计算实验方法的溯源、现状与展望
2023-03-06于湘凝周德雨周长兵王飞跃
薛 霄 于湘凝 周德雨 ,2 彭 超 王 晓 周长兵 王飞跃
随着互联网的普及、物联网的渗透、大数据的涌现以及社会媒体的崛起,复杂系统越来越多地呈现出社会、物理、信息相融合的特征.这类社会复杂系统[1-2]因为涉及到了人和社会的因素,其设计、分析、管理、控制和综合等问题正面临前所未有的挑战.为了应对上述挑战,研究者们需要实现两个目标: 规律描述与理论解释.规律用以理解系统复杂性 “如何”产生;理论用以回答系统复杂性 “为何”会发生.但是,社会系统的复杂性,以及人类认知的有限性,都导致传统的机理建模方法难以发挥作用.鉴于此,研究者们就考虑将实验方法引入到社会复杂系统的研究中.
但是,人们很快发现,社会系统的实物实验很难实施,其原因归结如下: 1)在方法层面.社会复杂系统不能用还原法进行分解,因为分解后的系统在本质上已经不具有原系统的功能和作用了,必须采用整体论的方法进行研究[3].2)在经济方面.如果直接在真实社会系统中进行实验,其成本往往过于高昂,时间周期也非常漫长,从而导致实验者难以承担.3)在法律方面.许多社会复杂系统涉及国家安全、军事战备、应急事件等问题,受立法保护,以致无法对研究的系统进行实验,也无法重建这些实验系统.4)在道德方面.社会复杂系统往往有大量人员的参与,对这些系统进行实验,有可能冲击人的正常生活,甚至危害人的生命和财产,以至于在道德上无法接受这类实验[4].
基于此,许多社会复杂系统的研究只能求助于计算机仿真环境中的 “反事实实验”,即在假设条件下对社会复杂系统的发展趋势进行推演分析[5].计算实验方法的思路如图1 所示,该方法以现实中的客观世界为参照系统,从微观尺度出发,构建出具有自治特性的个体模型与交互规则,在信息世界中培育出现实系统的 “计算实验室[6]” (人工社会构建);接着,通过修改系统所遵循的规则、参数和外部所施加的干预,可以在这个实验室中进行各种假设实验(计算实验执行);基于实验结果,可以寻找干预策略与系统涌现之间的因果关系,为解释、理解、引导和调控现实中的宏观现象提供了一种新的工具和手段(解释、预测和优化).
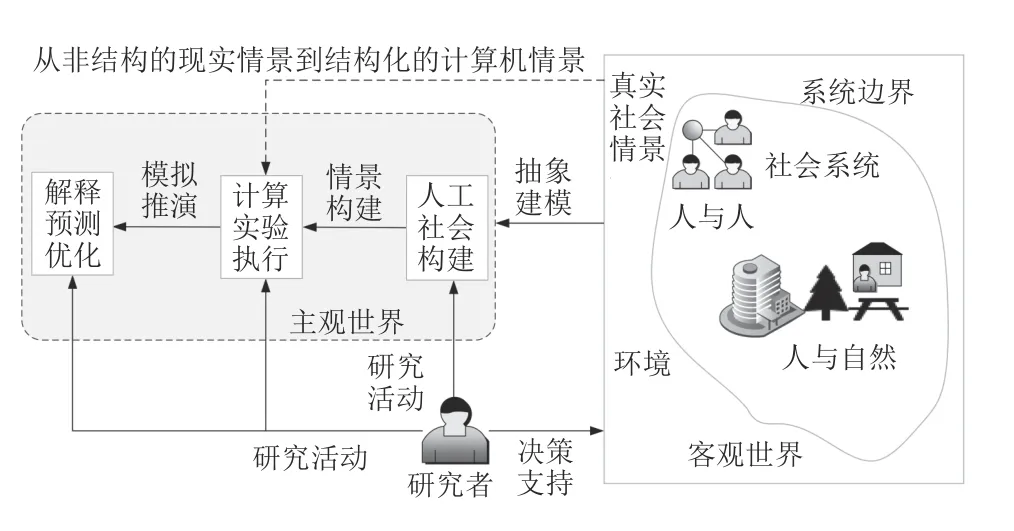
图1 计算实验的示意图Fig.1 Schematic diagram of computational experiment
计算实验的本质,就是将 “反事实”算法化,以数据驱动、涌现机制和多重世界的解释与引导理论为基础,为量化分析复杂系统提供一种数字化和计算化方法[7-8].与实物实验相比,计算实验具有以下特点: 1)精确可控.通过设置环境参数(如地理因素、人员分布等),以及触发事件(如时间、位置、类型、规模等),可以准确再现各种场景作为系统的运行环境.2)操作简单.在系统推演过程中,很容易通过各种极端实验来评估系统的不同性能指标,如正确率、响应率等.3)可重复性.这一优势使得研究者可以设计不同的实验场景,分别评估不同因素(如地理环境、触发事件特征等)对系统性能的影响[9].
经过十余年的发展,计算实验方法已经成为分析复杂系统的主流方法之一,成功应用于一些风险较大、成本较高或者现实中无法直接进行实验的系统研究,包括智能交通系统[10-11]、战争模拟系统[12]、社会网络系统[13]、生态环境系统[14]、生理/病理系统[15-16]、政治生态系统[17]等.但是,其发展也面临着一系列挑战,包括计算模型的比较与验证、计算实验的设计方法、知识驱动与数据驱动的融合等.对这些问题的深入研究,将会为计算实验更为广泛的跨学科应用,奠定坚实的理论基础.另外,随着强化学习、数字孪生、元宇宙等新技术的涌现,计算实验也需要不断与新技术加强融合,进一步提升计算实验分析解决问题的应用价值.
本文结构如下: 第1 节主要介绍计算实验方法的概念起源与应用特点,以及本文的研究动机;第2 节详细阐述了计算实验的方法框架,包含人工社会建模、实验系统构建、实验设计、实验分析与实验验证5 个环节;第3 节给出了三类计算实验的典型案例,包括现象解释、趋势预测和策略优化;第4 节探讨了计算实验方法面临的挑战和未来的发展趋势;第5 节对全文进行了总结.
1 背景与动机
计算实验是一个标准的交叉学科研究领域,其发展历史与复杂系统的研究,以及计算机仿真技术的发展密不可分.本节主要介绍计算实验方法的概念起源、应用特征以及本文的研究动机.
1.1 计算实验的起源
随着科学研究的深入,人们所关注的研究对象的规模越来越庞大,功能和结构日趋复杂,涵盖了自然现象、工程、经济、管理、军事、政治和社会等诸多领域[18].从方法和路径上看,计算实验具有连接计算机领域、应用工程、人文学科、社会科学和经济研究的可能性.研究者们从计算机学科的立场出发,把研究范围扩展到了社会领域,并以 “问题导向”为出发点,与其他领域的专家合作研究了许多有趣而新颖的课题.如图2 所示,复杂系统的研究(系统建模) 与计算机模拟技术的发展(仿真建模).两条主线互相交织,最终形成了计算实验方法的来源.

图2 计算实验的概念来源Fig.2 Conceptual sources of computational experiments
复杂性科学的研究可以用于指导社会复杂系统的建模,其最早起源于20 世纪初.奥地利生物学家Bertalanffy[19]首次提出了 “复杂性”的概念,其思想来源包括英国生物学家Darwin 的进化论和奥地利物理学家Boltzmann 的统计物理学.随后,复杂系统的研究体系逐步成熟,先后经历了三个较为明显的阶段: 1) 1950~ 1980 年.这个阶段的核心在于系统科学,其代表性工作包括老三论(系统论[20]、控制论[21]、信息论[22])与新三论(散耗结构论[23]、灾突变论[24]、协同学[25]).这一阶段构建起了系统科学的概念和基础方法论,并提出了复杂性科学的思想.2)1980~ 2000 年.这个阶段的关注点在于系统的动态性与适应性,代表性工作包括自组织理论(混沌理论[3,26]、分形理论[27]、临界理论[28])与复杂自适应系统理论[29].这一阶段提出了复杂性研究的计算机模拟方法,并提出了人工社会理论.3) 2000 年至今.这个阶段开始强调与数据科学理论的结合,代表性工作包括复杂网络[30-31]与社会物理信息系统[1-2].由此,复杂性研究迈入了新时代.
伴随着复杂系统研究的快速发展,用于仿真建模的计算机模拟技术也得到了长足的进步.计算机模拟技术的发展使得在信息空间中映射真实系统成为可能.传统的计算机仿真认为实际系统是唯一存在,并将仿真结果与实际系统是否一致作为检验实验结果的唯一标准.而计算实验则在此基础上更进一步,把计算机作为 “人工实验室”来 “培育”实际系统中可能出现的宏观现象,探究背后的规律,这为分析复杂系统行为和评估各种干预效果提供了一种可行方式.计算模拟技术的代表性成果如下:
1)元胞自动机.20 世纪50 年代,Neumann[32]提出了元胞自动机的概念,希望为复杂系统的模拟提供通用型的框架.元胞自动机模型强调对自主个体间的相互作用进行建模,更关心微观个体的简单行为在宏观层次上的涌现属性.该模型理论简单,关注点主要局限于微观个体.
2)人工生命.1970 年,Conway[33]编写了 “生命游戏”程序,开启了人工生命研究的序幕.随后,Langton[34]提出了人工生命理论,旨在用计算机等人工媒介构造出具有自然生命系统行为特征的模型系统.朗顿在 “混沌边缘”概念的基础上,与其他学者一起建立了各种人工生命演化模型,如自繁殖元胞自动机[35]、鸟群模型[36]、蚁群模型[37]和 “阿米巴世界”[38]等.相较于元胞自动机,人工生命理论规则复杂,但依旧只关注个体行为.
3)多Agent 技术.多Agent 仿真技术兴起于20 世纪90 年代中期,是研究复杂系统的重要手段.Agent 指具有一定的自治性、智能性和适应性的个体.应用比较广泛的多Agent 仿真工具包括Swarm[39]、Repast[40]、Ascape[41]和Netlogo[42].这些工具各有优劣,需要根据需求来进行选择.多Agent 技术关注个体之间的交互,研究如何从个体层面上升到群体层面.
4)人工社会.1991 年,Carl 等[43]第一次提出“人工社会”这一概念,即利用Agent 技术在计算机中构建社会实验室,对不同的政策进行试验评估,以确保政策的有效性.1995 年,Nigel[44]编辑出版了Rosaria Conte: Artificial Societies,The Computer Simulation of Social Life一书,人工社会被正式提出并成为一个相对独立的社会科学领域.1998 年,英国萨里大学主办的国际学术期刊The Journal of Artificial Societies and Social Simulation开始发行,标志着 “人工社会 -基于Agent的社会学仿真”这个领域的成熟.一批经典的人工社会模型相继涌现出来,包括Epstein 等[45]的糖域模型、Arthur 等[46]的人工股市模型、Basu 等[47]的ASPEN 模型等.人工社会的研究从抽象群体扩展到了具体的社会系统.
5)数字孪生.1994 年,Wang[48]提出 “影子系统”,指由自然的现实系统和对应的一个或多个虚拟或理想的人工系统所组成的共同系统.2019 年,密歇根大学的Grieves[49]正式发表了有关数字孪生的论文,希望在计算机虚拟空间中构建出与物理实体完全等价的数字孪生体,强调建立虚实双向动态反馈机制.在工业领域,数字孪生被用于物理系统和制造过程的监测、诊断、预测和优化.作为特定城市的虚拟副本,数字孪生技术允许城市运营商开发不同的策略,来优化城市的可持续发展[50].数字孪生强调虚拟世界与真实世界的完全映射,但较少涉及社会模拟.
随着复杂性科学与计算机模拟技术的飞速发展,Wang[51]在2004 年正式提出了 “计算实验”的概念,并形成了 “人工系统+计算实验+平行执行”方法,强调人工系统与实际系统之间的循环反馈优化关系[52-53].近些年,随着软件定义[54]、数字孪生[6]、强化学习[55]和服务生态[56]等技术的兴起,计算实验方法的内涵也正在变得日益丰富[8].作为联系虚拟世界与现实世界的桥梁,计算实验正在为解决复杂系统的设计、分析、管理、控制和综合等问题提供新的且更加有效的计算理论和手段.
1.2 计算实验的特点
计算实验方法基于分布式思想,采用自底向上的方法,利用分散的微观智能模型来模拟真实世界中各类实体的微观行为,再通过设计这些个体间的相互作用形成复杂的现象,从而反映整个系统在宏观层面的演化规律.通过精心设计的计算模型与模拟仿真环境,计算实验可作为系统复杂性推理、实验以及最终理解的强大工具.相比于传统分析方法,计算实验方法通过改变内外部因素的组合方式,可以建立各种各样的实验环境(包括现实场景和从未发生过的虚拟场景).对不同因素在系统演化中的作用进行全面、准确、及时、量化的分析评估,甚至可以对系统演化进行各种压力实验以及极限实验.这使得研究者更容易探索复杂系统的运行规律并找到有效的干预措施.
计算实验方法采用复杂系统研究的 “多重世界”观点,即对复杂系统进行建模时,不再以逼近某一实际系统的程度作为唯一标准,而将模型认为是一种 “现实”,是实际系统的一种可能替代形式和另一种可能的实现方式.实际系统只是可能出现的现实中的一种,其行为与模型的行为 “不同”但却 “等价”.表1 将实物实验、田野实验、计算机仿真和计算实验的特征进行了对比.简单来讲,计算实验不仅是实际系统的数字化 “仿真”,也是实际系统的可替代版本(或其他可能情形).可以为实际系统的设计、分析、管理、控制和综合,提供高效、可靠、适用的科学决策和指导.
