基于XGBoost模型的安徽省土壤pH空间建模
2023-03-15邱士其赵明松芦园园卢宏亮徐少杰陈宣强
邱士其,赵明松*,芦园园,卢宏亮,徐少杰,陈宣强
(1.安徽理工大学空间信息与测绘工程学院,淮南 232001;2.矿山采动灾害空天地协同监测与预警安徽省教育厅重点实验室,淮南 232001;3.矿区环境与灾害协同监测煤炭行业工程研究中心,淮南 232001;4.国家环境保护土壤管理与污染控制重点实验室,南京 210042;5.生态环境部南京环境科学研究所,南京 210042)
土壤pH不仅对土壤中微生物活性、土壤养分有重要影响,而且影响土壤理化性质以及植被对土壤养分的吸收、利用[1],是土壤中影响范围极为广泛的化学指标[2]。对于土壤pH的研究,有利于及时了解土壤状况,为合理施肥、改良土壤、加强土壤环境管理起到重要作用。
随着地信和遥感技术的发展,逐渐形成了以定量土壤-景观模型为理论基础、以空间分析和数学方法为技术手段的土壤调查与制图的现代化技术体系-数字土壤制图(digital soil mapping,DSM)[3-4]。数字土壤制图起初主要运用判别分析、线性回归等方法来建立土壤与环境之间的关系并绘制成图。随着研究人员对数字土壤制图技术的不断研究与完善,目前数字土壤制图方法包括统计学方法、基于专家知识的方法和机器学习等方法[5-6]。统计学方法是根据土壤与环境变量之间的统计关系,推测土壤属性空间分布的方法,常用方法包括:线性模型、判别分析。克里格[7]和地理加权回归[8]是空间统计中较为常用的方法。基于专家知识的方法是指从土壤专家处获得关于土壤与环境变量之间关系的知识,将获取的知识与语义模型结合,并借助地信技术来完成土壤信息制图的一种方法。Qin等[9]基于地理信息系统(geographic information system,GIS)、模糊逻辑和专家知识,建立了土壤一环境推理模型, 并考虑了感兴趣区位置和样本位置之间的空间距离信息,使得模型精度进一步提高。
