基于特征融合与SVM的内镜图像分类算法研究
2023-03-16金海彬吕志贤侯木舟
金海彬, 吕志贤, 侯木舟, 曹 聪
(中南大学 数学与统计学院, 湖南 长沙 410083)
0 引 言
据国家卫生健康委员会统计[1], 消化系统疾病患病率在我国两周患病率和慢性病患病率统计中分别排第五位和第四位, 且消化系统疾病住院率位居第三, 严重危害着人们的身体健康。 消化系统疾病通常症状突出而体征不明显, 随着医疗技术的发展, 拥有许多优点的内窥镜, 在消化系统病的医疗诊断中的使用日益增加[2]。 内窥镜的平均拍摄速率大约为2 帧/s, 在历时6 h~8 h的检测过程中, 获取的图像数量高达数万张, 通过医生逐张诊断的方式将耗费大量的时间, 容易造成医生视觉疲劳和错失有用信息, 而仅依靠人工诊断也无法应对逐年增长的患者数量[3]。 因此, 通过计算机辅助, 使用有效的内镜图像分类算法, 能够为医护人员节省宝贵的时间, 对消化系统疾病患者更是具有重大意义。
遗传算法借鉴生物界中适者生存、 优胜劣汰等进化规律, 模拟一个人工种群在若干代后达到最优解[4-5], 是一种随机化搜索优化方法, 在求解较为复杂的组合优化问题时, 通常会比传统的优化算法更快获取到较好的结果。 遗传算法在1975年由Holland提出, 其可以直接操作结构对象, 而不需要考虑连续函数的限定条件, 也不受求导的限制。 同时, 遗传算法有着从原理上对并行运算的友好性, 因此带来了更好的全局寻优能力。 另一方面, 遗传算法也是一种概率化寻优方法, 但其搜索空间与搜索方向总是能够自动适应, 而不需要人为添加过多的规则和干预。 大自然中的生物遗传主要由自然选择、 基因重组、 基因突变构成, 由此设计的遗传算法也是由选择、 交叉、 变异等过程构成。 遗传算法拥有的优良性质, 使其被应用于神经网络超参数寻优、 机器人AI算法设计等领域, 是现代智能计算中的重要技术之一。 目前, 遗传算法与特征融合技术主要应用在语音分割[6]、 情感识别[7]、 红外和可见光图像融合[8]、 高效自动图像注释[9]等领域, 这为基于遗传算法的改进多特征融合方法的设计提供了一种新思路。
支持向量机是一种广泛应用于机器学习领域的统计学习方法。 2010年, Surangsrirat等[10]提出了将内镜图像非线性失真校正后的原始像素的强度值作为支持向量机的输入特征。 2012年, 李凯旋等[11]提出了基于模糊纹理谱的胶囊内窥镜图像识别方法, 引入图像各分量上的模糊纹理谱, 分别提取特征向量, 并利用BP人工神经网络训练与识别, 对不同分量图像采用投票原则确定了最终识别结果。 2013年, 王晓云[12]通过引入群智能算法来优化核参数, 改善了支持向量机在构造核函数和选择核参数时, 大多依靠经验选取或者大范围网络搜索耗时等问题。 2016年, Xue等[13]提出了一种专用于食管癌图像分类的网络NBI-Net, 并使用支持向量机代替softmax分类。 同年, 邓江洪等[14]采用混沌粒子群算法确定特征权值, 提出了一种多特征筛选和支持向量机的图像分类模型, 实验表明, 该方法可以降低图像分类开销, 提升图像分类性能。 