正骨机器人术前视觉导航方法与实验验证
2023-03-15曹家勇吴世豪马千里
曹家勇,吴世豪,马千里
(上海应用技术大学机械工程学院,上海 201418)
实验研究表明,在对患者进行手术治疗之前配合正骨治疗,纠正软组织错位,能够对患者的术后恢复起到良好的促进作用,缩短患者住院时间[1]。但传统中医正骨复位主要依赖骨科医生完成,给临床医生造成了巨大的工作负担与安全隐患。
随着机器人产业的快速发展,机器人辅助手术治疗已逐步在临床应用,为实现临床疾病微创、精准、个性化治疗提供了一个新的研究方向[2],相比于传统人工正骨,现代骨科医用机器人可以提高手术操作的精确性、稳定性、可重复性,从而辅助医生完成一些以往无法实现的手术,促进患者的术后恢复。
郭悦等[3]结合六自由度并联机器人模拟中医正骨手法,针对简单骨折的辅助复位可行性进行了验证。北京航天航空大学研发的天玑骨科机器人是国内首个获得医疗器械注册证的手术机器人产品[4]。这些应用都极大地推进了医疗机器人的发展。
而伴随着骨科机器人的发展,骨科机器人的智能化要求也在不断提高,根据不同患者个体的实际情况制定相应的手术方案是未来骨科机器人的研发趋势之一[5]。而这需要骨科机器人具有较强的自主导航能力,目前骨科机器人主要通过光学视觉进行手术导航,但国内外目前的相关研究主要集中在骨科外科手术等领域[6]。针对结合传统中医方法的正骨机器人视觉导航方案相对空白,而能够正确抓握患者脚部是中医正骨方法实施的重要前提。
因此,现基于正骨机器人在面对患者腿部受固定装置约束状态下,针对脚部目标的术前定位和导航问题,提出一种基于立体视觉的脚部目标点云位姿计算方法,通过固定在机器人末端的RGB-D相机获取目标点云数据,利用点云数据计算得到脚部目标的位姿数据,并结合任务需要对数据进行修正。同时,基于此方法设计机器人引导系统,利用修正的脚部目标点参数进行机器人的视觉引导实验,验证计算结果的准确性和可靠性。
1 系统结构
基于双目视觉的机器人引导系统由Python编写的上位机作为控制模块和Intel RealSense D455深度相机作为视觉模块组成。选用Universal Robot公司的UR5协作机器人,控制模块通过URScript控制机器人,URScript是UniversalRobot公司在Python基础上研发的语言,可在脚本层上控制UR机器人。
