改进Inception结构的图像分类方法
2023-03-08董跃华彭辉林
董跃华,彭辉林
(江西理工大学 信息工程学院,江西 赣州 341000)
0 引言
自21 世纪始,互联网及大数据不断推动着深度学习算法的发展,其在语音识别[1]、目标检测[2]、图像分类[3]等众多领域都取得了重大成就。其中,卷积神经网络(Convolutional Neural Network,CNN)以其优秀的特征提取能力、泛化能力成为图像分类领域中的研究热门之一。Alex Krizhevsky[4]在ImageNet 大赛上提出的AlexNet 网络一举得魁后,成功地将CNN 推向了图像分类领域的研究热门之一,并带动了一系列CNN,如VGGNet[5]、Inception[6-9]、ResNet[10]、DenseNet[11]、MobileNet[12-14]等模型不断被提出,关于CNN 模型的研究尤如井喷式增长。
早期CNN 的发展趋势是网络深度越来越深。2015 年ImageNet 竞赛冠军ResNet 层数为AlexNet 的20多倍,是VGGNet 的8倍多,通过增加网络层数可以产生更好的特征表达。然而增加网络层数的同时也增加了CNN 的整体复杂程度,在深度网络中会导致大量参数冗余,并产生过拟合、网络退化问题等,从而使模型变得难以优化,所设计的网络不利于应用在目前发展迅速的移动端市场。因此,在保持模型精度的基础上进一步减少模型参数量和复杂度的轻量化CNN 模型逐渐引起人们的关注。2017 年,Google 提出采用深度可分离卷积代替标准卷积的轻量化网络MobileNet;2018 年,Zhang 等[15]提出ShuffleNet,对输入的通道进行分组;2020 年,华为提出GhostNet[16],通过廉价操作以更少的参数生成更多特征。轻量化网络通过降低模型参数量,不仅降低了对模型训练的硬件设施要求,还极大降低了模型训练时间,推动了CNN 走出实验室,更广泛地应用于移动端市场。但在深度CNN 中,其计算成本往往是由大量卷积操作所导致的,尽管在轻量化网络引入分组卷积等操作,以小卷积构建网络,但在深度网络中仍然会导致大量冗余参数。
为解决深度网络中容易陷入性能饱和区的问题,由Google 提出的Inception 系列模型首先提出一种基于多分组并行卷积结构的Inception 模块。Inception 模块的诞生使网络不再局限于向更深层次,而是向更宽的方向改进。通过并行训练多组不同尺寸的卷积池化操作,不仅可提升模型对不同尺度的适应性,还可拓展网络宽度,有效提升了CNN 的分类性能。然而,由于使用了大量小卷积操作,导致其在深度网络中同样存在大量冗余参数,从而使得网络难以优化。基于以上背景,文献[17-18]提出采用空洞卷积替代Inception 结构中的标准卷积,有效提升了模型的特征交互能力,但其结构复杂度使其在深度网络中仍然会产生大量冗余参数;文献[19]通过简化Inception 结构,有效解决了随着网络不断加深而导致的参数大幅增长问题,但同时也弱化了网络对不同尺度的适应性。
受以上研究工作启发,本文提出一个改进Inception 结构的轻量化网络模型,通过提取Inception 模块各分组中的1×1 卷积压缩Inception 模块结构,减少由于使用大量1×1卷积而带来的冗余参数,并结合GhostNet 模型,以廉价的深度卷积生成更多特征图。模型主体以标准卷积与非对称卷积交互结合,以此增加网络深度及其非线性表达能力。同时,将CIFAR-10 数据集以及苹果叶病害数据集[20]作为实验数据,对VGG16、Inception-V3、MobileNet 模型分别进行训练,并采用准确率、训练时间及模型参数量等评价指标与本文模型进行比较,以验证本文模型的性能。
