基于XGBoost算法的机会型创业预测研究
2023-03-13陈成梦黄永春吴商硕钱春琳
陈成梦,黄永春,2,吴商硕,钱春琳
(1.河海大学 商学院,江苏 南京 211100;2.河海大学 社会科学研究院,江苏 南京 210098)
0 引言
我国持续推进“大众创业、万众创新”战略,旨在缓解新常态下的经济下行压力,促进更高质量、更加充分的就业[1]。中共二十大报告提出,完善中国特色现代企业制度,弘扬企业家精神,加快建设世界一流企业。近年来,我国各级政府制定并出台了一系列鼓励创新创业的政策文件,因而全民创新创业热情和积极性被空前激发。创业模式逐渐从生存型创业向机会型创业转变,中国的机会型创业活动蓬勃发展。《全球创业观察(GEM)2017/2018中国报告》显示,中国机会型创业占创业活动的比例超过60%,较2002年的40%有较大提升,但与发达国家仍然存在一定差距。与难以找到工作、被迫进行创业的生存型创业不同,机会型创业由潜在商业机会驱动,具有较强的成长意向和较高的技术含量,可以催生更多就业机会,创造更高的经济收益,改善经济结构[2-3]。特别是在当前面临日趋复杂严峻的国际环境以及全球新冠肺炎疫情冲击的情况下,机会型创业有利于驱动中国从效率驱动型经济体向创新驱动型经济体转型,跨越中等收入陷阱,实现经济强国目标[4]。因此,如何有效甄别机会型创业、针对性培育机会型创业具有重要意义。
Shane等[5]指出,要加强以机会为中心的创业研究,包括机会的来源,发现、评估和利用机会的过程以及个人。现有研究发现,机会型创业受创业自我效能、受教育水平、社会资本等个人因素[6],社会精英家庭、人力残缺家庭等家庭因素[7],经济自由度、政府规模、腐败和税收政策等外部社会环境的影响[8-9]。虽然学者提出了机会型创业的一些影响因素,但相对零散。单一分析框架无法充分解释机会型创业,忽视机会型创业者的心理特征和动机可能难以揭示机会型创业背后真正的驱动因素。计划行为理论作为社会心理学领域具有重要影响力的行为预测理论,可以有效预测创业意向及后续创业行为,为机会型创业这种经过理性思考判断而作出的行为决策提供较为全面有力的理论解释框架。
创业活动是一个复杂的社会问题,受非线性网络反馈系统的动态特性影响[10],因而很难预测。与此同时,传统回归方法的显著性水平受样本量影响,回归系数受测量尺度影响,因而难以有效评估影响因素的贡献,关于影响因素的相对重要性仍存在争议[11]。机会型创业涉及的特征变量较多,各变量与机会型创业之间不仅仅局限于单一的线性关系,可能存在较为复杂的非线性关系[12]。从方法层面看,现有关于机会型创业的文献多基于传统计量方法研究变量间的关系问题,使用单一模型进行实证检验,没有引入人工智能算法,造成实证结果片面化,难以实现全面检验和有效预测。随着大数据时代的到来和计算机信息技术的发展,人工智能算法在越来越多的研究和应用领域日益受到关注,但对创业的关注相对较少。Obschonka等[13]认为,尽管存在一定挑战,人工智能和大数据正在颠覆与创业相关的工业、商业管理和创新等领域,并提出将人工智能与机会型创业相结合,关注这一新型创业研究及应用。作为人工智能领域的核心方法之一,机器学习算法在统计学理论基础上,让机器模拟人类进行自我学习并从海量信息中深度挖掘隐藏规律和信息,可以很好地拟合非线性关系,检测输入数据中交互的模糊性,适用于处理变量间较为复杂的关系(Gerasimovic等,2018;彭玉芳等,2022)。机器学习算法已逐渐运用在竞争力评价(张虎等,2016)、人才甄选(刘昕等,2019)、专利分类(Liu等,2020)、GDP增长预测(Yoon,2021)等方面。近几年,创业学者开始使用机器学习算法研究创业问题。例如,Koumbarakis等(2022)使用XGBoost、随机森林、支持向量机等机器学习算法预测新企业孕育结果。因此,XGBoost等机器学习算法可以预测个体是否进行机会型创业并区分不同影响因素的重要性,为传统计量方法难以解决的预测和重要性判别问题提供支撑。
