基于粒子竞争机制的半监督社区发现算法
2023-03-10王本钰顾益军彭舒凡
王本钰,顾益军,彭舒凡
中国人民公安大学 信息网络安全学院,北京100032
现实生活中,许多复杂系统都被描述成复杂网络的形式,例如生物网络[1]、引文网络[2]、社交网络[3]。复杂网络通常由多个社区组成,同一社区内的节点联系较为紧密,不同社区之间的节点联系较为松散。社区发现便是一个根据复杂网络节点间的关系,将节点划分到各个社区中的一个过程,有助于研究人员了解复杂网络的组织架构和功能。
社区发现由于研究方法的不同已经总结形成了许多具有代表性的算法,例如基于网络边介数的GN(Girvan-Newman)算法[4],基于标签传播的社区发现算法(label propagation algorithm,LPA)[5],基于粒子竞争机制的社区发现算法(stochastic competitive learning,SCL)[6],基于距离动力学的Attractor 算法[7],基于图卷积神经网络(graph convolution networks,GCN)的社区深度图信息极大化算法(community deep graph infomax,CommDGI)[8],融合迁移学习和自编码器的社区发现算法(community detection with deep transitive autoencoder,CDDTA)[9],基于生成对抗网络的社区发现算法(community detection with generative adversarial network,CommunityGAN)[10]。然而这些算法都是无监督社区发现算法,通常只利用了网络的拓扑结构,常常会出现社区发现结果难以解释、算法性能难以衡量的问题,尤其是当网络结构不清晰时,无监督社区发现算法的性能会大幅下降。
为了解决这样的问题,研究人员通常会采取半监督学习方式,通过引入一些复杂网络中易于获取的先验信息,例如节点标签信息[11]和成对约束[12-13]等,提高社区发现算法的鲁棒性和结果的准确性。因此近年来标签传播[14]、随机游走[15]、距离动力学[16]、非负矩阵分解[17]、粒子竞争机制[18]等算法中纷纷引入网络中的先验信息,以半监督学习的方式实现社区发现任务。Hua等[14]提出了一种基于节点影响力的半监督标签传播算法(node influence-based label propagation,NILP),通过节点的度值和局部密度来衡量节点的影响力,将先验信息优先传播给影响力大的节点以控制传播过程,解决了传统的标签传播算法将所有节点视为等价节点而忽略重要节点的问题。Liu等[15]提出了一种基于随机游走的半监督社区发现算法(semi-supervised DeepWalk,SSDW),通过先验信息改善了传统随机游走过程中的节点转移概率,实验证明SSDW 算法能获得较好的社区发现效果。Fan等[16]提出了一种基于距离动力学的半监督社区发现方法Semi-Attractor,结合先验信息和网络拓扑结构来改变节点之间的距离,实验结果表明该算法不仅提升了社区发现的准确性,而且加快了算法收敛速度。Lu等[17]提出一种融合非负矩阵分解与奇异值分解的半监督社区发现算法,通过奇异值分解方法来获得社区数量,然后结合先验信息和非负矩阵分解实现社区发现任务,实验结果表明可以显著提高社区发现效果。
