数据与技术双轮驱动的生物医学信息学发展与展望
2023-03-04范少萍张志强
范少萍,张志强
1.中国医学科学院医学信息研究所,北京 100020
2.中国科学院成都文献情报中心,四川 成都 610041
3.中国科学院大学经济与管理学院,图书情报与档案系,北京 100049
1 引言
生物医学信息学(Biomedical Informatics)是计算机科学与生命科学和医学的综合性交叉学科,是研究和探讨分子生物学、临床医学和健康数据采集、处理、储存、分发、分析、解释和可视化等在内的内容可拓展性、数据密集型学科,综合运用了生物学、医学、计算机科学、信息学等多种理论与技术[1-2],是发展最快的专业信息学学科之一。
随着数据密集型科学研究范式的发展与强化,以及生物医学领域科学大数据的加速积累与面向生命健康和生物安全的知识发现研究的科研创新需求的驱动,生物医学信息学正在经历前所未有的高速发展阶段。应对和防控世纪性新冠肺炎疫情的巨大现实需求更是加速了生物医学信息学的发展。生物医学信息学在疫情防控中起到重要的信息与技术支撑作用,欧洲核酸档案(European Nucleotide Archive,ENA)[3]、NCBI 基因数据库[4]、PubChem[5]、Drug Bank[6]等生物医学信息学数据库/工具在新冠肺炎下一代测序数据分析、基因组学研究等方面提供了强大数据支撑。生物医学信息学工具和技术的迅速研发,助力科研人员解释新冠病毒基因组结构及遗传差异[7]。一些涉及下一代测序[8]、全基因组关联[9]、计算机辅助药物设计[10]等研究已有效地应用于新冠病毒医学研究中,并以多种方式发现了有关新冠病毒的新信息[11],为早日战胜病毒提供科学支持和赢得时间。
为掌握生物医学信息学发展现状,了解研究领域与最新进展动态,明晰学科未来发展路径与重点,本文主要梳理了生物医学信息学理论体系、学科发展与最新进展,深入分析生物医学信息学的机遇与挑战,展望未来发展路径,以期为我国生物医学信息学学科完善与发展提供借鉴与参考。
2 生物医学信息学理论
生物医学信息学是信息技术向医疗领域的延伸,也是医学信息化、标准化的必然趋势。随着组学技术、信息技术、计算机技术等不断发展,生物医学信息学的重要性愈加突出,其研究成果(如梅奥诊所开发的NLPaaS 平台[12])不仅为医患双方沟通提供了便利,也为从海量实验数据与文献信息中发现新知识提供了强大工具。作为一门独立的、快速发展的新兴前沿学科,生物医学信息学已逐步形成其独特的学科理论框架。
2.1 生物医学信息学学科框架
2.1.1 生物医学信息学学科概念与范畴
20世纪60年代起,从事生物医学计算的研究人员就通过访问某些计算机系统开展相关工作,但一直未出现明确术语确定其概念与内涵。“生物医学信息学”一词随着1990年启动的人类基因组计划(Human Genome Project,HGP)开始出现,是由于对基础生物学数据分析问题的扩展调查导致研究人员更加意识到所谓的“医学信息学”的方法和过程广泛适用于所有生物医学。
20世纪90年代后期,美国国立卫生研究院(National Institutes of Health,NIH) 主任Harold Varmus 任命了生物医学计算工作组,该工作组在1999年提交报告,建议NIH 发表“生物医学信息科学和技术倡议”(Biomedical Information Science and Technology Initiative,BISTI)。2012年数据与信息学工作组发起了“大数据到知识倡议”(Big Data to Knowledge,BD2K),两份倡议大力支持生物医学和医疗保健领域数据科学和计算的发展。此后,各项活动逐步开展,推动信息学从医疗保健和生物医学研究的外围转移到中心位置[13]。越来越多的科学研究机构改变其学术单位的名称,取代医学信息学这一术语,以支持生物医学信息学。当然,并非所有机构都改变其名称,如美国医学信息学协会(American Medical Informatics Association,AMIA)等仍使用医学信息学术语[14]。
