自注意力下时空-语义相融合的POI序列推荐
2023-03-06刘树越于亚新吴晓露夏子芳王子腾
刘树越,于亚新,吴晓露,夏子芳,王子腾
1(东北大学 计算机科学与工程学院,沈阳 110819) 2(东北大学 医学影像智能计算教育部重点实验室,沈阳 110169)
1 引 言
无线网络和定位技术的不断创新,使得用户能够随时随地利用智能设备记录自己当前的地理信息[1],产生了海量时空数据,造成信息过载.如何有效的处理数据量持续上升的时空数据,挖掘用户有意义的运动行为模式,为用户推荐可靠的POI[2]受到了人们的普遍关注.
传统的POI推荐通常会根据位置、时间或者评论信息等向用户推荐POI,但是传统方法仅仅从静态的角度出发考虑用户和POI之间的关系,无法有效地捕获用户的动态偏好.与传统的POI推荐不同,POI序列推荐考虑了用户的顺序移动模式,利用用户的历史签到序列,从中挖掘用户的动态偏好,根据该偏好为用户提供准确的POI推荐.典型的解决方案有马尔可夫链MC(Markov Chain),循环神经网络RNN(Recurrent Neural Network)以及自注意力SA(Self Attention)机制,它们都能够从用户的历史签到序列中捕获用户的动态偏好.基于马尔可夫链的方法[3,4],用户状态间的转移仅依赖于前n个状态.此方法已经被成功地用来捕获推荐系统中的短期项目过渡,但是马尔可夫链难以捕获较长的上下文序列并且计算复杂度较高.循环神经网络RNN[5,6]也被应用到推荐中,包括长短期记忆网络LSTM[7](Long Short-Term Memory)和门控循环单元GRU[8](Gated Recurrent Unit).虽然它们可以解决长期依赖问题,但是每一时刻的状态输入都需要等待上一时刻状态输出完成,不能捕获全局信息,另外也不适合并行计算.相较于马尔可夫链和循环神经网络,自注意力机制[9]的提出有效地解决该问题.在序列推荐中,采用自注意力机制处理用户签到序列能够较好地捕获全局信息,而且可以实现并行处理.
然而,基于上述模型的POI序列推荐在处理用户与POI的交互数据时,都是将用户的历史签到数据假设为有序序列,而不考虑每个交互之间的时间间隔(即它们建模的是时间顺序,而不是实际的时间戳).显然,这不符合实际情况.即使用户的POI签到顺序相同,但具有更短时间间隔的POI将会对推荐效果产生更大的影响.另外,POI之间的地理距离以及语义信息也是影响推荐的重要因素.因此,本文提出了自注意力下时空-语义相融合的POI序列推荐模型SA-TDS-PRec(POI sequence recommendation model based on the integration of spatiotemporal and semantics under self-attention),主要贡献如下:
1) 提出自注意力下时空-语义相融合的POI序列推荐模型SA-TDS-PRec,将用户签到数据之间的时间间隔、空间间隔以及语义相关性进行结合,利用自注意力机制捕获用户动态偏好的演化,从而提升POI推荐的准确性.
2) 提出基于行为语义序列的POI关联度计算方法.通过构建POI语义关联图,从用户的历史签到序列中提取语义信息,计算用户签到序列中POI之间的语义相关性.
3) 进行可扩展性实验设计与测试.在公开数据上进行验证,结果表明SA-TDS-Prec模型优于其他基准模型.
2 相关工作
2.1 传统POI推荐
传统POI推荐利用用户对POI的签到次数挖掘用户偏好,根据该偏好为用户推荐POI.受项目推荐的启发,传统POI推荐算法把POI类比成项目,将项目推荐的一些方法直接应用到POI推荐上[10,11].比如说协同过滤CF(Collaborative Filtering)算法.在POI推荐的早期工作中,Ye等人将基于用户的协同过滤[12]和基于项目的协同过滤用于POI推荐[13].
