机器学习高效筛选用于CO2/N2选择性吸附分离的沸石材料
2023-03-01王璐张磊都健
王璐,张磊,都健
(大连理工大学化工学院化工系统工程研究所,辽宁 大连 116024)
随着全球气候变暖问题愈发严重,为减少CO2温室气体的排放,碳捕获和储存(carbon dioxide capture and storage, CCS)已成为全球石油和天然气、能源政策与可持续发展的重要议题。煤等化石燃料燃烧时所产生的烟道气是CCS的主要应用领域之一。目前主流的CO2捕获技术主要有燃烧前捕获、富氧燃烧捕获和燃烧后捕获三种方式。燃烧前的碳捕获将二氧化碳从气化或重整过程中去除,然后生产合成气以制造氢气,或在综合气化联合循环发电厂发电。燃烧前碳氢化合物含量较高,因此燃烧前捕获通常效率高,但需要的成本更高,而且其性能没有得到很好的测试。在富氧燃烧捕获过程中,燃料在氧气而不是空气中燃烧,因此烟气主要由CO2和SOx等杂质组成,捕捉难度低。然而氧浓度过高将导致腐蚀、污垢、潜在泄漏、维护成本高等问题,需要非常严格的安全管理[1]。燃烧后的碳捕获是一种简单的方法,是CCS现有设施的基础。对比燃烧前捕获和富氧燃烧捕获,燃烧后捕获的适用范围更大,经济可行性更高,因此本文主要研究用于电厂排放的燃烧后烟道气中的CO2捕集。
烟道气的典型组成包括13%CO2、73%N2、10%H2O、3%O2和其他污染物质,因此有必要将CO2分离出来,以减少温室气体的排放。变压吸附技术(pressure swing adsorption, PSA)在气体分离领域得到了广泛的应用,已成为CO2捕集的一个有前途的候选技术,尤其对于高纯度气体产品的生产[2]。然而基于吸附过程的碳捕集需要高性能吸附材料的支持,目前金属有机框架材料(MOFs)、各类碳基吸附材料(碳分子筛与活性炭)和沸石等多孔材料已被广泛用于CO2捕集过程。沸石由于其独一无二的笼状与孔道结构及稳定、廉价的优点,在气体吸附方面的应用非常广泛。例如,Wu等[3]发现纳米L型沸石对CH4和N2、CO2混合物中的CO2具有较强的分离和捕获性能。沸石是一种微孔结构规律分布的硅铝酸盐晶体,而在实际中一些已得到广泛应用的沸石材料则十分接近于纯硅结构[4]。鉴于存在大量潜在的吸附材料,因此寻找有效的方法来评估吸附材料是变压吸附CO2捕集工艺的关键。然而在大范围筛选吸附材料时,目标气体的单组分吸附等温线往往是唯一可以获得的信息,因此吸附材料的评估指标[5−9]可依据吸附等温线来计算得到。
传统的气体吸附等温线的测定方法为实验法,但实验法普遍具有耗费时间、金钱、人力物力的缺点。理论模拟计算的方法在克服以上缺点的基础上还可以观察到实验中无法直接观察到的现象及细节,因此理论模拟方法在该领域得到了越来越广泛的应用。其中,分子力学方法中的巨正则蒙特卡洛(grand canonical Monte Carlo, GCMC)方法常被用来模拟吸附材料对气体的吸附行为,这是因为巨正则系综要求温度、体积和化学势的恒定,较适合研究气体吸附和分离现象。例如,Mahmoud等[10]发现吸收量和孔径之间存在着很大的联系,是通过在一定温度下用巨正则蒙特卡洛方法对氢气分子在不同沸石结构中的等温吸附曲线进行模拟得到的。在模拟过程中,吸附分子可以利用随机移动方式(平移和旋转等)实现从系统中移除现有分子,或向系统内的随机位置中嵌入新分子。但随着材料种类数的不断增加,GCMC 方法所带来的计算量也随之增大。近年来,机器学习方法(machine learning, ML)的提出为省时并高效地快速发现材料提供了一条新的发展道路。例如,Lin等[11]将巨正则蒙特卡洛(GCMC)模拟与机器学习(ML)方法结合,系统地筛选了50959 个纯硅分子筛结构,并用4 种线型硅氧烷及其衍生物进行验证,得到230个具有良好吸附性能的分子筛。
