面向网络安全不平衡数据的特征学习和分类研究应用
2023-03-15韩凤董宗学军何戡连莲
韩凤董,宗学军*,何戡,连莲
(1.沈阳化工大学信息工程学院,沈阳 110142;2.辽宁省石油化工行业信息安全重点实验室,沈阳 110142)
计算机技术高速发展的现代,网络环境呈现复杂化和多变化的发展趋势,这也导致了网络安全事件的多发[1]。网络环境中的流量和告警日志是进行网络安全分析的主要依据,对流量和告警日志的统计分析及数据挖掘则成为了分析网络动态的重要方法[2]。另外,随着互联网时代的加速发展,网络流量呈现指数级增长,通过建立网络数据流量的主动分类模型,能为网络监管、故障诊断、态势感知等领域提供重要的评估和预测手段[3],提升对网络环境和网络资产的保护能力。
近年来许多学者在提升数据分类准确率方面提出了方法。刘云等[4]通过使用代价约束算法自动提取少数样本的特征矩阵,提高了入侵检测算法对于未知攻击的识别精度。伍德军等[5]将集成学习引入入侵检测,提高了攻击数据的检测精度。Fu等[6]为了提高模型的分类准确率和泛化性,提出一种梯度增强的特征融合技术,将特征融合和特征增强相结合,使得模型能更关注与分类相关的有效特征。Panigrahi等[7]使用基于混合决策表和朴素贝叶斯技术构建了基于签名的入侵检测分类模型,实验获得了较好的分类结果。Alazab等[8]使用飞蛾扑火优化算法为入侵检测系统生成有效的特征子集,在决策树模型上进行了验证,获得了较好的分类效果。Jiang等[9]将粒子群优化算法与极端梯度提升树 (extreme gradient boosting,XGBoost)结合,通过优化XGBoost分类模型的参数,在NSL-KDD网络安全数据集上取得了较好的分类结果。
虽然现有的很多方法能够提升数据分类准确率,但较少关注样本不平衡的问题。在真实的网络环境中,网络数据流多呈现高维度和类别不平衡的状态,正常数据流量远远大于异常数据流量,因此对于少数类异常流量数据的识别与分类更具有价值。并且,现有模型在数据类不平衡状态下特征学习效果及分类准确率依旧不是很理想,无法对攻击类型进行有效的检测。
针对网络安全数据样本不平衡的缺点,现将不平衡数据集的预处理与机器学习模型的优化相结合,提出一种改进SMOTE+GA-XGBoost机器学习数据分类方法。利用改进SMOTE(synthetic minoritye over-sampling technique)对少数类样本过采样,并对多数类样本随机欠采样,从而实现了样本再平衡;为增加模型特征学习的拟合度,将遗传算法 (genetic algorithm,GA)与XGBoost结合。实验结果表明,本文方法在网络安全不平衡数据集上拥有较好的机器学习性能以及分类准确率。