基于机器学习的数字土壤制图方法在处理多维、非线性海量数据、提高模型泛化能力、预测速度、精度等方面具有良好表现,目前已被应用到诸多领域[10-11]。卢宏亮等[12]研究发现,将Boruta算法与SVR模型结合可以提高土壤pH的预测制图精度,且模型的泛化能力较强。王世航等[13]研究表明,使用特征挖掘方法可有效提高广义提升回归和随机森林模型预测精度,且可以起到降维的作用。Liu等[14]基于先进的机器学习方法与高效的并行运算环境,大幅提高了现有制图的准确性和精细度,并提供了空间预测的不确定性信息,更好地表征了中国土壤属性的空间变异特征。
在数字土壤制图方法中,常见的机器学习模型包括随机森林[15-16](random forest,RF)、支持向量机(support vector machine,SVM)、神经网络(neural networks,NNs)等。
极端梯度提升模型[17](extreme gradient boosting,XGBoost)采用Boosting思想并使用多种方法防止模型过拟合。目前,XGBoost算法多应用在医学[18-19]、金融[20-21]、工程等领域,在数字土壤制图领域的应用包括:结合SFLA-XGBoost模型与高光谱的土壤有机质含量预测[22]、基于极限梯度提升和长短期记忆网络相融合的土壤温度预测[23]、土壤含水量估算等,但少有研究者将其用于土壤pH的预测和制图中。因此,探讨XGBoost模型在土壤pH预测及制图中的可行性以及模型所能达到的精度具有实际的研究意义。
鉴于此,以安徽省为研究区域,采用数字高程模型(digital elevation model,DEM)和野外实测土壤样本数据,利用3S技术提取17个环境变量,以土壤pH为研究目标。建立XGBoost模型并对土壤pH进行预测及制图,与随机森林模型结果进行对比分析。探讨两种模型下安徽省表层土壤pH的空间分布规律及差异,定量分析土壤pH的影响因素,以可视化的方式给出两模型的不稳定性表达,以期为XGBoost模型在数字土壤制图的应用提供参考并为安徽省加强土壤环境管理提供数据基础及安徽省土壤pH预测、研究提供理论基础。
1 材料与方法
