基于CEEMD-PCA-XGBoost的滚动轴承故障诊断方法*
2023-03-11何毅斌胡明涛
马 东,何毅斌,李 铭,唐 权,胡明涛
(武汉工程大学 机电工程学院,湖北 武汉 430205)
0 引 言
由于轴承是旋转机械中的重要零件,轴承故障的有效诊断对机械安全运转具有重要意义[1]。
滚动轴承是轴承中的一类。滚动轴承的故障诊断步骤可分为信号特征提取、故障诊断、故障分类3部分[2]。
受工作环境影响,外界噪声会产生干扰信号,因此,处理干扰信号所采取的不同方法会直接影响滚动轴承的故障诊断结果。
常见的滚动轴承信号处理方法包括:快速傅立叶变换(fast Fourier transform,FFT)、小波变换(wavelet transform,WT)及经验模态分解(empirical mode decom-position,EMD)等[3]。
FFT适合处理整体且较平稳的信号;WT虽然可以探究信号在时域和频域方面的变化,但该方法不能实现基函数自适应的目的;EMD可自动按照固定模式对振动信号进行分类,但会出现模态混叠等现象[4]。
集合经验模态分解(ensemble empirical mode decomposition,EEMD)是在EMD的基础上,通过加入白噪声,在一定程度上改善了模态混叠等现象,但不能自适应地调整噪声幅值等参数[5]。互补集合经验模态分解(CEEMD)则通过加入对称白噪声,提高了信号的重构精度,同时又节约了计算时间,可有效地解决模态混叠的问题[6]。
人工神经网络(artificialneural networks,ANN)[7]、支持向量机(support vector machine,SVM)[8]等在故障诊断领域得到广泛应用。ANN需要依托数据集进行多次训练,且易陷入局部最优解。SVM可解决ANN过拟合和局部最优解问题,但该方法处理大量数据样本时所需建模时间长,模型训练的速度较慢。极端梯度提升(XGBoost)[9]算法是梯度提升(gradient boosting)算法的改进版,其引入了正则化项,有效规避了模型产生过拟合现象;并且其采用并行式和分布式相结合的计算模式,极大提高了模型的训练速度。
在轴承故障诊断研究方面,梁治华等人[10]采用了EEMD和CS-SVM相结合的方法,即利用EEMD预处理轴承信号数据,并采用改进的SVM算法优化CS-SVM模型,提高了轴承故障识别的准确率。孙萧等人[11]首先将轴承振动信号经CEEMD分解,然后采用筛选峭度值的方式,对该信号进行了重构,并使用卷积神经网络对该信号进行了特征提取。王桂兰等人[12]研究了XGBoost算法在风机主轴承故障预测中的应用,结果表明,XGboost算法在处理大规模数据时,其分类精度和模型运算速度综合性较好。马怀祥等人[13]采用卷积神经网络(CNN),对轴承故障信号进行了特征提取,并使用XGBoost算法验证了其分类精度,结果表明,CNN结合XGBoost算法在轴承故障诊断中的分类精度更高。向川等人[14]采用堆栈稀疏自编码(ISSAE)堆叠的方式,有效提取了轴承故障信号中的数据特征,并结合XGBoost分类算法,在轴承故障诊断方面取得较好的效果。
在以上研究中,虽然研究人员都采用不同的方法对轴承进行了故障诊断,但其分类精度普遍不高,依旧存在提升空间。
在实际故障诊断过程中,算法堆叠会导致模型存在参数多、过拟合化等问题,数据过多也会影响模型的运算速度。利用各类数据处理方法可以最大程度地保留其数据特征,防止其数据失真;同时可以精简数据,提高其模型的运算效率。
