一种基于注意力机制的短临降雨预报方法
2023-03-15曹文南张鹏程贾旸旸
曹文南 张鹏程 贾旸旸
(河海大学计算机与信息学院 江苏 南京 210000)
0 引 言
降雨受地理位置、气候、热力和流场等多因素共同作用而产生,复杂的气象特性使得降雨成为最难预报的天气要素之一[1-2]。强降雨是其中形成最为复杂的一种情况,随着气候不断变暖,强降雨事件发生的概率将不断增加[3]。强降雨天气主要造成滑坡、泥石流和洪水等自然灾害,每年由于强降雨引起的灾害都会导致生命和基础设施的严重破坏和损失[4]。准确及时的降雨预报对农业生产和城市生活工作具有重要作用。
预报降雨的方法主要分为三类:(1) 根据物理定律结合超级计算机求解轨迹方程的NWP方法;(2) 统计学方法;(3) 机器学习方法。传统的NWP方法求解物理轨迹方程极其复杂,需要消耗大量的计算资源和时间,由于一些初始条件和边界条件的不确定性使得预报存在不及时、不够准确的情况。统计学方法如灰色预测模型GM[5]和自回归积分滑动平均模型ARIMA[6-7]等。文献[8]将降雨量作为ARIMA模型的输入,运用信息准则法中的BIC确定模型的阶数,有效预测了城市降雨。这些方法能够对降雨序列进行拟合并做出预测,但是较少考虑气象因子对降雨量的影响。机器学习方法通过更新神经元的参数来学习地理位置、气候条件等物理参数和雨量的关系,使得预报降雨的精度进一步提升。随着人工智能领域的发展,机器学习方法在降雨预测领域取得了很好的效果[9-10],降雨预报中常见的机器学习方法主要包括误差反向传播神经网络BPNN[11]、多层感知器MLP[12]、支持向量机SVM[13]、深度置信网络DBNN[14]和长短期记忆网络LSTM(Long-Short Term Memory)[15]等。文献[16]利用改进的BP神经网络预测城市降雨量,并且分析了不同气象因子对于降雨的影响程度。文献[17]充分挖掘水文时间序列中各隐藏要素的特征,建立了一种有效的基于深度信念神经网络的降雨量预测模型,并以贵州遵义地区的气象数据进行了验证。