2017年, 孟金龙等[15]提出了一种使用图像的梯度直方图(HOG)特征的支持向量机分类方法, 该方法能够有效地进行图像分类。 同年, Li等[16]采用了对病变图像进行数据增强, 迁移Inception-v3 网络并在网络最后添加全连接层的方法进行图像分类, 但分类的准确度有待提高。 2018年, 徐婷婷等[17]提出了基于颜色和纹理特征的胶囊内镜图像分类方法, 结合颜色矩和小波变换计算共生矩阵特征值, 进一步提升了准确率。 2021年, 梁立媛等[18]将经过迁移学习的卷积神经网络提取的图像特征作为支持向量机的输入特征。 同年, 曹燕珍等[19]提出了一种CNN-OVA-SVM模型, 该模型使用Resnet-50卷积神经网络提取图像特征, 将支持向量机作为子分类器, 使用一对多集成分类器进行图像分类, 对于不同分化类型的结直肠腺癌的鉴别具有一定的临床价值。
目前, 大多数基于支持向量机的内镜图像分类算法都采用传统的特征融合方法, 这种方法的缺点是特征数量大、 冗余度大,且受主观因素的影响较大。 采用卷积神经网络对内镜图像进行分类, 比传统分类方法拥有更强的自动学习特征的能力, 但设计一个有良好分类效果的卷积神经网络需要大量的数据来优化网络中的参数。 针对内镜图像数据量少的问题, 本文采用基于遗传算法的改进多特征融合方法, 首先对数据进行预处理以及数据增强, 从原始特征向量中选择多种分类性能优良的组合, 再将这些组合作为支持向量机的输入, 得到多个分类模型, 最终将多种分类模型的分类结果通过投票集成, 构建最终的内镜图像分类模型。
1 基于改进遗传算法的多特征融合方法
特征融合是指利用现有的多个特征集生成新的融合特征, 通常可以获取不同特征集之间最具差异的信息。 由于融合特征信息量总是不少于原始的任何单一特征集, 故使用融合特征进行分类的效果通常也优于使用原始的任何单一特征集。 因此, 本文提出一种基于遗传算法的改进多特征融合方法, 使用支持向量机作为分类器的内窥镜图像分类算法。 构建原始的初代个体作为主种群, 计算初代个体的适应度, 从中自然选择出父本个体, 通过基因重组生成子代个体, 对每个子代个体产生基因突变, 同时加入最优秀的父本个体共同构建下一代。 每一代主种群自然选择时, 若种群数量较少, 选择一部分次优个体构建新种群, 与主种群并行迭代, 否则这部分次优个体随机均匀分配到各个旁支种群中。 最终各个种群均获取到分类性能较好的个体, 这些个体共同构建一个投票模型。 基于遗传算法的改进多特征融合算法流程图见图1。

图1 基于遗传算法的改进多特征融合算法流程图
1.1 基于改进遗传算法的特征选择
对于大量的图像特征, 需要找到一种特征组合, 使得在低维度特征空间下也能有较好的分类性能。 由于特征组合之间很难找到一种有效的定量分析方法, 因此使用启发式搜索的遗传算法就很有必要。
1.1.1 遗传因子与自然选择
