基于强化学习的频控阵-多输入多输出雷达发射功率分配方法
2023-03-01丁梓航谢军伟
丁梓航 谢军伟 齐 铖
(空军工程大学防空反导学院 西安 710051)
1 引言
雷达系统位于复杂多变的电磁环境中,在敌方干扰机和其他干扰源会对雷达正常工作带来巨大的影响。因此,如何抑制环境中的干扰,提高雷达接收端的信干噪比(Signal-to-Interference-plus-Noise Ratios, SINR),对于雷达系统是至关重要的。
频控阵(Frequency Diverse Array, FDA)这一概念于2006年被提出[1]。相较于传统的相控阵雷达,FDA雷达的每个发射阵元间存在一个远小于载波频率的频率偏移量,这一频偏量使其能够获得角度-距离2维相关的波束方向图[2–4]。FDA波束因具有角度-距离相关这一特性,使其被广泛应用于包括目标角度-距离定位[5],2维波束形成技术和波束方向图设计等领域[6,7]。
多输入多输出(Multi-Input and Multi-Output,MIMO)雷达因其与传统相控阵(Phase Array,PA)雷达相比所具有的独特优势而得到了广泛的研究。文献[8]将FDA与MIMO雷达相结合,并提出了FDA-MIMO雷达接收处理模型。FDA-MIMO雷达同时具有FDA雷达距离-角度相关的波束方向图和MIMO雷达所拥有的多自由度的特点,由此可以被用于欺骗干扰压制[9–11]、联合角度-距离估计[5]和空时自适应杂波抑制[12,13]等。
近年来,雷达与干扰的博弈现象受到广泛关注。文献[14]对雷达对抗中的博弈论问题进行了系统的分析与梳理。文献[15]对博弈论思想在雷达系统设计中的应用进行了综述,主要集中于雷达对抗、雷达资源管理、雷达波形设计、雷达射频隐身等方面。文献[16]提出基于回波间互信息量(Mutual Information, MI)准则的Stackelberg博弈波形设计。文献[17]对多基地分布式MIMO雷达组网的功率进行了纳什均衡分析,提出了一种以SINR为约束的雷达功率分配优化方法。上述文献建立的博弈模型用于雷达与干扰的对抗分析,而针对频谱式干扰的研究还很少。
在博弈的阶段中,实际上是一个动态优化的过程。若干扰信号发生变化,雷达系统就需要立即调整发射功率分配模式,以获得较高的SINR。传统的优化方法普遍存在计算复杂度高的问题,而对抗过程是一个高实时性问题,因此亟需一种处理速度快的优化方法。近年来,深度学习(Deep Learning,DL)成为研究热点,而强化学习可以实现离线学习、在线寻优。对于已经离线训练好的网络,将当前状态输入到网络中,可以实时获取优化的结果。文献[18]利用凸优化方法对MIMO雷达发射功率进行优化以获得最优的检测性能。
在此基础上,本文建立了FDA-MIMO雷达与频谱干扰机的Stackelberg博弈模型。在两者动态博弈的过程中,利用强化学习中的DDPG算法对采集的干扰信号状态进行离线训练,获得演员和评论家网络的参数,然后根据雷达当前侦测到的频谱干扰样式对发射功率进行在线动态优化,使雷达在工作时间段内获得最优的输出SINR性能,达到对抗频谱干扰的效果。
2 数据模型
2.1 FDA-MIMO雷达
考虑一个发射和接收阵列均为均匀线性阵列的FDA-MIMO雷达。其中,雷达发射阵列含有M个发射阵元,阵元间隔为d=λ/2(λ为波长)。在接收阵列中,接收阵元数为Nr,阵元间隔为d=λ/2。假设该雷达发射信号类型为脉冲信号,则第m个发射阵元发射信号的表达式为
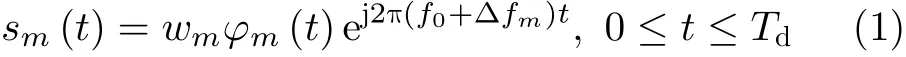
其中,∆fm=(m −1)∆f表示第m个发射阵元的频偏量,f0表 示发射信号的载波频率,Td为发射脉冲信号的脉冲持续时间。由于阵元间 ∆fm的存在,FDA-MIMO雷达能够同时工作在多个频率上,也使其具有精准频谱干扰的抗干扰能力。wm,φm(t)分别是第m个发射阵元的发射信号功率值和基带波形且φm(t)满足关系式为