文献[18]建立了一种动态区域感知的降雨预报网络,并在全国56个地区进行实验证明了模型的有效性。此外,深度学习的广泛应用使得利用雷达回波外推进行临近预报的方法不断有新的进展。文献[19]提出一种卷积长短期记忆网络ConvLSTM预测降雨,该模型由一个编码网络和一个预测网络构成,两个网络都是通过堆叠多个ConvLSTM层形成,减小了外推光流矢量中存在的累计误差,提高了模型预测的准确率。文献[20]提出一种预测递归神经网络PredRNN,该网络核心是一个时空长短期记忆网络ST-LSTM,可以同时对空间和时间信息进行提取和记忆,该方法的优良性能在雷达回波数据集上得到了验证。
目前,基于深度学习的降雨预报模型通常以站点的气象因子和降雨值作为网络的输入和输出,缺少对因子重要性评估及网络特征表现的工具。现有方法对中长期降雨预报(12 h以上)的准确率有一定提升,但对于短临降雨(0~12 h内)尤其是短临强降雨(单位小时内16 mm及以上)样本存在预测不精的问题。针对现有短板,本文提出一种基于含注意力机制LSTM的短临降雨预测模型SRF(Short-term Rainfall Forecasting model),首先计算反映目标站点长期气候状况的标准化降水指数SPI,解决了数据集中少量强降雨样本导致相关信息匮乏的问题,通过随机森林算法筛选出与降雨最相关的气象因子,减少无关信息对预测精度的影响。同时构建带有注意力机制的长短期记忆网络,将因子输入网络中训练得到未来3 h内的降雨量。本文方法关注因子包含的降雨深层语义信息并针对强降雨特性在模型中进行了改进,尝试提高短期降雨预报的准确率,并对模型训练权重进行可视化。实验结果验证了本文方法的有效性。
1 多头注意力机制
注意力机制是模拟人类视觉的注意力演化而来的,能够寻找网络中需要关注的信息并根据信息的重要程度进行加权。注意力机制在自然语言处理、语音识别、图像识别领域都有广泛的应用[21-22]。研究者根据不同需要研究出了各种形式的注意力机制。多头注意力(Multi-Head Attention,MHA)可以有效地在网络中关注多个子空间的信息,并行化计算多次注意力提升网络的训练速度,从多个维度捕捉序列信息的关键信息。多头注意力机制的结构如图1所示。
