“MAD”多注意力网络伪脸显廓系统
2023-03-16马梓为杨子琪李晨帆黄郅皓
马梓为 ,杨子琪 ,李晨帆 ,黄郅皓
(1.北京航空航天大学 沈元学院,北京 100083;2.北京航空航天大学 网络空间安全学院,北京 100083)
0 引言
进入信息时代后,个人身份比以往任何时代都更显重要,证明个人身份最常用最方便的方法之一就是人脸识别。然而,随着人工智能(AI)换脸技术的出现,不法分子替换甚至修改“受害者”的面部表情、说话口型,身份伪造的隐患大大升高。据统计,AI 换脸诈骗在我国每年约造成40 亿元的损失,占电信诈骗金额的11%。AI 换脸盗用名人身份造谣抹黑的现象层出不穷,还出现了换脸视频配合语音合成技术引发社会舆论动荡的现象。比如美国前总统奥巴马被换脸到一段痛骂特朗普的视频中,引发了美国社会激烈讨论。扎克伯格也在一段虚假视频中宣称他掌握了所有脸书用户的隐私信息,一时间受到人们口诛笔伐。这些现象都说明了AI 换脸行为危害与日俱增,保护个人身份不被篡改意义重大。发展AI 换脸检测技术以保障网络空间的公共安全势在必行。
普遍的AI 换脸检测方法对于全脸形式的AI 换脸十分有效。然而,随着换脸技术不断发展,出现了将人脸局部位置进行替换的局部换脸[1]。局部换脸产生的威胁十分严重,多个人的面部特征可以隐藏于同一张人脸上,而这张假脸具备了多个换脸者的身份信息。大多数的检测方法对于局部换脸技术都是无效的。究其原因,一方面是普遍的AI 换脸检测技术往往通过不自然的表情、光影、性别等特征鉴别真伪,而局部换脸会缩小这些方面的差距。另一方面,一些换脸检测技术仅仅针对特定算法,而无法检测其他算法生成的假脸。
本文以Deepfake 网络和人脸混合算法(Face blending)[2]生成的虚假人脸为检测目标,以人脸混合算法生成的虚假人脸为主要训练目标,以经过多注意力网络(Multi-attentional Deepfake Detection)[3]加强学习的人脸伪影网络(Face X-ray)为基础结构框架,创新性结合后搭建的基于卷积神经网络的机器学习神经网络。本文所做工作主要有以下几方面:
(1)实现了基于人脸特征点对局部人脸的进行替换的简单算法,凭借该算法构建了网络训练所需数据集。
(2)对高分辨率网络(High-resolution Net)[4-5]进行了推广,将其应用到人脸图像特征识别,作为网络中的特征提取模块。
(3)为多注意力网络(Multi-attentional Deepfake Detection)添加接口,成为网络中的多注意力模块,创新性地使其与高分辨率网络相结合。多注意力网络能够放大某一特定区域的特征信息,即标记可能的换脸痕迹并且生成一张包含换脸位置的灰度图。
1 相关研究
1.1 当前虚假人脸检测手段
作为出现伊始就备受关注的研究课题,目前已经出现大量针对人工智能换脸技术的检测手段[4-11]。早期的检测手段[7-8]常常集中于检测对象不符合生物特征的不自然动作,如眨眼或者与面部位置不符的头部动作。现有的大多数方法都将深度假检测视为一个通用的二元分类——真或假问题。他们主要研究如何构建复杂的特征提取,通过二分法来区分真假人脸。这些方法往往都是针对全脸,缺少对于部分位置的介观检测。同时,其中一些方法[6,12-13]则指只适用于特定环境或特定AI 换脸方式,比如微观检测网络(Mesoscopic Network/MesoNet)[6]是针对Deepfake和Face2Face 置于中层水平的分析。