系统整体硬件结构如图1所示,深度相机固定在机器人末端,采集图像并通过双目立体匹配获取得到深度图并转换为点云数据,基于点云数据获取脚部目标位姿参数经过修正后发送至下位机(机器人控制器),从而驱动机器人末端件以运动至贴合脚部目标,完成正骨手术前的机器人定位和引导工作。

图1 机器人视觉引导系统Fig.1 Robot vision guidance system
系统工作流程图如图2所示,对系统进行相机标定和手眼标定获取标定参数用于点云生成和目标位姿计算,通过深度相机获取深度图并转化为点云数据。通过点云数据处理在保留脚部点云特征的同时降低点云密度,处理后的点云数据的位姿信息经过参数修正后转换为机器人基坐标系下的目标位姿信息,利用URScript将目标位姿信息转为机器人控制指令,通过Socket通信发送至机器人控制器,完成机器人末端从起始点到脚部目标的视觉引导。
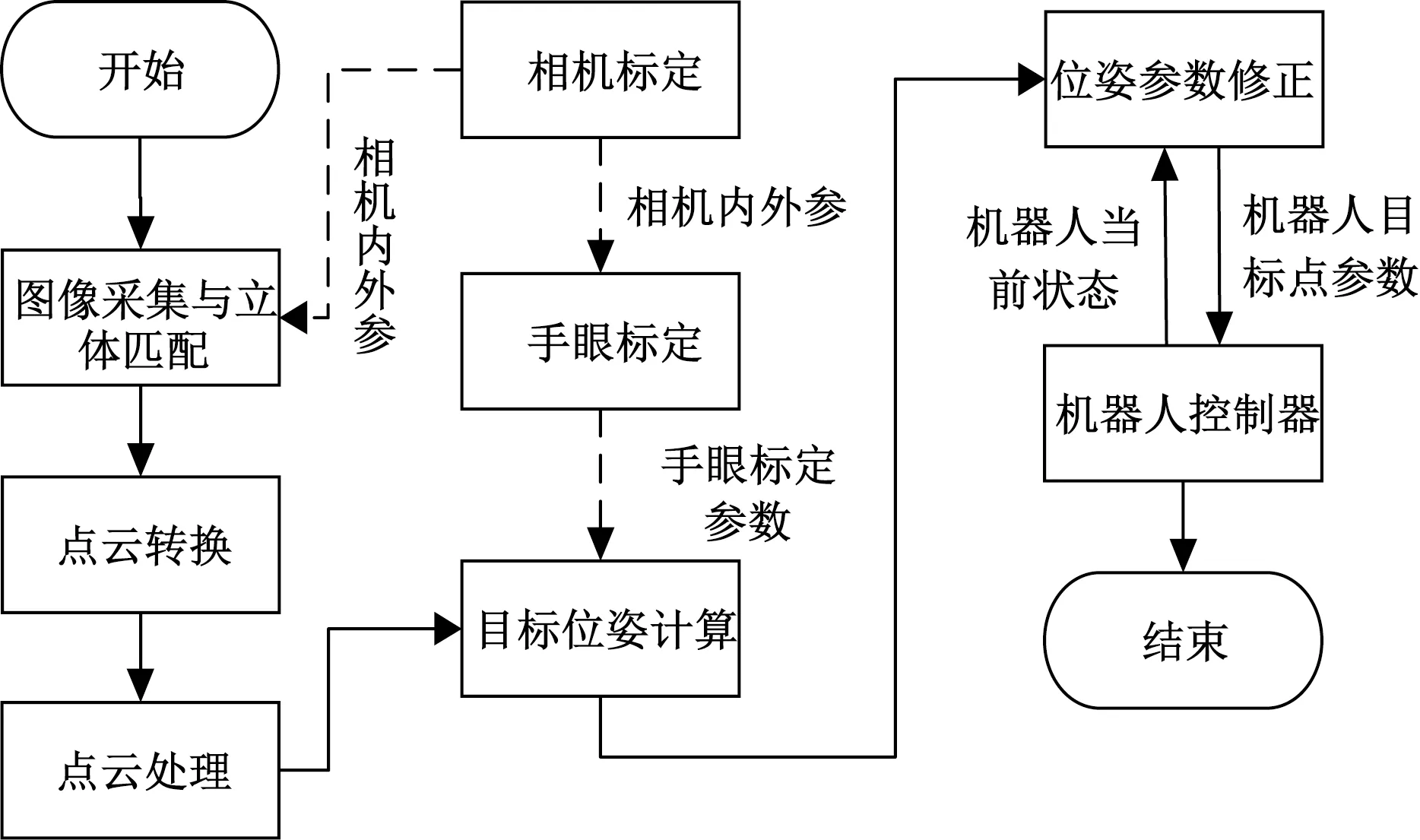
图2 机器人视觉引导系统流程图Fig.2 Flowchart of robot visual guidance system
2 点云数据处理
使用Intel RealSense D455深度相机获取深度信息计算得到点云数据,该深度相机尺寸小巧,内置完整的深度处理模块,同时提供成熟的接口便于程序开发调用,因此在机器人、物体识别和三维重建等领域都有很好的应用[7]。结合深度信息和相机内外参可以计算出像素点的三维世界坐标,这样便可通过深度图获取点云数据。
直接获取的点云数据除了包含所需的脚部目标点云外,还包含着大量的背景点云和噪声数据。因此需要对原始点云数据进行处理,去除多余的点云,保留主体点云,点云处理流程如图3所示。
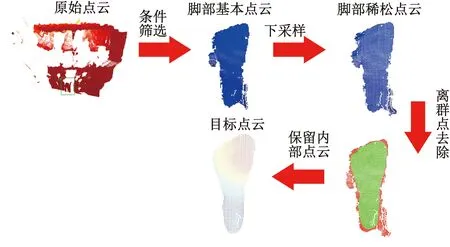
图3 点云处理流程图Fig.3 Flowchart of point cloud processing
2.1 点云条件滤波
针对深度相机采集的原始点云数据中包含大量背景点云的问题,为了快速找到目标区域,采用点云条件滤波方法[8]去除冗余的背景点云数据,突出目标点云的信息。由于正骨手术中患者腿部往往固定在固定支架上,脚部目标相对于机器人末断的相机距离固定,因此可以利用条件滤波截取一定范围内的点云数据作为感兴趣区域,在此区域内进行目标定位。空间坐标轴各方向的范围阈值设置可表示为