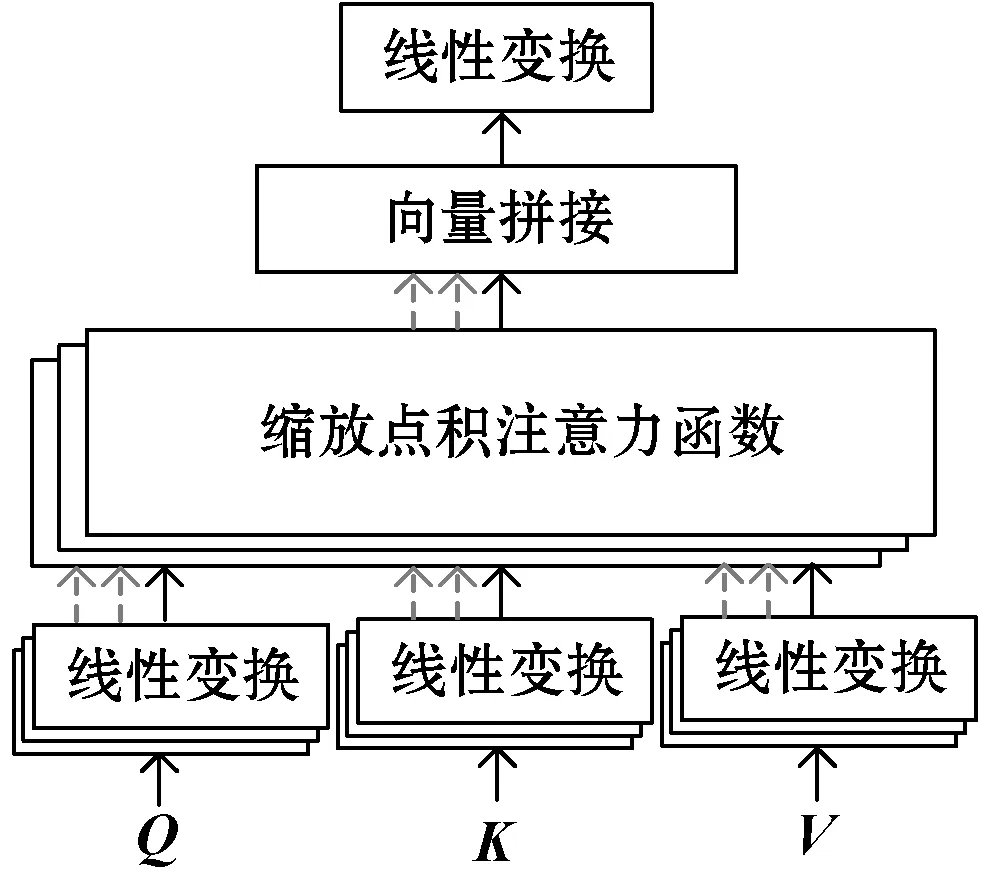
图1 多头注意力结构
目标序列向量为Q,K为键向量序列,V为键向量对应的值的序列,Q、K、V序列经过线性变换后输入到缩放点注意力(Scaled Dot-product Attention,SDA)中进行向量的点积相乘,计算方法为:
(1)
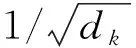
(2)
Z=Concat(head1,head2,…,headh)WO
(3)
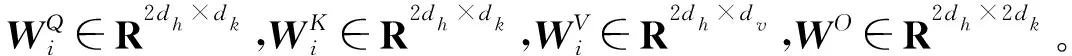
2 长短期记忆网络
长短期记忆网络(LSTM)在循环神经网络(RNN)中增加了多个记忆单元,LSTM的记忆单元解决了原始RNN训练时存在的梯度消失问题和梯度消失所导致的长期依赖问题。LSTM结构形态分为三层,输入层、隐含层和输出层。图2是一个LSTM的结构示意图。
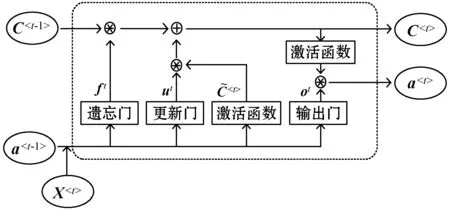
图2 LSTM网络结构
图2中,a
ft=σ(Wf[a
(4)
式中:σ为sigmoid激活函数;Wf为权重矩阵;[,]表示把两个向量拼接;bf为遗忘门的偏置项。
更新门ut确定需要更新的信息和新的加入信息,公式为:
(5)
ut=σ(Wu[a
(6)
式中:WC、Wu为权重矩阵;bc、bu分别为输入节点和更新门的偏置项。更新后新的记忆单元C
(7)
输出门ot经过激活函数后得到最终的输出为a
ot=σ(Wo[a
(8)
a
(9)
式中:*表示元素乘法;Wo为权重;bo为输出门的偏置项;tanh()为双曲正切函数。
3 短临降雨预测预报模型