矩阵分解MF(Matrix Factorization)是基于模型的协同过滤方法,它在POI推荐中的应用也十分广泛.矩阵分解通过将所有用户和项目投射到具有相同维度的空间中,利用隐向量表示用户偏好和项目属性,通过内积的方式预测用户与项目交互的可能性.另外矩阵分解方法具有良好的可扩展性,许多影响推荐效果的因素(如POI的地理信息、时间信息以及用户的社交关系等)都能与之相结合,因此衍生出许多POI推荐算法.
Cheng等人[14]利用多中心高斯模型MGM(Mutil-center Gaussian Model)建模POI之间地理距离关系,然后将MGM模型和矩阵分解MF模型相结合,并引入地理距离进行推荐.Li 等人[15]对地理社交网络中用户之间的关系进行了重新定位,分别为普通的社交关系,基于位置的关系以及邻居关系,通过使用两阶段模型,从朋友中学习潜在位置信息,然后将潜在位置与其他签到进行合并,最后融入到加权矩阵分解中,从而有效克服了推荐中的冷启动问题.Yang等人[16]提出一种基于张量分解得多维信息融合兴趣点推荐通用模型,利用三阶张量融合时间、社会关系和类别影响,有效解决数据稀疏和冷启动问题.Yuan等人[17]提出融合时间序列POI动态推荐算法,将用户与用户之间的关系、兴趣点位置以及流行度信息相结合,从而有效缓解数据稀疏的问题.Yu等人[18]利用社交网中大众数据的文本内容和签到服务地点,提出了挖掘活动和服务对应关系的ASTM,并将用户的活动区域与服务地点间的距离以及地点属性间的耦合性融合到矩阵分解中,实现个性化服务场所推荐.
2.2 POI序列推荐
与传统POI推荐(比如说基于协同过滤的方法)不同,POI序列推荐认为用户的每个签到行为并不是离散的,用户对POI的签到是有序的[19].POI序列推荐就是通过将用户与POI的交互建模成一个序列,通过分析序列的复杂顺序关系捕获用户的动态偏好,利用该偏好给用户推荐POI.
目前,POI序列推荐算法中常使用的一些技术主要有马尔可夫链、循环神经网络RNN、卷积神经网络CNN、自注意力机制等.Wu等人[20]提出了长短期偏好学习模型(LSPL),在长期模块中通过注意力机制捕捉POI长期偏好,在短期模块中通过两个LSTM模型学习针对位置和类别的偏好信息,将长短期偏好相结合更好地捕捉用户在特定时间对下一个POI的偏好信息.Kong等人[21]提出一种时空长短期记忆网络模型HST-LSTM,该网络模型在LSTM中结合了时空影响,在一定程度上缓解数据的稀疏性.Xu等人[22]提出利用RNN模型捕获复杂的长期依赖,同时也利用CNN模型提取在短期下隐藏状态之间的序列模式.Zhao等人[23]提出新的时空门控网络模型(STGN),通过引入时空门捕获连续签到之间的时空关系.Zheng等人[24]提出基于注意力的动态偏好模型(ADPM),设计了时空自注意力网络来探索复杂的POI顺序关系,捕获用户的动态偏好.
然而,上述模型都存在不足.传统的基于矩阵分解方法仅仅从静态的角度出发考虑用户和POI之间的关系,无法对用户签到序列进行有效地建模.基于马尔可夫链的方法无法同时考虑多种上下文信息以及上下文信息的交互作用.现有基于RNN的方法对时空信息建模,忽略了上下文的语义信息.虽然RNN可以解决长期依赖问题,但是需要大量数据才能优于更简单的基线方法.不同于已有模型,本文提出的SA-TDS-Prec模型将用户签到数据之间的时空间隔以及语义相关性相融合,利用自注意力机制捕获用户动态偏好的演化,从而提升POI推荐的准确性.
3 问题定义及描述
表1给出本文使用的符号列表和描述.

