基于YOLOv5的小麦种子发芽检测方法研究
2023-03-16白卫卫赵雪妮
白卫卫,赵雪妮,罗 斌,赵 薇,黄 硕,张 晗,*
(1.陕西科技大学,陕西 西安 710016; 2.北京市农林科学院 智能装备技术研究中心,北京 100097; 3.北京市农林科学院 信息技术研究中心,北京 100097)
小麦是现今世界上最重要的粮食作物之一,在我国其重要性仅次于水稻[1]。小麦的产量、品质与种子的质量息息相关[2]。种子的发芽率是衡量种子质量的最重要指标之一[3],高发芽率的小麦种子在田间发芽快、抵抗逆境生长的能力强;低发芽率的小麦种子在田间发芽较慢、出苗不规整,很容易受到生长环境的影响而造成农产品减产。传统的发芽检测是通过人眼观测,对萌发7 d的种子发芽情况进行统计判断[4],检验人员需要拥有丰富的经验,重复性的发芽率检测非常繁琐、费时、费力,而且容易引入主观误差,造成不同人员间统计结果不一致,可重复性较差。因此,需要一种客观的、可重复的、快速的并且经济可靠的测定方法。
近年来,机器视觉技术得到了飞速发展,且在农业领域得到广泛应用[5-7],许多研究人员将机器视觉应用到种子的发芽检测中。李振等[8]基于机器视觉图像处理技术开发了辣椒种子活力指数检测系统,活力指数检测精确率高达92%以上。张帆等[9]设计了一套基于机器学习的在线视觉检测系统用于检测穴盘苗的发芽率,基于机器学习方法制作训练样本,依据可信度来判断发芽情况,此方法具有较高的检测精度。王纪章等[10]提出一种基于Kinect相机的穴盘苗生长过程无损监测方法,对黄瓜穴盘苗的发芽率、株高、叶面积等参数进行了无损监测,其发芽率误差不大于1.567%。这些方法均采用机器视觉技术对发芽特征进行提取,通过形态学的检测实现种子发芽判别,然而不同作物的种子发芽特征不同,导致这些方法的应用均存在局限性。
随着科学技术的发展,深度学习逐渐出现在大众的视野中,深度学习技术已成为特征检测的有效方法,并且在目标检测领域取得显著突破,被大量应用于农业检测领域[11-15]中。YOLO系列模型作为一种单阶段卷积神经网络,因其具有检测实时性、高精度等优势在目标识别和定位检测中得到广泛应用[16-20]。权龙哲等[21]采用YOLOv4卷积神经网络模型对田间杂草和玉米秧苗进行目标识别,快速识别定位田间杂草,进行定向除草。赵德安等[22]采用YOLOv3网络模型对复杂环境下的苹果进行定位识别,在效率与精确率兼顾的情况下实现了复杂环境下苹果的检测。张晴晴等[23]建立了YOLOv3优化网络模型对复杂场景下茶树嫩芽进行识别,其模型的平均精度值(mAP)高达91%。
虽然深度学习在农业中应用广泛,但是在种子发芽检测方面的研究很少,深度学习技术在检测过程中无需对图像进行特征提取和形态学处理,极大降低了种子判别的建模过程。通过深度学习进行种子发芽的快速识别和定位,可为种子发芽检测提供一种新的解决方案。本研究以小麦为研究对象,通过机器视觉技术结合YOLOv5深度学习网络模型建立小麦种子发芽判别模型,实现小麦种子的发芽自动检测。结合小麦种子7 d标准发芽试验,设计一套基于YOLOv5的种子发芽检测改进判别方法(detection based on YOLOv5,DB-YOLOv5),通过7 d发芽试验图像组合分析,优化种子发芽判别,实现了对小麦种子发芽率、发芽势、发芽指数、平均发芽天数的快速检测。
1 材料与方法
1.1 发芽试验与图像采集
发芽试验按照GB/T3543.4—1995规定的小麦发芽试验方法进行。试验小麦种子品种为济麦22,选取2 000粒小麦种子作为试验样本。使用19 cm×13 cm×12 cm透明发芽盒进行发芽,每盒按照4×5摆放20粒种子,共计100盒。试验之前使用1%次氯酸钠溶液对小麦种子消毒10 min,然后使用蒸馏水冲洗3次。发芽盒用75% 乙醇消毒,每个发芽盒铺2层发芽纸,加入等量蒸馏水。发芽箱设置温度为20 ℃,采用12 h间隔光照,进行7 d发芽试验。
图像采集装置由相机、暗箱、遮光布、垫板和光源组成。采集装置示意图如图1-a所示。每次采集图像发芽盒位置与镜头的位置相对固定,以便于观察每粒小麦生长变化过程。放入种子立刻采集第1张图像为初始图像(记为第0天),每隔24 h采集1次,连续采集7 d,每盒共8张图像,如图1-b所示。100盒小麦种子共采集到800张图像。