机器学习作为人工智能领域的一个重要分支,其本质是使用算法模仿人类学习的方式从数据中自动获取规律并进行改进。根据数据类型(数据是否含有标签),可分为监督学习与无监督学习。目前化工领域常用的机器学习模型主要集中在监督学习,其主流模型包括支持向量机(SVM)模型、人工神经网络(ANN)模型以及决策树(DT)模型[12]等。其中ANN模型能够充分逼近复杂的非线性关系,具有很强的自学习和自适应能力[13],因此其被广泛用于研究材料的宏观性质(物理和机械性能)与其微观结构之间的构效关系[14],这恰恰符合本文的沸石结构与其吸附特性之间的关系(即结构-吸附性关系,简称SAR)。
ANN 是受生物神经系统启发的计算网络,与人脑的结构一样,神经网络模型由复杂非线性形式的神经元组成[15]。最早Rosenblatt[16]定义了一种被称为感知器的神经网络结构,这是之后很多神经网络模型的始祖。然而单层感知器仅可解决线性可分的分类问题,因此必须在输入输出层间添加隐藏层构成多层感知器来进一步增强。这种多层感知器理念最早是由Werbos[17]提出的。随后Rumelhart等[18]提出一般型Delta法则,即用反向传播算法(back propagation,BP)进行前馈式多层神经网络的机器学习训练,解决了中间层参数的确定问题。继BP 算法以后,Broomhead等[19]将径向基函数引入神经网络设计中,形成了径向基神经网络(RBF),标志着神经网络开始真正迈向实用化。此后又衍生出了循环(递归)神经网络[20]及卷积神经网络等模型[21]。2006年,由Hinton等[22]提出的深度神经网络(deep neural network, DNN)概念又一次引发了对神经网络的研发浪潮,深度模型与浅层模型相比具有更大的潜力。
因此,为克服实验法与理论模拟计算耗时等缺点,本文提出了一种基于机器学习方法的吸附材料筛选框架。首先,从Iyer等[23]的文献中获取由GCMC方法计算得到的沸石的吸附数据,引入沸石的结构描述符,建立基于ANN模型的沸石SAR预测模型。由此,利用已建立的机器学习模型来预测文献中的一些缺失数据,然后通过拟合纯组分气体的吸附等温线来预测混合气体的吸附等温线,以此计算几种吸附材料评估指标,筛选候选沸石材料。最后,利用GCMC方法对筛选结果进行验证。
1 基于机器学习的沸石吸附材料筛选框架
本节提出了沸石吸附材料的筛选框架,包括三个阶段(如图1所示)。在第一阶段中,构建了基于机器学习的SAR模型,通过沸石的结构描述符快速预测气体吸附数据,然后选用合适的等温吸附模型分别拟合两种气体的吸附数据,通过拟合得到的参数利用理想吸附溶液理论(ideal adsorbed solution theory, IAST)[24]预测混合气体吸附等温线。在该阶段,选用的几种吸附材料评估指标均由混合物吸附数据计算得出,以获得作为给定应用吸附材料的最佳候选材料列表。最后,通过混合气体的GCMC计算结果进一步验证候选沸石材料的吸附特性。
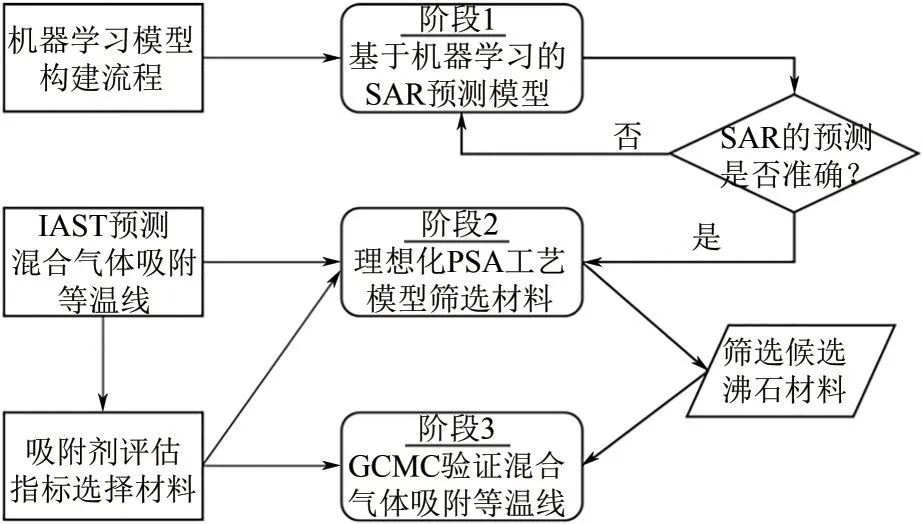
图1 基于机器学习的沸石吸附材料筛选框架
1.1 基于机器学习模型的SAR预测模型
在第一阶段,沸石的结构描述符与性质分别作为机器学习模型的输入和输出,将沸石骨架空腔、笼或孔道对应的天然构造单元(Natural Building Unit,NBU)[25]在模型中作为沸石的结构描述符。如图2所示,LTA沸石骨架是由3种NBU以3∶1∶1的比例堆积而成的。模型的构建流程如图3所示,可分为以下3个阶段:数据收集及预处理、模型建立和模型测试。

