数据分析报告自动评分研究*
2023-03-01夏稳宋捷
夏稳,宋捷
(首都经济贸易大学统计学院,北京 100070)
1 研究背景
随着信息时代的快速发展,数据正呈爆炸式增长,大数据时代已经来临,越来越多的数据被储存。如何让这些被储存的数据发挥作用是数据科学的目的所在。中国的数据竞赛正在逐渐崛起,目前全球范围内的各类数据竞赛总量已突破1 000 余场,中国市场超过了400 场,这背后涉及大量数据分析报告的评分工作。在大学的期末考察范围内,也存在大量期末论文评分工作,由于这些期末论文多以实证性分析问题为主,其本质也即数据分析报告。而这些数据分析报告的评分工作,往往需要在短时间内给出公平公正的评分结果,手工评分的过程耗时、缺乏可靠性[1]。因此,如何显著地降低评分所耗时长及保证评分的客观性是本文的研究重点。
在人工智能及机器学习普遍适用的背景下,将人工评分实现自动化能有效地提高评分效率,这涉及到的是中文文本评分。基于已有历史数据,通过算法学习,建立一个合适的自动评分系统,从而减少人工评分的人工工作量,且能极大地保证评分的可靠性和一致性。目前关于中文文本自动评分的研究主要集中在作文和主观题评分方向,对于数据分析报告的自动评分算法研究鲜有学者涉猎;另外现有的自动评分系统都基于已有标准参考答案或是确定的作文主题进行自动评分,而数据分析报告的特点是主题具有多样性、包含许多数据分析类的统计专有名词、没有标准答案以供参考,因此现有自动评分算法是不适用于数据分析报告的。鉴于以上特点,本文将提出一个适用于数据分析报告的自动评分框架,在没有标准答案及不确定主题的条件下实现自动评分这一过程。
本文以一名大学教师回收到的期末数据分析报告数据为研究对象,在对原始数据进行中文文本处理的工作基础上,建立起具有良好性能的自动评分模型。
本文工作主要集中在以下3 个方面:①由于数据分析报告的原始数据非结构化而无法直接使用,因此先进行结构化处理。本文基于隐马尔科夫模型的中文文本处理包括数据读取、分词、停用词过滤及词性标注等过程,此操作为后续的模型构建提供数据支撑。②根据数据分析报告的特点建立一个自动评分框架,进行特征变量的选取,确保数据分析报告自动评分这一过程的全面性和准确性。确保实现人工智能化的同时尽可能1∶1 还原人工评分过程。③利用机器学习常见模型建立数据分析报告的自动评分模型,对比各个机器学习模型的平均预测误差(Mean Prediction Error,MPE)指标,以验证本文自动评分算法的效果如何。
2 国内外研究现状分析
目前国内外研究者对作文自动评分系统的研究主要分为2 类:一类是研究文章的表层特征,以此评估文章的质量,体现文章的风格和语言;另一类是研究文章的内容质量,找出文章的潜伏语义,分析作者想要传达出的信息。本文研究的对象是数据分析报告,而数据分析报告更加侧重于文本的语言质量,因此重点回顾基于文本表层特征项的相关研究。
AJAY 等[2]在1973 年提出了PEG(Project Essay Grade)系统,PEG 系统通过评估间接反映作文的写作特征,例如语法、词汇及结构等,以此实现对作文的自动评分。PEG 技术为长期努力带来了一定希望,1994年PAGE[3]通过模仿评分者的行为分析了499 篇和599篇文章,得到了十分可靠的计算机评分结果。SHERMIS 等[4]在2001 年对PEG 系统提出了改进,重点对语法进行检查,以及对人类评分和PEG 系统评分的相似性进行分析,结果显示计算机模型的表现优于多名评分评委。