基于迁移学习的非约束环境下热带鱼类识别
2023-03-11刘薇芳朱宇鹏
张 珊,韩 溦,刘薇芳,朱宇鹏
(1.海南大学旅游学院,海南 海口 570208;2.海南超图科技有限公司,海南 海口 570220)
以往对于海洋鱼类资源监测常通过现场采样法[1]、渔获法[2]、水声学遥测等方法,这些方法不同程度地存在依赖专家经验、破坏生物资源、无法判断鱼的类型等缺点[3]。得益于数据处理技术、评价模型和方法的完善,海洋生物资源监测评价步入精准化、无损化时代[4]。建立水下视频深度学习系统,将是智能化监测海洋鱼类资源最为有效的方法。
计算机视觉捕捉分析技术作为一种非破坏性技术,在监测中可以保持海洋生物资源完整、带来最少的环境扰动,被广泛应用到海洋生物监测研究之中。人们通过摄影、摄像获取海底图像并采用图像处理方法研究海洋生物特征[5-7]。相较于传统方法,利用计算机技术进行海洋生物监测是一种自动、非入侵、经济且有效的方法。
虽然基于图像的目标检测技术近些年得到了广泛的研究,但是基于海底非约束环境下图像的目标检测技术仍然面临很大的挑战。由于鱼类的快速自由运动、天气、光照等外界因素经常变化[8]导致视频影像对比度低、纹理细节模糊,不利于训练网络提取图像特征。
1 鱼类图像识别算法
鱼类图像识别基本流程:输入鱼类图像、选择鱼类特征、构建分类器、分类识别。早期的方法过度依赖人工选择特征,人工选择特征主要依靠专家的先验知识,通过鱼的轮廓、形状、颜色等特征进行检测[9-10],特征设计中允许出现的参数数量十分有限,难以准确获取高层次特征[5],从而影响分类识别结果的准确性。随着人工智能技术的发展,深度学习在计算机视觉领域取得了巨大成功,传统的机器学习法正逐渐被基于深度学习的方法替代。深度学习可以从大数据中自动学习特征的表示,可以包含成千上万的参数,通过深度神经网络结构将数据从像素级低维特征映射到语义层高维特征,这使得它在提取图像的全局特征和上下文信息方面具有突出优势[11],为解决传统的计算机视觉问题(如图像分割和关键点检测)带来了新的思路。
2012年后,尤其是以卷积神经网络(convolutional neural network,CNN)为代表的神经网络模型得到了广泛应用[12-14]。CNN 是由交替卷积层和子采样层组成的一种流行的深度学习体系结构,由于它能够提取复杂、高维的图像特征,已经被证明在许多计算机视觉应用中有效,如分割[15]、对象识别和分类[16]、目标跟踪[17]。2017 年,谷歌和NASA 通过CNN 技术在开普勒-90 海量影像中发现了一颗新行星。Frederic[12]等亦通过CNN 从数十万张卫星影像中找到了濒危物种海牛。