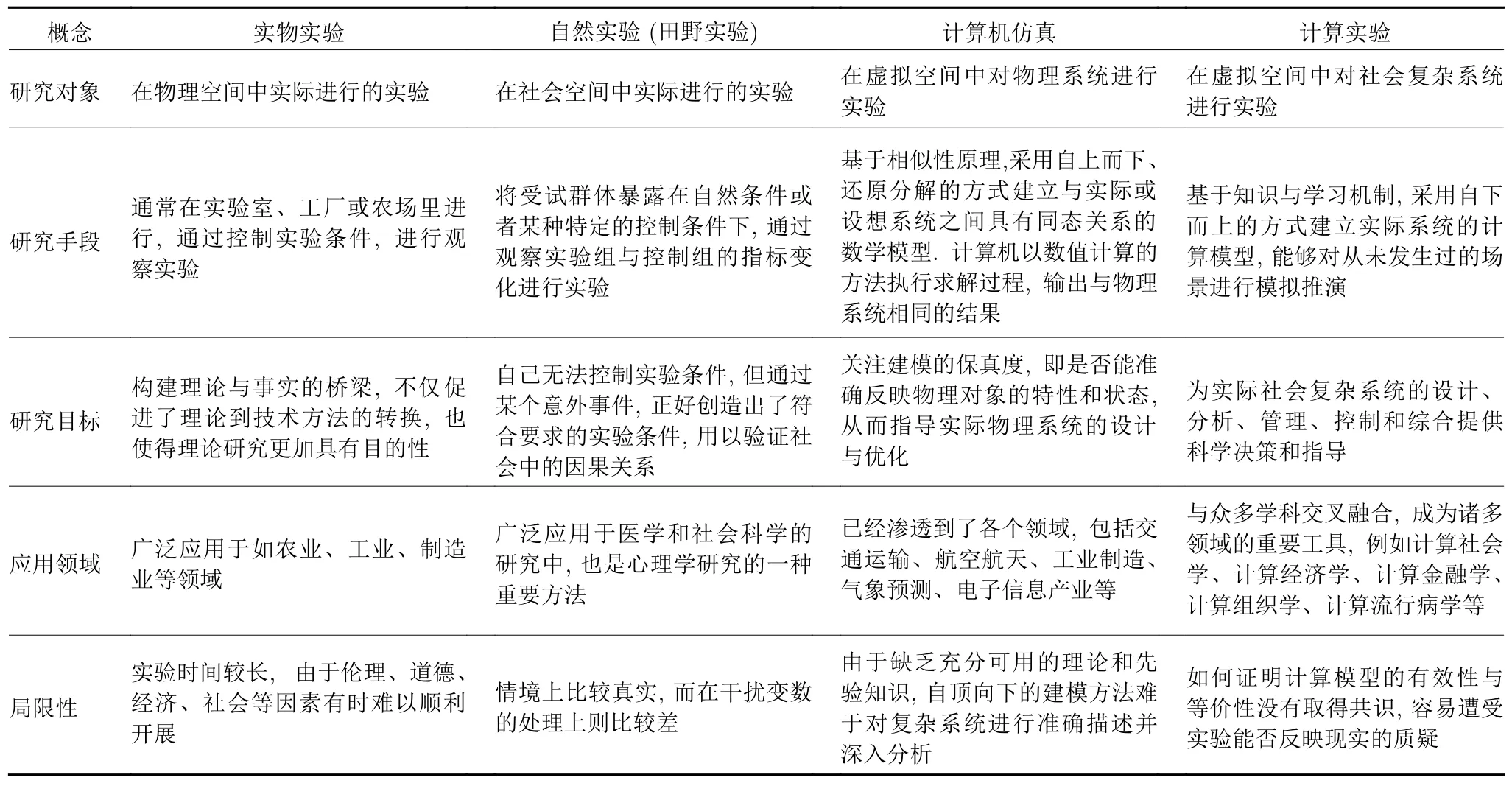
表1 计算实验与相关概念的区别Table 1 Differences between computational experiments and similar concepts
计算实验的应用领域广泛,所体现出的价值也大相径庭.例如,高度现实的模型可能有重大的决策支持价值,但需要针对特定领域定制,缺乏通用性,可能具有较少的理论价值;反之,高度抽象的模型可能提供深刻的科学见解,但就政策贡献而言,却无法提供可以直接应用的结果.根据计算模型的抽象程度,计算实验的相关应用可以归纳为以下4 类:
1)高度抽象
模型仅与参照系统有少数定性相似之处,并没有试图复制任何量化特征.这些模型主要用于基础科学的理论分析,而非运营策略分析.早期的一些社会仿真模型属于这一类型,例如热虫模型[57]、鸟群模型[36]等.
2)适度抽象
模型能够显示令人信服的定性特征且符合某些定量标准.虽然这些模型仍主要是理论性的,但是可以提供某些适用性的见解,对政策产生有价值的影响.比如经典的谢林隔离模型[58],虽然相当抽象,却揭示了关于社会隔离模式的重要见解,并为决策者提供了帮助.
3)适度现实
模型虽然属于定性范畴,但是在重要特征方面均符合定量特征,以实验为基础的社会计算研究对这类模型最感兴趣.例如,现实社会环境中,由于公共安全方面的考量,无法进行一些具有破坏性的社会实验.通过计算实验,改变实验条件、设置不同的变量取值,可以无风险地模拟出许多压力实验,甚至进行极限实验.
4)高度现实
实验输出和经验数据之间的定量和定性特征最为符合.高度现实仿真可以从多个维度与参照系统进行比照,包括空间特征、时间特征或组织模式等.此类模型在商业和政府组织中应用极为丰富.公共政策涉及到社会网络和人的行为这些高度不确定性的领域,导致其分析、制定和实施都伴随着复杂性.把人工社会当作实际系统的替代版本,可以预先利用计算实验方法分析政策(例如经济刺激方案、法律法规颁布等)实施后的效果,从而提升公共政策制定的科学化水平.
1.3 研究动机
随着研究者对于计算实验方法的日益关注,它与社会领域的众多学科交叉融合,已经逐渐成为诸多领域的重要工具,例如计算经济学[13]、计算金融学[59]、计算组织学[60]、计算流行病学[61]、计算社会学[62]等.2009 年2 月,哈佛大学、麻省理工学院等世界一流大学的15 位顶尖学者在Science上联名发表了论文 “计算社会科学时代的到来”[63].2020 年,这些学者在Science上再次联名发表论文,强调了计算社会科学在发展过程中所面临的问题和挑战[64].
但是,计算实验作为多学科交叉的一个研究领域(集成了计算机科学、社会科学、系统科学、人工智能、计算机仿真等诸多学科).尽管科研人员付出了很多努力,目前还没有形成一套完整而成熟的理论体系,其理论发展和实际应用之间还存在着巨大的差距.为了能够对本领域的发展有所帮助,本文梳理了计算实验方法的来龙去脉,希望帮助读者构建起计算实验方法的完整知识体系,从而为后续的方法应用奠定坚实的基础.本文所关注的内容主要包括三个方面:
1) 计算实验方法的技术框架是什么?
计算实验方法作为一个多学科的交叉领域,涉及的领域知识非常多,并且还在不断增长之中.初学者刚开始接触计算实验的时候,很容易淹没在浩如烟海的文献中,难以理清计算实验方法与各类技术之间的关系,而层出不穷的新技术与新应用更加剧了这种困境.由此引发的问题就是,能否形成一个统一的、通用的方法框架,用于指导现有模型的应用或者新模型的开发,从而大幅降低使用者的上手难度.基于此,第2 节对纷繁芜杂的文献资料剥茧抽丝,形成了通用的计算实验方法框架,并对方法的各个步骤进行了系统化阐述.
2) 计算实验方法如何实现特定应用?
由于应用领域的多样性和不确定性,加上人工社会的构建具有较大的主观性,对于所构建的实验系统是否能够代表原系统,在学术界始终存在着不同意见.高置信度是计算实验方法得以发挥作用的基础,除了在实验设计和模型验证技术方面取得突破,还需要对于成功的应用案例进行分析,吸收有价值的经验.只有这样,计算实验方法才会日趋完善,与其他方法取长补短,成为理解复杂系统运行规律的有力工具.基于此,第3 节对典型的计算实验案例进行了梳理,按照现象解释、趋势预测和策略优化三个层面进行了分类,有助于掌握不同应用的特点.
3) 计算实验方法的发展趋势是什么?
计算模型是计算实验方法的核心,也是不同领域知识发挥作用的容器.近些年,各类新技术层出不穷,例如数字孪生[6]、生成式对抗网络[65]、强化学习[55]等,这些技术对于计算模型的构建都造成了相当大的影响.基于此,如何利用各类新涌现出来的人工智能技术来提升计算模型设计,就成为计算实验方法持续发展所要面临的关键挑战.基于此,第4 节主要关注三个方面: a)如何利用大数据定义人工社会,即描述智能;b)如何利用计算实验预测未来,即预测智能;c)如何实现对现实世界的反馈干预,即引导智能.
2 计算实验的方法框架
根据文献[8],计算实验方法的研究框架可以总结为图3 所示,包含人工社会建模、实验系统构建、计算实验设计、计算实验分析、计算实验验证5 个步骤,并形成了一个反馈闭环.因为多Agent 技术是计算实验方法中所使用的主流技术,所以本节将以此为模板对每个步骤进行详细阐述.
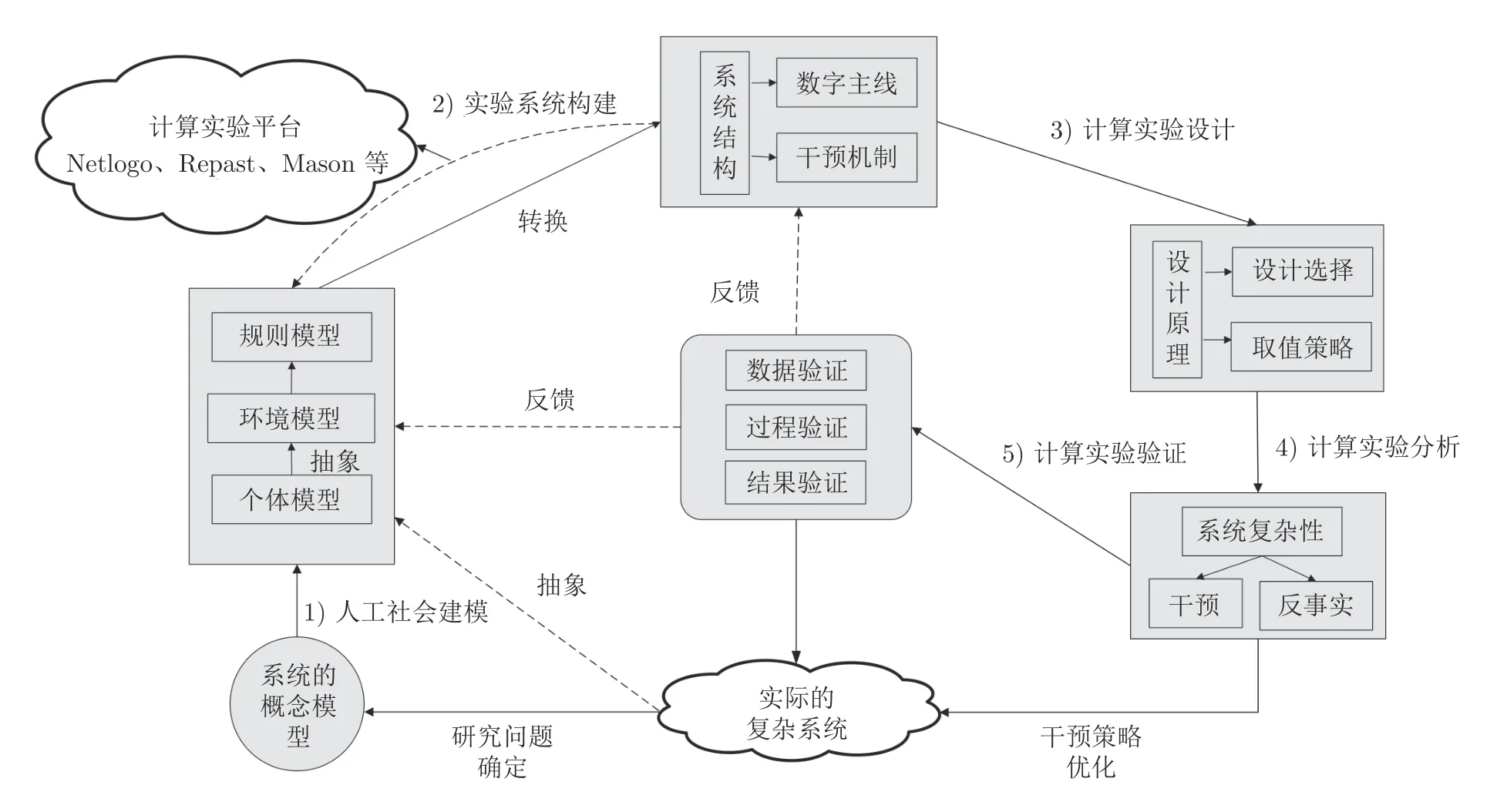
图3 计算实验方法的技术框架Fig.3 Technical framework for computational experiment methods
2.1 人工社会建模
人工社会是一种在计算机中模拟人类社会的建模方法[66].相比于一般的仿真模型,人工社会模型所描述的系统更加复杂,不仅个体行为存在着不确定性,而且个体之间还具有复杂的交互行为.在明确人工社会应具有的结构、要素和属性后,需要将所研究的复杂系统映射为信息空间中的多Agent系统,重点关注个体模型、环境模型、规则模型.个体模型是描述Agent 个体的自适应行为机制;环境模型是描述Agent 个体的社会属性;规则模型是对系统演化机制的描述.具体细节如下:
1)个体模型
人工社会中的Agent 是具有一定自主能力的个体,与现实社会的生物个体或者生物群体相对应.Agent 个体模型是不同领域知识发挥作用的容器,可以根据特定应用进行定制化,包括Agent 的结构、是否具有学习能力、交互机制等.人工社会中的个体Agent 可以采用同质型的结构,也可以采用异质型结构.如图4 所示,Agent 个体的典型结构由感知、决策、行为和优化4 个部分构成[67].
