迁移学习应用于新型冠状病毒肺炎诊断综述
2023-03-10孟伟袁艺琳
孟伟,袁艺琳
1.北京林业大学 信息学院,北京100083
2.国家林业草原林业智能信息处理工程技术研究中心,北京100083
自2019 年底起,由严重急性呼吸综合症冠状病毒(severe acute respiratory syndrome coronavirus 2,SARS-CoV-2)引起的新型冠状病毒肺炎(corona virus disease 2019,COVID-19)持续爆发,并迅速传播至全球,疫情的发展引起了世界的关注[1]。新冠肺炎的临床初步表现为乏力、咳嗽和发热,与普通感冒特征相似。除此之外,更有患者没有任何症状,属于无症状患者,加大了诊断的难度[2-3]。目前主流的检测方法大多基于实时荧光定量PCR(real-time quantitative polymerase chain reaction,RT-PCR),但是该方法存在一些缺点。例如,从采集到检测出结果耗时较长,与新冠状肺炎病毒传播的速度相比,这是一个相对较长的过程。除了检测的效率低下以外,核酸检测还存在阳性率较低的问题,由于其严重依赖样本采集,存在的问题包括数量和位置不足(鼻腔、喉咙或痰液)[4-5],检出率仅有30%~50%[6]。因此,快速且准确地检测出感染者是一项非常困难的任务。
研究表明,新冠肺炎早期影像表现为多灶性小斑片状阴影和间质性肺异常[7-8],进展期病变范围和数量均会增加,可能会发展为多发性毛玻璃浑浊(ground glass opacity,GGO)[9-11],在重症病例中,可能发生双肺弥漫性实变,很少出现胸腔积液。鉴于X 射线图像和CT(computed tomography)扫描图像的影像特点,这两种方法已用于检测COVID-19[12-13]。因此,除了核酸检测以外,还可以由放射科医生观察患者的X 射线图像和CT 扫描图像进行诊断。然而,这些影片的诊断需要具备专业知识的放射科医生,工作量十分巨大。为了缓解人工检测新冠肺炎病毒的低效性,研究人员在不断探索新的方法。近年来,深度学习技术在计算机辅助诊断领域受到了广泛应用[14],Bar等[15]将深度学习应用于胸部病理检测,在心肌肥厚的诊断中实现了87%的准确率。Wu等[16]提出了一种基于对比增强超声成像的肝病分类诊断系统,采用深度学习方法对良性和恶性肝脏局灶病变进行分类,该方法在准确率、召回率和特异性指标上明显高于其他方法。Burlina等[17]采用了深度卷积神经网络对不同的肌炎进行分类,探究了3 种不同的分类方式,实验结果表明,使用深度学习方法对炎症性肌肉疾病进行自动分类更加有效。Shin等[18]评估了5 种主流的卷积神经网络(convolutional neural network,CNN)模型在两种不同的计算机辅助诊断应用上的性能:胸腹淋巴结检测和间质性肺疾病分类,为该疾病提供了一种完全自动化的诊断方法。Sirinukunwattana等[19]提出了一种空间约束卷积神经网络,对癌组织的组织病理学图像进行检测以及对细胞核进行分类。相比其他方法,所提出的网络在检测和分类上都取得了更高的F1-score。
然而深度学习方法具有两方面的局限性:一方面,深度学习模型的训练过程依赖于大量数据,具有数据饥饿型的特点;另一方面,模型的训练过程耗时长,由于需要解决的问题变得不断复杂,模型所需要的参数数量也在不断增加,这将导致模型参数过多且不容易优化。
和其他成像领域相比,带标签的医学影像数据集一般比较小。迁移学习能够弥补医学图像数据集数量不足的缺陷,并且降低过拟合的风险。Girshick等[20]是将迁移学习与预训练的CNN相结合用于图像分类的最早贡献者之一。Nobrega等[21]采用在ImageNet[22]上预训练的模型处理肺结节图像,并使用传统分类器对返回的深层特征进行分类。实验结果表明,预训练模型和分类器的最佳组合是CNN-ResNet50 和支持向量机径向基函数(support vector machine-radial basis function,SVM-RBF),达到了88.41%的准确率和93.19%的AUC(area under curve)。Behzadi-Khormouji等[23]采用了基于问题的迁移学习模型检测儿童胸部X 射线中的实变,该模型取得了94.67%的准确率,优于之前的其他模型。
由于现有的研究方向比较分散,本文将针对迁移学习技术介绍当前的研究现状,根据模型类型展开分类探讨,并介绍具有代表性的基于迁移学习技术的诊断模型,分别从数据集来源、数据预处理方式、基于迁移学习的诊断模型、模型可视化、评价指标以及模型性能6 个层面展开剖析与对比,最后提出当前面临的技术问题以及未来的技术发展走向,以供后来学者研究参考。
1 COVID-19 医学影像数据集
1.1 X 射线图像数据集
X 射线设备是大多数医疗保健系统中的标准设备,因此胸部X 射线成像技术在许多临床站点更容易获得和访问。目前常用的COVID-19 检测开源X 射线数据集有以下5 个,这5 个数据集的采集来源比较可靠,标签规范且完整。相比其他数据集,这些影像数据在质量上相对较好。表1 列出了这些数据集的分布情况、开源网址和数据格式,图1 为部分数据集分布情况的饼图。

