基于熵掩蔽的DCT域恰可察觉失真模型
2023-03-10骆琼华王鸿奎殷海兵邢亚芬
骆琼华,王鸿奎,殷海兵,邢亚芬
基于熵掩蔽的DCT域恰可察觉失真模型
骆琼华,王鸿奎,殷海兵,邢亚芬
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
为提高离散余弦变换(discrete cosine transform,DCT)域恰可察觉失真(just noticeable distortion,JND)模型阈值精度并避免跨域操作,将熵掩蔽效应引入DCT域JND模型。首先,从自由能理论和贝叶斯推理出发,设计基于DCT域纹理能量相似性的自回归模型模拟视觉感知过程中的自发预测行为;其次,探索视觉感知与预测残差的映射关系得到块级无序度,并将熵掩蔽效应建模为关于无序度的JND阈值调节因子;最后,结合空间对比敏感度函数、亮度自适应掩蔽以及对比度掩蔽,提出基于熵掩蔽的DCT域JND模型。与现有DCT域JND模型相比,所提模型所有运算均在DCT域执行,更高效简洁。主观、客观实验结果表明,所提模型在感知质量相同或更好的情况下,噪声污染图的平均峰值信噪比(peak signal-to-noise ratio,PSNR)值比其他4个JND对比模型低2.04 dB,更符合人眼视觉系统的感知特性。
恰可察觉失真;人眼视觉系统;熵掩蔽效应;自由能理论;贝叶斯推理
0 引言
人类视觉系统(human visual system,HVS)由于其潜在的生理和心理机制无法感知一定阈值以下的图像失真,这一阈值被称为恰可察觉失真(just noticeable distortion,JND)阈值[1]。JND模型揭示了人类视觉系统对图像失真的感知特性,被广泛应用于图像和视频处理中,如图像和视频压缩/编码[2]、质量评价[3]、数字水印[4]和图像增强[5]等。
过去二十年里,JND阈值估计取得了巨大进展。现有JND估计模型根据计算域可分为两类:像素域JND模型和子带域JND模型。其中,像素域JND模型直接计算图像和视频中每个像素的JND阈值[6];子带域JND模型主要在压缩域中估计JND阈值,如小波域和DCT域[7]。本文重点关注基于DCT域的JND阈值估计,因为DCT域JND模型可直接应用于基于DCT变换的图像/视频压缩领域[2]。
DCT域JND模型主要由对比敏感度函数(contrast sensitivity function,CSF)、亮度自适应(luminance adaptive,LA)掩蔽效应和对比度掩蔽(contrast masking,CM)效应构成[7]。纵观现有JND模型,其核心问题是如何准确高效地估计CM模型。DCT域CM模型通常将图像块分为3种类型(即平面、边缘和纹理),并为这3种类型设置3个不同的权重以突出纹理区域[7]。然而内部生成机制(internal generation mechanism,IGM)对有序纹理内容是自适应的,因此这些有序纹理区域会被高估。