图2 LTA沸石骨架示意图

图3 机器学习模型构建流程图
1.1.1 数据收集及预处理
原始数据主要由以下两部分数据组成:第一,从IZA−SC[26]沸石数据库中获取186 种沸石的NBU组成。经统计,数据库中大多数沸石由2种或3种NBU组合而成,80%的沸石结构由不超过5种NBU构造得到。另外,如图4所示,对数据库中的沸石结构,在3种温度与11种压力下通过GCMC模拟,得到了186种沸石对于气体N2和CO2的吸附量(mol/kg)。

图4 沸石吸附数据的来源组成
第二,在机器学习模型建立过程中,数据的分布应尽可能均匀,因此对吸附数据进行最小值-最大值线性归一化,将数据映射到0~1 范围内,如式(1)所示。
式中,Qmax和Qmin分别是平衡吸附量的最大值和最小值;Q是某个沸石(在一定温度和压力下)对某种气体的平衡吸附量;Q͂是该值归一化后的数值。在对数据进行预处理后,为了避免在机器学习模型训练时可能出现的过拟合现象[27],还需要对数据进一步划分,并使用外部测试数据集来检测已训练的模型是否出现过拟合。
1.1.2 模型的建立
模型建立过程可以分为如图5所示的4个子步骤:a.选择合适的模型类型;b.设置参数构建模型;c.对模型进行训练调参;d.验证迭代后的模型是否符合要求。首先根据数据集大小、属性类型和数量以及模型应用任务类型等特点,选择合适的机器学习模型。具体地,本文采用浅层神经网络而非深度神经网络,这是因为数据库中的沸石结构和气体吸附量间关系相对明显,使用太过复杂的模型是没有必要的。图6是一个简单的三层神经网络示意图,图中每一个基本组成单元是一个M−P神经元[28](图7),单个神经元中的处理过程依据式(2)进行计算,其由n个输入神经x和1 个输出神经y组成,输入和输出神经分别伴有连接权重w与阈值偏差b。