为此,笔者提出一种基于CEEMD-PCA-XGBoost的滚动轴承故障诊断方法。该方法首先采用模态分解与主成分分析方法,对数据进行预处理,以在保证数据特征的同时,减少模型输入的参数及数据数量;然后将提取的特征量作为输入量,输入到极限梯度提升(XGBoost)模型中,并采用栅格法优化模型的参数。
1 理论基础
1.1 互补集成经验模态分解(CEEMD)
1.1.1 CEEMD原理
由于CEEMD在EMD中添加了对称分布的白噪声,在将目标信号分解成若干个本征模态函数(intrinsic mode functions,IMF)时,可以有效地减小重构的误差,降低噪声的干扰,减少信号模态混叠的影响。
CEEMD的主要分解步骤如下:
(1)在原始信号中加入对称白噪声K(t),产生新信号signew,即:
signew(t)=sigoriginal(t)+K(t)
(1)
(2)将signew进行EMD分解,然后得到IMF(n)和残余函数R(n);
IMF1=signew-c1
(2)
式中:c1—原始信号的上下包络平均值;IMF1—分解后第一个分量。
新信号表达式变为:
(3)
1.1.2CEEMD空间矩阵构建
(1)构建关于原始信号的时域矩阵。时域矩阵如下:
(4)
式中:ui—IMF的时域信号;ui=[ui1,ui2,…uij];j—signew(t)的信号采样点;uij—对应的离散幅值。
(2)构建关于原始信号的频域矩阵。频域矩阵如下:
(5)
式中:vi—时域信号相对应的频域信号,vi=[vi1,vi2,…,vis];s—频域幅值长度。
1.2 主成分分析(PCA)数据降维
主成分分析(PCA)可通过分解特征矩阵的方式,将原有数据的n维特征经过正交变换,构造出新的k维特征,去除数据中不重要的特征量,降低数据的维度[15]。PCA可以进一步减少噪声,用少数数据特征信息代替总体数据特征,减少数据数量,以提高模型运算的速度。
PCA降维流程如下(该处以2个IMF为例):
(6)
(2)计算样本的协方差矩阵。协方差矩阵表达式为:
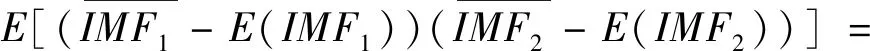
(7)
(3)计算协方差矩阵的特征值与特征向量。此处以式(4)中的时域矩阵T为例,若存在向量Φ是矩阵T的特征向量,则关于该矩阵的特征值λ可在式中表示为:
TΦ=λΦ
(8)
矩阵T特征值分解可表示为:
T=ζ∑ζ-1
(9)
式中:ζ—T的特征向量阵;∑—T的特征值对角阵;
(4)依次保留∑中若干个特征值较大的特征向量;
(5)在最大程度保留数据信息的同时,保留最少的特征向量,特征值作为输入量输入到下文的XGBoost模型。
1.3 XGBoost算法模型介绍
极限梯度提升(XGBoost)是一种集成式提升算法,以回归决策树(CART)为学习模型[16]。
为了得到满足样本数据特性的模型,该算法将简单回归树模型进行多次迭代,在每次迭代过程中,对前一棵树的残差加以拟合,同时引入超参数控制惩罚力度,使迭代损失计算更精确;并采用多线性并行的方式,使模型处理速度更快;模型采用列抽样,以有效规避模型过度拟合的现象。
依据输入的样本xi的地址及样本特征,回归树模型对样本进行分类,并求出结点值。
1.3.1 函数模型构建及算法优化
该模型的目标函数由4部分组成,即加法模型、前向分布算法、目标函数推倒、叶子结点最优解求取。
(1)加法模型。加法模型表达式如下:
(10)
(2)向前分步算法。向前分步算法是采用前一个树模型的已知变量,推导下一个树模型的变量的方式。向前分步算法表达式如下:
(11)