基于此,本文基于计划行为理论,从主观规范、行为态度、知觉行为控制3个方面,选择成就导向、风险承担、媒体宣传、公众认可、创业自我效能、机会识别和关系感知,并结合年龄、受教育水平、性别、家庭规模和家庭收入5个人口统计学特征共12个特征变量,以2018年全球创业观察数据库中等收入国家的个体数据为研究样本,基于XGBoost算法构建机会型创业预测模型并识别关键影响因素。在此基础上,基于准确率、精确率、召回率和F1值4个评估指标,将预测结果与支持向量机、随机森林和逻辑回归3种机器学习算法进行对比。研究可为政府和外部投资者有效识别潜在的机会型创业,政府针对性培育机会型创业者,个体积极从事机会型创业活动提供理论指导和实践参考,进而有利于推动中国跨越中等收入陷阱,向创新驱动型经济体转型,促进经济高质量发展。
1 理论基础与文献回顾
计划行为理论认为,个体有目的、有计划的行为受意向支配,从事某一行为的意向受主观规范、行为态度和知觉行为控制影响[14]。计划行为理论作为社会心理学领域具有重要影响力的理论,也被广泛应用于商业和管理领域,用于解释和预测意向与行为(Armitage等, 2001)。计划行为理论被应用于创业意向和创业行为研究主要体现在3个方面:第一,直接探讨主观规范、行为态度和知觉行为控制对创业意向的影响。例如,基于计划行为理论,聚焦不同群体,探究行为态度、主观规范和知觉行为控制对农民工返乡创业意向(熊智伟等,2011)、大学生创业意向(Al-Jubari等,2019)、学术创业意向(茅路洒等,2022)的影响。第二,探讨行为态度、主观规范和知觉行为控制通过创业意向的中介作用对创业行为的影响。例如,王季等[15]构建学术创业意愿形成和学术创业行为转化的两阶段整合模型,发现学术创业意愿受行为态度、主观规范和知觉行为控制影响,在情境和个人因素的调节作用下可以转化为实际创业行为。第三,将重点放在实际的创业行为上,利用计划行为理论直接预测创业行为,而不是创业意向。以往实证研究大多聚焦创业意向,而忽视了对实际创业行为的研究。Souitaris等[16]指出,创业意向与创业行为之间存在一定距离和时间差,具有创业意向的个体不一定会产生创业行为;Dézsi-Benyovszki等[17]基于计划行为理论,从行为态度、主观规范和知觉行为控制3个方面实证分析罗马尼亚早期创业行为和内部创业行为以及二者间的差异,以测试计划行为理论在预测创业行为方面的适用性;朱亚丽等[18]从行为态度、主观规范和知觉行为控制3个方面对员工内部创业行为进行组态分析;Shabir等[19]发现,行为态度、主观规范和知觉行为控制对沙特阿拉伯早期创业活动具有显著正向影响。
将计划行为理论纳入研究的创业学者认为,建立、发展企业以及与创业相关的其它行为都是有计划的行为[20]。个体是理性经济人,机会型创业是经过理性思考判断、有目的和计划的行为决策,因而计划行为理论适合作为本研究的理论指导框架。参考Dézsi-Benyovszki等[17]、朱亚丽等[18]、Shabir等[19]利用计划行为理论直接预测创业行为的做法,本研究进一步聚焦机会型创业行为,从主观规范、行为态度和知觉行为控制3个方面对个体是否进行机会型创业这一问题进行理论分析。