如果将经过过滤的特征全体作为基因组, 对每一个特征使用特征在特征集中的位置下标来唯一表示, 那么对于每一个个体, 规定其遗传物质为一个下标集合, 该集合中的每一个值都对应着基因组中的一个特征, 所对应的特征集合为基因组的子集。 序列集合的长度即个体的遗传因子长度, 为了之后的遗传过程能够顺利进行, 要求每个个体的遗传因子长度相等。 对于某一代的全体个体, 基于适应度函数从中选择评价较高的部分个体作为下一代的父本个体, 并淘汰其他个体。 鉴于适应度函数对遗传物质的微小变化过于敏感, 同时为获取整个遗传过程中最优秀的个体, 并将优秀个体的基因保留下来表达其在遗传过程中的重要程度, 在每次自然选择结束后, 选择父本个体中部分较优秀的个体, 加入到下一代中, 使得每一代的最好个体的评价指标总是不小于前一代。
1.1.2 两种基因重组策略
为分析不同特征组合对最终分类性能的影响, 考虑两种不同情况: 1) 单个含有较多信息的特征能对分类性能产生较大影响; 2) 特定的特征组合能对分类性能产生较大影响。 针对以上两种情况, 需要设置不同的基因重组策略来进行具体分析。
第一种情况, 首先需要找到对提高分类性能有作用的有效特征, 并假设遗传物质中含有较多有效特征的个体, 其适应度也相应较高。 此时, 采用基因池策略, 即将全体父本个体包含的所有特征合并作为基因池, 通过在基因池中随机选择子集生成下一代个体。 该方法保证每个子代个体都有均等的机会从每个父本个体中获得遗传物质, 但当子代数量较多时, 容易繁殖出含有更多有效特征的子代个体。 考虑到父本个体之间可能含有相同的特征, 这些特征在合并后可能同时遗传给下一代, 导致下一代的遗传物质中包含了两个或多个相同的特征, 因此在特征合并后, 可以先对基因池进行去重操作, 以避免这种情况的发生。 基因池策略示意图如图2 所示。
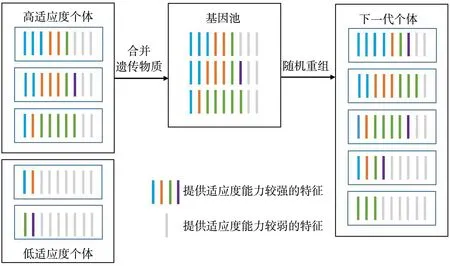
图2 基因池策略示意图
第二种情况, 需要找到对提高分类性能有作用的特征组合, 同样对于适应度较高的个体, 其遗传物质的特征组合较好, 此时如果同样使用基因池重组策略, 将完全打乱父本个体的特征组合, 无法有效保留父本较好的特征组合, 因此需要采用另外的重组策略。 从自然界的染色体交叉互换得到灵感, 采用交叉互换策略, 即对于任意两个父本个体, 通过交换少量特征生成子代个体, 这种基因重组策略能够在子代个体基本保留父本个体特征组合的情况下, 产生多样化的子代个体。 交叉互换策略示意图如图3 所示。

图3 交叉互换策略示意图
1.1.3 基因突变与动态变异度
基因突变在遗传算法中起到引入和维持多样性的作用。 如果仅以自然选择和基因重组获取子代个体, 则最终子代个体的特征组合是初代个体特征并集的子集, 导致得到的最终结果只是局部最优解, 无法反映整个特征空间的作用。 因此, 对于每次基因重组后产生的每个子代个体, 均要用部分基因组中的特征替换遗传因子中的部分特征, 以保证最终结果是在整个基因组下的满意最优解。 其中, 突变基因占总遗传物质长度的比例被称为变异度。 基因突变示意图如图4 所示。
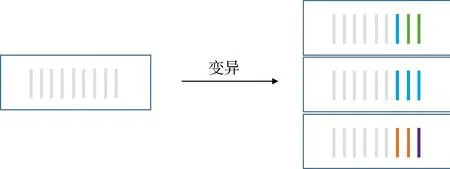
图4 基因突变示意图
如果种群中个体的遗传物质都基本相似, 那么基因重组对提高个体多样性的帮助将非常有限。 为了增强遗传算法的搜索能力, 通过增大变异度来增加基因突变的搜索范围, 为此引入动态变异度的概念。 为了描述种群的遗传物质多样性, 定义如下:

(1)

(2)
式中:α为种群遗传物质多样性系数,α=0表示种群中的所有个体的遗传物质均相同; φ为种群变异度; φ0为最大变异度; L为单个个体的遗传物质长度; N为全体种群不同的特征总数。
1.1.4 种群分裂与种群融合
在传统遗传算法中, 对于适应度不高的个体, 通常的处理方式是丢弃, 或是降低它繁殖的概率。 但在这类个体中, 可能也存在部分优秀基因, 若能提取出这部分优秀基因, 也能避免遗传算法陷入收敛局部最优解的情况。 主要的迭代种群称为主种群, 对于迭代过程中适应度低一级的部分个体, 单独剥离出来加入旁支种群, 在旁支种群中作类似于主种群的迭代。 旁支种群的平均适应度通常低于主种群, 而为了增加旁支种群的搜索效率, 需设置更大的变异系数。 同时, 由于旁支种群总在吸收主种群淘汰的次等个体, 这可能导致旁支种群中充斥着主种群基因。 因此, 可以增加旁支种群的数量, 将主种群每次的淘汰个体均匀分给各个旁支种群, 而某个旁支种群不会吸收太多来自主种群的基因, 保证了自己的基因独立性。
如果两个种群基因重合度较高, 即种群中个体的特征组合高度相似, 可以预见两个种群内个体的平均适应度也将相近。 对于这样的两个种群, 仍将它们分开计算是没有必要的, 而且分开计算还会增加计算机的性能开销。 因此, 可以将两个种群依照某种策略合并到一起计算。 一种策略是将两个种群直接合并构建出一个大种群, 这种策略能够完全保留原种群的遗传物质信息, 但计算机性能开销仍然较大; 另一种策略是选择两个种群中的优良个体合并为新种群, 并淘汰掉其他个体, 这种策略的计算机性能开销较小, 但也减少了基因信息。 因此, 在计算过程中需要综合考虑计算性能等方面的因素来选择不同的种群融合策略。
1.1.5 种群消亡与多种类投票制度
与自然界的生物进化状况相同, 一个物种的进化并不能保证总是适应环境, 最终也会因为无法适应环境而消亡。 同样, 旁支种群的进化过程并不总是有效的, 很可能在多次遗传迭代后, 种群的平均适应度仍然较低, 而且也没有产生适应度较好的个体, 此时, 认为这个种群的基因是较差的, 因此, 需要淘汰该种群以减少计算机性能开销, 视为种群消亡。
对于任意一个个体, 由于其遗传物质仅是基因组的极小一部分, 尽管他可能有较好的分类性能, 但无法改变其对整个图像特征集合利用率不高的事实, 这个问题会导致由此获取的分类模型泛化性能较低。 考虑到旁支种群在独立进化过程中, 可能会独立进化出有较高适应度的个体, 同时这些个体与主种群的基因重合度极低, 而在整个算法过程中, 可能最终得到多个这样的旁支种群及其中的多个优秀个体, 这些个体中的每一个都代表着一个支持向量机分类模型。 如果将这些分类模型通过投票的方式组合成一个集成模型, 一方面能够提升模型的分类准确率, 另一方面也将缓解单个分类模型对特征利用率不高的问题, 还能提升模型的分类泛化性能。
1.2 改进遗传算法在特征选择中的应用
1.2.1 基因编码与适应度函数的选择