转化为关于叶子结点值的表达式为:
(12)
(3)目标函数确立。目标函数分为总样本损失、正则项两部分。其表达式分别为:
(13)
(14)
式中:N—样本数;Ω(fj)—回归树复杂度;γ—L1惩罚参数;λ—L2惩罚参数;T—叶子结点个数;ωj—结点值。
(15)
(4)叶子结点最优解求取。将式(4,5)按照二阶泰勒公式展开,可得:
(16)
最终目标函数为:
(17)
1.3.2 XGBoost算法流程图
XGBoost算法运算流程图如图1示。
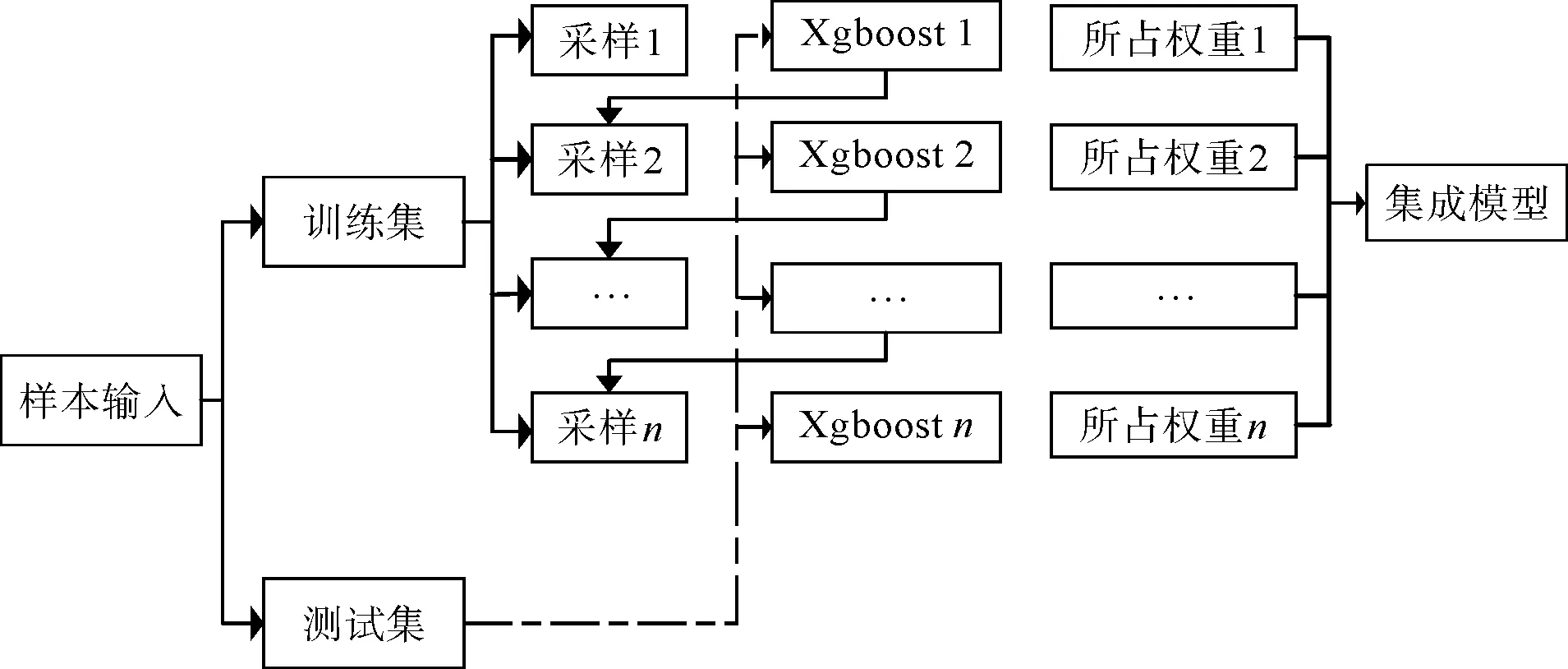
图1 XGBoost算法运算流程图
算法流程主要步骤为:
将输入数据分为测试集和训练集,对训练集进行若干次采样处理,将采样1的数据输入基学习器1,并计算该采样所占权重,基学习器1作为采样2的数据输入,如此,模型不断迭代;将训练后的数据模型用测试集验证,测试模型准确率。
1.4 CEEMD-PCA-XGBoost算法步骤
算法流程思路如下:
(1)利用CEEMD对数据信号进行分解、降噪处理,重构原始信号,得到若干个IMF分量;
(2)信号重构后,分析发现数据量依旧较大,采用PCA方法对数据进行二次特征筛选,保留对原始数据影响较大的特征值,减少数据数量;
(3)利用XGboost模型,设置训练集与测试集,最后验证模型的分类准确度。
算法整体流程图如图2示。

