基于深度学习的番茄识别与实例分割
2023-03-08诸德宏
高 倩,诸德宏,封 浩
(江苏大学 电气信息工程学院,江苏 镇江 212003)
0 引言
在我国,随着机器视觉技术的快速发展,图像处理已成为贯穿农业产业链各个阶段的重要技术之一,在选种适配、生长过程、采摘方式及水果质量检测等多个环节均有涉及[1]。成熟果实采摘是农产品走向市场的重要一步,准确识别出成熟果实是实现智能化果实采摘的首要任务。
当前的目标检测方式主要有传统检测和基于深度学习的检测两种[2]。传统目标检测算法大多基于手工特征构建,其中最具代表性的算法为Viola Jones、HOG Detector、基于可变形部件模型(Deformable parts-based Model,DPM)等[3]。由于其提取的特征单一,检测结果不够准确。2012 年,卷积神 经网络(Convolutional Neural Network,CNN)被提出,此后,围绕着CNN 的深度学习方法不断涌现,分为One-stage 和Two-stage 两大分支,其中代表性One-stage 算法包括YOLO[4]系列算法、SSD[5]等;代表性Two-stage 算法包括RCNN(Regions with CNN features)[6]、Fast RCNN[7]、Faster RCNN[8]、Mask RCNN[9]等。
近年来,越来越多的研究者将深度学习技术应用于农产品识别环节。例如,张文静等[10]针对番茄生长环境复杂、枝叶对果实造成遮挡及果实之间存在遮挡等因素,提出基于Faster R-CNN 的番茄识别检测方法,该方法的平均识别率达到95.2%,但并未实现番茄的实例分割;岳有军等[11]通过对Cascade RCNN 算法进行改进,增强网络对重叠番茄果实的识别能力,并对果实进行分类,将目标识别的准确率提高了2%,但也未实现实例分割;陈欣燕等[12]提出一种基于YOLOv3 的目标检测方法,该方法的目标检测mAP 达到96.34%,但识别速度较慢,也未实现实例分割;张凯中等[13]基于目标检测模型Mask RCNN 对群养猪进行实例分割,在区域建议网络(Region Proposal Network,RPN)网络中引入RoI(Region of Interest),并在RoI 中使用sobel 滤波器,同时提高了模型的检测精度和训练速度;岳有军等[14]在原始Mask RCNN 网络的基础上增加边界加权损失函数,使边界检测结果更为精确,该方法对苹果有不错的检测效果;任之俊等[15]对Mask RCNN 中的特征金字塔(Feature Pyramid Networks,FPN)进行改进,改进算法在目标边缘和包围盒两项检测中的平均准确率分别较原始Mask RCNN 检测框架提高了约2.4%和3.8%,尤其对于中等尺寸目标的检测准确率有较大提高,分别为7.7%和8.5%。
本文在以上研究基础上提出一种基于改进Mask RCNN 的番茄检测方法,首先提出一种新型RoI 提取器代替传统RoI提取器,不仅保留了FPN 各层的特征信息,也实现了特征增强。其次在主干网络中引入了空洞卷积网络,保证了番茄特征图不变化,还减少了算法的计算量,使得检测速度有所提升。最后采用迁移学习的方法将官方COCO 数据集训练得到的权重模型作为本文番茄果实检测算法的预训练模型[16],构建了一种能够同时实现番茄识别和实例分割的检测模型。
1 Mask RCNN
Mask RCNN 是深度学习领域的一大创新,其集成了物体检测和实例分割两大功能,大大提高了实例检测的准确度,取得了coco2016 数据集的冠军。Mask RCNN 主体结构如图1所示。
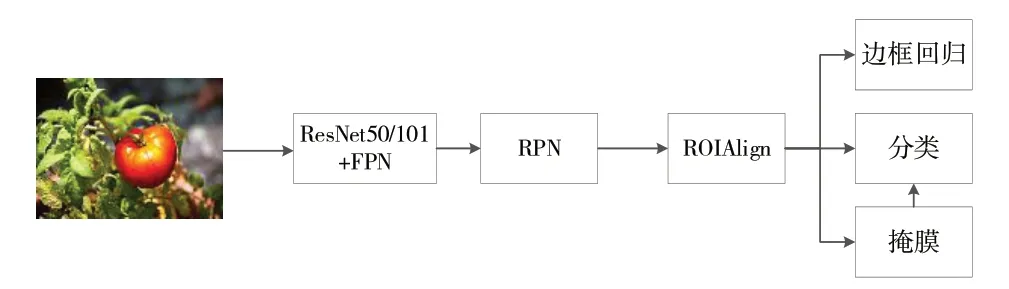
