双通道立体图像质量评价方法的研究
2023-03-15王杨贾曦然隆海燕
王杨,贾曦然,隆海燕
(1.河北工业大学电子信息工程学院,天津 300401;2.河北工业大学天津市电子材料与器件重点实验室,天津 300401)
立体图像相关技术发展日益迅速,但在采集、传输、存储立体图像过程中难以避免地引入失真,因此,有效地评估图像失真程度受到研究学者广泛关注。
Kang等[1]提出了一种基于浅层卷积神经网络的无参考图像质量评价算法,为日后研究基于卷积神经网络的立体图像质量评价算法做出了开创性贡献。随后,学者们将视觉特性与卷积神经网络引入立体图像质量评价中。Zhou等[2]提出了DFNet结构,获取并融合左、右视图单目特征,从而得到双目深度特征。Shi等[3]基于配准失真表示构建了多任务卷积神经网络模型,同时进行立体图像质量预测与失真类型识别。Yan等[4]构建权值共享模块联合提取左右视图特征,并设计融合模块聚合多层次特征。Feng等[5]基于多层级交互的卷积神经网络模型获取双目视差与融合信息。Li等[6]通过端到端的多损失约束卷积神经网络获得立体图像质量评价分数。Meng等[7]设计了“where”分支和“what”分支分别处理立体深度、形状和颜色等信息。Si等[8]设计了StereoIF-Net网络模拟人类双目互动与双目融合机制。Li等[9]考虑到人类视觉注意机制,构建DPCNN模型提取左、右视图及视觉显著性图像特征,预测图像质量。Messai等[10]利用融合图的3D显著性图像块进行立体图像质量评价。贠丽霞等[11]设计了2D-卷积神经网络(convolutional neural networks,CNN)和3D-CNN双通道结构,基于融合图、和图像与差图像特征获取质量评价值。
人眼观看图像时,75%来自清晰度,25%来自感知体验。因而,学者们引入视觉显著性、深度感知特性和双目竞争机制等力求获得更符合人眼感知特性的质量评价方法,但上述算法均利用单个卷积神经网络模型提取特征,其权重的不变性导致所得特征间存在相似性,并在一定程度上忽略了视觉语义感知对质量评价值的影响。视觉心理学研究表明视觉平衡特性与人类视觉感知息息相关,其重要性不容忽视[12],然而其在立体图像质量评价中的应用少有报道。