表1 符号列表Table 1 Symbol List
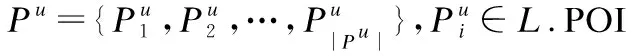
定义1.兴趣点POI.一个具有特定功能的地理位置,能够满足用户需求(如电影院或咖啡馆).在本文提出的模型中,POI包含3个属性:唯一标识符id、语义信息c和地理信息d(lng,lat),其中lng代表经度,lat代表纬度.
定义2.签到记录(Check-in).一个签到记录被表示为一个五元组(u,l,t,d,c),这个五元组的含义就是用户u在t时刻访问POIl,POIl的地理信息是d(lng,lat),类别信息是c.
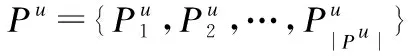
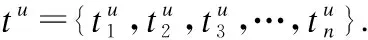
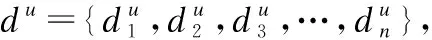
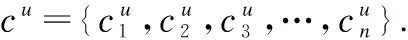
4 自注意力下时空-语义相融合的POI序列推荐(SA-TDS-PRec)模型描述
本文提出的自注意力下时空-语义相融合的POI序列推荐模型SA-TDS-PRec,根据用户实际签到时间对用户签到序列建模.同时将用户签到序列中POI之间的时间间隔、空间间隔和语义相关性相融合,并利用自注意力机制捕获用户动态偏好,从而为用户提供准确的POI推荐.
本文首先介绍时间间隔、空间间隔和语义相关性的具体计算方式,然后描述SA-TDS-PRec模型的具体组件,主要包括嵌入层、自注意力层和预测层.SA-TDS-PRec模型结构如图1所示.
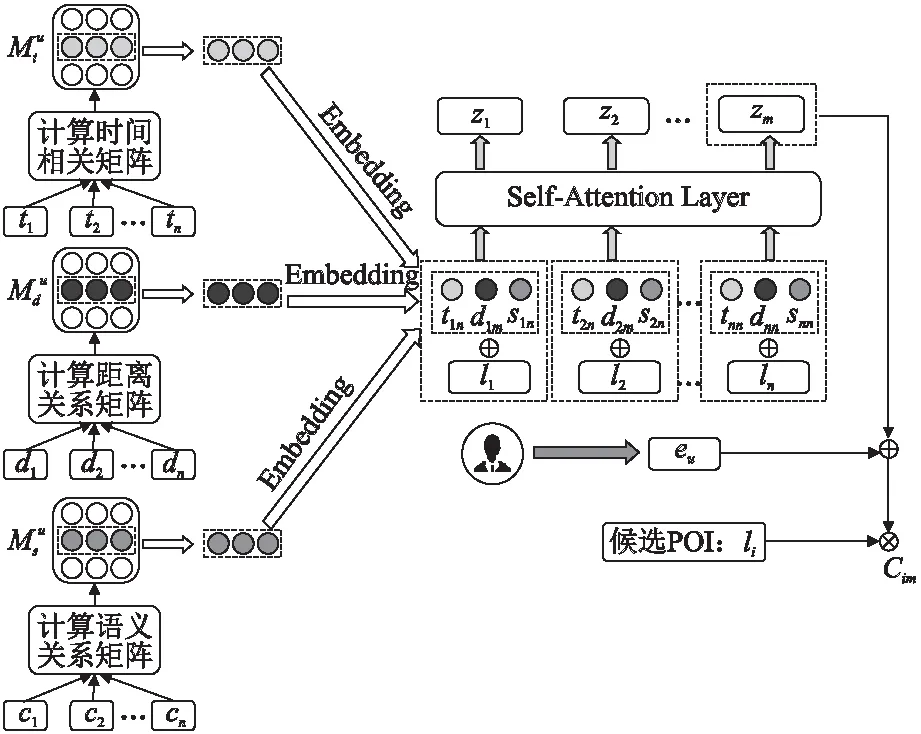
图1 SA-TDS-PRec模型结构Fig.1 Framework of SA-TDS-PRec
4.1 基于时空不等间隔的POI轨迹建模


(1)
根据第一地理学法则[25]可知,用户通常会访问距离自己当前位置较近的地点,用户的移动会受到空间距离的影响.因此,POI之间的空间距离也是影响推荐效果的重要因素之一.