1.1 研究区域
安徽省(114°54′E~119°37′E,29°41′N~34°38′N),居中靠东,沿江通海,是最具活力的长江三角洲组成部分,总面积达14.01×104km2。地形地貌呈现多样性,境内长江和淮河自西向东横贯全境,将全省划分成3个自然区域。境内主要山脉包括大别山、黄山、九华山等,最高山峰是黄山莲花峰,海拔 1 864 m。安徽省地处暖温带与亚热带过渡地区,四季分明、雨量充沛、气候宜人。安徽省土壤的过渡特征明显,以林为主的土壤主要有棕壤、草甸土、黄棕壤、黄壤、石灰(岩)土、紫色土、麻骨土、石质土等;农林兼用的土壤有红壤、黄褐土等;以农为主的土壤有砂姜黑土、潮土、水稻土等。
1.2 数据处理
研究所使用的土壤数据来源于《中国土系志·安徽卷》[24],所获数据包含采样点分布、环境条件和土壤理化性质等。采样时间为2010年,包含140个样点的表层土壤pH属性数据。地形数据为空间分辨率为90 m 的SRTM数字高程模型,来源于地理空间数据云。坡向(aspect)、坡度(slope)、高程(elevation)、平面曲率(plan curvature)和剖面曲率(profile curvature)通过ArcGis10.6获得;径流强度指数(SPI)、汇聚指数(CI)、多尺度谷底平坦度(MRVBF)、多尺度脊顶平坦度(MRRTF)、地形湿度指数(TWI)及地形位置指数(TPI)在SAGAGIS 6.3.0中得到。归一化植被指数(NDVI)和增强植被指数(EVI)来源于MODIS陆地产品,空间分辨率为250 m。气候数据使用来自中国农业科学院农业资源与农业区划研究所中国生态环境背景层面建造项目完成的栅格数据(1 km分辨率),为1980—1999年的逐月平均值计算生成年均温(MAT)和年均降水量(MAP)。此外,将x、y坐标作为环境变量引入建模。
1.3 研究方法
1.3.1 XGBoost模型