1 模型相关技术
1.1 卷积结构
传统CNN 模型一般由卷积层(Convolution)、激活层(activation)、池化层(pooling)和全连接层(fully connected neural network,FC)组成。为提高模型准确率,通常对其进行组合加深,或对某一种或多种结构进行改进。通过对卷积层进行改进可以在一定程度上改善模型性能,由其延伸而来的非对称卷积、深度卷积等卷积操作以及由卷积等操作结合的模块化结构取得很大成功。
1.1.1 标准卷积
对于一个标准卷积而言,其卷积过程如图1 所示。在输入特征图大小为H×W×M(其中H×W 为长宽,M 为通道数),卷积核大小为K×K,卷积核数量为N,padding 值为1,步长为1 的情况下,得到的输出特征图大小为H×W×N,计算过程为:①对于输入特征图上K×K×M 大小的特征,与K×K 大小的卷积核进行点乘求和,得到输出图中1 个通道的1 个点,其计算量为K×K×M;②为得到输出单通道为H×W 大小的特征图,需重复步骤①中的操作H×W 次,得到一个卷积核的卷积计算量为K×K×M×H×W;③对卷积核数量为N 个的卷积操作过程,还需对每个卷积核重复上述步骤,得到卷积操作计算量为K×K×M×H×W×N。
最终可得标准卷积操作的计算公式为:
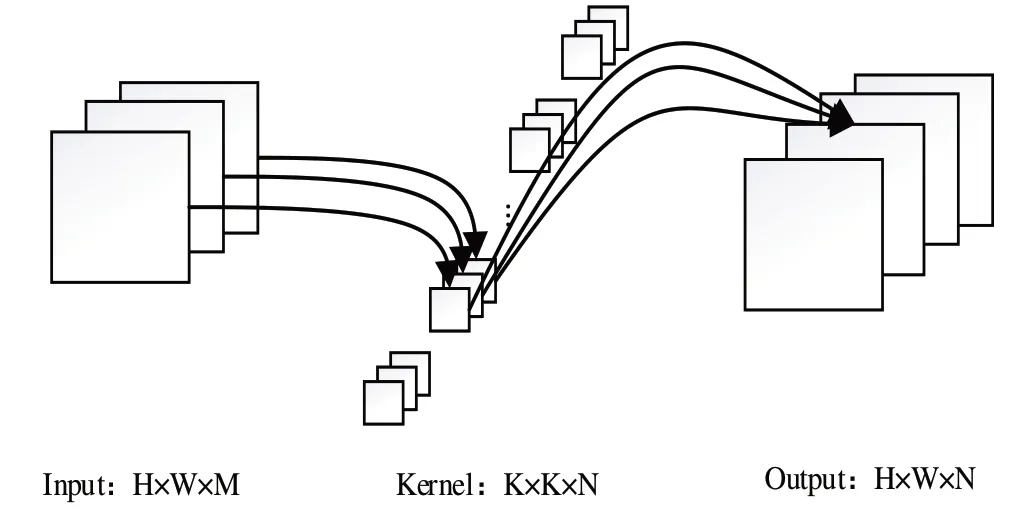
Fig.1 Standard convolution process图1 标准卷积过程
1.1.2 深度卷积
深度卷积与标准卷积的区别在于深度卷积的每次卷积操作只需与单个通道信息融合,如图2 所示,若输入特征图大小为H×W×M,卷积核大小为K×K,则输出大小为H×W×M,其计算过程仅为标准卷积操作的前两步即可。深度卷积的计算公式表示为:
1.2 Inception
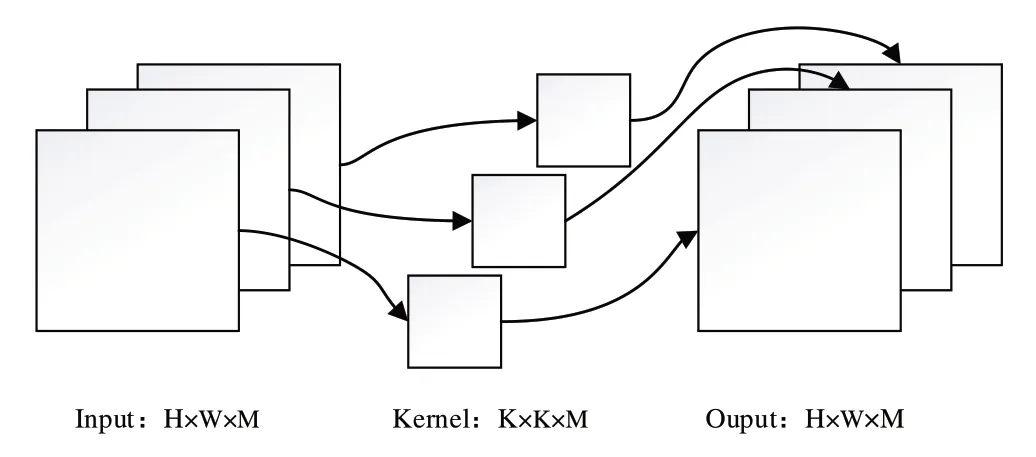
Fig.2 Deep convolution process图2 深度卷积过程
在Inception 系列模型之前,大部分CNN 的改进方式为通过增加传统的卷积、池化等操作加深网络,从而提取更深层次的特征。Inception 系列模型设计的Inception 模块是具有优良局部拓扑结构的网络,通过并行利用多个1×1、3×3、5×5 等不同尺寸的卷积与池化操作,并将其输出结果拼接,形成一个同时具备深度与宽度的特征图。在后续改进中采用小卷积代替大卷积,并引入非对称卷积,将3×3的卷积核拆分为3×1 和1×3 的两个卷积核,进一步减少了模型参数量。图3 展示了Inception v3 模型中采用的Inception 模块结构。

Fig.3 Inception module structure图3 Inception模块结构
1.3 注意力机制
注意力机制[21]具有强大的信息资源分配功能,可以在大量杂乱信息中将计算资源分配给更加重要的任务。CBAM(Convolutional Block Attention Module )模块是注意力机制中常用的一种,该模块由通道注意力模块与空间注意力模块两部分构成。通过构建空间注意力模块以及通道注意力模块,分别汇总空间和通道两个子模块的注意力信息,实现从通道到空间的顺序注意力结构,并能够嵌入到卷积操作当中,从而得到更完整的注意力信息,进而完善计算资源的分配方式,在只增加少量计算量的同时优化模型分类效果。