Spampinato[18]等提出了一种在无约束环境下跟踪鱼类的算法,基于协方差模型描述被检测对象,比较当前对象的协方差矩阵与候选对象的协方差矩阵,通过模板匹配生成轨迹,平均准确率约为80%,有待进一步提高。针对这些问题,Chuang[19]等进一步提出了一种基于可变形多核的跟踪算法,通过对颜色和纹理特征的均值偏移算法,有效地估计核的运动,实现鱼类跟踪,但文中并没有给出具体的测试结果。在此基础上,Jager[20]等通过两阶段图形法,用激活的CNN实现无约束环境下鱼类跟踪,具有较高的跟踪精度和效率,但模型的14个超参数无法自动调整,从而降低了模型的可移植性。Wang[21]等针对视频帧中每条鱼的头部图像,定制CNN 并在跟踪过程中对CNN 参数进行自适应更新,以适应轻微的光照和鱼的外观变化,该方法被证明对斑马鱼有较好的识别和追踪效果,然而实验仍然局限在水族箱环境内。贾宇霞[22]等通过图像增强和迁移学习在Fish4Knowledge 数据集上进行鱼类识别实验,识别精度达到99.63%,但仅限于单个鱼类主体,对无法解决鱼类重叠和遮挡。Pan[23]等构建了多尺度ResNet 实现水下目标对象定位,实现了实时识别,但对有遮挡对象和微小对象的识别效果不佳。Zhao[24]等通过改进ResNet,实现在低质量水下环境中的鱼类识别,但该实验对硬件要求较高。
2 数据来源
项目组从2017 年起在海南省三亚市蜈支洲岛周围,根据不同礁型、不同材质、不同水深等选取了5处人工礁进行海洋鱼类的拍摄观测,如图1 所示。水下电子舱布置在5 个观测点,一个舱内布置有两台光电式HB-HM-02 水下摄像机从不同角度进行数据采集。视频分辨率为648×480,即宽度和高度,帧速率为50。目前,五套设备已全部布置并运行良好,实现了视频数据和水质监测数据的连续不间断记录和传输。

图1 蜈支洲岛水下视频监控布点位置图
10 台摄像机每min 产生150+MB 的视频数据(夜间光照欠佳期间摄像机不拍摄视频),在12 h 的监控下,每天产生100 GB以上的视频数据,每年产生35+TB的视频数据,这个地区拥有丰富的鱼类生物资源如图2所示。

图2 蜈支洲岛数据库视频帧视觉效果示意图
从蜈支洲岛数据库中选取不同时间段对24个视频片段,共计3 100 个标记视频帧,其中75%作为训练集,25%的数据作为测试集,标签数据使用麻省理工计算机科学与人工智能实验室研发的LabelMe 深度学习图像标注工具完成。如表1所示。

表1 蜈支洲岛数据库概况
3 迁移学习