Distance(li,lj)=
(2)
其中,Distance(li,lj)表示POIi和POIj间的平面距离,radi表示弧度值,a=|lati-latj|表示两点的纬度差,b=|lngi-lngi|表示两点的经度差,r表示地球半径(r=6371公里),最终形成空间间隔集合Du.
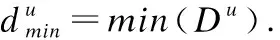
(3)
4.2 基于行为语义序列的POI关联度计算
语义序列是由用户POI轨迹中提取的每一个POI类别信息组成的.用户的每一次签到行为之间都存在着一定的语义相关性,并且签到序列之间语义相关性是成对的.语义相关性越大,代表用户选择的可能性越大.
之前关于语义相关性的计算是通过统计的方法来进行的,语义序列中两个类别之间的转换次数越多代表两个类别之间的语义相关度越高.但是,仅仅通过统计类别之间的转换次数来计算语义相关性的方法会受到数据量的影响.如果用户的签到数据很少,则计算结果会产生误差.由于用户签到POI之间的时间间隔会影响用户的移动,所以本文提出融入时间间隔计算语义相关性.
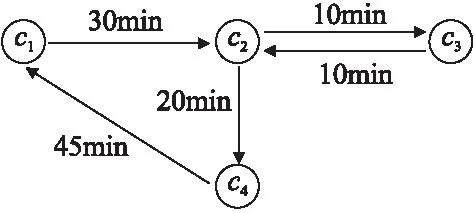
图2 语义关联图Fig.2 Semantic correlational graph
然后根据构建的语义关联图,计算用户语义行为序列中POI之间的关联度(即语义相关性).具体的计算规则如下:
1)如果两个相邻节点之间有向边的权重(即时间间隔)相等,那么两个节点之间有向边的数量越多表明POI之间的语义相关性越大,反之亦然.
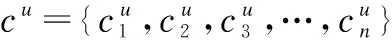
(4)
(5)
(6)
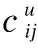
(7)
语义相关性算法伪代码如算法1所示.
算法1.语义相关性计算
输入:用户u的历史签到序列

1.构建语义关联图Gu
2.提取语义序列cu
3.划分cu为一对一的序列集合c′u
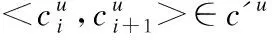
5.遍历Gu,统计m和we
6.如果m>0,执行
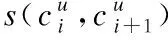
8.否则
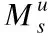
4.3 SA-TDS-PRec模型
4.3.1 嵌入层
在给定用户历史签到序列后,利用词嵌入技术创建POI嵌入矩阵ML∈RN×d,其中N代表POI的数量,d代表潜在维度.通过检索,获得用户签到序列的嵌入向量为EL∈Rn×d:EL=[l1l2…ln].
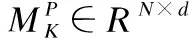
(8)
同样,个性化空间间隔嵌入向量如式(9)所示:
(9)
语义相关性嵌入向量如式(10)所示:
(10)
4.3.2 自注意力层
将上述嵌入层获得的POI绝对位置、时间间隔、空间间隔、语义相关性嵌入向量进行融合,输入到自注意力层中捕获用户的动态偏好.关于模型的每一步输出,自注意力层都考虑到了用户历史签到序列中其他所有POI对当前步的影响.最后得到输出序列Z={z1,z2,z3,…,zn},zi∈Rd.输出序列的每一项zi的计算公式如式(11)所示:
(11)
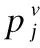
(12)
其中eij表示输入序列中POIj对当前POIi的影响分数,通过将键向量与查询向量进行点积运算来获得,如式(13)所示:
(13)
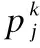
虽然自注意力机制能够将用户签到的POI绝对位置信息、时间间隔、空间间隔以及语义相关性相结合,但是它采用线性组合的方式进行的.因此在自注意力层之后,使用前馈神经网络FNN(Feedforward neural network),利用ReLU激活函数赋予模型非线性,具体计算公式如式(14)所示:
FFN(zi)=max(0,ziW1+b1)W2+b2
(14)
其中W1,W2代表权重,b1,b2代表偏差.