基于上述质量评价方法以及深度特征提取思想的启发,构建双通道网络评价立体图像质量,度量质量感知程度的同时引入视觉平衡特性。该算法在对称失真与非对称失真情况下均具有较高的准确性,一定程度上克服了浅层立体图像质量评价算法的不足。
1 双通道立体图像质量评价模型
1.1 图像质量与人眼的视觉平衡特性
视觉心理学和格式塔心理学认为图像的视觉观测效果是大脑皮层追求视觉平衡的体现,而视觉元素的构图原则与视觉平衡密切相关。格式塔心理学提出视觉元素中均存在着大小、方向不同的“知觉力”,从而构成“视觉场”。当画面构图满足视觉元素的“知觉力”到平衡中心“力距”处于平衡状态时可产生视觉平衡效果[13],常用的构图原则如图1所示。其中,三分法构图是艺术、美学和设计等领域最基本的构图原则并被应用于图像质量评价领域[14],当语义主体位于三分点或三分线时,更加契合视觉感知习惯,如图2所示。

图1 常用构图原则

图2 三分法构图图像
提取含有美学构图技巧的语义特征衡量图像视觉平衡效果以模拟人类视觉感知及审美思维。语义特征由全局视角出发较好地表达了图像的内容和属性信息,如场景类型和位置结构等,是最接近于人类对图像视觉理解与整体感知的高层次特征。引入双目语义特征既可以表征构图信息,又可以提高立体图像质量评价的鲁棒性[15]。
1.2 算法网络框架
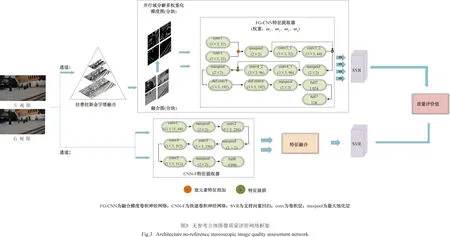
算法网络框架如图3所示,该网络包含两个通道:质量感知特征通道(quality-aware feature channel,QFC)、语义特征通道(semantic feature channel,SFC)。双通道网络基于支持向量回归构建主客观图像质量评价值的关系映射,以此得到图像最终的质量评价值。
1.2.1 构建融合图
立体图像由左、右视图构成,大脑视觉皮层通过获取其视差信息产生深度感知。基于拉普拉斯金字塔[16]构建融合图以模拟视觉处理过程,图像金字塔从多尺度、多分辨率的角度来表达图像,同时其包含了图像的各频段信息,对不同频段图像单独融合可优化融合效果。其主要步骤如下。