1.2 高分辨率网络
高分辨率网络是针对2D 人体姿态估计(Human Pose Estimation 或Keypoint Detection)任务提出的,并且该网络主要是针对单一个体的姿态评估。
大多数现有的方法都是从高-低分辨率网络产生的低分辨率表征中重新提取高分辨率表征。高分辨率网络在整个过程中保持高分辨率表征,从第一个阶段的高分辨率子网络开始,逐步增加高-低分辨率的子网络,并将多分辨率的子网络平行连接起来进行重复的多尺度融合,使每个高-低分辨率的表征都能不断地接收到其他部分表征的信息,从而导致更为丰富的高分辨率表征。本文将高分辨率网络识别人体姿态应用于人脸识别,可以标记目标的特征并检测换脸痕迹。
1.3 多注意力网络深度造假检测
如前所述,大多数方法将虚假人脸伪造检测作为普通的二元分类问题,即首先使用骨干网络提取全局特征,然后将其加入二元分类器(真/假)。但多注意力网络将深度造假检测制定为一个细粒度的分类问题。具体来说,它由三个关键部分组成:(1)注意力分布模块关注不同的局部区域;(2)在纹理特征增强块中,放大浅层特征中的细微假象;(3)对低层纹理特征和高层半实物特征进行聚合。
本文对多注意力网络中的注意力分布和材质增强部分进行了改进,修改其输入输出形式,同时得到单通道的灰度图用于表征换脸区域。
2 优化人脸混合算法
人脸混合算法是一种简单的人工智能换脸算法,其原理是基于人脸特征点位寻找目标人脸中特征点分布最为相似者进行替换。基本流程是选定目标替换区域,确定替换区域特征点编号,在背景人脸(source)库中选定一张人脸,遍历目标人脸(data)库中人脸,根据特征点位置计算相似度,按照相似度排序选定最相似的100 张人脸。随机选定100 张人脸的一张作为目标人脸。按照人脸轮廓换脸,生成虚假人脸轮廓(Xray),如图1 所示。
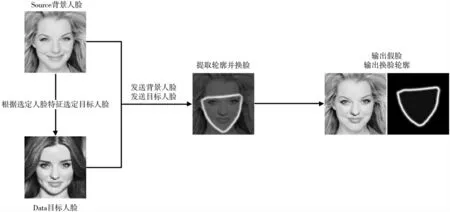
图1 人脸混合算法示意
人脸混合算法换脸后的结果多数出现了颜色不合适或突兀的现象,究其原因是人脸混合算法中使用了库函数color_transfer,其功能是根据背景人脸的颜色修改目标人脸的面部颜色以达到颜色一致,减少修改痕迹。但效果并不理想,图片颜色出现明显的颜色差异。因此本文删去了color_transfer 函数,发现换脸效果较好。与此同时,目标人脸的选择也发生了改变,选择了更为合适的目标人脸。利用人脸混合算法,共产生了大小为25 000 的训练集和2 000 的测试集。该数据集是目前可用数据集中唯一带有换脸痕迹的图片集。换脸结果如图2 所示。

图2 对于嘴部局部换脸结果
3 人脸伪影提取网络
将特征提取与多注意力模块创新性结合,形成人脸伪影网络,以此为核心搭建基于卷积神经网络的AI 换脸检测系统。
3.1 特征提取模块
高分辨率网络模型的作用是对输入的图片进行一系列操作,最终输出其预测的换脸轮廓,整个过程中保持高分辨率表示。反复交换并行多分辨率子网络中的信息来进行重复的多尺度融合,具体过程如下。