1 模型原理与解析
机器学习算法的应用,本质上是对数据执行分类和回归的过程,模型性能的提升依赖于数据端的处理和模型端的优化。通过数据端改进SMOTE插值和随机欠采样实验样本再平衡,模型端采用GA-XGBoost组合优化模型增加拟合度,具体原理解析如下。
1.1 改进SMOTE算法
1.1.1 SMOTE算法原理
SMOTE算法是一种针对不平衡数据中少数类样本过采样技术[10],区别于传统的随机过采样来增加样本,SMOTE通过数据点之间的线性插值“人为”制造出更多的少数类样本,从而平衡数据集来提升模型的学习能力。其计算表达式为
Snew=S+λ(Si-S),λ∈(0,1)
(1)
式(1)中:Snew表示新生成的样本;S表示当前取样的样本点;Si表示S样本点周围K个近邻中的第i个样本,通过式(1)在样本点之间进行线性插值,即可为模型学习少数类样本提供更多的数据特征。
1.1.2 LOF-SMOTE算法
传统SMOTE算法在最近邻插值点的选择上存在一定的盲目性,一旦选中噪声点与异常离群点进行插值操作,则会产生更多的冗余样本,造成样本边界的模糊化,降低后续模型的学习能力。
局部离群因子(local outlier factor,LOF)能够科学地度量样本之间的离散性,是一种密度计量方法[11]。为增进SMOTE插值的有效性,应用LOF计算样本点与其领域密度的比值,从而选择合适的SMOTE插值点。该方法通过对样本点离群值的有效量化,避免对噪声点和离群度较高的点进行插值处理,减少了冗余数据的产生,从而有效保证了生成样本的质量。LOF-SMOTE基本原理,如图1所示。
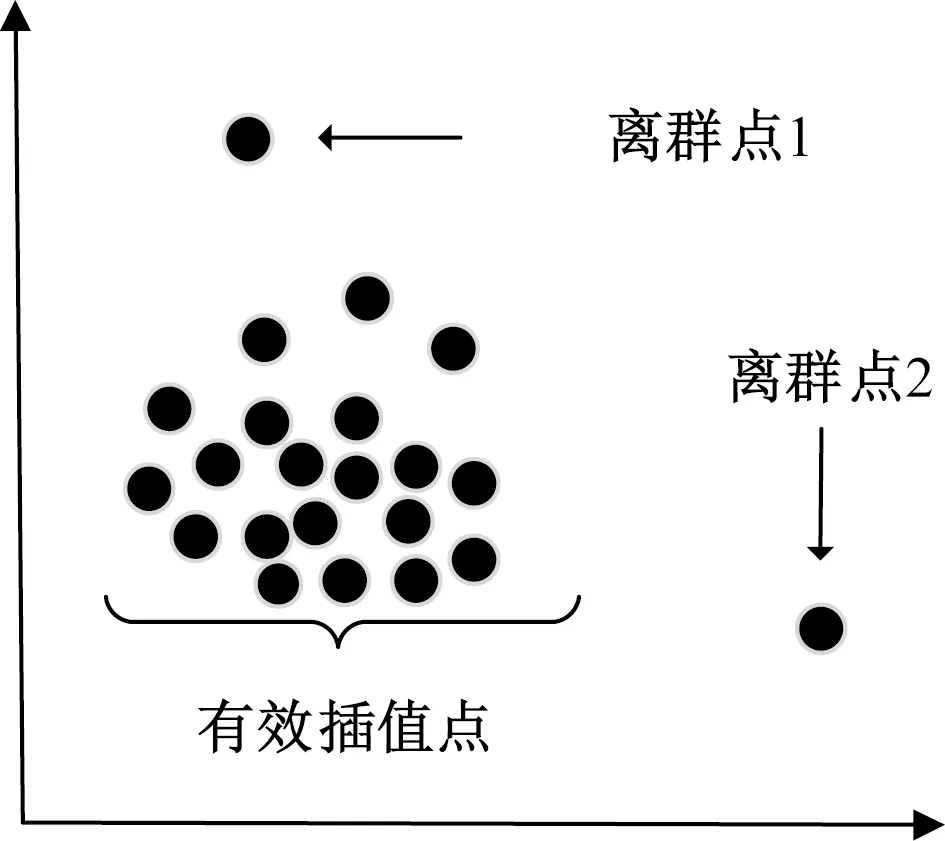
图1 改进SMOTE插值原理图Fig.1 Schematic diagram of improved SMOTE interpolation
LOF主要计算步骤如下所示。
(2)
(2)则可以得到计算每个样本的局部可达密度表达式为
(3)
(3)最终可得到每个样本的局部离群因子量化值表达式为
(4)
通过样本点离群值的科学量化,表现了样本点与样本群体之间的密度关系。若样本点离群度量值值远大于1,则表示该样本点为离群点,应避免对该样本点进行插值处理,从而可以有效筛选可插值点。
1.2 GA-XGBoost算法
1.2.1 遗传算法原理
遗传算法是基于模拟生物遗传和进化的一种全局概率优化算法,具有良好的适应能力和全局搜索能力,能够有效寻找模型的全局最优参数[12]。在遗传算法中,将j维决策空间向量X用j个Xj=[x1,x2,…,xn]组成的符号串表示。将每一个Xj当作一个可遗传基因,X则组成了问题可行解空间,所以最优化问题的解则是对染色体X的求解过程。