数据是深度学习的关键,有足够可利用的训练样本是计算机通过学习能够获得好的分类器的前提。大多现有可用数据是针对特定课题而设计的,如手写数字数据库MINIST,图片数据集ImageNet,图像语义理解数据集COCO 等,这些开源数据不能完全满足本研究所需的深度学习训练数据要求,因此要针对特定鱼类进行训练数据的补充。然而手动标注图像非常耗时,在对无人驾驶数据集Cityscapes 中单个图像的精细像素级的标注平均需要花费1.5 h。此外,由于人的主观因素也容易出现错误标注。因此,项目引入迁移学习来解决目前目标领域仅有少量有标签样本数据的问题。
迁移学习是运用已经训练好的知识对不同但相关领域问题进行求解的一种新的机器学习的方法,以解决目标领域中仅有少量有标签样本数据的问题。以往,针对不同的领域问题需要重新训练深度学习模型,一方面需要耗费大量的时间和计算资源;另一方面,在图像识别领域,图像底层特征相似性高,这些底层特征被组合成为不同的更复杂的特征用于图像分类识别。因此,可以将经过其他大型训练集预训练之后的网络模型作为底层图像特征提取器,从而实现将通用图像特征提取知识迁移到热带鱼类分类识别领域,减少对标注数据的依赖。斯坦福大学吴恩达教授在2016年NIPS会议上说:“迁移学习将会是继监督学习之后的下一个机器学习商业成功的驱动力”。
ImageNet图像数据集始于2009年,是目前世界上图像识别最大的数据库,由美国斯坦福的计算机科学家模拟人类的识别系统建立。包含约1 500万张图片,2.2万个类型,每张图片都经过严格的人工筛选与标记。从2010年起,每年都基于ImageNet举办全世界的大规模视觉知识挑战赛(ILSVRC),世界各地的研究团队在给定的数据集上评估其算法,并在视觉识别任务中争夺更高的准确性,2017年后比赛由Kaggle社区主持。在图像分类上,ImageNet竞赛已经是计算机视觉分类算法事实上的评价标准。Keras 是一个由Python 编写的开源人工神经网络库,主要提供了基于ImageNet训练的5 种开箱即用型的CNN 网络——VGG16、VGG19、 ResNet50、 Inception V3、 Xception。 与AlexNet、OverFeat还有VGG这些传统顺序型网络架构不同,ResNet50的网络结构依赖于微架构模组,因为使用了全局平均池化,而不是全连接层。尽管ResNet50 比VGG16 还 有VGG19 要 深,weights 却 更小。本文使用Keras 库中的ResNet50 网络,利用其自带已训练好的imagenet 作为权重来初始化训练目标模型参数,实现将已经学到知识共享给新模型,然后根据目标任务调整输出层,用热带鱼类图像样本精调网络模型进行训练,提高检测算法的精度和效度,最终得到热带海域鱼类分类识别模型,迁移学习流程如图3所示。
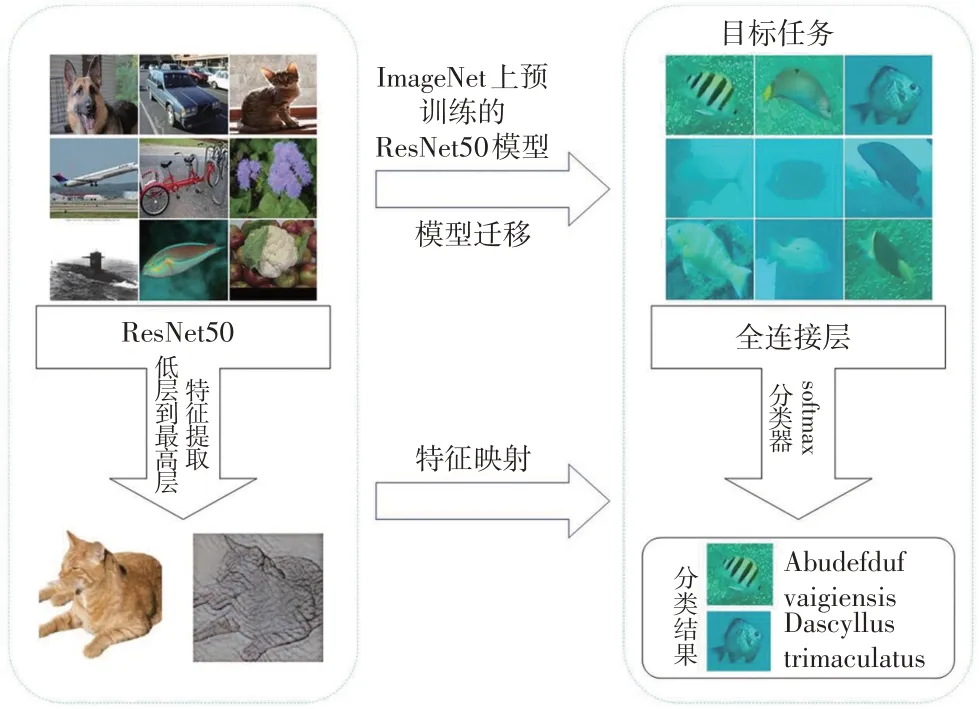
图3 迁移学习流程图
4 模型架构