AMIA 在2001-2002年开始研究生物医学信息学概念、角色和能力。经广泛审议后认为,生物医学信息学是一门跨学科领域,以改善人类健康为驱动力,研究如何有效利用生物医学数据、信息和知识进行科学探究、解决问题和辅助决策。AMIA 对生物医学信息学学科范围、理论方法等内容进行界定,如表1所示[14]。

表1 生物医学信息学学科范围、理论方法等界定[14]Table 1 Definition of discipline scope,theory and method of Biomedical Informatics [14]
图1展示了生物医学信息学与其主要应用和实践领域之间的关系。通过健康信息学(Health informatics)解决个体和人群研究,通过生物信息学和结构信息学(Bioinformatics and structural(imaging) informatics)解决分子、细胞和器官系统相关研究。最近出现的转化生物信息学(Translational bioinformatics)在寻求基因组和细胞机制解释和预测临床现象时将生物信息学、结构信息学和临床信息学联系起来,处理和分析数据,以支持临床试验和人群研究[14]。
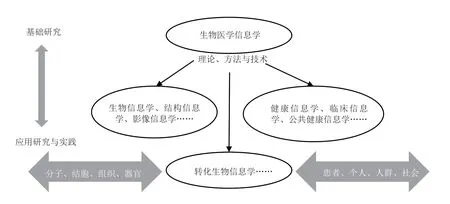
图1 生物医学信息学及其应用和实践领域[14]Fig.1 Biomedical Informatics and its application and practice[14]
2.1.2 生物医学信息学与相关学科关系
生物医学信息学是建立在计算机科学、信息科学与技术基础之上的,并为其发展做出贡献。此外该学科还有许多其他学科组成,包括统计学、认知科学、管理学、决策科学等,相关学科关系如图2所示[14]。

图2 生物医学信息学与相关学科关系[14]Fig.2 Relationship between Biomedical Informatics and related disciplines[14]
生物医学信息学最具影响力的应用是在文献情报与信息学领域。如生物医学文献检索系统MEDLINE、PubMed,统一医学语言系统(Unified Medical Language System,UMLS),各种生物医学本体、词表等,使得通过计算机挖掘生物医学数据成为可能,极大促成了生物医学领域知识发现研究与实践。通信与工程科学为生物医学数据交流与交互提供了便利条件。如远程医疗、可穿戴设备等的发展,使得偏远地区、慢病患者等的救治与健康管理变得更加便捷可行。认知科学和社会科学在生物医学信息学领域的研究与应用主要是对于认知及其在智能计算中的探索。如对医学文本理解的研究、知识编码、知识推理、基于计算机的临床指南对治疗决策制订的影响[15]。在序列相似性分析、基因表达分析、基因转录调控网络分析、序列结构与模式识别分析[16]等研究中,数学与统计学方法得到广泛应用。在医学影像、模拟建模等研究中,生物与物理科学发挥了独特的交叉学科优势,进一步解释生物的物理学特性。
随着语义网络、人工智能、自然语言处理、计算机视觉等领域的飞速发展,必将为生物医学信息学研究提供强大工具手段。
2.2 生物医学信息学学科发展
为全面掌握生物医学信息学学科进展与发展趋势,梳理本学科的主要研究内容,利用医学信息学、生物医学信息学等直接相关概念在Web of Science 核心合集检索2000-2021年相关文献,开展文献计量分析以量化说明。检索时间为2022年1月11日,共检索得到94,955 篇相关文献。
2.2.1 生物医学信息学学科发文量近年快速上升
自2000年起,生物医学信息学学科文献量逐年加速上升(图3),特别是2020年初新冠肺炎疫情全球爆发和大流行以来,发文量上升趋势更加明显。说明学科呈现出强劲发展趋势,且在大数据与大医学的时代背景下,显示出巨大发展潜力。

图3 生物医学信息学学科发文趋势图Fig.3 The trend of Biomedical Informatics research literatures
2.2.2 中国生物医学信息学发文量全球第一