实际上,HVS并非逐字翻译输入场景,而是通过IGM主动推断输入场景[8]。自由能理论为人类的行为、感知和学习提供了统一的解释,其基本思想是所有的适应性生物制剂都能抵抗紊乱的自然趋势[9]。HVS在自由能理论的指导下试图处理尽可能多的结构信息而避免不确定信息。这一特性揭示了HVS的感知局限性,包含大量不确定信息的无序纹理区域的JND阈值往往相对较高。近年来,自由能理论已被引入像素域JND模型中进行有意义的探索[10]。Wu等[10]通过贝叶斯预测模拟视觉系统自发的预测行为,将图像分为有序成分和无序成分进行独立处理,以熵掩蔽(entropy masking,EM)的形式引入像素域JND阈值估计。在此基础上,Wu等[11]引入模式掩蔽取代熵掩蔽和对比度掩蔽,并提出一个增强型的像素域JND模型。Zeng等[12]利用相对全变分模型和方向复杂度,将图像分成结构图像、有序纹理图像和无序纹理图像,并结合视觉显著性构建像素域JND模型。Liu等[13]将屏幕内容图像分解为屏幕内容集和非屏幕内容集进行处理,并研究了边缘掩蔽和模式掩蔽的组合掩蔽效应。Wang等[14]根据分层预测编码理论将视觉感知分为3个阶段,并结合正负感知效应提出一个新的像素域JND模型。
基于上述自由能理论在像素域JND阈值估计中的探索,本文认为在DCT域JND阈值估计中合理引入自由能理论与熵掩蔽效应将有助于提高DCT域JND模型的准确性。由于大多数图像/视频资源以压缩形式进行有效存储和传输,直接对压缩数据而非其解压缩版本进行操作变得非常重要。本文拟在避免跨域运算的前提下,引入熵掩蔽效应并提出DCT域JND建模方法。
1 DCT域JND模型概述
1.1 DCT域JND模型框架
本文主要研究基于DCT域的JND阈值估计。对于×大小的DCT块,第(,)个DCT系数计算式如下。
通常,DCT域JND模型被表示为多个调节因子的乘积,这源于Watson[15]的DCTune模型。本文提出的JND模型主要考虑4种掩蔽效应,计算如下。
1.2 CM模型改进
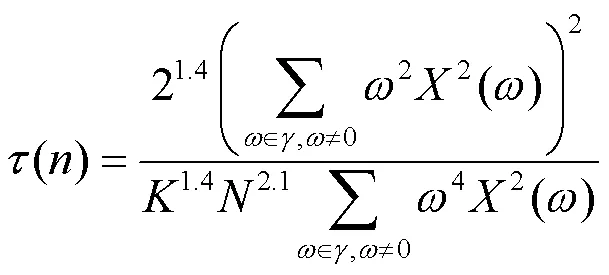
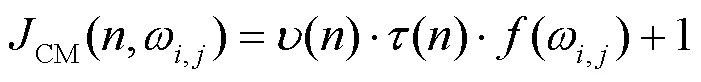
其中,是频率线性函数梯度,计算同Bae[7]的模型。引入抑制因子前后对比如图2所示,截取边缘区域(即黑色方框区域)进行更清晰的对比,通过引入抑制因子,边缘块的对比度强度被有效抑制,边缘区域的图像质量也得到明显改善。

图2 引入抑制因子前后对比