整个ResNet 深度卷积神经网络由初始卷积(Conv)层、若干个Residual Block 和最后的全连接层(fully connected,FC)组成。第一个Conv layer 不需要进行归一化和ReLU 非线性激活。首先按照均值和标准差,对图像进行归一化处理。考虑到梯度下降的训练时间,使用ReLU 非线性激活作为激活函数,比tanh 激活函数效果更好[28],然后进行第一次3×3 卷积运算,对卷积结果再次进行batch normalization,ReLU非线性激活后再进行第二次3×3卷积运算,执行跳远连接,将第一层的激活迅速传递给第六层后的下一个Residual Block。模 型 总 训 练 次 数(train steps) 为300,图片通过一系列3×3的滤波器进行卷积运算,卷积滑动步长固定为1,使用mini_batch对算法性能进行优化。考虑到内存有限,训练集和测试集的batch_size均设置为24,padding size 为same 进行图像填充。模型总参数23 587 712 个,固定参数53 120 个,可训练参数13 534 592个,模型结构及参数设置如图4所示。
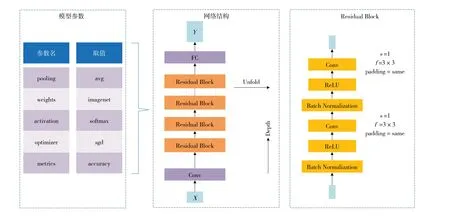
图4 ResNet热带鱼类识别模型架构图
5 实验及结果分析
为了评估迁移学习,在蜈支洲岛数据集上进行了实验,在网络结构、学习效率、损失函数等保持不变的情况下,对比了迁移学习前后的各项学习指标。实验使用了一台Intel(R)Xeon(R)X5675 3.06 GHz 计算机系统型处理器,32 GB 内存和NVIDA GeForce GTX 1050 Ti GPU。实验所得部分数据如表2所示。
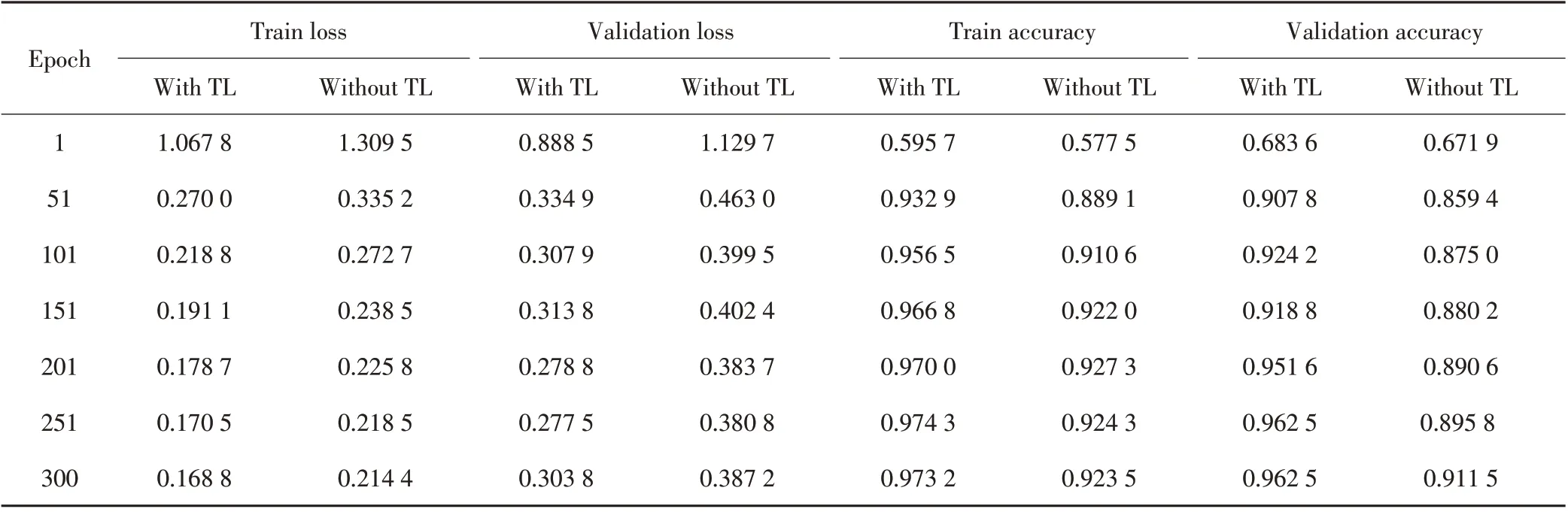
表2 迁移学习前后不同训练次数下的各指标数值
train loss 代表训练数据上的损失,使用交叉熵作为损失函数,主要用来衡量训练集上的拟合能力,train loss 值越低,说明模型在训练集上的拟合能力越高。validation loss 代表验证集上的损失,使用交叉熵作为损失函数,主要用来衡量模型在未知数据上的拟合能力,即模型的泛化能力,validation loss 值越低,说明模型的泛化能力越高。由图5 可见,在引入imagenet 已训练好的模型作为网络的初始权重下,train loss 值和validation loss 值迅速降低,并且随着训练次数的增加,train loss 值和validation loss 值均保持持续下降的趋势。在训练到150 次后,validation loss 值在0.41~0.37 区间震荡,随着训练的深入,loss 值进一步震荡下行,说明本方法具有较好的拟合能力和泛化能力。