我国生物医学信息学相关研究发文量全球第一(图4),其次是美国和英国等发达国家。“十三五”以来,我国高度重视人民生命健康,《“健康中国2030”规划纲要》中提出要推进健康医疗大数据应用;《国务院办公厅关于促进“互联网+医疗健康”发展的意见》中提到要推进“互联网+”人工智能应用服务,并完善“互联网+医疗健康”支撑体系。上述政策文件的发布实施,为生物医学信息学的发展提供了良好的政策环境,加之我国科技领域创新不断,相关产出层出不穷,客观上推动了学科发展。

图4 生物医学信息学学科研究主要国家分布图Fig.4 Major countries in Biomedical Informatics research
2.2.3 学科方向主要集中于重大疾病与数据库/工具研发
由于文献量较大,筛选791 篇高被引文献进行生物医学信息学热点研究主题分析,结果如表2和图5所示。主要分为4 类研究主题:癌症研究的生物医学信息学,组学数据库等资源研究,分析工具/软件研究,算法与模型研究。可以看出,癌症是生物医学信息学主要关注的疾病领域,数据资源、分析工具/软件以及算法/模型是生物医学信息学的主要且热点研究内容。

图5 生物医学信息学高被引文献关键词聚类图Fig.5 Keywords clustering of highly cited literatures in Biomedical Informatics

表2 生物医学信息学高被引文献主要关键词Table 2 Keywords of highly cited literatures in Biomedical Informatics
3 生物医学信息学最新进展
本节主要从大数据资源体系建设、数据分析算法与模型、数据分析工具与软件3 个方面介绍生物医学信息学的最新进展。
3.1 生物医学大数据资源体系建设
领域大数据是生物医学信息学研究的核心,生物医学领域数据库众多,发展迅速,有力地支撑了相关研究的深入开展。依据数据的来源、内容和性质等,可将数据库分为若干类別[17]。以各类组学内容为主体的数据库,比如核酸数据库,不仅包括粗数据(如档案类等),还包括整理后的数据(如人类基因组注释参照数据库和变异数据库等);蛋白质数据库包括蛋白质结构、相互作用网络等数据;代谢产物层面也有代谢产物、代谢酶与通路等数据库。药物研发方面有药靶和化合物数据库。另外,文献数据、临床诊断数据、健康大数据等也有各自的来源和特征。Nucleic Acids Research 和Genomics Proteomics & Bioinformatics 等专业期刊定期对相关数据库进行统计和介绍。例如,Nucleic Acids Research 的2022年第1 期“数据库特刊”中介绍到,NAR 在线分子数据库集合达1,645 个,过去一年中更新了317 个数据库,新增了89 个数据库[18]。
3.1.1 美国
美国国家生物技术信息中心(National Center for Biotechnology Information,NCBI)拥有35 个数据库,共包含约36 亿条记录,每个数据库都支持使用简单的布尔查询进行搜索,可以单独或批量下载。截至2021年9月4日,单核苷酸多态性数据库(dbSNP)累计记录数达10 亿之多,年增长率接近50%;存储生物医学文献的PubMed 数据库累计记录数为3,300 万,年增长率约5%[19]。
3.1.2 欧洲
欧洲生物信息学研究所(European Molecular Biology Laboratory-European Bioinformatics Institute,EMBL-EBI)拥有40 多个开放数据资源,涵盖分子生物学的所有数据类型,到2020年底,EMBL-EBI原始数据存储量已超过390PB。全球研究人员不断向EMBL-EBI 提供数据,基因组序列数据(European Nucleotide Archive)、受控访问的人类基因组和表型数据(European Genome-phenome Archive)、质谱数据(PRoteomics Identification DatabasE)、功能基因组数据(ArrayExpress)、代谢组学数据(MetaboLights)、大分子结构数据(PDBe)、电子冷冻显微镜和生物成像数据(EMDB、BioImage Archive 和 EMPIAR)近年来持续增长[20],如图6所示。