(1)
式(1)中:(Xmin,Xmax)、(Ymin,Ymax)、(Zmin,Zmax)对应各方向范围阈值,相关阈值可以根据实际条件计算获得。
滤波前后感兴趣区域的点云数量、形状、位置均未发生变化[9]。经过条件滤波处理后,点云数量得到了极大降低。
2.2 点云下采样
为了提高后续计算速度,在保留脚部目标特征信息的基础上,利用体素滤波算法[10]根据点云数据创建一个最小三维体素栅格,根据点云分布情况计算出小立方体栅格边长L,根据L的长度将三维体素栅格划分为m×n×l个小栅格,划分完成后将点云数据放入到对应的小栅格。对于不包含点云的小栅格进行删除,对于包含点云数据点的小栅格,将距离小栅格重心最近的点云数据点保留并删除小栅格内其余点云数据点。该方法简单高效,容易实现,不需要建立复杂的拓扑结构可实现对点云数量进行整体简化,从而达到快速点云计算的目的[11]。每个小立方体栅格中,三维栅格重心的计算公式为
(2)
式(2)中:n为小立方体栅格中点云个数,(xi,yi,zi)为小立方体栅格的第i个点坐标。体素滤波前后的点云整体形状、位置和大小均保持不变,但下采样后点云在保留目标特征的基础上数量大幅降低。
2.3 统计离群点去除
为了去除因为深度相机采集产生的稀疏离群点、点云边缘噪声以及条件滤波留下的部分残留离群点。采用统计离群点算法[12]对离群点进行去除。该算法通过对点云周围的K近邻点进行分析来判断该点是否为离群点进行删除。如果当前点距离K近邻点的平均距离与整个点云数据点之间的平均距离的差值大于一个标准差,则将该点视为离群点。邻域平均距离的概率密度函数为
(3)
式(3)中:假设每一点的邻域符合高斯分布,其形状是由均值σ和标准差μ决定。li为任意点的邻域平均距离。经过统计离群点过滤后,脚部目标边缘的离群点得到有效滤除,得到相对规则的目标点云用于后续的位姿计算。
3 点云位姿计算
3.1 基于PCA的目标点云位姿估计
