基于MA-DRNet的糖尿病视网膜病变等级识别方法
2023-03-15徐盼盼陈长骏闫志文李林超
徐盼盼,陈长骏,闫志文,李林超
(1.浙江省人民医院杭州医学院附属人民医院,临床医学工程部,杭州 310014;2.浙江大学医学院附属第二医院,临床医学工程部,杭州 310009;3.浙江啄云智能科技有限公司,杭州 310052)
目前中国已是世界上糖尿患者人数最多的国家之一,有超过11 000万患者且发病人口仍在增长中,专家预计到2035年发病人数将达到59 200万。不少糖尿病患者还伴有其他并发症,其中视网膜疾病就是典型的并发症之一。调研表明,患有高血糖视网膜并发症(diabetic retinopathy,DR)的病人人数约占糖尿病总人数的1/3,所以糖尿病视网膜病已变成国际失明人数上升的主因,该病症会严重影响到病人的视力甚至导致失明,是当今致盲率最高的导火索。在临床中,因为视网膜图像的影像数据等级较多且各个级别间差别较小,医生对此种病例的分级治疗过程相对耗时,长期大量的阅片将会让专家陷入疲惫状态,导致发生错误治疗、漏症等状况的出现,从而影响阅片的准确率。基于上述原因,通过深度机器学习技术辅助医师对DR疾病分级鉴别确诊已经成为了近些年在该领域的一个重点研发方向,而通过该技术能够更高效地辅助医师开展糖网病治疗,从而大大提高了DR疾病确诊的效率和准确度,并有着巨大的临床使用价值。对DR患者进行早期筛查和治疗可以有效防止视觉损害及失明,早期确诊原发疾病就可以对患者进行跟踪随访,能够有效的帮助患者保存视力、阻止DR患者失明。
近些年不少国内外学者针对深度学习在糖尿病视网膜病识别问题展开了一定的研究。Saichua等[1]采用了深度学习方法对糖尿病导致的视网膜病变图片进行等级分级,利用深度学习神经元去提取不同病变等级视网膜特征;Gulshan等[2]在公开数据集EyePACS-1和Messidor-2的基础上,利用深度学习方法进行临床验证,并制定评价指标;Valarmathi等[3]对病变视网膜分别采用手工提取特征和深度学习方法提取特征进行对比,论证深度学习方法提取病变视网膜特征的可行性;Liu等[4]将残差网络和自注意网络进行对比,得到残差网络比自注意网络效果好;Xie等[5]提出了Resnext残差结构,对网络的宽度和深度进行复杂化,提高分类的准确率;Bello等