步骤1基于高斯金字塔,由下至上将各层图像与经内插放大后的上层图像作差得到该层的拉普拉斯分解图像,进而得到左、右视点图像的拉普拉斯金字塔序列。
步骤2将左、右视图的拉普拉斯金字塔序列{IL0,IL1,…,ILn}、{IR0,IR1,…,IRn}逐层融合获取融合图,如式(1)所示,底层图像为IL0、IR0,顶层图像为ILn、IRn。
CI(x,y)=ωL(x,y)IL(x,y)+
ωR(x+d,y)ΙR(x+d,y)
(1)
式(1)中:CI为融合图;IL和IR分别为左、右视图;d为视差信息;ωL和ωR分别为左、右视图的融合系数。
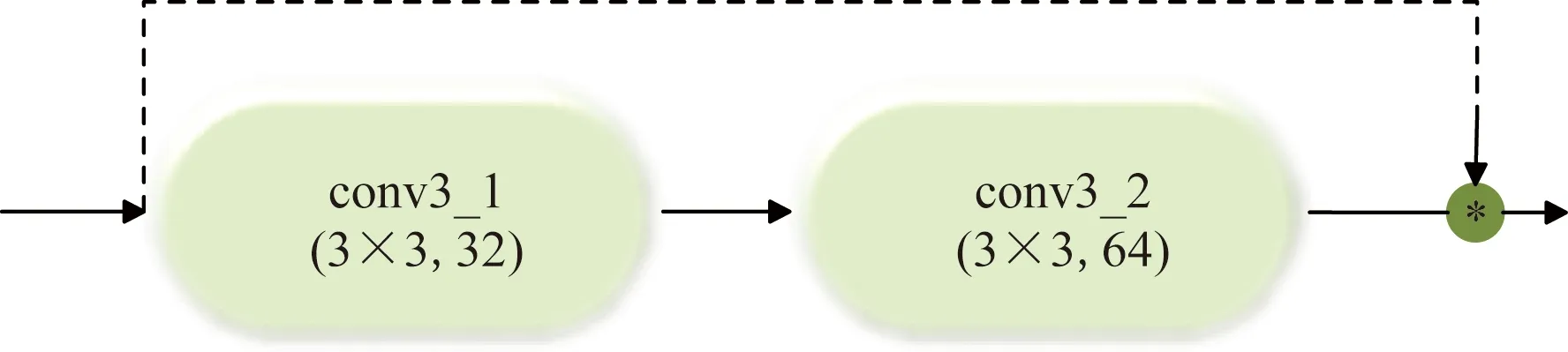
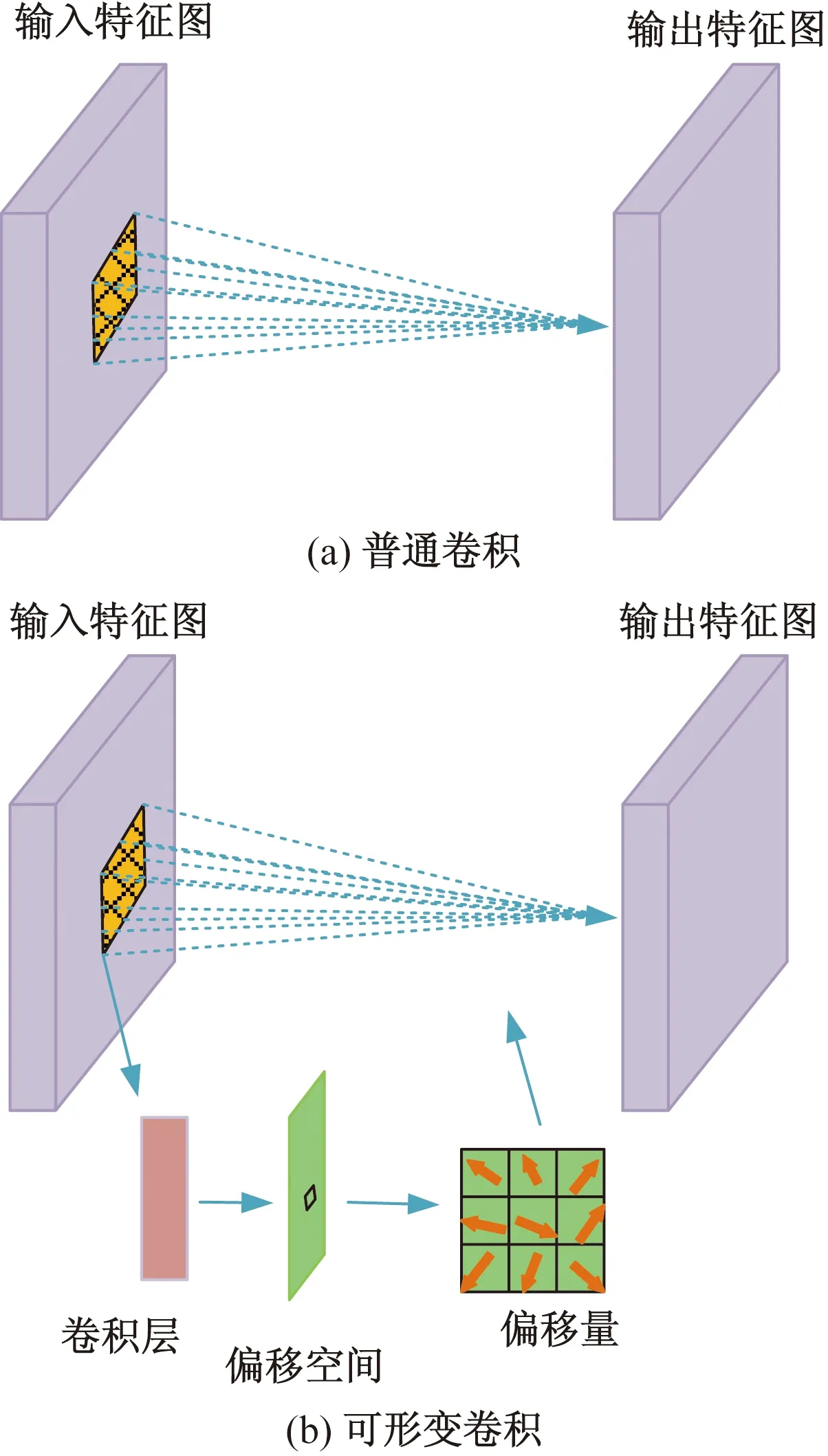
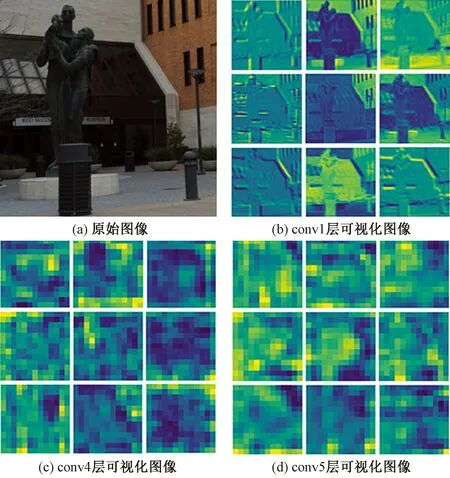
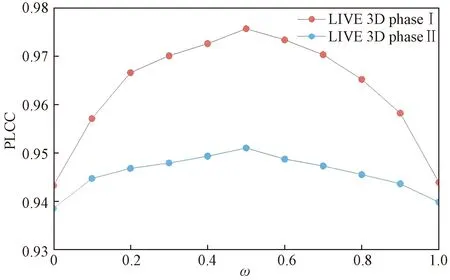
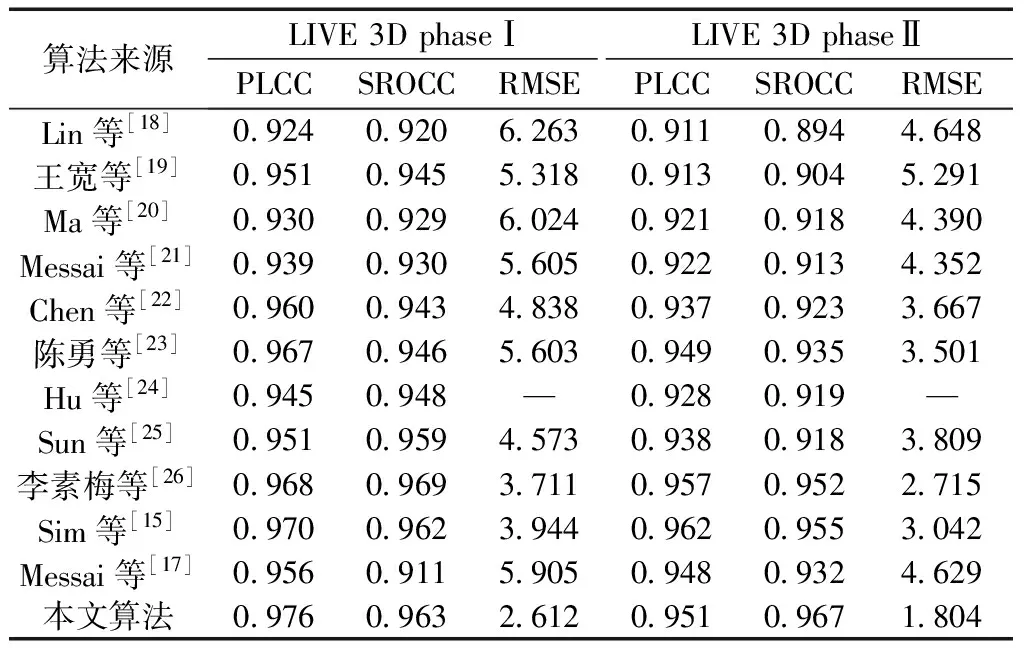
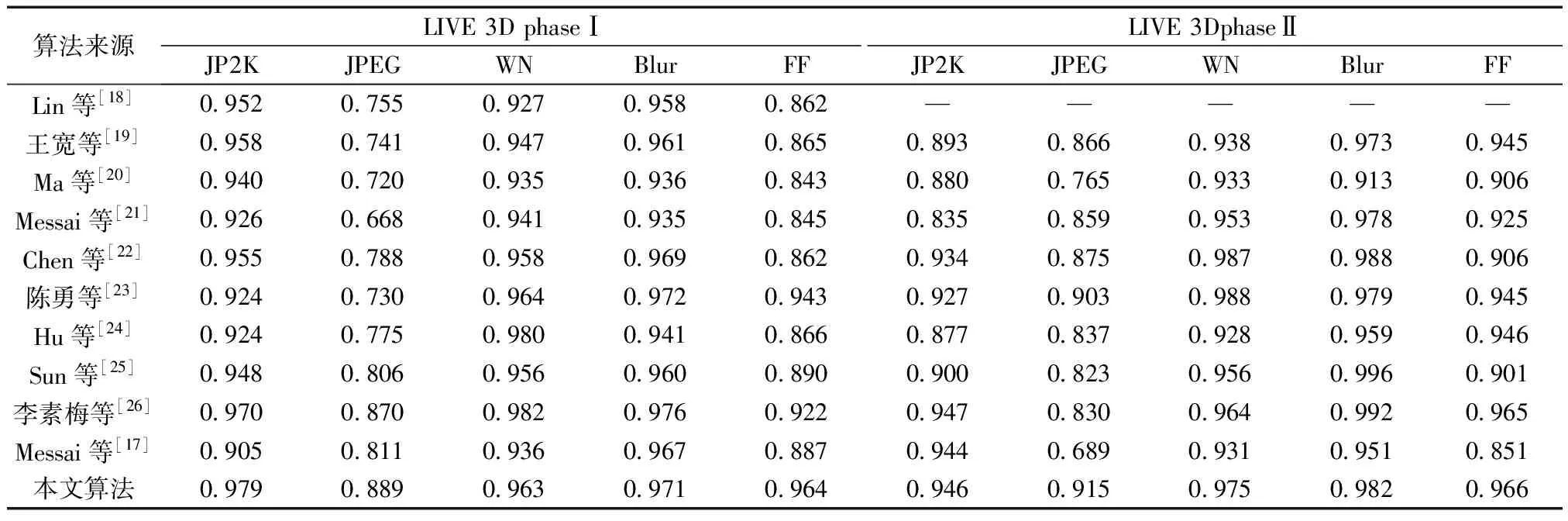
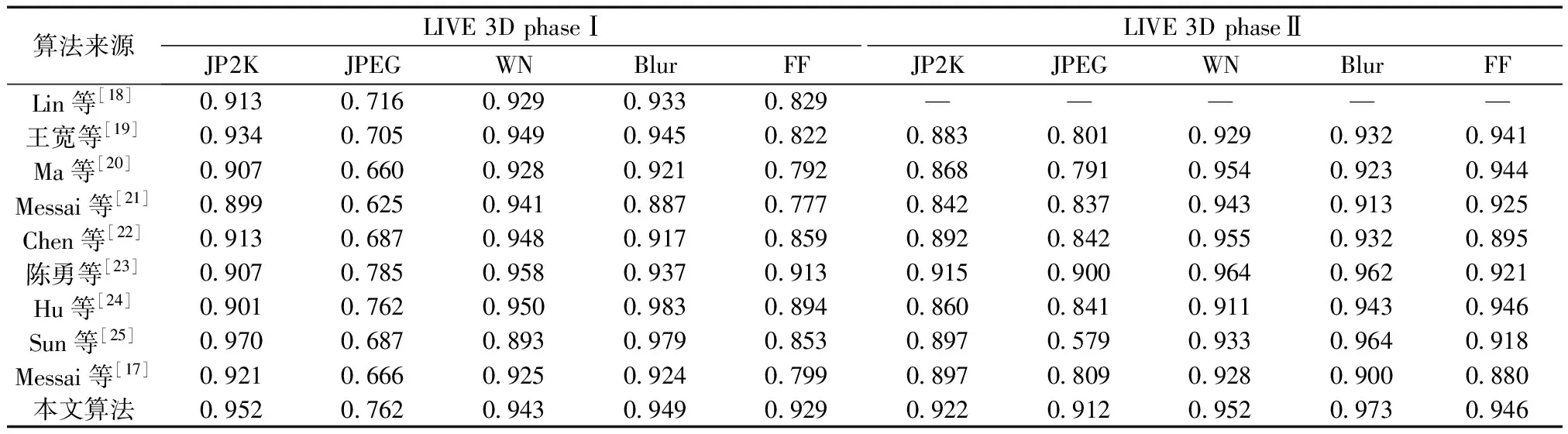
为体现左、右视图的局部纹理差异,采用平均梯度GLn确定顶层图像ILn融合系数ωLn,如式(3)所示。双目视觉中存在双目竞争机制,立体图像感知质量受左、右视图中包含更多信息的视图支配,因此采用区域能量ELm确定其他图层ILm(0 (2) (3) 式(3)中:M、N为左右视图图像大小;ΔIx、ΔIy分别为像素f(x,y)在x、y方向上的一阶差分。 (4) 式(4)中:ELm为区域能量;i、j为图像的第i行与第j列;μ为权值矩阵。 同理可得顶层图像IRn融合系数ωRn与其他图层IRm融合系数ωRm。 如图4所示,基于拉普拉斯金字塔所构建的融合图在保留了双目视图原始细节特征信息的同时,亦包含了视差信息,有利于后续的双目质量感知特征提取。 图4 立体图像的左、右视图与融合图 1.2.2 质量感知特征提取 融合图的多个局部区域均具有丰富的特征信息,单个卷积神经网络倾向于提取图像的一般全局特征而导致其对失真区域分布不均匀图像的细节特征获取不充分[17]。