主成分分析法(principal component analysis,PCA)是一种以特征向量分析多元统计分布的方法,表征了数据内部的主要分布方向,PCA处理可看作求一种线性投影,使数据最大方差的方向和新空间的轴对齐。PCA的工作就是从原始的空间中顺序找出一组相互正交的坐标轴建立PCA坐标系,其中,第一坐标轴与原始点云数据最大分布的方向重合,第二坐标轴是与第一坐标轴正交点云数据最大分布的方向,第三坐标轴是与第一、第二坐标轴正交点云数据最大分布的方向,在PCA中可视为三个相互垂直的主成分向量。因此PCA常用于点云配准中且具有较好的效果[13]。
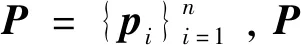
COV=(P-μ)T(P-μ)
(4)
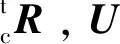
(5)
式(5)中:世界坐标系o的描述矩阵为三阶单位矩阵。
解得的脚部目标点云PCA坐标系如图4所示,此时,PCA坐标系相对于相机坐标系的姿态描述可以写为
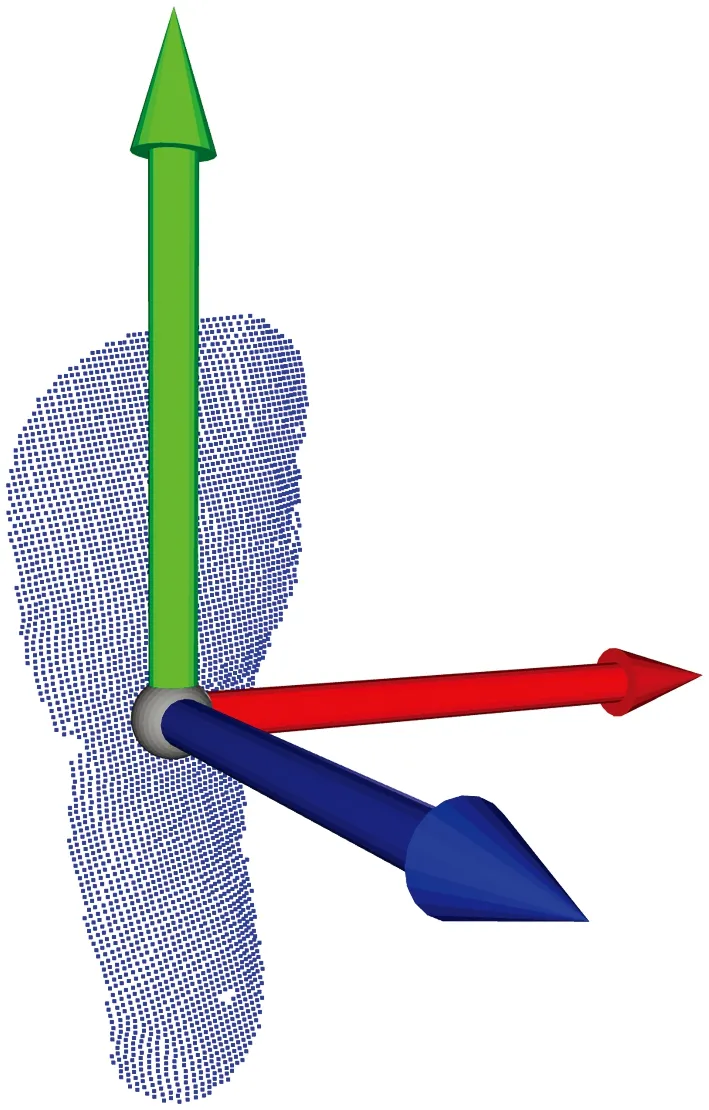
图4 PCA坐标系方向向量Fig.4 PCA coordinate system direction vector
(6)
由此,便可得到以相机坐标系到脚部目标点云PCA坐标系的变换矩阵。
3.2 参数修正
由于正骨手术中患者脚部受伤的特殊性,在机器人引导过程中不能对患者造成二次损伤,因此需要对引导目标点的初始参数进行修正,在机器人引导过程中碰撞检测,保证机器人引导过程的安全性和可靠性。
OBB包围盒是Gottschalk在1996年首次使用,如图5所示,红色包围盒为轴向包围盒AABB(axis aligned bounding box),绿色包围盒为方向包围盒OBB(orientation bounding box)。由于OBB方向上的任意性,其比AABB和包围球更加紧密地逼近物体,具有更高的检测精度。
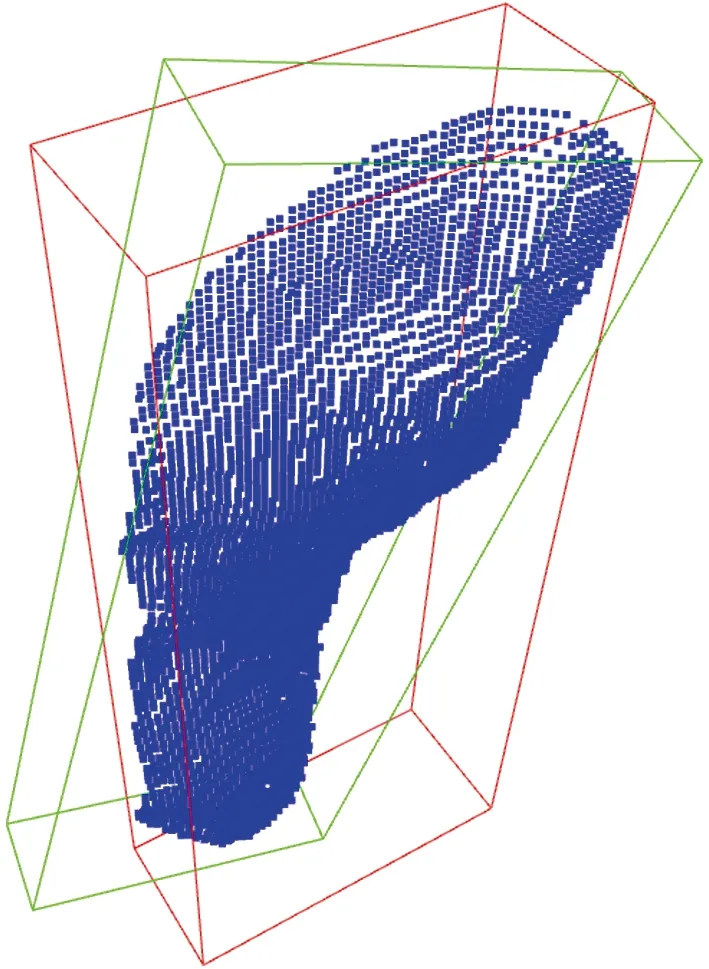
图5 基于脚部目标点云的AABB和OBBFig.5 AABB and OBB based on foot target point clouds
利用OBB包围盒可以对目标点的Z轴坐标进行修正,避免在机器人移动过程中,末端件与脚部目标发生碰撞,对患者造成二次伤害。