假设空间中一个远场目标位于空间位置(θ,r),经过目标反射,第n个接收阵元接收到来自第m个发射的信号可以表示为

τm,n为信号在空间中传播的时延,其表达式为
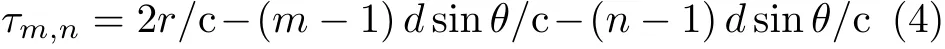
c表示光速。在窄带信号假设下,式(3)可以近似改写为
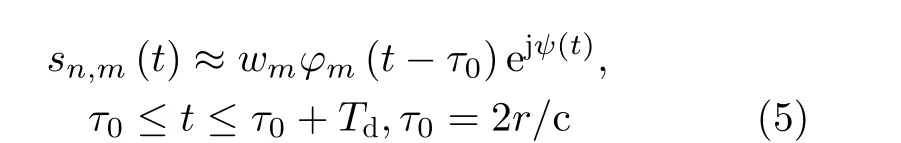
ψ(t)为信号传播带来的相位变化量,且可以表示为
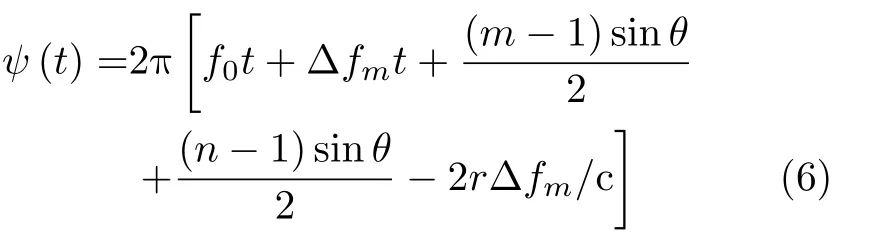
当信号被雷达接收系统接收后,会经过一系列的信号处理过程。文献[19]提出了一种多匹配滤波器的FDA-MIMO雷达的接收处理系统,本文也采用该接收处理方法。根据发射信号的相互正交性,经过匹配滤波器处理后的信号可以表示为

其中,⊗表示克罗内克积,⊙表示哈达玛积,(·)T表示转置操作。at(θ,r),ar(θ)分别为发射、接收导向矢量,w为发射功率向量,γ为目标反射系数。
2.2 干扰模型
考虑雷达系统处于频谱干扰环境,该干扰可能来自敌方的干扰机和其他与雷达共享频段的无线电。假设干扰信号可以表示为s(t),为了方便分析,考虑从第1个接收阵元。由2.1节,FDA-MIMO雷达将接收到的干扰信号s(t)通过信号接收处理过程后,在第m个通道采集到的信号为
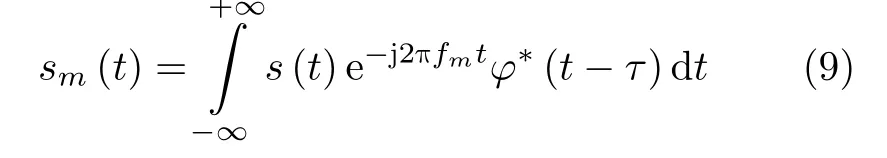
其中, (·)∗表 示共轭操作,τ表示采样时延,对应目标所处的距离单元。
将经过M个通道处理后的干扰信号表示为矢量形式s=[s1,s2,...,sM]T。经过接收处理的频谱干扰信号s服从均值为0,协方差矩阵为P的复高斯分布,其中

当Nr个接收阵元接收到干扰信号,每个阵元中都有M个处理通道,假设存在K个远场干扰信号,信号方位角为{θk}Kk=1,接收阵列采集到的干扰加噪声信号向量为

雷达系统的抗干扰能力可以用接收获得的信干噪比(SINR)来表征。当雷达系统工作时间位于t(t=1,2,...,T)时刻,基于最小方差无失真响应(Minimum Variance Distortionless Response,MVDR)的线性检测器