基于粒子竞争机制的半监督社区发现方法最初由Quiles等[19]提出。Quiles等定义了节点粒子竞争机制,粒子在网络中随机游走并且在节点上互相竞争,通过粒子占据更多节点的方式来达到社区发现的目的。Silva等[6]改进了粒子竞争机制中粒子的游走方式,通过结合粒子随机游走和优先游走的方式来实现社区发现任务。Verri等[18]重新定义了粒子竞争机制,提出了基于边粒子竞争机制标签组件展开算法(labeled component unfolding,LCU),通过粒子在网络中执行游走、吸收、生成步骤来争夺各类粒子对网络中边的占据权以实现社区发现任务。王本钰等[20]提出了融合粒子竞争机制与距离动力学模型的DDSCL(community detection algorithm based on dynamic distance and stochastic competitive learning)算法,改善了粒子游走初期随机性大的问题,实验中获得了不错的效果。此后,在错误标签检测[21]、动态社区发现[22]、重叠社区发现[23]、异常节点检测[24]、多层网络社区发现[25]、分类数量预测[26]以及图像分割[27]等各领域中纷纷引入了粒子竞争机制。粒子竞争机制的发展历程证明了其应用于复杂网络社区发现任务的可行性和有效性。
尽管现有基于粒子竞争机制的算法在不同场景下展示了其有效性,但是本文在研究中发现,该类算法仍存在以下不足:
(1)粒子游走过程具有很大的随机性,没有建立粒子游走的倾向性,导致社区发现效果差、粒子收敛速度慢。
(2)粒子游走范围没有约束条件,粒子在游走过程中容易偏离已占据节点,随着粒子游走次数增多,社区发现效果会越来越差。
(3)现有算法中粒子竞争机制仅单一存在节点或者边上,没有一种融合节点粒子竞争机制和边粒子竞争机制的社区发现算法。
为了解决上述问题,本文提出了一种基于粒子竞争机制的半监督社区发现算法(semi-supervised community detection algorithm based on particle competition,SSPC)。本文的主要贡献有以下几点:
(1)结合节点之间的交互影响,根据粒子在节点上的竞争情况提出转移提出概率和转移接收概率,重新定义粒子游走概率,降低粒子游走过程的随机性,建立粒子游走的倾向性,加快粒子收敛速度。
(2)设置粒子在边上的重启机制,体现粒子在边上的竞争情况并且有效限制粒子游走范围,提升社区发现效果。
(3)提出了一种融合了节点粒子竞争机制和边粒子竞争机制的半监督社区发现算法,并给出关于SSPC 算法收敛性的数学证明。在真实网络数据集和LFR 人工基准网络上对SSPC 算法与近几年具有代表性的社区发现算法进行实验测试比较,发现该算法可以获得较好的社区发现结果,同时对主要参数进行了讨论。
1 相关工作
1.1 网络基础知识
给定复杂网络G=(V,E),其中V是网络中节点的集合,E={e=(i,j)|1 ≤i,j≤n,i≠j}是网络中边的集合,用ij来表示边e=(i,j)。
记网络G的邻接矩阵A∈RN×N,定义为:
令网络G中社区类别的集合为y={1,2,…,C},其中C表示网络中社区的数量,yi=c表示节点i归属于c类社区。令网络G中已标记的节点集合为L={v1,v2,…,vl},其中l表示网络中已标记节点的数量。令网络G中无标记的节点集合为U={vl+1,vl+2,…,vl+u},其中u表示网络中未标记节点的数量。因此可得V(G)╞l+u,并且L∩U=∅,L∪U=V。由于网络中已标记节点的数量远远小于无标记节点的数量,本文假设l≪u,并且每个社区中至少存在一个已标记节点。
令h(i)={j|j∈V(i≠j)∧(i,j)∈E},称h(i)为节点i的邻居节点。
令di=|j|j∈V(i≠j)∧(i,j)∈E|,其中,集合内元素的个数用|*|表示,称di为节点i的度。
1.2 粒子竞争机制
近些年来,随着粒子竞争机制的不断完善,基于粒子竞争机制的社区发现算法在社区发现任务中具有良好的表现,其中以SCL[6]、LCU[19]、DPP(dynamic particle propagation)[22]算法较为显著。