E-rater 是美国教育考试处为了评估GMAT 考试中的作文质量在20 世纪90 年代开发的[5]。与PEG 系统相似,E-rater 的评分模型基于线性回归模型[6]。E-rater 的作文评分系统不仅利用了统计技术,还利用了矢量空间模型和自然语言处理技术[7]。所以相比PEG 系统而言,E-rater 系统不仅可以评判作文的语言质量,还可以评判作文的内容质量[8]。在早期的评分系统里,多采用的是基于模式匹配和基于统计的传统方法。
近些年来,自动评分系统开始采用基于回归的自然语言处理技术,部分学者使用了深度学习技术,结果产生了比早期更好的效果。DONG 等[9]使用循环卷积神经网络,引入了注意力机制来决定单词和句子权重,有助于找到判断论文质量的关键词和句子,有效解决了自动学习文本表示和论文评分的问题。他们是将一篇论文视作句子文档,以一个句子为一个级别,而本文选择的变量表示主要以词现数为主,因此一篇数分报告分词后是一个长词条。CAI 等[10]用深度学习模型进行论文的自动评分结果优于传统特征选择方法,并且尝试结合深度学习和传统的特征选择,结果显示这是有利于自动评分系统的,因为存在一些特征是无法学习到的。但是使用深度学习需要有大量的数据作支撑学习,CAI 等使用的数据也仅有11 000 条左右,而本文由于受现实因素影响,暂无法收集到大量数据进行深度学习。综上,能明显得到一个结果是,结合深度学习的方法是显然要优于传统的特征提取,但是本文研究的对象是中文文本,不同于英文,汉字具有更高的复杂度和处理难度。为了进行数据分析报告自动评分算法的初探,在基于自然语言处理的技术下,使用传统的特征匹配模式。
在基于中文文本的自动评分研究中,主要分为2个研究方向:一类是已有标准答案的主观题自动评分[11-15],另一类是已有固定主题或题目的作文评分[16-18]。李学俊[11]在研究中采用基于标准答案寻找特征及从考生答案中提取出特征的方法,他还提出了在自动评分算法中,词典、文本特征词及其权重、文本匹配规则这3 方面是主要的知识库来源。方德坚[12]则采用历史评分的人工标注与分词向量建立监督模型来进行评分。吴巧玲[13]基于自然语言处理的结果计算词和句子的相似度,相似度越高则得分越高。宋雪亚、王传安[14]也是计算考生答案和标准答案之间的相似度,和上篇文章研究不同的是,这里计算的是文本串长度相似度、文本串词性相似度和文本串词序相似度。韩辉、刘秀文[15]在前人的基础上新增了提取、匹配考生答案的关键词和标准答案的关键词,计算对立度以此判断不同句子之间的语义方向是否一致。这些学者都是对考生答案和标准答案进行相似度计算,区别在于相似度的指标种类不同。有一部分学者提出了一套计算机自动阅卷系统,可以在很大程度上帮助给定题目的作文评分,这些评分算法一般是借鉴了英语作文自动评分算法。王金铨、朱周晔[16]对国外英语作文自动评分系统进行了综述。徐昌火等[17]则分析了中文作文的语言流利性、语言准确性及语言复杂性的测度,从这3 方面来建立模型。诸如钟启东、张景祥[18]采用的算法是从语言深层特征的角度,提出从上下文关联的自动识别、非流畅语句的自动识别及作文素材的自动识别3 方面来构建评分算法。
上述都是对已有标准答案和确定主题的自动评分系统进行研究,但是数据分析报告不仅没有标准答案,而且主题不单一,目前这一领域研究空白,因此本文工作为国内自动评分的研究提供了另一种思路和导向。
3 方法
3.1 数据预处理