首先,行为态度是指个人对某一特定行为的结果进行评估而产生的积极或消极评价[14]。针对机会型创业的行为态度可以分为成就导向和风险承担两个方面[18]。机会型创业更多受价值实现和自由独立驱动,而不是生活所迫。具有高成就导向的个体更加注重获得社会尊重与社会地位,因而更愿意从事机会型创业活动。创业作为一种高压力、多挑战、重负荷的活动,使个体面临诸多风险与不确定性,尤其是机会型创业[21]。失败恐惧会阻碍创业活动,因此,当个体对创业失败风险持积极乐观态度、勇于面对创业活动的高风险性与高不确定性时,会更积极参与机会型创业活动[22]。其次,主观规范是指个体在综合各种社会压力等外部环境因素后产生的主观认知[14]。社会规范是客观存在的,而个体对社会规范的感知是主观构建的。公众认可和媒体关注等社会规范对创业活动的约束力和影响力甚至超过某些正式制度因素[23]。当创业被认为是一种理想的职业选择且被媒体广泛宣传报道时,个体感受到良好的创业氛围和创业合法性,进而有利于资源获取和知识共享,降低创业进入门槛和退出壁垒[24],从而激发机会型创业行为。最后,知觉行为控制是指个体感知到对特定行为掌控的难易程度[25],主要包括自我效能和感知可控两个方面[26]。创业自我效能是指个体对自己完成任务和发挥作用以取得创业成果能力的信心[27]。具有高创业自我效能的个体相信自己具有创业所需的能力和经验,成为创业者的意愿更强,更有可能进行机会型创业。创业感知可控是指个体感知到对创业机会、创业关系等具有一定控制能力[18]。创业机会感知是一种重要创业能力和开始创业活动的关键因素(DeTienne等,2007),识别到高价值商业机会的个体更有可能参与机会型创业活动。当感知到一定创业关系支持时,个体可以与外部利益相关者建立更牢固的情感契约和信任,集聚、整合和利用稀缺、有价值的创业信息和创业资源,从而提高机会型创业的合法性,为机会型创业活动提供支持(Svendsen等,2004)。
2 研究设计
2.1 研究方法
机器学习主要包括监督学习、无监督学习和强化学习,其中,监督学习探究输入数据与目标结果间的关系,因而采用监督学习方法研究机会型创业问题。集成学习不是单独的机器学习方法,而是通过构建并结合多个机器学习器完成任务。Boosting方法通过分步迭代构建模型,各个预测函数顺序生成,在每一步迭代时构建弱分类器,从而弥补已有模型的不足(王重仁等,2019)。
XGBoost全称为eXtreme Gradient Boosting,是由陈天奇(2014)提出的基于Boosting集成学习算法的极端提升树模型。其基本思想是通过不断进行特征变量分裂生成树,每生成一棵树,都重新学习一个新函数,拟合上次预测的残差,从而不断提高学习质量[28]。XGBoost算法适用于机会型创业预测研究,主要体现在3个方面:首先,个人是否进行机会型创业本质上属于一个二分类问题,该算法可以处理是否进行机会型创业这一分类问题。其次,XGBoost算法具有良好的性能,是对GBDT算法的一种改进,以CART作为基分类器,还可支持线性分类器,其损失函数采用二阶泰勒展开,同时用到一阶和二阶导数,为控制复杂度,在目标函数中加入正则项,支持列抽样,可以降低过拟合,减少计算,具有灵活性强、精度高、运算效率高等优点。因此,该算法可以处理机会型创业变量间的复杂关系和大规模数据,提高机会型创业的预测效果和运行效率[29]。最后,XGBoost算法可以评估自变量的相对重要性,反映自变量对机会型创业影响的大小。
2.2 数据来源