XGBoost是由GBDT(gradient boosting decision tree)模型发展而来的,在传统的Boosting基础上,利用中央处理器(central processing unit,CPU)多线程,引入正则化项,加入剪枝,使用列抽样来控制模型的复杂度。如何在每一步生成合理的树是 Boosting分类器的核心。
对于一颗含有t个基础模型的集成树来说,关键点就是第t个基础模型的选择。对于该问题,需要寻找一个能够使目标函数尽可能最大化降低的ft,故构造的目标函数可表示为
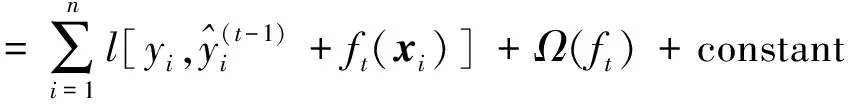
(1)
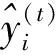
对于一般的损失函数来说,可以使用泰勒展开对损失函数做近似估计。移除常数项(真实值与上一轮的预测值之差),目标函数只依赖于每个数据点在误差函数上的一阶导数和二阶导数。
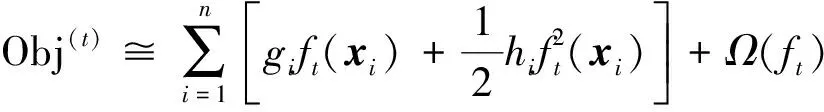
(2)
式(2)中:gi为数据点在损失函数上的一阶导数;hi为数据点在损失函数上的二阶导数。
XGBoost模型参数有3种类型,即:通用参数、辅助参数和任务参数[25]。通用参数包括:booster、silent、nthread等。辅助参数有:eta、gamma、max_depth、subsample等。任务参数包含:objective、eval_metric、base_score等。对nrounds、max_depth和eta 3个参数在R语言中利用caret包进行格网搜索及重复交叉验证并以均方根误差值为评价指标,选择均方根误差值最小时的参数组合作为最优参数,利用XGBoost包进行建模并进行预测制图。
1.3.2 随机森林模型
与XGBoost模型不同,随机森林模型在Bagging的基础上,进一步在训练过程中引入随机属性选择,且模型对于高维数据集的处理能力很好,泛化性能优越。
随机森林模型是n棵决策树{T1(X),T2(X),…,Tn(X)}的集合,其中X={x1,x2,…,xp}是与目标变量相关的特征的p维向量,结果为n棵树的输出值Y={Y1=T1(X),Y2=T2(X),…,Yn=Tn(X)},其中Yn为第n棵树的预测值。对于分类问题,Y由最多投票数获得;对于回归问题,Y是多棵树预测的平均值获得。