2 基于熵掩蔽的JND阈值调节因子
2.1 贝叶斯预测模型
HVS在自由能理论的指导下可以准确预测并充分理解有序内容,同时粗略感知无序内容[9]。显然,与无序区域相比,HVS对有序区域更敏感,其JND阈值更小。由于贝叶斯推理是信息预测的有力工具,本文采用贝叶斯大脑理论[19]模拟人脑中的IGM进行有序信息预测,并建立DCT域自回归预测模型。贝叶斯大脑理论的基本原理是,大脑有一个试图以最小误差概率表示传感器信息的模型[19]。对于图像而言,贝叶斯大脑系统以最大化条件概率表示像素值。
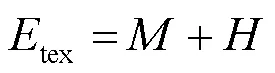

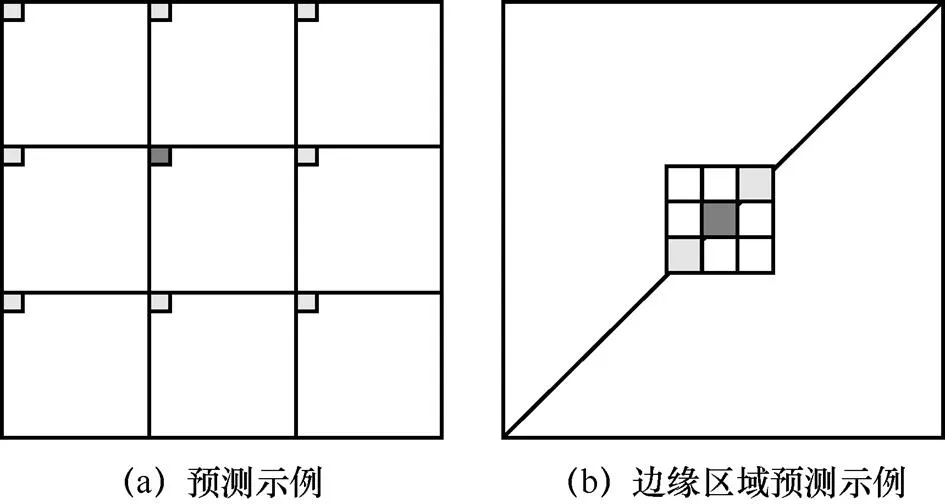
图3 DCT域贝叶斯预测示例

图4 8×8 DCT块能量分布
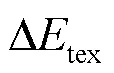
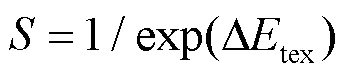
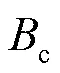
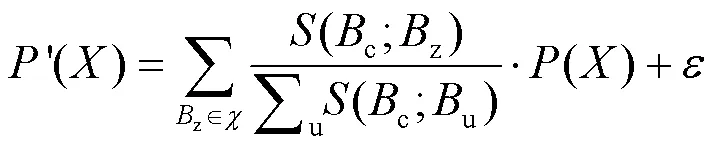
对于边缘区域,HVS应能自适应地进行预测。如图3(b)所示,中心块位于平坦区域的一条直线(即边缘区域)上时,应当只由同处边缘区域的周围块进行预测。因此,本文采用DCT域的TE块分类法[18]将图像分为边缘块和非边缘块进行预测。当中心块为边缘块时,仅由同为边缘块的周围块进行相似度加权预测;当中心块为非边缘块时,仅由非边缘块进行相似度加权预测;而当中心块为边缘块(非边缘块)且其周围块均为非边缘块(边缘块)时,中心块由周围8个块共同预测得到。
DCT域贝叶斯预测结果如图5所示,本文获得的预测图像和残差图像存在明显的块效应,这是由8×8的DCT所引起的。为证明本文预测模型的准确性,采用多尺度结构相似性(multi-scale structural similarity,MS-SSIM)指数度量预测图像与原始图像之间的相关性,高于0.5的MS-SSIM指数值表明图像间具有很强的相似性[20]。从图5(b)及其对应的MS-SSIM指数值可以看到,本文提出的DCT域贝叶斯预测模型能较为准确地预测图像内容。

图5 DCT域贝叶斯预测结果
2.2 熵掩蔽模型
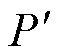
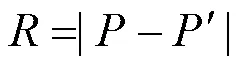
由于DCT后绝大部分能量都集中在左上角的低频系数中,DCT系数之间幅度相差很大。而DCT系数幅度越大,其预测残差往往越大。因此这里将DCT系数残差与原始系数值相除,并对其相除结果进行归一化处理得到无序度块。第个DCT块的无序度由其无序度块求平均得到,计算如下。