全球创业观察(Global Entrepreneurship Monitor,GEM)由美国百森商学院与英国伦敦商学院发起,是研究创业者特质、创业环境、创业行为等全球创业问题的权威数据来源[30],包括成年人口调查数据库(Adult Population Survey,APS)和国家专家调查数据库(National Expert Survey,NES)。由于GEM的完整数据集在数据收集3年后才对公众开放,因而本文基于2018年APS数据库获取数据。该数据库能够反映个体创业特点、动机和抱负以及社会对创业的态度等信息。同时,全球竞争力报告将国家收入组划分为低等收入国家、中等收入国家和高等收入国家3种类型。为使研究结论对中国等中等收入国家有借鉴意义,控制国家层面特征,确保案例总体之间具有充分的同质性[31]。因而,本文选取包括中国在内的中等收入国家作为研究样本,使用2018年APS数据库个体层面数据,剔除数据缺失的样本,最终获得12 829条个体数据。
2.3 评价指标
进行机会型创业的个体为主要研究人群,将其定义为正类。本文具体采用准确率、精确率、召回率和F1值4个评价指标衡量模型预测效果,通过混淆矩阵对4个评价指标进行计算,TP和TN分别表示对进行机会型创业样本和不进行机会型创业样本预测正确的样本数,FN和FP分别表示对进行机会型创业样本和不进行机会型创业样本预测错误的样本数,混淆矩阵如表1所示。
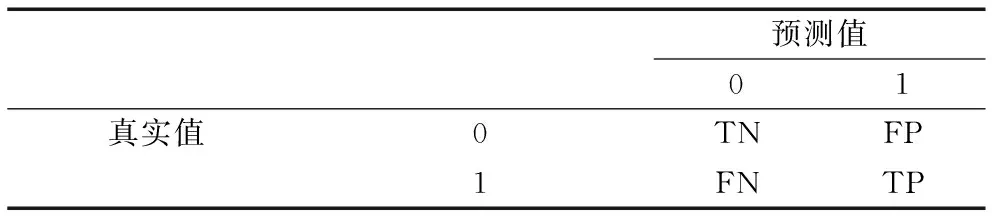
表1 混淆矩阵Tab.1 Confusion matrix
准确率表示预测正确的样本占总样本的比例,计算公式如下:
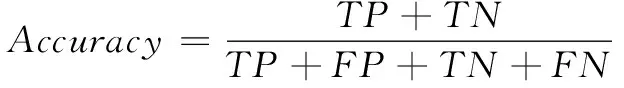
(1)
精确率表示对进行机会型创业预测正确的样本占被预测为进行机会型创业样本的比例,计算公式如下:

(2)
召回率表示对进行机会型创业预测正确的样本占实际进行机会型创业样本的比例,计算公式如下:
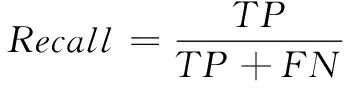
(3)
在某些情况下,精确率和召回率会产生矛盾。为综合评判模型的预测能力,使用F1值进行判定,F1是精确率和召回率的调和均值,即精确率与召回率乘积的两倍除以两者之和,其值越大,说明模型的预测能力越强,具体公式如下:

(4)
2.4 特征指标
本文主要借鉴朱亚丽等[18]关于员工内部创业行为的研究框架,参考郑馨等[23]、Ajzen[26]的研究,在行为态度层面选择成就导向和风险承担两个特征指标,在知觉行为控制层面选择创业自我效能、机会识别和关系感知3个特征指标,在主观规范层面选择媒体宣传和公众认可两个特征指标,在行为层面选择机会型创业特征指标。此外,性别、年龄等人口统计学特征是影响创业动机和行为的其它个人因素(Wood等, 1989)。因此,参考Dézsi-Benyovszki等[17]、Shabir等[19]的研究,选择年龄、受教育水平、性别、家庭规模和家庭收入5个人口统计学特征指标,具体解释如表2所示。

表2 特征指标及说明Tab.2 Characteristic indexes and description
考虑到变量可能存在共线性问题,从而影响预测效果,同时由于研究数据中存在非连续型变量,因而参考王言等[28]的研究,采用Spearman相关分析和方差膨胀因子(Variance Inflation Factor,VIF)两种方法进行检验。结果显示,各变量间的相关系数均小于0.6,各变量的VIF值及均值都小于3,说明不存在严重的共线性问题。
3 模型构建与效果对比