随机森林模型中有两个重要参数:分裂次数(mtry)和决策树数量(ntree)。在R语言中利用e1071包采用格网搜索和十折交叉验证进行参数调优,并以均方误差为精度评价指标,并用random Forest包进行建模。
1.3.3 精度评价
模型精度评价选用均方根误差(root mean squared error,RMSE)、平均绝对误差(mean absolute deviation,MAE)以及决定系数(R2)3个指标,其计算公式分别为
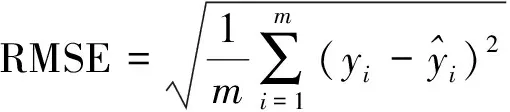
(3)
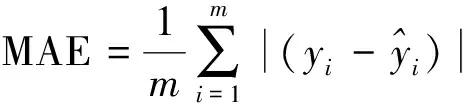
(4)
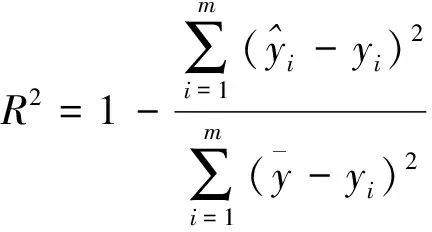
(5)
模型不确定性是数字土壤制图中的重要内容,不确定性可表示为90%置信区间的预测下限和上限。随机森林模型的不确定性可通过R语言中的quantregForest包对最优模型中各个树的结果进行统计获得,XGBoost模型的不确定性则是通过对100次最优模型预测结果统计所得。
2 结果与分析
2.1 土壤属性特征统计
如表1所示,安徽省土壤pH分布范围在4.58~8.67,平均水平为6.37,为中性土壤。从总体上看,总样本、训练集和验证集数据分布极为相似,标准差在1.16附近,变异系数也都分布在18%~19%,属中等变异。在安徽省土壤样本中,强酸性样本36个(26%),酸性样本45个(32%),中性样本33个(24%),微碱性样本20个(14%),强碱性样本6个(4%)。就整体而言,安徽省土壤样本中酸性占比大(58%),碱性样本则占18%。安徽省土壤样点位置分布如图1所示。
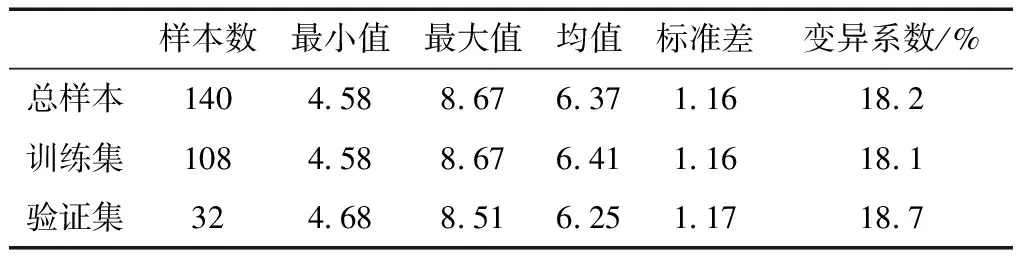
表1 土壤pH特征基本统计
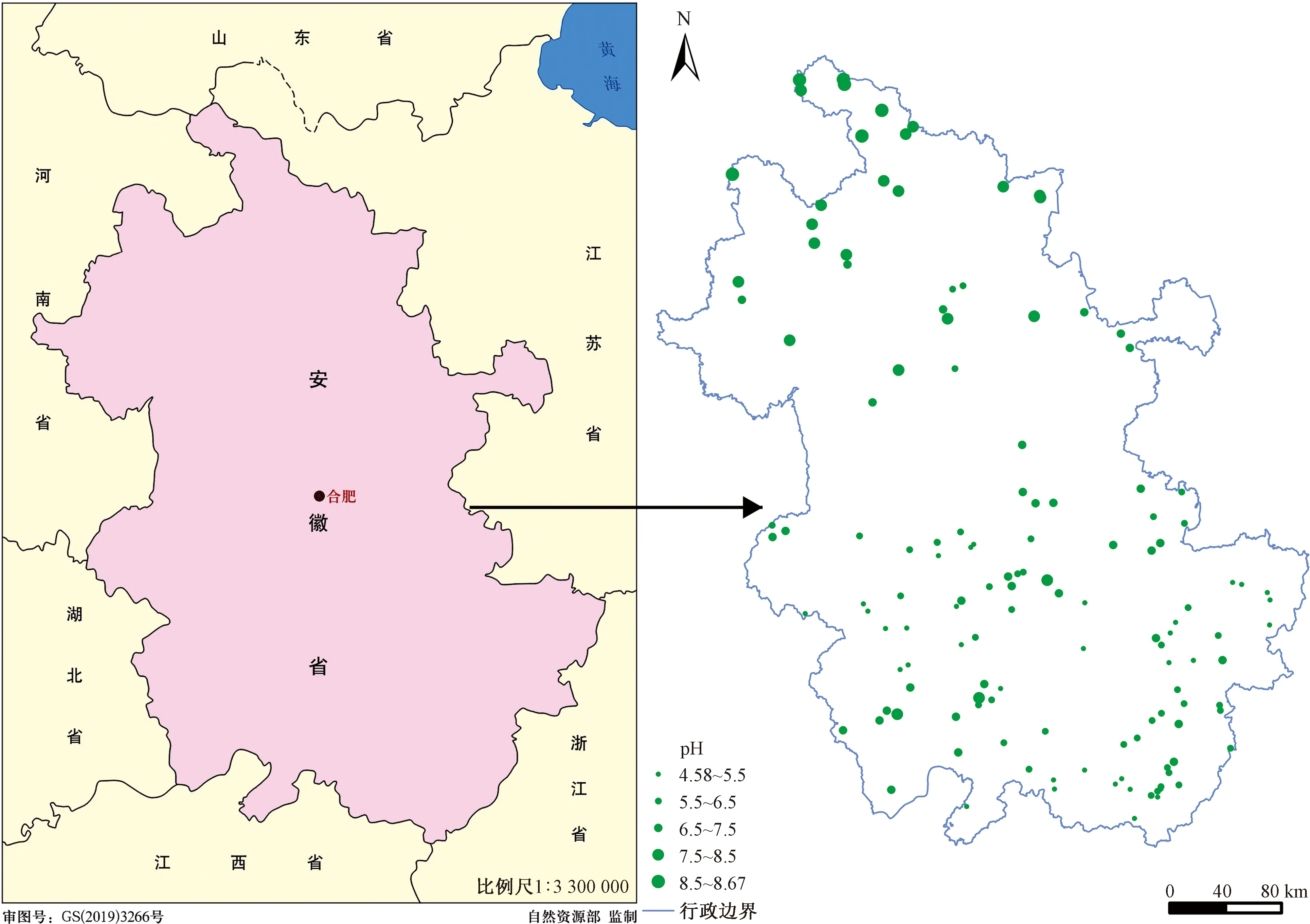