适应度函数表示种群个体对环境的适应能力, 也称为评价函数。 对于某一代的全体个体, 基于适应度函数从中选择评价较高的部分个体作为下一代的父本个体, 并淘汰掉其他个体。 本文的自然选择方法使用精英主义选择, 通过将种群中较优的个体保留到下一代中来保证某些优秀的个体不被变异破坏[20-21]。 在内镜图像分类任务中, 由于很难找到一个简单的数学方法去判别某一类特征组合的性能, 因此最直接的评价方式就是将这个特征组合输入到支持向量机进行分类, 并以分类结果作为评价指标。 该方法的缺点是计算开销较大。
1.2.2 初始种群的构建
实验采用随机生成的方式从基因组中获取30个个体作为初始种群, 30个个体的基因总数约为基因组的3倍。 为了最大化基因组的利用率, 采用对每个基因随机选择3个个体的方式, 以保证基因分配有较高均匀度。
1.2.3 实验流程
对于获取的原始内镜图像, 由于数据量较少, 首先要进行数据增强与数据预处理去噪, 再根据医生标注的内镜图像按照8∶2的比例分成训练集与测试集, 最后采用基于遗传算法改进的多特征融合算法迭代, 得到最终的正常与病变的二分类结果。 实验设计流程图如图5 所示。
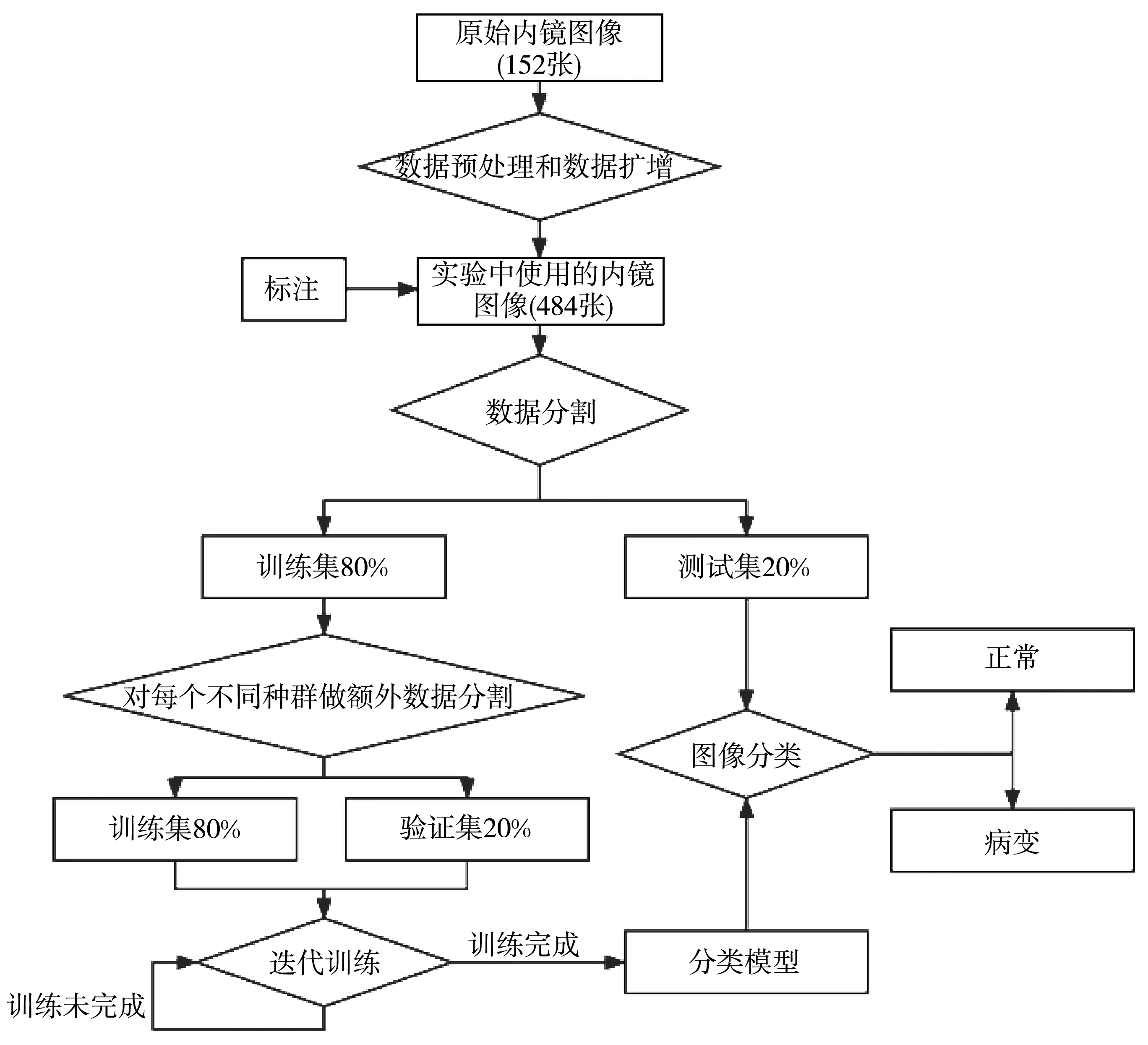
图5 实验设计流程图
2 实验数据与预处理
2.1 数据来源
本文使用了中南大学湘雅医院消化内科采集的实验数据集。 排除包含玻璃、 设备和低分辨率的图像, 该数据集包含152张内镜图像, 其中, 正常图像30张, 异常图像122张。 所有受试者均已签署知情同意书, 符合湘雅医院医学伦理委员会的伦理标准, 所有程序均根据批准的指导方针和法规执行。
2.2 数据预处理和数据扩增
部分原始内镜图像中包含一些冗余的文本数据或图像缩略图, 这些无关数据可能会作为噪音影响最终的模型分类性能, 因此需要先去除掉。 本文通过人工切割的方式进行无关数据去除。 图6 为冗余数据剪裁前后的对比。

图6 内镜图像冗余部分裁剪前后对比图
由于原始数据较少, 容易产生过拟合, 导致模型的泛化性能较差, 直观表现在模型对训练集的分类效果较好, 但对测试集的分类效果不理想。 为了缓解这个问题, 需要对数据进行扩增, 即通过镜面对称后对每张图像分别旋转90°, 180°, 270°,使图像数量扩充至原始数量的 8 倍。 同时, 为了解决类别不平衡的问题, 对已有的正常类别的图像进行上述操作, 而对于病变图像仅进行镜面对称操作, 使图像数量扩充至原始数量的 2 倍, 这样使得两类图像均达到 240 张左右, 得以均衡。
内镜图像含有一定的噪声, 而支持向量机是一种对噪声敏感的机器学习算法模型, 因此在获取图像特征之前, 首先使用高斯滤波去除噪声。 高斯滤波函数是一种线性滤波函数, 能够有效地去除图像中的高斯噪声。 另外, 由于人眼对蓝色的敏感性大于红色, 导致RGB(Red, Green, Blue)颜色空间是一种均匀性较差的颜色空间, 如果颜色的相似性直接用欧氏距离来度量, 其结果与人眼视觉会有较大的偏差。 对于某一种颜色, 很难推测出较为精确的3个分量数值来表示。 因此, RGB颜色空间并不适用于图像处理, 需要在HSV(Hue, Saturation, Value)颜色空间下重构图像。
图像从RGB颜色空间转换到HSV空间的算法如式(3)所示。