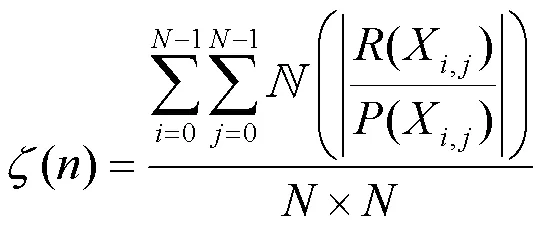
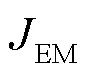
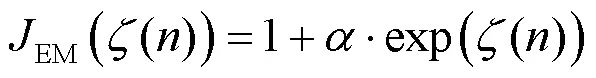
其中,是比例因子,根据主观观看结果,按照经验将其设为0.15。这里选取“IVC”数据集[22]中的一幅图像,给出主观质量对比的例子,不同值得到的主观质量对比如图6所示。从主观质量的角度可以看到,当在取0.1和0.15时图像主观质量相近,而时主观质量明显受损;从噪声隐藏能力的角度,可以看到依次取0.15和0.2时,PSNR值分别降低0.71 dB和0.27 dB。综上所述,取0.15时可以在不影响图像质量的情况下降低较多的PSNR值。
3 实验结果与分析
3.1 对比实验
本文提出的JND估计模型是在DCT域中结合EM效应而构建的。因此为验证本文DCT域JND模型的有效性,这里选择研究工作相近的3个JND模型进行对比实验,分别命名为Zeng2019[12]、Liu2020[13]以及Li2022[25]。其中,Zeng2019和Liu2020是考虑自由能理论的两种像素域JND模型,而Li2022是融合边缘掩蔽与中心凹掩蔽的像素域JND模型。
通常在更精确JND模型的指导下,图像能保持感知质量不变并隐藏更多噪声。在基于DCT域的JND估计中,噪声被添加到图像中的每个DCT系数[24],如式(13)所示。
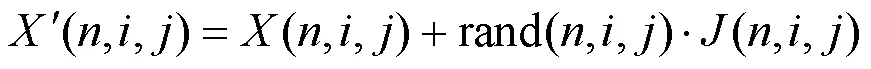
JND模型的噪声容忍能力是用峰值信噪比(peak signal-to-noise ratio,PSNR)衡量的,即相同感知质量下PSNR越低,JND模型估计越准确。8位灰度图像的PSNR由原始图像和噪声注入图像之间的均方误差(mean squared error,MSE)计算得到,如式(14)所示。
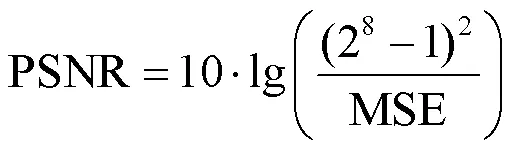
由于图像的最终接收者为人眼,仅以PSNR评估JND模型性能不够准确,因此采用MS-SSIM指数和平均意见分数(mean opinion score,MOS)评价图像的主观质量。其中,MS-SSIM指数通过图像间结构相似性评估图像质量,是一种更适合HVS的感知质量评价指标[26]。本文根据ITU-R BT.500-11标准展开主观质量评估(subjective quality assessment,SQA)实验[24],该实验用于测量原始图像和噪声注入图像间的主观质量差异。