[6]对残差结构的网络宽度和注意力机制进行了修改,证明了残差网络识别准确率高于NAS自动搜索网络;Ma等[7]验证了基于Transformer模型的视网膜图像分类方法的可行性;Hu等[8]验证通过挤压和激励模块增加通道之间的相关性,从而提高网络层提取特征的空间和通道的表征能力;Rosenfeld等[9]对网络的宽度、深度以及尺度进行调节,验证了模型的泛化能力和数据以及网络之间的相关性;郑雯等[10]对 ResNext50聚合残差结构进行预训练,结合多种数据增强策略扩充数据集,提高分类的准确率;顾婷菲等[11]使用了多通道注意力[12]选择机制的细粒度分级方法[13-14]对糖尿病性视网膜病变分级。陈明惠等[15]将迁移学习技术应用于视网膜图像自动分类上,达到了高效的视网膜病变自动分类效果。
糖尿病视网膜病变不同等级差异非常细微,病灶点微小且对分类精度要求较高,此外,相关影像数据比较有限。上述问题给深度学习模型用于糖尿病视网膜病变图像自动分类带来了一定的挑战。根据以上分析,为了进一步提高对DR的分析准确度与鲁棒性,从3个方面对模型进行了设计与优化。
(1)多级特征残差块:因为残差结构中的卷积层受卷积核限制,输出的特征层具有局限性,无法采用多分辨率[16-17]进行特征提取,提取到的特征图损失比较严重,所以多级特征残差块通过多组卷积在感受野和输入层的分辨率方面进行优化。多组卷积依据不同分辨率输入得到的多个不同尺度的特征,挖掘的特征信息更加全面和有效。多级特征残差块分成2个阶段:①阶段一从前到后级联,将前一组通道卷积得到的特征叠加到后一组通道中,得到的特征层具有前一层像素信息,再通过卷积得到的特征层具有不同分辨率信息;②阶段二从后往前级联,将后一组的卷积得到特征层叠加到前一层特征中,用1×1的卷积压缩通道,这样得到特征层具有多层语义信息,感受野更大。
(2)全局通道联合注意力机制:全局通道联合注意力机由通道注意力机制模型和全局上下文模块两个部分组成,得到的特征层既有通道的上下文关系,又有特征层的上下文关系,使特征层具有全局感受野,从而更好地捕获视网膜病变的有效特征信息。