图1 部分胸部X 射线数据集分布饼图Fig.1 Pie chart of partial chest X-ray dataset distribution

表1 胸部X 射线数据集Table 1 Chest X-ray datasets
(1)COVID-chestxray[24]
该数据集是一个GitHub 网站上开源的COVID-19 胸部X 光和CT 图像数据集,其中主要包括COVID-19 阳性、严重急性呼吸综合症(severe acute respiratory syndrome,SARS)、中东呼吸综合症(middle east respiratory syndrome,MARS)和急性呼吸窘迫综合症(acute respiratory distress syndrome,ARDS)。目前,该数据库保持定期更新,主要用于多分类模型。
(2)Pneumonia-chestxray[25]
该数据集包含5 863 张胸部X 光图像,分为肺炎和正常两个类别。由两位专家进行标签化,第三位专家负责审查,以减小标注误差。研究人员通常使用该数据集进行数据增强,解决数据集过小和类别不平衡问题。
(3)COVID-19 Radiography Database[26]
该数据集是Kaggle 上的一个开源数据集,在第二次更新中,此数据库增加到3 616 个COVID-19 阳性病例、10 192个正常、6 012个肺部不透明(非COVID肺部感染)和1 345 个病毒性肺炎图像。目前,此数据库还在持续更新中。
(4)COVID-19 Pneumonia Normal Chest Xray PA Dataset[27]
该数据集是从不同来源检索到的COVID-19 的X 射线样本,这些样本包括2 313 个COVID-19 阳性、2 313个正常和2 313个肺炎图像,样本分布比较均匀。
(5)COVIDx-CXR-3 Dataset[28]
该数据集是Github 网站上一个开源COVID-19 X 射线图像数据,目前还在不断更新中,最新版包含来自16 648 名患者的29 986 张图像。据作者所知,这是公开可用的COVID-19 阳性病例数量最多的数据集。
1.2 CT 扫描图像数据集
CT 是一种较为先进的数字放射成像,与胸部X射线图像相比,CT 扫描图像能够得到患者胸部的精确图像,器官、骨骼和组织更加清晰并且携带更多的信息,使其成为诊断肺部状况的有效方法。目前常用的COVID-19 检测的CT 数据集有以下6 个,这些数据集质量较好,具有潜在的研究价值。表2 列出了5 个数据集的分布情况、开源网址和数据格式。图2为部分CT 数据集分布情况的饼图。
图2 部分CT 数据集分布饼图Fig.2 Pie chart of partial CT dataset distribution

表2 CT 数据集Table 2 CT dataset
(1)COVID19-CT[29]
该数据集是一个公开的COVID-19 CT 数据集,作者从医学预印本上提取出这些图像,其中包含349张阳性CT 扫描和463 张正常或包含其他类型疾病的CT 扫描,该数据集在早期图像分类中最为常见。
(2)CC-CCII[30]
该数据集是由中国胸部CT 图像调查协会构建的大型COVID-19数据集,共有617 775张CT图像,由4 154名患者所提供。图像种类包括COVID-19阳性、普通肺炎和正常。其中普通肺炎又包含病毒性肺炎、细菌性肺炎和支原体肺炎。这是目前针对COVID-19 建立的大型CT 切片数据集之一。
(3)SARS-CoV-2 CT[31]
该数据集包含了210 名不同患者的4 173 次CT扫描,其中2 168 次是由80 名感染了SARS-CoV-2 患者的CT 扫描构成,并且都经过了RT-PCR 测试进行确认,具有一定的可靠性。
(4)COVID-CT-set[32]
该数据集共有63 849 张CT 扫描图像,其中有15 589 张表现为COVID-19 阳性,其余48 260 张表现为正常,由95 名COVID-19 患者和282 名正常受试者的CT 扫描组成。该数据集的新颖之处在于其使用16 位灰度数据格式,而不是将图像转换为8 位数据,从而保持数据的完整性。
(5)MosMedData[33]
该数据集包含了1 110 名匿名患者的胸部CT 扫描图像,根据患COVID-19 不同严重程度分为了5类,分别为CT-0 到CT-4,其中CT-0 表示正常或无病毒性肺炎,CT-1 到CT-4 表示COVID-19 阳性且毛玻璃样混浊、肺实质受累的程度从小于等于25%到超过75%。该数据集适合用于将CT 判别为COVID-19 阳性后,再进行细粒度分类。
(6)BIMCV COVID-19+[34]
该数据集包含了COVID-19 患者的胸部X 射线图像和CXR(CR、DR)图像,其中CR(computed radiography)图像7 377 张,DR(digital radiography)图像9 463 张和CT 图像6 687 张。此外,还提供了大量信息,包括患者的人口统计信息、投影类型和采集参数等。
2 数据预处理方法