首先,将原有的PyTorch 函数固定卷积核尺寸为3 重新封装,对输入图片先使用1×1 卷积先降维,再使用3×3 卷积进行特征提取,最后使用1×1 卷积重新升维。然后,利用前向传播函数forward 搭建高分辨率模块(HighResolutionModule):(1)仅包含一个分支时,生成该分支,没有融合模块并直接返回。(2)包含不仅一个分支时,先将对应分支的输入特征输入,得到对应分支输出特征,然后执行融合模块。高分辨率模块所有分支不断增加分支、加深、融合后,最终输出3 个参数,分别是36 通道的X1、72通道的X2、144 通道的X3。特征提取模块结构如图3所示。
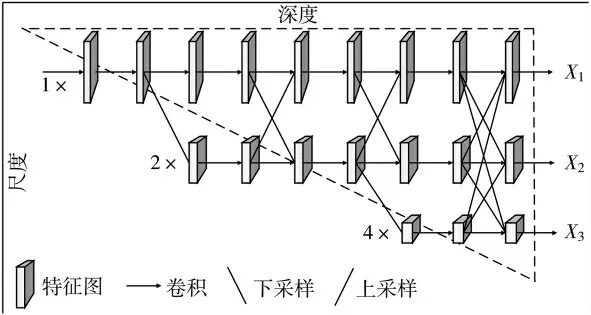
图3 特征提取模块结构
3.2 多注意力模块
为了从不同尺度提取伪造痕迹,以达到精细化识别的深度造假检测,本组决定使用多注意力网络,将检测目标集中于几个高反应的注意力区域(如嘴部、眼部等),分别检查造假痕迹并生成预测换脸痕迹。由于在不间断的训练之后神经网络的参数往往会使其集中于人脸的某一部分而忽略了其余部分存在的问题,采用多注意力模型强迫神经网络向更多的方向进行学习,而不是仅集中于某一块常出现问题的区域,可以增加整个网络的健壮性、精密性和稳定性。
多注意力网络对高分辨率网络的输出进行一系列处理,最终得到1 通道的灰度图,即预测换脸痕迹图。多注意力模块如图4 所示。
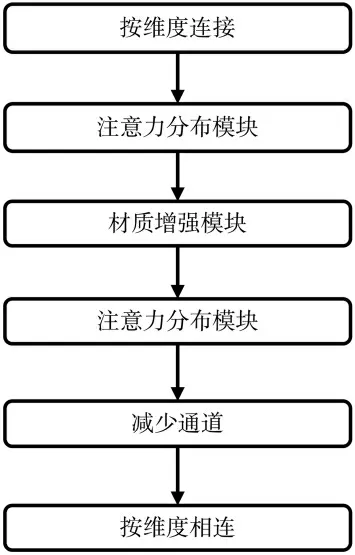
图4 多注意力模块
3.2.1 注意力分布模块
注意力分布模块(Attention Module)对某一特定区域给予独特关注,通过卷积、批处理归一化、非线性激活后输出许多层注意力块,即各个区域的扫描结果,如图5 所示。注意力信息模块本身是一个轻加权模型,由1×1 的卷积层、批处理归一化层和非线性激活层ReLU 组成。在输入某一层图像时,该模块可对其进行提取,最终得到大小为Ht×Wt的注意力块,代表着对某一特定区域的独特关注。

图5 注意力分布模块组件
3.2.2 材质增强模块
由于伪影通常在浅层特征的纹理信息中较为突出,为了保留更多的纹理信息来捕捉这些伪影,本文采用归一化平均池化的方法,并使用3 层密集连接的卷积块来增强纹理信息。
该模块主要流程为对于输入的特征层Sla,对其进行局部平均池化以向下采样得到该层的图像特征D,根据空间纹理定义对图像纹理进行如下定义:
在得到初步的图像纹理T 的基础上,将其输入3 层的密集连接卷积块,对其进行纹理增强,得到最终的图像纹理。
多注意力模块的加工处理过程如下:
(1)按维度连接36 通道的X1、72 通道的X2、144通道的X3得到240 通道的X:
(2)对X1进行注意力分布模块处理,输出72 通道的:
(4)对144 通道的X3进行注意力分布模块处理,输出17 通道的:
(5)对X 进行Head()处理,将其从240 通道变为17 通道:
对89 通道的Xout卷积,最终输出1 通道的预测换脸痕迹灰度图。
3.3 伪影概率检测与输出
概率输出组件在得到上述网络输出的预测换脸痕迹后,将其作为输入进行线性和非线性的运算,得到对应人脸为虚假的概率,判定输入网络的人脸是否为经过换脸的虚假人脸,并输出对应的换脸痕迹。概率输出组件实际上是由全局平均池化层、全连接层和softmax 激活层按顺序组成。
在全局平均池化层中,利用Adaptive-AvgPool2d函数对得到的预测脸框进行全局平均池化,在保持其原有数据特征的前提下对数据进行降维,以便于进一步处理与比较。同时,利用自适应池化使网络对任意图片都具有一定的处理效果,而并不局限于某一规格的输出。