遗传算法的运算对象为群体M,M由多个个体组成,将第t代迭代群体称为p(t)。遗传算法迭代优化的过程主要通过群体p(t)的selection(选择)、crossover(交叉)和mutation(变异)完成,产生群体p(t+1),在迭代过程中不断输出相应的fitness(适应度),从而更新群体p(t)。经过算法不断的迭代过程,最终确定较优群体以及较优拟合度。具体的遗传算法迭代过程如流程图2所示。
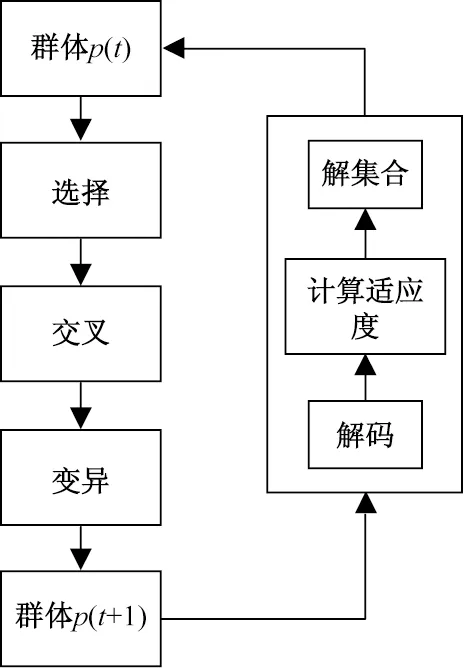
图2 遗传算法迭代原理Fig.2 Iterative principle of genetic algorithm
1.2.2 XGBoost原理
XGBoost算法由Chen等[13]提出,以分类和回归树(classification and regression tree,CART)为基础,被广泛应用于回归和分类问题。XGBoost算法目标函数由损失函数和正则化两项组成,表达式为
(5)
(6)
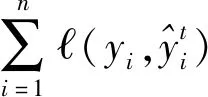
将XGBoost目标函数由泰勒公式展开,得到一个凸优化函数,因此为求出使目标函数达到最小值的ωj,对ωj求导并令导函数等于零可得
(7)
(8)
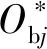
(9)
式(9)中:IL及IR分别表示左、右子树叶子结点集合。
1.2.3 融合遗传算法与XGBoost
融合遗传算法与XGBoost的分类预测模型流程如图3所示,其迭代原理如图4所示。
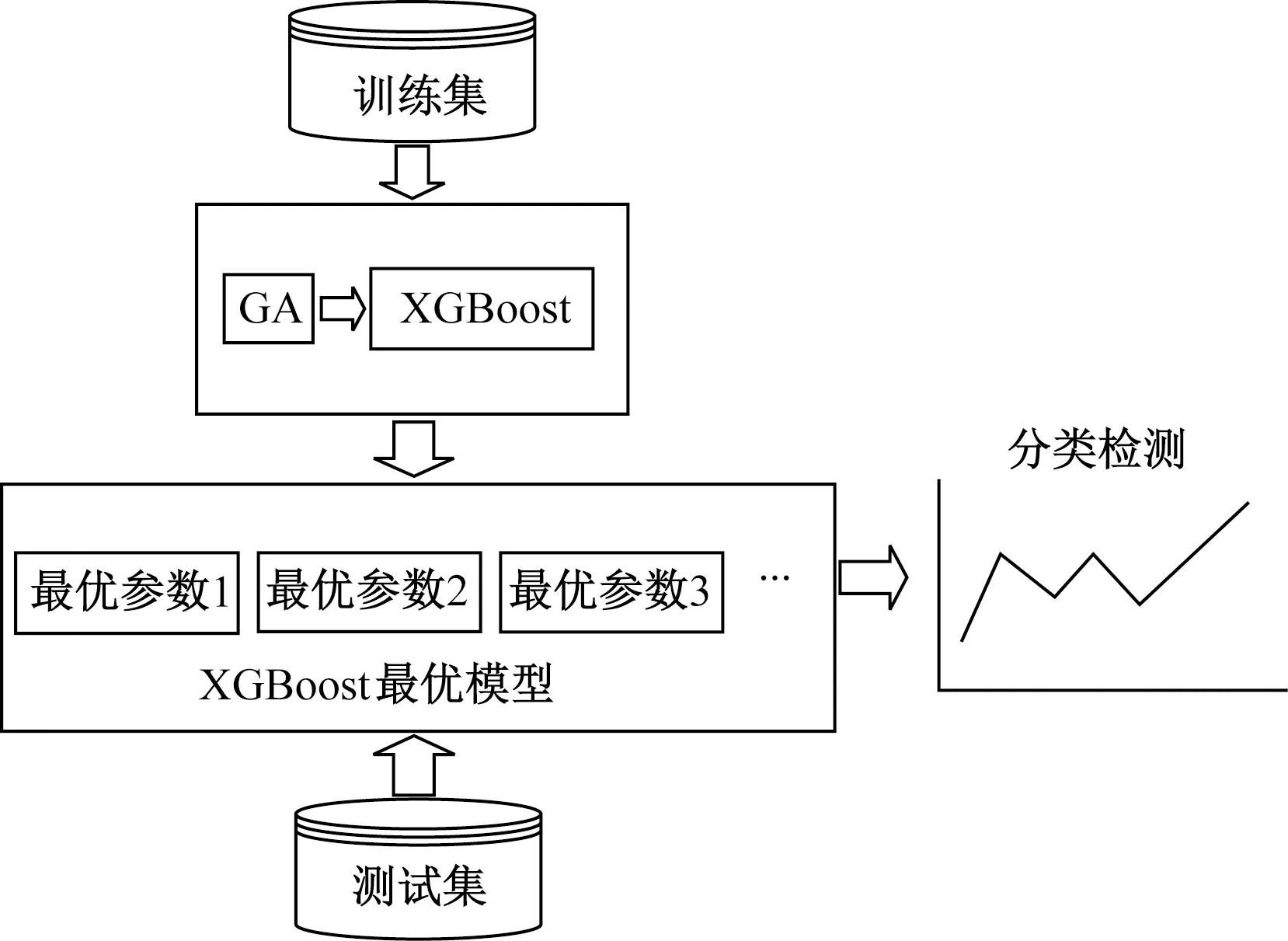
图3 GA-XGBoost分类预测模型Fig.3 GA-XGBoost classification prediction model
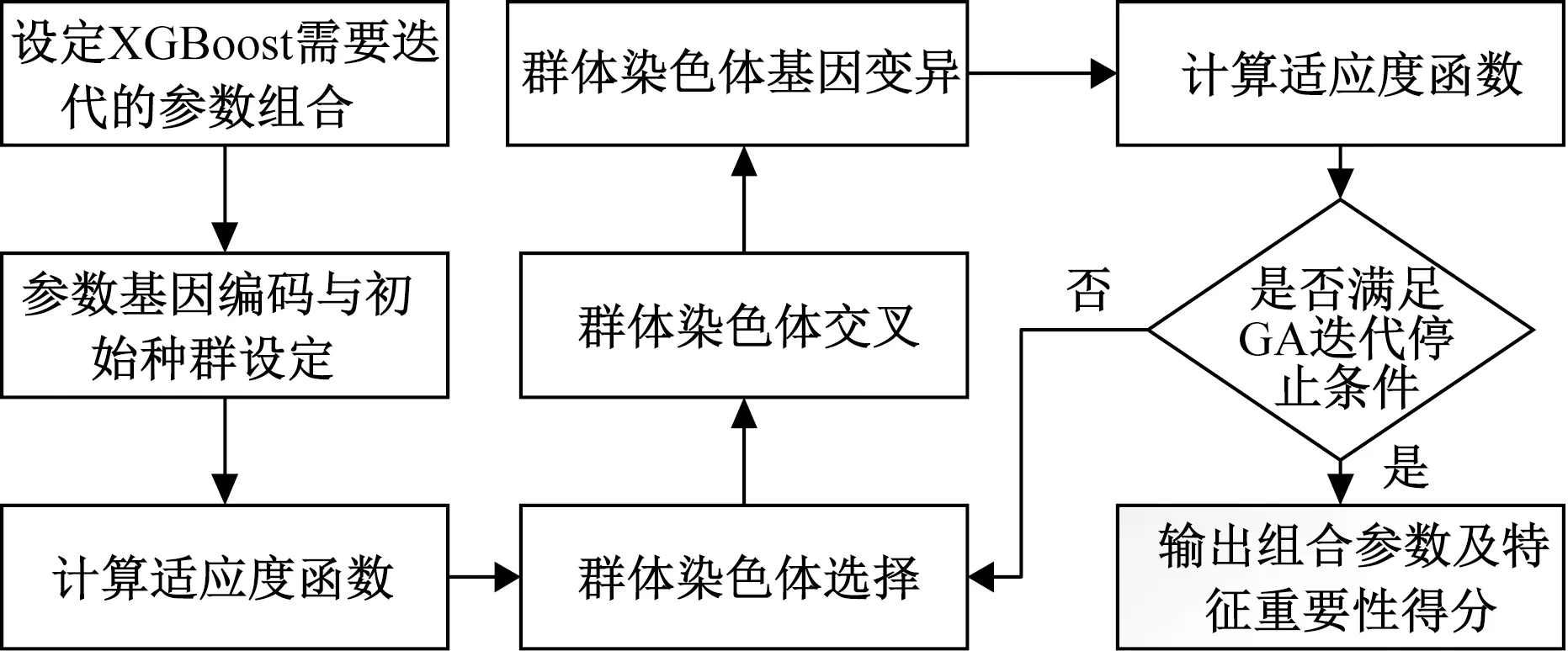
图4 GA-XGBoost迭代原理图Fig.4 GA-XGBoost iteration schematic
XGBoost基础模型超参数众多,人工调参过程繁琐。将遗传算法应用于XGBoost调参过程,经过遗传算法的不断迭代优化,能够解决XGBoost模型拟合度较差、特征学习收敛过慢的问题,有效增加模型的全局搜索能力,避免模型陷入局部最优。通常设定k为GA迭代的总次数,一次迭代需要的时间复杂度为ε,则至少需要k×ε时间复杂度。
1.3 改进SMOTE+GA-XGBoost模型实现
改进SMOTE算法利用过采样方法解决少数类样本数据量过少的问题,提升整体样本的均衡率。将改进SMOTE与GA-XGBoost算法进行组合,从数据和模型层面提升了机器学习对于不平衡数据的分类和检测能力。本文模型的整体架构主要由预处理模块、数据再平衡模块、特征学习模块组成,如图5所示。