1.4 Ghost模块
针对深度神经网络普遍存在大量冗余特征的问题,GhostNet 模型提出了Ghost 模块。该模块使用ratio 控制因子将输入特征分成两部分,第一部分进行标准卷积操作;另一部分则使用分组卷积操作进行线性变化以生成更多特征图,然后将两部分得到的特征拼接,形成完整的Ghost模块。与标准卷积结构相比,Ghost 模块参数量及运算成本均有所降低。Ghost模块结构如图4所示。
2 改进Inception结构的模型
2.1 改进Inception结构

Fig.4 Ghost module structure图4 Ghost模块结构
传统Inception 结构的优势在于利用1×1卷积进行降维操作,并结合不同尺寸小卷积操作与池化操作达到获取多样特征信息、减少参数量的目的。然而由于使用了大量1×1 卷积,导致大量不必要的冗余参数产生,且Inception 结构只有在深层次网络结构中才能起到更高效的作用,因此参数量依旧很高。针对以上情况,本文提出以下两点改进方法:①传统Inception 结构每个分组中都加入1×1 的卷积操作,其目的为进行降维操作,但使用大量1×1 卷积不仅会增加Inception 结构的复杂度,还会占用大量内存和浮点运算。因此,本文提出将传统Inception 结构中每个分组中的1×1 卷积提取出来并单独形成一层网络,通过减少1×1 的卷积操作,在实现降维操作的同时有效降低inception 结构的复杂度,并减少其参数冗余;②传统Inception 结构在深度网络中往往会产生大量参数,为进一步减少Inception 结构参数,本文结合Ghost 模块,以更廉价的深度卷积操作代替Inception 结构中的3×3 卷积分组部分,以更低参数生成更多幻影特征图,增强其特征多样性,在保留传统Inception 多分组带来的特征多样性的同时,增加Ghost 模块廉价卷积操作的特性。
改进后的Inception 结构如图5 所示,首先对输入进行1×1 的标准卷积操作进行降维;然后对降维后的输出特征分别进行3×3 的池化操作、1×3 和3×1 的非对称卷积操作以及1 个3×3 深度卷积操作;最后通过Concatenate 方法将这3 个分组输出的特征与1×1 标准卷积的输出特征进行特征融合,即可得到改进后Inception 结构的输出特征。

Fig.5 Improved Inception structure图5 改进的Inception结构
与传统Inception 结构相比,改进的inception 结构通过合并冗余的1×1 卷积操作简化了Inception 结构,同时增加了深度卷积操作,以低成本获取到更多特征图。改进后的Inception 结构参数量为165504,较传统Inception 结构参数量(439690)大大减少,仅约为传统Inception 结构的1/3左右。
2.2 模型结构
本文构建的基于改进Inception 结构的网络模型结构信息如表1所示。

Table 1 Network model structure based on improved Inception structure表1 基于改进Inception结构的网络模型结构