本文基础数据共12 829个样本,其中进行机会型创业的样本有1 744个,不进行机会型创业的样本有11 085个,样本不平衡问题明显。在样本存在明显不平衡的情况下,常见的机器学习算法绝大多数都不能很好地工作,模型对少数样本的敏感性降低,预测效果受到严重影响(Kuhn等,2013)。进行机会型创业与不进行机会型创业的样本数相差过大,可能导致在模型学习过程中,对不进行机会型创业的人群特征学习充分而对进行机会型创业的人群特征学习不够,在识别机会型创业者时不准确,从而导致分类预测效果欠佳。因此,本文参考吴翌琳等(2021)的研究,采用过采样方法,复用进行机会型创业的样本4次,得到共计19 805个样本进行建模分析。为更好地检验分类模型的预测能力,对样本进行多组实验,观察拟合效果,最终确定将样本数按7∶3的比例随机拆分为训练集和测试集,确保有足够的数据量训练模型。
3.1 XGBoost算法结果
3.1.1 参数设置
XGBoost算法主要包括控制宏观函数的通用参数、控制booster细节的Booster参数和控制训练目标的学习目标参数3类参数,具体涉及几十个参数(曹睿等,2021)。建模的一个关键因素在于选择适当的参数,为提高模型性能,本文基于XGBoost算法构建机会型创业预测模型并对参数进行优化调整,模型主要参数设置及说明如表3所示。
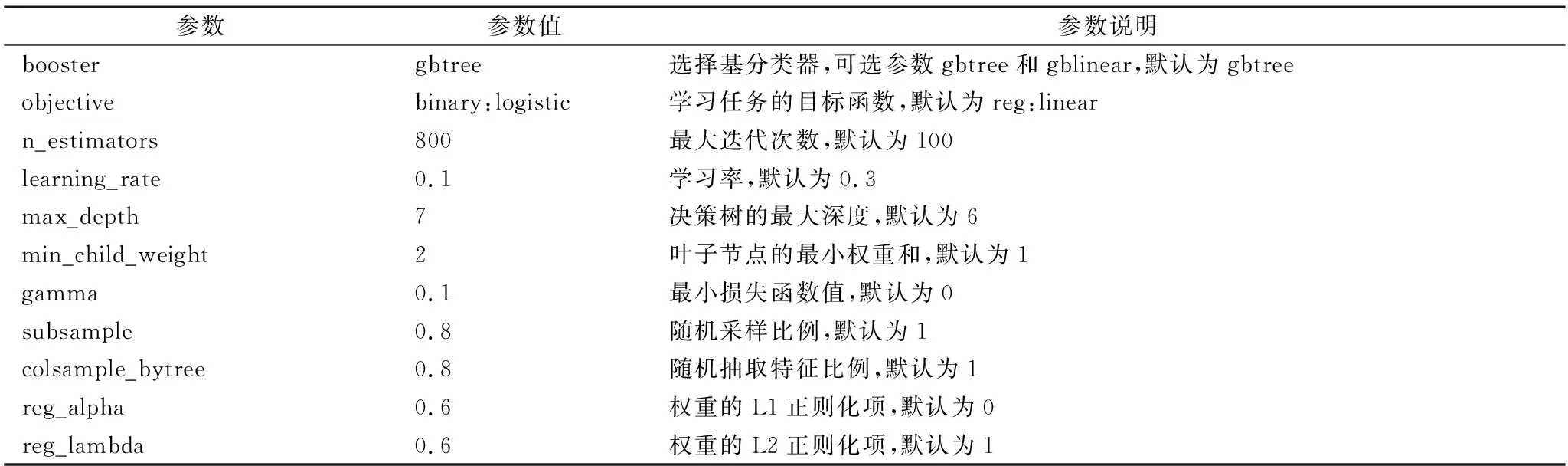
表3 基于XGBoost算法的参数设置Tab.3 Parameter settings based on XGBoost algorithm
3.1.2 运行结果
使用Python软件,利用训练集建立XGBoost模型,进而得到测试集的混淆矩阵,如表4所示。实际进行机会型创业的样本共2 591人,其中,2 487人被模型判定为进行机会型创业,104人被误判为不进行机会型创业。实际不进行机会型创业的样本共3 351人,其中,2 799人被模型判定为不进行机会型创业,552人被误判为进行机会型创业。通过计算得到模型的准确率为(2 487+2 799)/(2 591+3 351)=89.0%,表明XGBoost算法具有较高的准确率。从进行机会型创业的类别看,根据混淆矩阵计算模型的召回率为2 487/(2 487+104)=96.0%,表明XGBoost算法对实际进行机会型创业的人挖掘能力很强,挖掘率达到96.0%。精确率为2 487/(2 487+552)=81.8%,表明在被判定为进行机会型创业的人群中存在18.2%的人不进行机会型创业。根据精确率和召回率,得到F1值为2×96.0%×81.8%/(96.0%+81.8%)=88.3%。总体来看,XGBoost算法在精确率、准确率、召回率和F1值4个评价指标上都达到较高水平,对机会型创业具有较好的预测效果。
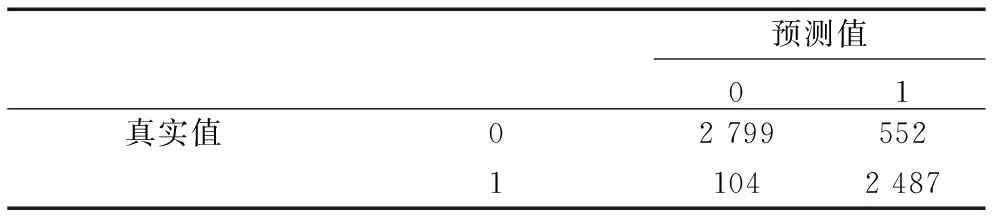
表4 基于XGBoost算法的混淆矩阵Tab.4 Confusion matrix based on XGBoost algorithm
在此基础上,根据真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)的值,进一步绘制ROC曲线(Receiver Operating Characteristic Curve)。其中,纵轴是真阳性率,横轴是假阳性率,把不同的点连成曲线,如图1所示。AUC(Area Under Curve)为ROC曲线下方与坐标轴围成的面积,通过计算AUC值为0.94,大于0.85的阈值,说明XGBoost算法对机会型创业的预测效果较好。
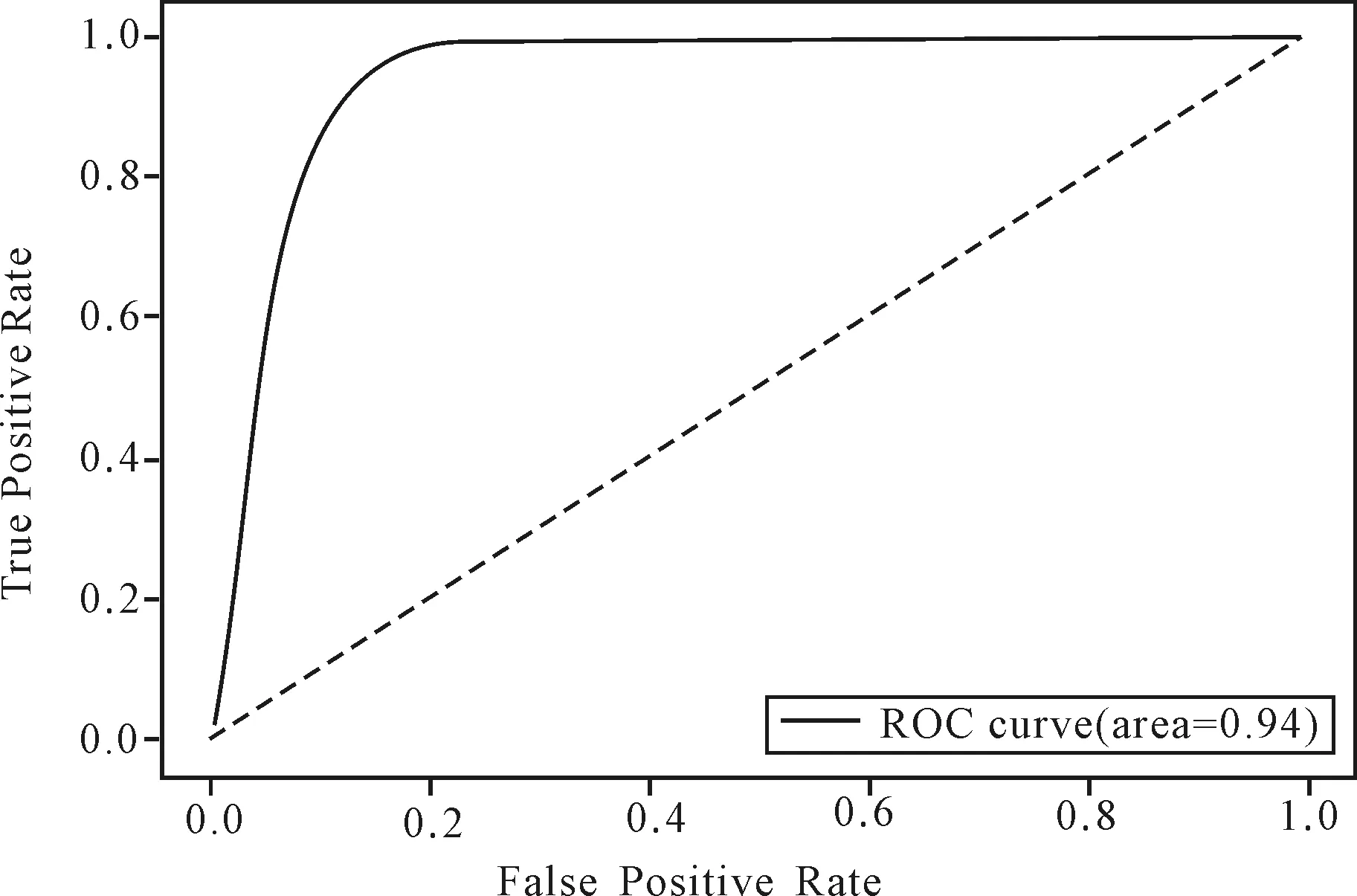
图1 基于XGBoost算法的ROC曲线Fig.1 ROC curve based on XGBoost algorithm
3.2 对比分析