每次测试中,为了更好地比较主观质量,将原始图像作为标准放在左边,4个注入噪声的图像(本文模型和用于对比的3个模型)以随机顺序在右边并列显示。主观评价标准和分数被分为4个等级,以指示噪声注入图像相对于原始图像的失真程度。评价标准具体为:“0”表示右边图像质量没有下降,“-1”表示轻微下降,“-2”表示下降较多,“-3”表示下降严重。25位视力正常或矫正视力正常的受试者被邀请评估噪声注入图像的感知质量,个人评价分数以MOS的形式提供。在SQA实验中,显示器的分辨率为1 920 dpi×1 080 dpi,并将观看距离设置为显示屏高度的4倍[24]。
3.2 性能评估
JND模型的性能是以PSNR、MS-SSIM指数和MOS衡量的。被测JND模型的良好性能意味着由JND模型注入噪声的图像与其他模型相比具有更低的PSNR值以及更高的MS-SSIM指数值和MOS值。表1~表3展示了注入相同噪声后本文模型与其他3个模型在不同图像数据集上的PSNR、MS-SSIM指数和MOS值,其中由于MS-SSIM指数值相差较小,在这里保留3位小数。为了更直观地对比JND模型性能,采用柱状图的形式描述不同JND模型在3个数据集上主客观评价指标的平均值,如图7所示。本文以PSNR测量JND模型隐藏噪声的能力。由表1~表3可知,本文模型在3个分辨率不同的数据集上均具有最低的PSNR值。具体而言,本文模型在3个数据集上获得的平均PSNR值为26.75 dB,分别比其他模型低2.52 dB、2.12 dB和1.47 dB,如图7(a)所示。此外,本文以MS-SSIM指数和MOS测量噪声注入图像的感知质量。由表1~表3可知,本文模型在3个数据集上均获得最高的MS-SSIM指数值和MOS值。具体来说,本文在3个数据集上获得的平均MS-SSIM指数值为0.963,分别比其他3个模型高0.020、0.018和0.023,如图7(b)所示;而平均MOS值为-0.29,比其他模型高出0.17、0.13和0.16,如图7(c)所示。由此可见,与其他3个模型相比,本文提出的DCT域JND模型更精确,能隐藏更多噪声,获得更好的图像感知质量。
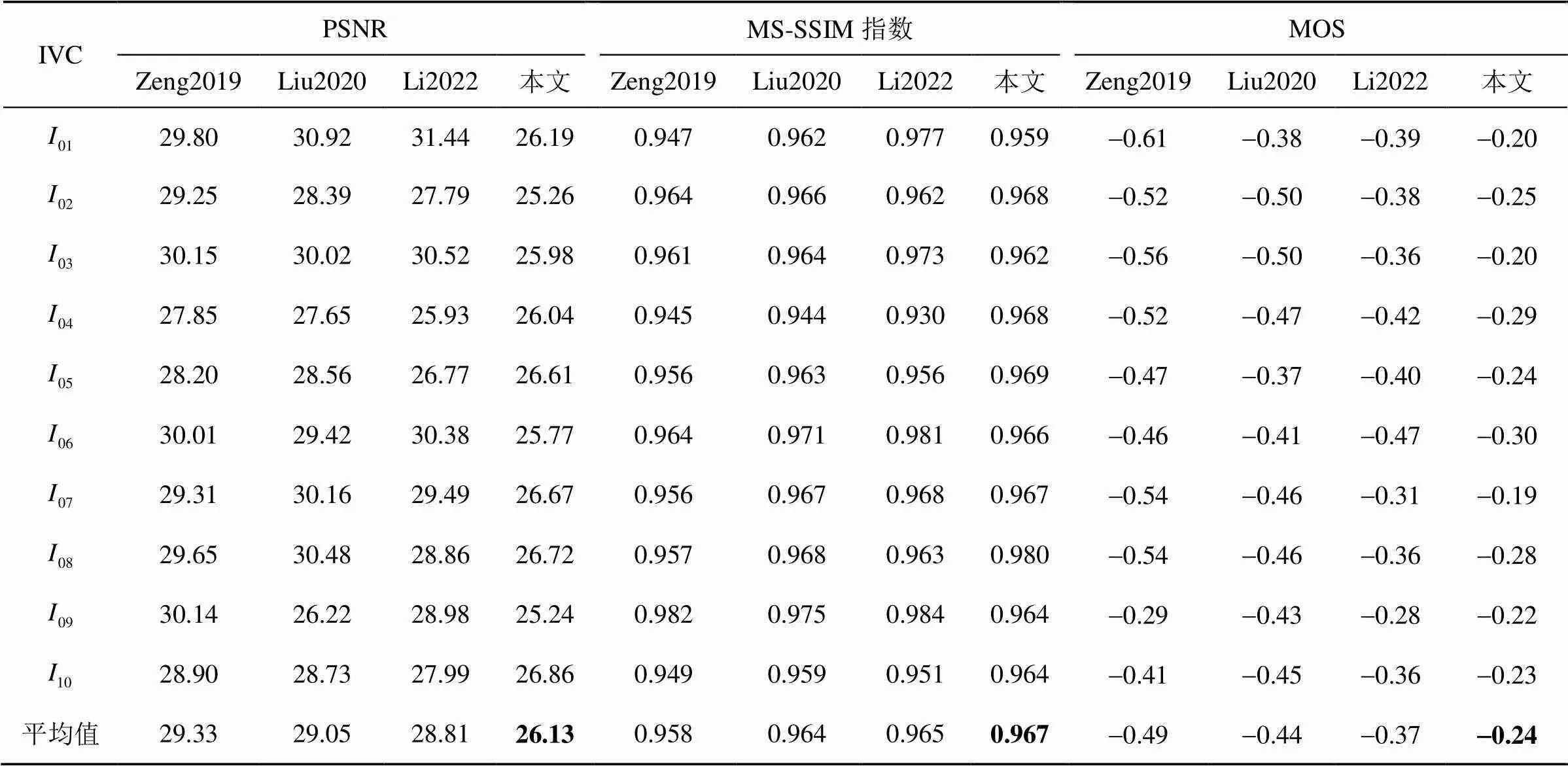
表1 不同JND模型在“IVC”数据集上的性能对比
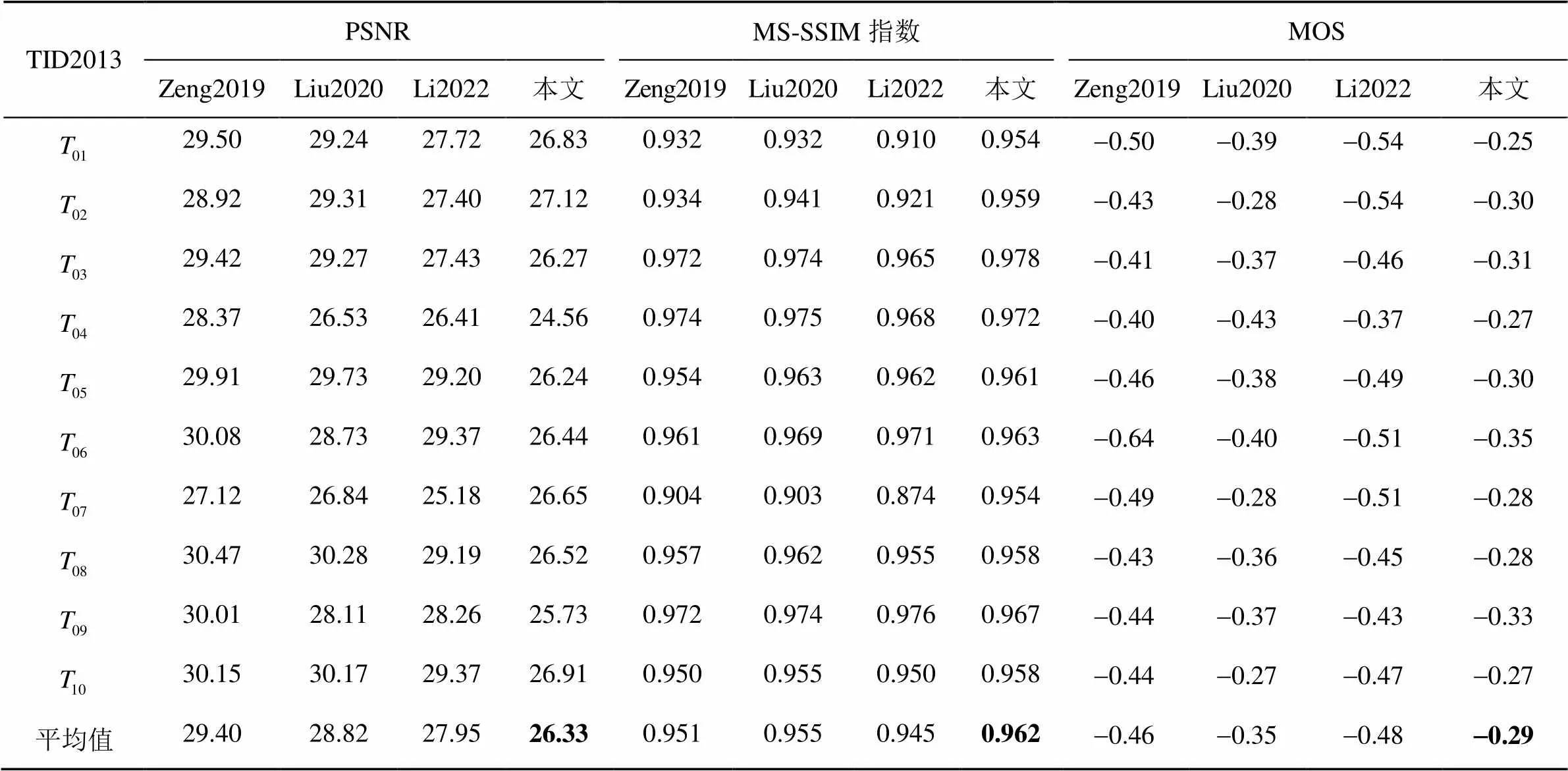
表2 不同JND模型在“TID2013”数据集上的性能对比
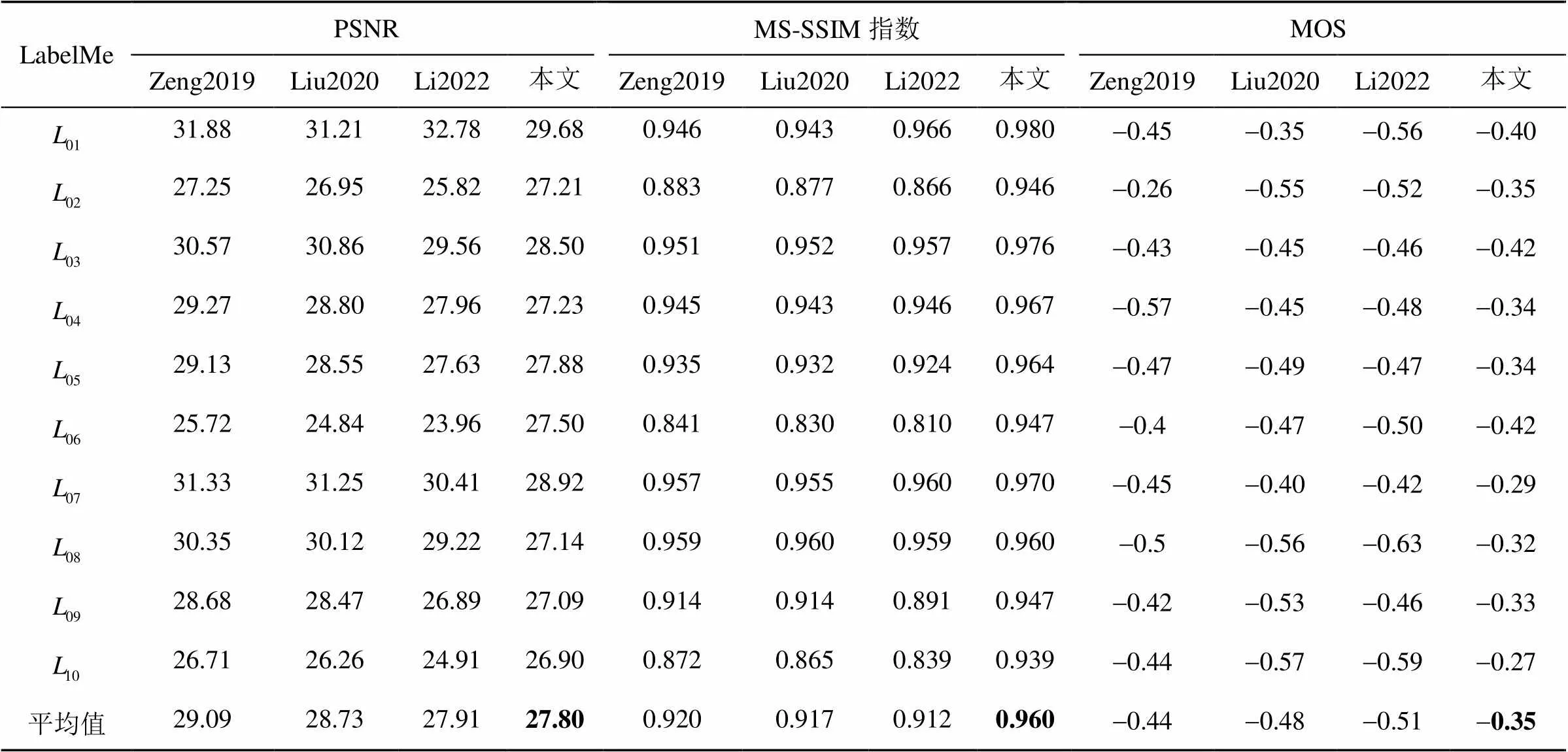
表3 不同JND模型在“LabelMe”数据集上的性能对比
注:加粗字体为最优结果。
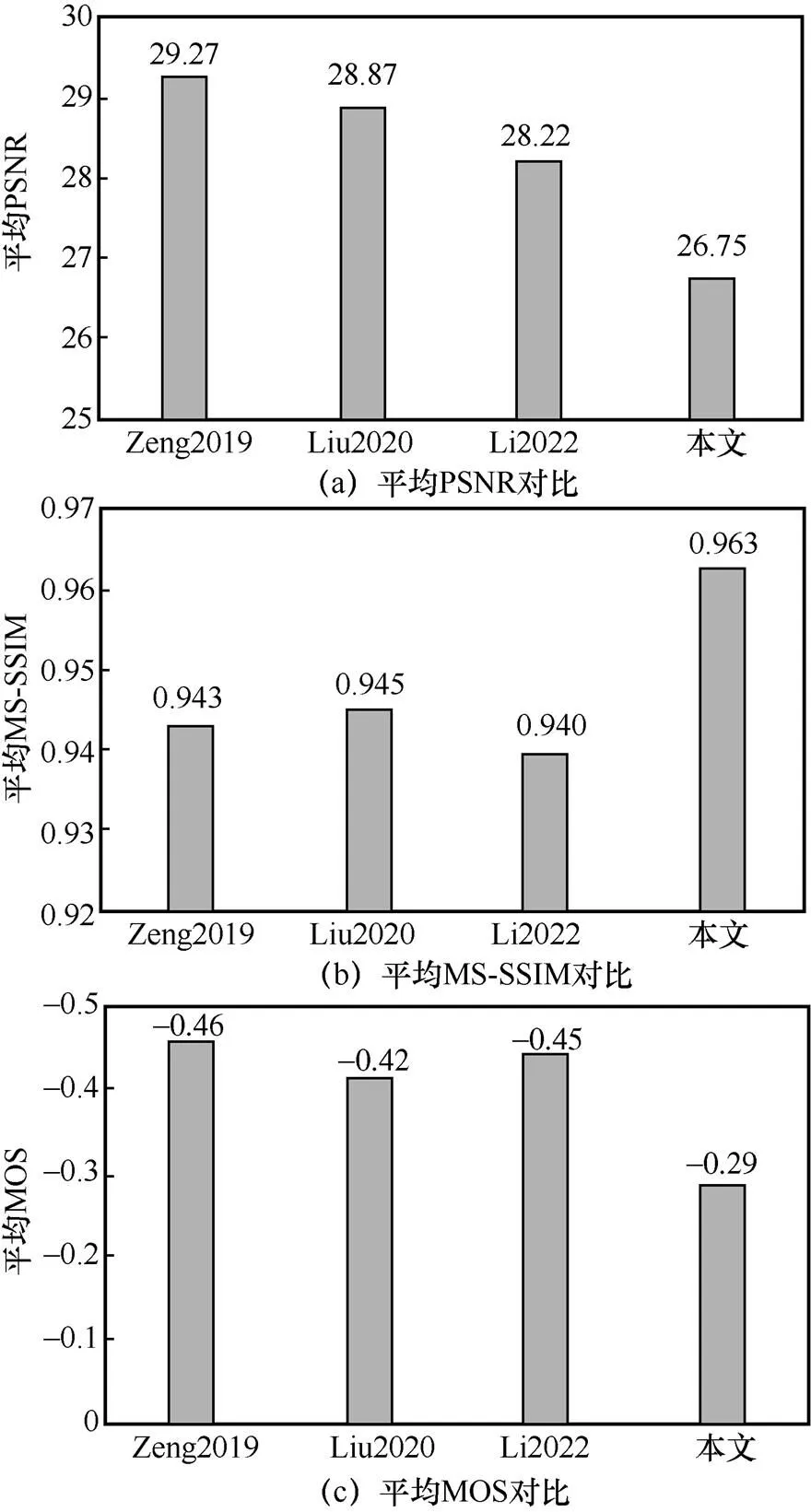