a,图像采集装置示意图;1,采集箱;2,工业相机;3,条形光源;4,相机支架;5,发芽盒;6,载物台;7,条形光源;8,小麦种子;9,传输图像;10,计算机。b,采集图像。a, Image acquisition device structure; 1, Collection box; 2, Industrial Camera; 3, Strip light; 4, Camera mounts; 5, Germination box; 6, Loading table; 7, Strip light; 8, Wheat seeds; 9, Transferred images; 10, Computer. b, Acquired images.图1 图像采集装置示意图与采集图像Fig.1 Schematic diagram of image acquisition device and image acquisition
1.2 构建数据集
1.2.1 数据标注
建模前使用labelImg软件对采集图像中的小麦种子进行标注,如图2所示,图像标注使用矩形框,标注过程中尽量减少多余的背景进入矩形框,小麦种子位于矩形框正中间,矩形框的位置由其两个对角的坐标确定。每幅图像里根据小麦种子的位置标注20个不同的矩形框,将所有图像标注完成后产生16 000个矩形框。本研究将种子类别分为2类,一类是没有发芽的种子,标注为N;另一类是已经发芽的种子,标注为Y。经统计,此次试验中标注的N有5 910粒,标注的Y有10 090粒。发芽判别标准采用GB/T3543.4—1995的规定:当小麦种子胚根与种子的长度相同,胚芽长为种子长度的一半时,则判定为种子发芽。种子类别标注工作是有经验的人通过肉眼判别种子胚根长度和胚芽长度对种子类别进行标注。种子类别标准如图2所示。

用彩色加深胚根与胚芽是为了直观地说明发芽判别标准,在试验中并不对胚根长度和胚芽长度进行标注。The radicle and germ were depicted in color in order for the germination discrimination criteria to be visually illustrated. The radicle length and germ length were not labeled in the experiment.图2 labelImg标注与发芽判定Fig.2 labelImg mark and germination determination
1.2.2 划分数据集
数据集包括100盒小麦种子原始采集图像和种子发芽过程连续7 d采集的图像,共计800张,每张图像根据发芽盒的编号和发芽天数命名。通过labelImg软件对每张图像中的种子进行标注,产生了16 000个种子标注框。数据集按照分层采样进行划分,划分比例为训练集∶验证集∶测试集=7∶2∶1,分别为70盒、20盒、10盒,对应到采集的图像数量分别为560张、160张、80张,对应的种子数量分别为11 200粒、3 200粒、1 600粒。
1.3 检测算法
1.3.1 YOLOv5模型
YOLO算法是将目标检测任务重新定义为一个单一的回归预测问题,直接从图像像素中获取边界框坐标和类别概率。其采用组合的卷积神经网络提取图像多尺度的特征,然后经过全连接网络层进行特征融合,并将图像特征传递到预测层,最后处理网络预测结果并对图像特征进行预测,生成目标边界框和预测类别概率[24]。
YOLOv5的输入端采用Mosaic数据增强、自适应锚框计算和自适应图片缩放方式对输入图像进行处理。Backbone端包含Focus结构和CSPNet。Focus结构包含4次切片操作和1次32个卷积核的卷积操作,将原始608×608×3的图像变成304×304×32的特征图。CSPNet仿照Densenet[25]密集跨层跳层连接的思想,进行局部跨层融合,利用不同层的特征信息来获得更为丰富的特征图。Neck端使用FPN加PAN结构,属于网络的融合部分,将特征混合组合,传递到Output,FPN结构自顶向下传递特征,可以改善底层特征的传播,PAN结构自底向上传递特征,两者结合操作,增强了网络特征的融合能力。输出端采用GIoU Loss[26]作为Bounding box的损失函数,它能够解决边界框不重合的问题,通过非极大值抑制NMS来筛选目标框。YOLOv5检验结果包括标注框的中心坐标(x,y)、标注框的长度a、宽度b、置信度p、判别结果。网络结构图如图3所示。