Silva 等提出了SCL 算法,SCL 算法通过无监督的方式实现社区发现任务。SCL 算法中随机放置多个粒子在网络中,每个粒子在网络中执行随机游走、优先游走、生成等步骤。在随机游走步骤中,粒子将以同等的概率向周边节点进行游走。在优先游走步骤中,粒子将会以更高的概率访问已被该类粒子占据的节点。在生成步骤中,粒子每游走到一个节点上时将会检查自身的能量状态。如果节点被同类粒子占据,粒子的能量会增加。如果节点被其他类粒子占据,粒子的能量会减少。当粒子能量耗尽时,粒子将会执行生成步骤。粒子将会在已占据节点上重新生成。SCL 算法中每个粒子对应一个社区,以粒子达到收敛状态时每个粒子占据的节点来揭示网络的社区结构。
Filipe 等提出了LCU 算法,LCU 算法是一个半监督社区发现算法。LCU 算法中已知网络中社区的类别,并且每个社区中都有少数已标记的节点作为先验信息。在算法初始化阶段,会在每个社区的已标记节点上产生一个粒子,该粒子携带的标签信息对应所属社区的类别。粒子通过既定的规则在网络中执行游走、吸收、生成步骤,不同类粒子之间会相互竞争,争夺粒子对于边的占据权。在游走步骤中,LCU 算法采用类似于SCL 算法中的随机游走步骤,粒子将以相等的概率向周边节点进行游走。在吸收步骤中,粒子向周边节点游走时会有一定的概率在边上被吸收。如果粒子没有被吸收,粒子将会成功转移到下一个节点上。粒子被吸收的概率取决于当前时刻粒子对于边的占据程度,粒子对于边的支配程度越大,粒子被吸收的可能性越小。在生成步骤中,如果粒子被吸收,粒子将会在该类粒子已标记的节点上重新生成。最终当算法达到收敛条件时,根据粒子对于边的占据程度揭示网络的社区结构。
Li 等提出了DPP 算法,DPP 算法中通过粒子在网络中执行游走、分裂、跳跃步骤改变粒子对于节点的占据程度,粒子对于节点的占据程度的改变也会影响粒子的运动。在游走步骤中,DPP 同样采取向每个邻居节点进行同等概率游走的策略。在分裂步骤中,DPP 算法为了解决LCU 算法中粒子数量需要人为指定的问题,通过粒子在节点上进行分裂的策略,根据网络拓扑结构自动确定每类粒子的数量。在跳跃步骤中,粒子向周边节点游走时存在一定的概率进行跳跃。同类粒子累计访问边的次数越多,粒子越不容易执行跳跃步骤。相反,同类粒子访问边的次数越少,粒子越容易执行跳跃步骤。经过一系列相互作用,DPP 算法可以实现半监督社区发现任务。
2 SSPC 算法
为了提高社区发现的准确性,解决粒子竞争机制中粒子游走随机性大、不能限制粒子游走范围的问题,本文提出一种融合节点粒子竞争机制和边粒子竞争机制的半监督社区发现算法SSPC。SSPC 算法的时间复杂度和网络中节点和边的数量呈线性关系,因此该算法在提高社区发现准确性的同时在应用于大规模网络时也具有很好的扩展性,是一个兼顾准确率和时间复杂度的算法。该算法主要分为4个阶段:(1)初始化阶段,SSPC 算法通过网络中的先验信息以半监督学习的方式在已标记的节点上产生粒子,粒子通过既定的规则在网络中执行游走和重启步骤。(2)游走阶段,SSPC 算法结合节点之间的交互影响,提出了转移提出概率和转移接收概率,重新定义粒子的游走概率,充分体现粒子在节点上的竞争关系,并且建立粒子游走的倾向性,降低粒子游走的随机性,加快粒子的收敛速度。(3)重启阶段,为了体现粒子在边上的竞争关系并且限制粒子游走范围,该算法设置了重启机制。当粒子在边上游走时会产生粒子间的竞争,粒子存在一定概率重启。当粒子重启时,粒子将会基于粒子对于各节点的占据程度选择节点进行重启。(4)收敛阶段,当粒子达到收敛状态时,节点将被某一类粒子所占据。根据各类粒子占据的节点来揭示网络的社区结构。