为突破上述局限性,采用并行域分解多权重化策略提取图像特征。在选取域分解方式时,考虑到图像中多个视觉元素等效抽象为单个视觉元素的“重心”在视图中心位置即可达成视觉平衡[13],因此,为使得各部分视图的视觉心理“不失重”,将融合图与梯度图分割为局部区域,分块训练特征提取网络,得到4个权重不同的FG-CNNωi(fusion gradient-convolutional neural networksωi,FC-CNNωi)网络,其中i=1,2,3,4从而获取更加丰富的融合图细节特征。 在人脑视觉感知的信息流中,边缘特征可以较好地表征几何信息,于是基于融合图利用Prewitt梯度算子获取其梯度域图像,将二者同时输入至FG-CNN以量化表示边缘特征。但随着网络层次的加深,边缘特征逐渐减弱,为缓解此问题,FG-CNN中引入级联残差模块,复用浅层图像特征的同时,减小网络训练时因梯度过小而无法优化参数的问题,图5为级联残差模块结构。 图5 级联残差模块结构 FG-CNN包含6层传统卷积层、2层可形变卷积层、4层最大池化层、2层全连接层。卷积层均由多个3×3大小的卷积核堆叠而成,填充处理保持图像块尺寸恒定。可形变卷积层可以有效地提升网络对几何物体的建模能力,通过在传统卷积的采样点上添加偏移量使得采样网格可以自由形变,将采样点集中在更加重要的目标区域,打破了传统卷积的规则网格约束,其偏移量由附加卷积层从特征图中学习得到,普通卷积与可形变卷积计算过程示意图如图6所示。 图6 普通卷积与可形变卷积计算过程示意图 有监督学习训练过程中,考虑到参数优化时存在振荡现象以及随机梯度下降法需要人为设置参数的局限,采用可以自动更新学习率的Adam优化算法加快网络收敛速度,并选用平均绝对误差(mean absolute error, MAE)作为损失函数以量化预测值与训练标签间的差异,其表达式为 (5) 式(5)中:Bp为一个批尺寸大小的图像数量;fθ1(pi)为图像块pi经参数为θ1的网络模型预测值;qi为图像块pi的训练标签。 1.2.3 视觉平衡特征度量 QFC基于局部图像块提取质量感知特征,保留图像原始细节信息,但造成了整体构图信息的缺失,因此,增加SFC获取语义度量值以衡量图像视觉平衡效果对人类视觉体验感所造成的影响。 