模型第一段结构通过使用非对称卷积替换部分标准卷积操作,以标准卷积与非对称卷积交替提取特征,旨在提升模型的深度并减少网络参数量,并以池化操作对网络进行下采样,实现降维功能。模型第二段和第三段结构中加入改进的Inception 结构,以达到提升网络深度及宽度、减少网络参数的作用,并通过提取多种不同尺度的特征信息,稳固提升CNN 模型对不同尺度的适应能力。与此同时,对改进的Inception 结构加入残差结构可以很好地解决随着网络不断加深而带来的网络退化问题,并加快模型收敛速度。为增加网络中的特征权重、提升网络泛化能力,在Inception 模块后添加注意力机制CBAM,通过CBAM 获取经权重分配后的特征图,从而获取更加关键和重要的特征信息,达到提升模型分类效果的目的。在模型结尾加入全局平均池化操作,以取代传统的全连接层。全局平均池化可以在结构上对整个网络作正则化,进而防止过拟合,且其对输入图像尺寸没有限制,通过重新整合空间特征信息,使算法具有更强的鲁棒性。最后通过softmax 函数对输入图像进行分类。
3 实验方法与结果分析
3.1 实验数据来源
网络模型的泛化能力越强,表明其普适性越强,对未知数据集的处理能力也就越强。为了验证本文模型的有效性,分别在CIFAR-10 数据集与苹果叶病害数据集上进行实验。其中,CIFAR-10 数据集由50000 个训练图像和10000 个测试图像组成,共分为10 类,每类有6000 个彩色图像,每张彩色图像大小为32×32。图6 为CIFAR-10 数据集中的示例图像。

Fig.6 Examples of image in CIFAR-10图6 CIFAR-10图像示例
苹果叶病害数据集由斑点落叶病、褐斑病、花叶病、灰斑病以及锈病5 种苹果叶面病害图像数据组成,其中斑点落叶病5345 张,褐斑病5655 张,花叶病4875 张,灰斑病4810 张,锈病5694 张,每张图像数据大小为512×512 像素。图7展示了苹果叶病害数据集中的示例图片。
为降低模型计算量,增加实验数据,通过数据裁剪的方式将原始图像裁剪为224×224 大小的图像数据,训练集与测试集比例为9∶1。同时通过数据增强方式增加图片数据量,以防止过拟合并提高模型泛化能力。模型训练采用Nadam 算法,初始学习率为0.02,学习衰减因子为0.1,最小学习率为le-6,批次处理大小为128,迭代次数为100。
3.2 实验环境配置
本文实验在NVIDIA GTX1050TI GPU+8G 内存配置的服务平台上进行,另采用Python 语言的keras 深度学习库框架对CIFAR-10 数据集及苹果叶病害数据集进行训练与测试。详细配置如表2所示。
3.3 实验结果分析

Fig.7 Examples of image in apple leaf disease dataset图7 苹果叶病害数据集图像示例

Table 2 Experimental environment configuration表2 实验环境配置
通过在CIFAR-10 数据集和苹果叶病害数据集上的分类准确率、训练参数及模型参数量来比较本文模型与传统CNN 模型(VGG16、InceptionV3、MobileNet 模型)的性能。同时,为了比较改进Inception 结构与传统Inception 结构的性能,在本文模型中分别使用这两种Inception 结构进行实验。表3 和表4 分别展示了各模型在CIFAR-10 数据集和苹果叶病害数据集的训练性能。由表3 可以看出,本文模型在CIFAR-10 数据集上相较于传统CNN 模型参数量更少、训练时间更短、准确率更高,其中分类准确率相较VGG16和InceptionV3模型分别提高了3.91%和2.69%。虽然轻量化CNN 模型MobileNet 模型参数量及其训练时间都要略低于本文模型,但其分类准确率只达到了88.21%,比本文模型降低了4.48%。此外,改进Inception 结构的模型不仅参数量比传统Inception 结构更少、训练时间更短,且准确率提升了0.77%,训练时间减少了9min,在减少模型参数的同时不仅提升了其准确率,还有效降低了模型训练时间,充分体现了改进inception 结构具有结构简单、功能强大的优势。