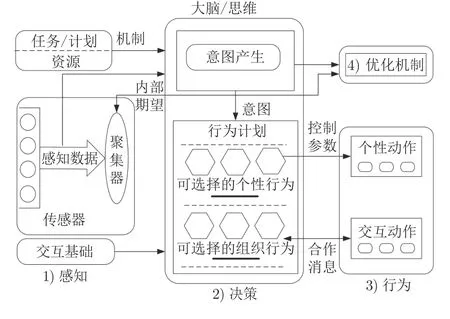
图4 Agent 的结构模型Fig.4 Structural model of individual Agent
Agent 结构中的信息控制流将各个部分联系成了一个整体.式(1)给出了Agent 结构的形式化表达式,由一组与时间t相关的属性来描述.
式中,R表示Agent 不随时间变化的特征,如标识.St表示Agent 随时间变化的特征,例如Agent 的角色.Et是Agent 感知到的、对其状态及行为可产生刺激作用的外在事件的集合.Yt是Agent 在感受外在事件刺激以及与其他Agent 进行交互过程中所采取的决策机制.Vt是Agent 的行为集合,包括Agent 自发采取的以及受外在事件刺激采取的所有行为.N是Agent 所受的约束条件,包括环境、其他Agent 以及任务目标对该Agent 的限制.
在人工社会中,Agent 个体并不是毫无意识和缺乏能动性,其学习过程是系统演化的重要动力机制.Agent 在运行过程中,会通过与环境交互不断获得解决问题的经验,从而更新自身的规则库,进而对自身的决策机制产生影响.按照个体意识(或者理性) 的强弱,可以将个体的学习模型归纳为三类: a)进化学习.强调Agent 的行为来自于父母遗传.b)强化学习.指Agent 通过与环境的不断交互学习.c)模仿学习.指Agent 模仿邻居行为更新自身.三者的共性是出于个体的角度改变规则,从而提高对外部环境的适应程度.
2)环境模型
在人工社会中,环境模型就是实际物理环境在计算机中的映射,是Agent 赖以存在的活动场所.按照建模方式,环境模型可以分为实体型建模和网格型建模.实体型建模是指将真实社会中诸如建筑物、道路交通、气候条件之类的各种环境要素都抽象成实体模型.目前,很多典型的人工社会系统都以这种方式实现,如EpiSimS[68]等.网格型建模则并不关注具体的环境对象,而是将聚焦点落在对环境空间的建模上,利用离散的网格来描述空间的存在和环境的属性,例如糖域模型[45].
由于人工社会场景规模大小不同,环境场景要素的模型粒度不尽相同.对于大场景的人工社会,环境模型的粒度相对较粗,通常采用网格型模型,例如交通网络;对于小场景的人工社会,环境模型的粒度相对较细,通常采用实体型模型,例如自然环境、建筑物和道路的细致模型.对于规模较大的人工社会场景,通常使用地理信息系统来建立地理空间模型.对于小规模的人工社会场景可采用二维或三维显示技术建立可视化场景,同时采用网格技术建立地理空间的坐标体系,以确定地理空间的相对位置(如图5 所示).

图5 环境模型的抽象层次Fig.5 The abstraction level of environment model
由于实际条件的限制,环境模型的初始设置往往只能统计特征数据.因此,需要研究人工社会初始化数据的生成算法,包括Agent 统计特征(总数、性别比例、年龄分布等)、Agent 地理分布情况、人口社会关系属性、环境实体的统计特征(总数、类型、可容纳的人口数等)、环境实体的地理分布情况等.从群体数据的统计特征恢复重构出群体中每个个体的具体特征是环境建模的基本思路.通常可以根据公布的宏观统计数据和样本数据,运用迭代比例拟合方法生成个体级的微观数据,或者根据具体情景,执行特殊的人工人口生成算法,并且需要将生成结果与真实数据进行对比统计分析和逻辑正确性分析.这个过程中,需要满足两方面的一致性: a)保证生成的Agent 数量与真实世界在统计特征上保持一致[69];b)保证生成的Agent 内部逻辑结构、关联关系与真实世界一致.
3)规则模型
规则模型描述了人工社会的循环机制,包括Agent 之间、环境之间、Agent 与环境之间 “行事处世”的准则.这些规则既可以是真实社会规则的映射,也可以是人为假设的假想规则.如图6 所示,人工社会采用自底向上的规则框架 -社会演化模型(Social learning evolution,SLE)从三个层次制定出人工社会的演化秩序: 底层是个体演化空间,用于模拟个体在社会系统中经历遗传进化的现象;中间层是组织演化空间,模拟个体通过模仿和观察学习提高自身能力;顶层是社会演化空间,用于模拟文化推动的社会系统加速演进现象,从底层汲取优秀知识所建立的社会文化,可以指导底层个体的演化[56].
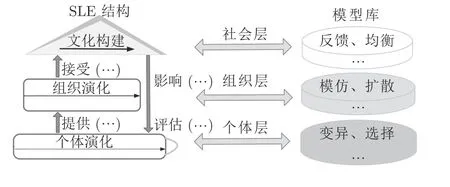
图6 社会演化模型建模框架Fig.6 SLE modeling framework
因为考虑到各层级间演化机制的相互嵌套和互为因果,这种分析框架也具有复杂系统理论的特征.SLE 的三个层次及其互动构成了人工社会演化过程较为完整且又抽象的环状分析结构.每一层次分别关注社会经济系统中的不同层面(例如个体、组织、集群和国家等).相关的建模技术可以根据特定的需求进行选择.SLE 的具体实现逻辑如算法1 所示.
算法1.SLE 的实现逻辑
Agent: 用于代表人工社会系统中的个体.
1)个体演化: 变异是多样性的生成机制,也是社会系统演化的源动力.如果没有变异和创新,就无所谓演化.在模型框架中,Agent 个体的演化规则可以根据各类进化算法进行设定.有些是模仿生物系统的进化功能而被设计出来的,例如人工神经网络[70]、遗传算法[71]、进化策略[72]等.
2)组织演化: 选择机制则是多样性减弱的机制,通过某种标准来判断个体的适应性,选择适应性高的演化单元,淘汰适应性低的演化单元.在模型框架中,组织的演化规则可以根据生物群落的演化特征进行设定.例如蚂蚁种群优化算法[37]、粒子群算法[73]、人工蜂群算法[74]等.
3)社会涌现: 组织演化侧重选择适应性高的演化单元,而社会涌现阶段侧重于其他个体对于精英的模仿学习.在激烈的竞争之后,一些精英会从个体中脱颖而出.其他个体通过模仿学习他们的行为,可以提高自己在生态系统中的生存能力,这个阶段就是社会演化阶段.存在三种典型的扩散模型: 传染病模型[75]、社会阈值模型[76]和社会学习模型[77].
4)二阶涌现: 二阶涌现体现在社会空间对个体空间的反作用,这是宏观现象对微观个体产生作用的机制.为了模拟文化可以加速个体进化速度这一现象,本文在模型框架中设计了反馈规则,通过干预策略的选择机制不仅影响某个具体个体的变异水平,还会影响整个系统的变异水平.
5)下一个循环: 随着时间的推移,一些精英可能会落后,一些能力较强的新个体将成为新的精英.最后,整个社会系统的演化均衡被打破,进入下一轮循环.
2.2 实验系统构建
计算实验系统的架构大都是基于人工社会模型,采用自底向上的方法来模拟整个社会复杂系统.首先需要真实模拟出各类智能体实体的微观行为,再通过这些个体间的相互作用来反映整个系统的宏观规律,实现由简单元素互相作用而形成的复杂现象.计算实验系统构建的重心在于如何设计数据主线来集成各个模型,为建立人工社会集成数据,从而寻找最合适的干预策略.
1)系统模块
计算实验系统的开发主要采用两种方法: a)自己编程,目的是获得更大的建模自由度;b)采用特定平台,目的是获得更高的开发效率.目前,人工社会模型开发尚处于初级阶段,开发效率的重要性高于建模自由度.研究者通常选择一种开发平台自动生成一些框架代码,然后手工编写特定功能的代码,从而减小编程工作量.如果平台是可信的,那么自动生成的代码也是可信的.目前,利用平台开发人工社会模型已成为主流趋势,包括Swarm[39]、Repast[40,77]、Mason[17]和Netlogo[42]等.
如图7 所示,人工社会的体系结构可以划分为预处理、计划执行和输出3 个模块.系统根据预处理阶段收集的Agent 状态值,虚拟环境提供的外部状态值和外部指令数据,选择知识库中的知识规则和模型库中的模型,计算并执行各类Agent 在仿真环境中的行为,并将计算结果输出到行为选择器,设置Agent 下一时刻的子目标.行为选择完成后,在行为选择结果和外部环境检测数据的基础上,利用知识库中Agent 行为经验学习规则进行Agent行为复合配置,并可以通过反馈对行为选择参数进行修正.最后,更新Agent 的内部状态值,并将行为状态信息传递给仿真模块中构建的虚拟环境,利用知识库中环境更新规则实现虚拟环境的动态更新,并进入下一个时刻的循环计算.
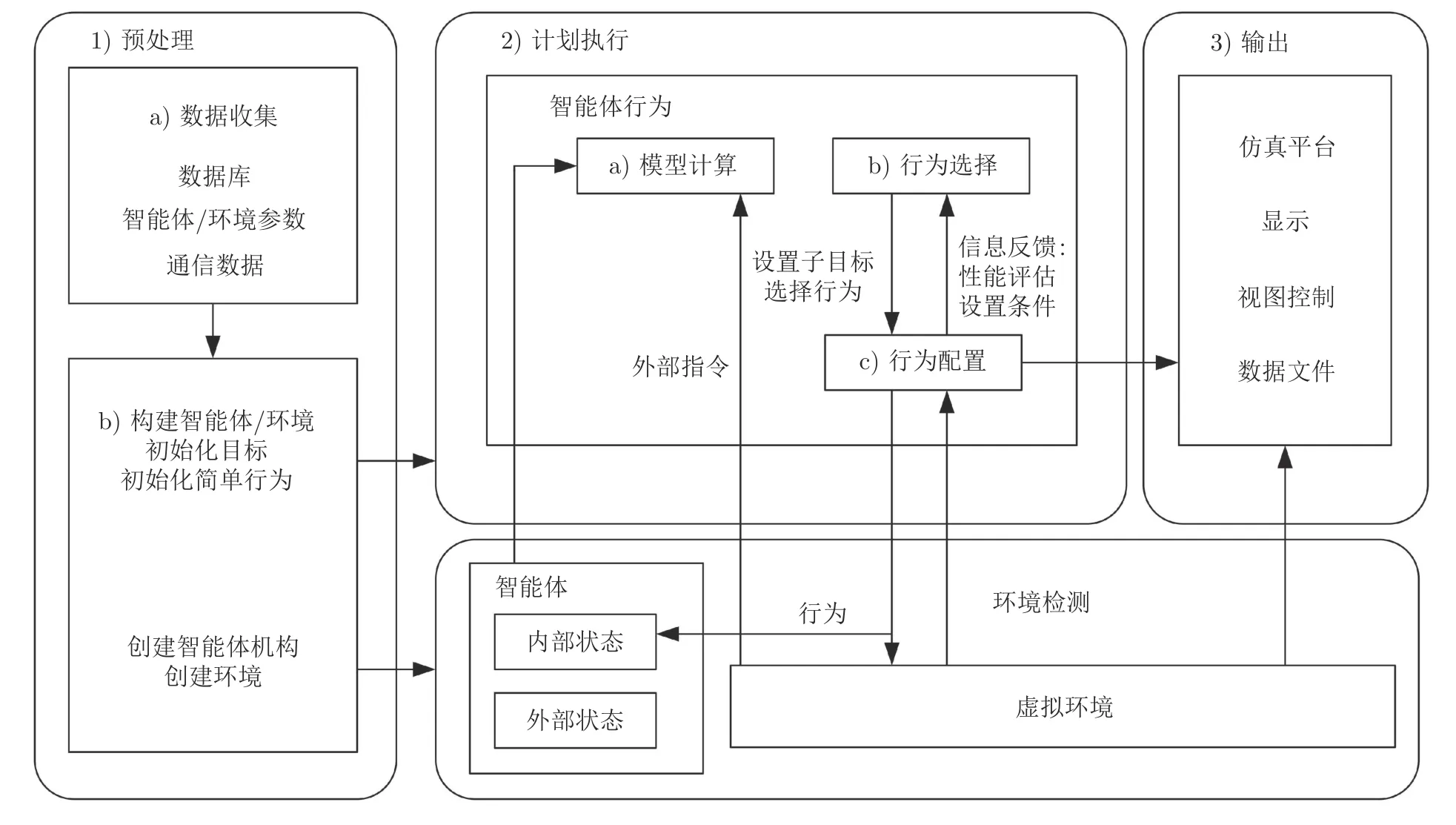
图7 计算实验系统的运行流程图Fig.7 The operation flow chart of the computational experimental system
2)数字主线
计算实验系统的构建是一个复杂的多阶段、多因素、多模型的过程.从时序角度出发,计算实验系统运行过程包括概念模型、数学逻辑模型和仿真模型等阶段,其间有相互的依赖和约束关系.在概念层,人工社会建模是将现实系统的知识进行组织和编码,使计算实验系统能接受并处理现实世界的数据输入.逻辑层的模型与概念层密切相关,该层的模型主要建立了状态变量之间的关系.在连续系统中,这种关系通常是偏微分方程或常微分方程.对于复杂系统这些方程难以得到解析,所以需要转换成可数值计算的模型.在仿真层,通过完成上层模型(逻辑层) 到底层模型(数值计算模型) 的转换工作,可以认为计算实验系统具有了对概念模型、逻辑模型进行计算的能力.