V=max(R,G,B),

(3)
VGG16模型对输入图像的尺寸要求为224×224, 而本文所使用的数据图像尺寸大小不一, 因此需要调整尺寸到224×224。 使用按比例放缩的方式, 将原图像长边缩小至224像素, 短边按相同比例缩小并补0值至224像素。
2.3 图像特征提取
通过颜色矩、 灰度共生矩阵、 VGG16[22]、 Resnet-152[23]分别提取内镜图像的颜色、 纹理和深层特征, 构成图像的原始特征集。 将高斯滤波后的图像从RGB颜色空间转换到HSV颜色空间, 提取均值、 方差、 斜度每个分量上的3个低阶矩, 构造9维颜色特征向量。 提取灰度共生矩阵前需先将原3通道图像转换为灰度图像, 根据人眼对颜色的感知, 颜色转换的公式为
Gray=0.299R+0.587G+0.114B。
(4)
使用经过压缩的灰度图像可以获得更好的效果, 因此将灰度级设置为16级。 同时, 为了获取图像中的精细纹理, 使用步长为1, 大小为7×7的滑动窗口, 取0°, 45°, 90°, 135° 四个方向获取特征值。 原始正常内镜图像及其经过灰度处理的图像见图7, 原始的病变内镜图像及其经过灰度处理的图像见图8。

图7 原始的正常内镜图像和经过灰度处理的正常图像

图8 原始的病变内镜图像及经过灰度处理的病变图像
通过提取图像的灰度共生矩阵, 计算出二次统计量对比度、 熵、 能量和均匀性, 构造出图像的32维纹理特征向量。 使用预训练的VGG16和Resnet-152卷积神经网络模型, 通过选择其特征提取层部分构建的特征提取模型, 输入尺寸为224×224的内镜图像, 输出大小为7×7×512的特征矩阵, 由此分别构建25 088维特征向量和2 048 维特征向量。
3 验证实验
3.1 实验设置
本实验在python环境下实现, 实验设备为华硕TUF GAMING FX504GE_FX80GE, 硬件为Intel(R) Core(TM) i7-8750H处理器, 16 G内存。 将尺寸大小不一的原始图片调整为224×224, 不同尺寸的图片只是分辨率有所不同, 在内容上无特殊差别。 缩小尺寸可以让各个特征提取模块更好地处理图像, 减少运算量, 加快运算速度。 为了避免偶然性, 在研究中随机选取80%的图像作为训练集, 20%的图像作为测试集测试模型的分类准确性及可靠性。 类似于交叉验证, 对于每个种群, 将训练集的20%作为验证集。 训练与测试数据之间互不交叉。
训练支持向量机模型时, 采用网格搜索的方式获取最佳参数设置, 设置惩罚因子C的候选参数为1, 5, 10, 15, 20, gamma值的候选参数为0.01, 0.001, 0.000 1, 核函数kernel的候选参数为高斯核、 线性核和多项式核。 遗传算法中使用的各项参数为: 最大遗传代际数量为100, 个体遗传物质长度为2 048, 每代个体数量为30, 最大变异度为0.05, 自然选择父本数量为6, 父本直接遗传至下一代的数量为1, 最大种群数量为7。
为了对比不同实验方法和参数对最终分类结果的影响, 本文进行了3组实验。