图6 EMBL-EBI 服务的数据增长(按数据类型),Y 轴为对数刻度[20]Fig.6 Data growth of EMBL-EBI services by data type.Y axis in logarithmic scale [20]
3.1.3 日本
日本DNA 数据库(DNA Data Bank of Japan,DDBJ)是由日本国家遗传学研究所的生物信息和DDBJ 中心建立的核苷酸序列公共数据库。2020年,DDBJ 接受了6,836 份注释核苷酸序列提交,其中59.3%由日本的研究团队提交。2021年6月DDBJ共包含2,830,321,188 个序列和15,093,100,107,909 个碱基对。此外,DDBJ 中心运营高通量测序数据的公共数据库——DDBJ 序列读取档案(DDBJ Sequence Read Archive,DRA),截至2021年8月25日,DRA以SRA(10.7PB)和FASTQ(1.3PB)格式分发了12.0PB 的测序数据。功能基因组学数据的公共数据库——基因组表达档案(Genomic Expression Archive,GEA),截至2021年8月25日,GEA 在ftp 站点提供了88 个实验。2020年10月,DDBJ 中心与EBI的MetaboLights 合作推出了一个新的公共存储库MetaboBank,用于存储代谢组学数据,截至2021年8月25日,MetaboBank 发布了98 个项目[21]。
3.1.4 中国
由中国科学院北京基因组研究所(暨国家生物信息中心)、中国科学院生物物理研究所、上海营养与健康研究所等共同建设的国家基因组科学数据中心(National Genomics Data Center,NGDC)于2019年正式成立,致力于通过大数据归档、管理、集成和分析,提供一套数据库资源的开放访问,从而加速生命和健康科学的进步。NGDC 包含了健康与疾病、文献与教育、生物多样性与生物合成等9大类资源的多个数据库。例如,CancerSCEM 是癌症单细胞表达图谱的开放存取数据库。在当前版本中,整合了来自20 种人类癌症类型的208 个样本的总共638,341 个高质量细胞。CompoDynamics 是综合数据库,包含24,995 个物种、34,562 个基因组、1,692,647 个基因,以及118,689,747 条开放读码框序列。BioProject 和BioSample 分别是生物研究项目和样本的两个公共存储库,收集有关生物项目和实验研究样本的描述性元数据。截至2021年9月,共有来自514 个组织的2,538 名用户提交了4,514 个生物项目和482,577 个样本,与2020年8月的2,288 个项目和176,288 个样本相比增长迅速[22]。
3.1.5 新冠肺炎疫情相关数据库
为支持新冠肺炎疫情相关研究的有效开展,生物医学数据库研究人员除在已有数据库中增加相关新冠病毒数据外,全新构建了特色数据库(如表3所示)[18]。

表3 新冠肺炎疫情相关生物医学数据库[18]Table 3 Descriptions of new databases related to COVID-19[18]
从上述数据库数量与存储数据量变化可以看出,生物医学数据持续保持较快增长趋势。一方面,随着新技术、新工具的应用促使更多数据资源被发现与开发,导致数据量增加;另一方面,相关学科的快速发展、人类疾病的演进、重大公共卫生事件等对生物医学数据资源的快速增加也产生了积极作用。
3.2 数据分析算法与模型
生物医学领域存在大量标注与未标注的文本、图像等数据,利用数学与计算机科学算法和模型可以有效挖掘潜藏在大规模数据中的领域知识。传统且典型的非线性动力系统方法、复杂性分析方法、多序列比较方法、统计学方法、数据库技术、数据挖掘、自然语言处理技术等已得到广泛应用。目前,深度神经网络已经成为数据挖掘的主流模型,且迅速更新迭代,在多种任务上性能最佳。该方法的主要优点是能够自动学习各种任务的有效特征,降低特征工程成本。本文将针对生物医学文本挖掘领域的基于深度神经网络方法的最新进展进行简要梳理,如表4所示。