图1 土壤pH采样点空间分布
2.2 环境变量与土壤pH相关性分析
如表2所示,土壤pH与X3(r=0.63)和X4(r=0.61)呈显著正相关,与X1、X2、X6、X10、X13、X14显著负相关;与X8在0.05水平上显著负相关。此外,X14与土壤pH的相关性最高,说明随着年均降雨量的增加,pH呈显著下降的趋势。除X1、X3、X4和X14与土壤pH均具有较高的相关性外,其余环境变量与土壤pH的相关系数并不高。此外,X1与X2、X3、X4、X10、X13、X14、X15显著相关,与X6、X8相关(P<0.05);X2与X3、X4、X10、X13、X14、X15显著相关,其余变量之间也存在类似的情况。X13与X15之间存在着最高的相关性(r=-0.83)。
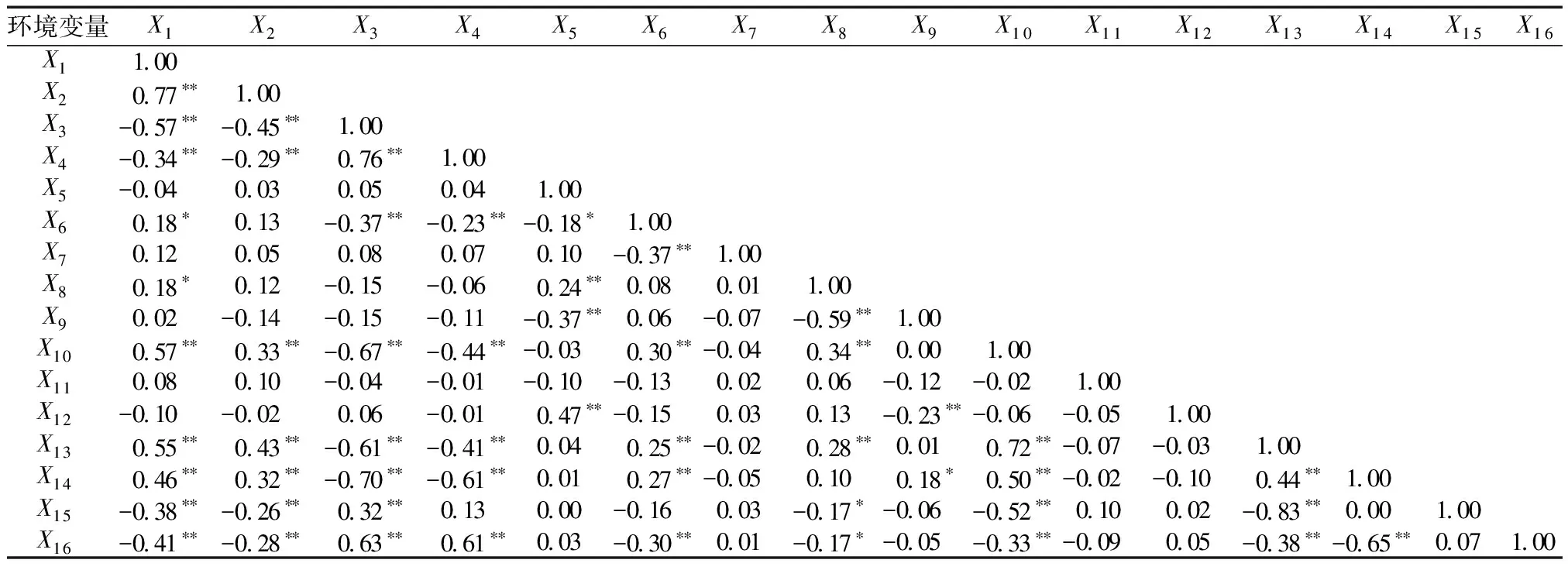
表2 土壤pH与环境变量的相关性分析
2.3 土壤pH建模及参数优化
如图2所示,在学习率eta=0.005、0.01、0.02时,无论树深max_depth为何值,随着nrounds的值不断变大时,RMSE逐渐减少并在到达一定的值时趋于稳定。eta=0.03时,与其他3种情况稍有不同,在max_depth=2的情况中,迭代次数nrounds在200后值不断增加时,RMSE也在不断变大,但在nrounds=1 000后,值同样趋于稳定。可以看出,XGBoost模型对于eta是较为敏感。随着eta不断地变化,RMSE范围越来越小:0.5~4.0、0.6~2.6、0.75~1.20、0.75~0.85,且RMSE趋于稳定时,nrounds的值也在不断变小:1 000、500、300。max_depth 对于RMSE影响较小,在eta=0.005、0.01时,无明显的差异;在 eta=0.02、0.03时,才能看出明显差异。最终的参数组合为:nrounds=860,eta=0.01,max_depth=2。
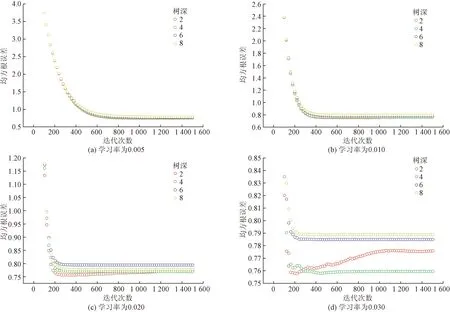
图2 XGBoost模型参数调优结果