(3)设计了集成难例挖掘的训练方法:集成难例训练方法引导模型关注难分类和分类错误的数据集,减少对易分类数据集的过多学习,其方法能够解决传统模型训练方法对易分类数据集和难分类数据同样权重的学习,导致模型训练阶段对难分类数据关注不够,对易分类数据集学习过多;而在推理阶段对难分类数据集特征不够敏感,对易分类数据集特征过于敏感。集成难例挖掘训练方法包含了3个方面:①挖掘难分类训练集,在模型训练过程中在线分析训练集,挖掘难例信息;②采用图像融合方法将难例数据和原始训练集进行融合,得到多类训练集;③多类别损失函数计算:采用sigmoid方法实现一张图片多个类别分类问题。现对主干网络结构的残差块采用不同分辨率进行特征提取和不同感受野融合,残差块间采用全局和通道注意力来提高有效特征提取,以及在线难例样本挖掘提高易错样本的模型学习能力。因此,研究的MA-DRNet模型可提升在不同分辨率下病灶特征提取、增大感受野、降低有效特征的损失和增加难例样本的学习能力,从而提高模型对眼膜病变等级识别的准确率。
1 模型整体方案
在多级特征残差块、全局通道联合注意力机制和集成难例训练方法3个方面进行创新。
(1)多级特征残差块是基于Resnet50基础框架进行修改。Resnet50的残差块虽然能够将输入层特征信息和输出层特征信息进行融合,但受3×3卷积的限制,得到特征图具有局限性、输出特征层对输入层的信息没有更深入的挖掘,挖掘的语义信息较少,输出的卷积图有效信息丢失严重,但多级特征残差块能够有效解决Resnet50的残差块的不足。多级特征残差块分成两个部分:①3×3卷积替换成多组卷积使模型能够对同一张特征图片进行不同分辨率的有效特征信息挖掘;②每组卷积与邻近卷积的特征层融合,扩大模型的感受野,减缓卷积所带来的局部性。
(2)全局通道联合注意力机制:用于残差模型之间的连接,得到的特征层具有全局性,增加模型的感受野。全局通道联合注意力机制在通道和特征层两个方面对有效特征增加权重,利用损失值对模型反向传播,引导模型向有效信息学习,减少模型对噪声等无效信息的关注。
(3)集成难例训练方法:在模型训练过程中,对训练集进行分析,得到难例样本;采用图像融合的方法,将难例数据集和原始数据集进行融合,提高难例数据集出现的频率,从而提高模型对难例数据集的学习能力;采用多类损失函数方法,解决传统分类模型一张图片只能出现一类的难题,实现了图像融合。不仅如此,多类别损失计算减少易分类训练集对模型的影响,增加模型对难例样本的学习。图1给出了本文对糖尿病视网膜病变等级识别的整体方案和分类模型框架。包括对数据集进行加载,模型读取图片信息;然后对数据进行预处理,采用最小比例缩放方法对数据进行缩放;接着将缩放信息输送到模型中;最后对网络输出层采用sigmoid操作得到预测值。