基于此,本文将工业互联网中 “数字总线”[78]的概念引入计算实验方法,用以描述从模型设计到运行的全生命周期过程,提供关键要素的虚拟表示(数字孪生) 和相互之间的关联关系.如图8 所示,数字主线可以被看作连接不同模型的桥梁,其目标在于展示出实验周期中系统的演变历史和特别的状态转换.这可以在正确的时间以正确的方式对实验现象进行向前或前后追溯,从而可以协助策略评估研究、变更影响分析、缺陷回溯分析等问题.
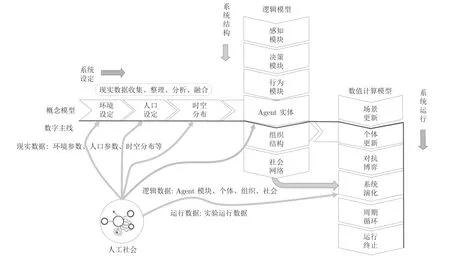
图8 计算实验的数字主线Fig.8 Digital thread for computational experiments
3)干预机制
计算实验的运行过程其实就是个体之间以及个体与环境之间博弈演化的过程,是内部因素和外部因素共同作用的结果.外部环境因素是客观的、不可控的,主要包括初始条件以及外部环境.内部因素是可控的、可调整的,主要包括个体之间的组织形式、协作策略和协调机制等.如果没有外部因素的干预,实验系统将会进行自然演化,可以用来分析初始设置与内部机制在系统演化中的作用.如果对实验系统施加外部干预,则可以用来对干预措施进行推演和优化.为了促使实验系统向预期方向演化,有必要对其实施有限度的、合理的干预.
如图9 所示,通过将干预策略和人工社会(包括所有直接和间接承受干预影响的多类主体) 连接形成闭环,并变换外部输入和人工社会模型的初始设定,来对干预策略的效果进行测试.

图9 计算实验的干预机制Fig.9 Intervention mechanism of computational experiments
根据干预尺度,干预策略可以分为3 类: a)将干预策略加载到人工社会的Agent 模型中,在仿真的过程中可能会对个体的特征、行为规则造成影响.在无人驾驶的测试实验中,往往采用真实控制器和虚拟被控对象联调,就属于此类干预[79-80].b)将干预策略加载到人工社会的组织模型中,在仿真的过程中可能会对群体的交互方式、学习规则造成影响.c)将干预策略加载到人工社会的社会模型中,在仿真的过程中可能会对社会的传播方式、均衡状态造成影响.人工社会经过反应,输出干预实施可能引致的结果,干预制定者将其目标和偏好与输出结果进行比对,可以就干预的可行性做出判断.这样经过不断地试错、迭代和完善,最终就如何干预达成共识.
2.3 实验设计
随着研究对象的复杂度增加,影响因子的组合数量会呈指数级增长,并且变量之间还可能会产生交互作用.在含有大量因子的计算实验中,如果对这些因子进行任意组合的测试和观测,会导致实验次数呈指数型增长,根本无法大规模应用.只有通过合理的实验设计,才能够以最迅速、最经济的方法,得到理想的实验结果.合理的计算实验设计主要包括设计原理、设计选择和数值生成三个方面.
1)设计原理
如图10 所示,计算实验过程通常可以视为操作、模型、方法、人以及其他资源的一种组合.把多种输入(通常是一种组合) 转变为有一个或多个可观测的响应变量的一种输出.其中x1,x2,···,xm是人工系统的输入,y1,y2,···,yn是人工系统的输出,u1,u2,···,up是可控因素或者决策,v1,v2,···,vq是不可控因素或者事件.计算实验的目的可包括以下内容: a)通过计算实验确定最能影响系统输出的因素集;b)通过计算实验确定最有效的可控因素ui,使输出结果集变得更小,且更接近理想的水平;c)通过计算实验确定最有影响的可控因素ui集,使得不可控因素或事件vi对系统的影响作用最小.
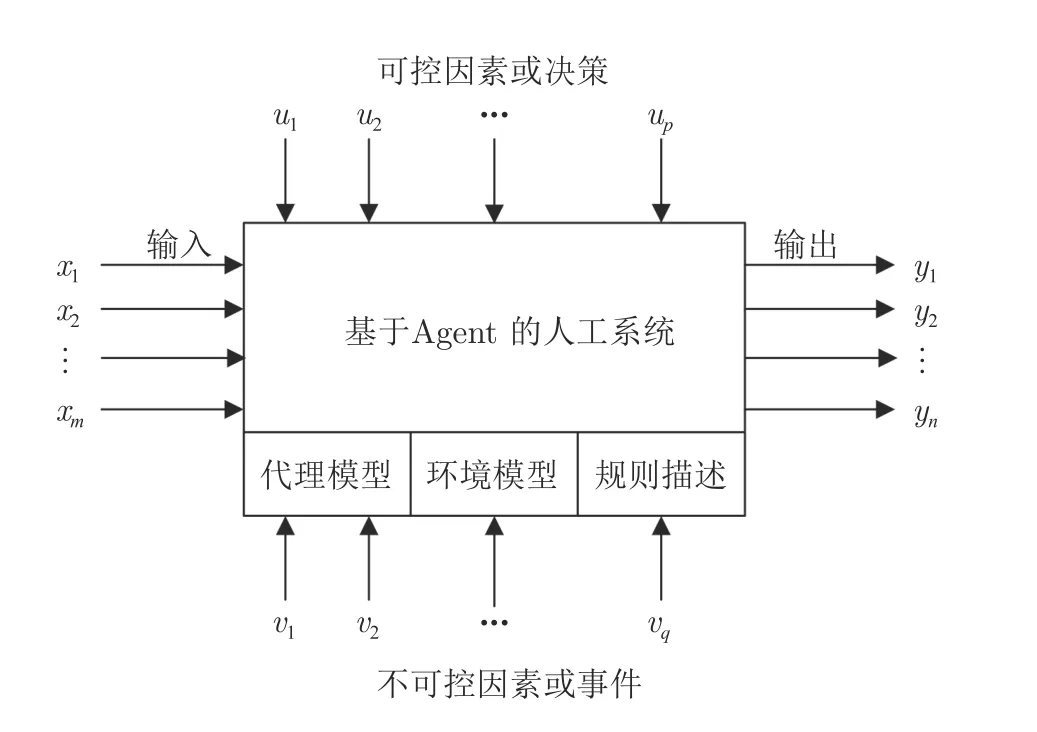
图10 计算实验设计的示意图Fig.10 Schematic diagram for computational experiment design
由于实物实验与计算实验之间的区别,许多实物实验中的假设与边界条件在计算实验中并不满足.实物实验中通常假定误差是独立同分布的,有些实验还认为实验误差满足正态分布,然而计算实验中通常不能满足这些假定.虽然使用不同的伪随机序列可以保证误差的独立性,然而同分布这一性质仍然难以保证.因此许多经典的实物实验设计方法不能直接应用于计算实验中.例如部分析因设计中需要假定因素间不存在交互效应或仅存在低阶交互效应,然而对于复杂的计算模型而言,这一假设很难满足.
为了更有效地进行实验,就必须用科学的方法进行设计.所谓实验的统计设计,就是设计实验的过程,以便收集适合于统计方法分析的数据,从而得出有效且客观的结论.如果想从数据中得出有意义的结论,那么用统计方法做实验设计是必要的.当问题涉及受实验误差影响的数据时,只有统计方法才是客观的分析方法.就计算实验而言,其实验设计同样需要遵循本领域的随机化、重复和区组化[81]这三个基本原理.
2)设计选择
每个计算实验都有多种可能的设计方案.为了选出最合适的方案,本文往往采用因果图作为组织信息的可用工具.如图11 所示,感兴趣的效应或者响应变量画在因果图的脊骨上,潜在原因或者设计因子安排在一串肋骨上.以此为基础,进行实验设计的选择,包括明确实验目的、考虑样本量(重复次数)、合适的实验次序,是否划分区组或者是否涉及其他随机化限制等.
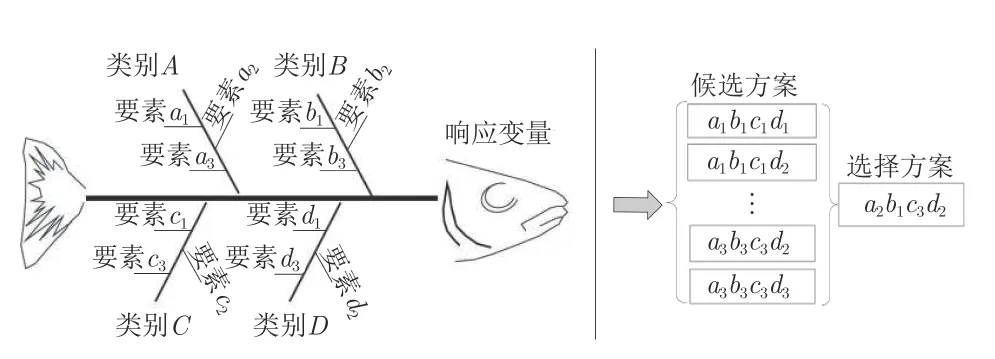
图11 计算实验的因果图Fig.11 Cause and effect diagram for computational experiments
整个方法包括如下步骤: a)问题的识别与表述.为了在设计和分析实验时使用统计方法,研究者需要预先对所研究的问题究竟是什么以及如何收集数据等有一个清晰的认识,至少要对如何分析这些数据有一个定性的了解;b)响应变量的选择.在选择响应变量时,研究者应该确信这个变量确实会对所研究的过程提供有用的信息;c) 因子的选择.明确计算实验所涉及的大量因子,包括设计因子、保持常量因子、讨厌因子;d)水平和范围的选择.一旦研究者选择了设计因子,他必须选择这些因子变化的范围及其特定水平,还必须考虑如何将这些因子控制在所希望的数值上以及如何测量这些数值.
如果交互作用存在,处理多个因子的正确方法是进行析因实验[81].这种实验策略是所有因子一起变化,而不是一次变一个.假定只考虑2 个因子,且每个因子有两个水平,经过 22轮析因实验,就可以帮助实验者研究每个因子的个体效应并判定因子是否存在交互作用.一般地,如果有k个因子,每个因子有两个水平,那么析因实验就要进行 2k轮.析因设计的重要特点就是可以高效率利用实验数据.一般而言,如果有 4~5 个甚至更多的因子,通常没必要对所有可能的因子水平组合进行试验.分式析因实验是基本析因设计的变形,只需要对所有组合的一个子集进行实验.
3)取值策略
在含有大量因子的计算实验中,场景变量通过交叉组合可以得到成百上千种细分场景,所需的实验次数呈指数型增长,有限的时间和成本显然不可能完全覆盖所有的场景.所以,本文需要采用一定的取值策略,一方面降低单次验证的成本,另一方面提高试错的效率.
对于已知各类影响因子取值范围的情况,经常采用的取值策略是模型无关的实验取值方法.这种取值策略并不针对某一种特定的元模型,而是关注由标准实验输入定义的k维单位立方体构成的设计空间.主要的模型无关设计包括拉丁超立方设计[82]与均匀设计[83].对于现实数据缺乏的情况,计算实验通过模拟仿真来生成数据集.图12 总结了这些方法的分支以及关联关系[84],主要包括重采样和蒙特卡洛两类数据生成方法.