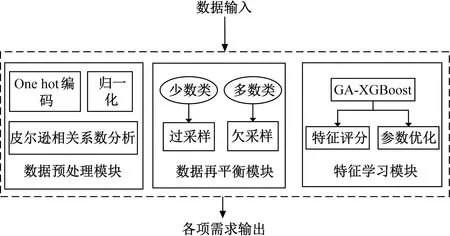
图5 数据分类整体架构Fig.5 Overall architecture of data classification
由于原始数据存在较多“异构”数据,所以对于原始数据的预处理是非常必要的。
2 数据集样本再平衡
为增加实验的参照性,采用公开的UNSW_NB15数据集,该数据集是综合性的网络入侵数据集,挑选的数据集中含有175 432条数据以及45个维度特征[14-16]。
2.1 数据预处理
对数值型数据和字符型数据进行数据清洗工作,处理缺失值和异常值,保证数据的一致性。采用one-hot编码对字符型数据进行预处理,将字符型特征转换为数字维度特征。为解决数据极差较大的问题,增加模型处理性能,对数据进行归一化处理,归一化公式为
(10)
式(10)中:X为原始数据列;Xmin表示原始数据列中的最小值;Xmax表示原始数据列中的最大值。
为避免处理后数据的维度过高,模型陷入维度诅咒(curse of dimensionality)的问题,使用皮尔逊系数对标签与数据特征进行相关性分析,计算公式为
(11)
式(11)中:cov(X,Y)表示数据列X与数据列Y样本之间的协方差;σX与σY分别表示数据列X与数据列Y样本的标准差;μX与μY分别表示数据列X与数据列Y样本的平均值;E表示求均值函数。
根据统计的皮尔逊相关系数筛选与标签相关系数值超过0.3的特征,达到降维的目的,并且避免了重复特征对于机器学习性能的影响。处理好的数据共有81 173条,15个特征维度。经数据预处理后的数据样本分析表如表1所示。
从表1可知,经过预处理后的UNSW_NB15数据集存在类别不平衡的问题,类别不平衡会导致分类模型偏向多数类样本,降低了少数类样本的分类精度,因此需要增加少数类样本实现样本的再平衡。

表1 预处理后样本分析表Table 1 Sample analysis table after pretreatment
2.2 样本再平衡
将预处理后的数据集划分为7份训练集和3份测试集,划分随机种子设定为10。训练集样本的再平衡如表2所示。
如表2所示,对于样本量少于300的数据进行自身样本量5倍的改进SMOTE过采样。为进一步平衡数据集,对于样本量在5 000~20 000的数据进行自身数据量0.5倍随机欠采样,对于样本量超过20 000的超量样本进行0.25倍自身数据量的随机欠采样。
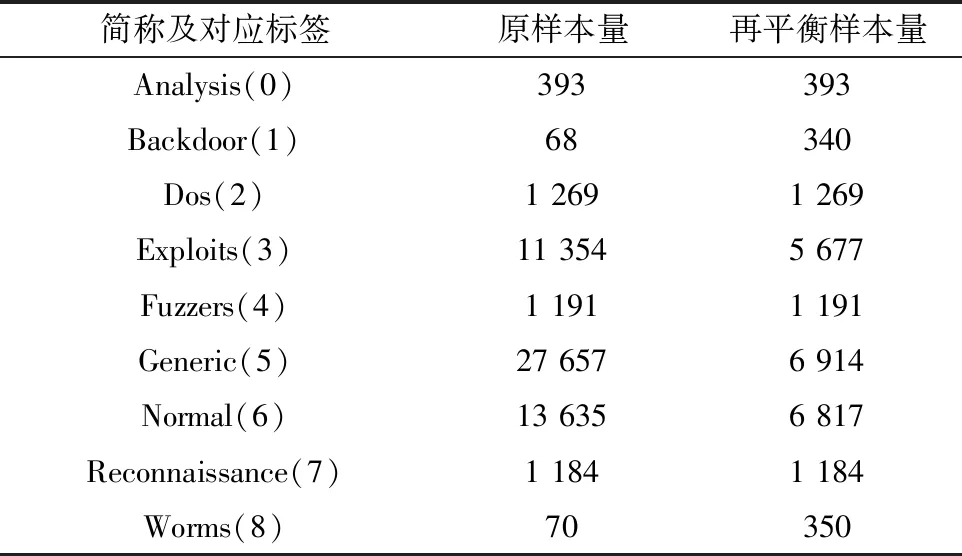