考虑到针对足踝的正骨手术需要机器人将患者脚部沿足踝转动中心扭动,需要对引导目标点设置在足踝转动中心的轴线上。由于人体脚底踵心与足踝转动中心基本处于同一位置,故选择踵心作为引导目标点。结合基于中国在1965年和1968年进行的两次大型脚形测量的成年男、女及儿童脚型规律(表1)[14],可以得到脚部踵心相对于脚部的位置范围。

表1 全国成年男、女及儿童脚型规律Table 1 National foot patterns for males,females and children
综合上述目标点坐标修正后,机器人引导的目标点位置如图6所示。
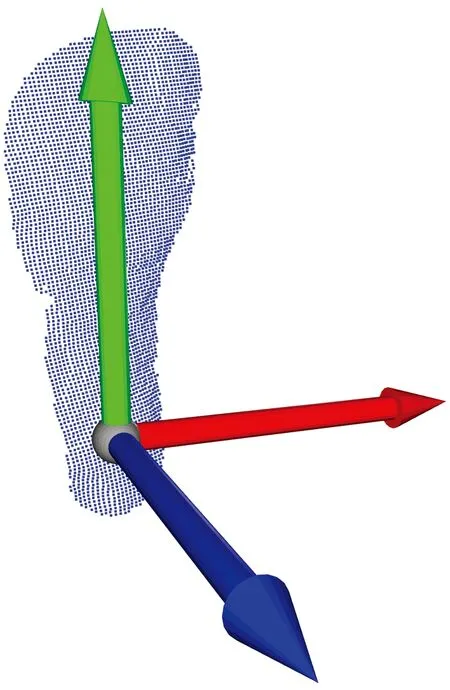
图6 参数修正后目标点位置Fig.6 Target point position after parameter correction
4 位姿转换
为了根据获得的脚部目标位姿结果完成对正骨机器人的引导工作,需要建立完成的坐标关系转换,将相机坐标系下的脚部目标模型位姿转换为机器人基坐标系的位姿描述。在进行机器人目标位姿转换前,系统需要对整个机器人系统进行手眼标定,对像素坐标系和机器人末端坐标系之间的关系进行求解,进而完成手眼标定。
根据相机相对于机器人安装位置的不同,可以分为眼在手外(eye-to-hand)和眼在手上(eye-in-hand),眼在手外即摄像头安装在手臂之外的部分,与机器人的基座(世界坐标系)相对固定,不随机械臂的运动而运动;而眼在手上是摄像头安装在机械臂上,会随着机械臂的运动而发生运动。本文引导系统采用eye-in-hand的模式,深度相机固定安装于机器人末端下部,其手眼标定原理如图7所示。标定时,相机固定安装在机器人末端,标定板相对于机器人基座固定。
图7中,b表示机器人基坐标系,e表示机器人末端坐标系,c表示相机坐标系,k表示标定板坐标系,A表示机器人基坐标系b到机器人末端坐标系e的转换关系,B表示机器人末端坐标系e到相机坐标系c的转换关系,C表示相机坐标系c到标定板坐标系k的转换关系,D表示机器人基坐标系b到标定板坐标系k的转换关系。此时则有系统坐标系间关系为
D=ABC
(7)
式(7)中:相机坐标系c到标定板坐标系k的转换关系C可通过相机标定求得。机器人基坐标系b到机器人末端坐标系e的转换关系A可通过获取机器人末端位姿得到。机器人的末端位姿描述描述通常有两种方式:①基于关节坐标值的显示,以各轴相对于上一级的轴的旋转角来显示当前位姿;②基于直角坐标系的显示,使用机器人末端的工具坐标系和设定于基座的直角坐标系来显示当前位姿[15]。