图3 YOLOv5网络结构图Fig.3 YOLOv5 network model
YOLOv5的官方代码中给出了4种不同的网络模型,分别是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,这4种网络模型在大小和精度上依次递增。YOLOv5s网络是4种网络模型中深度最小、特征图的宽度最小的网络,后面3种网络的深度和宽度都是在此基础上不断增加。由于网络深度和宽度不同,所以它们可应用于不同的场景。针对以上YOLOv5在目标检测中的特征和优势,本研究提出基于YOLOv5对小麦种子发芽进行检测判别,验证利用YOLOv5对小麦种子发芽检测判别的可行性。
1.3.2 DB-YOLOv5检测方法
在研究过程中,保持相机镜头与种子的距离始终不变,在第4天之后种子的胚芽开始长出茎、叶(如图1-b);在镜头的图像采集视野中苗的茎、叶之间会产生相互遮挡,采集的图像无法捕捉到种子导致YOLOv5网络模型在测试集进行检测时出现漏识别的问题(如图4-7a橙色框标记种子)。在种子处于发芽判别临界点之间时,YOLOv5网络模型在检测时会给出2种判别结果并注明其置信度,故而会将单粒种子进行重复识别(如图4-7a蓝色框标记种子)。针对以上两种情况,本研究设计了一套基于YOLOv5的种子发芽检测改进判别方法,借助种子在图像中所处的位置和置信度,通过连续7 d图像的判别结果,对相邻2 d的识别结果综合分析,降低种子漏识别率和重复判别率。判别过程如图4所示,判别步骤如下:
1)以1盒种子的7 d发芽图像为1组,使用YOLOv5对10组种子0~7 d的8张图像进行检测,并输出0~7 d发芽数据:标注框的坐标(x,y)、标注框的长度a、宽度b、置信度p、判断类别。第0天的识别框个数r即为每张图像中应当存在的种子数,本研究受发芽盒的大小限制每盒摆放20粒种子,故获取的r值为20。
2)按照顺序对1~7 d检测重复识别的结果进行剔除。计算单幅图像全部标注框的相对位置距离,当2个识别框的位置距离L小于识别框平均宽度的1/3时,判别该2个识别框重叠,剔除置信度p较低的识别框结果。
(1)
式(1)中:L为2个识别框的位置距离;xi、yi表示第i个判别框的中心位置的横、纵坐标;xj、yj表示第j个判别框的中心位置的横、纵坐标;i和j不同时相等。
3)重复识别结果剔除完成后,从第1天开始按照1到7的顺序检测每张图像是否为20个种子标注框,当第n张图像标注框的总数低于20个,则判定第n天图像出现漏识别。遍历第n-1天图像中20个识别框的位置与第n天全部识别框的最小距离Lk,当Lk大于识别框平均宽度的2/3时,则判定为第k个籽粒在第n张图像上漏识别,将第n-1天的第k个识别框结果传递给第n天,完成漏识别种子的检测。
(2)
式(2)中:Lk为第n-1天图像中20个识别框的位置与第n天全部识别框的最小距离;xk、yk表示n-1天第k个识别框的中心位置的横、纵坐标,k的范围是1~20;xi、yi表示第n天中第i个识别框的中心坐标。
重复判别改进如图4-7a和图4-7b所示,图4-7a中蓝色框标记的种子为检测到重复判别种子,将置信度较低的标注框剔除,得到图4-7b,完成重复判别的改进。
漏识别改进如图4-7a和4-7c所示,图4-7a中橙色框标记的第7天漏识别的种子,将漏识别种子第6天的检测结果传递至第7天。即图4-6c中橙色框补充至图4-7c,完成漏识别种子的改进。

图4 种子重框与种子漏识别的改进判别Fig.4 Correction of duplicate seed markers and lack of seed detection
1.4 评估指标
1.4.1 模型评价指标
YOLO中使用精确率P(precision)、召回率R(recall)、F1-score和mAP(mean average precision)作为评估指标对训练后的模型进行评价,从而对模型的性能进行验证和比较。其中,精确率P表示模型预测目标的精确程度,召回率R表示模型搜索目标的成功程度,F1-score是精确率和召回率的调和平均数,认为精确率和召回率同等重要,最大为1,最小为0。mAP衡量模型对所有类别检测能力的好坏。精确率P、召回率R、F1-score和mAP的定义如公式(3)~(6)所示。
(3)