图7 不同JND模型在3个数据集上的主客观指标平均值对比

图8 不同JND模型在“”图像上的对比

图9 不同JND模型在“”图像上的对比

图10 不同JND模型在“”图像上的对比
以上主观、客观实验证明,本文提出的JND模型能充分考虑人眼视觉特性,在平坦、有序纹理、无序纹理区域分别注入少量、适量、大量噪声,实现噪声的合理分配。综上所述,本文模型能在注入相同噪声的情况下获得最好的感知质量和最低的PSNR值,性能优于其他3个JND模型。
4 结束语
本文通过探索HVS主动预测输入信号的特性,提出基于熵掩蔽的DCT域JND模型。算法充分考虑DCT块间的相关性,设计基于纹理能量相似性的DCT域贝叶斯预测模型,利用预测残差计算块级无序度描述图像内容的不确定性;最终将熵掩蔽效应构建为关于无序度的调节因子,以指示更多噪声分配到包含大量不确定信息的无序纹理区域。主观、客观实验结果表明,所提模型能在避免跨域操作的同时去除更多感知冗余,性能优于现有JND模型。
[1] JAYANT N, JOHNSTON J, SAFRANEK R. Signal compression based on models of human perception[J]. Proceedings of the IEEE, 1993, 81(10): 1385-1422.
[2] KI S, DO J, KIM M. Learning-based JND-directed HDR video preprocessing for perceptually lossless compression with HEVC[J]. IEEE Access, 2020(8): 228605-228618.
[3] 崔帅南, 彭宗举, 邹文辉, 等. 多特征融合的合成视点立体图像质量评价[J]. 电信科学, 2019, 35(5): 104-112.
CUI S N, PENG Z J, ZOU W H, et al. Quality assessment of synthetic viewpoint stereo image with multi-feature fusion[J]. Telecommunications Science, 2019, 35(5): 104-112.
[4] LI J, ZHANG H, WANG J, et al. Orientation-aware saliency guided JND model for robust image watermarking[J]. IEEE Access, 2019(7):41261-41272.