本系统选择第二种表示方式,其中机器人末端中心位置采用(X,Y,Z)描述,在UR5机器人系统中,机器人末端相对于机器人基坐标系的姿态描述采用旋转矢量法表示,因此需要将旋转矢量转为旋转矩阵,等效轴角坐标系如图8所示。
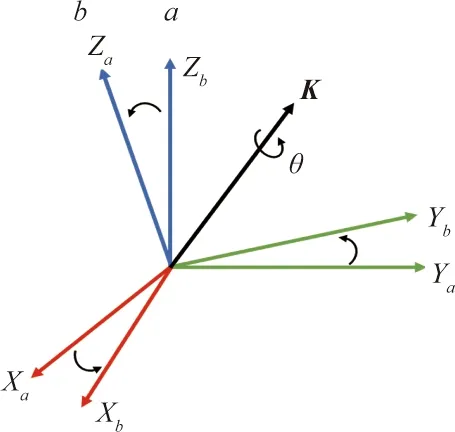
图8 等效轴角坐标系Fig.8 Equivalent axis angle coordinate system
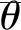
(8)
因此,机器人基坐标系b到机器人末端坐标系e的转换矩阵可表示为
RK(θ)=
(9)
式(9)中:S表示正弦函数;C表示余弦函数;Kθ=1-cosθ。
而机器人末端坐标系e到相机坐标系c的转换关系B就是手眼标定需要解决的问题,这也决定了手眼标定的本质就是数学问题。
如图9所示,理论上,令机械臂运动两次,得到两个不同的机器人位姿,并保证标定板在相机视野范围内,此时根据式(10)可得
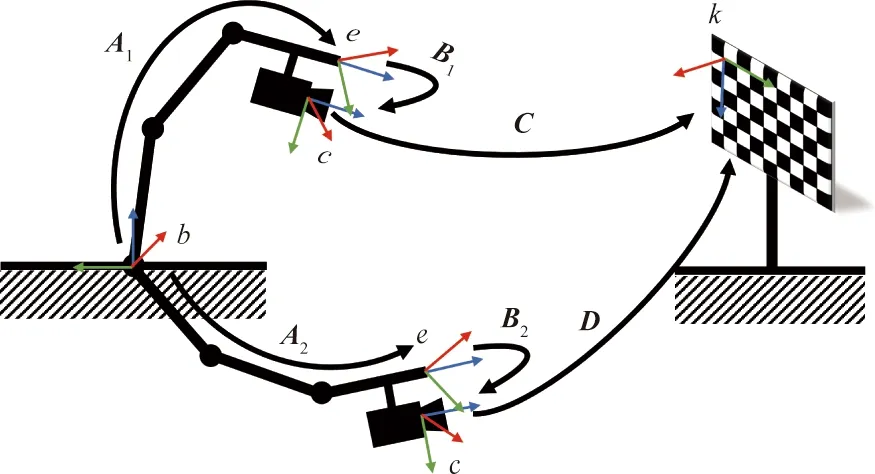
图9 两个不同位置的标定系统示意图Fig.9 Schematic diagram of a calibration system at two different locations
D=A1BC1=A2BC2
(10)
经过变换,式(10)可写为
(11)
于是,手眼标定又转化为“AX=XB”的问题。关于“AX=XB”问题的求解目前存在许多方法,此处采用Tsai两步标定法求解[16],Tsai两步标定法需要一个已知的标定块作为空间参照物,利用空间参照物与图像特殊点的对应关系标定相机。
标定过程如图10所示,基于机器人操作系统 (robot operating system,ROS)下利用开源手眼标定功能包easy_handeye完成手眼标定工作。由于X矩阵求解需要经过机器人两次不同的相对位置变换得到,位置变换过程中旋转轴不平行,因此容易出现偶然误差[17]。为了消除这种偶然误差,在实际标定过程中对机器人的位姿进行了17组变换,采集得到了相机在17个不同位置的图像用于手眼标定。