2.1 初始化阶段
初始化阶段,SSPC 算法会通过网络中的先验信息在已标记节点上产生一个粒子,同时确定每类粒子在初始化阶段对于节点和边的占据程度。
初始化阶段,节点i上的c类粒子数量定义如下:
其中,L表示已标记节点的集合。
初始化阶段,c类粒子对于节点i的占据程度定义如下:
初始化阶段,c类粒子对于边ij的占据程度定义如下:
2.2 游走阶段
在LCU、DPP 等基于粒子竞争机制的社区发现算法中,粒子向周边节点游走的概率由当前粒子所在节点的度值确定,即粒子向周边各节点的游走概率相等,粒子的游走是一个完全随机的过程。这样的游走概率一方面没有考虑节点间的交互影响,未能建立粒子游走的倾向性,另一方面完全随机的游走概率会导致粒子收敛速度慢,社区发现的准确性差。因此,本文结合粒子对于当前节点的占据程度和粒子对于周边节点的占据程度提出转移提出概率Pforward(t)和转移接受概率Paccept(t),重新定义粒子的游走概率Ptransition(t)。
粒子对于节点的占据程度由t时刻该类粒子在节点上的数量和各类粒子在节点上的总数量的比值表示,因此c类粒子在t时刻对于节点i的占据程度定义如下:
其中,表示t时刻,c类粒子在节点i上的数量。C代表粒子的种类,即网络中社区的数量。
各类粒子在t时刻对于节点i的占据程度定义如下:
粒子转移概率Ptransition(t)由提出概率Pforward(t)和接收概率Paccept(t)组成,充分考虑了节点之间的交互影响,并且随着时间变化而动态变化,最终收敛达到一个确定值,c类粒子从节点i向节点j进行转移的概率定义如下:
其中,ij表示边e=(i,j)。
提出概率体现了当前粒子向周边节点提出转移的概率,定义如下:
其中,表示c类粒子在节点j上的占据程度,d(i)表示节点i的邻居节点。c类粒子在节点j上的占据程度越大,粒子从节点i向节点j提出转移的概率越大。
接收概率体现了粒子向周边节点进行转移时被接收的概率,定义如下:
其中,表示c类粒子在节点i上的占据程度,d(j)表示节点j的邻居节点。C类粒子在节点i上的占据程度越大,粒子从节点i向节点j转移时被接收的概率越大。
最后,将粒子转移概率进行归一化处理,定义如下:
其中,aij表示节点的连接情况,若节点之间存在连接,则该值为1,否则为0。
2.3 重启阶段
为体现粒子在边上的竞争关系并且限制粒子游走范围,SSPC 算法中设立重启机制。重启机制中,粒子重启概率和粒子对于边的占据程度有关,c类粒子在t时刻对于边ij的占据程度定义如下:
各类粒子在t时刻对于边ij的占据程度定义如下:
当粒子对于边的占据程度越大,该类粒子执行重启步骤的可能性越小,其他类粒子执行重启步骤的可能性越大。因此,在t时刻,c类粒子从节点i向节点j游走时重启的概率定义如下:
其中,为c类粒子在t时刻对于边ij的占据程度。λ为重启执行概率参数,λ∈[0,1],用来调节粒子在边上的竞争强度和重启执行概率,λ值越大则不同类粒子之间的竞争关系越强,粒子越容易执行重启步骤。若λ为0,则粒子不会执行重启步骤,粒子将一直执行游走步骤。
粒子若执行重启步骤,则下一时刻将会根据粒子对于节点的占据程度选择节点进行重启,当c类粒子执行重启步骤时,在节点i上重启的概率定义如下:
根据粒子占据程度选择节点进行重启的策略,可以防止粒子在游走过程中陷入局部最优,通过局部游走和全局游走相结合的方式,提高粒子的游走能力。
如果粒子不执行重启步骤,则粒子会成功转移到周边节点。粒子重启机制保留了复杂网络中产生的全部粒子,保证了粒子控制能力不会因游走失败而降低。
2.4 收敛阶段