(4)
(5)
(6)
公式中,TP、FP和FN表示真阳性、假阳性和假阴性样本的数量,VF1-score、VmAP分别代表F1-score、mAP的值,C为类别的数量,N为设置阈值的数量,k为设置的阈值,P(k)和R(k)为k值对应的精确率和召回率。
本研究中,类别的数量C为发芽和不发芽2类。在识别发芽种子时,发芽种子为识别目标,TP表示正确识别为发芽种子的数量,FP表示错误地识别为发芽种子的数量,FN表示错误地识别为未发芽种子的数量,精确率即为在所有识别为发芽种子中实际发芽种子所占的比率,召回率为实际所有发芽种子中识别出来的发芽种子所占的比率。在识别未发芽种子时,未发芽种子为识别目标,TP表示正确识别为未发芽种子的数量,FP表示错误地识别为未发芽种子的数量,FN表示错误地识别为发芽种子的数量,精确率为在所有识别为未发芽种子中实际未发芽种子所占的比率,召回率为实际所有未发芽种子中识别出来未发芽种子所占的比率。
1.4.2 发芽检测指标
发芽率是检测种子发芽的重要指标,为了验证本研究的发芽检测结果,分别取人工检测发芽率、YOLOv5检测发芽率和DB-YOLOv5判别之后的发芽率进行对比。此外,将人工检测、YOLOv5和DB-YOLOv5检测结果的发芽势、发芽指数(GI)和平均发芽天数(MGT)进行对比。发芽势指第3天初次统计发芽率,发芽指数和平均发芽天数计算方法如公式(7)、(8)所示。
(7)
(8)
式(7)和(8)中:VGI为发芽指数的值;VMGT为平均发芽天数的值;Dt为发芽天数;Gt为与Dt相对应的每天新增发芽种子数;G为发芽率[27]。
2 结果与分析
2.1 种子发芽判别
2.1.1 基于YOLOv5x种子发芽检测
为了得到较好的种子发芽检测判别结果,选用网络深度和宽度最大的YOLOv5x进行种子发芽检测。YOLOv5x检测种子发芽部分结果如图5所示。
采用YOLOv5x网络对数据集进行训练和测试,结果显示,YOLOv5x的P为92.21%,R为90.62%,mAP为87.48%,F1-score为91.41%。由于YOLOv5x网络有着较大的深度和宽度,在训练模型时YOLOv5x花费的时间为22.6 h。该研究的目的是使种子发芽检测过程实现自动化,并尽可能减少人工劳动,虽然在数据标注和训练过程中会花费一些人力和时间,但其综合成本要远远小于人工手动检测种子发芽。由各评估指标表明,YOLOv5x在检测种子发芽中具有较高的准确性,较高的评估指标在测试集中也有较好的表现,但是由于种子在发芽过程中存在一些客观因素,降低了YOLOv5x种子发芽检测的准确率。表1为YOLOv5x在测试结果中存在问题统计。
如表1和图5-c、5-d所示,YOLOv5x在测试集中存在两类问题影响检测的准确性,一类是种子漏识别,另一类是单粒种子重框判别。漏识别问题主要出现在第5天、第6天和第7天,是由于在发芽试验的后期茎叶已经长高,各种苗的茎、叶之间互相造成遮挡,导致YOLOv5x模型对测试集进行检测时无法识别种子与种苗特征,从而出现漏识别现象。单粒种子重复判别主要出现在第2天和第3天,多数种子在第2天和第3天时开始长出胚芽和根毛,此时种子处于发芽和未发芽判别条件临界点之间,YOLOv5x模型在检测时对较难区分的种子分别标出了不同的判别结果,并注明各自的类别和置信度。上述两类问题为种子发芽过程中客观存在,并非YOLOv5x网络模型自身检测性能不佳。