表2 训练集样本再平衡Table 2 Training set sample rebalancing
3 实验分析与验证
3.1 模型拟合
基于参数重要性原则,挑选XGBoost模型中学习率(learning_rate)、基学习器(n_estimators)、树最大深度(max_depth)、子采样比例(subsample)、惩罚项(gamma)这5个参数作为优化对象,在梯度提升树中,这些参数对于模型的性能具有重要影响[17]。
针对遗传算法的参数设置,编码方式设置为“BG”(二进制/格雷码),初始总群数(population_size)设定为10,迭代次数(generations)设定为40,交叉概率(crossover_probability)设定为0.8,变异概率(mutation_probability)设定为0.1。模型使用3折交叉验证,求解目标为测试集上拟合度较高的函数参数。
将再平衡训练集输入GA-XGBoost模型进行参数拟合。为表现拟合效果,输出遗传算法优化下XGBoost模型在再平衡训练集上的拟合情况如图6所示。
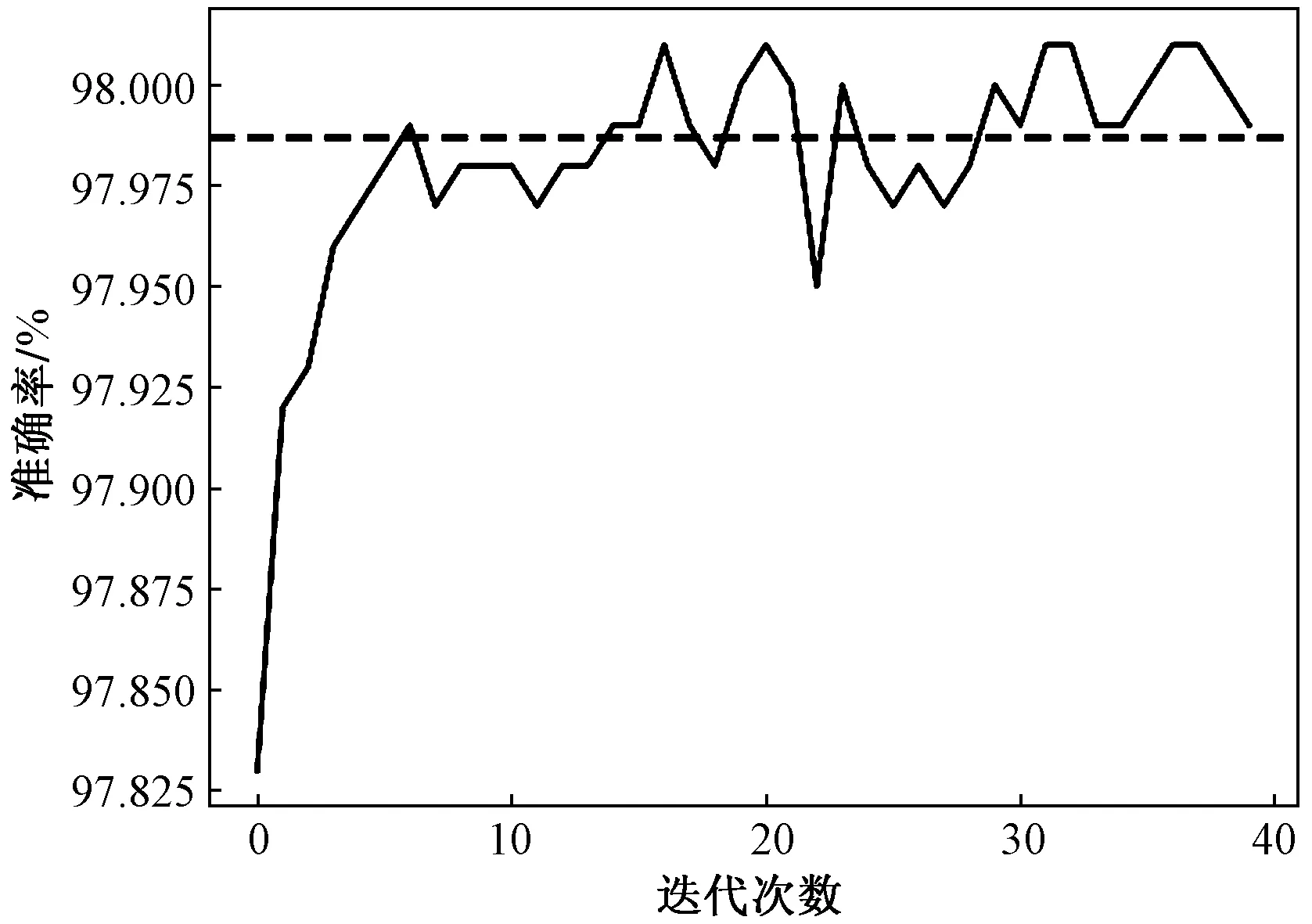
图6 模型在训练集上拟合情况Fig.6 Fitness on training set
从图6可知经过遗传算法的迭代优化,模型在再平衡训练集上渐趋波荡性稳定。列出XGBoost优化后的参数与原默认参数的对比表如表3所示。
表3中各个参数的作用在于,learning_rate控制迭代后更新权重的步长避免欠拟合和过拟合,n_estimators默认为“gbtree”(树模型),max_depth控制树最大深度从而限制模型过拟合,subsample通过子采样率限制模型过拟合,gamma控制节点斐裂最小损失函数下降值限制模型过拟合。从表3可知XGBoost参数的变动较大,默认值显然不满足对数据精确的需求,表明经过遗传算法优化的XGBoost模型拥有更好的拟合参数。

表3 XGBoost默认参数与优化参数对比Table 3 Comparison of XGBoost default parameters and optimization parameters
3.2 模型评估与对比
3.2.1 评估标准
以准确率(accuracy,ACC)、召回率(recall)、查准率(precision)、F1-score以及误报率((false negative rate,FNR)、漏报率(false positive rate,FPR)作为本文模型的评价标准。在对模型进行评估时,通常将模型的输出分为4类:真正常类(true positive,TP) 、真异常类(true negative,TN) 、假正常类(false positive,FP)和假异常类(false negative,FN)。则accuracy、recall、precision以及F1-score计算公式为