经过多次的粒子游走、重启步骤,SSPC 算法将会得到社区发现情况。对于一个动力学算法,需要讨论算法的收敛条件。LCU 算法为提高算法运算速度,当网络中粒子游走的次数等于最大网络子图的直径长度时算法则收敛。DPP 算法为进一步提高算法的运算速度,当粒子遍历完网络中全部节点后便停止运行算法,输出社区发现结果。本文提出的SSPC 算法为了获得准确的社区发现结果,当每条边上都有一类粒子的占据程度趋于稳定时,则认为粒子已经达到了收敛状态,停止粒子的游走,输出社区发现结果,粒子收敛状态判定公式定义如下:
2.5 算法收敛性分析
本节将对SSPC 算法的收敛性进行讨论。SSPC算法的收敛条件是网络中的每条边上都有一类粒子的占据程度趋于稳定,因此SSPC 算法是一个全局收敛算法。在SSPC 算法中,当t→∞时,网络中的每条边和节点都存在某一类粒子对其的占据程度达收敛状态,同时粒子转移概率也会趋向于一个确定值,达到收敛状态。
假设网络中存在C类不同的社区,每个社区中存在少数已标记节点,在初始化阶段,会在每个社区已标记节点上产生1 个粒子,粒子种类对应社区的类别。
根据式(11)可以定义某一类粒子对于某一条边的占据程度,因此c类粒子在t时刻对于边ij的占据程度定义如下:
根据式(16),可得c类粒子在t+1 时刻对于边ij的占据程度如式(17)所示:
因此,根据式(17)、式(18)和式(19),可得c类粒子在t+1 时刻对于边ij的占据程度如式(20)所示:
接下来讨论粒子对于节点的占据程度和粒子转移概率的收敛性问题。
在t时刻,节点i上的c类粒子数量等于节点i的周边节点转移到节点i上的c类粒子数量加上在节点i上重启的粒子数量,因此可得式(24):
根据式(5)、式(6)和式(24),可得在t时刻,c类粒子对于节点i的占据程度,定义如下:
因此当t→∞,根据式(26),可得在t时刻,c类粒子对于节点i的占据程度如式(27)所示:
因此当t→∞,粒子对于各节点的占据情况也将达到一个收敛状态。
而粒子转移概率Ptransition和粒子对于节点的占据程度相关,因此当粒子对于各节点的占据程度达到一个收敛状态时,粒子转移概率Ptransition也会达到一个收敛值。
综上所述,SSPC 算法是收敛的,具有有效性和可行性。
2.6 算法流程
基于粒子竞争机制的半监督社区发现算法SSPC具体方法流程见算法1。
算法1SSPC 算法
2.7 时间复杂度
SSPC 算法在粒子游走阶段计算粒子游走概率时,需要计算粒子对于当前节点的占据程度和粒子对于当前节点的邻居节点的占据程度,因此时间复杂度为O(C
3 实验
为了验证本文算法的可行性与有效性,将SSPC算法与近几年具有代表性的社区发现算法在真实网络数据集和LFR 人工基准网络上进行对比实验。首先介绍实验数据集、对比算法、实验指标和实验环境,之后进行参数设置实验,最后分析社区发现实验结果。
3.1 实验数据集
3.1.1 真实网络数据集
实验中使用的真实网络数据集是Dolphins[28]、Football[29]、Polbooks[30]、Youtube[31]、Dblp[31]这5 个数据集。真实网络数据集信息如表1 所示。
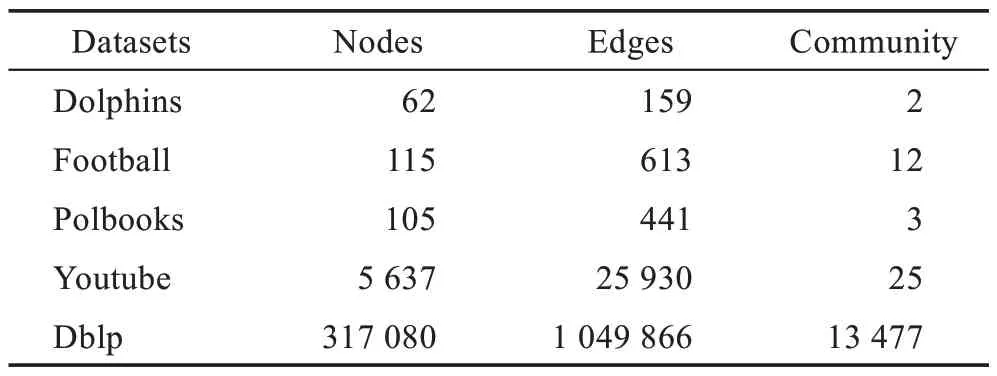
表1 真实网络数据集信息Table 1 Information of real network datasets
Dolphins 数据集源自1994 年至2001 年间对62只海豚之间的关系的调研观察数据;Football 数据集源自美国某橄榄球联盟比赛中12 支大学生参赛队比赛情况网络;Polbooks 数据集源自美国政治书籍网络;Youtube 数据集源自美国社交平台Youtube 上的用户交友关系网络;Dblp 数据集源自科学家合作关系网络。
3.1.2 LFR 人工基准网络