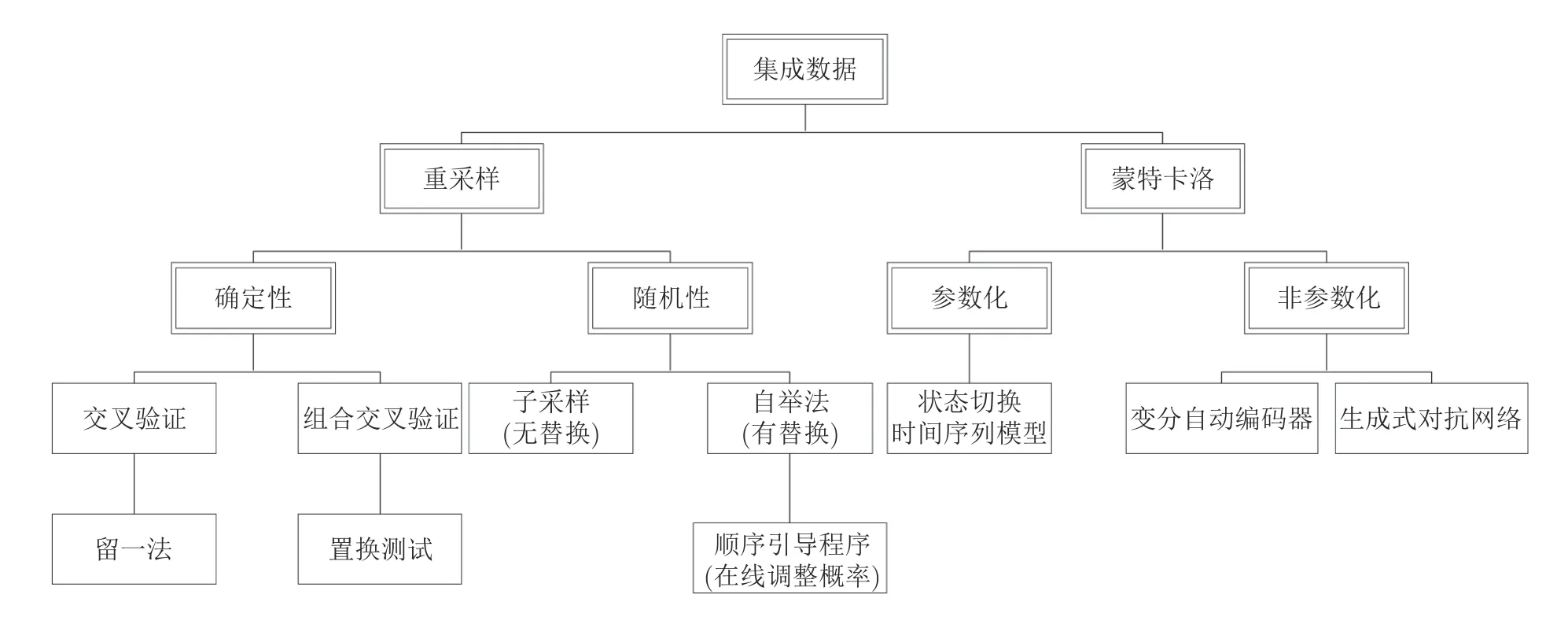
图12 计算实验的数据集产生方法[84]Fig.12 Dataset generation methods for computational experiments[84]
如果已经有了一定时间周期内的历史数据,可以以此为基础进行取值.但是,这些数据往往是有限的,而且很容易出现过拟合,为了应对这种情况,重采样技术被广泛应用.重采样是指通过对观察到的数据集重复采样来生成新的(未观察到的)数据集.重采样可以是确定性的,也可以是随机的.确定性重采样的实例包括交叉验证法(留一法)和混合验证法(置换测试).随机重采样的实例包括无替换的随机采样(子采样)和有替换的随机采样(自举法).
针对那些有概率分布或概率密度函数的变量,可以用蒙特卡洛方法,构建一系列样本集,使得满足各种概率条件.蒙特卡洛实验可以是参数化的,也可以是非参数化的.参数化方法可以将已观察数据集的统计属性,复制到未观察到的数据集中.但是,参数化蒙特卡洛的一个缺陷是,数据生成过程可能比一组有限代数函数的复制过程更为复杂.在这种情况下,非参数蒙特卡洛实验可能会有所帮助,例如变分自动编码器、自组织图或生成式对抗网络[65].
2.4 实验分析
在计算实验中,可以同时设立多组对照试验,有目的地对人工社会的参数做出改变,或者施加特定的干预措施,并在必要时进行多次大量的重复模拟,从而根据实验数据挖掘出复杂现象背后的深层次原因.一般而言,计算实验可以从宏观分析、中观分析与微观分析三个层面进行实验分析,三者互为补充,相辅相成.“宏观分析”是从宏观角度出发,以动态网络为手段来分析系统的复杂性;“中观分析”则采用事件链来追溯寻找事件发生的原因;“微观分析”更强调微观个体采取某种行为的内在机理,通过对微观行为的分析来解释或预测宏观现象.
1)宏观分析(自上而下)
如图13 所示,为了挖掘出社会复杂系统的运行演化规律,宏观层面以动态网络分析为手段,遵循如下步骤: 驱动力→运行→状态→溯源→响应[85].首先,本文需要了解系统的运行驱动力与演化机制,并通过数据分析及时发现系统运行的当前状态.然后,通过机理分析,快速识别和处理关键环节,进而不断优化系统的运行和治理.

图13 计算实验的宏观分析Fig.13 Macro analysis of computational experiments
a)驱动力.社会复杂系统的宏观分析,首先需要确定其演化的驱动力是什么.一般而言,系统持续演化取决于自上而下的设计与自下而上的涌现共同作用.一方面,新的主体涌现,或者现有主体的优化升级,并不是把原有系统进行简单的改变,而是通过自生长、自组织演化出新的模式.外部干预则是对这个演化过程起到加速或者阻碍的作用.
b)运行.社会复杂系统本质上是一个社会-技术系统,可以用多层异质网络进行描述,包括社会网络、信息网络以及价值网络.社会网络表示系统中主体间的交互关系,包括需求侧、供应侧、运营侧及其群体间的交互关系.信息网络是指所有可用信息服务构成的网络,核心是具有丰富物理社会信息的服务以及服务间的交互关系.价值网络则是联系社会网络与服务网络的桥梁,表示主体之间通过服务的提供与消费所形成的价值流转过程,类似于自然生态系统中的能量循环过程[86-88].
c)状态.社会复杂系统结合了复杂系统的自组织特征和生态系统的协同进化特征,以及经济系统的价值驱动特征.因此,社会复杂系统的度量与评估,需要从 “生态系统-经济系统-复杂网络”三个维度进行.生态特性主要研究系统中主体之间通过交互作用形成的生态位,采用指标包括多样性、层次性等.网络特性主要用于对比分析不同系统的基本结构与相互作用[89-91],采用的指标包括网络规模、路径长度、结构空洞、健壮性、可靠性等.经济特性决定了社会系统是否可持续发展,包括竞争模式、公平性、有效性、外部性、风险/安全、信用、偏好等.
d)溯源.社会复杂系统演化过程的影响因素纷繁复杂且难以确认,而且还会受到人的自由意志和主观能动性影响,有的时候还会因为偶发事件而改变演化路径.为了揭示隐藏在这些现象背后的原因,本文需要从因果决定性、目的趋向性和随机偶然性三个方面开展研究.因果决定性在很大程度上取决于隐含在社会系统演化背后的必然规律(例如网络传播).即使这些规律本文可能目前并未意识到.目的趋向性则体现了社会演化中人的自由意志与有限理性,这会造成系统不断调整自身的演化方向、策略和结构.随机偶然性是量变行为积累的结果,例如单个节点变化等带来的网络涌现.
e)干预.社会复杂系统的演化可能会出现不同的趋势,既有可能发生由低级到高级,由简单到复杂的进化;也有可能出现由高级到低级,由复杂到简单的退化.为了促使系统实现健康发展,有必要对其演化实施有限度的、合理的干预[92].其目标遵循控制论的基本逻辑,即基于感知系统获取的信息来揭示实际成效与标准之间的差,并采取纠正措施,通过循环反馈使系统稳定在预定的目标状态.对关键节点施加引导,就成为一种可选的治理机制.针对增量节点,可以基于生态位识别实现诱导机制,鼓励新的服务参与竞争,填补空白[93].针对存量节点,可以基于社会效用评价来实现节点更替机制,推动节点自主改进,实现优胜劣汰[94-95].
2)中观分析(联系宏观和微观)
中观分析的基本观点是承认事件未来的结果和实现这种未来结果的途径都是不确定的,重点在于预测未来可能发生的情景,以便研究人员对可能情景进行有效应对[96].其实质是完成对事物所有可能未来发展态势的描述,包括三部分内容: a)描述事件发生和发展过程,分析事件发展的动力学行为;b)在复杂的 “事件群”中,通过归纳与梳理,整理出若干要素和事件链;c)获得这一过程中所体现出的时间情景之间所蕴含的动态性和关联性,建立同类事件的逻辑结构.传统情景分析的手段主要是靠人工想象和推理,而计算实验方法可以构建出事件发生、发展、转化和演变的 “可视化场景”.从情景的发展和演化规律出发,可以描述如下:
式中,Tr表示情景启动的触发条件;Des是对情景的简要语言描述;Actor是情景中涉及的参与人员;In是从外界环境得到的数据或者条件,随着外界环境变化而改变;Action是情景启动后执行的行为或动作;Out是情景行为执行过程中产生的数据;ES是发生异常情况时的替代情景.根据式(2)所构建的备选场景能够涵盖不确定性对系统的影响,建立起人工社会演化过程与多个主体行动及相互作用的关联关系.
在影响因子的作用下,情景之间的转换概率会受到影响,情景之间可能产生选择性关联转变.图14模型提供了关于Simon 理论的一阶表征,主要结果为Ω 空间内的各种情景均可通过条件组合产生.在某些初始时间点r0,在特定环境中发生了事件E.在后续时间点r1,为了应对当前环境的挑战,个体可根据有限理性决定是否发生适应性改变,即事件D.如果它们并未做出改变的决定(即事件~D),则结果为E.如果它们决定适应,则可选择是否实际执行决策和落实适应性措施(即事件A).如果它们未能成功执行事件(即事件~A),则会产生结果E.可论证E≈E*.如果个体已经采取了某些行为,则在r3时刻,行为反馈可能有效,也可能无效.若反馈有效(事件W),则结果为C且具有更高的复杂度.若反馈无效(事件~W),则结果为失败后仍需忍受环境影响(结果E**).可论证S(E**)>S(E),其中S(X) 代表与事件X有关的影响或无效性.
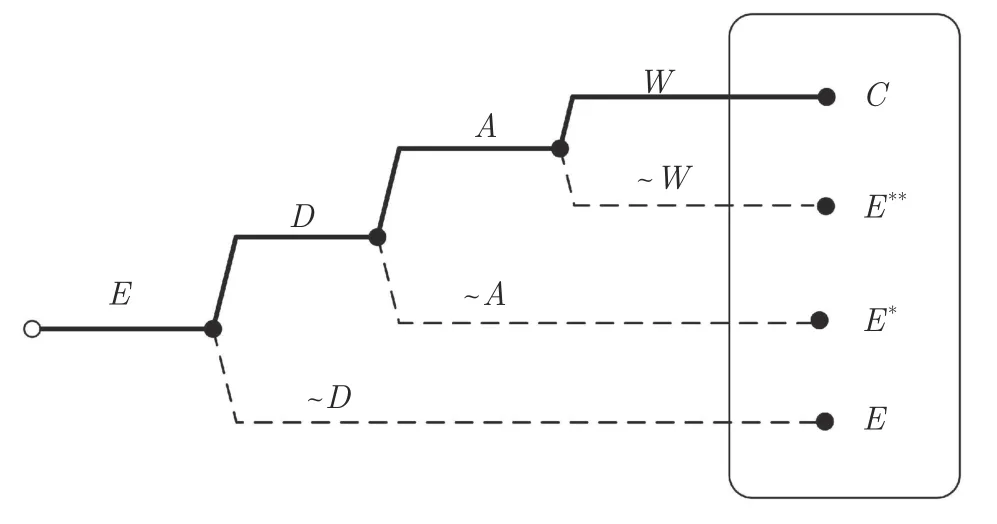
图14 情景出现的顺序因果逻辑树Fig.14 Sequential causal logic trees of system scenario emergence
在顺序逻辑模式[97]下,系统情景C的出现被解释为经过多项博弈的分支过程P,是样本空间Ω 内的一种结果,即可能事件之一.由图14 可以看出,情景C的出现最少需要4 种必要的顺序状况,具有显著的低概率.其他结果(E、E*和E**) 发生概率相对较高.在条件逻辑模式下,可根据当前情景来研究背景状况,提供必要或充分条件进行解释.通常,情景C的出现可能有2 种情况: 或者基于必要事件的同时出现(事件X1,X2,X3,···,XN通过AND连接);或者基于任意一充分事件的发生(事件Z1,Z2,Z3,···,ZM,通过 O R 连接).
3)微观分析(自下而上)
整个社会复杂系统的演化过程最终是多个主体行动及相互作用后涌现的结果.“主体分析技术”主要是从个体层面来分析现象背后的成因,包括模型拟合与机制分析[98].
“模型拟合分析”是通过构建能与最终结果拟合的微观个体行为模型来解释从干预前的情景1 到干预后的情景2 (图15 箭头1)).这类分析首先从海量Agent 行为数据中挖掘出Agent 行为模式(图15 箭头2));然后基于智能模型(神经网络、遗传算法、群体智能、强化学习等) 实现Agent 行为自学习(归纳-概率模型)和演化(演绎-规则模型);进而使用这种演进的Agent 行为规律解释或预测情景2 (图15 箭头3)).这种行为分析方法假定源头情景1 与预测情景2 之间由简单的Agent 行为作为中介,即两个现象间的行为链条是可以通过智能模型代替的.但是,这种分析是以统计学为基础的,智能模型产生的行为规律本身在现实中可能并不存在;即使存在,也无法表述从情景1 到情景2的 “因果”关系.