将图像分类算法直接应用于原始数据集通常是不可行的,例如,医学数据图像质量受设备和显示系统的影响,质量会受到一定的损坏;数据集分布不平衡问题,将导致迁移学习效果下降。因此,在应用算法之前解决上述问题非常重要。本章将讨论常用的数据预处理方法,如图像重采样、对比度和亮度调整、旋转或翻转、放缩或剪切和生成式对抗网络(generative adversarial networks,GAN)[35],这些方法是构建检测COVID-19 模型的首要步骤。
2.1 图像重采样
图像重采样是图像预处理最常用的方法之一,通常情况下,神经网络的输入必须是固定长度的图像,但在COVID-19 数据集中,图像大小并不统一,因此在进行输入之前需要对图像进行上采样或下采样,即调整图像大小。
2.2 对比度和亮度调整
由于有的数据集来自不同的设备或不同的采集场景,实验所用到的CT 扫描图像和胸部X 射线图像具有整体明暗程度不一和对比度低的特点,通常需要对图像进行自适应对比度和亮度调整,从而得到质量更高的图像。
2.3 数据增强
类别不平衡问题是图像处理和计算机视觉中的常见问题,在医学领域表现更为明显。由于医疗数据涉及患者的隐私,特定疾病的图像数量要少于其他类别的图像数量。因此,在训练模型之前对数据集进行数据增强处理尤为重要。COVID-19 为近年新发现的疾病,数据集往往较小,且COVID-19 阳性数据的占比也较小。通常对该类数据集进行数据增强操作,通过创建具有较少对象的类来修复类别不平衡。实现数据增强常见的方法包括有监督的几何变换以及无监督的GAN。有监督的几何变换包含对图像进行水平和垂直翻转、剪切变换、随机旋转等操作[36]。图3 展示了几种常见的几何变换。无监督的GAN 可以对数据集中的少量数据样本进行扩充,是解决图像类别不平衡的常用方法[35]。图4 展示了由GAN 网络生成的人工COVID-19 胸部X 光图像[37]。结合当前研究,在以上这些预处理方法中,使用尺寸调整的研究比例较高,而使用GAN 的研究比例较低。Gifani等[38]对COVID19-CT 数据集采用了较原始尺寸10%的随机水平和垂直移动,20%的随机旋转和水平翻转。Sheykhivand等[37]采用了GAN 技术对数据进行预处理,获取更多的COVID-19 阳性数据样本。除此之外,一些研究人员还采用了自适应滤波器[39]和仿射变换[40]的方法。

图3 常见几何变换Fig.3 Common geometric transformation
图4 由GAN 网络生成的COVID-19 胸部X 光图像Fig.4 Chest X-ray image of COVID-19 generated by GAN network
3 基于迁移学习的COVID-19 检测诊断模型
3.1 迁移学习概述
深度学习方法可以直接从任务中提取并学习相关特征,协助研究人员解决目前的复杂问题。训练模型需要大量数据,在训练数据不足的情况下,很难建立最佳的模型。模型中的参数数量随着网络的加深而增加,网络越深,计算越复杂,对训练数据的要求也越高。由分析可知,COVID-19 数据集属于小型数据集,因此可以利用迁移学习方法来弥补COVID-19 数据集数量不足的缺陷,以取得更好的效果。
迁移学习是一种机器学习方法,将模型在源域中学习到的知识应用到目标域,因此能够减少收集额外训练数据的需求和工作量。Girshick等[20]是将迁移学习与预训练CNN 一起用于图像分类,从相对较小的数据集学习,并用于目标检测的最早贡献之一。迁移学习通常加载ImageNet 上的预训练模型,有关迁移学习的研究表明,从ImageNet 等大数据集学习到的特征可以高度转移到各种图像识别任务中,并且经过充分微调的预训练CNN 可能比从头开始训练更加有效[41]。同时,采用预训练模型有很多好处,例如,所需的训练时间更短,对硬件的要求降低,计算量也更低。根据预训练数据的来源,可以将迁移学习分为跨域和跨模型两种迁移学习[36]。在医学应用中,基于跨域的迁移学习使用的是在自然图像上的预训练模型,如ImageNet 数据集,而基于跨模型的迁移学习使用的是在医学图像上的预训练模型,如严重急性呼吸综合征(SARS)图像数据集。图5 展示了基于跨域和跨模型两种方法,模型对从上述图像中所学到的知识进行迁移的方法分为特征提取器和微调网络两种方法。其中使用较多的方法是特征提取器方法,通过更改预训练模型的最后一层,其他层的参数被冻结,只有最后一层的参数针对新任务进行训练[42]。如果目标任务与原始任务相似,那么使用该方法能够达到更好的效果。在目标任务的数据有限的情况下,这种方法能够有效减少训练过程中的参数数量并避免过拟合;当目标任务拥有足够多的数据集,则可以训练整个网络[43],使用预先训练的模型而不是随机初始化权重的模型,这样能够提高模型的收敛速度[41],这种方法并不会冻结卷积神经网络,而是在训练过程中更新权重,称为微调网络方法。本节将对基于迁移学习的COVID-19 诊断的典型模型进行分类讨论。
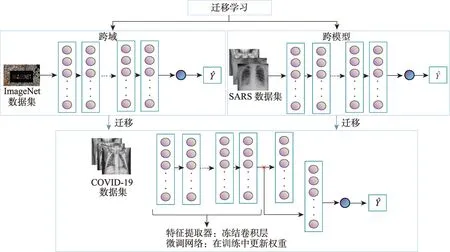
图5 迁移学习的两种方法Fig.5 Two approaches of transfer learning
3.2 传统迁移学习COVID-19 诊断模型