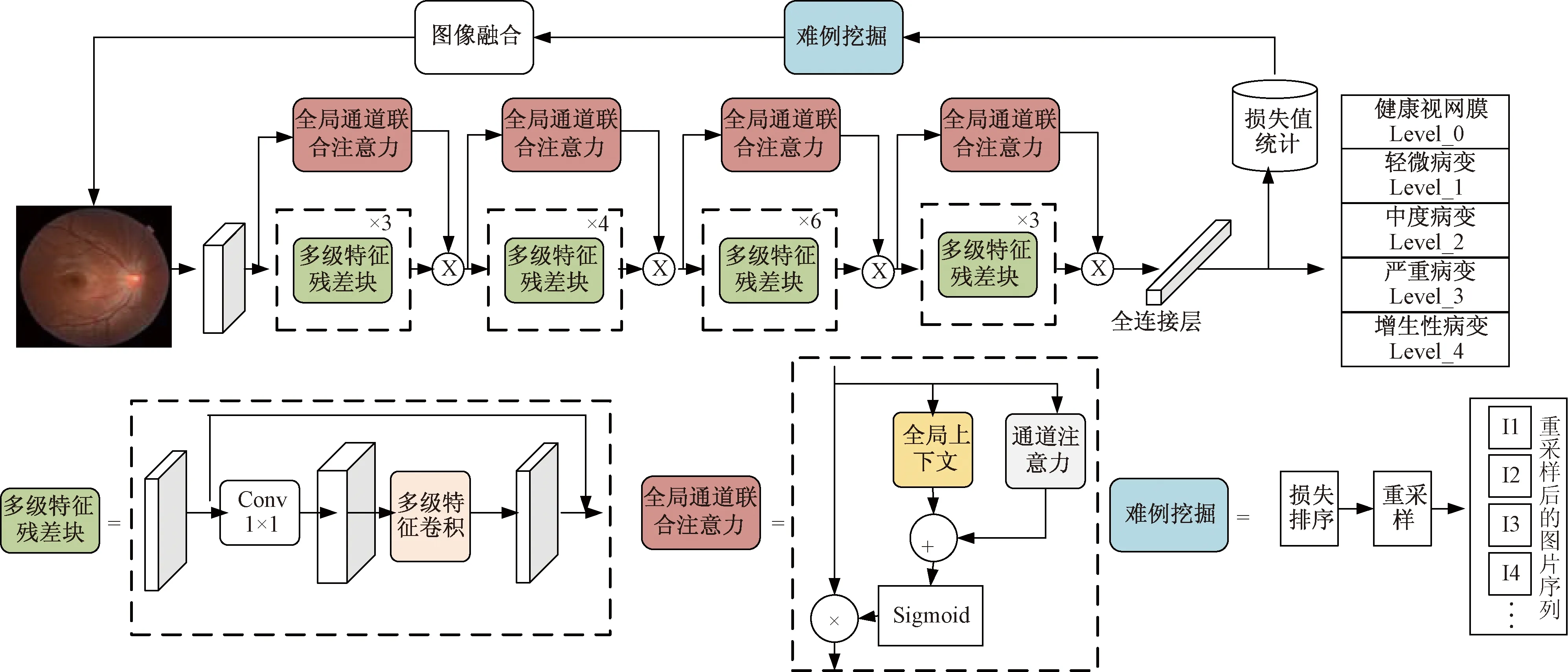
图1 糖尿病视网膜病变等级识别的整体方案图Fig.1 Overall plan of grade recognition of diabetes retinopathy
2 多尺度特征提取残差结构
模型的基础架构是Resnet50网络,先对输入块做卷积操作,然后包含4个残余误差块,最后再进行全连接操作以便于完成分析任务,Resnet50包含50个conv2d操作。其中,残差单元的算法如图2所示,通过残差学习解决了深度网络的梯度弥散问题。但这样的残差结构受到神经网络卷积核的限制,得到的特征值是从固定范围提取,仅能代表卷积层部分信息。基于上述问题进行修改,将在通道方面进行分组卷积,如图3所示。
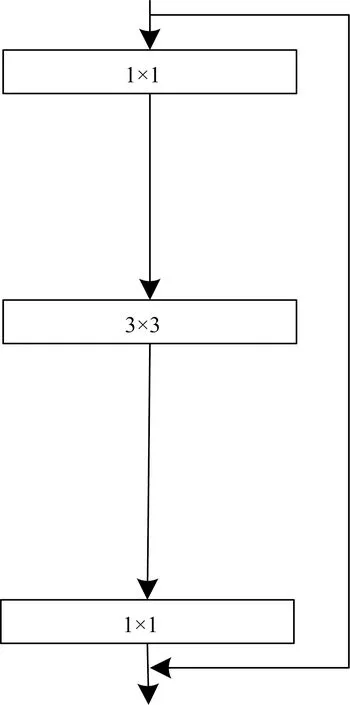
图2 原始残差单元Fig.2 Original residual element
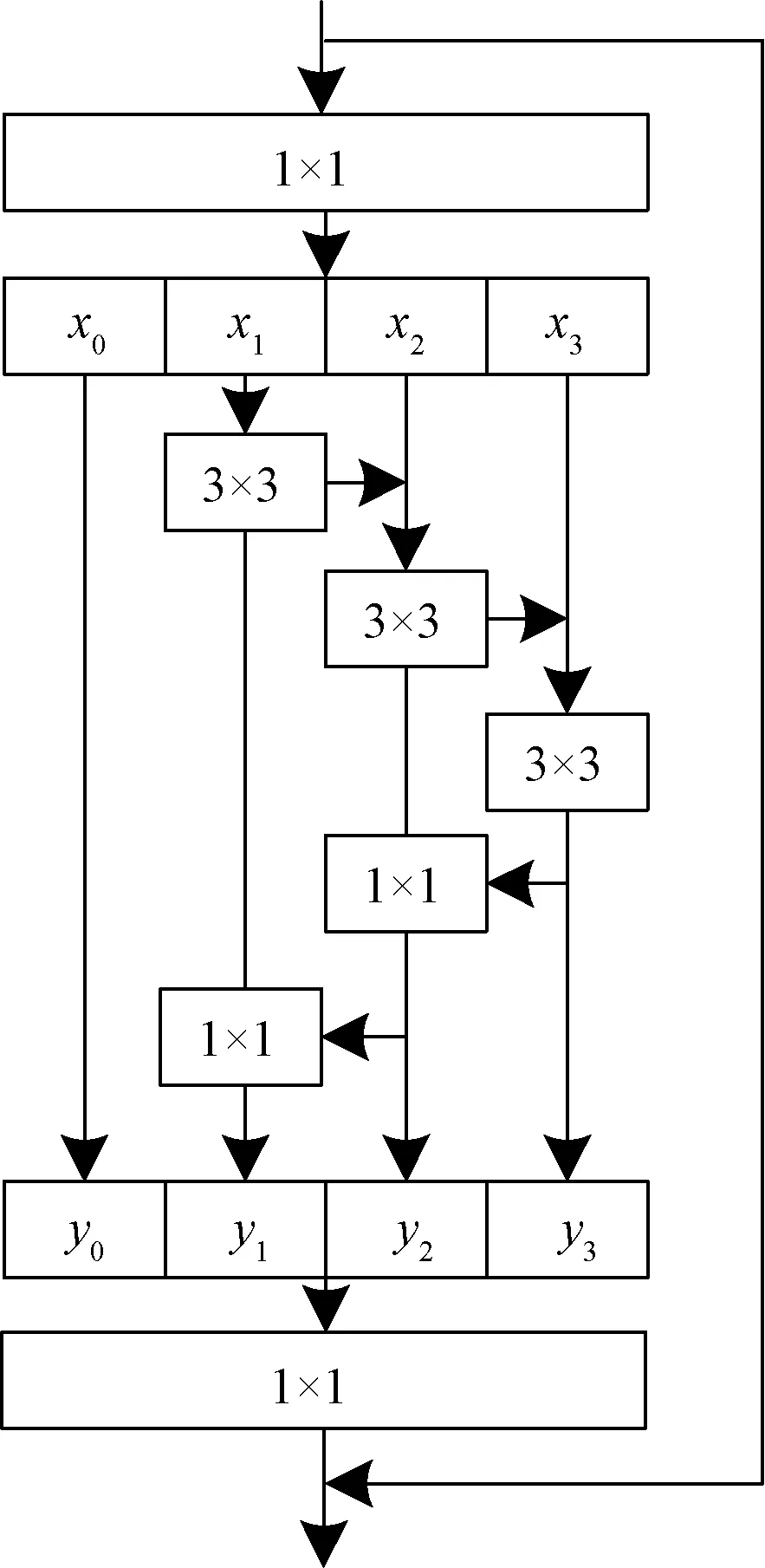
图3 多级特征残差结构Fig.3 Multistage characteristic residual structure
(1)先依次对卷积通道进行卷积,将上一组卷积输出的特征层叠加到下一组卷积特征层。得到当前组卷积的输入信息拥有本层输入层信息也有上一组经过分组卷积得到的特征信息,这样形成的分组卷积的输入层具有不同分辨率信息,可以让模型对不同分辨率进行信息挖掘,相当于采用不同卷积核对输出层进行数据挖掘,得到不同感受野特征层。
(2)反方向叠加,从后向前操作,将分组卷积向前依次叠加,大感受野特征值重新叠加到前一组分组卷积特征层;因此,多尺度[18]特征残差块增大网络感受野,使每组分组卷积除了原始卷积3×3的感受野以外还增加后一层感受野信息。除此之外,与其他分组卷积特征值相加,得到其他通道信息,捕获不同通道糖尿病视网膜信息。因此,多尺度特征可以增加捕获细节和获得不同感受野信息,扩大各个网络层的感受野覆盖范围。
残差结构输出xl+1由上一个阶段特征层xl直接映射和本阶段的特征输出层两部分组成。