CNN-F(convolutional neural networks-fast)网络经过ImageNet图像数据集训练后具有良好的语义特征提取能力[15],选用其作为语义特征提取工具,图7为CNN-F网络卷积层可视化结果。 由图7可以看出,随着CNN-F网络层次加深,所得图像特征逐渐由低级到高级,由具体到抽象。其中,深层conv5卷积层倾向于提取图像高层次语义特征信息。利用CNN-F网络所得到的左、右视图单目语义特征,经加权后合成为双目语义特征。 图7 CNN-F网络卷积层可视化结果 fB=ωsfL+(1-ωs)fR (6) 式(6)中:fL和fR分别为左、右视图单目语义特征;fB为双目语义特征;ωs为权重系数,ωs设置为0.5,以平衡左、右视图的语义特征。 图8给出了视觉重量的效果图。其中,图8(a)~图8(c)中主体对视觉注意力吸引较大,所占视觉“重量”较重,而图像背景占据面积大但其视觉“重量”较轻,当主体位于三分线位置时产生视觉平衡效果,契合美学标准,此时语义度量值较高;图8(d)不满足视觉平衡条件,其语义度量值较低,但三幅图的语义度量值均接近于主观质量评价分数,说明语义度量值能够较好地衡量人眼视觉感知特性。 qs和DMOS分别为语义度量值、主观质量评价分数 1.2.4 质量分数预测 将图像的主观评价值分别与质量感知特征向量集、语义特征向量集作为支持向量回归(support vector regression, SVR)的输入,构建从特征域到分数域的映射关系,从而获取质量感知值qq与语义度量值qs,对qq与qs加权后得到立体图像质量评价分数q,可表示为 q=ωqs+(1-ω)qq (7) 式(7)中:ω为权重系数,多次迭代得最佳值。 本文算法在LIVE 3D phase Ⅰ与LIVE 3D phase Ⅱ立体图像库测试性能。LIVE 3D phaseⅠ包含365幅对称失真立体图像对和20幅原始参考立体图像对,失真类型分别为JPEG压缩、JP2K压缩、加性白噪声(WN)、高斯模糊(Blur)和快速衰落(FF)。LIVE 3D PhaseⅡ包含8幅原始参考立体图像对、120幅对称失真立体图像对和240幅非对称失真立体图像对,其失真类型与LIVE 3D phaseⅠ相同。