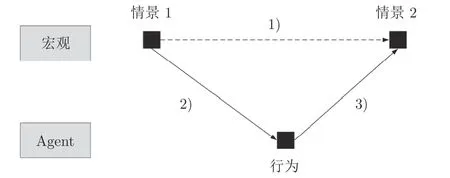
图15 基于模型拟合的分析模型[98]Fig.15 Analysis model based on model fitting[98]
在计算实验中,“行为机制分析”是指分析主体行为的生成规则和主体间行为的互动规则,以及涌现出特定宏观结果的内在机理.如图16 所示,基于行为机制的分析是解析因果链条的过程,解析的重点是主体,从主体的行为取向入手: a)首先分析情景1 对主体行为取向的某些影响,包括信念、愿望和意图等属性[99],即分析情景1 与行为取向之间的因果链条(图16 箭头2));b)然后,解析主体的这些行为取向与其他主体和政策环境之间的作用机制,即主体行为的生成机制,形成主体行为规则(图16 箭头3));c)这些规则将表现为主体的行为,进而涌现出情景2 的推演结果(图16 箭头4)).

图16 基于行为机制的分析模型[98]Fig.16 Analysis model based on behavior mechanism[98]
基于行为机制的分析是宏观现象间的 “因果”关系分析,是对从宏观现象到微观行为再到宏观现象的 “影响-作用-涌现”机制的解析.这类分析不同于通过模型拟合来追求宏观现象间的重合率,而是真正切入了人工社会演化过程的每个环节,还原了干预作用的机制.因此,机制分析是计算实验的核心.为进一步量化两个节点之间的因果关系,可以用概率因果模型[100]来形式化定义相关操作.
2.5 实验验证
实验验证是从计算实验的应用目标出发,考查实验系统在其应用域内是否准确地映射了原型系统.为了增强实验的置信度,就必须提供一种可信的证明来确保模型假设代表了系统真实规律.高的置信度是计算实验得以施展作用的基础.只有在实验验证方面取得突破,计算实验方法才会成为社会经济领域的主流方法,与其他方法取长补短,成为理解复杂系统运行规律的有力工具.目前,研究者们已经提出了各种各样可用于计算实验的有效性验证方法[101].如图17 所示,按照计算实验的运行流程,实验验证可以分为结构验证、数据验证和结果验证3 个部分.

图17 实验验证的分类Fig.17 Classification of experiment validation
1)结构验证
系统模型是对真实系统的抽象,经过编程实现得到可实际执行的计算模型.结构验证是对模型构建的过程进行验证,使模型能够反映真实系统的内部构造特征,保证假设产生模型行为的中间过程是正确的,即保证假设模型是产生行为结果的充分条件.计算实验系统构建过程包括系统模型设计和计算模型实现两个步骤,因此结构验证也包含了系统模型验证和计算模型验证两个方面.
a)系统模型验证
这个阶段主要检查系统模型与研究目的、给定的假设、已有的理论和证据是否保持一致,确定模型的简化处理不会严重影响模型的可信性和对真实系统重要特征的认识,同时系统模型要满足内在完整性、一致性和正确性.模型合理性判断主要采用专家判断、理论比较、实证数据拟合3 种方法,往往是定性的而不是严格证明的.通过与现有其他模型的比较和借鉴,研究者可以极大提高系统模型的验证程度,包括: i)说明模型的适用范围和缺陷;ii)主流理论采用了相同假设,或者其他研究者做过的类似研究和采用的相同假设;iii)开发和分析一组具有相同核心假设,但具有不同附加假设的模型;iv)可以建立与原有Agent 模型行为具有类似特征的方程模型.
b)计算模型验证
这个阶段主要检查算法、编码、运行条件等是否与系统模型一致.系统模型通过编程转变成特定计算机系统可以运行的计算模型,此过程涉及因素繁多,容易产生不易觉察的错误.由于Agent 模型是离散模型,同时各种编程语言和计算机系统存在显著的差别,编程的细节对模型结果具有重要影响.目前计算模型验证采用的方法主要有: i)代码级检查,判断计算模型与概念模型的一致性;ii)在不同计算机上,采用不同的操作系统,不同的伪随机数发生器运行相同代码并进行比较;iii)利用不同的编程语言实现系统模型并进行比较;iv)测试计算模型在极值情况下的行为[101].无论哪种情况都涉及代码检查,从原理上说,代码检查可以发现所有的编程错误.
2) 数据验证
在计算实验中,通常把 “模型假设+模型参数=模型行为”作为研究的先验条件.模型构建,实际上相当于提出了一种假设,并认为这种假设代表了真实系统的规律.通过执行计算实验,观察模型行为结果,来对真实系统做出因果解释.输入数据的质量好坏将直接影响计算实验的最终结果,糟糕的数据输入甚至导致与实际情况相去甚远.想要构建一个有效的实验系统,首先需要在源头上保证数据的可用性.不少研究者[102-103]注意到了数据可用性的问题,包括一致性、精确性、完整性、时效性和实体同一性等性质.针对计算实验而言,需要着重考虑如下因素:
a)可信度.数据收集过程其实是根据命题采集数据的人为过程,所以从开始就带有倾向性,操作过程中也无法保证完全真实.既然没有绝对的 “真实”,那么严格遵循科学原则、主观性较少的数据是更接近 “真实”的,是可信的.一般而言,政府和权威机构的数据可信度较高.
b)数据量大小.在统计学中,样本容量的大小与推断估计的准确性有着直接的联系.在总体既定的情况下,样本容量越大其统计估计量的代表性误差就越小;反之,样本容量越小其估计误差就越大.在估计模型参数时,对于同一个总体(如同一地区)而言,数据量更大可以减少随机误差出现的概率和代表性不足的问题.
c)时效性.复杂系统的运行是一个动态过程,数据趋势可能会随着情景设置和外部干预的变化而出现剧烈波动.因此,数据的时效性是影响实验结果的重要因素,尤其是对于某些时效性较强的项目而言.然而,有一个不可避免的问题是收集数据需要一定的时间,数据的获取具有滞后性.尤其是在某些突发的应急事件初期,数据延迟的问题非常突出.对于计算模型而言,选用越临近当前、更新越及时的数据,实验效果越好.
d)相关性.很多情况下,数据资源中没有想要研究的数据,或者与研究问题相关的直接数据非常欠缺.于是研究者会寻找替代变量来进行研究,那么替代变量与直接变量的相关性大小,将对实验结果产生影响.
3)结果验证
结果验证主要用于评价实验结果是否与真实系统行为相一致.真实数据可以从现实世界采集而来,而模型输出的数据是由设定的模型运行机制产生.将模型产生的数据与真实数据对比,以推断是否可以 “恰当地”反映现实,从而达到结果验证的目的.但是,计算实验经过有限次运行得到的仅仅是总体中的有限样本,并且模型行为是不稳定的、参数敏感的.因此,在与真实系统行为比较时,计算实验的结果验证会面临以下问题:
问题1.如何应对参数组合爆炸与敏感性分析?众多的模型参数会导致组合爆炸,即使结果与真实数据一致,也难以确定产生最终结果的决定性影响因素.同时模型结果往往不稳定,受到初始条件的影响很大.目前研究者基本上采取两种方法缩小参数空间.第1 种方法是在建模开始,通过已有的数据、事实、相应的模型与理论,以及专家经验和知识来缩小参数空间.这种方法可以充分利用已有知识,但容易引入未加验证的先验信息.第2 种方法是先给出一种先验空间,在模型建立并运行后,通过灵敏度分析找出敏感参数,从而缩小参数空间.这种思路通常采用实验设计、统计学方法和蒙特卡洛方法等,结果具有很强的说服力,但很多情况下实施非常困难.这两种思路经常结合使用,分别从两个方向进行空间缩减.
问题2.如何比较实验输出与实证数据是否一致? 实验运行的结果是一个分布,而真实世界的数据只是一个样本,难以用一个样本来检验一个分布.实验的输出在何种程度上可以认为与真实数据是“一致的”,目前主要还是通过主观确认,并辅助一些简单的拟合度统计描述,其结果很大程度上受制于分析人员的主观意识.这种判断不仅要考虑模型输出一致性,还必须考虑输入输出的一致性,即需要对模型先进行校准研究,然后才能考虑结果的一致性[101].目前历史数据法提供了一个可行的解决方法,这是实验验证未来的一个研究热点.
问题3.如何验证现实中没有发生过的结果?通常情况下,实验验证是利用已有的经验数据进行推论.但有的时候,计算实验的结果可能并未在现实世界中产生过.在这种情况下,需要充分利用领域知识,去探寻产生这种现象的原因是什么,是否是现实世界中一种可能的发展趋势,以此来判断该实验是否有效.其结果很大程度上受到分析人员所熟悉的知识范围与问题分析能力制约.
近年来,普遍采用的结果验证方法包括间接标定方法[104]、Werker-Brenner 方法[105]和历史数据法[106],但目前没有一个公认的方法和流程能够完全解决上述所有问题.因此现在主流的观点认为计算实验验证最好同时与其他实证方法(如案例研究、格式化特征分析、角色扮演博弈和受控实验等)同时使用,才能取得好的效果.
3 应用案例
计算实验作为一种新的科学研究方法,其应用范围大致可以分为现象解释、趋势预测与策略优化三个方面.本节将分别给出这三个方面的一些经典案例,以帮助读者加深对计算实验方法的理解.
3.1 现象解释
现象解释,并不是针对特定的情景或者特定真实社会系统进行建模,而是追求描述一般社会系统的抽象逻辑关系,希望通过实验来探索和量化分析某些假设对人类社会所造成的难以预料的结果.其优势在于为验证人们所提出的各种假想提供了手段,但这类研究规避了实际社会到人工社会的映射问题,所能给出的往往是隐喻、启示和定性趋势,而不是复杂问题的精确回答.
1)糖域模型
1996 年,Epstein 等[45]提出了 “人造社会”模型SugarScape,可以进行经济学和其他社会科学的相关实验.如图18 所示,SugarScape 模型是一个由方格构成的封闭世界.圆点表示Agent,仅仅能在这个世界中游走;染色部分表示社会财富 -糖,且深浅表示糖的分布浓度.每个Agent 包含视力范围r、资源的新陈代谢率v和拥有糖的数量s三个属性.Agents 按照以下规则游走: a)对视力范围r内的所有单元格进行观察,并确定含糖量最大的单元格;b)如果拥有最大含糖量的单元格不止一个,则就近选择;c)移动到这个方格;d)收集该单元格的糖并对相应状态变量进行更新.

图18 SugarScape 中糖和Agent 的分布Fig.18 Distribution of sugar and Agent in SugarScape
随着实验的进行,一些Agent 可能由于个人能力出众、所处位置的资源分布优势等,能够获得较多的糖;而缺少糖的Agent 会凋零死亡,导致大部分Agent 都逐渐聚集到糖含量比较高的两个区域.最终,少数Agent 拥有大量的糖,而多数Agent 仅仅拥有少量的糖,这就验证了社会学中著名的马太效应.进一步,通过向SugarScape 人工社会中添加多种资源(例如香料).以此来研究真实社会中个体间如何通过资源交换形成市场.此外,本文还可以通过改变Agent 所遵循的不同规则,来研究环境变迁、遗传继承、贸易往来、市场机制等社会现象.
2)谢林模型
谢林模型也叫谢林隔离模型,由美国经济学家Schelling[58]提出,该模型描述的是同质性对于空间隔离的影响与作用,揭示了种族和收入隔离背后的原理.该模型包含产生行为的Agent、Agent 遵循的行为规则以及Agent 行为所导致的宏观结果三个元素.如图19 所示,实验中将整个城市看作一块巨大的棋盘,棋盘上每一个小格子允许Agent 居住或空闲.其中存在2 种Agent,数量大致相等,大约10%的网格为空.每个Agent 都有一个最低的宽容度阈值,一旦发现同类邻居数量低于阈值,则会迁移至未被占领的且满足其居住要求的位置.Agent的行为规则为: a)计算周围同类邻居的数量;b)如果邻居数量大于等于其偏好值,则Agent 认为满意,停止运动;否则继续运动;c) Agent 会查找满足其偏好值且与其距离最近的闲置网格,移动至此处.

图19 基于谢林模型的种族隔离实验Fig.19 The segregation experiments based on the Schelling model
随着时间的推移,不同种类Agent 之间的隔离程度最终会呈现出非常明显的状态.通过改变实验设定,例如Agent 寿命值、闲置空间等,可以发现,改变宽容度阈值并不足以避免产生种族隔离,因为几乎每个Agent 均追求所有邻居与其种类相同.该现象引发本文关于社会问题的思考: 种族主义达到何种程度会将整个社会变为此类隔离模式?
如何能够逆转种族隔离的状况? 研究者们对这类模型进行了扩展,并应用于不同地区的种族冲突研究中,获得了较好的结果[107-108].
3) RebeLand 模型
乔治梅森大学的Cioffi 等[17]提出了MASON RebeLand 模型,用于分析内部(内生)或外部(外生)过程(例如经济变化、人口、文化、自然环境等)如何影响政体的稳定性.RebeLand 表示一个位于自然环境中的政体或国家,由一个被水包围的岛屿组成,以忽略与其他邻近国家的互动.RebeLand 的环境由地形和简单的天气系统组成,可以模拟气候动态变化(例如长期干旱、气候多变等).