本文首先计算目标站点的标准化降水指数,利用随机森林算法计算出气象因子与降雨的相关程度,根据重要性动态筛选出与降雨密切相关的因子作为带有多头注意力的长短期记忆网络SRF的输入,预测目标未来3 h内的降雨量。模型建立主要分为三个部分:数据预处理与SPI计算、因子筛选与网络建模、权值可视化与模式对比。SRF模型建立过程如图3所示。
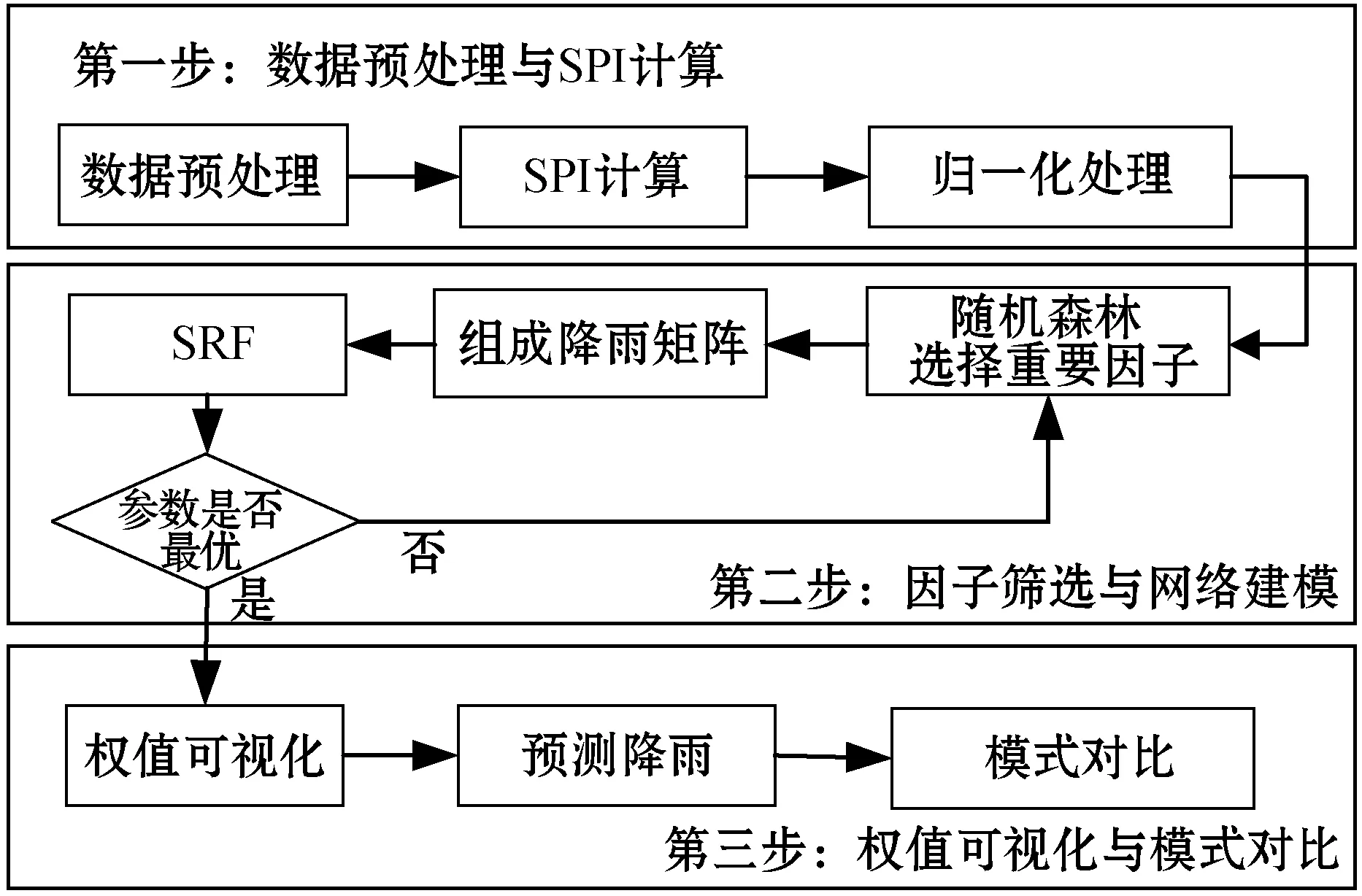
图3 SRF模型建立流程
3.1 数据预处理与SPI计算
在对数据集中的物理参数进行分析和选取后,主要收集了12个气象因子,如表1所示。
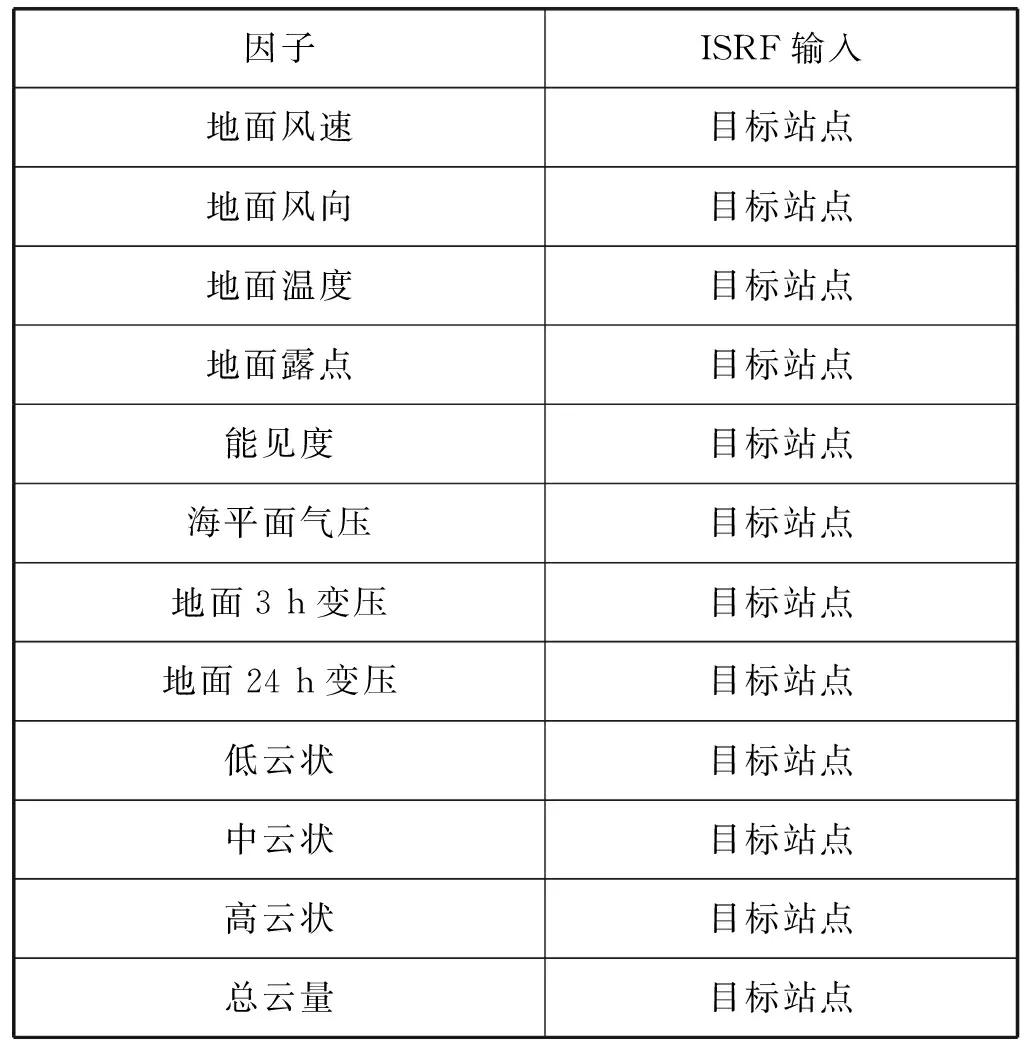
表1 气象因子和模型输入参数
SPI指数是反映地区旱涝时空特征的重要气象参数[23],能够反映目标区域在一定时间尺度内的降雨情况,灵敏表现区域的气候特征,是评估目标区域降雨量或短时强降雨等极端天气情况的重要参考指标,有效提高模型对强降雨特征的敏感程度,解决了数据集中强降雨样本较少导致模型对强降雨特性学习能力较弱的问题。SPI将一段时间尺度的降雨序列服从gamma分布,通过分布概率密度函数推算求得累积概率,最后将累计概率转化成标准正态分布。设某一时段的降雨量为x,则其τ分布的概率密度函数为:
(10)
式中:α为形状参数,β为尺度参数,α与β采用极大似然法估计参数;τ(α)为Gamma函数。
(11)
(12)
(13)
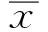
H(x)=q+(1-q)G(x)
(14)
(15)
(16)
式中:q表示降雨量为0的概率;G(x)为在该时间段小于降雨x的概率。
将累计概率H(x)转换成标准正态分布函数,计算待测站点的标准降水指数SPI值。
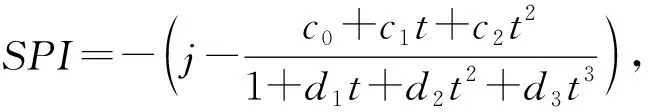
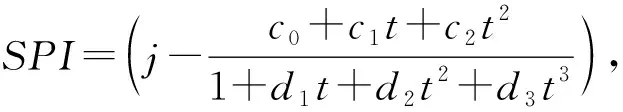
式中:co=2.515 517,c1=0.802 853,c2=0.010 328,d1=1.432 788,d2=0.189 269,d3=0.001 308。