图2 算法整体流程图
2 数据准备
此处的数据集采用美国凯斯西储大学(CWRU)轴承数据集中的驱动端轴承数据[17]。
CWRU实验平台如图3所示。

图3 CWRU实验平台
实验平台包括发动机、扭矩传感器、功率传感器等。
设定电机转速为1 930 r/min,负载为0 hp,频率为12 kHz;选取4类划痕信号(内圈、外圈、滚动体3种故障信号及1种正常信号)。
故障类型代号及样本分配数量如表1所示。

表1 故障类型代号及样本分配数量
为保证数据的多样性,以上数据选取了直径分别为0.007 cm、0.014 cm、0.021 cm的轴承信号各3组,直径为0.007 cm的正常信号1组,共10组信号。
在4类信号中,随机选取70%作为训练样本,剩余的30%为测试样本。
3 实验及结果分析
实验使用的软件为MATLAB2019b、Python3及包含的相关工具包,处理器为酷睿i7-8750H。
3.1 信号类型图
笔者选取直径为0.007 cm的4种轴承信号做代表性研究,数据采样点10 240个。
4种轴承信号的时域波形图如图4示。
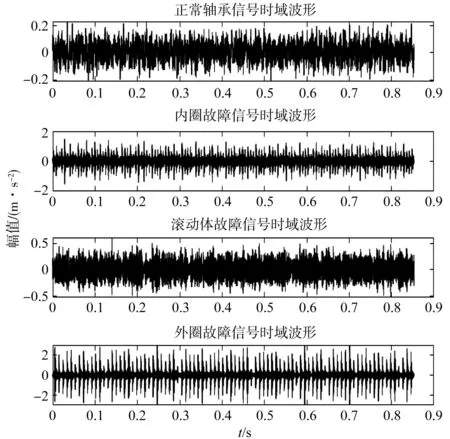
图4 4种轴承信号时域波形图
4种轴承类型数据为1 217×1 601组,特征信号1 600组,标签数据1组。
3.2 CEEMD分解
笔者选取直径为0.007 cm的轴承外圈故障信号进行代表性分析(其他类型数据处理方法相同);对于采样生成的故障信号,则采用CEEMD方法进行特征提取。
CEEMD处理后的信号分解图如图5所示。
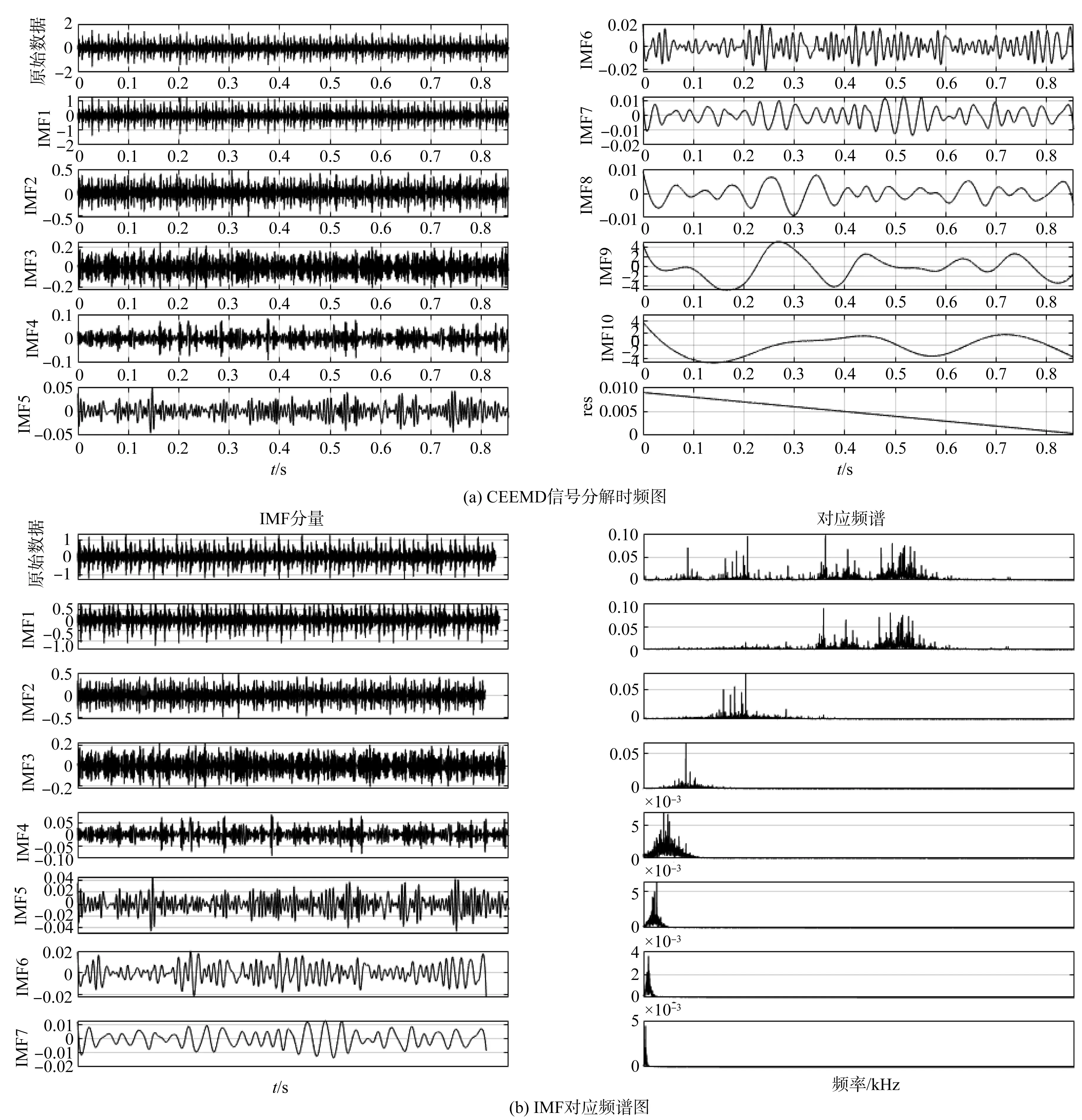
图5 CEEMD处理后的信号分解图
由图5(a)可知:序号1~7的IMF特征较为明显,其余的特征相对较弱;对比图5(b),IMF对应频谱图在序号1~7变化较为明显。
综上所述,笔者选取序号1~7的IMF为研究对象。
笔者对其他直径的信号处理方式相同,经CEEMD分解后,此时的故障数据为1 217×1 201组,特征信号1 200组,标签数据1组。
3.3 PCA降维
CEEMD分解后保留了7个IMF,即保留了部分数据特征,为降低计算量,需要对多个特征进行降维,笔者采用主成分分析法来降低数据的维度。
主成分分析图如图6所示。

