基于知识图谱的医疗问答系统设计及算法并行化
2023-03-15蔡宇翔王佳斌郑天华
蔡宇翔,王佳斌,郑天华
(华侨大学工学院,福建 泉州 362021)
随着信息时代的繁荣发展,足不出户的网络问诊已经成为了许多人的诊疗首选。但是,现如今的网络问诊还存在着一些问题,如大部分的网络诊疗都是医生利用业余时间作答,并不能保证回答的实时性等。针对这些问题,本文设计了一个基于知识图谱的医疗领域问答系统,并对其相关工作进行了研究。
知识图谱以<实体,关系,实体>的结构来进行表示,相较于传统的关系模型,在知识表示与检索方面具有十分明显的优势[1]。医学领域是知识图谱使用最广泛、最成功的领域之一,在诊断、预防等方面都可以发挥巨大的作用。任燕春等[2]构建了一个新冠肺炎的知识图谱,用于进行新冠肺炎的智能问答。知识图谱作为一种新型的知识表示方式,为问答系统提供了有力的数据支撑。
1 医疗知识图谱的构建
构建知识图谱方式有2 种,分为自顶向下与自底向上。而构建封闭领域的知识图谱一般采用自顶向下的方式[3]。主要步骤是知识的采集度、处理与存储。
1.1 知识的采集与处理
医学领域的数据要求较高的专业性,所以经过认真的对比之后,本文使用爬虫技术对医学类专业网站进行知识的采集。这类数据属于未经处理过的非结构化数据,需要对数据进行清理。
通过使用python 中的urlib 模块进行网页的爬取,并使用正则表达式对网页数据中的网页结构等无关数据进行过滤,再以<字段名:值>的键值对形式进行存储。其中键值对中的字段名是根据网页数据的结构提前设计好的关系类型与属性类型。采集的每条数据以疾病实体为主体,采集疾病的属性。共有7 种实体,分别为疾病、别名、症状、发病部位、科室、并发症和药品。共有6 种实体关系,分别为疾病实体与其他各个实体的关系。疾病实体共有8 种属性,分别为发病人群、是否医保、传染性、检查项目、治疗方法、治疗周期、治愈概率以及治疗费用。
1.2 知识的存储
Neo4j 是使用最为广泛的NoSQL 图形数据库,Neo4j 的最基本单位是实体、关系和属性,可以直观地表示知识图谱。在数据的查询方面,Neo4j 的Cypher查询语句简单易用、查询效率高。将之前处理好的数据使用python 语言通过py2neo 接口导入Neo4j 数据库中,以完成知识图谱的存储。
2 基于Spark 的问句解析算法
Spark 是一种分布式计算框架,相比于基于磁盘的MapReduce,Spark 基于内存,支持将需要重复使用的数据保存在内存之中,不需要反复对磁盘进行读取、存储操作,减少了数据加载耗时,可以有效提高迭代计算的能力,保证了计算的实时性。RDD(Resilient Distributed Dataset,弹性分布式数据集)是Spark 的核心概念,是一种分布式的数据结构,主要使用它来进行数据的分布式存储与计算。
问答系统通常有语义解析和模板匹配2 种方法,语义解析是将输入的问题转换为让知识库可以读懂的逻辑形式,再进行查询。模板匹配方法较为常用,通过实体抽取等自然语言处理技术将问句转化为三元组,与对应的查询语句模板进行匹配,再使用知识图谱进行查询[4]。对于用户输入的问句,先进行过滤停用词等预处理,通过相似度计算来抽取问句中的实体,再使用文本分类方法来进行问句的意图识别,最后匹配到预先设置好的查询模板中,在知识图谱中搜索并返回答案。
2.1 基于Spark 的实体抽取算法
为了更好地抽取问句中的实体,本文结合Spark计算框架,设计了基于相似度的实体匹配算法。Spark计算框架是基于内存计算,极大地减小了磁盘IO 开销,可以大幅度提高处理效率。该算法利用相似度的计算,将问句中的实体与医疗实体库中的实体进行匹配。相似度的计算主要使用最小编辑距离和词向量的余弦相似度进行度量。最小编辑距离是指将字符串A改写为字符串B 时至少需要多少次的编辑操作。单词的插入、替换和删除字符操作即为编辑操作。编辑距离的相似度计算公式为:
式(1)中:SED为字符串A 转换为字符串B 需要经过的编辑次数;MAX(LA,LB)为字符串A 和B 中较长的字符串的字符数。