在全连接层中,通过.view 函数将池化后的特征图转换为一维向量,再将一维向量通过nn.Linear()进行全连接,通过sigmoid 函数对得到的结果进行激活,得到最后的预测概率。
4 实验与分析
4.1 数据集信息
CelebA[14]数据集是一个大规模名人特征数据集,包含超过200 000 张名人照片,每张照片都有40 个属性标注,注释包括2 025 999 个人脸图像的5 个关键点位置。
CelebAMask-HQ 是一个大规模的人脸图像数据集,包含了3 万张从CelebA 数据集中选择的高分辨率人脸图像CelebA-HQ,每个图像都有对应CelebA的人脸属性的分割掩码。CelebAMask-HQ 的mask 大小为512×512,共有19 类属性特征,包括皮肤、鼻子、眼睛等面部部位和装饰配件。
实验所用数据集以CelebAMask-HQ 所标定的目标区域为基础,利用改进的人脸混合算法进行局部和全部的人脸替换,生成了全脸、眼睛、嘴巴、鼻子、眉毛部位经过替换的各2 500 张假脸和另外12 500 张真脸,共同构成了大小为25 000 的实验所用训练集。同时生成上述5 种替换不同部位的假脸各200 张,与1 000 张真脸构成了大小为2 000 的测试集。
4.2 神经网络训练
在Python3.9.7 64 bit 环境下,利用“12 500+12 500”的训练集和大小为“1 000+1 000”的测试集对网络进行训练。
(1)人脸混合算法基于人脸特征筛选相似人脸,换脸得到输出的虚假人脸及换脸脸框。
(2)伪影提取网络对输入的人脸进行换脸脸框预测,并预测损失值。输入中的Label 代表输入脸框为真实(1)或虚假(0)。
(3)伪影检测网络计算输入脸框代表的人脸为虚假的概率,并给出概率损失值,同时输出伪影检测网络对输入人脸的判断Label_NNc。
(4)将伪影提取网络输出的预测脸框损失值与伪影检测网络输出的概率损失值进行线性运算,得到最终的损失值loss,将loss、Label_NNc 反向传播,进行机器学习并开始下一轮的训练。
学习网络框架如图6 所示。

图6 学习网络框架
4.3 测试集测试结果
经过100 轮训练,最终测试正确率高达98%,测试集中部分假脸与真脸测试结果如图7 所示。

图7 测试集中部分假脸与真脸测试结果
表1、表2 展示了训练过程中的训练轮数与准确率和检测效果之间的关系。
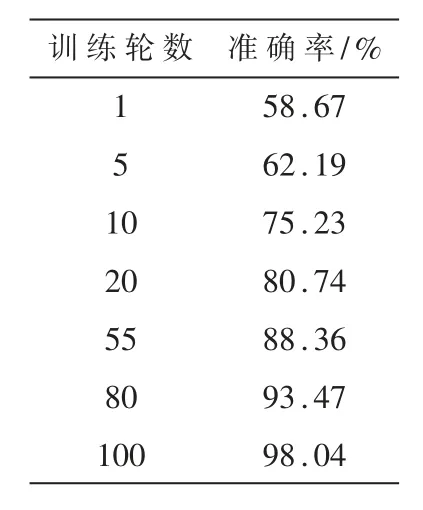
表1 训练轮数与准确率

表2 训练轮数与测试结果
5 结论
多注意力网络伪脸显廓系统(MAD)方案主体为伪影提取网络,主要包含特征提取模块和多注意力模块。前者用于提取目标人脸的面部特征与像素转换,后者用于区分注意力区域和加强特征。伪影检测组件根据伪影提取网络所输出的特征图进行判别并输出预测换脸痕迹。如果目标人脸经过人工智能换脸操作,可以通过本文方法判断其为换脸痕迹。本文方法对虚假人脸的检测在一定程度上保护了个人肖像权、名誉权,可以用于预防新型换脸诈骗以及身份窃取、身份伪造所造成的严重后果。
AI 换脸技术,尤其是近两年刚刚兴起的局部换脸技术,在追究换脸者法律责任时,存在“检测难”和“举证难”的特点[15-17]。本文利用多注意力网络不仅能鉴别一般的人工智能换脸照片,解决了“检测难”的问题,更是能够精确地鉴别局部换脸,保证了整个网络的稳定性,解决了“举证难”问题。本文方法成本低、效率高、可操作性强,拥有广泛的实际应用价值。
