改进的U-Net网络用于视网膜血管分割
2023-03-10吕佳程超
吕佳,马 超,程超
重庆师范大学 计算机与信息科学学院,重庆401331
视网膜血管异常与一些常见疾病,诸如糖尿病、白内障、动脉硬化等有着密切的联系。血管分割图像是计算机辅助诊断视网膜疾病的重要依据[1],因此如何高效准确地对视网膜血管进行分割成为临床诊断的迫切要求。视网膜血管分割常用的方法有基于传统算法和基于深度学习的方法两大类。传统算法包括区域生长法[2]、形态学法、阈值分割法[3]和传统机器学习方法[4-5]等。但是这些方法容易受到专家的主观因素干扰且需要复杂的人工预处理和大量的时间成本,不利于大规模临床应用。因此研究一种快捷、准确的视网膜血管分割算法来辅助系统的诊断、筛查、治疗具有重要的应用价值[6]。
近些年来,深度学习在图像领域迅速发展,最初全卷积神经网络(fully convolutional networks,FCN)[7]被提出,该网络舍去了之前网络结构的全连接层实现图片的端到端输出,提高了网络模型的分割准度,也很快被应用到视网膜血管任务上。但是由于FCN最后单次大跨度的上采样损失了较多血管细节信息,导致最后分割结果不佳。U-Net 网络[8]同样是端到端结构,通过采用跳跃连接复合了浅层和深层的空间特征,能够一定程度保留血管的细节信息。Huang 等人[9]提出了DenseNet,减轻了消失梯度的问题,增强了特征传播,鼓励功能复用,并大幅减少参数数量。之后,Jégou 等人[10]将U-Net 中的卷积层替换为稠密聚集块,使网络更加准确且易于训练,不只局限于单一的结构。生成对抗网络(generative adversarial networks,GAN)也被越来越多人用于血管分割。Liang 等人[11]将轮廓信息和GAN 合并在一起,使用不均匀的光去除和主成分分析来处理眼底图像,增强了血管与背景之间的对比度,并获得了具有丰富特征信息的单比例灰度图像。He 等人[12]提出了基于GAN 的端到端视网膜血管分割模型,通过添加一个自制的放大器来放大眼底图像,用于生成器,最后生成视网膜血管的概率图进行分割。Kamran 等人[13]提出了RVGAN(retinal vessel generative adversarial networks)的多尺度生成架构,通过使用两个生成器和两个基于多尺度自动编码器的鉴别器,以实现更好的微血管定位和分割。Zhou 等人[14]提出了一个端到端合成神经网络,包含一个对称平衡生成对抗网络(symmetric equilibrium generative adversarial networks,SEGAN)多尺度特征细化块和注意机制,避免了高分辨率特征被模糊,从而更好地合并多尺度特征。在最新的研究中,Mou 等人[15]依据血管的连通性,利用血管初始检测和概率正则化来提高分段血管的连通性,提出了一种新的分割算法。Samuel等人[16]使用双容器提取层,并在基础VGG-16 网络上增加监督。血管提取层包括血管特有的卷积块来定位血管,跳连接卷积层使丰富的特征传播。Khan 等人[17]在解码器的上采样阶段共享从编码器中获得的信息,降低了计算量和内存需求,提高了捕获细小血管的鲁棒性能。将不同尺度分辨率的特征进行融合已经被证明是一种能够提升网络性能的有效方法[18]。