表4 生物医学文本挖掘领域进展梳理Table 4 The progress of biomedical text mining
生物医学文本挖掘主要研究内容包括实体识别与规范化、关系抽取、通路提取、文本分类和预测等[23]。表4整理了各任务一些最新研究成果。可以看出,命名实体识别与规范化、关系抽取、文本分类三种任务因具备支撑研究开展的语料库,相关研究较丰富,且研究继承性较强,算法结果可比,易于算法与模型的更新和应用。通路提取因缺乏公开可用数据集,一些新算法与模型还未得到广泛应用。预测研究多基于知识图谱技术,但预测结果的可靠性、可解释性与可用性仍需专家介入。
虽然生物医学文本挖掘研究已取得令人振奋的进展,具有良好性能的模型不断迭代,结果越来越接近人类判断结果。但这些实验室研究距离真实世界应用还有一定差距,仍需在实践中不断完善。未来随着标注数据库的不断完善,算法性能地不断提升,文本挖掘将会有更多更具代表性研究,或推广至实践应用。
3.3 数据分析工具与软件
日益增长的生物医学数据资源对分析工具与软件的需求与日俱增,研发高效、便捷的数据分析工具与软件是生物医学信息学的主要研究方向之一。典型分析工具与软件如BLAST 系列工具[37-38]等不断更新以适应用户与数据需求,一些结合新方法、具备更丰富功能的新工具在不断研发应用(如表5所示)。如,GalaxyHeteromer[39]从氨基酸序列或组成异源二聚体的两个不同亚基蛋白的结构中预测异源二聚体蛋白质-蛋白质复合物结构。DeepGOWeb[40]使用基于深度学习和序列相似性的蛋白质功能预测方法。Mergeomics[41]不仅适用于特定疾病不同来源、不同数据类型,还通过功能基因组学考虑组学之间的关系,以推导疾病网络和预测治疗方法。iNetModels[42]对具有不同代谢条件的个体进行了大规模的多组学生物网络分析。新建的药物分析工具如DrugComb[43]对大量癌细胞系的药物组合筛选研究结果进行了积累和标准化,LigAdvisor[44]将DrugBank、Protein Data Bank、UniProt、Clinical Trials 和Therapeutic Target Database 整合到一个直观的平台中,以促进药物发现任务。

表5 新建生物医学数据分析工具举例Table 5 New biomedical data analysis tools
4 生物医学信息学发展展望
随着数据密集型、数据驱动型科研范式的确立和兴起,学科领域大数据驱动的知识发现已成为科学研究的显著特色和重要方式[45]。生物医学信息学是生物学、医学、信息学、计算机科学等融合发展的交叉学科,需要在海量可靠数据资源基础上,建立科学、可解释、可迁移的计算模型,对生物医学领域数据进行深入挖掘,发现新知识,探索新领域。虽然生物医学信息学学科逐渐完善,但国际卫生健康环境变幻莫测,人类面临的生命健康与公共卫生安全风险不断,新的生物医学大数据不断产生并海量增长,新的技术手段不断迭代应用,创新人才不断涌现,生物医学信息学仍有较大发展空间。
(1)持续推动生物医学数据标准化与开放共享,努力实现数据互联互通
生物医学海量数据资源在收集、整合、存储、共享、互操作等方面面临许多挑战。建立统一、规范的元数据标准是提高数据收集质量、促进数据集成整合、实现数据互联互通的前提[46]。如美国2018年起全面实施的All of Us 研究计划,旨在建立至少包含100 万美国居民的国家级大型队列,以深入研究影响健康与疾病的遗传、社会和环境因素。该项目采用“观察性医疗成果合作方的通用数据模型”(OMOP Common Data Model)的基础结构对参与者电子健康档案(Electronic Health Records,EHRs)源数据进行标准化处理,再进行数据核查、清洗和质量控制,以及多源异构数据的分析和整合,最终存储到标准数据库[47],实现数据标准化管理。2016年FORCE11 组织正式提出了在科学数据管理领域引入FAIR 准则:可查询(Findable)、可获取(Accessible)、可互操作(Interoperable)、可重利用(Reusable)[48]。数据的FAIR 化是数据开放共享、分析利用的基础,也是科学数据管理的基本目标。生物医学领域构建了大量领域数据标准、术语、本体等,可以实现数据的语义标准化,提升数据质量,促进数据整合共享。但术语或本体存在开发与维护耗时耗力、多语言版本兼容性等问题。世纪性新冠肺炎疫情再次令各国政府意识到数据标准化与开放共享的重要性,各国都在确保数据安全的前提下,纷纷推进生物医学数据标准化与共享,未来生物医学数据的标准化与可获得性也将大大提升。