LFR 人工基准网络由Lancichinetti 等人[32]提出,可用于验证各类社区发现算法的性能。LFR 人工基准网络可以通过设定参数的方式调节网络结构。N表示网络中节点的数量;k表示网络平均节点度;kmax表示网络最大节点度;Cmin表示网络中最小社区规模;Cmax表示网络中最大社区规模;τ1表示网络的节点度幂率分布指数;τ2表示网络社区规模幂率分布指数;μ表示网络混合度参数,反映了网络中社区清晰程度,是衡量社区发现算法性能的一个重要参数。μ∈(0,1),μ值越小网络社区结构越清晰,μ值越大网络社区结构越不明显,被发现的难度也越大。
通过调节LFR 人工基准网络的参数,可以获得不同拓扑结构性质的网络,LFR 人工基准网络基本信息如表2 所示。

表2 LFR 人工基准网络信息Table 2 Information of LFR artificial benchmark networks
3.2 对比算法
将SSPC 算法与近几年具有代表性的算法进行对比实验。其中SELP(semi-supervised label propagation)[33]、SDPT(semi-supervised discrete potential theory)[34]、LCU[19]、DPP[22]是半监督社区发现算法,Infomap[35]、GN[4]、CNM(finding local community structure in networks)[36]、Walktrap[37]是无监督社区发现算法。
SELP:是一种基于半监督标签传播的社区发现算法。通过两个信度函数表示已标记节点和未标记节点,在标签传播过程中,将标签从已标记节点上传播到未标记节点上。当传播过程达到收敛状态时揭示网络的社区结构。
SDPT:是一种基于半监督离散势理论的社区发现算法。该算法将复杂网络视为电阻网络,每一个已标记节点看成一个单位电荷,不同标记节点的单位电荷产生的静电场不同。通过Dirichlet 定理计算未标记节点的最大电压值来揭示网络的社区结构。
LCU:是一种基于半监督粒子竞争机制的社区发现算法。通过粒子在网络中执行游走、吸收、生成步骤来争夺各类粒子对网络中边的占据权以实现社区发现任务。
DPP:是一种基于半监督粒子竞争机制的社区发现算法。通过粒子在网络中执行游走、分裂、跳跃步骤来争夺各类粒子对节点的占据权以实现社区发现任务。
Infomap:是一种基于随机游走和信息编码的社区发现算法。通过优化目标函数的方式将相似度较大的节点分配到同一个社区之中。
GN:是一种基于网络边介数的社区发现算法。基于复杂网络社区内部联系紧密、社区外部联系松散的特点,GN 算法通过不断删除社区之间的边获得紧密的社区结构来实现社区发现任务。
CNM:是一种基于模块度函数的社区发现算法。通过不断合并两个社区来获得最大模块度函数值增益以实现社区发现任务。
Walktrap:是一种基于随机游走理论的社区发现算法。Walktrap 算法认为节点在随机游走过程中会陷于社区内部,因此基于节点间的距离定义两个节点的相似性来实现社区划分。
3.3 实验指标和实验环境介绍
本文实验中使用的数据集源自具有真实社区划分的网络,因此本文采用标准化互信息指标(normalized mutual information,NMI)[38]作为实验评价指标。NMI 指标用于比较真实社区结构与算法计算得到的社区结构之间的相似性,NMI 指标的计算公式定义如下:
其中,N表示节点数量;A表示真实社区结构;B表示算法计算得到社区结构;M表示混淆矩阵;CA表示真实社区数量;CB表示算法计算得到社区数量;Mi·表示A中第i个社区的节点数,即矩阵M的第i行元素之和;同理,M·j表示B中第j个社区的节点数,即矩阵M中第j列元素之和;Mij表示A中属于第i个社区的节点属于B中属于第j个社区的节点数。NMI(A,B)∈[0,1],NMI 值越接近1 代表算法计算得到的社区结构B和真实社区结构A越接近。当NMI(A,B)=1 时,表示真实社区结构A和算法计算得到的社区结构B完全相同。