机器学习算法具有较强的领域适用性和效果良好的运算结果,本文选择逻辑回归、支持向量机、随机森林3种机器学习算法与XGBoost算法进行对比,从而比较不同算法对机会型创业的预测效果。表5结果显示,逻辑回归算法的准确率为69.3%,支持向量机算法的准确率为72.8%,随机森林算法的准确率为77.8%,XGBoost算法的准确率为89.0%,XGBoost算法最优,其次是随机森林算法和支持向量机算法,最后是逻辑回归算法。从召回率、精确率和F1值看,也呈现较一致的结果。这可能是因为,逻辑回归是一种广义的线性回归模型,本质上是一个线性模型加上Sigmoid函数,服从伯努利分布,因而预测效果相对较差。这表明机会型创业具有较为复杂的非线性关系,使用基于非线性关系的模型可以获得较好的预测效果。其它几种机器学习方法可用于解决非线性问题,且不局限于某种分布[32],更适用于大数据下机会型创业的预测问题。在建模过程中,支持向量机算法可以解决非线性的二分类问题,对变量间的非线性关系进行一定程度的拟合,其准确率、精确率、召回率和F1值均比逻辑回归高,但预测效果仍有待提高。从理论上看,集成分类器的性能总体上优于绝大多数单一分类器,基于集成学习的XGBoost算法和随机森林算法预测效果较好。随机森林算法基于Bagging集成学习算法,采用随机方式建立一片森林,基于所有树的分类结果进行综合判别分类,可以处理高维度数据,模型抗噪声能力强、泛化能力较强且训练速度快[33]。在机会型创业预测上,XGBoost使用梯度提升框架,比逻辑回归、支持向量机、随机森林3种算法的预测效果更好,4个评价指标均为最优。这与Koumbarakis等(2022)的研究一致,相较于其它几种算法,XGBoost算法在预测新企业孕育结果方面表现最佳。这也表明本文构建的影响因素框架是有效的,基于计划行为理论和人口统计学特征深入挖掘影响因素可以较好地预测个体是否进行机会型创业。在此基础上,本文进行五折交叉验证,将样本随机均等划分为5个数据集,轮流选取其中4个数据集作为训练集,剩下的一个数据集作为测试集,依次进行迭代,并计算平均值。以准确率为例,XGBoost算法的平均准确率达到88.6%,比随机森林算法的平均准确率高出约10%,比支持向量机算法的平均准确率高出约17%,比逻辑回归算法的平均准确率高出约20%,再次验证了XGBoost算法在预测机会型创业方面的良好效果。

表5 4种算法结果对比Tab.5 Comparison of the results of the four algorithms
3.3 重要性排序
通过比较XGBoost、逻辑回归、支持向量机、随机森林几种机器学习算法,发现XGBoost算法对机会型创业具有良好的预测效果。同时,XGBoost算法可以通过数据分类回归得到各特征变量的重要性大小。重要性本质上是指某个变量在迭代构建决策树过程中被选择的次数占所有自变量被选择总次数的比例,所有特征变量的重要性之和为1[29]。因此,本文基于XGBoost算法评估各特征变量的重要性,结果如表6所示。结果显示,机会型创业影响因素框架中的12个特征变量对机会型创业预测都具有作用,重要性最高的前3名分别为创业自我效能(0.250)、机会识别(0.097)和关系感知(0.081)。由此可见,创业自我效能在预测机会型创业时发挥最重要的作用,机会识别和关系感知也相当重要。
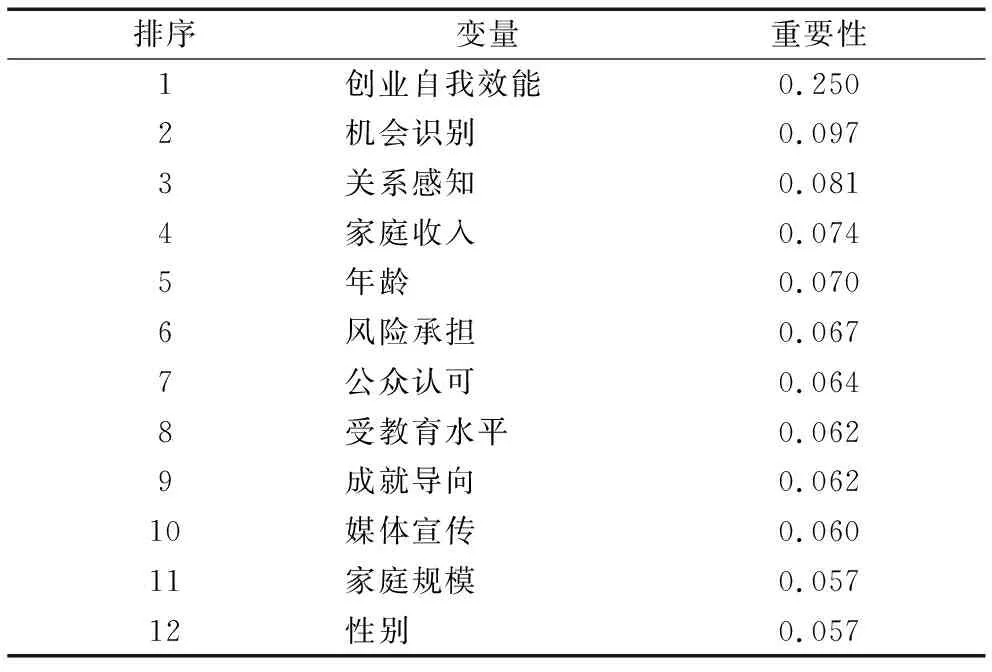
表6 变量重要性评估结果Tab.6 Assessment results of variable importance