实验1: 为了验证遗传算法中两种基因重组策略对遗传算法的收敛速度及最终分类性能的影响, 基于两种基因重组策略进行迭代, 并对比迭代结果。
实验2: 为了验证基于遗传算法的特征选择的有效性, 将遗传算法迭代结果与将简单特征融合作为支持向量机输入训练的模型对比。
实验3: 为了对比在该实验数据下, 对支持向量机分类模型应用不同的核函数对分类性能的影响, 使用不同核函数分别训练模型并进行对比。
3.2 评价指标
对于本研究的分类问题, 根据样本真实标签与分类器预测标签的组合分为真正例, 真反例, 假正例, 假反例四种, 研究中TP,TN,FP,FN分别代表对应的样例数, 其中取标签正常为正例, 标签异常为反例。 另外, 本研究中采用典型的性能评价指标: 准确率Acc(Accuracy)、 精准度Pre(Precision)、 召回率Rec(Recall)、F1得分(F1-Score)、 特异度Spe(Specificity)。

(5)
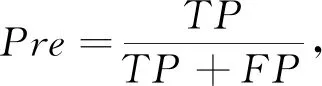
(6)
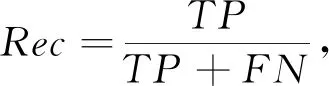
(7)
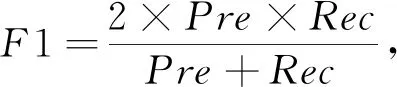
(8)

(9)
3.3 实验结果分析
3.3.1 基因重组策略对比
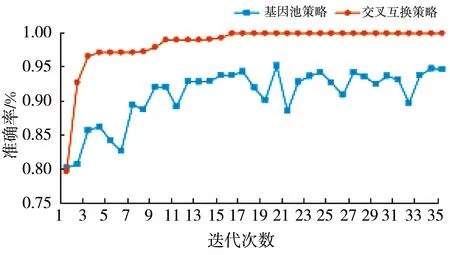
为了验证两种基因重组策略对遗传算法迭代过程与最终获取的分类器性能的影响, 基于两种基因重组策略进行实验对比分析。 预测的准确率对比见图9。
(a) 每代父本个体
在基因池策略下, 种群父本个体在验证集上的平均预测准确率在前10代中从80%左右上升到92%左右, 之后的变化情况呈振荡式; 种群最优个体在验证集上的预测准确率缓慢上升, 最终达到99.03%。 在交叉互换策略下, 种群父本在验证集上的平均预测准确率逐步上升, 最终收敛到100%, 说明所有父本个体在验证集上都有100%的预测准确率; 种群最优个体在验证集上的预测准确率在14代左右也收敛到100%, 说明该策略下的遗传算法有搜索到全局最优情况的能力。
对比两个基因重组策略下的结果, 相比于基因池策略, 交叉互换策略有更高的收敛速度和局部寻优能力, 说明交叉互换策略更加适用于本实验数据。 后续实验都将基于交叉互换策略。
3.3.2 多种特征选择方法对比
针对不同的特征选择对支持向量机模型分类性能的影响进行对比实验分析。 5种方法分别是基于颜色矩和灰度共生矩阵的颜色和纹理特征、 基于VGG16[22]卷积神经网络提取的特征、 基于Resnet-152[23]残差网络提取的特征、 基于上述3种方法的全体特征以及在全体特征基础上经过改进的多特征融合方法获取的特征。
表1 展示了5种方法的实验结果。 其中, 基于改进的多特征融合方法获取的分类模型, 分类准确率达到93.39%, 精准度达到94.55%, 召回率达到92.86%,F1得分达到93.69, 特异度达到94.00%。 相比任何单一特征提取方法, 改进的多特征融合方法的分类性能均有较大的提升, 对于使用3种特征提取方法获取的综合特征, 除准确率和特异度外也有一定提升。