[5] XU Y F, ZHANG N, LI L, et al. Joint learning of super-resolution and perceptual image enhancement for single image[J]. IEEE Access, 2021(9):48446-48461.
[6] 邢亚芬, 殷海兵, 王鸿奎, 等. 基于视频时域感知特性的恰可察觉失真模型[J]. 电信科学, 2022, 38(2): 92-102.
XING Y F, YIN H B, WANG H K, et al. Video temporal perception characteristics based just noticeable difference model[J]. Telecommunications Science, 2022, 38(2): 92-102.
[7] BAE S H, KIM M. A novel generalized DCT-based JND profile based on an elaborate CM-JND model for variable block-sized transforms in monochrome images[J]. IEEE Transactions on Image Processing, 2014, 23(8): 3227-3240.
[8] FRISTON K J, DAUNIZEAU J, KIEBEL S J. Reinforcement learning or active inference?[J]. PloS one, 2009, 4(7): e6421.
[9] FRISTON K. The free-energy principle: a unified brain theory?[J]. Nature Reviews Neuroscience, 2010, 11(2): 127-138.
[10] WU J J, SHI G M, LIN W S, et al. Just noticeable difference estimation for images with free-energy principle[J]. IEEE Transactions on Multimedia, 2013, 15(7): 1705-1710.
[11] WU J J, LI L D, DONG W S, et al. Enhanced just noticeable difference model for images with pattern complexity[J]. IEEE Transactions on Image Processing, 2017, 26(6): 2682-2693.