图6 主成分分析图
由图6可知:为了降低计算量,图中仅保留了2个维度的特征,但存在丢失数据特征信息的问题。通过绘制累计可解释方差贡献率曲线,可找到所需保留特征值的最优数量;衡量标准为当累计可解释方差贡献率为1时,主成分可取的最小数量。
累计可解释方差贡献率曲线图如图7所示。

图7 累计可解释方差贡献率曲线图
由图7可知:在保留16个维度时,数据最大程度保留了原始数据的特征信息,并减少了其计算量。
分类后的数据为1 217×17组,其中,特征信号16组,标签信号1组。
3.4 XGBoost模型检验
3.4.1 XGBoost模型参数设置
笔者选取几个影响较大参数(max_depth)为最大深度,控制模型的拟合程度,深度越大,则模型的复杂度越高;min_child_weight为最小权重,影响模型的运算速度;gamma为最小损失函数减小的大小;subsample为样本的采样率;seed为步长,控制运算速度。
3.4.2 XGBoost模型测试
笔者处理后的数据1 117×17组,选取训练数据781组,测试数据336组。
该实验对比了XGBoost算法的优点,对比该算法迭代次数与负对数似然函数的关系,对训练数据和测试数据进行分类预测,负对数似然损失值越小,表明预测效果更好。
迭代次数与负对数似然损失关系图如图8所示。