(12)
(13)
(14)
(15)
对于机器学习分类效果而言,正确率、召回率、查准率、F1-score越大,则分类效果越好。与召回率和查准率相对应的便是漏报率(FNR)和误报率(FPR),计算公式为
(16)
(17)
漏报率和误报率越低,则说明模型对于网络安全数据集的分类效果越好及可靠性越高。
3.2.2 评估结果分析
通过在再平衡训练集上的拟合,将测试集上的分类结果作为各个模型对比的依据。为控制变量,本文所提其他相关模型的训练集均为降维后未进行改动的训练集。
将本文模型与常用多层感知机(multi-layer perceptron,MLP),K近邻(K-nearest neighbor,KNN)、决策树、随机森林 (random forest,RF)以及原XGBoost模型进行比较分析[18],输出各模型对于各标签数据的查准率如表4所示。
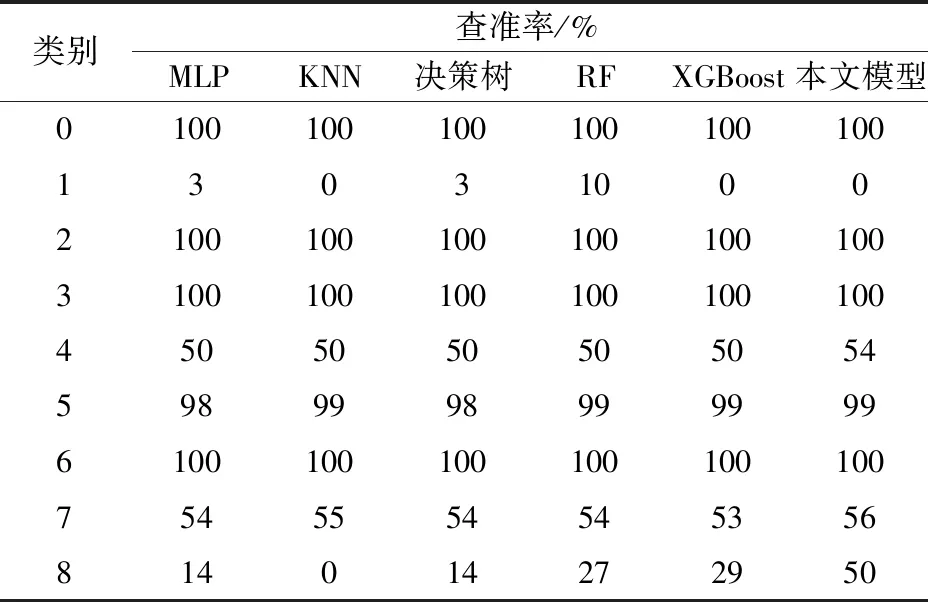
表4 不同模型查准率对比Table 4 Comparison of accuracy of different models
从表4可知,本文所提出的改进SMOTE+GA-XGBoost模型相对于其他模型对于各标签查准率最高,性能最平稳。但通过表4也可知,对于进行改进SMOTE插值的样本数据,只有标签8的准确率显著提升,而标签1的查准率相对于原XGBoost模型依然为0,说明对于标签1的分类效果并没有提升,根本原因还是在于样本量过少的影响,可见现实情况下,大量的数据样本依然是分类器工作的必然要求。
假设每一个类别数据都是公平存在的,设定总体F1-score和recall均为各个样本相应计算值和的均值,则输出各模型的平均召回率、平均F1-score、平均误报率、平均漏报率以及整体准确率如表5所示。从表5可知,本文提出的改进SMOTE+GA-XGBoost模型在测试集上的平均召回率、F1-score及 总的模型准确率与常用机器算法相比都为最高,并且拥有最小的平均漏报率和平均误报率。
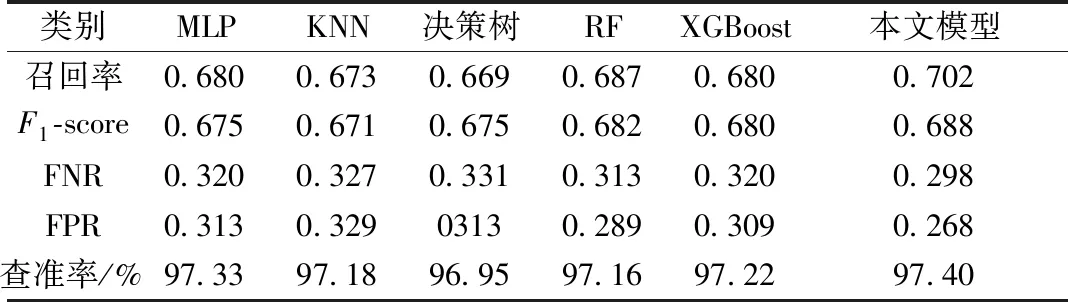
表5 各模型召回率、F1-score、准确率对比Table 5 Comparison ofrecall,F1-score and accuracy
另外,对比本文方法与SMOTE+XGBoost、随机欠采样(random undersampling,RS)+XGBoost等不平衡数据分类方法的机器学习性能,如表6所示。从表6可知,本文方法拥有较好的不平衡数据分类性能。