Zhuang[19]通过增加梯形子网提供了更多的信息流路径,并在视网膜血管分割任务上验证了其优越性。Wang等人[20]在多路径中添加注意力机制,实现高低层像素的有效融合,能够解决细小血管分割问题。Fang 等人[21]提出了一种监督广义线性模型和无监督对比度受限自适应直方图均衡的组合算法,使用Gabor 小波变换与多尺度信息集成广义线性模型,提出的监督过程可以提取出视网膜血管的更多突出特征。Ding等人[22]在梯度提升过程中加入了注意力机制,增强了粗略分割的信息。并在三维U-Net 分割网络中引入了CAB(category attention block)模块,构建了一个新的多尺度提升模型,加强了网络中的梯度流,充分利用了低分辨率的特征信息。Jin 等人[23]在基础网络中添加了可变形卷积使得网络能够结合低级特征和高级特征来提取上下文信息并实现精确定位;并且还可以根据血管的尺度和形状自适应地调整感受野来捕捉不同形状和尺度的视网膜血管。Yang 等人[24]将初始结构引入到多尺度特征提取编码器部分,并将最大池化指数应用于改进网络的特征融合解码器中,使得编码器的特征能够映射传输到对应的解码器上。Atli 等人[25]提出了一种正弦网络模型,首先应用上采样、下采样分别捕获浅层和深层特征,以携带更多的上下文信息到更深的层次。
然而,随着深层网络中上采样的次数越多,融合后的浅层信息越容易被稀释,最终导致对于分割结果的贡献度降低。
基于以上分析,本文提出了一种新的血管分割模型,主要创新点如下:
(1)利用血管的浅层信息,通过引用概率分布注意力机制的提升算法来改变其权值分布,避免被过度稀释,最后提高在最终分割结果中的贡献度。
(2)在深度监督侧输出的线性聚合方式的基础上,引入了一种非对称聚合结构,并在实验上证明了其有效性。
1 基本原理
1.1 提升算法
集成学习是将弱分类器训练成强分类器的算法,其机制是通过多个基础学习器依次迭代提升,最终将它们进行加权结合,其基本原理在文献[26]中得到了以下阐述。
这里为了便于理解,将各个基础学习器之间的结合方式选择为简单的相加,f(x)为多个学习器相加之和。
其中,a0和h(x;a0)分别为初始参数和初始基础学习器。am是优化参数,βm是扩展系数,M是基础学习器的个数。
通过逐步迭代的方式优化f(x),并假设初始值为f0(x),则:
由于评估f(x)的方式是逐步迭代,故假设当迭代步数为(m-1)th时,f(x)表示为fm-1(x),则此时扩展系数βm为:
这里βmh(x;am)的本质为y与fm-1(x)之间的残差值,将其抽象为gm,则得到:
1.2 深度监督
深度监督和侧输出层线性聚合预测,已被证明在许多[27-30]医学分割任务中是有效的。它能够补充各层的梯度流,避免模型在训练过程中发生梯度消失的现象,导致反向传播损失计算时对接近输入层的有效性降低。另一方面正如Zhang 等人[31]所指出的,通常在U-Net 中使用的低级别和高级别特征的简单融合可能不那么有效,因为这两个特征在这方面存在语义水平和空间分辨率差距。因此,使用深监督学习更多“语义”的低级特征可以帮助网络获得更好的U-Net 体系结构性能。图1(a)是U-Net 网络,(b)、(c)是两种常见的深度监督聚合方式,(d)是本文引入的非对称聚合方式。