[12] ZENG Z P, ZENG H Q, CHEN J, et al. Visual attention guide dpixel-wise just noticeable difference model[J]. IEEE Access, 2019(7): 132111-132119.
[13] LIU X Q, ZHAN X N, WANG M H. A novel edge-pattern-based just noticeable difference model for screen content images[C]//2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP). Piscataway: IEEE Press, 2020: 386-390.
[14] WANG H K, YU L, LIANG J H, et al. Hierarchical predictive coding-based JND estimation for image compression[J]. IEEE Transactions on Image Processing, 2020(30): 487-500.
[15] WATSON A B. DC Tune: A technique for visual optimization of DCT quantization matrices for individual images[C]//Sid International Symposium Digest of Technical Papers, Society for Information Display, 1993(24): 946-946.
[16] WEI Z Y, NGAN K N. Spatio-temporal just noticeable distortion profile for grey scale image/video in DCT domain[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2009, 19(3): 337-346.
[17] ECKERT M P, BRADLEY A P. Perceptual quality metrics applied to still image compression[J]. Signal processing, 1998, 70(3): 177-200.
[18] ZHANG X H, LIN W S, XUE P. Improved estimation for just-noticeable visual distortion[J]. Signal Processing, 2005, 85(4): 795-808.
[19] KNILL D C, POUGET A. The Bayesian brain: the role of uncertainty in neural coding and computation[J]. TRENDS in Neurosciences, 2004, 27(12): 712-719.
[20] EASTTOM C. On the use of the SSIM algorithm for detecting intellectual property copying in web design[C]//2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC). Piscataway: IEEE Press: 2021: 0860-0864.
[21] Le C P, Autrusseau F. Subjective quality assessment IRCCyN/IVC database[EB]. 2005.
[22] Ponomarenko N, Jin L, Ieremeiev O, et al. Image database TID2013: peculiarities, results and perspectives[J]. Signal Processing: Image Communication, 2015, 30: 57-77.
[23] JUDD T, EHINGER K, DURAND F, et al. Learning to predict where humans look[C]//2009 IEEE 12th International Conference on Computer Vision. Piscataway: IEEE Press, 2009: 2106-2113.
[24] WANG H K, YU L, YIN H B, et al. An improved DCT-based JND estimation model considering multiple masking effects[J]. Journal of Visual Communication and Image Representation, 2020(71): 102850.
[25] LI J L, YU L, WANG H K. Perceptual redundancy model for compression of screen content videos[J]. IET Image Processing, 2022, 16(6): 1724-1741.
[26] WANG J, LIU Y, WEI P, et al. Fractal image coding using SSIM[C]//2011 18th IEEE International Conference on Image Processing. Piscataway: IEEE Press, 2011: 241-244.
Just noticeable distortion model based on entropy masking in DCT domain
LUO Qionghua, WANG Hongkui, YIN Haibing, XING Yafen
College of Communication Engineering, Hangzhou Dianzi University, Hangzhou 310018, China
In order to improve the threshold accuracy of JND (just noticeable distortion) model in DCT (discrete cosine transform) domain and avoid cross-domain operation, entropy masking effect was introduced into DCT-based JND model. Firstly, starting from the free-energy theory and the Bayesian inference, an autoregressive model based on texture-energy similarity in DCT domain was designed to simulate the spontaneous prediction behavior of visual perception. Secondly, the mapping relationship between visual perception and prediction residuals were explored to obtain the disorder intensity in block level. Thirdly, the entropy masking effect was modeled as a JND threshold modulation factor of disorder intensity. Finally, the JND model in DCT domain for the entropy masking was proposed by fusing the contrast sensitivity function, the luminance adaptive masking, the contrast masking. Compared with the existing JND model in DCT domain, the proposed model performed all operations in DCT domain, which was more efficient and concise. The subjective and objective experimental results indicate that the proposed JND model shows greater tolerance to distortion with better perceptual quality.
JND, human visual system, entropy masking effect, free-energy theory, Bayesian inference
TN91
A
10.11959/j.issn.1000–0801.2023014

骆琼华(1998-),女,杭州电子科技大学通信工程学院硕士生,主要研究方向为视频感知编码。
王鸿奎(1990-),男,博士,杭州电子科技大学通信工程学院讲师,主要研究方向为视觉感知理论、视频感知编码以及视频智能编码。
殷海兵(1974-),男,博士,杭州电子科技大学通信工程学院教授,主要研究方向为数字视频编解码、图像和视频处理以及VLSI结构设计。
邢亚芬(1997-),女,杭州电子科技大学通信工程学院硕士生,主要研究方向为视频感知编码。
The National Natural Science Foundation of China (No.62202134, No.61972123, No.61931008, No.62031009), Zhejiang Provincial “Pioneer” and “Leading Goose”Research and Development Project (No.2023C01149, No.2022C01068)
2022-08-03;
2023-01-09
国家自然科学基金资助项目(No.62202134,No.61972123,No.61931008,No.62031009);浙江省“尖兵”“领雁”研发攻关计划项目(No.2023C01149,No.2022C01068)