残差结构表达式为
xl+1=xl+F(xl,wl)
(1)
式(1)中:xl表示上一个阶段特征层;F(xl,wl) 表示卷积操作;xl表示当前阶段特征层;wl表示卷积核。
多尺度特征残差结构表达式为
y0=x0
(2)
y11=f1(x1,w11)
(3)
y12=f1(x2+y11,w12)
(4)
y13=f1(x3+y12,w13)
(5)
y22=f2[f3(y12+y13),w22]
(6)
y21=f2[f3(y11+y22),w21]
(7)
yl=f3(y0,y21,y22,y13)
(8)
式中:x0、x1、x2、x3表示将输入层按通道分成4组;f1表示3×3卷积;f2表示1×1卷积;f3表示特征层按通道叠加;yl表示特征层输出;w11、w12、w13表示3×3卷积核,w22、w21表示1×1卷积核。
从式(2)~式(8)可以得到输出的特征层包含了每组通道的特征信息,其中第2、3、4组先依次为后一组分组卷积增加感受野和特征值,然后反向传输,将后一组特征按通道叠加到上一组特征中,采用1×1卷积对通道进行减少到原来一样,这样第2、3、4在不减少特征损失的前提下,扩大特征提取范围,使残差结构更多关注有效特征值。
3 全局通道联合注意力模块
由于视网膜图像的复杂性,对于病灶的识别仅仅用到病灶所在区域的局部特征[19-20]是不充分的,往往还需要依赖周围区域的特征甚至全局区域[21]的整体特征,而卷积神经网络是通过滑窗的方式分别提取局部的信息,难以建立信息之间的依赖关系。此外,不同特征通道之间表达的信息侧重点不同,对于病灶的识别往往更注重于边缘和纹理特征,这就需要模型提高对相应特征通道的关注[22]。因此,本文提出了一种全局通道联合注意力模块,使模型可以同时具备捕获长距离依赖关系和通道注意力的能力。全局通道联合注意力模块包含通道注意力模块与全局上下文模块,具体实现如图4所示,图中的C、H、W分别为特征图的通道数、高、宽,操作原理定义为
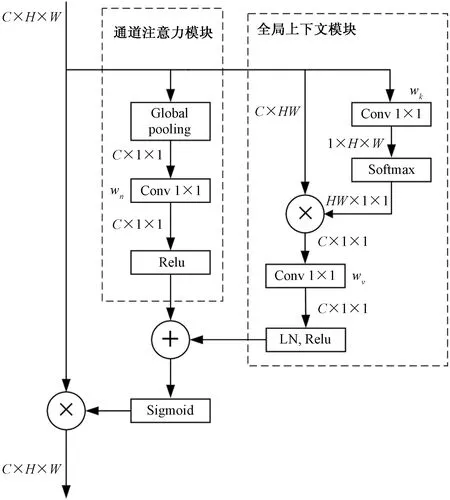
图4 全局通道联合注意力模块Fig.4 Global channel joint attention module
Zi=XiS(Bs+Bc)
(9)
Bs=R[wnG(Xi)]
(10)
(11)
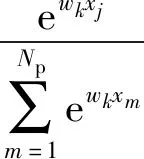