由于各个因子的数值区间处于不同的数量级,归一化可以将数据标准化到[0,1]之间防止某些指标被忽视,影响数据分析的结果。归一化的计算方法如下:
(17)
式中:x*为输入样本归一化后的值,x表示原变量序列中的某个值;xmax和xmin分别为变量中的最大值和最小值。
3.2 因子筛选与网络建模
随机森林算法是一种常用的机器学习算法,能够很好地解决回归和分类问题,它采用自助采样的方法生成众多并行式的分类器,多个分类器的结果通过“少数服从多数”的原则来确定最终的决策结果。由于每一个决策树互不干扰,所以在算法训练时可以高度并行化,随机选择决策树节点对特征进行划分可以有效地对高维数据进行降维训练。随机森林算法的基本步骤如下:
(1) 从训练数据集中随机选出M个样本,然后放回,进行N次取样,每一次取样生成一个训练集,得到N个训练集。M为设定的训练集中的样本数量,N为设定的训练集数量。
(2) 对于每一个训练集,训练一个决策树模型。
(3) 每一个决策树模型持续分裂,直到该节点的所有训练样例都属于同一类。在分裂的过程中保留决策树的完整性,不对决策树进行剪枝操作。
(4) 生成的n棵决策树组成随机森林,按多棵树分类器投票决定每个因子最终的权重大小。
LSTM能够保存长时间降雨序列的历史信息,LSTM中加入多头注意机制强化了模型对于降雨关键信息的敏感程度。SRF结构如图4所示。
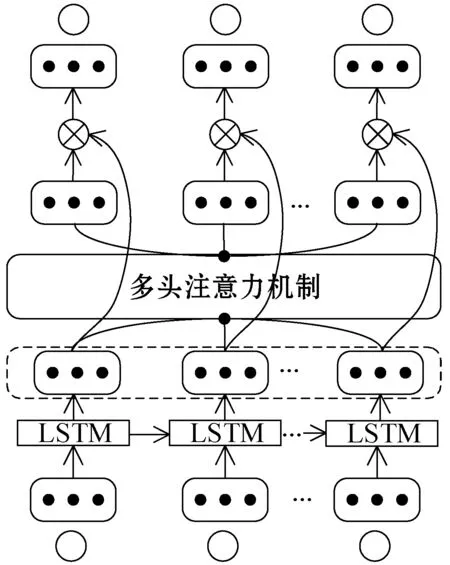
图4 SRF网络结构
输入降雨序列W=(w1,w2,…,wn),输出预测序列Y=(y1,y2,…,yn)。将筛选得到的因子输入SRF网络中,LSTM的输出作为下一层Attention的输入,经过LSTM层得到的向量hn与多头注意力机制形成的向量mt融合形成新的加权向量S,γ、δ作为网络中的两个参数,在模型训练中自动学习。融合公式如下:
S=γ*hn+δ*mt
(18)
为了避免训练过拟合,本文设置学习率为0.1,droupout率为0.5,最大迭代次数设置为5 000,设定h=9,即进行9次多头注意力计算。