将所有样本图像按照8∶2的比例随机划分为训练集和测试集。 为了有效评估算法性能,采用皮尔逊线性相关系数(PLCC)、斯皮尔曼阶相关系数(SROCC)、均方根误差(RMSE)作为客观评价指标。其中,PLCC衡量算法预测值与DMOS值的线性相关性,SROCC衡量算法单调性,RMSE衡量算法预测值与DMOS值之间的偏差。PLCC与SROCC值越接近于1,RMSE越接近于0时,证明算法性能越好。 为验证网络的有效性,从双通道结构、拉普拉斯金字塔融合、并行域分解多权重化策略三方面考虑设计了消融实验,利用PLCC值衡量网络性能,如表1所示。 表1 不同情形时网络性能 对比Q1、Q2和Q可知,与单通道网络性能相比,双通道网络所得PLCC值分别提升了3.3、3.2、1.2、1.1个百分点,具有更高的准确性,其可能的原因在于:对于QFC,单个卷积神经网络训练后所得权重值使得网络倾向于提取整幅图像的一般全局特征,而本文采用4个权重不同的网络分块提取特征,丰富了质量感知特征集,但分块提取特征策略导致网络对图像全局语义信息获取不充分;对于SFC,CNN-F网络具有输入图像尺寸限制,将数据集图像大小均缩放为224×224×3,图像经缩放后损失部分质量感知特征,但其全局语义信息保存较为完整。综合上述,结合视觉平衡特性采用双通道网络集成立体图像的质量感知特征信息和高层次语义特征信息,从而提升算法性能。 对比Q3和Q可知,相较于小波融合算法,利用拉普拉斯金字塔进行融合处理时效果更佳,并且小波基的选择对小波融合效果影响较大,其普适性略差。对比Q4、Q5和Q可知,基于四分块并行域分解多权重化策略时网络性能更佳,其PLCC值分别提升了1.4、0.9、0.7、0.4个百分点,未经域分解处理时,同权重化网络所得特征间存在相似性,网络性能略差,相较于二分块域分解方式,四分块处理能够将特征集更大程度地丰富化,从而提升算法的准确性。考虑到平衡图像的全局性与网络复杂度,未将图像继续细分。 为确定式(7)中质量感知值与语义度量值各自的权重系数,将ω以0.1为间隔由0增加至1,其结果如图9所示。 