图8 迭代次数与负对数似然损失关系图
由图8可知:经CEEMD处理后,训练集与测试集的曲线的拟合性较好;在经过15次迭代后,训练集的负对数似然损失值趋于0.1,模型分类准确率为99.407%。
3.4.3 XGBoost模型参数优化
为了进一步优化模型,使XGBoost取得更好的实验结果,笔者采用栅格法对主要参数进行调整。
参数调整前后迭代次数与负对数似然损失关系如图9所示。

图9 参数调整前后迭代与损失关系对比图
对比分析图(8,9)可知:参数优化前的测试集依旧存在优化空间;参数优化后,测试集的负对数似然损失值无限趋近于0,达到理想状态;模型所需迭代次数由优化前的15次变为优化后的20次,所需迭代时间增加;分类准确率提升至100%。
为了进一步验证模型的准确率,笔者绘制了混淆矩阵图。
参数调整后的混淆矩阵图如图10所示。
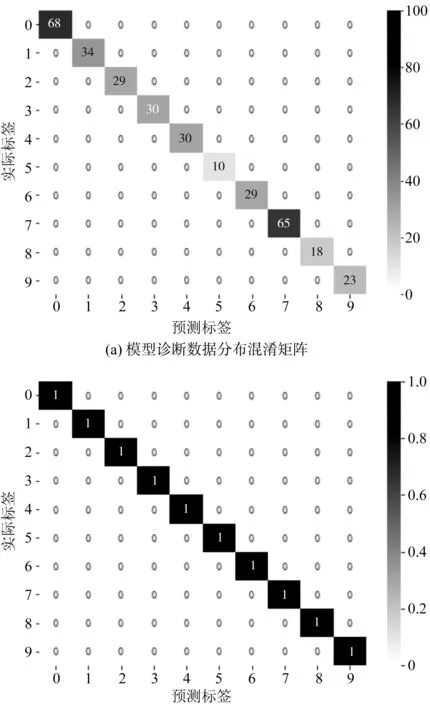
图10 参数调整后混淆矩阵关系图
图10(a)中显示了336组测试数据的分布结果;图10(b)的混淆矩阵显示准确率稳定在100%,模型效果好。
模型参数优化前后对比如表2所示。

表2 优化前后参数对比表
从表2中可以看出:树的最大深度由3变为为1,优化前的数据未完全拟合;步长由7变为8,步长增加,模型运算效率提高,最小损失函数减少量、样本最小权重及随机采样率数值不变。
3.5 数据集验证
此处所采用的验证数据集为IEEE PHM 2012竞赛数据集[18]。其采样频率为25.6 kHz;采集信号间隔10 s。
笔者使用官方数据集中的振动数据(比赛时截取的测试数据与训练数据),3种数据类型分别为:(1)负载4 000 N,转速1 800 r/min;(2)负载4 200 N,转速1 650 r/min;(3)负载5 000 N,转速1 500 r/min。
3类数据编号为bearing1~bearing 3,每类数据依次划分为bearing类型-1~bearing类型-7,生成的信号如图11示。

图11 振动信号图
该实验截取的部分数据中,初始数据为2 460×801组,经CEEMD分解后,数据为2 460×129组;经PCA分解后,数据缩减为2 460×21组。
轴承寿命预测曲线如图12所示。

图12 轴承寿命预测曲线图
由图12曲线可以看出:由于初始时轴承状况良好,拟合曲线重合度不足;但是随着时间的推移,轴承逐渐出现损坏,拟合曲线重合度逐渐变高。
对比文献[19]中的算法结果可知,CEEMD-PAC-XGBoost算法有更好的拟合效果。
3.6 方法对比分析
为了检验基于CEEMD-PAC-XGBoost的算法在轴承故障检测中的优势,笔者共设置了几组方法进行对比试验。
3.6.1 与XGBoost算法的对比
未经CEEMD-PCA处理的数据为1 217×1 200组(其中,训练数据851组,测试数据365组);为了对比CEEMD-PCA方法对数据预处理的重要性,笔者绘制了数据处理前后的算法迭代次数与负对数似然函数对比图。
算法迭代对比图如图13所示。