图5 YOLOv5x种子发芽检测结果Fig.5 YOLOv5x seed germination test results
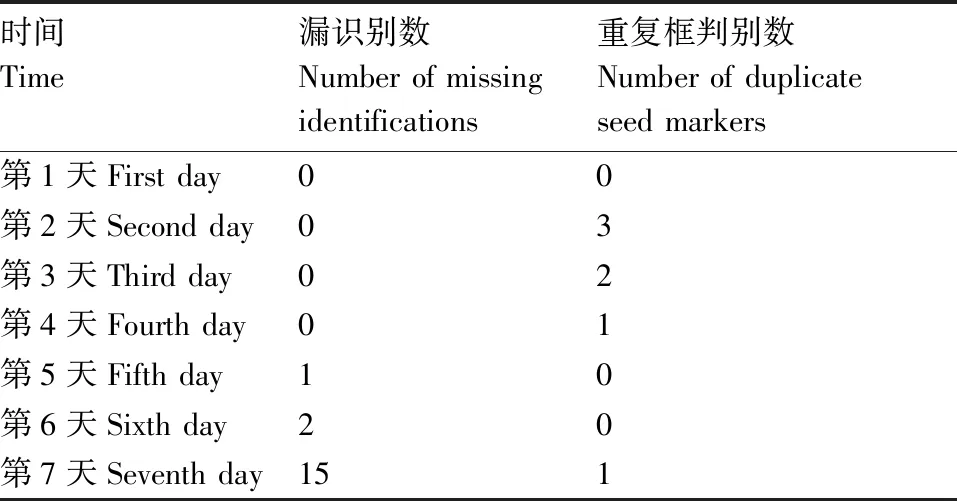
表1 YOLOv5x测试结果的漏识别数和重复框判别数
2.1.2 基于DB-YOLOv5重复判别和漏识别检测
YOLOv5x模型与人工检测相比存在漏识别和重复识别问题,会对发芽率等检测指标的计算造成影响。通过DB-YOLOv5对YOLOv5x的检测结果进行改进判别。判别算法改进之前和改进之后的重复判别数和漏识别数如表2所示。YOLOv5x重复识别个数和漏识别数分别为7粒和18粒,经DB-YOLOv5方法改进判别之后重复识别个数和漏识别数均为0粒。说明本研究设计的DB-YOLOv5方法可以有效解决YOLOv5存在的重复识别问题和漏识别问题,使所有种子都能参加到发芽率等各指标的统计当中,确保了结果的完整性和精确性。
2.2 基于DB-YOLOv5的种子发芽率检验结果
采用YOLOv5x模型和DB-YOLOv5模型统计测试集中200粒种子每天的发芽率,并与人工检测结果进行对比,结果如图6所示。种子从第2天开始发芽,到第5天种子发芽率趋于稳定。人工检测、YOLOv5x和DB-YOLOv5模型检测的发芽率在第2天分别为31.5%、28.5%、30%。出现误差的原因是部分种子在发芽试验第2天根长或苗长接近判别发芽条件临界值,使用YOLOv5x检测时出现重复识别,导致检测发芽率偏低。在人工检测时通过目测判定,未进行实际测量,存在一定的人为误差,部分临界发芽的种子DB-YOLOv5模型与人工判别结果不一致。第5天后随着YOLOv5检测中出现大量漏识别,YOLOv5x检测发芽率开始低于DB-YOLOv5和人工检测,在第7天发芽率降至91%。
结合检测模型,统计测试集7 d发芽数据,测量种子发芽率、发芽势、发芽指数和平均发芽天数发芽指标,统计结果如表3所示。YOLOv5x检测的发芽率、发芽势、发芽指数和平均发芽天数与人工统计的误差分别为6%、1%、4.85和0.35 d,DB-YOLOv5方法检测种子发芽与人工检测结果中发芽率相同,发芽势、发芽指数和平均发芽天数误差为0.5%、2.39和0.1 d。表明通过DB-YOLOv5方法改进判别之后,检测到的发芽率、发芽势、发芽指数和平均发芽天数准确性均得到提升,有效弥补了YOLOv5在检测时存在的不足。

表2 YOLOv5x和DB-YOLOv5方法判别测试结果误差对比

图6 人工检测、YOLOv5x和DB-YOLOv5种子发芽率检测对比Fig.6 Comparison of seed germination rate by manual testing, YOLOv5x and DB-YOLOv5
3 结论
本研究借助YOLOv5目标检测算法对小麦种子进行了发芽检测,在此基础上设计了一套DB-YOLOv5算法对YOLOv5的检测结果进行补充判别,实现了小麦种子的发芽检测分析。通过种子发芽检测试验,得到3点结论:(1)借助YOLOv5对小麦种子进行发芽检测研究,通过试验得到了精确率、召回率等一些较高的评估指标值,并且通过统计测试集检测数据得到了良好的检测结果。表明YOLOv5算法可以对小麦发芽进行判别分析和定位识别。(2)YOLOv5算法在检测发芽判别时无需对种子图像进行特征提取和形态学处理,学习到的特征更为精确,通过训练得到的模型检测速度快、鲁棒性好。(3)YOLOv5模型在检测小麦发芽动态过程中会出现种子漏识别和重框判别的问题,对种子发芽检测结果造成一定的影响。本研究开发的DB-YOLOv5判别算法,通过多天图像组合分析有效解决了种子漏识别和重框判别的问题,为种子发芽自动化检测提供了一种可行的方法。

表3 人工、YOLOv5x、DB-YOLOv5种子发芽检测指标对比