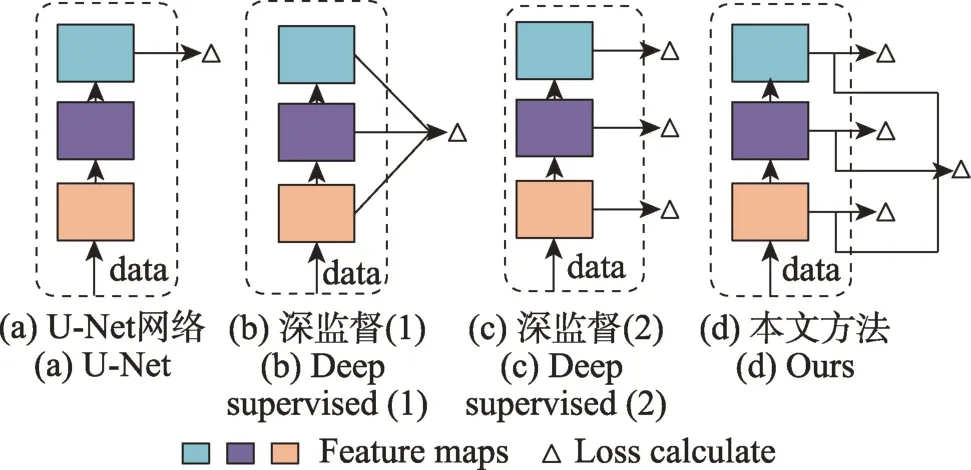
图1 深监督聚合方式Fig.1 Deep supervision aggregation method
2 本文方法
本文提出了一个新的网络结构。浅层信息随着网络加深会变得稀薄,为了采集丰富的浅层语义信息,在下采样阶段,通过将前两个编码器提取的特征信息保留,并由单独路径传输作为此后第一个提升算法块的输入。上采样阶段,每一层通过跳跃连接会接受到大量的浅层信息,这对网络的分割性能具有积极的作用。基于此,本文选择将提升模块嵌入到侧面,接收每次上采样之前的语义特征,作为提升块的输入。提升块中概率分布注意力机制会保留浅层信息,同时也会生成相应的特征信息。之后,第一个提升块的输出和之后的上采样之前的融合信息再作为第二个特征块的输入,迭代往后,逐层保留,直至最后一层。考虑到上采样的弊端,采用双线性插值来调整每一层特征图的尺寸。由于三次提升会得到三个不同层次的特征信息,将其定义为底层、中层和最终层。不同层的特征信息会包含不同程度的语义信息,考虑到全局性,通过深度监督计算各层侧输出损失,如图2 所示。

图2 网络模型结构图Fig.2 Network model structure
2.1 改进的提升算法
将浅深层的特征信息融合在一起能够确保分割的完整性。顾佳等人[32-33]对基础网络添加分级聚合并激活高低层特征信息,会提高分割精度。但在上采样的过程中融合信息当中的底层信息会被稀释,且上采样次数越多,稀释越严重,导致对分割结果的贡献度降低。
受到CAB 方法[22]的启发,本文将其引入血管分割任务,如图3 所示。假定浅层信息流定义为Fˉ,fi(i=1,2,…)分别为基础网络U-Net 三次上采样的输出,K为大小1×1 的卷积核。通过将原始信息流和f1作为第一个提升块的输入,进行如下点积运算:
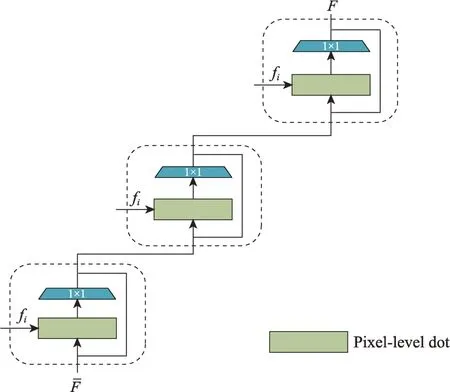
图3 提升结构Fig.3 Lifting structure
其中,u、v为特征向量,T 为转置操作,||为正则化。再经过1×1 的卷积降低通道,减少参数。最后和F通过一个残差结构相加,最大化保留原始特征。依次经过三个提升块进行迭代,并通过双线性邻差值来调整每一次迭代前输入特征的尺寸大小以保持一致,最后输出结果为F。整个过程如式(8)所示。
2.2 概率分布注意力的提升算法
对于浅层信息被稀释问题,按照文献[22]的方法将其转换到概率空间,并通过引入一种概率分布注意力机制来改变浅层信息被映射到概率空间后的权重,直到上采样结束。分别定义在概率空间浅层信息和深层信息为=P(c,i,θ)和Fi=P(c,i,θ)。令:
其中,图片I的大小为N,c代表不同的分割类型:血管的主干、分支以及末梢等。Xi为像素值。
于是,利用Softmax 函数可以进行概率转化:
浅层信息可以为最终分割提供全局的指导作用。通过式(9)将分割结果通过Softmax 引入到概率空间后,可以得出不同类型的概率图。因浅层信息的分割结果较粗糙,相应的血管主干得到的概率权重会比较大。对于每个类别概率图,再将其与fi每个像素点对位相乘(选择每次跳跃连接后,并且在未经过上采样操作之前的信息作为fi,因为此时的fi融合了浅深层网络信息,包含丰富的浅层语义信息),然后将所有类型的注意力特征图拼接在一起得到FCA。换言之,FCA的每一个特征图为每个单一特征图和每一个类型概率图对应像素相乘。如图4 所示,F是经过注意机制之后得到的新的血管特征信息。F与的关系为:
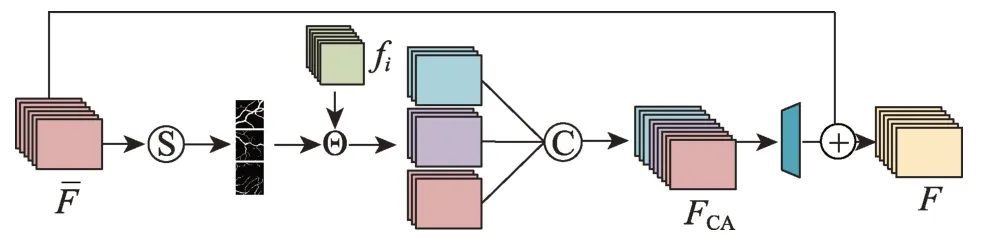
图4 概率分布注意力Fig.4 Probability distribution attention
其中,soft(·)为概率分布映射操作,本文采用的是多分类器Softmax。
2.3 深度监督非对称聚合
1.2 节已经介绍了深度监督的一般结构。此前的工作[30]通过深监督将U-Net 网络上采样三个阶段的损失线性聚合起来,可以提高模型的分割能力,但是作者发现通过对深度监督各个侧输出层损失采用非线性的聚合方式,可以在原来的基础上获得更好的效果,并利用实验进行了验证。
本文引入的深度监督非对称聚合结构如图5 所示,首先对每个分支采用3×3 卷积来调整通道数。然后,将特征映射上采样到与原始图像相同的大小,以生成侧输出特征。侧输出特征可以使用一个简单的1×1 卷积来预测结果,其次将所有的侧输出层特征连接起来,以构造包含丰富的多尺度和多层次信息的混合特征。之后利用非对称卷积n×n进行非线性聚合,非对称卷积的选择原因有两点:其一可以分为两个大尺度的卷积核1×n、n×1 来更好地提取高分辨率的信息,并通过实验对比可以得出n=7 为最佳选择;其二可以减少模型计算的参数量。由于在聚合之后加了ReLU,深监督的特征聚合也具有非线性。
2.4 损失函数
在模型解码阶段中,假设从左往右三个解码块分别称为低层、中间层和输出层。定义W是网络的权重,Wl、Wm、Wf分别为三个解码器的权重。其中某一层采用交叉熵损失函数可以定义:
其中,X是训练样本的数量,p(yi=t(xi)|xi;W,wc)为属于样本X的xi被正确分类为对应类标签t(xi)的概率。c∈{l,m,f}为解码器索引,最后损失函数被定义为:
其中,αl、αm、αf是三个损失的权重,控制不同解码器的强度。在本文实验中,αl、αm、αf分别被设置为0.3、0.3 和0.4。
另外将低层和中间层上采样到原图像尺寸,再和输出层拼接,利用交叉熵函数计算拼接后的损失。
其中,N代表类别的数目,pn,i为当像素i属于第n类时的预测概率值,gn,i为像素i对应的真实标签值。
最后模型总体损失为:
其中,λ为权重系数,本文采用的λ为0.5。在3.4.2小节中对不同λ值进行了实验分析。
3 实验
3.1 数据集
为了验证算法模型的有效性,本文选择在DRIVE[34]和STARE[35]两个公开眼底数据集上进行训练和预测。
DRIVE 数据集是Niemeijer 团队在2004 年根据荷兰糖尿病视网膜病变筛查工作建立的彩色眼底图库。其图像是从453 名25~90 岁的不同个体拍摄得到,随机抽取了其中40 幅,分成训练集和测试集,每个子集20 幅图像,每幅图像对应2 个专家手动分割的结果和对应的掩膜,如图6 所示。其中7 幅有早期糖尿病视网膜病变,33 幅是没有视网膜病变的眼底图,每幅像素为565×584。

图6 数据集Fig.6 Datasets
STARE 数据集是用来进行视网膜血管分割的彩色眼底图数据库,包括20 幅眼底图像,其中10 幅有病变,10 幅没有病变,图像分辨率为605×700,每幅图像对应2 个专家手动分割的结果,是最常用的眼底图标准库之一,但是需要自己手动设置掩膜。为了方便训练,在已有的数据集基础上进行扩充和划分,如表1 所示。