图13 迭代次数对比图
图13中,笔者直接使用XGBoost算法对轴承故障数据进行处理。当迭代次数为30时,负对数似然损失值趋于平稳。
由此可见,基于CEEMD-PAC-XGBoost的算法所需迭代次数为15,模型迭代次数更少,具有更好的拟合性,运算速度更快。
笔者依据精度(Precision)、召回率(Recall)、综合评价指标(F1-score)4个指标,对比分析数据处理前后的XGBoost模型在(0~9)标签上的不同分类准确度。
标签分类结果对比图如图14示。

图14 标签分类指标对比图
由图14可知,经CEEMD和PAC方法处理后,轴承数据具有了更好的分类效果,具体如下:
(1)精度分析。处理后的数据仅在标签6上的精度较低,最低为91%;未处理的数据仅在标签7上有较好的分类精度,其他标签分类精度普遍低于80%;
(2)召回率分析。处理后的数据仅在标签8上的召回率较低,为93%;未处理的数据仅在标签0、7上有较好的召回率,其他标签分类精度普遍低于70%;
(3)综合评价指标分析。处理后的数据仅在标签8上的综合评价值最低,为96%;未处理的数据仅在标签7上有较好的综合评价值,其他标签分类综合评价值普遍低于65%。
3.6.2 与已知其他方法对比
相关算法参数设置如表3所示。

表3 相关对比算法参数设置
相关算法准确率与运算时间对比如表4所示。

表4 准确率与运算时间对比表
经对比可知:XGBoost分类算法耗时长,准确率低,效果最差;在分类准确率上,CEEMD-PAC-XGBoost算法较EMDD+KNP-SVDD[20]算法提高了2.1%,在运算时间上缩短了10.3s;EMD-SVD+CNN[21]分类方法分类精度高,但运算速度欠佳;CEEMD-PAC-XGBoost算法在保证精度的同时,缩短了运算时间2.24s。
由此可见,CEEMD-PAC-XGBoost算法在故障信号分类上具有较好的实现效果。
4 结束语
由于轴承故障诊断过程中,存在诊断精度(分类精度)不够高和耗时较长的问题,为此,笔者提出了一种基于CEEMD-PCA-XGBoost的滚动轴承故障诊断方法。
该方法首先采用模态分解与主成分分析方法,对数据进行预处理,以在保证数据特征的同时,减少模型输入的参数及数据数量;然后将提取的特征量作为输入量,输入到极限梯度提升(XGBoost)模型中,并采用栅格法优化模型的参数。
笔者提出的基于CEEMD-PAC-XGBoost的轴承故障诊断方法,对提高轴承诊断精度、评估模型诊断时间具有重要参考意义。
研究结论如下:
(1)对比XGBoost算法和CEEMD-PAC-XGBoost算法,后者模型运算时间缩短了45 s,分类精度提高了49%;分析迭代次数与负对数似然损失值曲线,可以发现,在参数优化后,可经过少量的迭代,实现更好的分类效果;
(2)对比XGBoost、EMDD+KNP-SVDD、EMD-SVD+CNN及CEEMD-PAC-XGBoost方法,可以发现,CEEMD-PAC-XGBoost方法分类准确率提高了2.1%,在运算时间上缩短了10.3 s,在分类准确率和运算速度上有更好的综合性能;
(3)采用2种不同的数据集进行了验证,CEEMD-PAC-XGBoost在故障诊断与寿命预测上均取得较为优秀的实验结果。
在此次实验中,笔者仅对数据集中的单一类别划痕进行了分析。因此,在后续的实验中,笔者将对不同损伤类型(比如,疲劳、变形等)加以验证。
