高速公路造价快速估算模型与方法的研究
2023-03-10王建
王 建
(中铁工程设计咨询集团有限公司济南设计院 ,山东 济南 250000)
在现阶段发展形势下,产业竞争日益加剧,高速公路设计前期工作需要对项目投资进行快速、准确地评估。无论是业主或设计单位,都需要快速准确地估算项目成本,而快速估算项目造价成本不仅需要各个工作部门之间的配合,还需要辅助计算机快速算量技术。完善的估算模型不仅可以有效地解决这一问题,还可以提高造价成本估算效率,降低传统人工大量计算所需要的工作量[1]。目前,部分工程项目承包方已开发了高精度估算模型用于执行项目造价估算工作,但现有工作的方案一直未能达到预期或理想状态。下文将以此为切入点,结合现有的工作经验,设计全新的估算模型。
1 高速公路造价快速估算模型与方法
1.1 确定模型中神经元与学习规则
为实现对高速公路造价的快速估算,引入模糊数学和人工神经网络,在建立相应的数学模型前,需要先确定模型中的神经元以及神经网络的学习规则[2]。将通用神经元模型作为造价快速估算模型的基本结构。在该模型当中假设包含n个输入值,图1为通用神经网络模型的基本结构。
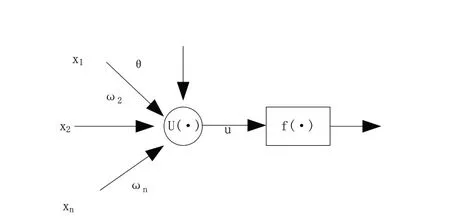
图1 通用神经网络模型的基本结构
图1中x表示输入的神经元,其集合可表示为:
输入的可调节权值可表示为:
图1中θ代表偏移信号,可通过这一偏移信号实现对神经元兴奋阈值数值的确定。u(·)和f(·)代表神经元的基函数和激活函数。利用启动函数挤出基函数,使u在给定的区间内由非线性函数进行转换。
1.2 原始数据处理
由于网络的训练是根据已知的样本量资料归纳出输入与输出之间的复杂关系,因此,要使高速公路造价快速估算得更为精确,就必须尽量保证输入数据的准确[3]。如果样品不具备合理的可靠性,将不能评价该模型的性能。为实现对原始数据的统一处理,使估计值更为合理,各样本数据尽量选用工程预决算数据。因特殊原因导致工程造价与正常成本有偏差的,应当予以剔除[4]。例如,在施工的时候,出现了一些无法控制的情况,或者是一些人为的原因。针对这一部分产生的异常数据,可将其剔除[5]。同时,在对原始数据处理时,将包含在成本中的施工辅助措施和工程的费用以及工程量从总成本中剔除,分别计算。认真地核对每一条道路的成本和数量,剔除掉一些偶尔出现的不符合常理的数据,将那些超出实际成本的数据全部删除。在此基础上,对定性的数据进行定量化处理。其中,路面形式、地形特征、地区等都是影响路面质量的重要因素[6]。按道路形态划分,可将其划分为沥青砼路面和水泥砼路面,两者均可按0.8、0.6计算;根据地形特点,将其划分为平原微丘区、重丘区、山岭区,其分布范围分别为0.2、0.5、0.8;区域按中国不同省份划分为三类,分别为0.3、0.6、0.9。针对同一条公路的不同路段需要按照不同工程特性处理。以某高速公路数据为例,该公路中包含平原微丘区共a公里,重丘区b公里和山岭区c公里。则根据实际情况,确定权重取值,并计算得出对应路段公里长与总里程的比值η:
上述计算公式中:L表示公路总长度,L=a+b+c。除此之外,针对部分数据进行特殊处理。以高速公路修建的年份为例,为了使数据更加紧凑,可选择某一年份为基年,将其排序号为1,第二年排序号为2,以此类推。
1.3 构建基于模糊数学的相似样本选取模型
在完成对原始数据的处理后,引入模糊数学,构建相似样本选取模型。首先对隶属函数进行选取,隶属函数是指某一元素隶属于某一特性的函数[6]。隶属函数的取值在0~1范围内,越接近1,则隶属度越高,反之越接近0,则隶属度越低。由于不同的项目,其取值也是不同的,因此采用数据标准化的方式,将其转换成[0.1,0.9]之间的数值(通常是标准化到[0,1]之间,但是为了保留一定的空间,将这一范围缩小),以此充分符合选择隶属函数的准则。归一化后的数据可以被视为该工程的工程属性的一个从属关系。在进行下一阶段的神经网络模型时,必须选取接近于预测的工程资料作为模型的样本。在建模过程中,将工程描述成具有模糊性质的工程特征,为了衡量两组数据的相似程度,引入了接近度的概念。接近度可通过下述公式计算得出:
上述计算公式中, (,)ACα表示A组数据与C组数据的接近度。结合上述公式,确定预测项目与各个施工项目之间的关系,并由大到小对其进行排序。估算工程与贴近度最大的已建工程最相似,第二大的次之,以此类推,通过这种方式,可以挑选出与预期项目类似的项目,同时将不是类似的项目则可以从模型培训中剔除,以此减轻模型的运行负担。
1.4 基于人工神经网络的造价快速估算
根据高速公路项目实际需要,模型输出的数据中应当包含造价建安费、路基工程费、路面工程费、桥梁涵洞工程费等。根据输入与输出要求,初步设计为:在人工神经网络结构当中设置的输入神经元和输出神经元分别为12个和6个[7]。但这一种方式泛化能力较差,对此设置多个子网,在每个子网当中设置12个输入神经元和一个输出神经元,如图2所示。
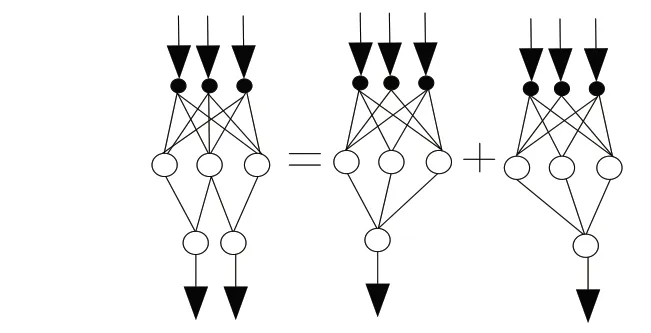
图2 人工神经网络中两输出全连接前向网输出分解
在确定人工神经网络结构中的要素后,设置中间层神经元数量,其数量可参照下述公式设置:
上述计算公式中,P代表人工神经网络中间层的神经元数量;E代表样本容量;d代表输入神经元数量;e代表输出神经元数量。在实际估算中,先按照告诉过东路工程特性,完成数据的归一化处理。将各个数据作为元素模糊关系系数。列出各个工程的模糊子集,将贴近度最大的3个样本提取,并通过构建的基于模糊数学的相似样本选取模型运算,确定估算样本[8]。再经过人工神经网络,得到工程总的造价估算结果和各个单位工程的造价估算结果。
2 实证分析
2.1 估算工程项目资料
使用本文设计的估算模型进行高速公路造价快速估算,估算前,选用某个已竣工的高速公路工程项目作为实例。利用该项目的预决算资料作为此次实验的样本数据,整理资料构建数据库。
由于资料有限,因此,下表仅呈现一些本次试验中所需要的数据资料。如表1、表2。
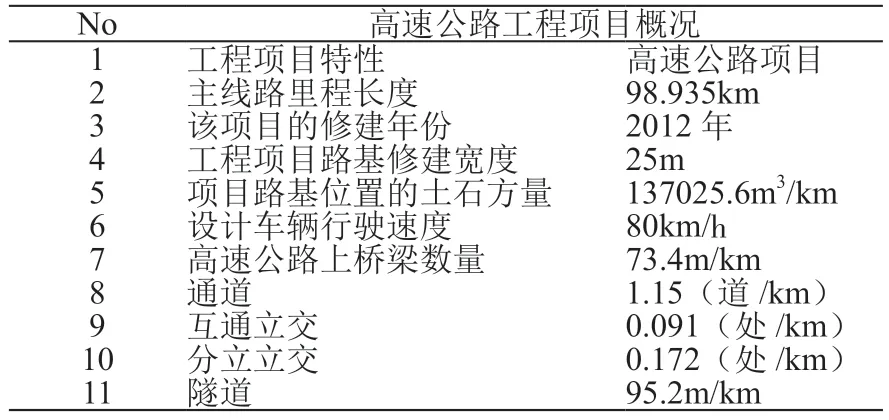
表1 高速公路工程项目概况

表2 高速公路工程项目部分预决算资料、数据
2.2 造价快速估算
完成对此项目基本情况的分析后,将上述2.1中所呈现的数据作为此次实验的样本数据,对数据进行初步选取。选取过程,删除样本集合中一些存在漏洞、不完善的数据组,保留具有合理性、客观性、完整性、依据性的数据,将此部分数据作为估算模型的训练数据。
使用本文设计的估算模型与传统模型,对高速公路现有的造价样本数据进行估算。设计模型在训练过程中的人工神经网络参数,见表3。

表3 基于人工神经网络的数据集合训练条件、参数
2.3 估算模型对样本数据的迭代次数对比
对本文估算模型与传统估算模型在估算时的训练过程进行截取,训练过程见图2。
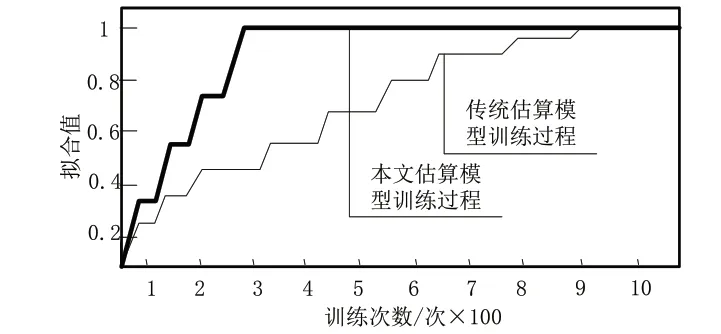
图2 本文估算模型与传统估算模型对样本数据的估算训练过程
2.4 估算结果精确度对比
将上文中表2数据作为该项目的真实数据,使用本文模型与传统模型,对该项目的不同费用进行估算。对比两个模型估算高速公路造价结果的精确度。统计估算结果误差,见表4。
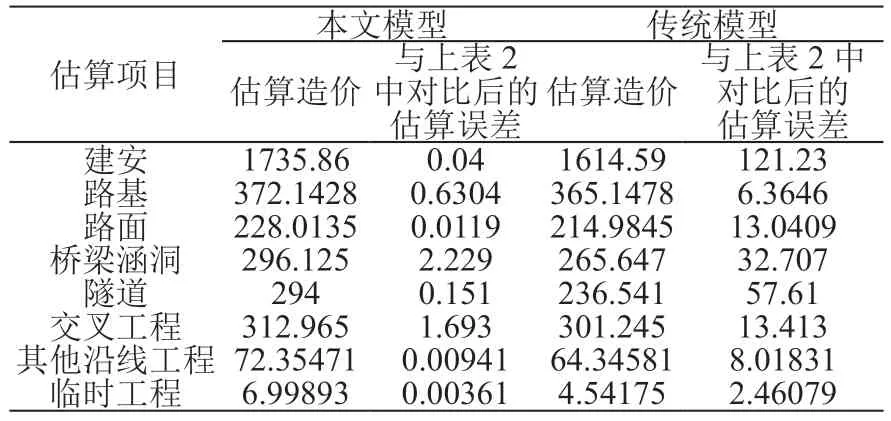
表4 高速公路工程项目造价估算结果误差(万元/km)
3 结语
通过上述研究,得到如下几个方面的结论:
(1)根据图2本文估算模型与传统估算模型对样本数据的估算训练过程,本文模型在训练300次后,估算模型的拟合值达到1.0,传统模型在训练900次后,估算模型的拟合值达到1.0。在模型单次训练所需时间相同的条件下,本文模型对高速公路的造价估算更加快速,传统模型估算造价所需要的耗时更高。
(2)根据表4高速公路工程项目造价估算结果误差结果,本文估算模型的单项估算误差在3万元/km范围内,而传统估算模型的单项估算误差显著大于本文估算模型的单项估算误差。
(3)根据上述研究成果证明本文设计的估算模型具有快速、高精度等优势。