本文研究的数据来源于一所高校教师收到的期末反馈,共计77 份数据分析报告。该数据集中存在多个写作者自选主题,教师进行人工评分时没有标准答案进行比对,教师根据历史预先给出一份评分细则,以此作为自动评分框架的构建基础。
要想实现自动评分算法,首先对非结构化的原始数据采用中文分词统一进行结构化处理。中文文本分词是自然语言处理的基础,分词准确率的高低直接影响了中文文本挖掘的效果,也直接影响了后续模型训练的效果。本文采用混合模型进行分词处理,混合模型结合使用最大概率法和隐马尔科夫模型。最大概率法是根据Trie 树构建有向无环图和进行动态规划的算法,它是在最大匹配分词算法上的改进,对于一个待分割的字符串有多种分词结果,原则为选取其中概率最大的分词结果,这是分词算法的核心;隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。由于数据分析报告中会出现许多专业名词,因此在模型中导入人工统计词典以便提高分词结果的准确性。采用混合模型对数据分析报告进行文本分词及词性标注后,对分词结果进行停用词过滤及粗糙地降维以避免维度灾难。经过处理后的文本,可以得到每一篇数据分析报告都是一个高维向量,此时数据呈现结构化。在预处理完的数据中选取了几个样本展示,如表1 所示。

表1 数据预处理部分结果
3.2 特征选择
数据分析报告中的评分细则一般包含几个部分的分项评分,即选题、资料检索、整理、阅读、变量描述、数据预处理、软件运用、模型使用与评价、工作量与进度、书写、逻辑、格式、创造性与思考深度等。根据这些分项选定可以测度的量化指标变量,然后从文本的各种特征出发匹配。本文根据以上分项评分,选定了以下7 个变量,即主题变量、描述性变量、工作量变量、内容丰富度变量、逻辑变量、格式变量、资料运用能力变量。
数据分析报告是否偏离主题内容的一个特征就是全文主题的一致性,一致性最直观的表现就是主题词的共现频率,主题词的确认会直接显示在数据分析报告的题目中,比如“Facebook 帖子评论数预测分析”中可以直接得到该篇主题为“帖子”和“评论”,文章的内容都离不开这2 个核心主题词。通过提取这样的特征进行评分框架的搭建。
衡量数据分析报告的专业性离不开正确的数据分析方法,它是写作者专业能力的综合性展现。数据分析报告应该涵盖数据描述性分析、数据预处理、数据建模分析及总结等内容,其中会出现大量的统计专业名词,例如“相关系数图”“显著性水平”“回归分析”“决策树”“logistic 回归”等,在文章中寻找这类专业名词。
体现数据分析报告总工作量的特征就是文章篇幅含量。文章内容越多则说明作者工作量越多,通过计算文本分词后的总词数进行数分报告工作量的评估。文章语言内容的丰富度离不开名词的占比,提取文章中名词数量来评估数据分析报告的语言质量。
语言逻辑性是数据分析报告的最基本要求,它包含文章完整、内容简明扼要、整体连贯且合乎逻辑,其中最重要的是文章的逻辑通顺流畅性。逻辑通畅与否体现在文章中出现的逻辑词。
规范数据分析报告的写作格式能够向读者准确传达写作者的研究思路。从评分角度来看,一篇结构清晰完整的文章能够获得更高的分数。通过检索文章中的段落标题序号来体现文章整体格式规范问题。
在进行实证分析的过程中,写作者根据研究方向需要参阅和利用大量的科学文献,对于主要引用的文献需要在文章末尾注明出处。考察写作者对参考资料的运用能力,检索数据分析报告中引用的文献资料数量。本文共计选取了7 个可以测度的量化指标变量,分别从数据分析报告的内容、专业性和格式2 个方向进行评分,如表2 所示。