为了避免在堆叠很多层后出现过拟合、梯度消失等问题,模型采用了层归一化、残差连接和Dropout技术.残差连接的主要作用是保证有用的底层特征能够直接传播到最后一层,计算公式见式(15).层归一化操作用来对特征向量进行规范化处理,简化学习难度,计算公式见式(16).Dropout技术用来防止出现过拟合现象.
Zi=zi+Dropout(f(LayerNorm(zi)))
(15)
(16)
其中,f(·)是前馈神经网络或者自我注意层,⊙是element-wise product,μ和σ是输入向量zi的均值和方差,α和β是学习的缩放因子和偏置项.
4.3.3 预测层
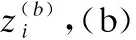
(17)
其中lj表示POIj的嵌入表示.Ri,j越高意味着用户的兴趣越大,POIj被推荐的可能性越大.
4.4 模型训练
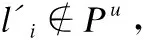
(18)
5 实验及结果分析
5.1 实验设计及数据集
本文在两个开源的数据集Gowalla和Yelp上进行模型评估.首先进行数据清洗,如果用户和POI出现次数少于10,删除该用户.清洗完数据后,根据每个用户的具体签到时间建模用户的签到序列.数据统计见表2.
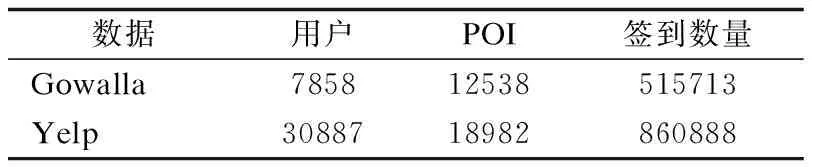
表2 数据集统计Table 2 Statistics of datasets
5.2 评估指标
为了验证SA-TDS-PRec模型的性能,采用两个常用指标命中率Hit@k和NDCG@k.Hit@k是一种常用的衡量召回率的指标,计算出真实的下一个POI在推荐的前k个POI中所占的比重大小,计算公式如式(19)所示:
(19)
其中,GT分母是所有的测试集合,NumberOfHit@k分子表示用户top-k列表中属于测试集合的个数总和.
NDCG@k是一种衡量排序质量的评价指标,该指标考虑了所有元素的相关性,同时还引入了位置影响因素,它在较高的位置上分配较大的权重.计算公式如式(20)所示:
(20)
其中,DCG@k是折损累计增益,它是让相关性越好的结果排名越靠前.IDCG@k表示理想情况下最大的DCG值.
5.3 对比模型
为验证所提出的SA-TDS-PRec模型的性能,对比模型如下:
1)BPR[26]:一种基于矩阵分解算法的排序算法,采用贝叶斯最大后验概率,利用成对方法来进行排序.
2)FPMC[3]:因式分解个性化马尔可夫链,该方法将矩阵分解和一阶马尔可夫链进行结合,矩阵分解用来捕获用户的长期偏好,一阶马尔可夫链用于建模用户与项目交互的序列信息,通过上一时刻的交互预测下一时刻的交互.
3)GRU4Rec[6]:利用循环神经网络进行会话行为推荐.传统的序列化推荐方法在进行推荐时只考虑用户的最后一个行为,没有考虑完整的行为序列信息.而该模型恰好解决了这一问题.
4)Caser[27]:卷积序列嵌入推荐模型,该模型利用卷积神经网络CNN建模用户行为序列,学习用户短期序列特征,并结合用户静态偏好,共同为用户进行推荐.