如图20 所示,RebeLand 的地图显示其主要的自然和社会特征.国家用岛屿形状表示,自然资源用三角形表示,叛军和政府军用椭圆形状表示,道路和省的边界用折线段分割,岛屿被海洋包围.RebeLand 政治组成部分包括一个社会系统和一个通过公共政策处理事务的政府系统.最初,政府制定政策以解决影响社会的问题.在实验的后期,在某些条件下,社会还可以产生与政府军互动的叛乱分子以及其他涌现现象.

图20 MASON RebeLand 模型Fig.20 MASON RebeLand model
这项研究演示了稳定、不稳定和失败3 种政治状态.为了测试一个政体的总体弹性,通常不仅需要执行一个或几个压力测试,还需要进行大量的测试条件组合(例如通货膨胀、叛乱与环境压力同时爆发).这些结果可能不会立即得到针对特定议题的可行政策建议,但至少可以为研究人员和政策分析师提供新的、有价值的见解.这类研究还常被用于选举预测和应用政治学[109].
3.2 趋势预测
计算实验的趋势预测是面向真实社会系统建模,强调人工社会系统和真实社会系统之间的高度匹配,期望解决现有社会中确实存在或者可能存在的问题.这类应用往往会遇到真实社会映射到人工社会的有效性验证问题.当前研究者主要希望通过先进的数据获取和处理技术来解决,从而使实验结果能够预测真实的趋势.其优势在于可以利用较为抽象的模型对现实策略进行评估,但是预测结果是否准确非常依赖于现实数据是否充分以及模型抽象程度是否合适,并且也无法实现对策略的优化.
1)人工股市
股票市场显然是一个复杂系统,多种组成要素和层次结构使股市整体表现出复杂性与难预测性.为了证明和理解投资者怎样做出资产组合选择,Arthur 等[46]提出了 “人工股市”模型,用一种全新的观点来理解经济系统中的复杂性.这个模型摒弃了完全理性、全知全能的 “经济人”假设,取而代之的是能够学习和适应环境的有限理性人,把经济系统看成是由若干相互作用的个体进行交互的复杂系统.在这个虚拟市场中,若干交易Agent 通过观察数字世界中股价和股息的不断变换而做出预测,并且根据这些预测做出是否购买股票以及购买数量的决策,以使自己效用最大化.所有Agent 都独立形成自身的期望,并具有学习能力,可以根据以前预测的成败进行决策调整.反过来,所有交易者的决策又决定了需求与供给相互竞争的状态,进而决定股票的价格.
如图21 所示,整个股票交易市场就构成了一个自我封闭的计算系统.模型运行时间是离散的,实验可无限进行下去.人工股票市场提供了一个很好的现实股市的隐喻,可以用于检验不同预期最终是否会演化为相同的理性预期以支持有效市场理论.在主体层次和组织层次上会出现更加复杂的行为,可以支持实际投资者的观点并解释金融市场的实际现象.随后,不少研究者对人工股票市场模型进行了改进,以期进行更深层次的分析,例如将微观投资行为与宏观股市动态联系起来、价格限制的有效性等[59,110-111].

图21 Agent 与股市相互作用结构Fig.21 The interaction structure of Agent and stock market
2) O2O 服务
移动互联网商业模式近些年获得了飞速发展,其速度已经远远超出了人们的想象.O2O 模式已经成为许多传统行业升级改造的典型商业模式,涉足餐饮、旅游、医疗、交通、生活服务等诸多领域.互联网已经对人们的生活习惯产生了极大的影响,也给传统产业的运营模式带来了挑战.对于互联网是否能颠覆传统产业的运营模式,或者说互联网在多大程度上能改变传统模式,人们所持观点截然对立.针对该问题,文献[112]以供需匹配理论为基础,提出了 “服务桥”方法,以评估互联网的跨界影响力,包括供给侧能力模型、需求侧特征模型和服务桥模型这三个主要部分.
如图22 所示,模型中的河流象征着供给侧和需求侧之间的障碍;左边表示需求方主体,右边表示供给方主体;服务桥表示将供给方和需求方联系起来的渠道,用于描述不同运营模式的能力.在计算实验系统中,供应侧Agent 的属性主要包括市场能力(如客户推广、用户画像、服务推荐、基础设施等)和供应链能力(如物流能力、制造技术、支付手段等)两类.需求侧Agent 的属性则包括多种因素:消费能力、消费者偏好、区域特征、价格因素、时间因素(接收时间、交货时间等)、品质因素和信用因素等.通过对供给侧和需求侧的要素组合,可以定制出所需要的各类竞争场景,从而分析互联网模式与传统模式之间的优劣.文献[112]采用该模型对零售业、金融业、制造业和医疗行业进行了行之有效的分析,并给出了相应的趋势预测.
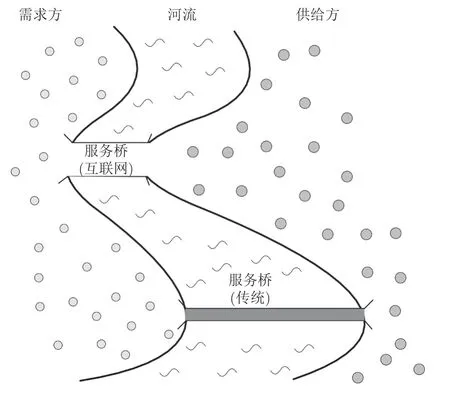
图22 服务桥模型Fig.22 Service bridge model
3)流行病预测
随着SARS、H1N1、新冠疫情等突发传染病的流行,传染病的传播模型成为了研究热点.但是,传染病传播是一个动态的不确定过程,不仅影响因素众多,而且存在很多未知领域与突发事件,使得预测研究极为困难.计算实验采用人工社会模型实现基础数据、模型方法及分析结果的综合集成,主要涉及三个方面: 疫情态势的生成(例如初始感染人数、接触率、传播速率、病毒潜伏期、死亡率、康复概率等)、空间地理特征的表示(例如城市类型、交通网络、人口密度、气温、天气、不同年龄段人口比例、城市基础设施等)、资源和管治能力的建模(例如医疗资源、病床数量、社会组织、防控措施、信息透明度等).表2 对几种传染病相关的模拟系统进行了特征比较,不同的系统在实现方式、表示方法和准确性程度方面各有特点.
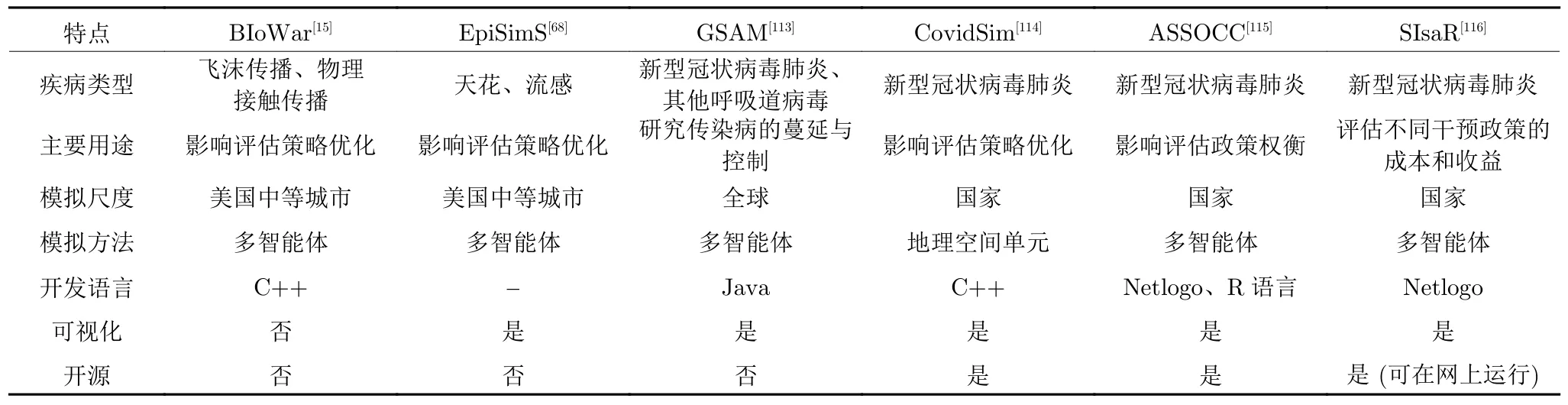
表2 典型的大规模流行病传播模拟系统特征对比Table 2 Comparison of characteristics of typical large-scale epidemic spread simulation systems
目前,计算实验已经成为研究流行病大规模传播的一种重要手段,主要应用在3 个方面: a)传播趋势预判.发达的交通系统使得重大流行病更容易形成大规模的传播,在疫情尚未到达某一区域时,对其传播趋势的分析与判断是应急准备的重要前提;b)影响预评估.疫情在区域内的爆发和传播,会对人口健康产生直接危害,还会对社会经济环境产生次生影响,定量评估其影响是应急储备、干预决策的重要依据;c)干预策略优化.重大流行病应急防控的干预措施多种多样,每种干预措施都有不同的干预对象和干预强度.在实践过程中,如何选择合理的干预措施及其强度,形成组合干预策略,既能控制住疫情,又能减少干预的代价,是应急决策的重要难题.
3.3 策略优化
科学研究的目的在于提供一种能将已有事实联系在一起的因果关系假设.如果所构建的人工社会模型代表了这种规律,那么该模型的输出行为就能对现实世界产生有效作用.其优势在于建立与现实社会具有同态关系的人工社会模型,通过二者的并行执行与循环反馈,可以支持对现实复杂系统的管理与控制.其缺陷是需要从现实环境实时获取数据以实现对人工社会模型的校准,现实中这点往往难以实现,即使能获得数据,也会存在资金和工作量过大的问题.
1)虚拟淘宝
淘宝网作为国内最大的零售平台之一,商品搜索是其核心业务.淘宝的业务目标是通过策略来优化向客户所展示的页面从而增加销售量.由于客户的反馈信号取决于页面序列,商品搜索引擎和客户互为彼此的环境.强化学习解决方案擅长学习顺序决策并最大化长期回报.但是,直接应用强化学习的一个主要障碍是,当前的强化学习算法通常需要与环境进行大量交互,需要很高的成本,例如资金、时间、糟糕的用户体验等.
为了降低成本,研究人员使用模拟器(即虚拟淘宝) 进行强化学习训练,然后在模拟器中对页面策略实现离线训练[117].虚拟淘宝中的客户和客户间的交互都是生成的,如图23 所示,模拟分布的生成对抗网络用于模拟各种客户,以及他们的需求;多智能体对抗性模仿学习被用于生成交互.实验结果表明,虚拟淘宝展现出的属性非常接近于真实环境性.虚拟淘宝可用于训练平台策略以最大程度地提高收入.与传统的监督学习方法相比,在虚拟淘宝中训练的策略在实际环境中实现了2%以上的收入提升.
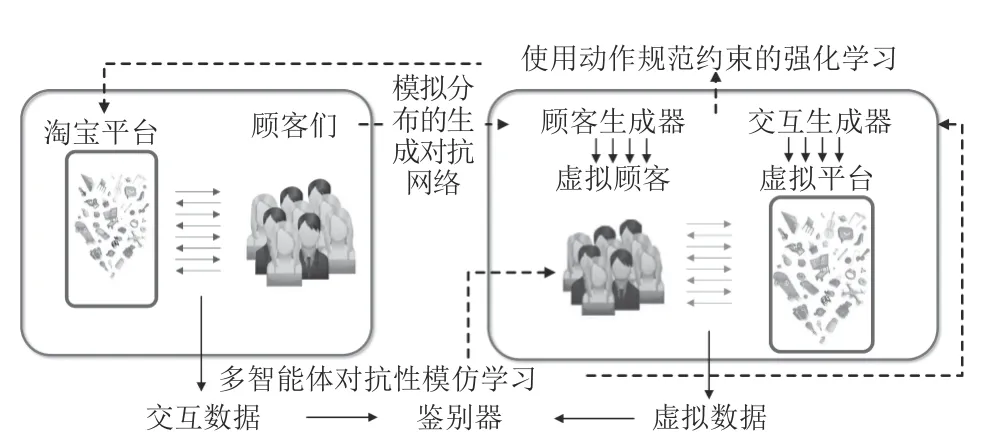
图23 使用强化学习的虚拟淘宝架构Fig.23 The architecture of virtual Taobao using reinforcement learning
2)小岛经济
经济不平等正在全球范围内愈演愈烈,并且因其对经济机会、健康和社会福利的负面影响而备受瞩目.对于政府来说,可以使用税收政策来改善社会福利.但是,由于税收和劳动力之间存在耦合关系,高税收可能会降低生产率.因此,如何在降低经济不平等的同时保持生产率仍是一个亟待解决的问题.由于缺乏适当的经济数据和进行实验的机会,在实践中很难对这类经济问题进行研究.为此,Zheng 等[118]提出了一项名为 “The AI Economist”的新研究,通过人工智能体进行经济模拟,用以发掘能够在经济平等和生产率之间高效寻找平衡点的税收策略.其中的市民和税收策略都具有学习和适应功能,形成了一个两级强化学习框架.如图24 所示,“The AI Economist”的核心实现框架是市民和税收策略的博弈演化机制,即如何使用强化学习实现智能体行为和税收策略的共同优化.