先使用全局平均池化将特征图中每个通道的特征固定成相同尺度于上下文建模,然后使用1×1卷积计算每个通道的重要程度。
4 集成难例挖掘训练方法
4.1 集成难例挖掘训练过程
模型训练结束后使用难例挖掘方法对难分样本进一步巩固训练,加强模型对于易错样本的学习,本文提出一种综合多阶段的难例挖掘与训练方法,具体方法如下。
(1)选择最后k个epoch模型结果,k一般取总的训练epoch的1/10。
(2)使用这k个模型分别在训练数据上前传传播得到预测结果。
(3)根据便签样本统计k个模型在训练集中分别预测错误的图像列表{L1},{L2},…,{Lk}。
(4)统计k个列表中图像列表的交集,重复采样2次得到列表Ln。
(5)统计k个列表中出现次数大于2次的图像,采样1次得到列表Lu。
(6)Lk、Ln、Lu这3个列表混合的一起,得到最终的混合难例列表Ls。
(7)修改采样器,随机抽取Ls中的数据与训练集采用图像融合技术进行数据预处理得到mix_data。
(8)将mix_data输入的网络得到输出特征层。
(9)输出特征层采用sigmoid预测图片的类别和得分。
(10)将预测结果与标签进行损失计算,反向传播,优化模型。
4.2 图像融合技术
图像融合技术把不同类型的图像按比例融合,达到扩充训练数据集,如图5所示。数据混合计算方法为
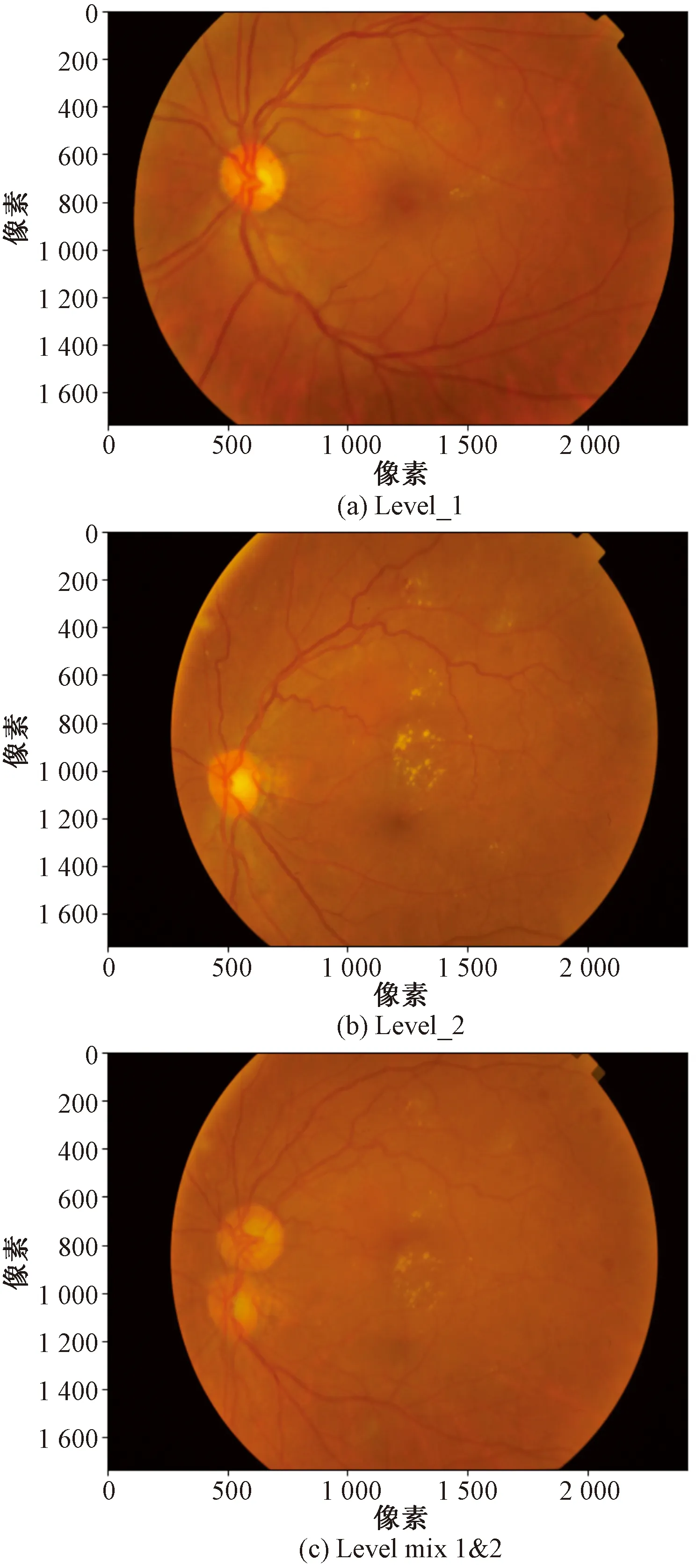
图5 图像融合前后对比图Fig.5 Image fusion before and after comparison
λ=B(a,b)
(12)
MBx=λBx1+(1-λ)Bx2
(13)
MBy=λBy1+(1-λ)By2
(14)
式中:B为贝塔分布;λ为混合系数;α和β设置为0.5;MBx为混合后的样本数据;MBy为数据集对应的标签;Bx1、Bx2分别对应两种不同数据集。
4.3 多类别分类头处理方法
模型的输出采用one-hot的编码方式,为了使模型拥有更丰富的特征信息,扩大类间距,采用多类别分类头,训练时将同一个batch内的图像采用图像融合的方式融合到一起,那么同一张图像便拥有了多个图像的特征信息,训练阶段编码方式如图6所示,分类头输出的神经元个数与分类任务的类别数相同,对特征图采用sigmoid函数进行损失计算,也就是说对每张图每个类别进行预测,这样就可以解决一张图片有多个类别的问题。采用分类多类别数据集训练可以让模型更好的关注到糖尿病病变不同等级的区别,使模型捕获更细粒度等级的特征。