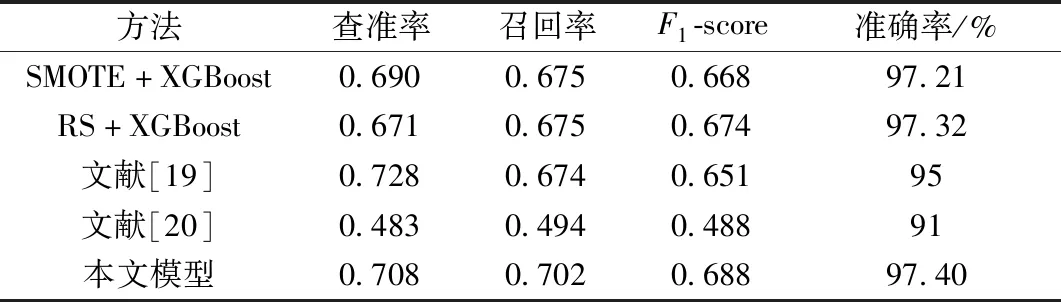
表6 不平衡数据分类模型对比Table 6 Comparison of unbalanced data classification models
综上,通过对比常用机器学习分类算法及相关不平衡数据分类方法,表明本文模型对于网络安全不平衡数据集的分类效果较好,综合性能较优。
3.3 特征子集的提取
网络维护人员对网络环境中的数据流信息进行分析时,需要对数据包的特征对象加强甄别以捕获网络威胁[21]。XGBoost作为一种极端梯度提升树,能够有效对特征进行重要性评估,输出训练集特征重要性得分排序性得分图如图7所示。
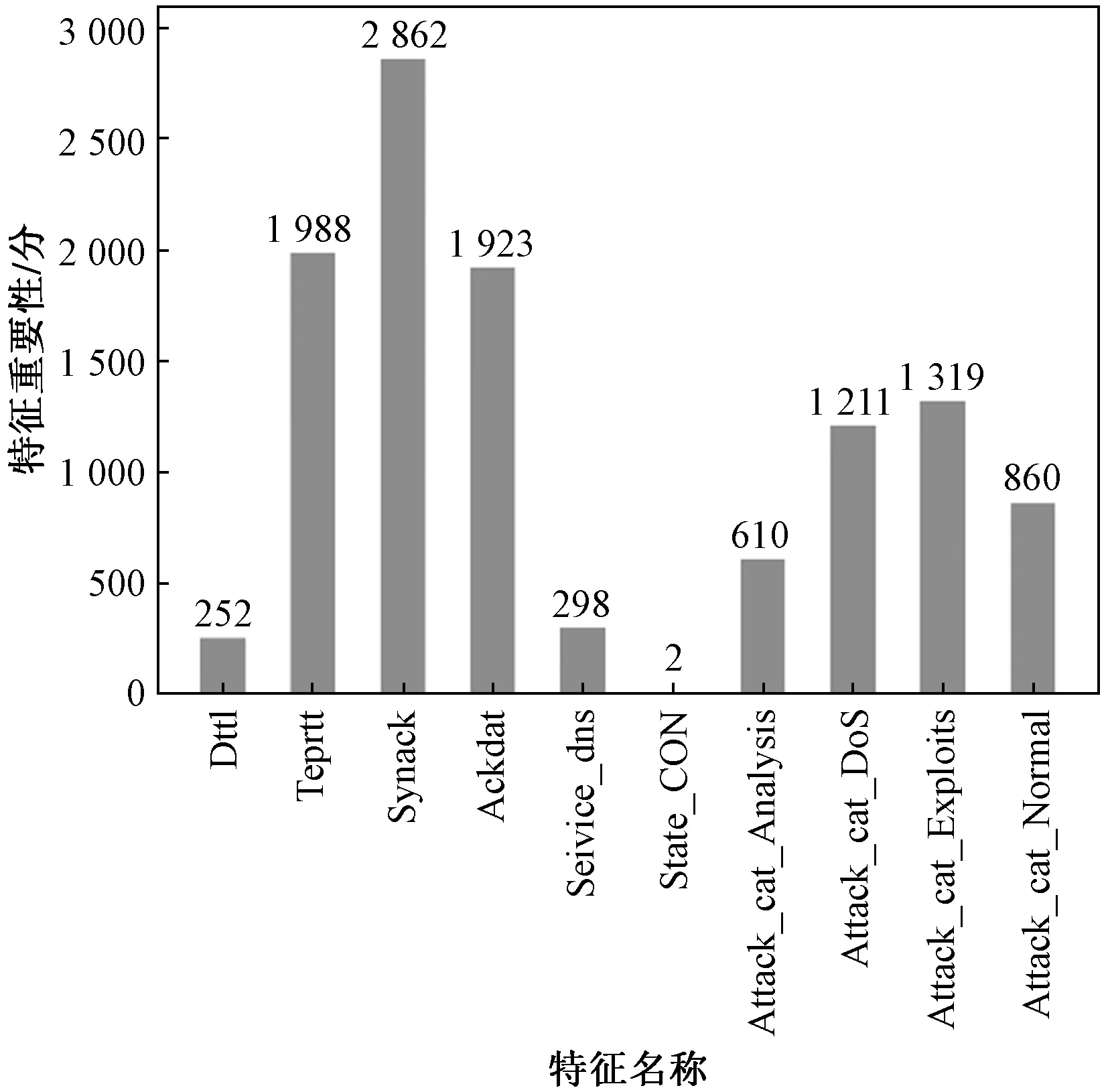
图7 各特征重要性得分Fig.7 Importance score of each feature
图7中,将特征在提升树中作为分裂节点的次数作为评价标准,剔除得分为0的特征。由特征得分图7可知,再平衡训练集中存在10个特征作用于模型最后的准确分类。其中synack(TCP的SYN和SYN_ACK数据包之间的时间)、tcprtt(TCP的“synack”和“ackdat”之和)以及ackdat(SYN_ACK和TCP的ACK数据包之间的时间)为辨别数据为异常攻击数据时最重要的3个特征。在通信过程中,这3个特征为TCP/IP协议簇正常工作的重要表现形式,表明TCP/IP协议簇对网络安全运行的重要性。
模型学习能力,一定程度上也受到特征数量的影响,为进一步确定特征子集数量对于总体准确率的影响,对特征重要性进行排序,设置阈值比例输入模型,输出总体准确率变化如图8所示。

图8 不同子特征数量准确率Fig.8 Accuracy of number of different sub features
从图8可知,随着特征子集的增加,模型整体准确率是逐渐提高直至稳定,收敛速度随着特征子集的增多逐步放缓。在特征子集数量为8时,模型整体准确率达到了初始平衡点,表明这8个特征对网络数据流的正确分类起到了重要作用。
通过图8曲线的收敛速度,进一步将这8个特征划分为4个关键特征和4个重要特征,即synack、tcprtt、ackdat、attcak_cat_Exploits(漏洞攻击)为关键特征,attcak_cat_Analysis(分析攻击)、attcak_cat_Dos(拒绝服务攻击)、attcak_cat_Normal(正常数据攻击)、service_dns(域名解析服务)为重要特征。关键特征对于网络数据流的正确分类具有关键作用,进一步验证了上述特征重要性得分的正确性,而attcak_cat_Exploits为操作系统自身的漏洞所导致的攻击,所以操作系统本身的漏洞处理以及TCP/IP协议簇的稳定运行是网络安全运行的关键因素。重要特征则是外部链接或者攻击行为所产生的数据流信息特征,造成操作系统权限的丢失及破坏正常的DNS(域名解析)服务等,这表明稳固正常的系统服务以及增加网络防护也至关重要。