5.4 性能测试与分析
5.4.1 总体性能
表3展示了该方法在Gowalla和Yelp数据集上与基准方法的对比结果.从表中可以看到,SA-TDS-PRec模型与最优的基线模型相比,在Gowalla数据集中命中率和NDCG两个评价指标分别提高了7.9%和11.0%.在Yelp数据集中命中率和NDCG两个评价指标分别提高了12.0%和8.6%.一方面,SA-TDS-PRec模型采用自注意力机制,在训练模型的时候每一时刻状态输出都考虑了用户所有的签到信息,而不像传统的马尔可夫链模型和循环神经网络模型,它们每一时刻的状态输出都依赖上一时刻的状态输入.另一方面,SA-TDS-PRec模型融合了用户历史签到序列中POI之间的时间间隔、空间间隔和语义相关性,进一步提高了推荐的准确性.
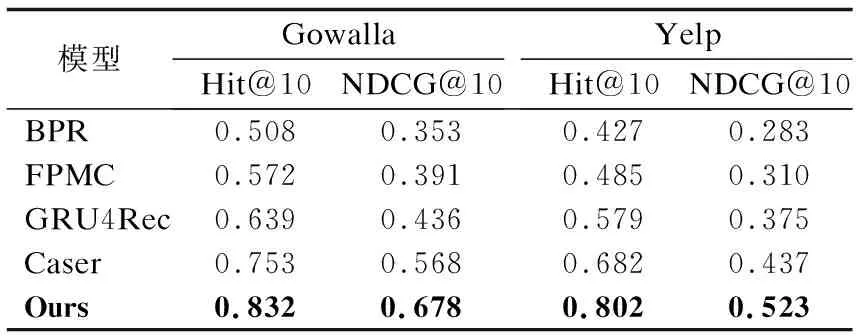
表3 整体性能比较Table 3 Overall performance comparison
5.4.2 时间、空间、语义对模型影响
本文利用自注意力机制处理用户轨迹,另外融合用户轨迹中POI之间的时间间隔、空间间隔和语义相关性的信息.为验证提出方法的有效性,设计4组消融实验.其中SA模型是只利用自注意机制进行推荐,不考虑其他因素.SA-T模型是只考虑时间间隔因素.SA-D模型只考虑空间间隔因素.SA-S模型是只考虑POI的语义相关性.SA-TDS-PRec融入时间间隔,空间间隔以及语义相关性.实验结果如表4所示.
从表4中可以看出,与只利用自注意力机制推荐的模型SA相比,融合时间间隔因素SA-T模型、融合空间间隔因素SA-D模型和融合语义相关性模型SA-S,推荐准确性都得到了提升.这表明在个性化POI推荐中,不论是时间间隔、空间间隔还是语义相关性,都会影响推荐的准确性.而且本研究也发现,时间、空间以及POI的语义信息对推荐的影响程度几乎相同.这说明用户在出行的时候会考虑多方面因素,实验结果也表明将3种因素综合考虑,会进一步提升推荐的准确性.
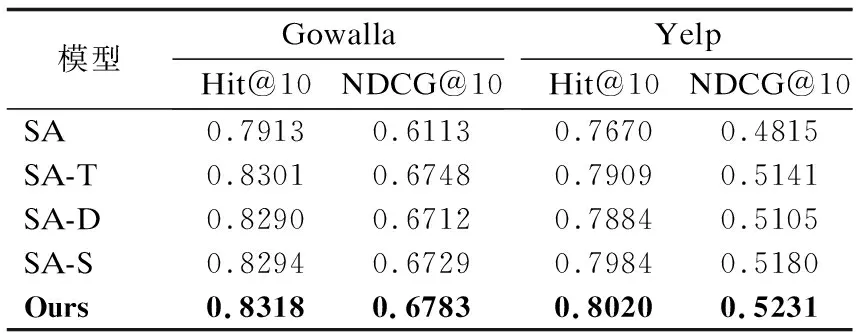
表4 消融实验结果比较Table 4 Comparison of ablation experiment results
5.4.3 签到序列长度n对模型影响
图3和图4分别在Gowalla和Yelp数据集上展示了用户签到序列长度n对于评估指标NDCG@10的影响.将用户签到序列长度n的值设为从10~50,其他参数保持不变.从图中可以直观的看到,无论是在Gowalla数据集上还是Yelp数据集上,当用户签到序列长度不断增加时,现有模型的推荐效果整体呈现上升趋势.这说明用户的签到序列越长,模型所学习到的用户信息就越多,因此能够更好的捕获到用户的动态偏好.