3.3 权值可视化与模式对比
深度神经网络又被称为“黑盒”模型,复杂的网络构成和隐含层的多样性使得网络内部结构与模型输出之间的关系难以建立。循环神经网络中加入注意力可以有效提高对于重要因子的关注能力,因子输入网络后,隐含层提取因子中的降雨信息并不断更新神经元存储的有效信息,因子权重变化的可视化表达展示了网络对于特征的动态学习能力,可以观察到不同权重的因子对于结果的影响,当高权重的输入因子对于输出的结果具有决定性作用时,则一定程度上认为整个模型的决策是合理的,帮助判断和理解模型决策结果的有效性。
在模式对比阶段,评估所提模型预测降雨能力优劣的判定标准主要考虑两个方面:预测量级精度和预报概率精度,预测量级精度主要考虑均方误差MSE和绝对误差MAE,误差小可以体现模型在预测量级上的准确性,其计算方法如下:
(19)
(20)
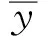
预报概率精度主要考虑TS,中国气象局规定,TS是短期降雨预报能力的计算方法之一。预报概率较高可以体现模型在分类上具有较高的准确性。TS用于表示正确预测的样本比例,包括准确预测降雨量或无降雨量。其计算方法如下:
(21)
式中:N1表示预测正确降雨量的样本数;N2表示预测无降雨的正确样本数;N3表示预测无降雨但实际降雨的样本数;N4表示预测降雨但实际上没有降雨的样本数。Acc用于表示正确预测强降雨样本的比例,是评估模型强降雨预测能力的重要指标,N5表示预测强降雨正确的样本数,N6表示预测无强降雨但实际有强降雨的样本数。Acc计算方法如下:
(22)
4 实 验
4.1 实验设置
本文算法实现在Pycharm平台上完成,计算机CPU为Intel i7- 8750H,内存为16 GB。