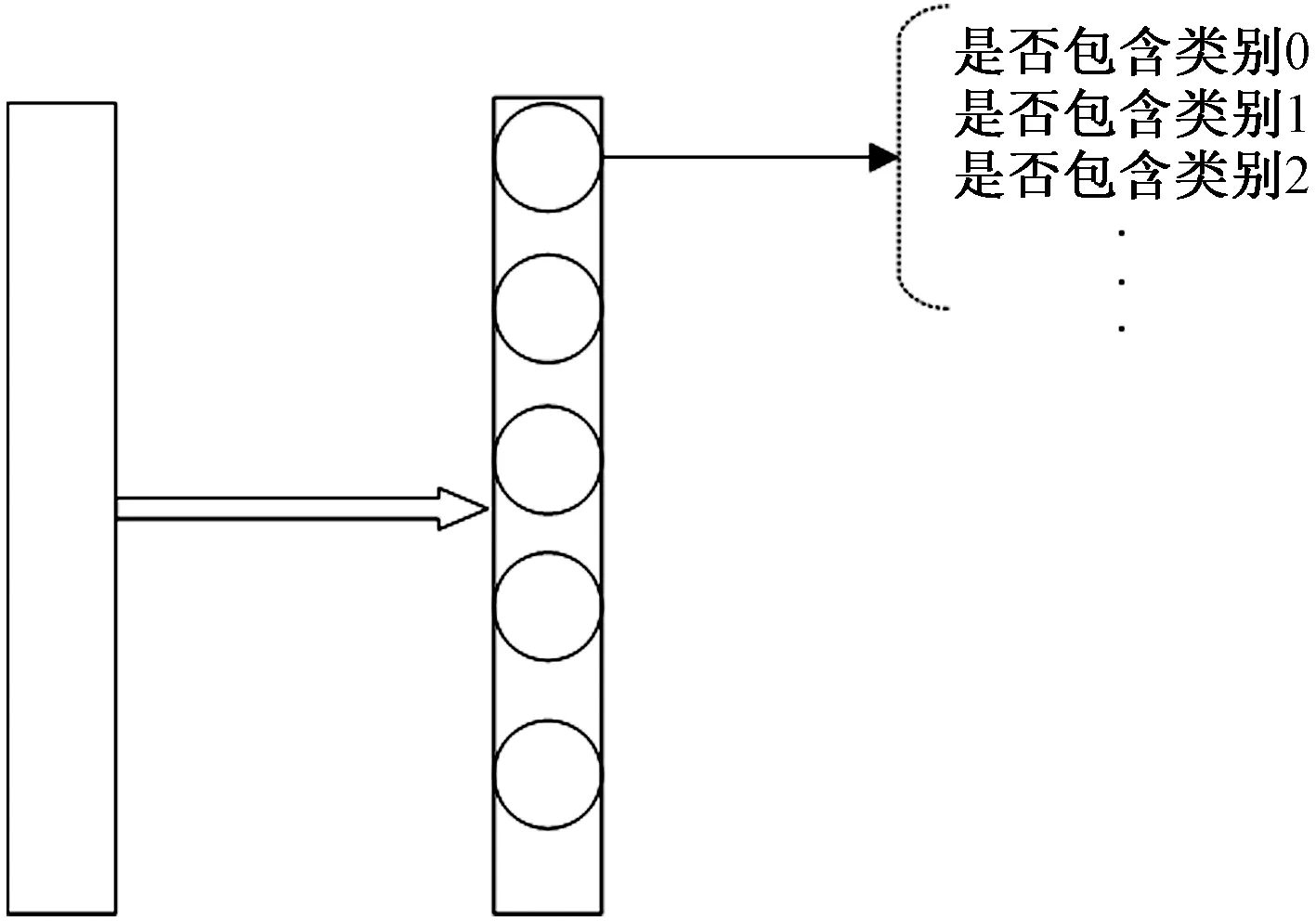
图6 多类别分类头Fig.6 Multi-category classification header
4.4 损失函数与优化器
首先,图像送入模型中进行推理,输出层的激活函数使用Sigmoid函数得到每个类别的置信度,函数表达式为
(15)
(16)
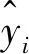
最后,通过对模型进行反向推导得到模型参数的偏差,采用Adam算法对模型参数优化,将梯度动量并入梯度指数加权估计,使用偏置修正非中心的二阶矩估计和动量项一阶矩。
5 实验与分析
5.1 实验数据集与训练环境
本文所使用的是DR_data数据集采用Kaggle(2014)和MESSIDON(French Ministry,2014)公开数据集。其中Kaggle数据集是由法国EyePacs眼底及视网膜平台免费提出,该网络平台汇集了多个医院的视网膜图像,共计数万张图像涵盖了不同的成像环境。而MESSIDON眼膜数据则是由法国国防部研究部的筛查项目所提出,收集了3家不同眼科机构数据。视网膜类别图像如图7所示。
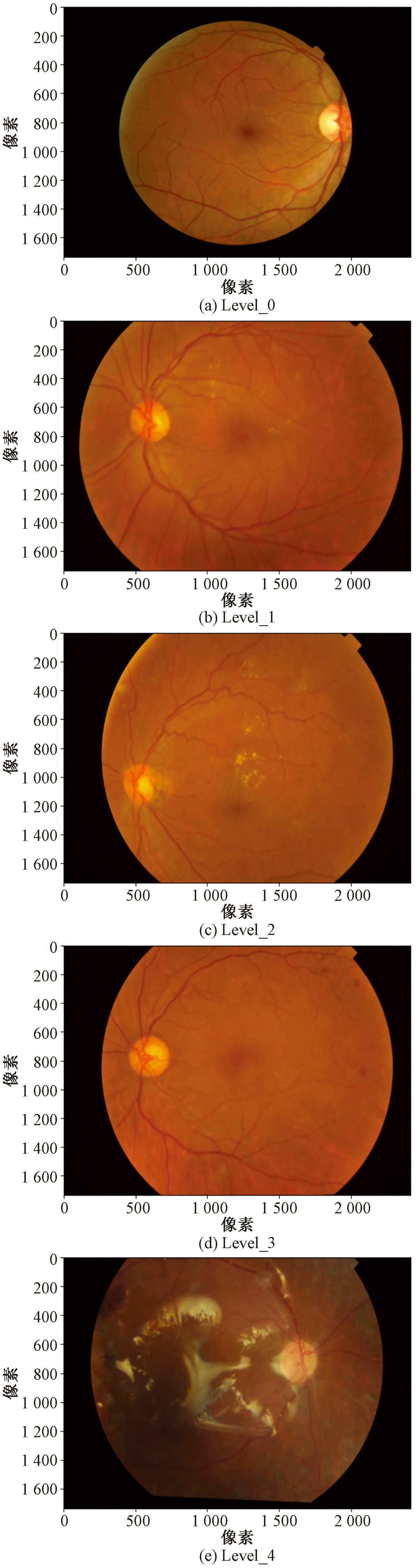
图7 数据类别图Fig.7 Data category
本文实验代码基于python3.7,pytorch版本为1.7,torchvision版本0.8.0,Linux系统版本为20.04,GPU配置为Rtx3090。在网络训练过程中,Batch size是32,学习率是0.1,优化器是adam,学习率衰减是0.000 1,线程为8。
5.2 实验指标介绍
选用特异性SP(specificity)、敏感性SE(sensiti-vity)、准确性AC(accuracy)作为指标评估。其计算方法分别为
(17)
(18)
(19)
式中:TP、FP、FN、TN分别代表真阳性、假阳性、假阴性和真阴性。
5.3 消融实验结果分析