具有最高的输出SINR,在该检测器下获得的SINR由式(15)给出
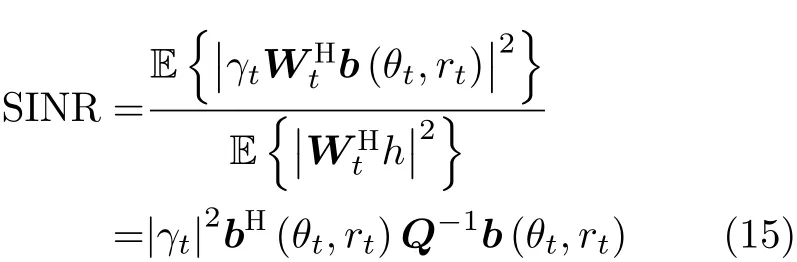
其中,(·)H表示共轭转置操作。
从式(15)可以看出,不同的发射阵元功率分配模式,在MVDR线性检测器下,可以获得不同的SINR。因此,通过对发射阵元的功率分配优化,可以获得最高的SINR。
3 基于强化学习的雷达抗干扰博弈的功率分配算法
3.1 博弈的基本模型
一种基于FDA-MIMO雷达的功率分配博弈论框架被建立。在雷达系统工作时,环境中的频谱干扰对其产生了极大的影响,且雷达系统与干扰信号之间没有合作关系,因此两者建立非合作博弈关系,前者控制发射阵元功率矢量w,后者控制干扰信号的发射功率矩阵P。雷达和干扰之间是一种零和博弈,即一个参与者的增益是另一个参与者的损失。雷达和干扰的博弈框架可以表示如式(16)的形式


(3) 效用函数:U={Ur,Ui}, 其中,Ur=max{SINR}为 雷达的效用函数,雷达通过调整w获得输出的最大SINR,Ui=min{SINR}为干扰机的效用函数,干扰机通过改变P来获得输出的最大SINR。
在实际环境中,雷达与干扰机间存在一种Stackelberg博弈关系。Stackelberg博弈是一种完全信息动态博弈,跟随者根据主导者的行为制定自己的行为策略,然后主导者再根据跟随者的行为策略调整更新自己的策略以获得最大效用。在本文中,考虑我方雷达需要在变化的干扰环境中保持较好的抗干扰性能,因此雷达是主导者,干扰机是跟随者。在Stackelberg博弈框架下,该问题转化为两阶段的优化问题,该优化问题如式(17)所示
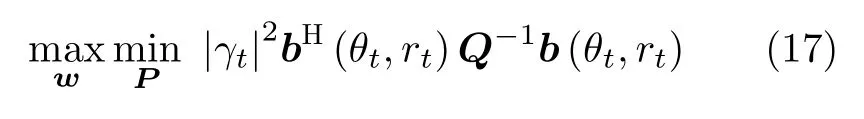

其中,Pmin,Pmax分别表示每个发射阵元的功率最小值和最大值,Ptotal为发射阵元的总功率。
需要说明的是,在整个博弈时间T中,干扰机对雷达频谱功率的感知需要一定的时间,即在雷达根据干扰信号动态调整功率分配策略后,干扰机只能在多个时刻后才能对发射的干扰信号进行调整,使得雷达获得最小输出SINR。雷达系统可通过外部的频谱感知模块和辅助传感器阵列,感知环境中的干扰噪声信号,可以实时地估计出干扰信号的频谱以及协方差矩阵,便于雷达在博弈过程中获得最佳的抗干扰性能。
3.2 基于DDPG算法的优化求解
当雷达接收到干扰机发射的干扰信号后,需要自适应地调整发射阵元的功率来避开干扰信号。在整个博弈的过程中,本文采用强化学习中的DDPG算法对雷达发射功率矢量w进行优化。将雷达各个阵元设置为智能体,负责收集环境中的干扰信号,并对发射阵元功率进行控制。
DDPG算法对智能体神经网络进行训练,得到网络参数。在第t个雷达工作时刻,雷达阵元根据所接收到的状态s∗t,利用行为网络输出功率分配行为a∗t,并获得对应的奖赏rt∗和下一步的状态s∗t+1,进入第t+1个工作时刻。将每个工作时刻获得的经验(st,at,rt,st+1)存储在经验池中。接下来,本文将对强化学习网络中的状态、行为、奖赏和行为-评论家网络进行说明。
(1)状态。在第t个雷达工作时刻,强化学习中的状态是一个向量st=[xt,yt,pt], 其中,xt,yt分别表示目标的空间位置,pt是第t个工作时刻下,干扰信号的功率矩阵的对角线元素组成的行向量。
(2)行为。在深度强化学习框架中,智能体的行为向量为at=[w1,t,w2,t,...,wNt,t],其中每一个元素代表在每一个确定的工作时刻下雷达系统发射阵元的功率分配情况。
经过sigmoid函数输出的at范 围为[ 0,1],为保证行为at中 元素满足约束条件式(17a)Pmin≤wi ≤Pmax,其作用于环境时再通过线性变换映射至真实范围。设输出的某一个行为取值为at,i,将其从[ 0,1]映射到[Pmin,Pmax] 范围上的线性变换为at,i(Pmax−Pmin)+Pmin。
(3)奖赏函数。根据式(17)中的目标函数,奖赏函数被定义为雷达输出的SINR,即在第t个工作时刻下的奖赏函数为