Fig.1 Mask RCNN main structure图1 Mask RCNN主体结构
1.1 主干网络
Mask RCNN 的主干网络包括特征提取网络和FPN[17]。特征提取网络一般采用残差网络中的ResNet50 或ResNet101。残差网络ResNet 旨在解决当模型训练时,随着模型的层数增加,其中的冗余层越来越多的问题。如果能将这些冗余层实现恒等映射,那么其输入和输出就能保证完全相同,从而确保这些冗余层对模型训练结果不产生影响。残差网络具体结构如图2 所示。当F(X)=0 时,该残差网络就完成了一个恒等映射。本文考虑到只检测番茄一种物体,为提高模型检测效率,故采用ResNet50 作为特征提取网络。FPN 是对特征提取网络的扩展,可很好地将高层的、高语义、低分辨率信息与浅层的、低语义、高分辨率信息连接起来,因此本文选用ResNet50+FPN 作为本文的主干网络。
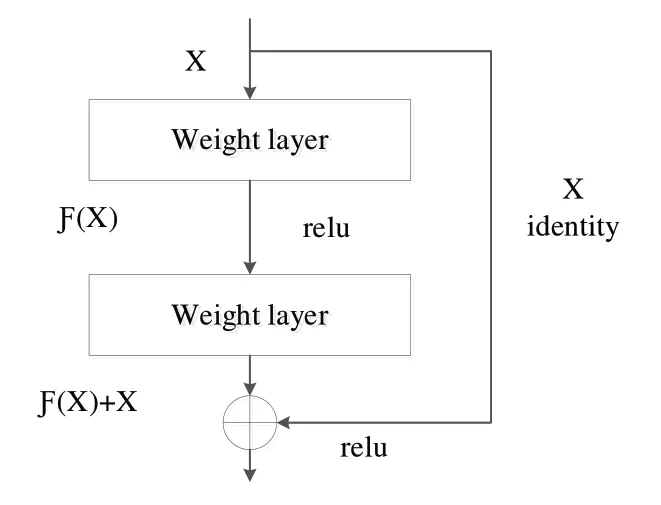
Fig.2 ResNet structure图2 残差网络结构
1.2 RPN
RPN 最初是在Faster RCNN 中被提到,在Mask RCNN中被沿用,其将主干网络中输出的Feature Map 作为输入,在原图中生成若干个anchor(包含4 个坐标的矩形框),并通过滑动窗口机制生成多个不同尺度的anchor。IoU(即交并比)在RPN 网络中尤为常用,利用IoU 可以将检测框与真实框进行对比,从而得到所需要的目标框,然后计算出两者的位置偏移,得到回归损失函数,其计算方式见式(1)。同时它还有一个很好的特性,即尺度不变性。将这些anchor 与真实框进行IoU 对比,规定一个阈值,若IoU 大于这个值,则为目标框,否则属于背景框。
式中,A为检测框,B为真实框。
1.3 RoI Align
在Mask RCNN 出现之前,Faster RCNN 算法是通过RoI Pooling 将不同大小的特征图池化为同一大小,以方便之后的卷积操作。然而该操作导致量化误差过大,因此本文提出RoI Align 算法,其取消了量化操作,利用双线性插值法计算获得坐标为浮点数的像素值,然后池化这些浮点数坐标值,最后得到同一大小的Feature Map。
1.4 损失函数
Mask RCNN 是在Faster RCNN 的基础上增加了一个mask 分支,既有与Faster RCNN 相同的分类损失和回归损失,又有其独有的mask部分损失。总损失公式表示为:
只有当为1 时才需要考虑回归损失函数,该函数表示为:
式中,ti为预测框与候选框之间的偏移值,为真实框与候选框之间的偏移值。
Mask损失函数表示为:
式中,y为经过二值化处理后的实际物体,y*为二值化后检测的分割结果。
2 改进Mask RCNN
2.1 一种新型RoI提取器
在深度神经网络中,低层特征语义信息比较少但目标位置准确,高层特征语义信息比较丰富但目标位置比较粗略[18],针对这种语义信息不平衡现象,FPN 被提出,其网络结构见图3。以ResNet50 作为backbone 的主干网络为例,FPN 通过自上而下的结构得到了{C2、C3、C4、C5}这4 个特征图,也是该网络的4 个级别。其利用自上而下和下采样的方法将顶层的小特征图放大,并通过侧向连接的方式使得相同层特征得到融合,然后经过3×3 卷积核,得到最终的特征图{P2、P3、P4、P5}。
传统的RoI 提取器仅从FPN 中选择其中的一层,而FPN 得到的不同层特征图对应不同的特征尺度,且对最终检测结果有一定作用,因此为保证FPN 的所有层信息都能够得到保留,本文提出一种新型RoI 提取器。首先将FPN中输出的不均匀Feature Map 进行RoI Align 池化操作,得到相同尺寸的特征图{Q2、Q3、Q4、Q5};然后运用non-local模块进行预处理,增强特征信息,获得{S2、S3、S4、S5};最后通过1×1 卷积核对特征图进行降维,将所有特征进行连接,得到一个单一的RoI,其结构如图4所示。