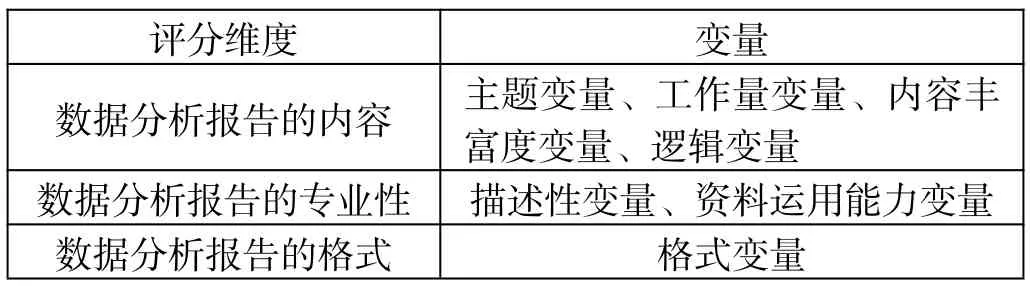
表2 特征维度
3.3 自动评分算法实验
通过以上数据的预处理和特征选择可以得到适用于机器学习模型的结构化数据与特征变量。本节利用这些数据和几种常见的机器学习模型对数据分析报告进行模型的学习和验证,从而实现自动评分,接下来分别从实验方法和实验结果这2 个部分进行详细的描述。
3.3.1 实验方法
数据分析报告的自动评分算法是基于已有的历史数据进行监督学习,由于该数据的标签是连续型数据,可以将其抽象为一个回归问题。将提取出来的特征作为影响最终评分结果的变量,通过训练模型学习特征重要性,从而预测待评分文本的分数。回归问题下常见的机器学习模型有线性回归、决策树、随机森林、Boosting 等,接下来将使用这些模型分别对数据进行训练。本文实验抽取50%的数据进行训练,利用剩下50%的数据进行测试,共进行100 次重复运算实验。
3.3.2 实验结果
对于模型的训练结果,本文主要采用了平均预测误差(Mean Prediction Error,MPE)和平均训练误差(Mean Training Error,MTE)这2 个指标进行评价。各个模型的评价指标结果如表3 所示,综合来看随机森林模型的表现结果更好。因此,本文使用基于随机森林的数据分析报告自动评分算法,随机森林是一种特殊的Bagging 方法,简单来说就是构建多个决策树并将它们合并在一起以获得更准确和稳定的预测。使用随机森林进行待评分文本的预测可以得到人工评分和机器自动评分的平均预测误差在3.85 分左右。

表3 实验结果
基于已经搭建好的随机森林模型,可以从中评估特征变量的重要性。图1 为变量重要性排序图,图中的“IncNodePurity”是通过残差平方和来度量,它代表了每个变量对分类树每个节点上观测值的异质性的影响,从而比较变量的重要性,该值越大表示该变量的重要性越大。据此可以判断出工作变量和描述性变量2 个变量与数据分析报告最终得分密切相关。

图1 变量重要性排序图
由以上实验结果可知,对结构化的文本数据进行预处理后,利用随机森林建模能得到更准确的评分结果,还能提供重要特征进行教学反馈。上述实验反映的预测结果和实际打分情况存在差异,但是差异结果不大,与费时费力的人工评分相比,机器自动评分可以显著地节省时间成本和人力成本,还能反馈重要的特征变量给教师,教师据此可以进行以评促学的教学模式改革。
4 结论
本文将人工评分系统与自然语言特征相结合提出了一种新的自动评分算法。将人工智能的定量研究引入教学过程,通过自动评分模型的搭建完成数据分析报告的自动化评分,从而很大程度上地缩减了繁复的人工打分过程,以及消除了人工打分过程中存在的主观因素,并且从模型中发现工作变量和描述性变量这些文本特征是非常重要的,未来有助于相关方面的教学强化——譬如在工作量保证的前提下,教师应当重视专业方面的学习指导,锻炼学生的语言组织能力及逻辑思维能力,引导学生如何阅读以及使用文献资料,即实现有模型指导的以评促学的教学实践。
同时,本文工作在未来还有待提升的方面。首先是考虑增加样本量,由于搜集到的实验样本量较小,一定程度上影响实验精度;其次是如何将人工评分中的非语义特征考虑进模型,量化非语义特征,提高自动评分结果的精确性;最后,如何持续提高数据分析报告自动评分算法的准确率,也是未来持续研究的问题之一。