图5 模型建立流程

图6 三层前馈神经网络结构示意图

图7 M−P神经元模型
模型训练阶段目的是获得一个优化的模型,其过程的目标是利用学习算法F来最小化模型M的代价函数fcost,可用式(3)表示。
式中,P是M模型的超参数;x'和y'分别代表经过预处理的输入数据与输出数据。由于超参数数量众多,容易出现组合爆炸的问题,且在追求更高的模型性能的同时,参数的调整常常会造成过拟合的现象,因此本文采用一种贪心式调参策略来避免这一问题。如图5所示,在模型训练过程中,应首先使用神经网络贪心式调参策略来配置具有一个隐含层的神经网络的超参数。选定目标参数后,接下来确定初始值、上限和下限值以及增量/步长。之后基于上述配置,调整参数Pi,并使其他参数保留其初始值。当模型性能训练达到最优状态时,即可确定参数Pi的最佳值,再继续调节下一个参数,直至确定所有参数的数值。
模型验证阶段主要是评估模型是否过拟合。一方面如果模型的性能经验证后并不理想,则可以不断添加隐含层,并调整相应的参数,除非模型发生过拟合。另一方面,如果模型发生过拟合,则建议在所构建的模型中添加正则化系数或丢弃部分神经元。
1.1.3 模型的测试
在模型经训练和验证之后,进一步通过预先划分、与交叉验证中所使用的训练集不同的数据集测试该模型。在该阶段,如果测试性能能够达到期望值,则证明所构建的模型是有效的;否则,将使用新的结构描述符来关联性质。
1.2 基于理想化PSA 工艺模型的沸石吸附材料筛选
本文采用了Ga等[2]提出的理想化PSA工艺模型,由于理想化PSA的模拟仅需要吸附材料的等温线数据,不需要传质速率、热容和内部孔隙率这些需通过复杂、耗时的实验来获得的数据,因此可以更加方便、快速地进行吸附材料的筛选。针对文献中提出的假设[2],绘制了如图8 所示的理想化PSA 工艺模型示意图:在等温操作条件下,假设T=298K,该模型的进料采用摩尔分数(yi)为0.14/0.86的CO2/N2二元混合物,包括理想的吸附(ads)和解吸(des)两个循环,组分S(strongly)和W(weakly)分别表示强吸附物质和弱吸附物质。模型对解吸步骤中产生的气体组分的摩尔分数(y*i)进行数值求解,由此获得在给定解吸条件下的吸附量(Qdes*i)。过程建模所需的基本信息为混合物的吸附平衡,本文采用理想吸附溶液理论(IAST)来预测在给定的摩尔分数及温度下不同压力的混合物吸附平衡。此外,本文采用的所有吸附材料评估指标均由混合物吸附数据(Qi)获得。

图8 理想化PSA工艺模型示意图
1.2.1 理想吸附溶液理论(IAST)
Myers和Prausnitz[29]在1965年提出的理想吸附溶液理论(IAST)是一个被广泛使用的热力学框架,可从相同温度下的纯组分吸附等温线来预测得到多组分吸附等温线。该理论的基本假设条件是被吸附物质可以形成理想的混合物,IAST 的预测结果与各种气体混合物和不同非均相吸附材料的实验数据在数量上是一致的,这在许多文献中被证实[29−33]。在这些适用的情况下,IAST可以省时省力地进行混合气体吸附测量,即使对于分子模拟,模拟纯组分吸附等温线和应用IAST 也可能比运行多组分巨正则蒙特卡罗模拟更为迅速[34]。

a. Langmuir:
b. Dual-site Langmuir:
c. Quadratic:
d. Brunauer-Emmett-Teller (BET):
e. Temkin Approximation:
f. Henry’s law:
以IZA−SC[26]沸石数据库中的WEI 沸石为例,利用pyIAST,在温度T=298K下,通过拟合CO2与N2的GCMC 模拟数据,求出在总压为35bar(1bar=105Pa)、物质的量组成为0.14/0.86时的CO2/N2混合物吸附数据。由图9可知,经IAST预测得到的混合物吸附平衡时的CO2和N2的吸附量(mmol/g)与GCMC模拟计算得到的数据非常相近,这说明可以用IAST 来预测混合物的吸附平衡数据,从而使用1.2.2节中的评估指标来对吸附材料进行排序。