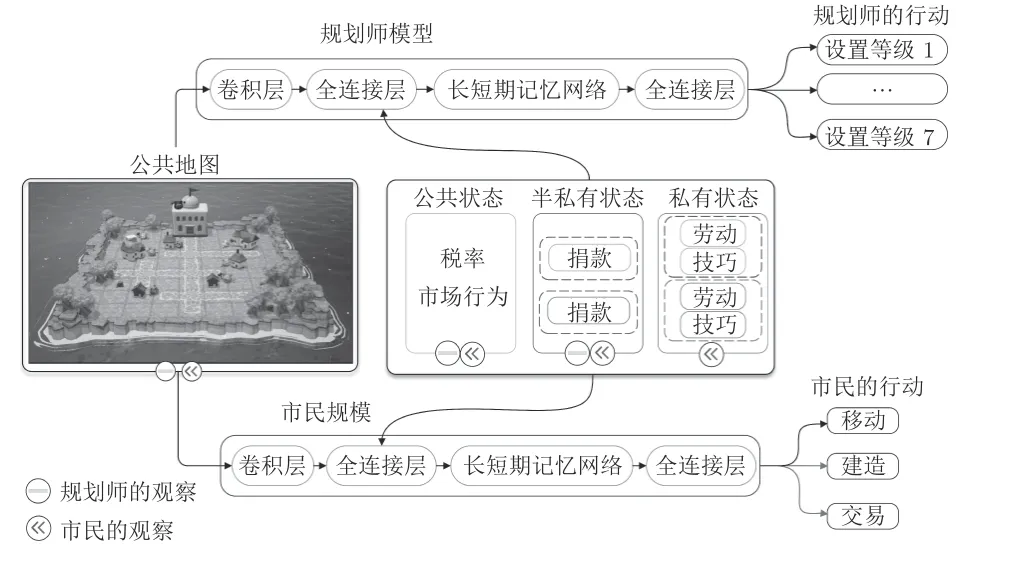
图24 小岛经济Fig.24 Small island economy
研究者将 “The AI Economist”的运行结果与自由市场(不征税或再分配)、模拟的美国联邦税收计划以及由Saez 框架产生的税收策略[119]进行了比较.实验表明,与Peter 等[119]提出的税收框架相比,“The AI Economist”可以将经济平等与生产率之间的权衡提高16%.该框架不使用先验知识或建模假设,能够直接针对任何社会经济目标进行优化,并且仅从可观察的数据中学习.开发者希望 “The AI Economist”能够解决传统经济研究无法轻易处理的复杂性问题,可以客观评估政策对现实经济的影响.
3)无人驾驶
无人驾驶需要测试和验证无人车对复杂交通场景的理解和行驶决策的能力,是人工智能领域面临的重大挑战之一.但是,现实测试场景(例如暴雪、暴雨、台风等极端场景) 的搭建极具挑战性,并且其创建、复制和迭代的成本很高,这几乎是不可能完成的.因此,在虚拟世界中对无人驾驶策略的训练与测试就成为一种可行的技术选择,不仅可控、可重复,而且安全有效.为了在虚拟世界中看到与现实世界无限接近的自动驾驶测试,需要实现三种层次的还原: a)几何还原.需要做到三维场景仿真和传感器仿真,让环境和测试车辆条件都与现实世界相同;b)逻辑还原.要在虚拟世界中模拟出测试车辆的决策规划过程;c)物理还原.需要模拟出车辆的操控和车身动力学作用结果.同时,仿真平台还要满足高并发的特点,实现所有场景下各种车辆反应的排列组合.目前,平行学习方法越来越多地应用于虚拟场景生成和无人驾驶车辆的智能测试中[10-11,79-80].
如图25 所示,腾讯在模拟仿真平台、高精地图平台和数据云平台的基础之上,构建了一个运行在云端,与现实物理世界平行的虚拟城市.城市仿真不仅包含静态的环境信息,也包含交通、人流等动态信息,既可支撑自动驾驶的开发和安全验证,还可为智慧城市、智能交通的建设助力.为了提升路采数据的利用率及测试场景的丰富性,可以利用大量路采数据训练交通流Agent AI,生成真实度高、交互性强的交通场景,进行闭环仿真,提高测试效率、降低采集成本.例如被测试的自动驾驶主车想要超车,可以借由Agent AI 来控制仿真系统中的车辆做出与真实世界一致的避让或其他博弈行为.

图25 腾讯TAD Sim 仿真系统场景演示Fig.25 The scene demonstration of Tencent TAD Sim simulation system
4 问题与挑战
计算实验已成为人们认识和研究社会复杂系统的重要途径.但相对于其日益广泛的应用,计算实验作为一种方法论和技术还没有完全成熟.因此,为了进入研究者的主流工具箱,计算实验方法必须解决以下3 个问题: 1) 如何利用大数据定义人工社会,即描述智能;2)如何利用计算实验预测未来,即预测智能;3)如何实现对现实世界的反馈干预,即引导智能.
4.1 问题1.如何实现描述智能?
通过对真实社会系统中的复杂行为和复杂现象进行抽象和简化,使之成为能够在计算机平台上运行的、满足逻辑合理性的、正确性的人工社会模型,是进行计算实验的基础.目前的人工社会建模主要有2 种手段: 1)基于数据的模型构建方法.将复杂系统视为黑箱,关注输入和输出之间的关系,并不对系统内部复杂的过程进行建模和模拟.在实际应用中,复杂系统往往会被替代为基于数据和智能算法的统计模型,包括图神经网络、支持向量机和模糊方法等.2)基于机理的模型构建方法.从整体角度对实际中的复杂系统进行认识、理解和剖析,遵循 “简单一致”原则,设计并还原系统各个部分的结构和功能.在按照自下而上原则构建计算模型的过程中,底层微观模型的准确度和复杂度对整个复杂系统的演化发挥着至关重要的作用.
但是,复杂系统要素多样、变化频繁、关系耦合、多层次运行,信息传递和交互作用复杂.传统的机理建模受制于当时的认知能力,往往难以精确描述复杂系统的运行和演化机制;数据驱动的建模由于缺乏过程单元内部结构和机理信息,严重依赖于数据样本的数量和质量,难以对系统机理进行深层次的分析和解释.因此,如何针对社会复杂系统构建人工社会模型,就成为这个领域里非常有前景的研究问题之一.机理分析有利于抓住系统的本质特征和主要矛盾,获得有效的模型结构;数据驱动的方法则可以自动获取潜藏在数据中的信息和知识.综合二者的优点,将描述个体行为的规则模型与统计模型相耦合,建立融合系统机理分析和大数据的混合模型,不仅降低了对数据的依赖性,而且弥补了传统模型难以模拟个体行为规则的不足.未来这类模型将有很大的发展空间,可用于更具真实感行为的虚拟人工社会模型构建.
最后需要注意的是,由于Agent 模型自由度大,缺乏标准化的核心模型,容易过度推广夸大自己的成果,这很容易招致批评.因此,在对复杂系统进行渐进式建模的过程中,有几点需要注意: 1)有必要确定一个简单的初始模型,足以理清模型的全部细节,同时包含了参照系统最终模型的核心要素.2)设计模型的序列并不是随意的,必须为完成最终模型提供递进式的帮助.3)在整个开发过程中,模型验证是有必要的,但需要适度.因为中间阶段的模型尚不成熟,可能由于缺乏足够的实证支持而被否决.4)确定参照系统的最终模型是必要的,否则模型的改进会无限期延续下去.
4.2 问题2.如何实现预测智能?
在复杂系统中,从主体的自主性,到主体所处的环境,再到对主体行为进行干预的过程,各个环节都充满了由个体行为所引发的高度不确定性,进而导致在智能预测中伴随着由不确定性引发的复杂性.大数据技术主要是基于对历史数据的分析,更像是对事实的一个总结归纳,对于从未发生过的不确定事件,就显得无能为力.因此,如何针对复杂系统做出准确的路径预测是计算实验所要解决的基本问题.
人工社会可以在虚拟世界中对现实世界的问题进行精确描述、并使之可控,进而产生海量的复杂系统模拟运行数据.计算实验通过推演现实中各种从未发生过的场景,可以发现系统运行中的问题和薄弱环节,并找出原因,提出符合实际的问题解决方案或建议.对应于Pearl 等[5]的三层因果关系(关联、干预和反事实推理),实验分析方法包括动态网络分析、事件链分析以及行为机制分析等.动态网络分析主要关注个体在时间和空间上的相互作用,尤其是异质网络间的循环反馈.事件链分析可以用于梳理影响因素与最终场景之间的关系,确定某种可能情景的发生概率.行为机制分析则可以设计各种反事实实验,用于对现象背后的因果关系进行追根溯源.
以 “决策剧场”为代表的公共政策仿真很好地体现了这种思路[120],通过 “如果这样,后果会如何”的设问式场景呈现,可以对不同政策产生的后果进行反事实推理.其具体工作流程如下: 1)对于需要解决的问题,收集其相关的大量历史数据,并按照不同的维度进行整理;2)由政府决策人员和专家共同合作,建立问题模型,再运用计算实验将抽象的专家知识转化为大众群体可接受的场景语言;3)将模拟现实的仿真决策场景三维可视化,为政策制定者提供多个政策场景及其结果预演;4)在协商一致的群体决策环境下,各个利益群体为政策问题选择一个共同满意的解决方案.美国亚利桑那州立大学有关凤凰城水资源利用是一个典型的应用案例[121].
4.3 问题3.如何实现引导智能?
在复杂系统中,个体活动日趋复杂、多样、差异化,而干预方式往往是简单、统一、平均的集中式控制.考虑外部环境的动态性和不确定性,干预策略的介入势必会导致某些个体会根据周围环境发生自适应改变,进而导致初始干预策略的失效.因此,干预策略的设计并非是一个毕其功于一役的任务,而是需要不断根据外部环境的变化而进行调整和优化.计算实验可以打通虚拟世界与现实世界的藩篱,通过反事实推理来剔除不可行的策略,将优化过的策略迁移到真实空间中指导真实系统的运行.
在计算实验中,引导智能主要通过平行优化来实现,其核心就在于从现实中实时动态获取数据,实现人工社会与现实社会的同步校准.在实验系统中,可以创造出在当前真实世界中难以重现的极端场景.然后,结合运筹学关于不确定、多目标条件下的优化理论,对干预策略进行不断地训练修正,以期获得预期的优化效果.这是以未来视角干预当前的发展轨迹和运行状态,发现策略可能产生的不良影响、矛盾冲突和潜在危险等,为应对可能情况提供 “借鉴”、“预估”和 “引导”.基于这个层面的理解,各类机器学习的主流技术(包括但不限于强化学习、深度学习等)均可用于实现干预策略的调整优化,从而实现引导智能.
最终,计算实验和实际系统之间可以构成一个相互协作的共生的动态反馈控制系统.首先,通过分析数据与行为的依赖关系,将真实世界中的问题抽象到认知空间;然后,在认知空间中建立模型、进行计算实验,得到的结果可以动态地指导或控制真实世界中的策略执行;接着,通过干预策略与现实世界之间的博弈过程,来探索平行系统间差异最大的动作空间,达到降低人工系统建模误差和干预策略执行误差的目的;最后,真实世界执行结果反过来以动态数据输入的形式,不断更新认知空间的模型,形成了一个循环反馈的学习过程.系统以这种虚实互动、平行执行的方式不断迭代,直至收敛.在不断融入越来越多数据的过程中,人工社会的训练和模拟会变得更加真实准确,并通过与现实世界的交互反馈而具有自生长、自优化的能力.
5 结束语
在科学研究中,归纳是在实证数据中发现模式,广泛用于观点调查和宏观规律分析;而演绎则是定义一套公理,并证明由这些公理所能推导出的结论.与归纳、演绎这两种标准方法对比,计算实验可以看作是进行科学研究的第3 种方法.如同演绎一样,它起始于定义一套清晰的假设;但与演绎不同的是,它并不证明定理.计算实验产生模拟数据,这些数据可以用归纳的方法进行分析;但是又和典型的归纳法不同,模拟数据来自于规则运行产生的涌现,而不是对真实世界的直接测量.归纳旨在从数据中发现模式,演绎希望发现假设的结果,而计算实验则是通过虚拟世界中的系统推演、试错和预估,来验证本文的直觉.
本文对计算实验方法的现状与挑战进行了总结,包括计算实验的概念起源、方法框架、应用案例以及技术挑战.计算实验的方法框架主要介绍了人工社会建模、实验系统构建、实验设计、实验分析和实验验证.计算实验的应用案例主要从现象解释、趋势预测与策略优化3 个方面进行了介绍,涉及到政治、经济、商业、流行病传播、无人驾驶训练等诸多领域.计算实验的技术挑战主要关注本领域需要持续研究的核心问题,包括描述智能、预测智能与引导智能.
计算实验的提出为复杂系统的分析与研究提供了新的思路,尽管相关研究已经取得了很大进步,但是在实验设计、实验分析与实验验证等方面还存在很多问题与挑战.例如计算实验结果是否与已知系统规律相匹配(正确性);计算模型的表示形式是否优雅,包括规则式、句法结构以及相似特征等方面(简洁性);计算实验分析是否能够对改造现实世界发挥作用(有效性)等.
本质上,计算实验旨在解决基于现实参照系统所定义的一个或多个研究问题.一般来说,计算实验的表现形式比较简单,而实际系统的运行比较复杂.如果计算系统抽象程度过高,就难以反映现实世界的运行规律.如果计算系统的抽象程度过低,建立模型的复杂度就会很高,会遇到数据缺乏、资源和时间不足、知识体系尚未建立等一系列问题.因此,计算实验方法的发展需要不断在建模灵活性与结论可信性之间寻求平衡,设计更加通用的实验设计与分析方法,为复杂系统的分析、设计、管理、控制和综合等问题提供新的且有效的计算理论和方法.