图5 迁移学习训练后的train loss和validation loss变化图
Train accuracy 代表训练数据上的准确率,validation accuracy代表验证集上的准确率,accuracy的值越高,说明模型对热带鱼类分类识别的准确度越高。由图6 可见,在引入imagenet 已训练好的模型作为网络的初始权重下,train accuracy 值和validation accuracy值迅速升高,并且随着训练次数的增加,train accuracy 值和validation accuracy 值均保持持续增加的趋势。在训练到150次后,validation accuracy值在0.85~0.90区间震荡,随着训练的深入,accuracy 值进一步震荡上行,说明本方法具有较好的识别精度。
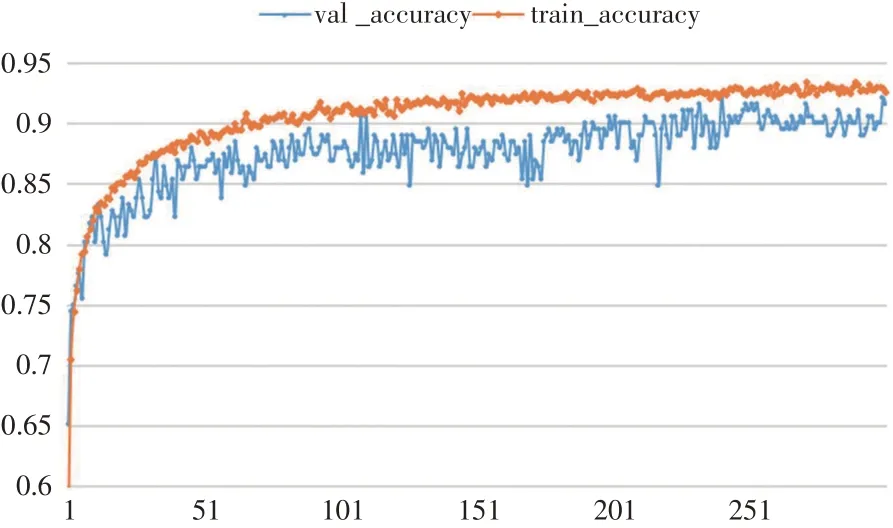
图6 迁移学习训练后的train accuracy和validation accuracy变化图
在保持网络结构和其他超参数相同的情况下,本文对比了使用迁移学习前后的train loss 和validation loss 指标的变化。从图7 中可见,在使用迁移学习前后,train loss值均随着训练次数的增加而减小至0.2~0.3左右。在训练起始阶段,loss会有一个较为明显的下降,当训练到约100 次后,train loss 就基本降低到30%以下,validation loss在0.25~0.45之间震荡。迁移学习后的loss明显低于迁移学习前。

图7 迁移学习前后的train loss和validation loss对比图
在保持网络结构和其他超参数相同的情况下,本文对比了使用迁移学习前后的train accuracy 和validation accuracy指标的变化。从图8可见,在使用迁移学习前后,train accuracy 值均随着训练次数的增加而增加至0.9左右。在训练起始阶段,accuracy会有一个较为明显的上升,当训练到约50次后,train accuracy就基本稳定在0.8以上。迁移学习后的accuracy明显高于迁移学习前。

图8 迁移学习前后的train accuracy和validation accuracy对比图
6 结 语
本文以非约束条件下海洋视频监控数据中的热带鱼类为研究对象,构建了基于迁移学习的热带鱼类识别模型,以ResNet50 作为基础训练网络。结果表明,迁移学习对非约束环境下热带鱼类的计算机识别具有较好的效果,有助于提高识别准确度并缩短学习时间。今后将进一步获取超高清视频数据,优化算法,解决收敛到局部最优而不是全局最优的问题。同时改善硬件条件,进一步提高处理精度。