首先,创业过程充满挫折,需要创业者具备极高的心理素质,创业自我效能体现了创业者克服创业困难取得创业成功的信念(周键等,2019)。即使创业活动带来的经济效益可预期,个体也不一定选择创业,而是首先评估自己是否有能力进行创业并实现创业目标[34]。因而,创业自我效能是创业开始的重要因素,能够很好地预测机会型创业。例如,李彦宏在硅谷工作数年后,怀揣巨大的创业信心回到国内,凭借广泛的资讯、丰富的经历和开阔的视野,最终成功创立百度。李彦宏也提到,在面临战略机遇期和攻坚期时,创业者要树立自信心,坚持不断创新,坚定信仰,不跟风、不动摇。其次,创业本质上是由机会识别及相关活动和职能共同构成的(谷晨等,2019)。机会前瞻意识较强的个体可以基于个体偏好和外部环境敏锐识别创业机会,进而从事机会型创业活动。例如,马云在创建阿里巴巴时,发现中小企业在互联网消费市场占据巨大份额且急需互联网销售平台的商业机会,进而开创了B2B的电子商务模式。最后,在转型经济国家,法律、法规等正式制度还不完善,因而个人社会关系等显得尤为重要[35]。当个体感知到创业关系支持时,更容易集聚、整合和利用创业资源,进而从事机会型创业活动。例如,马云积极扩展创业关系网络,组建“十八罗汉”创业团队,积极争取软银和雅虎的投资资金支持,成就了阿里巴巴商业帝国。
值得注意的是,在5个人口统计学特征变量中,家庭收入最为重要,其次为年龄,而性别、受教育水平和家庭规模在判别机会型创业时发挥的作用较小。这说明机会型创业在初期往往难以获得广泛的外部资金支持,风险投资等外部资金占比较低,而个人的家庭收入往往成为机会型创业初始阶段的重要资金来源[6]。创业自我效能、机会识别和关系感知作为知觉行为控制的3个具体维度,体现了知觉行为控制对机会型创业的重要影响。此外,已有研究强调社会规范对创业行为活动的重要作用,但在本文研究中,除人口统计学特征变量外,媒体宣传和公众认可作为主观规范的两个具体维度,在计划行为理论框架下对机会型创业的影响最弱,这与已有研究有相似之处。Autio等[36]运用计划行为理论分析芬兰、瑞典、美国和英国大学生创业意向的影响因素发现,知觉行为控制是最重要的影响因素,而主观规范的影响最弱。
4 研究结论与启示
4.1 研究结论
本文将机器学习算法引入机会型创业领域,基于计划行为理论,从主观规范、行为态度、知觉行为控制3个方面,并结合年龄、受教育水平、性别、家庭规模和家庭收入5个人口统计学特征选择12个特征变量。以2018年全球创业观察数据库的中等收入国家个体数据为研究样本,使用Python软件,运用XGBoost算法预测机会型创业并甄别关键影响因素。研究发现,基于准确率(89.0%)、精确率(81.8%)、召回率(96.0% )和F1值(88.3%)4个评估指标,XGBoost算法的预测效果较好,通过ROC曲线进一步计算AUC值为0.94,可以较好地反映机会型创业与各影响因素之间的非线性关系。XGBoost算法基于梯度提升框架,通过集成学习组成一个强学习器,利用决策树集成优势对庞大的创业数据进行非线性拟合,能够更加快速准确地解决机会型创业预测等科学问题,优于支持向量机、随机森林和逻辑回归算法,五折交叉验证也证明XGBoost算法具有较好的预测效果。此外,基于XGBoost算法评估12个特征变量的重要性发现,创业自我效能、机会识别和关系感知是影响机会型创业的重要因素,说明知觉行为控制对机会型创业具有重要影响,而性别等人口统计学特征影响较小。
4.2 研究贡献
基于计划行为理论和人口统计学特征,通过多种影响因素的组合,使用XGBoost等机器学习算法预测机会型创业,本文研究贡献如下:
(1)拓展了计划行为理论的适用边界。计划行为理论作为社会心理学领域具有重要影响力的理论,已被广泛应用于行为和意向研究中。创业领域学者也运用计划行为理论研究创业意向和行为,但在机会型创业领域应用有限。同时,现有研究从个体、家庭和环境层面提出机会型创业的影响因素,相对比较零散,对于个人为什么进行机会型创业有待进一步探究。本文响应Shane等[5]加强机会型创业研究的号召,应用计划行为理论并结合人口统计学特征,剖析机会型创业的影响因素,构建包含主观规范、行为态度、知觉行为控制和人口统计学特征的整合性研究框架。这弥补了以往机会型创业研究缺乏系统性的不足,提高了对机会型创业复杂性的解释力,验证了计划行为理论在解释机会型创业上的适用性,为机会型创业研究提供了可行的理论切入点。
(2)扩展了机器学习算法在创业领域的应用。现有关于机会型创业的研究主要运用传统实证方法研究关系型问题,而自变量与机会型创业之间并不一定呈线性关系,可能存在复杂的非线性关系,因此难以实现有效预测,而且关于影响因素的相对重要性仍存在争议。本文回应了Obschonka等[16]将人工智能与机会型创业结合的观点,进行计算机科学与创业领域的学科交叉,关注这一新型创业领域。本文将机器学习方法应用到机会型创业预测中,构建个体是否参与机会型创业的预测模型。对比分析发现,XGBoost算法对机会型创业的预测效果最好,可以检测输入数据中变量交互的模糊性和非线性效应,扩展了机器学习方法在创业领域的应用,弥补了传统计量分析方法的不足。此外,XGBoost算法还可以度量影响因素的重要性,丰富了创业研究中的优势分析方法(Arin等,2015)。
4.3 实践启示
有效的预测方法作为一种支持系统,有利于政府和外部投资者识别潜在的机会型创业,有利于政府针对性培育机会型创业,并指导个体从事机会型创业活动。针对本文研究结论,从以下方面提出实践启示:
(1)为政府和外部投资者有效甄别机会型创业提供科学方法。XGBoost等机器学习算法可以对机会型创业进行预测,在精确率、准确率、召回率和F1值4个方面都达到较高水平,预测效果较好。因此,政府可利用XGBoost算法挖掘潜在的机会型创业,从而将资源更多地分配给潜在的机会型创业者,以促进机会型创业实践。同时,风险投资、天使投资等外部投资者可以基于XGBoost算法识别潜在的机会型创业,从而降低选择成本,进行有效的创业投资。
(2)为政府针对性培育机会型创业提供实践参考。本文利用XGBoost算法评估机会型创业各特征变量的重要性,发现创业自我效能、机会识别和关系感知是影响个体进行机会型创业的重要因素。因此,政府要加快营造有利于机会型创业的社会环境,不断优化创业生态系统,完善创业教育体系,加大创业资金支持,营造宽容失败的创业氛围,搭建创业服务咨询与交流协作平台,为个体进行机会型创业创造条件。
(3)为个体积极从事机会型创业活动提供实践启示。对于个人而言,要特别注重提升个体创业自我效能、增强个体创业关系感知、提高个体创业机会识别能力。个体不仅要加强创业技能和理论知识学习,增强创业自信心,而且要注重创业关系的积累,积极与创业者进行交流互动,努力撬动社会资源支持。此外,个体要擅于寻找和发现创业机会,提高对创业机会的警觉性,积极识别创业机会进而转化为机会型创业行为。
4.4 研究不足与展望
本研究存在一定不足,未来可以从两个方面加以改进和完善。一方面,不同算法模型具有不同预测效果,只能逼近模型的最优效果,只有不断纳入更多数据维度,并进行特征变量选择,才能提高模型的预测效果。创业是一项复杂且具有不确定性的活动,受限于数据的可得性,本文选择的变量有限,与现实情况仍存在一定差距。未来可基于其它视角和数据库,从多角度、多因素有效预测机会型创业,从而为政策制定提供更为全面科学的理论指导和实践参考。另一方面,机器学习领域发展较快,新的算法模型不断涌现,未来可以融合其它算法进一步完善机会型创业预测模型及其应用,提升研究结论的准确性和指导力。