传统迁移学习通常只采用预训练网络,不叠加其他网络和模型,对模型进行简单的微调。Rahaman等[44]在一个包含860 张胸部X 光射线的小型数据集上,对比了15 种不同的预训练CNN 模型。由于数据集较小,采用了数据增强方法扩充数据集,对比了使用数据增强前后模型的准确率和损失率,增强后准确率得到了明显提升且损失率下降,可以有效对抗过拟合。根据比较得出,VGG19 的各类指标均为最佳,准确率为89.3%,精确率为90.0%,召回率为89.0%,F1-score 为90.0%。该研究仅使用了传统的迁移学习模型,由于该数据集较小,浅层网络比深层网络表现得更好。随着网络深度加深,网络出现了梯度消失问题,使得网络的性能下降。基于此数据集,浅层网络能够达到较好效果,但这可能导致模型的泛化能力较差,该研究忽略了对模型进行外部验证,而外部验证对于检测模型的稳定性至关重要,缺乏外部验证的模型可能最终也无法在临床实践中应用。
在传统迁移学习的基础上,加入一些优化方法,分类效果可以得到明显提升。Zhang等[45]将预训练网络DenseNet 与优化方法相结合,首先采用数据增强方法扩充训练集大小,然后训练DenseNet 网络。与其他迁移学习方法不同的是,该研究提出了一种优化框架,即对网络的冻结层、中间层和新层分配了不同的学习因子。冻结层的学习因子设为0,即不更新;中间层具有预训练模型的权重,将其设为1 并缓慢更新;由于新层具有随机初始化的权值,分配的学习因子为10,以便进行快速学习。该策略使得不同的层采用不同的学习速度,提高了模型的性能。优化后的迁移学习算法的召回率、特异性、精确率、准确率、F1-score 和马修斯相关系数分别为96.35%、96.25%、96.29%、96.30%、96.30%和92.64%。此外,该研究使用了预计算的方法,将冻结层后的特征图保存到硬盘,以减少随机存取存储器(random access memory,RAM)存储,加快了算法的速度。然而,该研究没有验证冻结层、中间层和新层的最佳值,并且只采用了一种学习因子的组合,没有测试其他的组合值以寻找最优的组合配置。
3.3 集成迁移学习COVID-19 诊断模型
集成学习是一种融合两个或多个基础学习器特征的学习策略,能够减少预测误差中的方差,因此该框架比单一模型具有更强的鲁棒性。传统的集成框架,如平均概率得分、多数投票等,在对COVID-19 进行分类的任务中被大量研究者所采用。
Gifani等[38]对CT 扫描数据集进行二分类时,由于其使用的数据集较小,首先采用了数据增强技术扩充数据集。然后对15 个主流的预训练网络进行了微调,采用多数投票准则对不同网络进行了集成。作者通过大量实验评估了不同网络结构下集成的有效性,共使用了3、5、7、9、11、13 和15 种不同体系结构的集合。通过实验得出,结合5 种迁移学习模型的集成 模型,即EfficientNetB0、EfficientNetB3、Efficient-NetB5、Inception-ResNet-v2 和Exception,相较于其他模型取得了最佳效果,并且优于单个模型,准确率达到了85.0%,精确率达到了85.7%,召回率达到了85.4%。
Kumar等[46]采用了多数投票的集成学习策略对胸部X 射线图像进行二分类和多分类,其中集成的模型包括EfficientNet、GoogLeNet、Xception。通过实验结果得出,该集成模型的分类效果优于单个网络,能够增强学习系统的泛化能力。
Rajaraman等[47]在对肺部X 光的多任务分类中,首先对多个预训练模型进行了剪枝操作,减少可训练参数的数量,以减轻计算的负担。然后选择性能最好的剪枝模型构建集成模型,采用了最大投票、简单平均、加权平均和模型叠加等集成方法进行预测。结果表明,加权平均策略的精度最高,能够达到99.01%的准确率。
集成学习通过考虑预测的多样性,提高了组合模型的性能。但是上述的简单融合方案,如多数投票准则和加权平均准则,没有考虑到基于测试时不同分类器所获得的决策得分,根据不同的得分为分类器分配不同的权重。传统的加权平均方法大多倾向于预先定义分类器权重,是一个静态的计算过程,没有考虑到模型对每个样本预测的置信度。Kundu等[48]采用了四种预训练模型,分别是VGG11、Goog-LeNet、SqueezeNet v1.1 和Wide ResNet-50-2,提出了一种基于模糊积分的集成方法。该方法不是为每个分类器分配一个固定的权重,而是在训练的过程中动态分配权重,能够进一步细化预测。根据各个分类器获取互补信息的概率分数,动态调整各模型的权值,比传统的静态加权平均具有更强的鲁棒性。
Paul等[49]采用了VGG16、ResNet18 和Dense-Net161 三种预训练模型,通过Grad-CAM(gradientweighted class activation mapping)可视化各个模型所关注的胸部X 射线区域,观察到这三个模型能够注意到胸部的不同病理区域,因此通过集成能够产生更好的结果。该文提出了一种基于倒钟形曲线的模型集成,模型的权重根据倒钟形曲线函数进行分配,有助于惩罚更大范围的低置信度值,从而提高模型的性能。