该方法便于理解,易于实现,同时也可以很好地在字符层面度量相似度。但是基于编辑距离的相似度计算方法对于2 个同义词,例如“开心”和“快乐”,并不会有很好的效果,所以在该方法的使用上结合Word2Ⅴec 词向量。Word2Ⅴec 是MIKOLOⅤ提出的一种基于神经网络的概率模型[5],对比传统的高维向量,可以简化计算,且不会引起维度灾难。
Word2Ⅴec 分为skip-gram 和CBOW 两种方式,在本文的词向量训练中使用的是skip-gram 模型。CBOW模型是通过前后的n个词来预测中心词出现的概率,而skip-gram 模型则是通过中心词来预测前后的n个词。词向量的余弦值可以反映词语在语义层面的相似度,计算公式为:
式(2)中:a、b为字符串A、B 的词向量组;ai与bi为其中的第i个向量。
将最小编辑距离和词向量的余弦相似度相加求平均,作为实体间的相似度。本文使用Spark ML 机器学习算法库进行Word2Ⅴec 词向量的训练,并在Spark 上实现了相似度算法的并行化。
首先分别生成问句实体与医疗实体库中实体的Word2Ⅴec 词向量的RDD,并将其进行JOIN 操作,逐一计算相似度,进行排序,最后输出相似度最高的医疗实体。经过测试,该方法相较于分别使用最小编辑距离与词向量的余弦相似度,拥有更好的效果。
2.2 基于Spark 的意图识别算法
对于用户输入的问题,经过实体抽取模块后,还需要判断问句的意图。本文设计了7 种问句类型,通过意图识别分类器将问句匹配到相应的问句类型中。7种问句类型包括查询疾病、查询症状、查询治疗方法、查询检查项目、查询所属科室、查询治愈率以及查询治愈周期。在分类任务常用的机器学习算法有支持向量机、朴素贝叶斯等。其中支持向量机具有健壮性好、正确率高等优点,被广泛运用在文本分类、语音识别等分类任务中[6]。因此,本文使用Spark ML 机器学习库的支持向量机方法进行分类,利用并行化技术提高计算效率。在得到问句的实体信息与意图后,使用提前设置好的模板,将问句转换为查询语句,在Neo4j数据库中进行查询,得到答案。
3 问答系统测试
3.1 问答系统的测试与结果分析
本文使用精确率、召回率和F1 值作为评价指标。这些也是自然语言处理任务中被广泛运用的指标。
在实体抽取中,在中文医学问答数据集cMedQA中任意选择了300 条问句,对其中的实体进行手工标注。分别对基于编辑距离、基于词向量和两者相结合的方法进行对比测试,得到的结果如表1 所示。可以看出,两种方法结合可以提高实体抽取算法的准确度。
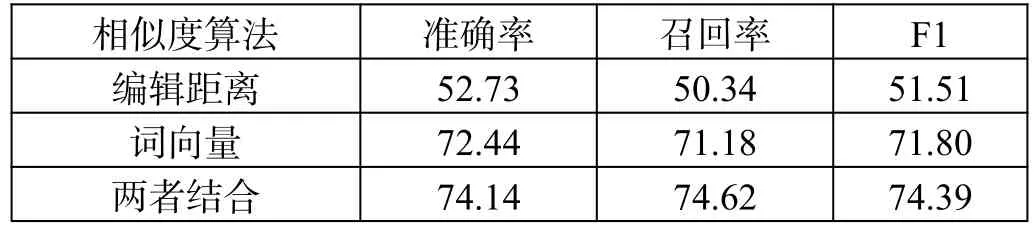
表1 实体抽取效果对比(单位:%)
对于意图识别问题,本文先使用Spark ML 库中的Word2Ⅴec 词向量工具将问句转化为向量形式,再训练分类器对其进行分类。在中文医学问答数据集cMedQA 选择了符合本文问句类型的1 400 条问句,其中每个类别为200 条,训练集与测试集比例为4∶1。对2 种算法分别进行测试,结果如表2 所示。可以看出,支持向量机的F1 值要高于朴素贝叶斯,所以在意图识别模块中,本文使用支持向量机进行分类。

表2 分类效果对比(单位:%)
3.2 问答系统评估
为了验证本系统的效果,需要进行问答功能的测试。本文在中文医学意图数据集CMID 中选择了300条适合该问答系统回答范围的问句进行测试。每次从数据集中随机选择100 条问句进行测试,共进行3 组测试。在测试结果中,每组平均返回了83.3 个回答,其中74 个回答正确结果,得到了74%的准确率与88.8%的精确率,说明该系统具有一定的实用价值,可以回答一些简单的医疗问题。
4 总结
本文通过知识采集、处理、存储等步骤,构建了一个专业的医学类知识图谱,并使用了结合编辑距离和词向量的相似度算法进行实体抽取,同时使用支持向量机分类器识别问句的意图。并结合Spark 分布式计算框架,实现问句解析算法的并行化。但是该问答系统还存在着一些缺陷,例如无法进行复杂关系问题的问答以及知识图谱的规模需要扩大。