2.4 环境因素对土壤pH建模影响
在XGBoost模型中,可用gain来衡量特征的重要性。gain 增益意味着相应的特征对通过模型中的每个树采取每个特征的贡献而计算出的模型的相对贡献。与其他特征相比,较高值意味着它对于生成预测更为重要。
在随机森林模型中,可用IncNodePurity来判断特征的重要性。该值通过残差平方和来度量,代表了每个变量对分类树每个节点上观测值的异质性的影响,从而比较变量的重要性。该值越大表示该变量的重要性越大。
如图3所示,在两个模型排名前5的环境变量分别为:纬度(Y)、MRVBF、MAP、MAT、EVI和MAP、Y、MRVBF、EVI、MRRTF。环境变量的选择稍有不同,XGBoost模型中包含MAT,而RF模型中则有 MRRTF,其余变量对于土壤pH的影响较低。其中,MAP 在两个模型中的排名均在前列,说明年均降雨量对于土壤pH有重要影响。在多雨环境中,土壤及其母质浸出强烈导致土壤酸化,而安徽省南部降雨多于北方,这会导致南北土壤酸碱度的差异[26]。而MRVBF和MRRTF可以识别谷底和山坡两种地形,这两种地形存在着明显不同的土壤含水量。一般来说,过量的水分导致土壤酸化,过少的水分导致土壤碱化。
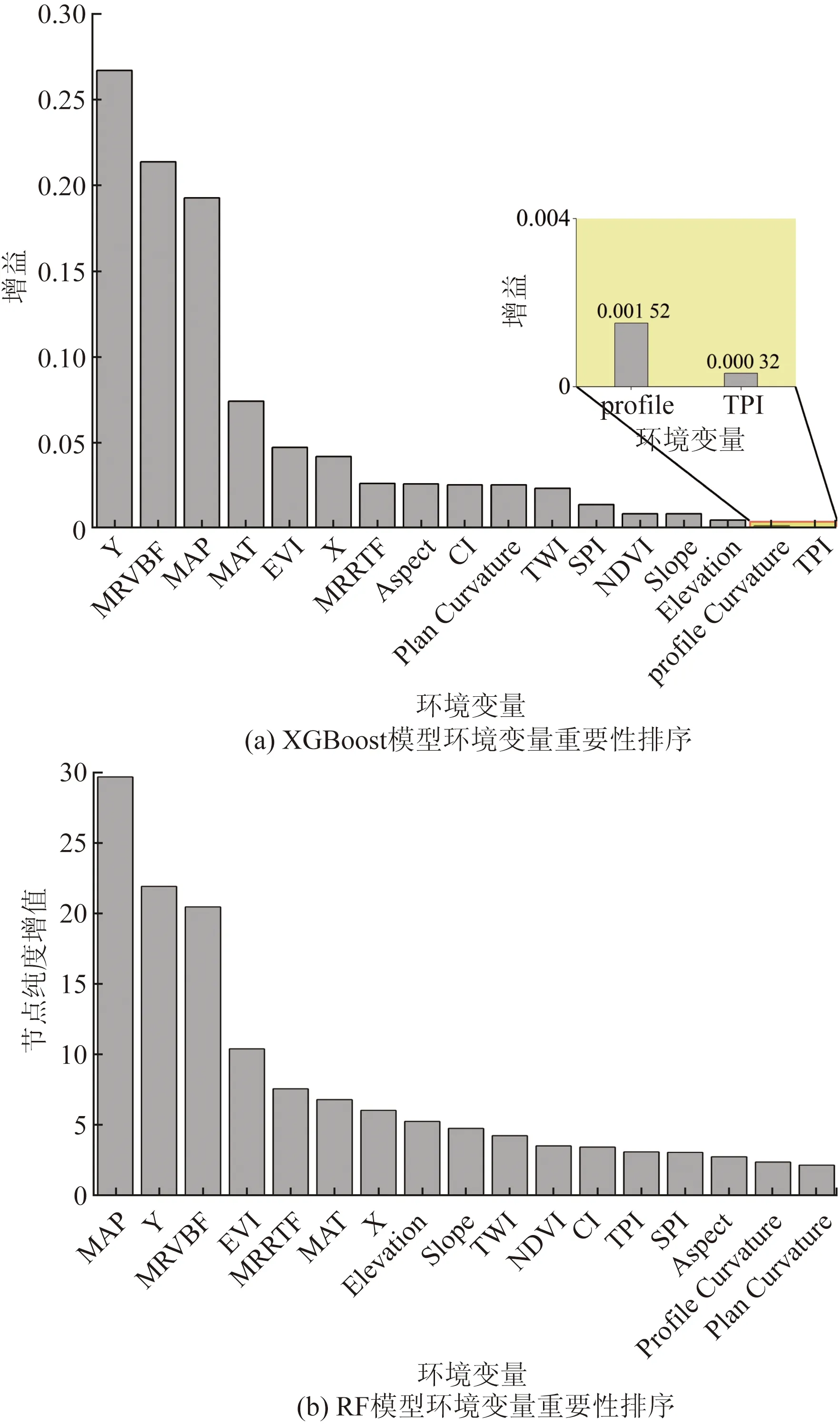
X为经度
3 讨论
3.1 模型精度及空间制图
如表3所示,XGBoost模型的精度为:训练集(RMSE=0.32、MAE=0.25、R2=0.93)、验证集(RMSE=0.65、MAE=0.50、R2=0.73);随机森林模型的精度结果为:训练集(RMSE=0.75、MAE=0.60、R2=0.57),验证集(RMSE=0.68、MAE=0.53、R2=0.71)。可以看出,XGBoost模型在训练集的精度是最高的,明显优于验证集的精度和随机森林模型的精度,XGBoost模型验证集和训练集精度均优于随机森林模型训练集的精度,较优于随机森林模型验证集的精度,且随机森林模型训练集精度低于验证集精度。综上,XGBoost模型对于土壤pH预测结果精度优于随机森林模型预测结果。