以上集成模型分别采用了多种不同的模型进行集成,然而训练多个预训练神经网络进行模型平均的计算成本较高,快照集成是在不增加训练成本的情况下集成多个网络,采用余弦退火循环调度学习率,在训练过程中定期保存模型参数,实现集成的效果。Samson等[50]对COVID-19 的胸部X 射线诊断过程中,采用了一种改进的快照集成技术,提出用加权平均代替所有模型的平均概率,且将计数器的数量规定在一定的范围内,因此可以得到更加精确的改进权重。该方法适用于训练数据有限和数据分布不均匀的情况,从而使模型具有良好的鲁棒性。
3.4 混合型迁移学习COVID-19 诊断模型
除了上述迁移学习方法以外,许多研究人员采用混合模型,将迁移学习与其他模型相结合,提出了许多新框架,以此提高模型的泛化能力。Sheykhivand等[37]提出了一种迁移学习混合模型,将GAN、深度迁移学习、长短期记忆(long short-term memory,LSTM)网络相结合使用。首先使用GAN 网络生成图像,平衡各个类的数据。然后改进了预训练网络Inception V4,将两个LSTM 网络嵌入其中。结果表明,较其他迁移学习模型,该混合模型在各个指标上都有明显提升。修改后的预训练网络与LSTM 网络相结合能够减小网络的震荡,提高模型训练的速度,加速模型的收敛,同时也提升了该算法的精度。该实验为了验证所提出网络的鲁棒性,将不同信噪比(4 dB 到20 dB)的高斯白噪声添加到原始胸部X 射线图像上,对算法进行了观测噪声测试,观察该模型分类的准确率。实验结果表明,在添加了不同信噪比的高斯白噪声后,分类准确率仍然能够达到80%以上,证明了所提出模型对噪声具有较强的鲁棒性。但是该研究由于数据集数量不足,混合了6 个不同的数据集,混合的数据集过多可能会存在偏差,模型训练结果的可信度会降低。例如,有的医疗设备会对X射线图像进行文本注释,而另一些设备不会注释,这就产生了两种不同的背景信息,如果这两种数据集融合在一起且恰好类别不同,网络会学习背景信息,产生与任务无关的特征,而分类器将关注最容易区分类别的特征,而不是真正的特征。在研究过程中数据集的选择也是影响结果的关键因素,尽量避免混合数据集或选择偏差较小的数据集进行混合,以提高结果的可信度。
Niu等[51]使用了远域迁移学习方法(distant domain transfer learning,DDTL),提出了一个新的迁移学习框架,该框架包含两部分:缩小尺寸的ResUnet 分割模型和距离特征融合(distant feature fusion,DFF)。传统的迁移学习算法假设源域和目标域存在一定的共享信息,然而在实际应用中这种假设不总是成立。例如医学图像和自然图像领域的特征联系比较松散,很容易导致负迁移。在该项研究中,采用了跨模型的迁移学习,使用没有标签的Office-31、Caltech-256 和胸部X 射线图像数据集作为源数据,并使用一小部分带标签的COVID-19 肺部CT 作为目标数据,使源域数据与目标域数据联系更加紧密,有效处理训练数据与测试数据之间的分布偏移。此外,该研究引入了新的特征选择方法DFF,并没有使用传统迁移学习中的预训练网络框架,而是采用了卷积自动编码器和解码器的形式。并且达到了96%的分类准确率,这比非迁移学习算法的分类准确率高0.13,比传统的迁移学习算法高0.08。该算法有两方面的改进:第一,不需要有标签的源域数据,只需要少量的带标签的目标域数据,该模型在目标域上就能够达到较高的分类准确率;第二,它解决了传统迁移学习算法产生的最具挑战性的问题之一,即负迁移问题。但是该算法仍存在一些不足,例如,大多数远域迁移学习算法往往是针对特定情况的,同样的算法难以运用到其他的领域。并且提取远距离特征的过程计算量较大,目前基于特征的远域迁移学习算法可解释性较差。
Perumal等[52]将机器学习方法与迁移学习方法相结合,使用机器学习方法手动提取特征。首先对所有图像进行预处理,采用直方图均衡化和维纳滤波器方法增强对比度和去除图像噪声,并提高图像质量。然后对COVID-19 胸部X 射线图像构建灰度共生矩阵,提取出Haralick 特征,该特征可以确定相邻像素点之间的强度关系,将其输入ResNet50、VGG16和InceptionV3 预训练模型进行分类。最后使用Grad-CAM 生成热力图,对网络进行可视化。实验结果表明,基于VGG16的迁移学习模型相较于ResNet50和InceptionV3 获得了最佳表现,该模型的准确率达到了93%,精确率达到了91%,召回率达到了90%。但Haralick 特征的提取通常需要人工干预,而手工提取特征经常导致特征冗余,造成参数量和计算量的急剧增加。并且作者没有设置对比实验说明手动提取的Haralick 特征比卷积神经网络自动提取的特征更加有效。
Um等[53]提出了一个由深度卷积神经网络、特征增强机制和双向LSTM(bidirectional LSTM,BiLSTM)组成的统一架构,将预训练的CNN模型,如ResNet50、SqueezeNet、GoogLeNet 和DenseNet201与特征增强机制和BiLSTM 相结合来评估模型的性能。该框架没有使用传统的数据增强策略,例如基于几何变化的数据增强,而是采用基于重构独立分量分析(reconstruction independent component analysis,RICA)[54]特征增强机制,通过特征空间逼近真实分布,所生成的特征是相互独立的,并且保证了特征的多样性。该方法生成的特征与上述生成的Haralick 特征相比较,该低维增强特征更紧凑,可以显著消除干扰信息或冗余。最后使用主成分分析(principal components analysis,PCA)投影和t分布-随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)特征可视化方法解释该模型。所提出的方法在三个公开数据集上进行了测试,并与最新的模型相比较,实现了97%的准确率,比目前关于三分类的最佳模型高出0.1。