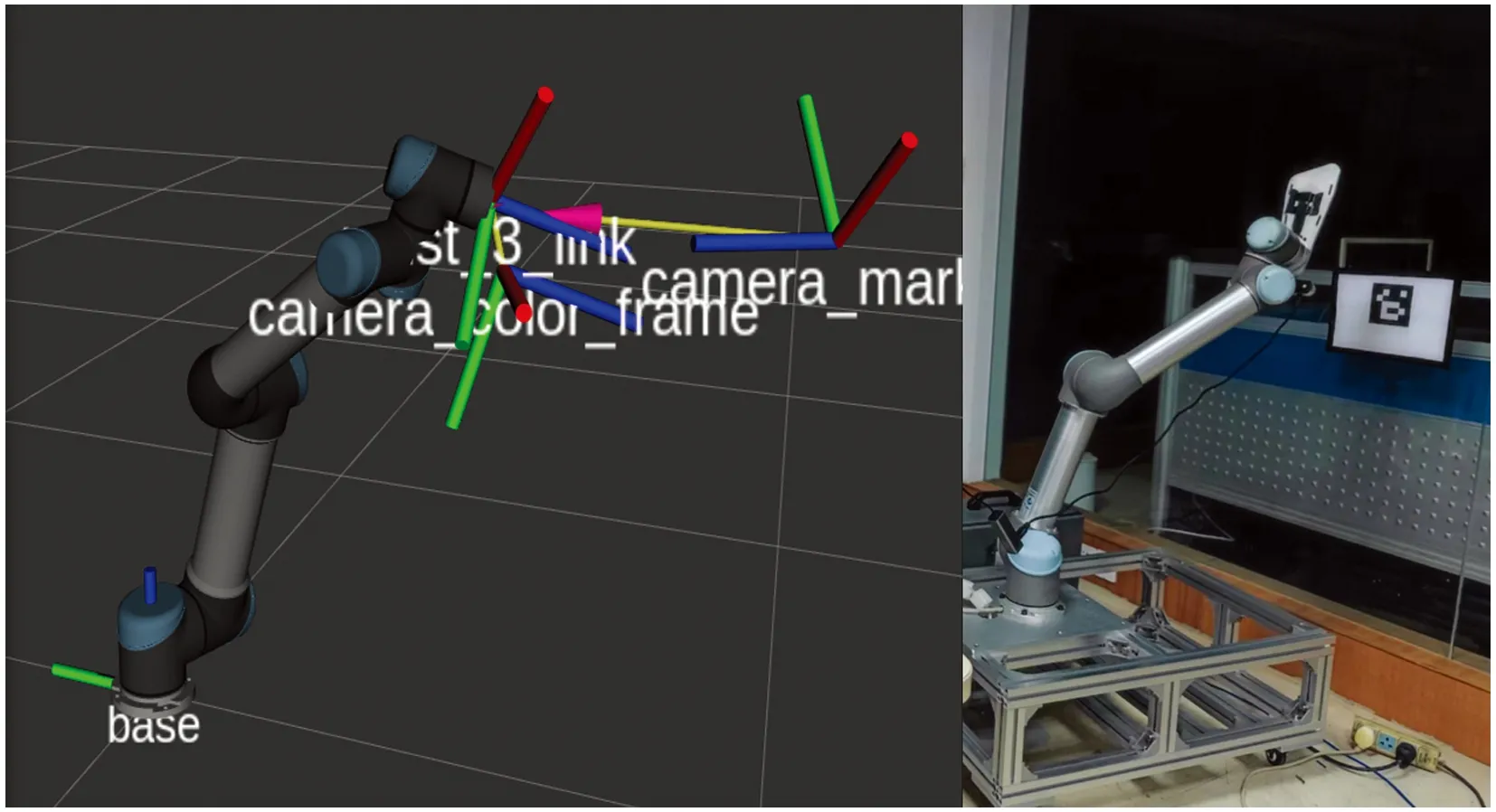
图10 机器人手眼标定Fig.10 Robot hand-eye calibration
经过手眼标定后获得的相机机器人末端坐标系e到相机坐标系c的转换关系如表2所示。

表2 手眼标定参数Table 2 Hand-eye calibration parameters
完成手眼标定后,可得到相机坐标系c到标定板坐标系k的转换关系C,其可描述为
(12)
类似的,在进行机器人视觉导航时(图11),则具有对应的坐标转换关系。
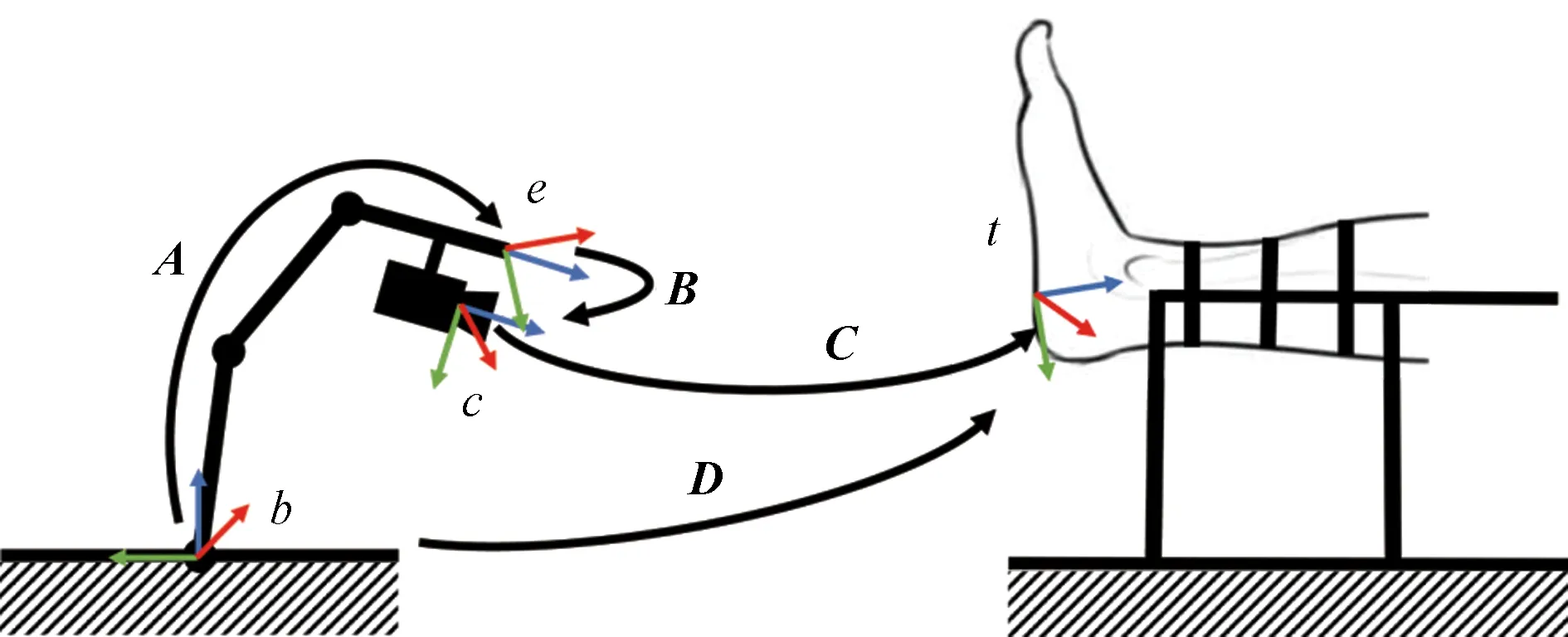
图11 视觉导航中的坐标转换Fig.11 Coordinate transformations in visual navigation
综合上述各坐标变换关系,有
(13)
将坐标系旋转变换用旋转质量表示,则有
(14)
故
(15)
综上可得,发送给机器人控制器的脚部模型引导位姿为(Xd,Yd,Zd,Rx,Ry,Rz)。
5 实验验证
利用获取的基于相机坐标系下的目标点云数据位姿信息,经过相机标定和手眼标定转换为基于机器人基坐标系下的目标位姿信息并作为目标点发送给机器人控制器,完成机器人的视觉引导工作。
实验针对本文方法的有效性和可靠性分别进行验证。针对方法有效性,在相机视野下,对不同姿态的脚部目标进行视觉定位与引导,并选取手动引导的姿态参数作为期望定位结果进行比较。定位效果如表3所示。
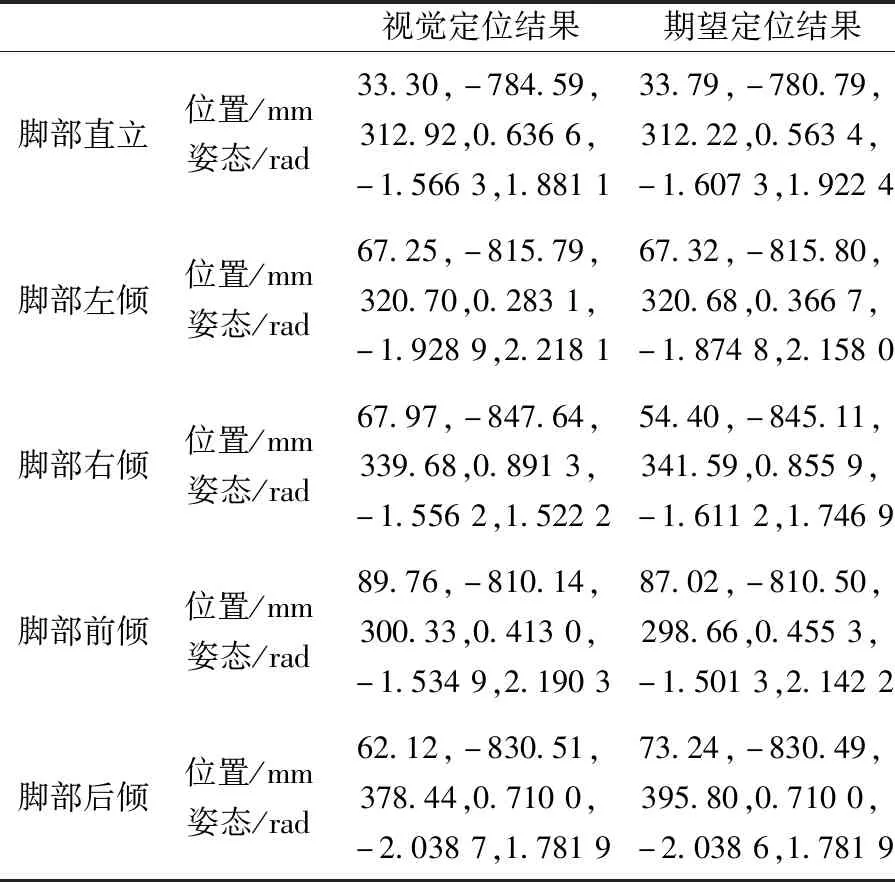
表3 不同姿态下的目标定位结果Table 3 Arget positioning results in different postures
多次实验结果表明,针对不同姿态的脚部目标,系统可有效完成视觉定位和引导,经由视觉引导的机器人末端件与脚部模型贴合度较高,且未与脚部模型发生碰撞造成脚部模型发生偏移。视觉引导机器人末端件与脚部模型的贴合效果如图12所示。

图12 视觉引导贴合效果Fig.12 The fit effect of visual guidance
为了更加直观地观察定位效果,对定位结果人为增加间隙,增加间隙后的机器人末端姿态与脚部模型姿态的符合程度由图13可以看出,视觉定位结果与期望定位结果存在一定误差,但定位效果符合定位期望。