本文实验数据包括中国气象局发布的2015年至2017年地面填图数据,该文本数据集按照气象站点排列,可以按照地区编号提取数据。在比较准确率时使用ECMWF(European Centre for Medium-range Weather Forecasts)和JAPAN数值模式2017年发布的逐3 h降雨预报数据。这种数据是按照经纬度排列的格点式文本数据,可以根据经纬度提取相应地区的降雨预报值。实验选择全国92个大型气象站点作为预报对象,这92个地区均有地面气象观测站和雷达探空站。
4.2 因子选取
数据集输入到随机森林中计算各气象因子的权重大小,在单个决策树模型进行分裂时,采用基尼指数选择最好的特征进行分裂。基尼指数的计算公式为:
(23)
式中:训练样本特征的个数为a,分为K个类,样本点属于第k类的概率为pk,实验设置a=12,K=2。因子筛选个数根据模型训练结果进行动态择优,实验选出的9个因子和各因子对于降雨的平均权重如表2所示。
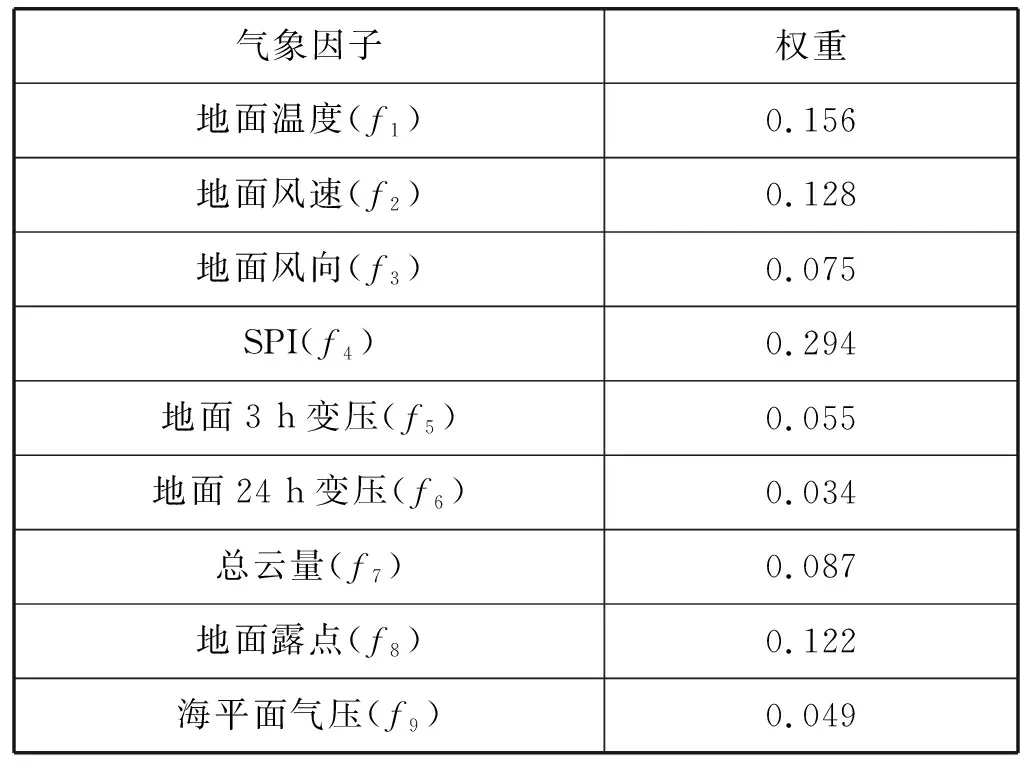
表2 模型输入的气象因子和权重
4.3 模型可视化
输入因子权重在网络中的动态变化解释了模型的迭代学习能力,实验使用热力图对网络中因子的参数变化进行可视化实现。图5(a)至图5(f)为连续六个时刻的因子权重变化图,横坐标f1,f2,…,f9为输入模型的因子,纵坐标t,t-1,…,t-9为历史时刻。色块颜色深浅表示因子权重大小。因子对于降雨影响程度越大,则色块颜色越深。白色代表权重影响最小,黑色代表权重影响最大。
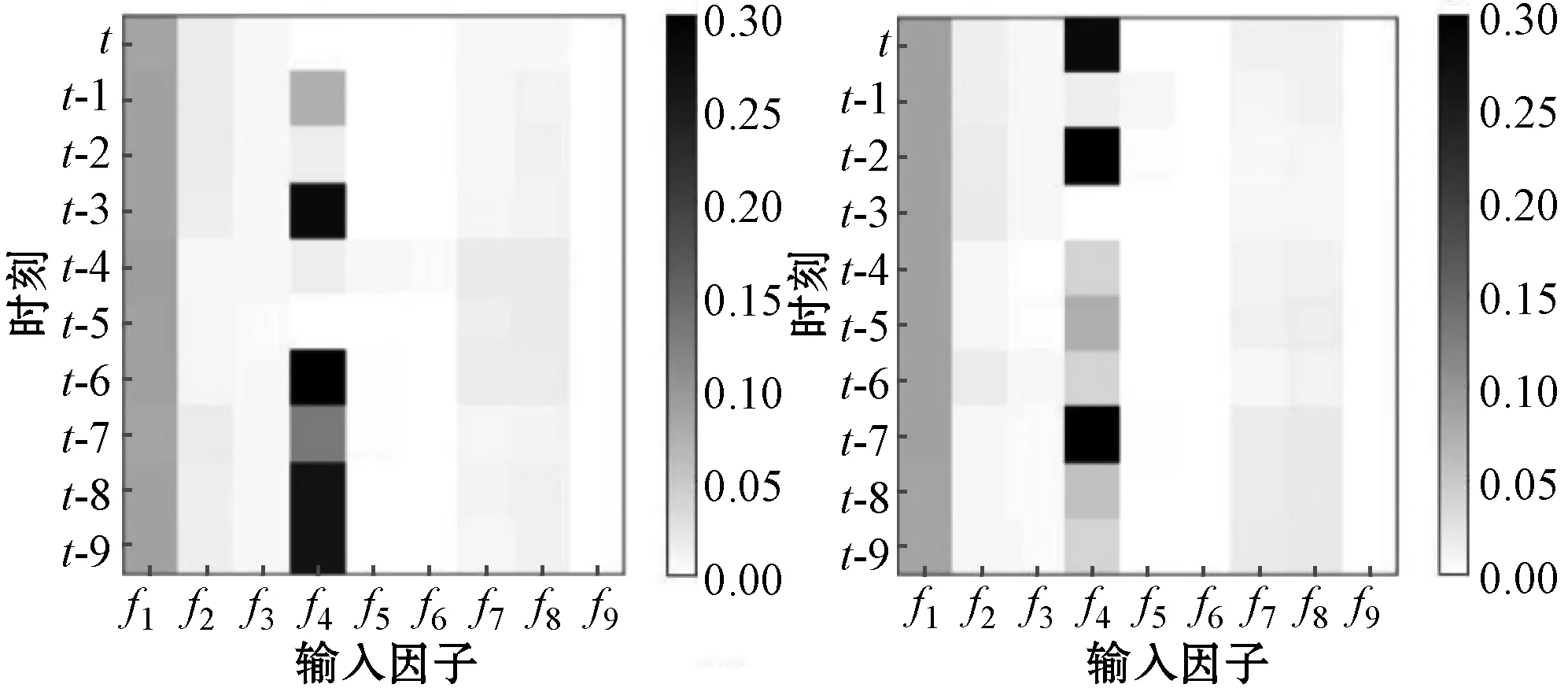
(a) (b)
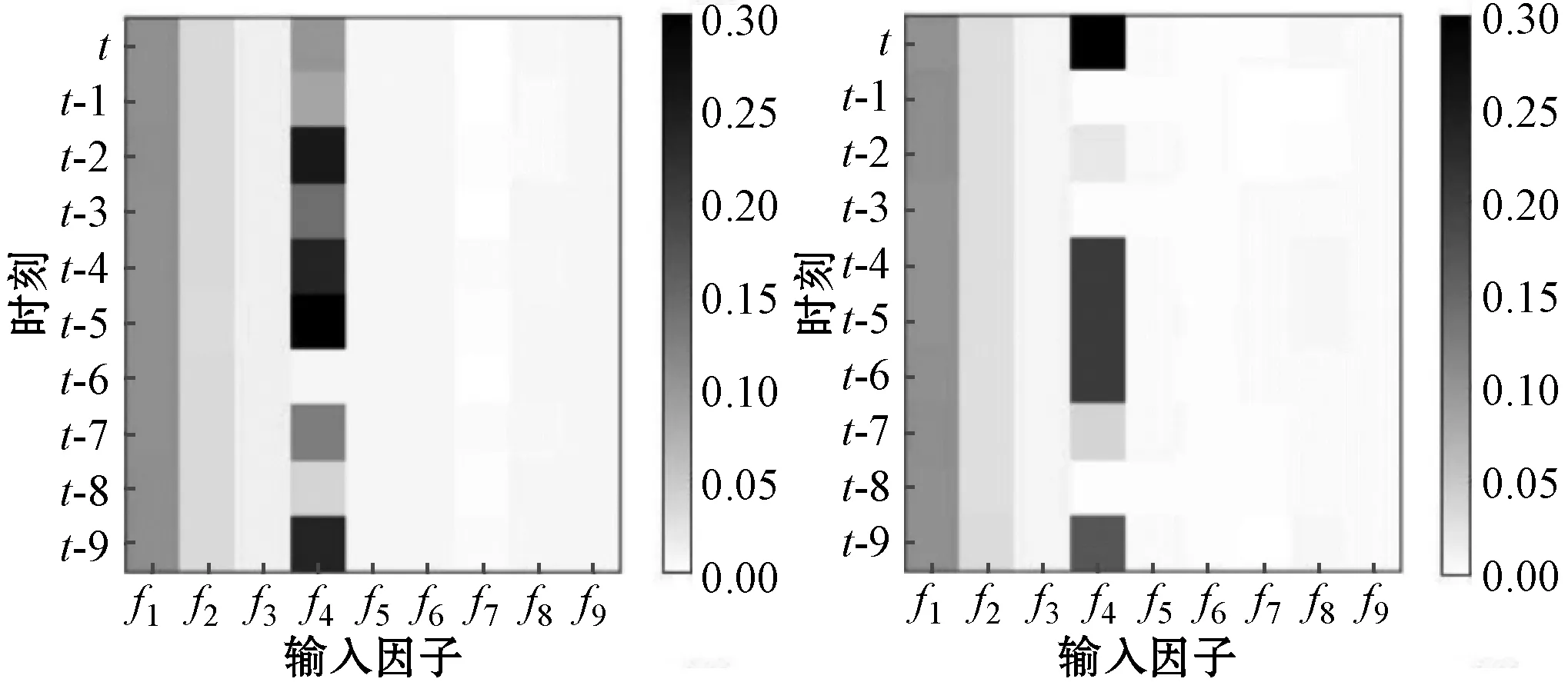
(c) (d)
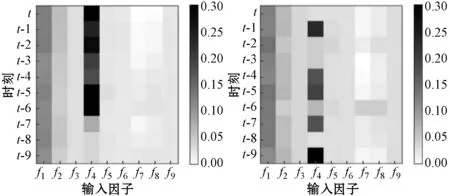
(e) (f)图5 因子权重可视化
可以看出网络在动态训练时因子的注意力权重与使用随机森林算法筛选因子时计算的大小顺序一致,符合模型的预期结果。当使用权重擦除法将权重大小删去其中一个因子进行训练时,预报准确率下降的程度与权重大小呈正相关。因子权重的可视化展示了模型训练时参数的动态变化过程,增加了模型透明度,提高SRF的可理解性。