Jokandan等[55]提出了一种基于不确定性感知的迁移学习方法,首先采用4 个预训练网络VGG16、ResNet50、DenseNet121、InceptionResNetV2,从胸部X 射线和CT 图像中提取深度特征。为了证明提取特征的有效性,该文引入了Grad-CAM 的概念,对模型的决策进行了可视化,所描绘的热力图突出显示了分类决策输入的最显著区域。然后对网络进行微调,为了避免在将特征传递给分类模型之前丢失,在最后一层卷积层中舍弃了池化操作,并且将最后一层全连接层用不同的机器学习分类器替换,包括KNN(K-nearest neighbors)、linear SVM(linear support vector machine)、RF(random forest)等。实验结果表明,SVM 和神经网络模型在准确率、召回率、特异性和受试者工作特征曲线(receiver operating characteristic curve,ROC)方面取得了最佳结果。该文引入了认知不确定性来解释模型分类结果的不确定性,认知不确定性与模型的泛化能力密切相关。由于所使用的新冠肺炎数据集较小,训练数据不足,导致模型对于没有见过的数据会有很低的置信度。模型在进行高风险应用和处理小型稀疏数据时,定量分析其决策的不确定性非常有必要。
4 模型可视化
神经网络体系结构通常被称为黑匣子,将图片输入网络之后,无法直观地体现产生输出的工作机制。为此,许多研究人员采用多种方法对预测结果进行可视化,并通过生成热力图来标识胸部X 射线的关键区域。常用的可视化方法包括类激活图(class activation map,CAM)[56]、基于梯度的类激活图(Grad-CAM、Grad-CAM++)[57]、分层相关性传播(layer-wise relevance propagation,LRP)[58]和局部可解释模型-不可知解释(local interpretable model-agnostic explanation,LIME)[59]。以上方法能够直观地展示分类结果。例如,类激活图将具有不同亮度的特征权重生成二维热图,亮度与特征的重要性相对应。该热图被叠加在输入图像上,以定位突出的区域。在基于CT 扫描图像的COVID-19 诊断模型中,只有少数研究采用了CAM 和Grad-CAM 对模型进行可视化解释,更多则是将其应用于胸部X 射线图像。图6 显示了当输入图像被分类为COVID-19 时,Grad-CAM 定位突出区域的可视化结果。

图6 Grad-CAM 可视化结果Fig.6 Results of Grad-CAM visualization
5 评价指标
分类任务中,模型常见的评价指标包括准确率(Accuracy,ACC)、精确率(Precision,PRE)、特异性(Specificity,SPE)、召回率(Recall)、F1-score、ROC曲线和AUC 指标。
在分类模型中,准确率是衡量分类器性能质量的最常见、最基本和最简单的标准,但其主要缺点是无法区分“假阴性”和“假阳性”,该标准认为所有的错误都是相同的。因此,高准确率并不能反映模型的实际性能。由分析可知,有的COVID-19 数据集具有高度不平衡性,此时准确率就会失效,因此引入了精确率、召回率和特异性等综合指标来对模型的性能进行全面的评判。准确率、精确率、特异性、召回率计算分别如式(1)~(4)所示:
其中,TP(true positive)是指样本被正确分类为阳性;TN(true negative)是指样本被正确分类为阴性;FP(false positive)是指样本被错误分类为阳性;FN(false negative)是指样本被错误分类为阴性。
召回率和精确率均为单一指标,一般情况下,召回率越高,精确率越低;精确率越高,召回率越低,两者是相互制约的关系。根据不同的分类情况,引入了F1-score,F1-score 是精确率和召回率的调和平均值,它综合考虑了这两种指标,F1-score 的计算公式如式(5)所示:
ROC 曲线又称为受试者工作特征曲线,1-specificity 为横坐标,表示假阳性率,sensitivity 为纵坐标,表示真阳性率。由于ROC 曲线无法进行定量比较,又引入了AUC。AUC 表示在此坐标轴中曲线的面积。相比ROC 曲线,AUC 值作为一个数量值,更具有可比较性,可以进行定量的分析,因此大多研究者也采用该值作为评价模型的标准。
6 模型性能
模型性能的好坏由多方面的因素所决定,如数据集的大小、所采用的模型以及模型的特点等。表3从数据集大小、分类类型、性能评价、所采用模型和模型特点,对当前基于迁移学习的COVID-19 检测诊断模型进行分析和比较。