由于行为向量存在约束条件,为使强化学习网络能够满足行为的约束条件,本文提出一种新的奖赏函数来实现对行为的约束。该奖赏函数更新为

通过重构奖赏函数,可以将行为的约束引入到深度学习网络中。
3.2.1 功率优化方法的整体框架
在雷达侦测到干扰机发射干扰信号的先验信息的条件下,DDPG网络被用来求解雷达发射阵元的功率分配问题。在每一雷达工作时刻,雷达侦测到的先验信息被存储到记忆回放池并将其作为强化学习网络训练的输入。对于传统方法,在每一个工作时刻都需要对雷达的发射功率进行优化求解。经过记忆回放池中采样数据对DDPG网络训练完成后,可以直接获得雷达当前工作时刻优化后的功率分配结果。图1为雷达-干扰机博弈下的功率优化方法的整体框架示意图。

图1 发射功率优化方法整体框架
3.2.2 DDPG算法流程
采用DDPG算法对上述雷达-干扰机博弈功率优化模型进行离线训练,算法的整体流程如算法1所示。

算法1 DDPG算法
在网络更新迭代训练过程中,先积累经验回放到经验池中,根据经验池中随机抽取的样本分别更新评论家和演员网络。首先通过损失函数更新评论家网络参数θQ。接下来通过评论家网络得到的Q函数相对于动作的策略梯度,将梯度传递到演员网络中对其参数θµ进 行更新。最后通过得到的θQ,θµ通过参数τ,按照设定的比例更新各自所属的目标网络中,其目标网络会在下一步的训练中用来预测行为和Q值。
4 仿真分析
FDA-MIMO雷达发射接收阵列均为均匀线性阵列且阵元数分别为M=6,Nr=5,阵元间距均为d=λ/2 。发射阵列阵元间频偏量∆f=10 kHz,载波频率f0=1 GHz。雷达工作时间最小间隔为2 s,雷达工作总时间设置为20帧(40 s)。每个发射阵元的功率最小值和最大值分别为Pmin=0和Pmax=Ptotal。
在雷达工作初始时间内,空间中的目标位于(5 km,5 km),在整个雷达工作时间内,假设目标沿着45°方向,以速度v=100 m/s做匀速直线运动,雷达系统通过跟踪算法在每个工作时刻对目标的位置进行实时更新。
假设干扰机的干扰频段数量小于等于3。在初始工作时刻,干扰信号从方位角为45°进入雷达接收机系统,以30 dB, 25 dB和30 dB的干扰功率,干扰第1、第4和第6个发射阵元的频段。根据所提博弈准则,雷达作为领导者会根据干扰机释放的干扰信号通过自适应控制发射阵元的功率来提高输出的SINR。在雷达调整阵元功率后,经过一段时间,干扰机侦测到雷达发射信号的变化,通过调整干扰信号使得雷达系统接收端获得的SINR最小。雷达再根据新的干扰信号调整发射阵元的功率,形成博弈态势。
干扰信号的功率分布计算公式为