3.4 模型的分析与应用
为进一步分析本文算法模型在实际场景数据下应用的有效性,将本文模型与辽宁省石油化工行业信息安全重点实验室的工业信息安全平台结合。通过在工业安全平台控制站中引入木马程序(该木马程序通过收集主机注册表和漏洞信息以及复制重要工控配置文件以数据流的形式在网络环境传播),使用wireshark监听内存和网络环境中的数据包信息,工业信息安全平台如图9所示。

图9 工业信息安全平台Fig.9 Industrial information security simulation platform
在该木马程序运行时间内总计收集1 000条数据,经过特征工程处理后,其中234 条数据标记为异常数据,剩余的766条数据标记为正常数据,正常数据标签为0,异常数据标签为1。将数据集划分7份为训练集,3份为测试集,计算相应的Acc、F1-score如表7所示。
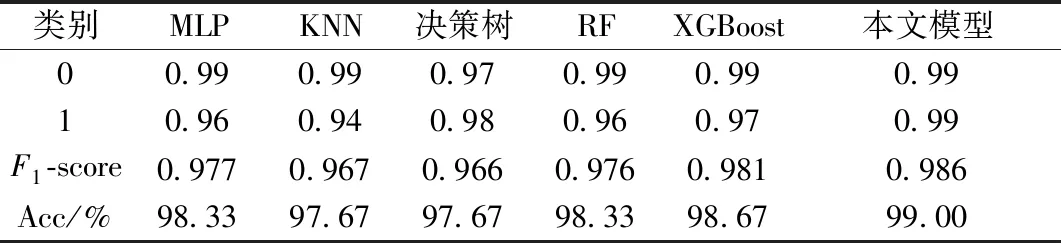
表7 实际场景应用结果分析Table 7 Analysis of application results in actual scenarios
从表7可知,本文的改进SMOTE+GA-XGBoost模型在实际的二分类数据下依然能够有效增加模型对于异常数据的检测率,有较高的单项检测率以及F1-score,改善了模型对于少数类样本数据的检测效果。
4 结论
针对网络安全数据集多存在样本不平衡、特征复杂度较高的问题,提出一种改进SMOTE+GA-XGBoost不平衡数据分类方法。基于UNSW_NB15数据集进行样本多分类实验,结果表明,对比不同的机器学习分类方法,本文模型拥有较高的分类准确率(97.4%)和平均F1-score(68.8%),符合不平衡网络安全数据分类的要求。使用本实验室工业信息安全平台提取的数据集进行二分类验证,模型依然有较高的分类准确率(99%)及平均F1-score(98.6%),证明了本文模型的有效性和可行性。另外,通过特征子集提取的研究,得出了影响网络数据流正确分类的重要表现特征,这为网络安全运维人员对网络环境的监控和解决网安安全事件提供了新的方向与途径。
虽然本文模型提升了整体分类准确率,但对于样本中某些少数类的识别还未达到理想结果,因此为不平衡网络安全数据样本建立更为准确的分类模型,进一步总结攻击行为的规律将是下一步需要研究的工作。