表3 不同模型分析和比较Table 3 Analysis and comparison of different models

表3(续)
6.1 数据集
对所采用数据集的类别进行分析,采用CT 数据集和胸部X 光数据集的分类模型比例大致相等。由于CT 图像中往往包含更多的细节,早期研究者更多采用CT 图像作为数据集,但是CT 扫描图像采集时间较长、采集的成本较高。而胸部X 射线成像技术在许多临床站点更加成熟也更便宜,因此后期使用胸部X 射线的研究也开始逐步增多。从采用的数据集的大小可以看出,目前关于COVID-19 的CT 扫描图像和胸部X 射线图像数据集大多属于小型数据集,因此许多研究采用了有监督的几何变换,即对图像进行水平和垂直翻转、剪切变换、随机翻转等操作,以增大各类图像的占比。从数据集的类别占比可以得出,大多数据集具有类别不平衡的特点。和其他成像领域相比较,医学图像领域的数据集大多封存于医院的专有数据库中,由于涉及患者的隐私,可能会阻碍数据的公开和获取。因此COVID-19 阳性病例图像数量占比普遍较小,大多研究采用无监督的GAN 生成COVID-19 类别的图像,以增大COVID-19图像的占比。
6.2 采用模型
大多研究采用的骨架网络为VGG、ResNet、DenseNet 和Inception 等当前比较流行的预训练模型,对胸部X 射线图像和CT 图像的特征进行有效提取,最后对图像进行分类。所采用的迁移学习模型通常有两种迁移策略:第一种策略通过预训练模型进行特征提取,不改变预训练模型的初始框架和所有学习的权重。骨架网络仅充当特征提取器,将提取到的特征送到执行分类任务的新网络中。该方法避免了从头开始训练深层网络所带来的计算成本。第二种策略较第一种策略更为复杂,首先对骨架网络进行特定修改,这些修改可能包括架构调整和参数调整。只保留从先前任务中挖掘的特征,而将新的可训练参数插入网络。这些新参数需要使用大量的数据进行训练,才能发挥优势。
6.3 分类类型
基于迁移学习的诊断模型分类类型包含二分类、三分类和四分类,具体将胸部X 射线图像和CT图像根据健康、病毒性肺炎、细菌性肺炎和COVID-19 阳性进行分类。大部分研究的分类类型仅包含二分类,只将图像区分为感染COVID-19 或正常。只有少部分研究会细化到三分类或四分类,三分类将图像区分为感染COVID-19、健康、患有其他肺炎;而四分类则是将其他肺炎再细分为感染病毒性肺炎或细菌性肺炎。选择二分类虽然可以加快模型的诊断速度,但是并不能诊断患者是否患有普通肺炎,不便于对患者进行后续治疗。
6.4 性能评价
在上述研究中,采用的评价指标主要包括准确率、精确率、特异性、召回率,少数研究加入了F1-score和AUC 指标。大部分研究性能能达到90%以上,少部分在85%左右。由于该分类任务属于医疗诊断,在保证准确率的条件下,应尽可能提升召回率,更高的召回率表示模型将COVID-19 阳性病例划分为无COVID-19 症状病例的情况更少,即假阴性率更少。然而由于数据集的大小和质量,以及分类类型的不同,无法对不同研究的模型仅从性能评价上进行单一比较。
7 未来发展
大多情况下,从头开始训练一个深度学习模型需要较高计算能力的硬件和较大的数据集,才能保证训练的效果,而使用有限的训练样本学习大量的参数往往会导致过拟合。此外,从头开始训练模型也是相当耗时的。迁移学习的预训练模型可以在小型数据集上更快地收敛。由于COVID-19 病例的迅速增加,SARS-CoV-2 核酸检测试剂短缺且效率低下,将医学图像与迁移学习结合有助于在COVID-19快速传播期间提供更快、更准确的结果。虽然迁移学习在COVID-19 的诊断中表现出了良好的性能,但仍然存在一些局限性,对此本文针对数据集、多模态数据、噪声处理、分类类型、集成模型、不确定性量化六方面,提出了当前存在的问题以及未来的发展方向。
7.1 数据集
当前的数据集种类较多,大部分研究采用公开的数据集,少部分研究采用私有的数据集。公开数据集普遍较小,容易产生过拟合问题。而私有的数据集所训练的模型,由于研究中所使用的数据集不公开,这些工作很难被复制和采用。
上述问题都将导致最终的自动诊断系统无法应用于临床诊断,因此创建一个公开的数量和质量都较高的统一数据集,供研究者使用是非常必要的。扩大数据集的规模能提升模型的鲁棒性,提高数据集的质量能够提高模型的性能,并且数据集统一有利于对不同模型进行比较。另一个问题是数据集的标注问题,采用人工标注的方法不仅耗时,且标注的数据带有主观性,未来的研究可以将迁移学习与自监督学习或无监督学习协同集成,消除数据集的限制。
7.2 多模态数据
通过数据增强产生的人工图像来自同一个训练数据集,其提高特征的多样性和丰富性的能力是有限的。例如采用有监督的几何变换,随机旋转图像可以生成代表同一类新像素值的图像,但如果图像不是方形图像,可能会丢失信息;采用无监督的GAN进行数据的扩充时,如何避免对抗网络训练过程中的非收敛性是一个非常具有挑战性的问题,而梯度消失和梯度爆炸使得对抗性网络的训练过程非常困难。