表1 不同特征融合方法对内镜图像分类的结果比较
改进的多特征融合方法分类的混淆矩阵如图10 所示, 从实验结果看, 使用改进的多特征融合方法, 对于提升分类性能有一定帮助。
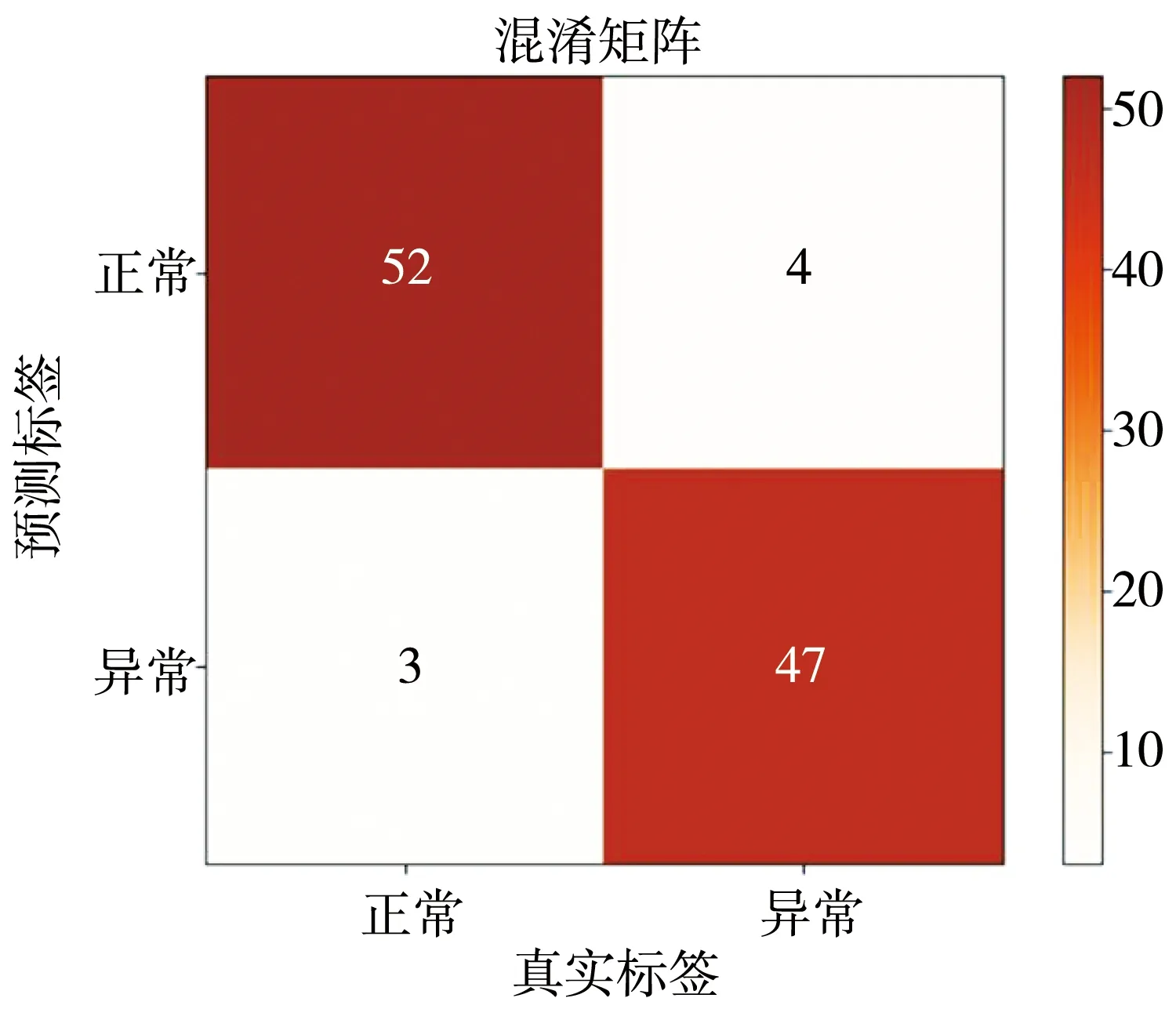
图10 改进的多特征融合方法分类的混淆矩阵
将本文方法同其他的图像分类方法进行对比, 结果如表2 所示。
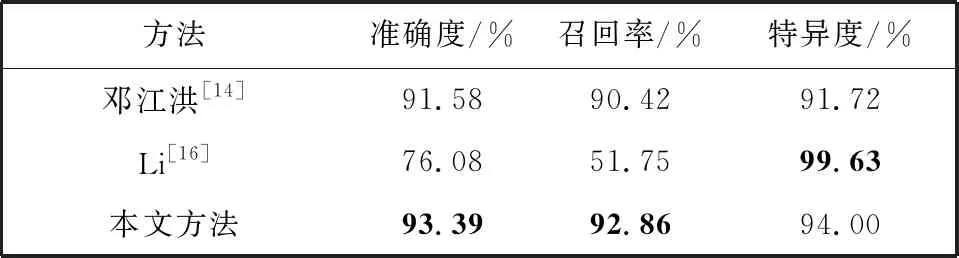
表2 本文方法与其它方法的分类结果对比
邓江洪等[14]是根据特征的平均影响值对提取的颜色矩和灰度共生矩阵特征进行筛选, 再用SVM进行分类。 Li等[16]采用只对病变图像进行数据增强, 迁移Inception-v3网络并在网络最后添加全连接层的方法来分类图像。 由表2 可知, 本文改进的多特征融合方法在敏感性、 准确率方面均高于其他2种方法, 由于数据的样本少以及数据不平衡, 特异性略微低于Li等[16]的方法, 实验结果验证了本文方法的有效性。
3.3.3 不同核函数对分类性能的影响
实验使用3种不同的核函数(线性核(linear)、 高斯核(rbf)、 多项式核(poly))分别训练支持向量机分类模型。 表3 展示了在改进多特征融合方法下不同核函数对分类性能的影响。 实验结果表明, 基于高斯核的支持向量机有更好的分类性能, 使用线性核则分类性能相对较低。 为了继续探究核函数对分类性能的影响, 对经典的特征融合方法进行同样的研究, 结果见表4。

表3 改进多特征融合方法下不同核函数的支持向量机模型分类性能对比
由表4 可知, 在经典特征融合方法下, 使用的核函数为线性核时分类性能最佳, 而使用的核函数为高斯核时分类性能一般。 实验结果表明, 在经典特征融合方法下, 图像的高特征向量维数与实验图像样本数量存在巨大的差异时, 采用线性核核函数时分割能力较为优异, 而在特征向量维度较低的情况下, 采用高斯核核函数时分割能力较为优异。

表4 经典特征融合方法下不同核函数的支持向量机模型分类性能对比
综上所述, 本研究提出的基于改进遗传算法的多特征融合方法, 在支持向量机模型下对内镜图像的分类性能优于传统的特征融合方法。
4 结 论
本文在传统特征融合方法的基础上, 提出了基于改进遗传算法的多特征融合方法, 使用支持向量机作为分类器的内窥镜图像分类算法。 该遗传算法通过在迭代过程中保留最优个体, 采用基因交叉互换和种群分裂、 融合、 消亡以及种群投票制度获取优质个体。 实验结果表明, 该算法在本文所使用的数据集上结合支持向量机能够较为有效地进行二分类, 分类准确率达到93.39%, 其余指标都较为优异。 相比于经典的特征融合方法, 分类性能有一定提升, 为内镜图像辅助诊疗及相关算法研究提供了一种新思路。
在去除内镜图像中的各种无效部分时, 由于尚未找到一个较好的自动化方法, 文中采用的方法都是人工去除, 这种方法在数据集较小时适用, 但面对较大数据集时将无能为力。 另外, 由于消化道内各种组织液对光线的反射会在内镜图像中形成高光等杂质, 本文未对这些特殊噪声进行消除, 一定程度上来说降低了最终模型的分类性能。