图13 定位姿态示意图Fig.13 Schematic diagram of positioning posture
针对定位结果可靠性,通过对同一位姿目标进行20组重复定位,实验结果如图14所示。
从图14中可看出,20组重复定位结果分布较为集中,同时,对20组重复定位结果进行结果统计,从表4中可以看出,定位结果受外部环境影响的随机波动较小,证明了方法的可靠性和稳定性。
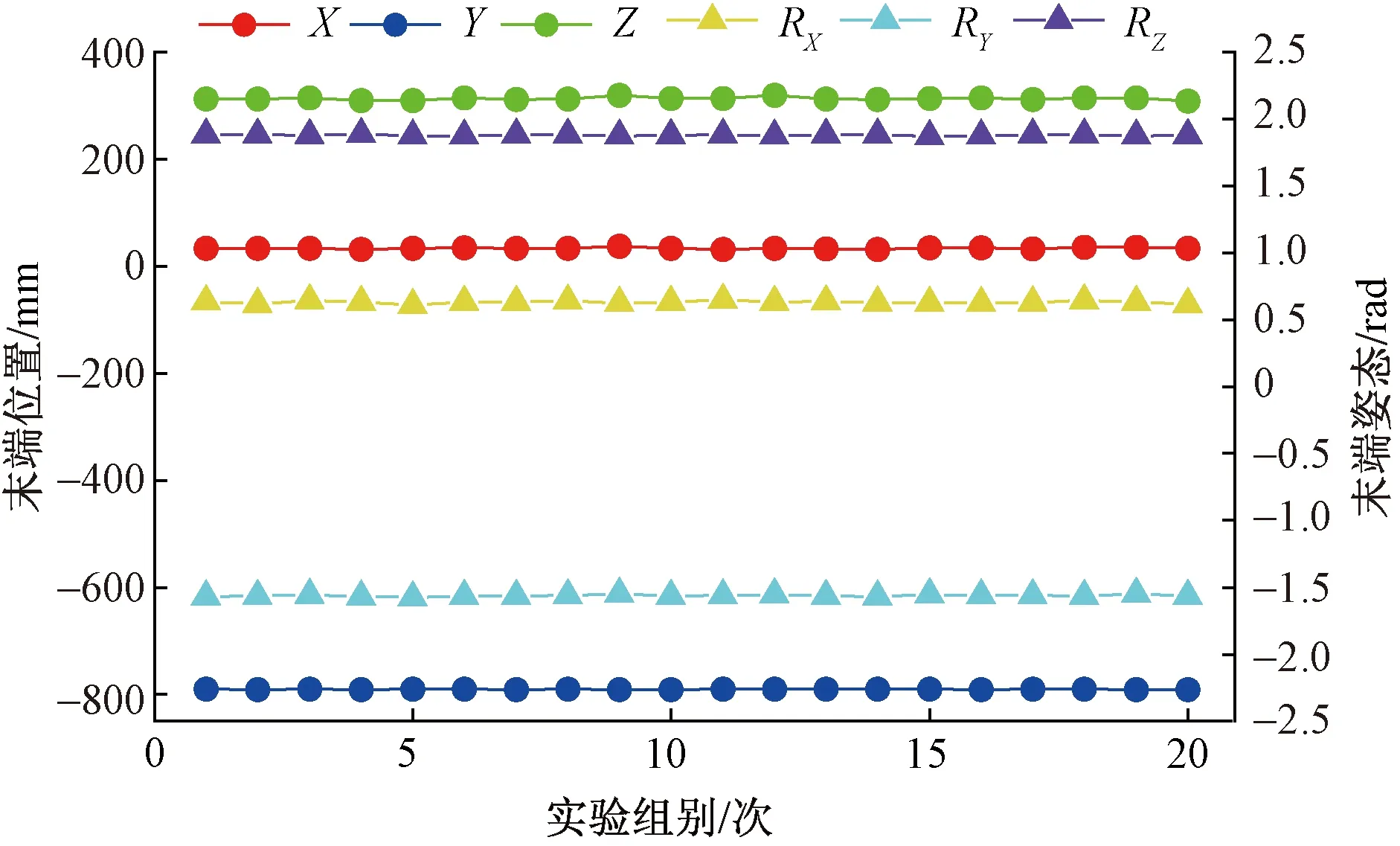
图14 20组重复定位结果Fig.14 The results of 20 sets of duplicate positioning
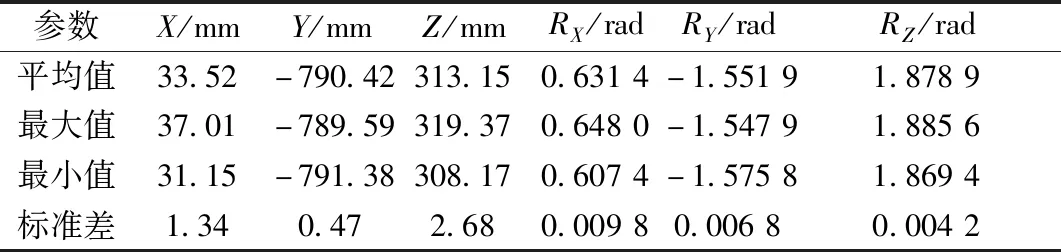
表4 重复定位结果Table 4 The experimental result of duplicate positioning
综上对实验结果的分析可得,通过本文方法对脚部目标的定位结果符合人体主观判断,结果一致性较高,相比与传统方法更具灵活性和鲁棒性,定位结果受外部条件的影响较小,基于定位结果的机器人引导工作具有较高的成功率。
经误差分析,定位结果的误差主要由于相机标定和手眼标定过程中标定板的制作误差和相机的安装误差导致,该误差可通过进一步提高标定版的制作精度和相机与机器人的安装精度来弥补,同时可以从视觉引导的工作流程上进行进一步的优化。
6 结论
基于正骨机器人在面对患者腿部受固定装置约束状态下,针对脚部目标的术前定位和导航问题,提出一种基于Intel Realsense D455深度相机的脚部目标点云位姿计算方法,并对方法有效性和可靠性进行验证。结合实验相关结果可得以下结论:
(1)针对不同姿态下的脚部目标,视觉定位结果具有较高的准确度和一致性,根据视觉定位结果引导的机器人末端件与目标脚部模型贴合效果良好,视觉引导效果符合预期判断。
(2)本文方法的提出,实现了正骨手术中患者脚部的术前自动定位引导,解决了正骨机器人的术前导航问题,提高了正骨机器人的智能化。
(3)本文方法的应用满足正骨手术中机器人目标定位的实际需求,为结合中医正骨机器人进一步实际应用提供了理论与实践基础。