4.4 实验结果和模型对比
本文将所提模型SRF与不带多头注意力机制的LSTM模型用相同的数据集进行训练,LSTM层使用相同的结构和参数设置。SRF与LSTM的网络损失值与迭代次数的关系如图6所示。当迭代次数达到5 000时,SRF和LSTM的预测结果趋于稳定,带有多头注意力机制的SRF比LSTM有更低的损失值,说明SRF的降雨预测准确率更高,验证了多头注意力机制能够强化LSTM网络对于降雨特性的学习能力,有效提升模型的预测精度。
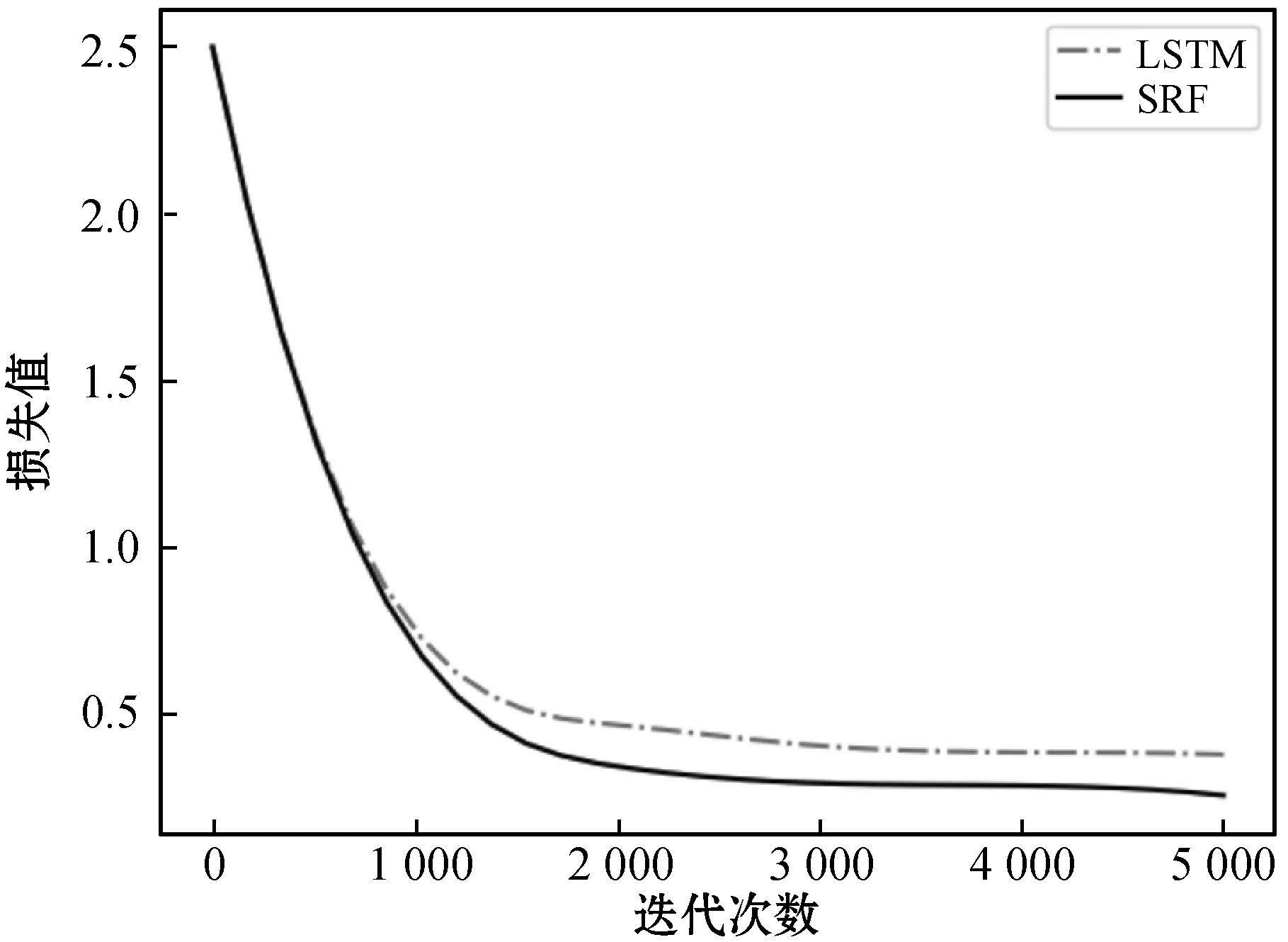
图6 SRF降雨预测
为了验证模型的泛化能力,SRF在全国92个气象站点进行了实验,2015年和2016年数据集作为训练集,2017年数据集作为测试集。将统计模型中的自回归移动平均模型(ARIMA),机器学习模型中的长短期记忆网络(LSTM)、支持向量机(SVM)、多层感知器(MLP)作为对比模型,中国气象局常用的业务预报模型ECMWF、JAPAN也作为对比模型来验证方法的有效性,各模型的结果见表3。
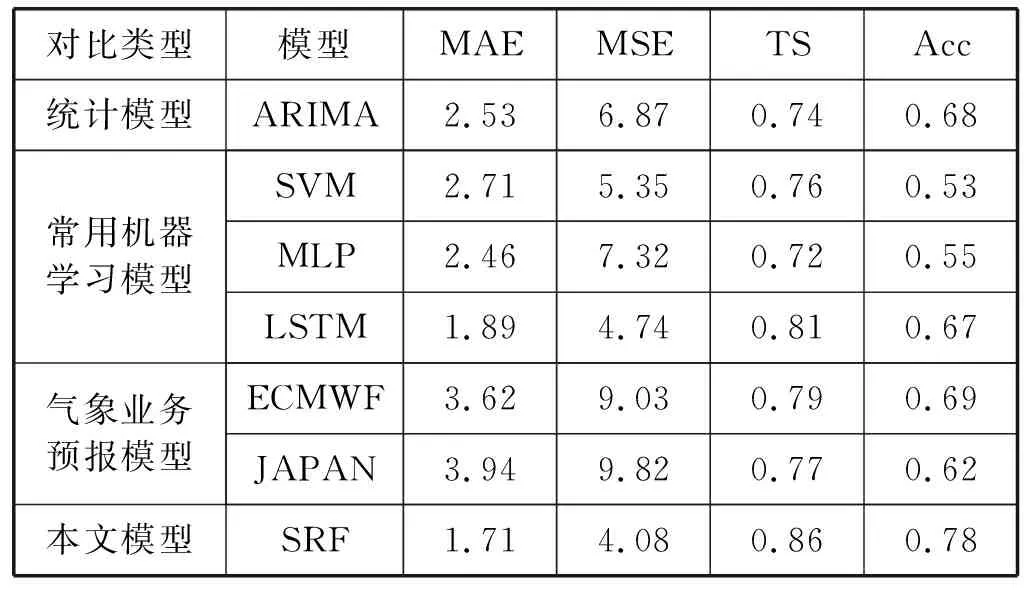
表3 模型对比
SRF降雨预测的准确率为86%,优于其他方法。SRF在短临强降雨预报上比效果最好的气象业务模型ECMWF准确率提高了0.09。结果表明,通过引用相关因子和多头注意力机制,SRF对比传统的机器学习模型和气象业务预报模型在预测量级精度和预报概率精度上均有一定提高。
5 结 语
为了准确预测短临降雨,提高短临强降雨的预测精度,本文提出一种基于注意力机制的短临降雨预报方法SRF,基于气象局数据,利用随机森林算法计算气象因子和标准化降雨指数与降雨的权重,动态筛选出影响降雨最密切的因子作为输入,建立多头注意力机制的长短期记忆网络SRF来学习因子中的降雨信息并根据重要程度进行加权处理,预测得到目标站点未来3 h内的降雨量。结果表明,本文方法可以有效提高短临降雨的预测能力。未来会对雨量进行分级预报,针对性地提高不同量级降雨的预报准确度。