图9 不同ω值对PLCC的影响 由图9可知,预测性能随着ω的增加首先提高,然后有所降低,当ω=0.5时,预测值与主观评价值保持高度线性相关,网络预测准确性能最佳。 为验证本文算法的有效性,将算法与其他九种算法在LIVE 3D立体图像库上的实验结果比较分析。其中,文献[18-19]为全参考立体图像质量评价,文献[20]为半参考立体图像质量评价,其余均为无参考立体图像质量评价。上述算法可按照特征提取方式再划分,文献[18-23]为手工特征提取算法,其余均为深度学习特征提取算法。整体性能实验结果如表2[15,17-26]所示,不同失真类型下的实验结果如表3[17-26]、表4[17-25]所示,其中最佳结果被加粗显示。 表2 LIVE 3D立体图像库整体性能比较 表3 不同失真类型的PLCC值 表4 不同失真类型的SROCC值 由表2可知,本文算法在LIVE 3D phaseⅠ和LIVE 3D PhaseⅡ下取得了优异成果,PLCC与SROCC值均超过0.95,RMSE较接近于0。同时可以看出,相较于手工特征提取算法,深度学习特征提取算法预测性能更佳,证明了其多层级交互结构能够较好地模拟视觉感知系统。与其他深度学习特征提取算法相比,Hu等[24]、Sun等[25]和Messai等[17]均基于图像块获取局部特征,忽略了图像全局语义信息的完整性,Sim等[15]考虑到了全局语义信息,但网络分离式提取左右视图特征,未能体现双目视觉的交互性,并且其质量感知特征经由手工提取特征方式获得,未能较好地模拟视觉感知系统。而本文算法综合考虑图像的局部与全局信息,梯度图的引入和结合级联残差模块、可形变卷积所设计的FG-CNN特征提取器使得模型所得质量感知特征更加精细化,取得了更佳的预测效果,验证了所提算法的合理性。 由表3、表4可知,算法在JP2K、JPEG、FF失真类型下性能表现较为突出。在LIVE 3D phaseⅠ中WN失真与LIVE 3D phaseⅡ中WN、Blur失真情况下PLCC、SROCC值虽然未达到令人满意的程度,但较接近于最佳值;仅在LIVE 3D phaseⅠ中Blur失真所得SROCC表现略差。准确地评价非对称失真立体图像质量相对困难,只有更加符合人眼视觉认知机理的算法才能获得良好的结果[26],而本文算法在对称失真和非对称失真情况下均展现出较好的效果,并且算法未因改变失真类型而产生较大的性能差异,可以较好地模拟人类视觉感知过程。