在这种情况下,采用多模态研究可能是提高模型性能的一个更有效的方法,与单模态分析相比,多模态数据集往往能达到更高的性能[60]。例如在COVID-19 的检测中,大多数研究仅使用一个单一的顺序架构,多模态研究通过采用两个平行的特征提取器,一个提取CT 扫描图像的特征,另一个提取X射线图像的特征,将这两个特征在分类前进行组合,从而进一步提高模型的性能,这也是一个很有价值的研究方向。
7.3 噪声处理
X 射线通过给人体传播一定的辐射,被人体不同的组织吸收后,最终呈现在胶片上。在这个过程中,一些辐射发生散射后会在X 射线图像上产生噪声,主要有椒盐噪声和泊松噪声。这些噪声会给后续特征提取带来干扰,因此处理这些噪声数据非常重要。
而上述研究中只有极少数研究对噪声进行了处理,大部分研究所使用的数据集都是清晰X 射线。为了将模型运用于现实场景中,当采用带噪声的数据集时可以使用合适的滤波器来消除此类噪声,以提高噪声数据集的准确率。
7.4 分类类型
随着类别数量的增加,对图像的分类变得更加困难。相比之下,二分类情况更容易处理,因此当前大部分研究侧重于对图像进行二分类,即分为COVID-19 或正常,这导致多分类研究存在空白。
由于新冠肺炎与其他肺炎在图像特点具有相似的表现,未来研究可以考虑选择多类肺炎以及COVID-19 图像,对分类的类型进行细化,加入多分类问题,这也便于医生对患有其他类型肺炎的患者进行后续治疗。X 射线也能用于检测COVID-19,但它不能提供感染肺部的细节。CT 扫描则是一种更复杂的技术,图像往往包含更多的细节,在预测疾病感染严重程度方面非常敏感,后续研究可以对确诊COVID-19 的图像进行严重程度分级,如果是重症患者便于医生立即采取相应的治疗方案,最大程度挽救患者的生命。
7.5 集成模型
最初将迁移学习应用于COVID-19 的诊断时,大部分研究所采用的模型都是单一的预训练网络,或者对预训练网络进行简单调整后再将数据集放入进行训练,训练出的模型效果不佳。集成学习通过并行训练多个神经网络来解决分类任务,可以解决由深度学习网络产生的高方差问题,并且集成模型的效果优于单一网络。
希望研究者在未来的研究中能够提供更高性能的集成网络。除此之外,还可以将实验结果和医学图像以及患者的临床表现相结合,以便更加全面地诊断COVID-19,对于已确诊的患者增加风险分析和生存预测,这将预测感染是否会威胁患者的生命,从而有针对性地对患者制定诊疗计划。
7.6 不确定性量化
深度学习模型需要考虑以下两种不确定性:一是由于数据本身包含噪声所产生的偶然不确定性,是数据分布的固有属性,因此它是不可约的;二是由于模型训练不佳产生的认知不确定性[56],通过收集更多的数据能够减少这种不确定性。但是COVID-19的数据集比较匮乏,目前大多模型并没有对新病例给出一个置信度,错误的诊断可能会导致疫情持续传播,如果模型在输出结果的同时,输出了一个较低的置信度,就需要专家介入对其进行诊断,这样可以从很大程度上减少误判的概率,因此对模型进行不确定性量化非常有必要[61]。评估不确定性模型当前普遍存在的挑战有缺乏理论基础、对不完整数据的敏感性低、计算量大等。
深度学习领域常用的不确定性评估方法有贝叶斯深度学习[62]、蒙特卡洛[63]、马尔可夫链蒙特卡洛[64]。贝叶斯的核心在于求解后验分布,然而在深层网络中,后验分布很难求解,只能通过近似的方法解决后验分布的求解问题。贝叶斯深度学习将贝叶斯概率论与深度学习相结合,为应对复杂问题中的不确定性建模与推断提供了强大的工具。其对过拟合问题具有较强的鲁棒性,可应用于小型数据集。蒙特卡洛(Monte-Carlo,MC)方法可以近似后验推断,但是集成到深度架构中时,存在计算缓慢且计算成本较高的缺点。为了解决上述问题,引入了MC dropout[65],其原理是在训练和测试阶段都使用dropout作为正则项计算预测的不确定性。然而该方法在样本集中的情况下,所预测的不确定性较低;在样本稀疏的情况下,不确定性会明显增大。马尔可夫链蒙特卡洛(Markov chain Monte Carlo,MCMC)是另一种近似后验分布的有效方法,所采样的方法都是无偏的。但其需要迭代的次数过多,达到期望分布的收敛时间较长。基于上述问题,提出了随机梯度马尔可夫链蒙特卡洛(stochastic gradient MCMC,SG-MCMC)[66],它只需要估计小批量数据的梯度,因此可以较快收敛到真正的后验分布。
在未来的研究中,需要对各种不确定性量化的方法加强理论分析。在采用半监督学习自动生成数据标签时,可以将不确定性量化方法与之结合。此外,还可以将其应用于数字医疗领域,量化其不确定性,并将其部署到真实的临床环境中,这也是一个值得研究的方向。
8 结束语
本文研究了几种基于迁移学习检测COVID-19的诊断模型,并阐明了这些模型的特点。首先,表1和表2 分别展示了公开的X 射线和胸部CT 数据集,详细描述了数据集来源、分布、占比等。然后讨论了数据预处理的方法,最常见的方法是尺寸调整,使用GAN 方法的研究占比较小。接着按照模型分类阐述了各个模型的特点,以及常用的模型评估方法。一些研究结合了可视化技术(即CAM、Grad-CAM、Grad-CAM++、LIME 和LRP),以突出与预测结果密切相关的关键区域,最常用的可视化技术是基于CT扫描和X 射线模型的Grad-CAM。最后整理和总结了当前领域面临的问题并提供了未来的研究方向。希望本综述能为研究人员和放射科医生提供指导。