其中,az(θ)=ez ⊗ar(θ),ez表示第z个元素为1,其余元素都为0的单位向量。z表示干扰频谱的位置索引。
(4)DDPG中的参数设置。智能体的状态表示为8维数组向量,动作表示为6维数组向量。演员网络包含2个隐含层,每个隐含层的神经元个数为32,所有隐含层都采用tanh激活函数。评论家网络包含3个隐含层,每个隐含层的神经元个数为32,所有隐含层都采用tanh激活函数。演员网络和评论家网络的学习率分别为0.001,0.01。折扣因子为κ=1 ,超参数ε=0.1。
本文程序是基于keras框架编写的,计算机硬件条件为Core i5-10210CPU, 3.60 GHz, 8 GB内存,设置回合数为800,每一个回合中的迭代步数为20。
在各个回合中,雷达与干扰机智能博弈的完整工作过程的累计奖赏值和平均SINR值如图2(a)和图2(b)所示,雷达的目的是通过不断地学习提升奖赏值,来获得最大的奖赏,即最大SINR值。累计奖赏值和SINR值越大表明雷达的功率分配优化结果越好,网络的学习效果越好。由仿真结果可以看出累计奖赏值与平均SINR值整体的变化趋势是逐步增加的。在回合数大于400时,累计奖赏值和平均SINR值均达到最大且基本保持稳定。
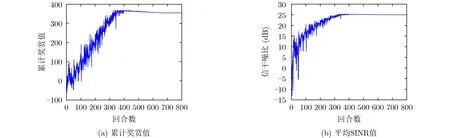
图2 累计奖赏值和SINR随回合数的变化情况
图3(a)为通过所提算法对FDA-MIMO雷达发射功率分配结果。从结果中可以看出,当t= 1时,在当前工作时刻,雷达没有感知到外界的干扰信号,因此保留基本的功率均匀分配策略。当2≤t ≤10时,雷达侦测到干扰信号后,使发射功率集中在第2个发射阵元上;当 1 1≤t ≤15时,由于干扰机调整了频谱干扰策略,雷达在侦测到干扰信号后立即对发射功率进行优化,使功率集中到第1个阵元;同样地,当1 6≤t ≤20时,雷达将发射功率集中到第6个阵元,以获得最优的SINR。图3(b)为通过内点法对雷达发射功率优化分配的结果。由仿真结果可以看出,内点法得到的功率分配策略与所提算法类似,在雷达工作时间段中,功率都集中在某一个发射阵元上,且均避开了频谱干扰信号所在的频点。由此,验证了本文所提算法能够实现与传统优化算法相似的优化效果,验证了其有效性。
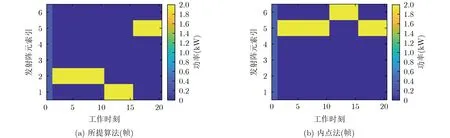
图3 发射功率分配情况
为了直观地展现出内定法和DDPG算法的性能,两种算法得到的SINR值随雷达工作时间的变化情况如图4所示。从该仿真结果可以看出,当t= 1时,雷达采用功率均匀分配策略,此时雷达已经受到干扰,因此SINR较低。当t>1时,雷达系统开始根据干扰信号对发射功率进行优化,得到的SINR较高。相较于内点法,文中所提算法对发射功率优化后得到的SINR有一定的波动,这是因为所提算法在训练时所用到的目标位置信息和干扰信息与仿真中设置的信息有一定差异。但通过两种算法得到的SINR基本一致,因此验证了所提算法的有效性。

图4 SINR值变化情况
干扰在整个工作时间段的干扰信号参数变化情况如表1所示。
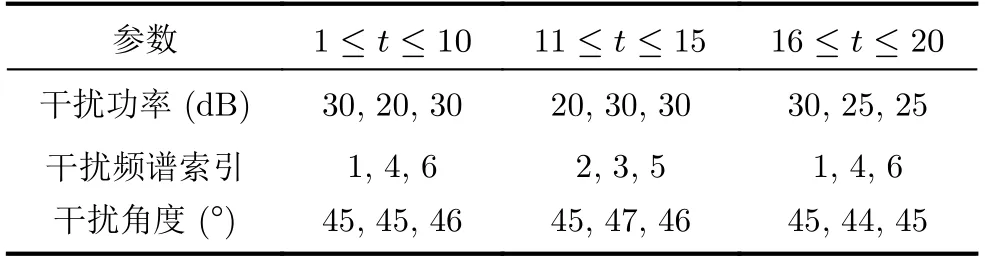
表1 频谱干扰信号在工作时间段内的参数变化情况
各个时刻干扰信号在角度-频率2维平面上的功率分布如图5所示。

图5 干扰信号在频率-角度的功率分布情况




表2 算法复杂度
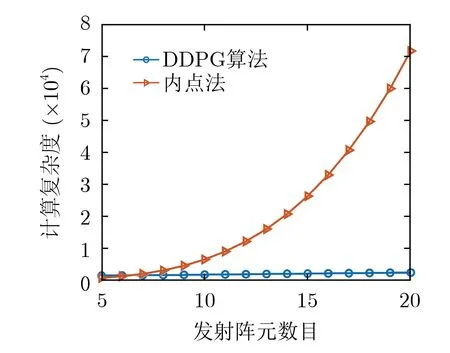
图6 计算复杂度随发射阵元数目变化情况
5 结论
本文建立了FDA-MIMO雷达与释放频谱干扰信号的干扰机的Stackelberg博弈关系,并将雷达作为领导者,干扰机作为跟随者。为了使雷达获得最大的抗干扰效果,将深度确定策略梯度算法应用于雷达发射阵列的功率优化分配中,使得雷达在干扰信号产生变化过程中,能够动态调整阵元功率分配来获得最优SINR。算法中考虑了单个阵元功率约束和阵列总功率约束,并在约束下输出动作。仿真结果表明,通过DDPG算法的多个回合的训练,使雷达能够很好地感知干扰信号的变化并合理地分配发射阵元的功率,达到最优的SINR,实现抗干扰的效果。