图9 WEI在298K和35bar总压下CO2/N2混合物平衡时的IAST验证
1.2.2 吸附材料评估指标
为了评估材料作为捕获气体吸附材料的性能,许多研究者们从目标气体的吸附等温线出发,陆续提出了一些评估吸附材料性能的指标[5,7−9,35−36],如表1所示。

表1 吸附材料评价指标
式中,摆动能力∆QCO2定义为在吸附压力和解吸压力下气体捕获能力之间的差异。混合物吸附选择性(Sadsads,CO2/N2/Sdesads,CO2/N2)定义为在吸附压力Ptotal,ads或解吸压力Ptotal,des下,各组分的吸附容量与体相中各组分摩尔分数yi之比。吸附材料选择参数SSP,CO2/N2和吸附材料性能分数APSCO2/N2以不同的方式结合了目标组分与竞争组分的摆动能力以及吸附和解吸压力下的吸附选择性。此类指标旨在反映摆动能力和吸附选择性之间存在的权衡关系。最后一个指标再生能力R,即在吸附压力下,摆动能力与强吸附物质的吸附量之比。该参数估计解吸步骤中能够再生的吸附位点的分数。以上所有吸附材料评估指标均根据混合物吸附数据(Qi)计算得出。
1.3 使用GCMC方法对沸石筛选结果进行验证
对于已筛选出来的候选沸石材料,使用分子模拟软件RASPA[37]中的GCMC方法,计算沸石在给定温度压力下对CO2/N2二元混合物的平衡吸附量。GCMC模拟需要设置的参数如表2所示,用于描述范德华作用力的Leonard−Jones相互作用参数是从纯硅沸石的Garcia−Perez力场[38]中获得的。为了获得具有统计学意义的结果,模拟了50000个平衡和50000个循环周期。CO2和N2使用统一的分子类型,且各种随机移动(平移、旋转、重新插入)的概率相等,并将交换操作中的插入和删除的概率设为1。此外,在不考虑因堵塞使得分子无法进入孔的情况下,选取一个3×3×3的晶格单位(晶胞)进行模拟,并且采用了周期性边界条件。将模拟结果与通过IAST 预测的混合物吸附数据作比较,验证沸石对CO2/N2的分离性能。

表2 GCMC模拟参数设置
2 算例分析与讨论
本节使用燃烧后烟道气的处理作为算例,烟道气主要由CO2与N2组成,为减少温室气体的排放,主要目标是从CO2/N2混合物中捕获CO2。虽然真实的烟道气中除了CO2与N2,还包含H2O、O2、CO、SOx、NOx和Hg等杂质,但现在还没有足够的信息来准确预测这些微量杂质对吸附过程产生的影响。且已有研究表明,通过适当的设计手段,可以实现干烟气进料[39]。因此,该算例可简化为从摩尔分数为0.14/0.86且不含其他成分的干散装CO2/N2二元混合物中吸附分离CO2。
首先,建立SAR模型。基于Iyer文献[23]数据库中个别值的缺失,首先则需要对CO2及N2的吸附数据进行剔除空白值操作,然后将所有数据按9折交叉验证法划分为训练集、验证集和外部测试集,具体见表3。最后以回归系数R2[见式(14)]和均方根误差RMSE[见式(15)]为指标来评估ANN模型的性能。

表3 SAR模型的数据划分
在模型训练过程中,应首先使用神经网络贪心式调参策略来配置具有1层隐含层的神经网络模型,随后又增加到了2层隐含层,发现模型性能没有显著地提高,因此本文最终选用了仅有1层隐含层的三层前馈神经网络。不断增加神经元数量,CO2、N2的模型性能分别如表4、表5所示,其中的R2和RMSE值均为交叉验证中的9组不同数据组合的平均值。从表4的结果可知,神经元个数等于9时,CO2的预测模型性能最佳,即训练集、验证集及外部测试集的RMSE值最小,R2值最接近于1。同样地,对于N2的预测模型,神经元个数为13时,效果最好,由此给出了如图10 所示的最优神经网络结构下的CO2及N2的训练结果图。综上所述,对于CO2和N2,验证集和外部测试集的预测结果说明模型没有出现过拟合且泛化能力较好,因此用NBU 描述符来预测沸石的吸附性是有效的。