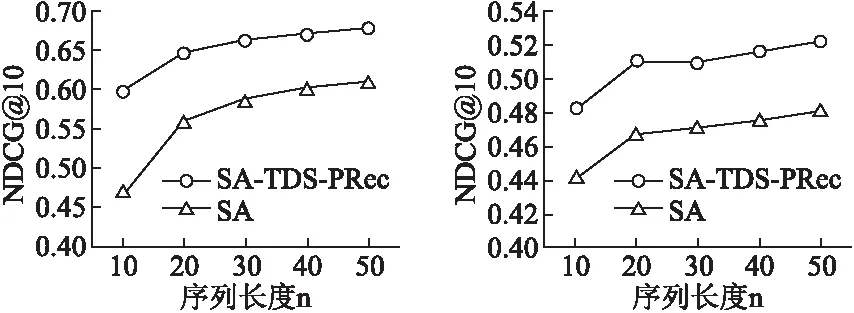
图3 Gowalla数据集中序列长度对NDCG的影响 图4 Yelp数据集中序列长度对NDCG的影响Fig.3 Effect of sequence length on NDCG in the Gowalla dataset Fig.4 Effect of sequence length on NDCGin the Yelp dataset
5.4.4 特征表示维度d对模型影响
图5和图6分别在Gowalla和Yelp数据集上展示了特征维度d对于评估指标NDCG@10的影响.将特征维度d的值设为从10~50,其他参数保持不变.从图中可以看出,无论是在Gowalla数据集上还是Yelp数据集上,随着特征表示维度的不断增加,现有模型的推荐效果整体呈现上升的趋势.相较于SA模型,SA-TDS-PRec模型的性能始终优于SA模型.
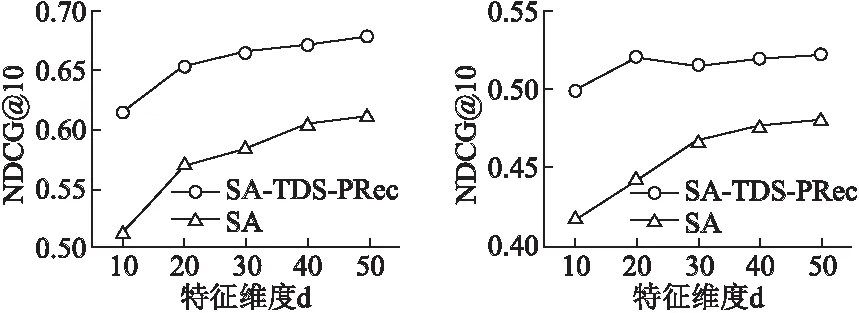
图5 Gowalla数据集中特征表示维度对NDCG的影响 图6 Yelp数据集中特征表示维度对NDCG的影响Fig.5 Effect of feature representation dimension on NDCG in the Gowalla dataset Fig.6 Effect of feature representation dimension on NDCG in the Yelp dataset
6 结 论
本文提出自注意下时空-语义相融合的POI序列推荐模型SA-TDS-PRec.该模型根据用户对POI的具体访问时间对用户签到序列进行建模,另外还将序列中POI之间的时间间隔、空间间隔和语义相关性纳入考虑范围,利用自注意力机制捕获用户动态偏好的演化,进一步提升推荐的准确性.本文在公开数据集Gowalla和Yelp上进行模型评估,实验结果表明,本文提出的模型在性能上优于其他基准模型,有效提升推荐结果准确性.在未来的研究工作中,希望可以加入用户对POI的评论信息,以此来更好的挖掘用户的动态偏好.