本文的实验环境为:处理器为Intel®CoreTMi7-8750H CPU@2.20 GHz,内存为32 GB,操作系统为Windows 10 64 bit。
3.4 参数设置
SSPC 算法中需要讨论的参数是重启执行概率参数λ和各社区中已标记节点数量。重启执行概率参数λ可以决定粒子在边上游走时执行重启步骤的概率,当λ非常低时,粒子执行重启步骤的概率就会非常低,粒子在游走过程中会远离已被该类粒子占据的节点,导致社区发现效果偏差。虽然SSPC 算法中结合节点之间的交互影响重新定义了粒子游走概率,减小了粒子游走的随机性,即使λ为0 时粒子在游走初期也会建立一定的倾向性,但是误差会随着游走次数增加而逐步增大。当参数λ∈(0,1)时,粒子向其他类粒子控制的节点游走时受限制程度小,粒子游走的随机性较大,尽管每类粒子游走范围会扩大,但是社区发现的准确性会更差。当λ为1 时,粒子游走的范围会受到限制,重启步骤会得到充分的应用,社区发现的准确性越好。实验中,λ取值0至1,步长为0.1,各社区中已标记节点数量设置为3,采用Football、Youtube 两个真实网络数据集进行社区发现任务,实验评价指标是NMI指标,实验结果如图1 所示。
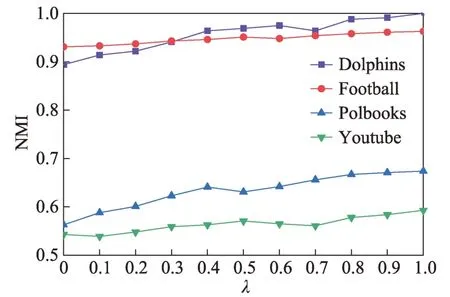
图1 重启执行概率参数λ 的影响Fig.1 Influence of parameter λ on algorithm
实验结果表明,在Football 和Youtube 两个真实网络数据集上,当λ为0 时,NMI 值最低,社区发现效果最差。NMI值随着λ的增大而增加,当λ为1.0 时,NMI 值最大,社区发现效果最好,可以证明重启机制可以有效限制粒子游走范围,防止粒子在游走过程中远离已占据的节点。因此,在后续的实验中λ取值为1.0。
SSPC 算法中各社区中已标记节点数量需要人为指定。因为已标记节点数量越多,算法可利用的先验信息就越多,所以在半监督社区发现算法中当各社区中已标记节点数量越多时,社区发现的效果越好。本文将在接下来的真实网络社区发现实验中进行验证。
3.5 真实网络社区发现实验结果分析
将SSPC 算法与4 种半监督算法SELP、SDPT、LCU、DPP 在Dolphins、Football、Polbooks、Youtube、Dblp 这5 个真实网络数据集上进行对比实验。同时在实验中,讨论各社区中已标记节点数量对于社区发现效果的影响,各社区中已标记节点数量取值1 至5,步长为1,实验中重启执行概率参数λ设置为1.0,实验评价指标是NMI指标,实验结果如图2 所示。

图2 真实网络数据集下算法的NMI值比较Fig.2 Comparison of NMI values of algorithms with real network datasets
实验结果表明,各社区中已标记节点数量取最大值时,NMI 值最高,社区发现效果最好,可以证明各社区中已标记节点数量和社区发现效果呈正相关。LCU、DPP、SSPC 这三种基于粒子竞争机制的半监督社区发现算法相比其他半监督社区发现算法都取得了更好的社区发现效果。当各社区中标记节点数量为3 时,在Polbooks 数据集上,LCU 算法相比SELP算法NMI 值提高16.5%,相比SDPT 算法NMI 值提高6.3%,可以证明基于粒子竞争机制的半监督社区发现算法性能优于其他的半监督社区算法,具有一定的优越性。