图10 CO2及N2的训练集、验证集和外部测试集的训练结果

表4 CO2的模型性能

表5 N2的模型性能
其次,根据纯组分的吸附等温线通过IAST 来预测CO2与N2混合物平衡吸附数据,然后使用表1中的吸附材料评估指标对154种沸石(具有完整的GCMC模拟数据)进行表征,引入图11的材料选择策略来筛选候选沸石材料。其中,摆动能力是在CO2分压为2.7bar(PCO2,ads)和0.1bar(PCO2,des)时的CO2容量差来计算得到的,它的下限设定为3mol/kg。吸附选择性则是考虑将吸附相中CO2的摩尔分数下限设定为0.9。但高选择性吸附材料不能保证高再生性,故将再生能力下限设为75%。

图11 吸附材料评估指标筛选材料
最佳吸附材料为满足所有这些约束条件的候选吸附材料(Ⅰ组),并考虑了满足部分但非全部约束条件的材料(Ⅱ、Ⅲ、Ⅳ组)。表6为筛选得到的Ⅰ、Ⅱ、Ⅲ、Ⅳ组沸石名称列表。第Ⅲ组的沸石具有较高的CO2选择性,但CO2摆动能力不太大,例如MVY 沸石的CO2/N2选择性高达2986,但∆QCO2只有1.9mol/kg。第Ⅱ组沸石与第Ⅲ组正好相反。第Ⅳ组沸石GIS、SIV、WEI除了再生能力不高外,CO2摆动能力及选择性都比较大。进一步根据指标吸附材料选择参数SSP,CO2/N2和吸附材料性能分数APSCO2/N2来对Ⅰ组沸石进行排序,具体结果与各项指标如表7所示。

表6 筛选得到的不同组别沸石列表
对于缺失模拟数据的32 种沸石材料,首先利用前面所建立的机器学习模型进行预测得到完整的吸附数据,同样地,再利用IAST与吸附材料评估指标筛选出符合图11中各项约束条件的沸石有VSV、RSN 及KFI,3 种沸石的各项指标数值如表7 最后三行所示。


表7 Ⅰ组沸石的吸附材料指标数值


图12 GCMC模拟验证候选沸石的混合物吸附等温线

3 结论
日益增长的材料种类使得通过实验法与理论模拟计算的方法来快速发现具有优异性能的理想材料变得十分困难。因此,本文提出了一种基于机器学习的吸附材料筛选框架,用于高效地选择具有良好CO2捕集能力的沸石材料。通过建立机器学习模型,证明了沸石结构描述符(即NBU 描述符)能够很好地预测其吸附性能(训练集、验证集及外部测试集的R2值均在0.99以上)。此外,理想吸附溶液理论可以将纯组分的吸附等温线转化为更为精确表征气体分离问题的混合物吸附等温线,并举例证明了IAST 的预测结果与GCMC 模拟的计算结果在数值上是高度一致的。由此可通过混合物吸附数据来计算摆动能力、吸附选择性、再生能力等吸附材料评价指标来选择候选沸石材料,最后用GCMC方法进行了验证。本文将该框架应用于温度T=298K、摩尔分数为0.14/0.86 的CO2/N2吸附分离CO2过程中,成功地从154种沸石材料中筛选出了满足所有吸附材料指标约束条件的8种沸石材料,另外的32种材料的纯组分吸附数据由机器学习模型补充,从而筛选得到了3种高性能候选沸石材料,证明了本文所提框架的可行性与有效性。该方法有望通过机器学习模型预测更多沸石材料的吸附特性,加速具有目标吸附特性的材料发现过程。同时可通过改变二元混合物的摩尔分数,筛选适应于不同气体分离背景下的吸附材料。
符号说明