表1 数据集设置Table 1 Setting of dataset
3.2 评价指标
在视网膜血管分割中,将血管图中的像素分为真阳性(ture positive,TP)、假阳性(false positive,FP)、假阴性(false negative,FN)和真阴性(ture negative,TN),并与相应的真实标签进行比较。然后,采用准确性(accuracy,ACC)、敏感性(sensitivity,SE)、特异性(specificity,SP)和F1-score 评价模型的性能。为了进一步评估不同神经网络的性能,还计算接收者工作特性曲线(receiver operating characteristic,ROC)下的面积(area under ROC curve,AUC),如表2 所示。

表2 评价指标Table 2 Evaluation index
3.3 实验环境及参数设置
实验所用的计算机型号为HP Z6 G4 工作站,CPU 为Intel Xeon Silver 4114(×2)20C/40T,操作系统为Windows 10,显卡为NVIDA TITAN V,显存为12 GB。本文方法使用Pytorch 框架和Python 语言进行实验,批数量(batch size)设置为64,用带有默认参数的Adam优化器来训练模型,并使用余弦退火方法辅助训练,初始学习率设置为0.000 5,训练迭代次数为50 轮。
3.4 实验结果与分析
3.4.1 对比实验
视网膜血管分割前期的粗糙信息和高阶特征有效融合能够提升血管分割效果的精确度。提出的融合概率分布注意力的提升算法能够在特征融合的过程中降低前期信息的稀释度,增强对于最终分割的参与度,达到较为准确的分割效果。在提出的提升算法基础上进一步引入了深度监督,补充不同提升块的梯度流,增强模型性能和鲁棒性。为了验证本文算法的有效性,分别与4 种经典算法以及5 种最新算法在DRIVE 和STARE 数据集上进行对比实验。
表3 显示了不同算法的F1、SE、SP、ACC 和AUC。本文方法在DRIVE 数据集上,总体上均取得了比较优秀的性能,其中SP 均取得了最好的表现,优于现有的最高指标;在STARE 数据集上,SP 也达到了最先进的水平,其他指标也表现不错。

表3 不同算法对比Table 3 Comparison of different algorithms
图7 显示了在DRIVE 数据集上不同算法分割效果可视化对比图。
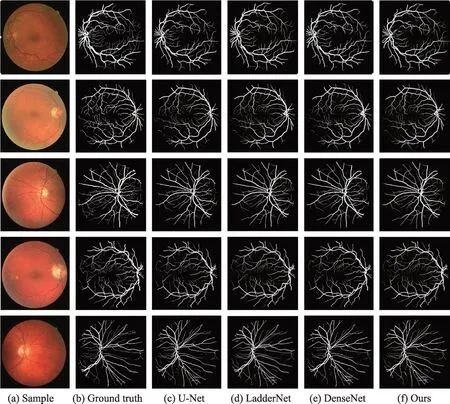
图7 DRIVE 数据集分割可视化Fig.7 Visual segmentation of DRIVE dataset
考虑到添加非对称聚合模块会增大模型复杂度,本文在不同模型上统一使用DRIVE 数据集进行对比实验。其中选取了FLOPs、参数量以及每张图片的平均推断时间作为评价指标从多个方面进行综合评价,如表4 所示。
从表4 中可以看出,因为用1×1 卷积替换了全连接层,添加了非对称模块以及提升模块并不会使模型的参数量大大提高。本文所提出的模型网络参数量有5.3×107,对运行内存的需求不是很高。值得一提的是,在FLOPs 为3.0×109的情况下测试时间只有1.710 s,相较于其他算法,具有一定的实际应用潜力。