而SSPC 算法社区发现效果相较于LCU、DPP 在各个数据集上都有较大幅度的提升。当各社区中标记节点数量为5时,在Youtube数据集上,SSPC算法相比LCU 算法NMI 值提高4.8%,相比DPP 算法NMI 值提高6.5%,可以证明SSPC 算法改进了原有粒子竞争机制中存在的问题,提高了社区发现效果。在大规模网络Dblp 数据集上,SSPC 算法相比其他半监督社区发现算法在不同标记节点数量上都取得了更好的社区发现结果,可以证明SSPC 可以运用于大规模网络社区发现,具有较好的可扩展性。
3.6 LFR 人工基准网络社区发现实验结果分析
将SSPC 算法和Infomap、GN、CNM、Walktrap 等无监督社区发现算法在LFR 人工基准网络(表2)上进行实验,分别检测算法对于混合度参数、网络规模的适应性,同时验证半监督社区发现算法相比无监督社区发现算法的优越性。
3.6.1 不同μ 值网络的社区发现实验结果分析
在不同μ值的人工基准网络(N1 网络)上的实验结果如图3 所示。

图3 不同μ 值网络下的各算法的NMI值比较Fig.3 Comparison of NMI values of algorithms in different μ values networks
实验结果表明,当μ取值在0.1 至0.3 时,社区结构较清晰,除了CNM,各算法都取得了不错的社区效果,NMI 值几乎都为1。随着μ值增大,各算法得到的NMI 值都呈下降趋势。其中,SSPC 算法在不同μ值网络上的NMI 值都高于对比算法,当μ值为0.8时,GN、CNM 算法得到NMI 值为0,算法已无法获得社区发现结果,而SSPC 算法仍可以把大多数节点划分到正确的社区中,可以证明半监督社区算法准确性优于无监督社区发现算法,并且SSPC 算法运用于社区发现任务中具有可行性和有效性。
3.6.2 不同规模网络的社区发现实验结果分析
在不同规模的LFR 人工基准网络上的实验结果如图4 所示。

图4 不同规模网络下的各算法NMI值比较Fig.4 Comparison of NMI values of different algorithms in different scale networks
实验结果表明,除了Infomap,SSPC 算法在各规模的网络上相较于其他算法的社区发现效果都有大幅度的提升,可以证明SSPC 算法对于各规模的网络都有一定的适应性。Infomap 算法在不同规模上的LFR 人工基准网络上社区发现效果与SSPC 算法持平,分析原因是LFR 人工基准网络生成过程中,其社区内部连边和社区之间连边分别采用随机连接方式产生。这导致网络中各社区内部连边分布比较均匀,两节点之间的连边概率与其度数成正相关关系,因此在网络μ值相对不高、网络结构相对清晰时,LFR人工基准网络中社区分布比较平衡,网络结构也相对稳定,因此基于随机游走理论的社区发现算法Infomap 可以获得较好的社区发现效果。
4 结束语
本文提出了一种基于粒子竞争机制的半监督社区发现算法SSPC。该算法融合了节点粒子竞争机制和边粒子竞争机制,每个类别的已标记节点会产生粒子在网络中执行游走、重启步骤,且粒子每次执行游走和重启步骤都会影响粒子对于节点和边的占据程度。经过多次游走后,当网络中的每条边上都有一类粒子的占据程度趋于稳定时,根据粒子占据程度可以获得社区发现结果。实验结果表明,该算法具有可行性和有效性,同时本文也给出了关于SSPC算法的收敛性证明。但是本文仍有几个方面不足:首先,本文研究的网络是简单无向网络,并没有研究有向、属性等更加复杂的网络;其次,没有解决复杂网络重叠社区发现问题。在下一步的研究中,尝试将本文算法扩展到更加复杂的网络上执行社区发现任务,并致力于解决重叠社区发现问题。