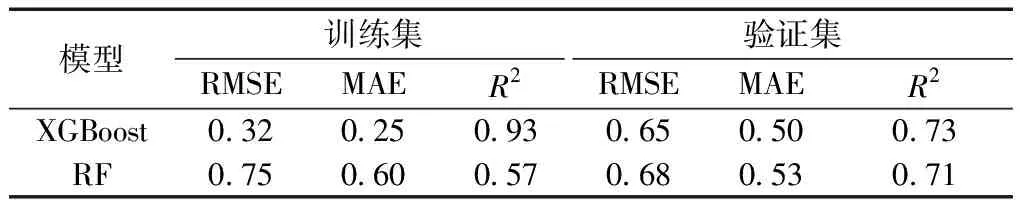
表3 模型精度
如图4所示,两种模型的预测结果趋势大体相同,安徽省土壤pH呈“南酸北碱”趋势。以长江为分界线,长江以南多为酸性或强酸性土壤,长江以北多为碱性土壤或中性土壤。两模型土壤pH预测的范围不同:XGBoost模型(4.59~8.96)、随机森林模型(5.52~8.16),差别较为明显。且在部分地区两者略有差异。
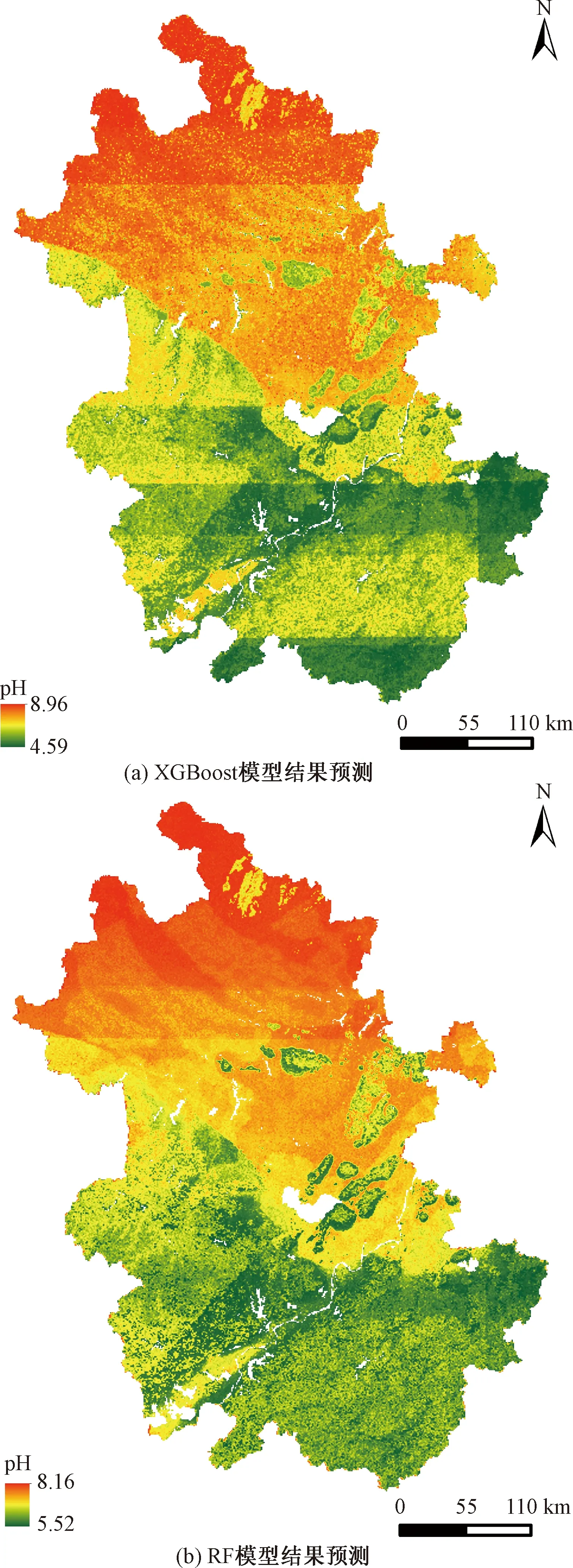
图4 模型预测结果图
3.2 模型不确定性
如图5所示,5%的预测下限和95%的预测上限与最优预测结果具有相似的空间模式(安徽省北部土壤pH要高于南部)。随机森林模型不确定性较大的区域集中在合肥、阜阳、淮南等长江以北区域,最大的差值为3.99,最小为1.64;XGBoost模型不确定性较大的区域则相对集中在靠近长江的地方,包括六安、黄山、宣城等地,最大差值为1.73、最小为0.38。从结果上看,XGBoost模型的稳定性要高于随机森林模型。
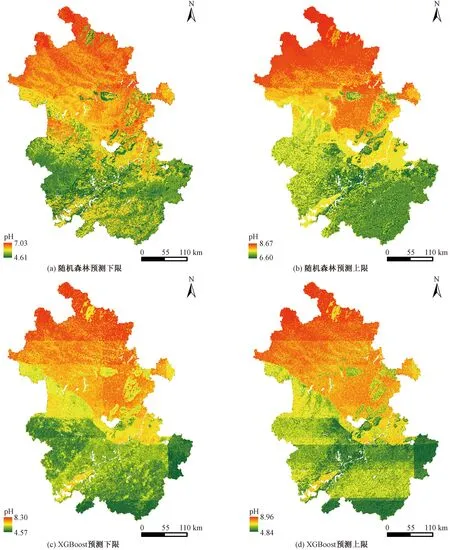
图5 模型不确定性图
4 结论
基于XGBoost、随机森林模型建立了安徽省表层土壤pH空间预测模型,并对比分析了模型精度和不确定性。得出如下主要结论。
(1)XGBoost模型的调参结果说明eta、max_depth、nrounds对于模型的精度均具有一定的影响。其中,eta的变化对于模型的影响较大。
(2)MAP、Y、MRVBF、EVI对土壤pH建模有重要的影响。
(3)XGBoost模型在训练集和验证集预测精度均高于随机森林模型,训练集精度明显高于随机森林模型训练集精度,验证集精度较优于随机森林模型验证集精度。模型5%的预测下限和95%的预测上限与最优预测结果具有相似的空间模式,从结果上看,XGBoost模型的稳定性要高于随机森林模型。两模型预测结果都表明了安徽省土壤pH呈“南酸北碱”的趋势,但两者在部分地区结果仍有区别。