以Resnet50为基线模型分别对多级别残差结构、全局通道联合注意力模块和难例挖掘所做的优化进行消融实验,实验在Kaggle(2014)和MESSIDON两个数据集上的平均准确率如表1所示。
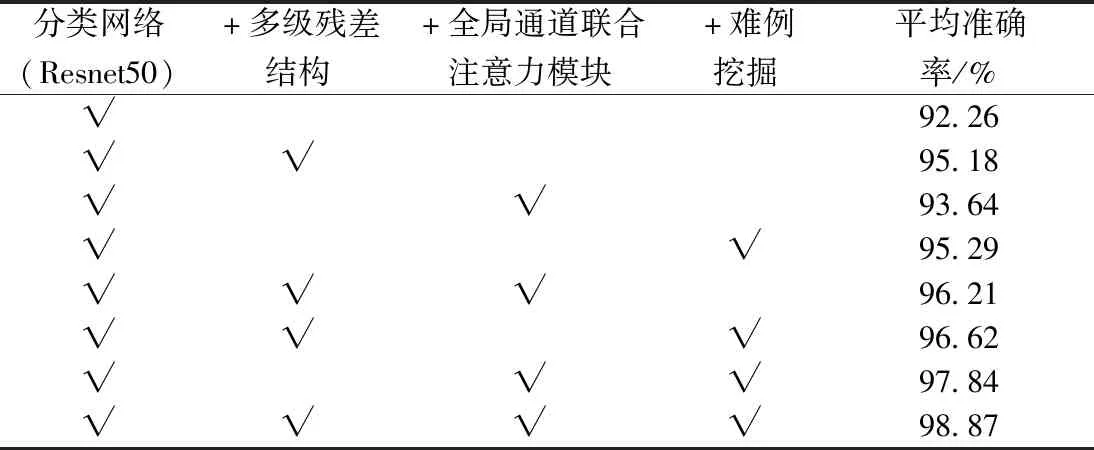
表1 不同基线模型平均准确率对比结果Table 1 Comparison results of average accuracy of different baseline models
5.4 各类别识别情况分析
本文最终优化后的模型在各个类别上的预测结果准确率如表2所示。
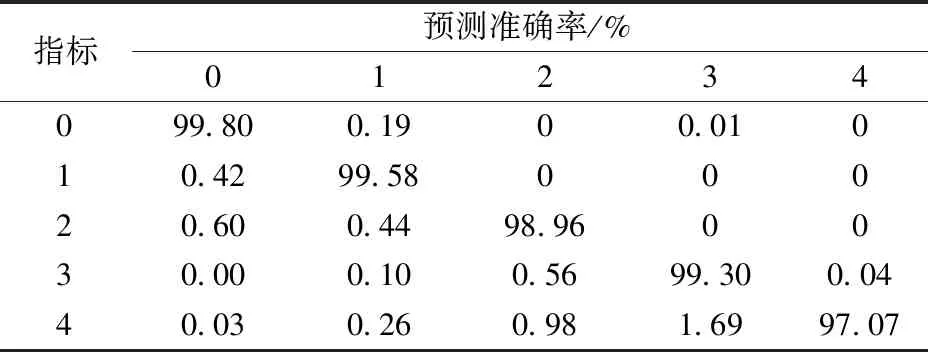
表2 本文模型类别结果准确率Table 2 This paper model classification results accuracy table
5.5 与其他算法实验对比结果
本文中采用sigmoid得到分类结果,依据式(17)~式(19)对DR数据集的五分类和二分类各项评估指标进行计算。最终本文模型在测试集上的特异性为99.02%,敏感性为98.26%,准确率为98.87%,优于现有各方法,如表3所示。
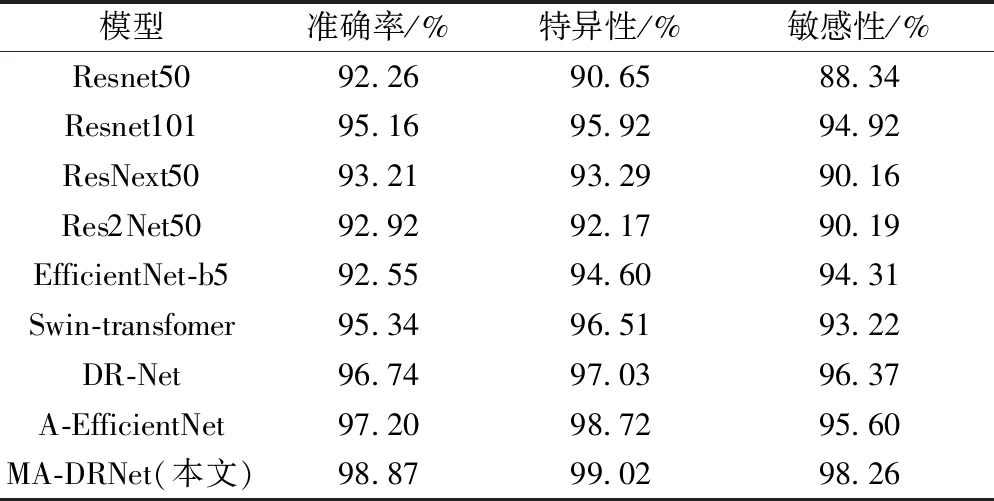
表3 不同算法对比实验结果Table 3 Compare the experimental results with different algorithms
6 结论
提出了MA-DRNet模型解决的了传统卷积神经网络对于糖尿病视网膜病变复杂特征学习困难,准确率低的问题。提出的多级特征残差块扩充了模型的感受野,加强了模型对于小尺度病灶的学习能力以及对于尺度的鲁棒性;优化的全局通道联合注意力机制同时实现像素长距离依赖关系捕获,提升了模型对于复杂病灶的表征效果;设计的集成难例挖掘与训练方法,改善了模型对于易错样本学习效果差的问题。使用本文MA-DRNet模型在Kaggle和MESSIDON两个数据集上训练和测试,在测试集上分类准确率达到98.87%,特异性达到99.02%,敏感性达到98.26%,超过目前已知同类方法。此外,本模型所提出的方法可以即插即用到其他卷积神经网络中,可以大幅提升模型对于糖尿病视网膜病变分级的准确率。本文方法对于糖尿病视网膜病变的自动分级诊断,提升眼科疾病筛查的准确率和效率方面具有重要意义。
