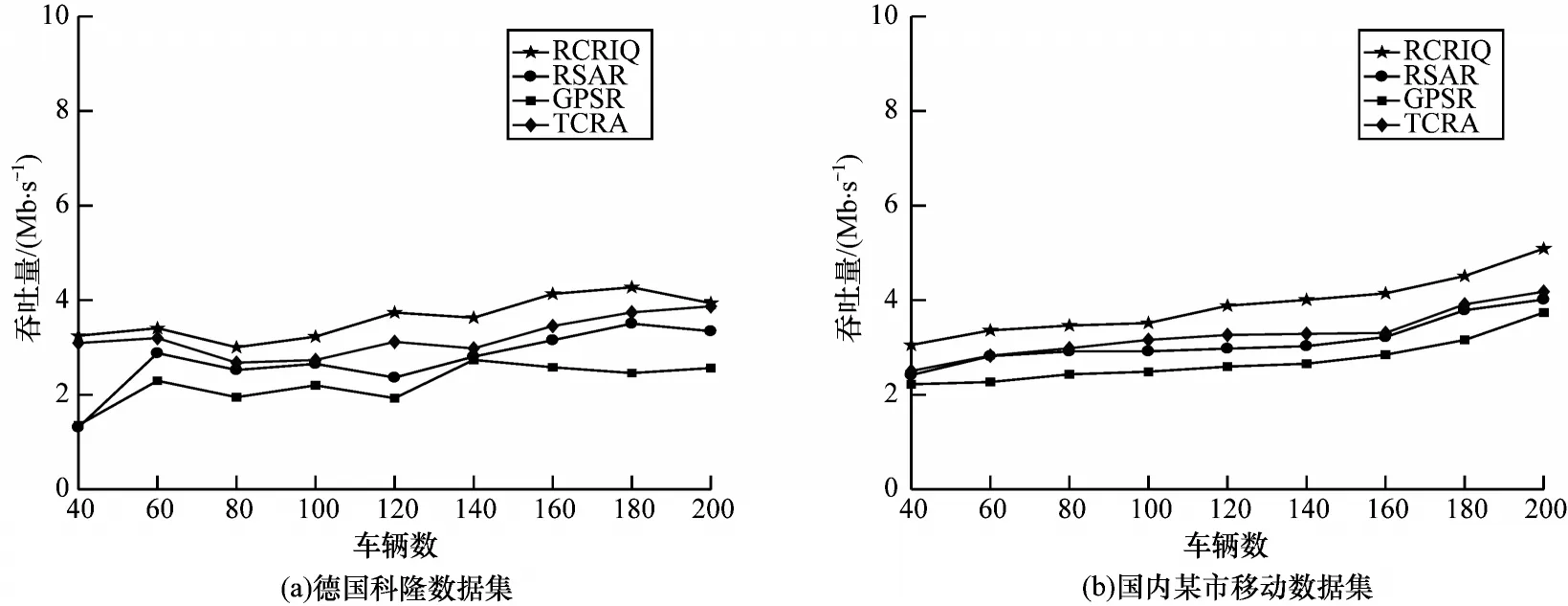
图8 不同路由算法的吞吐量对比Fig.8 Throughput comparison among different routing algorithms
5.4 丢包率对比
丢包率用来衡量源节点发送的数据包经过路由转发之后丢失数据包的比例[25]。图9 所示为不同数据集中丢包率与车辆节点数目之间的关系。随着车辆节点数目增加,4 种算法的丢包率均呈先下降后趋于平稳的状态。RCRIQ 的平均丢包率分别 比RSAR、GPSR 和TCRA 分别减少56.78%、94.02% 和17.83%。RCRIQ 平均丢包率位于7.1%~10.6%之间,随着节点数目的变化,丢包率整体变化不大。造成这种现象的原因是RCRIQ 基于Q 学习,通过Q值更新达到适应动态变化的VANETs 环境。与RSAR 不同,RCRIQ 通过簇头或网关车辆实时维护Q 表结构,数据包通过Q 表结构的变化,可以实时感知网络的变化。RSAR 也基于Q 学习理论,在构建路由时,对链路稳定性进行了评估,因此丢包率与RCRIQ 整体接近。GPSR 采用贪婪转发和边缘转发的思想选择下一跳节点,能够适应高密度的场景。TCRA 依赖于簇头,因为簇头在选择完成后丢包率变化不大,所以最终的丢包率变化也不大。

图9 不同路由算法的丢包率对比Fig.9 Packet loss rates comparison among different routing algorithms
5.5 时延对比
时延表示数据包从源车辆出发,经过一系列中继节点路由传输,最终成功到达目的车辆时所花费的时间。本文通过时延可以衡量路由算法的通信性能。不同算法的时延对比如图10 所示。随着车辆节点数目的增加,在德国科隆数据集中,节点数为120~160,4 种算法的时延先短暂上升后下降,其原因为随着节点数目增多,短时间内会出现大量冲突的数据包,造成大量数据包丢失以至于重传。随着路由算法对网络环境的适应,时延呈现下降的趋势。RCRIQ 的平均时延比RSAR 降低14.52%,这是因为随着车辆节点数目增加,RCRIQ 中簇头节点和网关节点数目也增加了,找到综合性能最优的下一跳节点的可能性更大,因此网络整体延迟更低。GPSR 采用贪婪策略对数据包进行传输,当通过贪婪和边缘转发方式都无法到达目的地时,直接丢弃该数据包,以降低传输延迟。此外,图9 中GPSR 算法的数据丢包率最大,也间接说明其延迟最低。TCRA 延时最高的原因是分簇的形成需要花费一定的时间,不能根据VANETs 环境的变化及时做出调整,且TCRA 基于AODV 协议,需要不断对建立的路由进行维护,而在VANETs中拓扑断连的现象非常普遍。
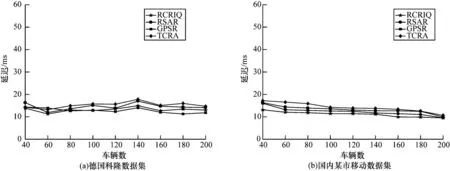
图10 不同路由算法的时延对比Fig.10 Time delay comparison among different routing algorithms
6 结束语
传统VANETs 路由算法存在路由维护成本和通信延迟较高且吞吐量较低的问题。为此,本文提出基于分簇和改进Q 学习的复合路由算法,采用节点性能评估函数和最大Q值两种方式对待选的下一跳节点进行综合评估。在德国科隆数据集和国内某市移动数据集上的仿真实验结果表明,相比RSAR、GPSR 和TCRA 路由算法,RCRIQ 能提高数据包 传输率并延长链路存活时间,且降低传输延迟和丢包率,有效缓解由VANETs 网路拓扑频繁变化带来的问题。由于LTE 具有高带宽和覆盖范围大的特点,因此下一步将结合LTE 与专用短程通信构建混合分簇网络模型,以提高大数据包的传输效率。