(2)建设生物医学大数据质量控制标准,确保数据质量
生物医学大数据中蕴含极为丰富的领域知识,是关乎公共卫生安全和人类生存健康的重要战略资源[49],容不得半点虚假。新一代测序技术的发展、精准医学计划的推进以及新冠肺炎疫情大流行,使得生物医学数据指数级增加,如何确保数据资源质量是学科发展的关键。但不同数据类型的数据质控要求不同,需要提供参考数据集作为基准,包括实验方法产出的原始数据、数据分析形成的分析结果与参考数据集的吻合情况等,因此,可通过建设参考数据集加强数据质量管控[50]。同时,数据的可交互性和互操作性也是数据资源建设过程中需考虑的重要问题之一。
(3)积极构建生物医学“多模态异构数据+智能计算”的技术生态,提升领域知识发现效率
获取生物医学大数据已不再困难,但大数据本身不是直接可使用的专门知识,只有经过有效地处理、分析和挖掘,才能充分发挥数据应有的价值。然而,生物医学数据的实时性、多模态、结构化程度弱、噪音大等问题对数据分析方法与工具提出了更高要求。以人工智能、大数据计算、区块链等为代表的新兴技术发展迅速,在生物医学数据获取、预处理、分析、共享等各个方面发挥重要作用。通过技术手段整合组学数据、影像数据、表型数据、文献数据等各类生物医学大数据,利用人工智能技术进行深度挖掘,成为生物医学信息学研究的重中之重,已在肿瘤、阿尔茨海默病等疾病诊断、分型分类、风险预测、医学影像辅助诊断等[51-52]方面具有良好应用。因具有去中心特性,区块链技术在生物医学数据共享方面有所应用[53]。如美国All of Us研究计划的数据与研究中心利用区块链技术等建立安全的云环境,对数据进行云储存与云共享,通过个人信息去标识化等有效保护参与者隐私与数据安全[47]。未来随着人工智能技术的迭代更新、多模态异构资源整合技术的不断突破、组学技术的快速发展等,“多模态异构数据+智能计算”的生态环境将不断完善,促使生物医学知识发现早日走向临床实践。
(4)完善生物医学信息学多元课程体系,培养闭环多学科交叉融合的专业人才
生物医学信息学是典型的交叉学科,多学科交叉与融合是学科发展特色,培养具有多学科视野与思维方式的复合型人才是学科发展的关键。国外生物医学信息学课程存在多元化、个性化与职业化倾向,包含通识与人文社科类课程,重视人才综合素质的培养,而国内课程设置上仍以专业化为主。因此,生物医学信息学教育将向着高层次、理论与实践相结合的方向发展,并将基于生物、医学、计算机科学、信息科学等多元依赖关系构建课程体系,进一步体现其多学科交叉融合特色,更加注重基础理论和核心技能培养[54]。根据学科特点,突出科研优势、拓宽人才知识范围、储备闭环多学科交叉融合人才是未来人才培养的重点。
(5)加强临床研究转化应用监管,促进知识发现成果转化应用
生物医学信息学的研究目的之一就是通过技术与数据的融合,辅助临床决策,改善临床结局。一些生物医学数据分析平台或系统已经在小范围内推广应用[12,55],但因数据兼容性、隐私性、安全性等突出问题无法大规模推广应用。除此之外,一些新技术在临床研究中取得突破,可有效辅助临床决策,但因管理不清、政策不明等原因无法有效转化应用。我国卫健委2019年发布《生物医学新技术临床应用管理条例(征求意见稿)》[56]中对生物医学新技术临床研究的管理、监督、转化应用等做出明确规定,未来该条例将颁布实施,将进一步加强对临床研究转化应用的监管,有利于促进生物医学信息学研究成果的转化应用。
面对复杂多变的国际大环境以及生物医学大数据的挑战,数据与技术仍是生物医学信息学发展的两大关键要素。建立全面支撑科学研究的数据汇交、管理、共享与挖掘的技术与资源体系,形成以资源为基础、以技术为手段、以人才为核心、以应用为导向的生物医学信息学发展路径,将有效支撑生物医学信息学学科的发展。
利益冲突声明
所有作者声明不存在利益冲突关系。