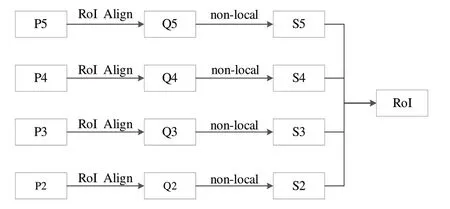
Fig.4 Novel RoI extractor architecture图4 新型RoI提取器结构
为增强特征信息,可使用non-local 模块,其输出大小与输入相同,表示为:
式中,x为输入的Feature Map,y为输出,f(xi,xj)可以计算出i 与j 之间的位置关系,g(xj)计算输入在j 位置的特征值,c(x)为归一化参数。
non-local 模块结构如图5 所示,其中X 为一个输入的特征图,H、W 分别为特征图的高和宽,1024 为特征图的通道数,经过3 个1×1 的卷积核,通道数分别减少一半,变为512,经过flat和trans 处理得到[512,H×W]的输出。将α卷积核对应的支路进行矩阵转置操作后得到[H×W,512]的输出,与ɓ 卷积核对应的支路进行矩阵乘法操作,得到一个[H×W,H×W]的矩阵。然后经过softmax 归一化处理,与γ卷积核对应的支路输出进行矩阵相乘,得到[512,H×W]的结果。将H×W 重新扩展为[H,W],再经过一个1×1 卷积核便能得到与x 相同的特征图Y[1024,H,W],与X 叠加得到Z,实现了特征增强。
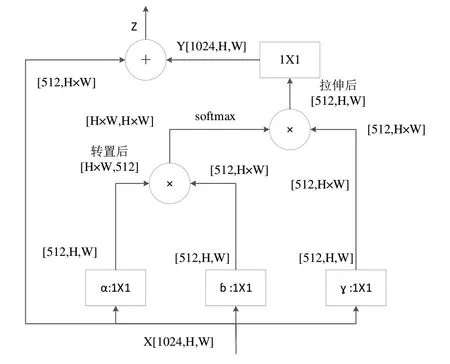
Fig.5 Schematic diagram of non-local module structure图5 non-local模块结构
由于每个FPN 输出的均为RoI Align 池化所得到的一个256 维的特征图,为了合并形成一个单一的RoI,需要将4 个FPN 输出的1024 维的特征图降到256 维,可以采用1×1 卷积核降维。假设池化后所得到的特征图大小为28×28×256,则可以使用64 个1×1×256 的卷积核,得到28×28×64 的特征图,将4 个FPN 输出连接,就能获得一个256 维的RoI。
2.2 空洞卷积算法
空洞卷积(Atrous Convolution)[19]又称为扩张卷积或膨胀卷积,其主要通过在常规卷积核中填充0 来扩大卷积任务中的感受野。Mask RCNN 在进行番茄分割任务时使用常用的池化层和卷积层来扩大感受野,会缩小最终的番茄特征图尺寸,空间分辨率也会降低,而且大量池化层进行下采样也会使一些重要的番茄数据丢失。因此,本文在主干网络中添加空洞卷积。空洞卷积与常规卷积不同,其引入了一个超参数(Hyper Parameter),称为扩张率(Dilation Rate,以下简称rate),通过控制rate 的大小能够得到不同大小的卷积感受野[20]。图6(a)(b)(c)中分别显示的是rate=1、rate=2 和rate=3 的空洞卷积核产生的感受野,与传统的3×3 卷积相比,(a)无变化,(b)将感受野扩大到了5×5,(c)的感受野甚至达到了7×7。

Fig.6 Receptive field generated by different rate values图6 不同rate值产生的感受野
本文选用rate=2 的空洞卷积核提取特征,不但扩大了卷积感受野,还保证了番茄输出特征图的不变化。此外,卷积核的引入还降低了本文算法的计算量,使得检测速度有所提升。
3 实验方法
3.1 数据获取与标注
本文将江苏大学蔬菜大棚内的番茄作为研究对象,采用Canon 600D 型号相机作为拍摄工具,挑选出2400 张番茄图像进行试验,其中2000 张作为训练集,200 张作为测试集,200 张作为验证集。使用Labelme 对数据集进行一一标注,使用多边形线段描出每个番茄的轮廓,并对所有番茄赋予标签“Tomato”,标注方法如图7所示。