由表4 可以看出,在苹果叶病害数据集中,本文模型分类准确率达到93.43%,与VGG16、InceptionV3 及MobileNet 模型相比分别提高了9.18%、6.65%和4.53%,同时本文模型训练时间较VGG16 与InceptionV3 分别降低了384min 及507min,较MobileNet 仅增加23min。与传统Inception 结构相比,改进Inception 结构的模型准确率提升效果较在CIFAR-10 数据集中更明显,提升了2.51%,且训练时间也降低了99min。
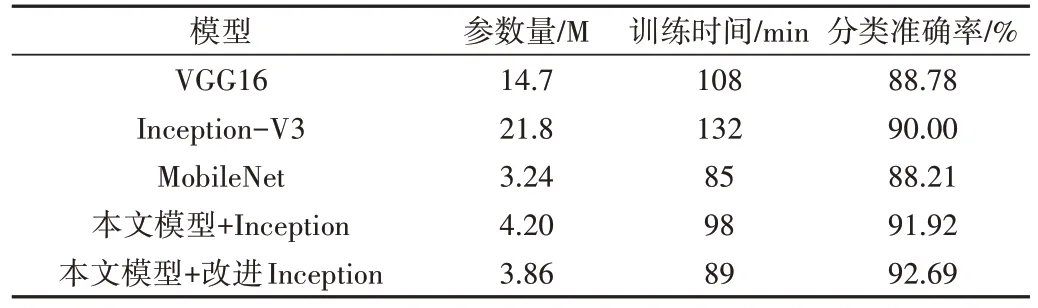
Table 3 Performance of each model on the CIFAR-10 dataset表3 各模型在CIFAR-10数据集上的性能
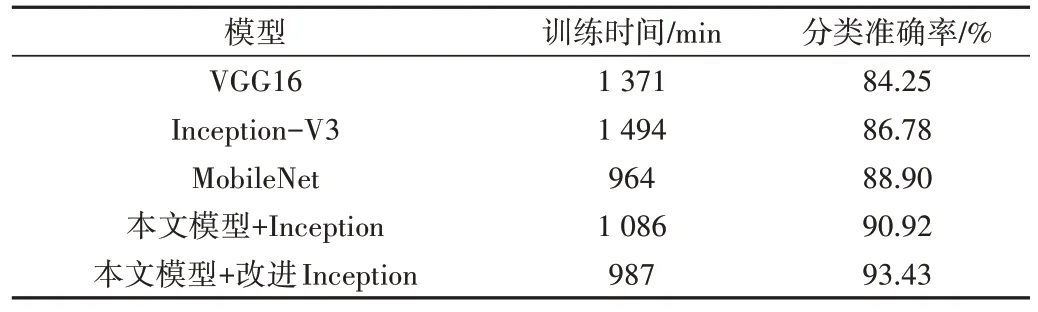
Table 4 Performance of each model on the apple foliage dataset表4 各模型在苹果叶病害数据集上的性能
为测试改进后Inception 结构在深度神经网络中的表现,在不同模型深度层次下分别进行多次实验,结果如表5所示,表中A 指的是Block_inception 在模型中的叠加次数。可以看出,本文模型在深度网络中的性能并未随着Inception 模块叠加次数的增加而一直增加。当Block_inception模块数量为1 时,改进模型在CIFAR-10 及苹果叶病害数据集中的准确率分别为92.69%与93.43%;当Block_inception 模块数量为3 时,准确率达到92.87%与94.54%,模型准确率呈上升趋势;当Block_inception 叠加5 次时,模型准确率最高,分别达到了93.75%与96.81%。此后继续增加Block_inception 模块数量时,模型准确率不增反降,因此可以看出,当Block_inception 模块数量叠加5 次后,模型分类效果最佳。
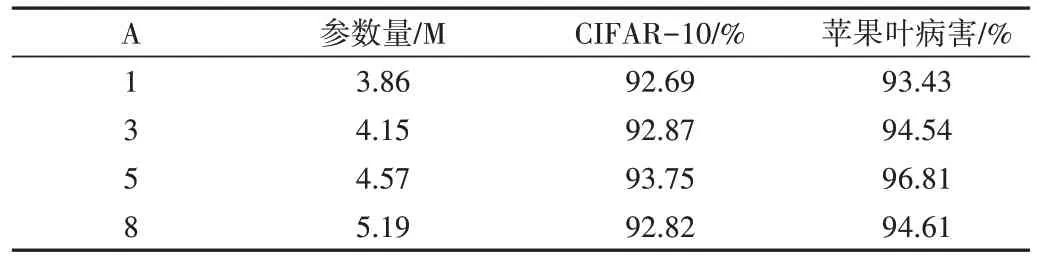
Table 5 Model training performance at different depths表5 不同深度的模型训练性能
4 结语
本文提出一种基于改进Inception 结构的轻量化CNN模型,该模型通过整合传统Inception 结构中冗余的1×1 卷积,并引入深度卷积操作,有效改善了传统Inception 模块结构复杂、参数冗余的问题。为进一步减少网络模型参数量,提高其特征多样性,在模型主体结构设计时以标准卷积和非对称卷积交替插入。改进模型参数量较传统CNN大大缩减,在实际应用中能够极大降低模型运行时间及对硬件设施的要求。通过在CIFAR-10 数据集与苹果叶病害数据集上的实验结果表明,与传统CNN 模型及轻量化CNN 模型相比,本文模型的图像分类效果更佳,模型分类所需设备及训练时间要求更低。此外,本文提出的改进Inception 结构也具有更好的特征表达能力,能进一步推动CNN 向移动端应用市场靠拢。