表4 复杂度对比Table 4 Complexity comparison
图8 显示了不同方法下对于微小血管的可视化结果。从对比结果可知,本文方法通过减少高低层融合信息的稀释,使得分割结果更加精细化,对于细小末梢血管的分割更加明显。

图8 细节放大对比Fig.8 Detail zoom comparison
3.4.2 消融实验
为了探究不同权值的λ对算法的影响,分别对其取了6 组不同的数值。为了方便训练,以下4 个消融实验只取2 000 样本进行训练。通过实验结果比较得出相对最优结果,见表5。
由表5 可知,当λ=0.5 时,AUC 达到了最好的效果。特别地,当λ=0 时,由式(13)可知,模型深监督聚合方式变成了线性,对于算法的性能增益并不明显。当λ=1.0时,深监督的聚合方式又只有非对称性,相对于线性聚合,对模型性能提升要大。因此,线性和非对称聚合方式的结合更能有效提高算法性能。
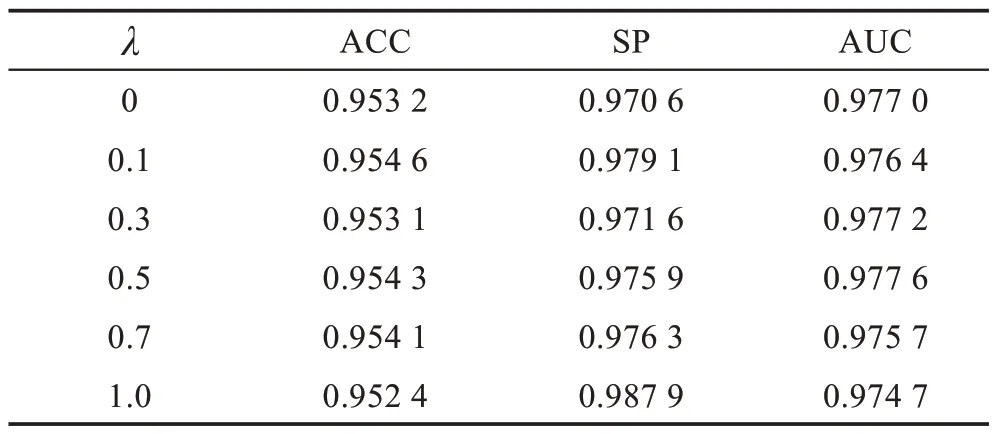
表5 不同λ 取值分析Table 5 Analysis of different λ
为了得到一组较好的损失权重,在已有的经验基础上,本文设定了6 组权重系数对比分析。由表6可以看出,从第一组开始随着αl逐渐增大,ACC 也随之上升,这是因为3 个不同上采样阶段,特征信息丰富度不同,越往后网络提取到的血管信息越多,也越接近真实值。基于以上分析,本文将第3 组权重系数作为实验超参数。

表6 不同α 系数取值分析Table 6 Analysis of different coefficient α
在非对称卷积核选取方面,不同尺寸的卷积核信息提取能力不同,大尺寸的卷积核能够提取到的信息内容更多,但是相应会带来更多的参数计算。为了更客观地得出对比效果,选择U-Net 作为基础网络,选取3×3、7×7、9×9 三种尺寸的卷积核,并将每个尺寸的卷积核拆分成非对称形卷积后进行实验分析。
由表7 可以看出,随着卷积核尺寸变大,算法最终分割的准确率有所提升,但是增加到9×9 以后,准确率提升效果不明显,而参数量越来越大,故从计算成本和分割精度综合考虑,最终选择的卷积核大小为7×7。

表7 不同尺寸卷积核Table 7 Convolution kernels of different sizes
表8 选取了U-Net 网络对深监督非对称聚合方式进行消融对比。从采用线性聚合和非对称聚合的实验结果可以得出,深监督非对称聚合方式能够更好适应原始图像分辨率,从而提高分割性能,且具有一定的泛化性。

表8 不同聚合方式Table 8 Different aggregation methods
4 结束语
本文从浅层信息在多次上下采样过程中容易被稀释的问题出发,引入了浅层信息被稀释带来的两个问题:降低对最后分割的贡献度和梯度流失。通过加入融合了概率分布注意力机制的提升块能够层层助推浅层信息,提高在最终分割中的作用;此外引入的深监督能够补充浅层梯度流,引用的非对称聚合方式相对于线性聚合对模型性能的效果更好。对于医学图像获取大量标签数据困难的问题,如何利用自监督方法进行处理,将是下一步的工作方向。