为更加直观地展现预测值与DMOS值间的相关程度,绘制了两者的散点图,如图10所示。可以看出,散点紧密分布在拟合曲线周围,表明了预测值与DMOS值的较高一致性。 图10 立体图像质量评价值和DMOS值散点图 为验证算法的时间复杂度,对比不同算法在LIVE 3D phaseⅠ的平均运行时间,结果如表5[27-28]所示。实验环境为:11th Gen Intel(R)Core(TM)i7-11800H CPU;NVIDIA RTX3050 GPU;16 GB RAM;Python3.8。 由表5可知,本文算法运行时间明显少于Si等[27]、Kim等[28],具有运行速度较快的优势。综合上述,算法所得预测值与主观评价值具有较强的相关性并且其时间复杂度较低。为准确预测非均匀失真图像质量,捕捉立体图像局部特征信息和全局语义空间信息,基于并行域分解多权重化策略得到权重不同的卷积神经网络分块提取融合图与梯度图特征,从而获取含有视差信息的质量感知特征,通过语义特征度量人眼视觉平衡特性使得算法更加符合人眼视觉认知机理。此外,多数基于深度学习的立体图像质量评价算法仅依靠小型数据集训练导致模型难以获取最佳性能,而本文算法通过立体图像库训练QFC、ImageNet数据集训练SFC,克服了数据集规模有限而导致模型训练不足的问题。 表5 平均运行时间比较 提出了一种双通道无参考立体图像质量评价算法,获取图像质量感知特征的同时,结合视觉感知平衡特性,引入语义特征通道对图像质量进行综合度量。实验结果表明:所提算法的有效性和可靠性,可以为图像质量评价领域提供一种新思路。未来可以探究更加符合人眼视觉感知的分块方式,进一步提升网络性能,并对人眼视觉平衡特性进行深入研究,将其应用于风格迁移和图像识别等方向。
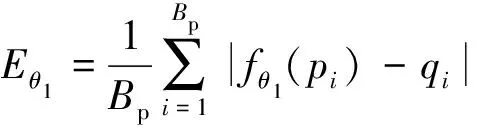

2 性能测试与分析
2.1 数据集和评价指标
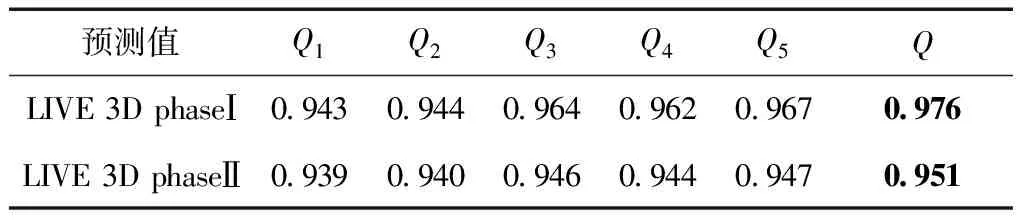
2.2 消融实验
2.3 权重选择
2.4 算法性能分析


3 结论