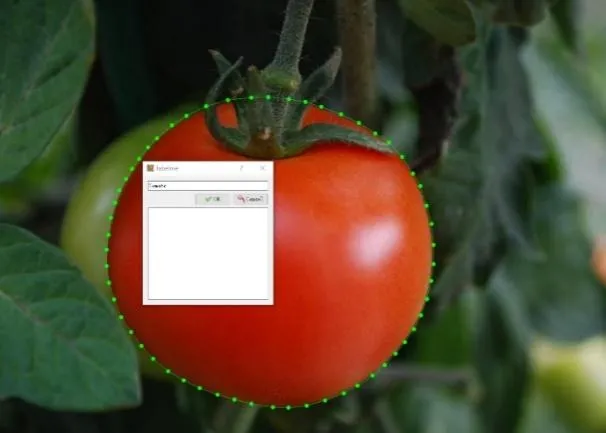
Fig.7 Dataset labeling methods图7 数据集标注方法
3.2 模型训练与测试
本文算法基于深度学习框架Tensorflow,实验环境为Windows 2010 操作系统,代码运行环境为Python3.6,使用NVIDIA GeForce GTX 1660 的图形处理器(GPU)加速运算。训练时所设置的具体参数如下:图片大小为1024×600,动 量(momentum)为0.9,学习率(learning_rate)为0.001,迭代次数(num_steps)为20000 次。使用官方COCO数据集上预训练好的模型框架作为本文的初始化网络模型,将训练好的模型在Jupyter notebook 软件上进行测试,验证本文模型对番茄识别的准确性。
4 实验结果分析
4.1 评价指标
选择平均精度(Average Precision,AP)和平均召回率(Average Recall,AR)作为番茄检测准确性的数值指标,其中精度(Precision,P)、召回率(Recall,R)的计算方式分别为:
式中,TP 为真阳性,表示被模型检测为番茄且实际为番茄的数量;FP 为假阳性,表示被模型检测为番茄但实际为背景的数量;FN 为假阴性,表示被模型识别为背景但实际为番茄的数量。
以R 为横轴、P 为纵轴作P-R 曲线,AP 可以表示为PR 曲线与坐标轴围成的面积,计算公式为:
以IOU 为横轴、R 为纵轴作召回-IOU 曲线,AR 可表示为召回-IOU 曲线下面积的两倍,计算公式为:
可以看出,AP 和AR 值越大,检测准确度越高。
4.2 改进算法的检测效果与性能分析
采用Jupyter notebook 软件对训练完成的模型进行准确性验证,将本文改进算法模型与Faster RCNN、原始Mask RCNN(ResNet50)模型检测结果进行比较,结果如图8 所示。可以看出,Faster RCNN 模型检测准确率差,只达到80%,且没有实现实例分割;原始Mask RCNN 模型虽实现了实例分割,但识别准确率不高;本文改进算法模型不仅在检测精度上有不错提升,实例分割部分也比原始模型更饱满、更准确。3 种模型的AP 和AR 值如表1 所示。通过对自制番茄数据集的训练,改进后的Mask RCNN 模型不仅能对番茄果实进行识别,还能进行实例分割,且准确率更高,较改进之前的AP 值分别提高了5.5%和4.7%,AR 值分别提升了6.8%和4.6%。

Fig.8 Comparison of the detection effects of three models图8 3种模型检测效果比较

Table 1 Comparison of test results of three models表1 3种模型测试结果比较
5 结语
本文提出新型实例分割方法,可以实现对成熟番茄的自动识别,达到自动化采摘的目的。该方法设计了一种新型RoI 提取器,首先对不均匀Feature Map 进行RoI Align 池化操作,然后运用non-local 模块增强特征信息。此外,空洞卷积核的引入使得算法计算量降低,检测精度有所提升。通过在自制番茄数据集上进行训练和测试,实验结果表明,平均精度和平均召回率均相较于改进之前的Mask RCNN 有明显提升,更好地实现了实例分割,提升了检测识别精度。后续研究主要考虑两个方面,一是均衡模型的复杂度与泛化能力,综合考虑多个因素增加输入特征,减少训练中的输入偏差;另一方面是在实例分割算法[21]的基础上进行改进,对果实成熟度、果实质量检测以及病害果实识别等方面进行深入研究。
